中文HMM参数化语音合成系统构建
2012-08-10康世胤
胡 克,康世胤,郝 军
(新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046)
0 引言
在语音合成领域,基于大语料库的拼接合成系统的合成质量已经达到了相当不错的水平,甚至能够在特定条件下形成产品。但这类方法存在的固有弱点,如语料库构建成本高,合成稳定性低,灵活性较差等。这些弱点限制了拼接合成方法的进一步应用。而基于统计模型的参数化语音合成技术恰恰在构建成本和合成多样化方面展现出其独特的优势,因此逐渐得到广泛的应用。
在这种背景下,文中以基于HMM的参数化语音合成系统为基础,针对中文语音的特点,构建出中文HMM语音合成系统。
1 隐马尔可夫模型
隐马尔可夫模型是一种时间序列上的统计模型,它广泛的应用于多个领域,尤其是语音识别[1]。近年来,HMM在语音合成中也有了成功的应用。HMM是一个有限状态机,它可以生成一个离散时间的观察序列。在每一个时间点,HMM由马尔可夫原则进行状态转移,并且产生一个观察值 o。这样的一个状态转移和输出包含两个概率:
1)状态转移概率ija,表示从状态i转移到状态j的概率。
2)输出概率 bi(o)。

图1是典型的HMM模型示意图。图1(a) 是一个3状态互联的HMM模型,这个模型中任何一个状态都可以在一定的转移概率下到达任一个其他状态。图1(b)是一个3状态由左到右HMM模型,这个模型里一个状态随时间增加,在转移概率的作用下,有可能保持状态不变或到达下一个状态。可见,由左到右HMM模型十分适合用来为随概率变化的信号建模,它的这种特性可以很好地应用在语音识别及语音合成领域。
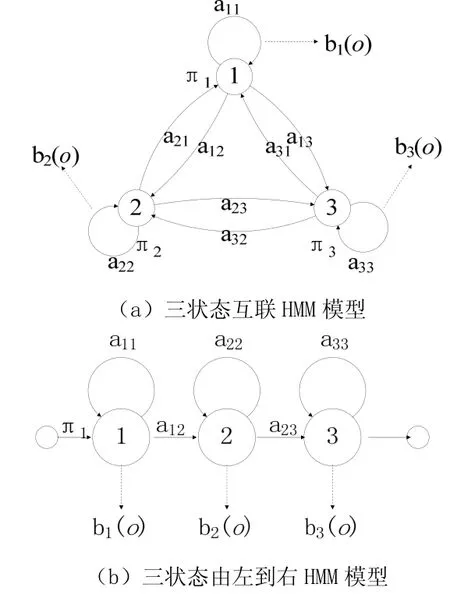
图1 HMM模型示意
由于观察序列 o可能是离散的也可能是连续的,那么对它的描述可以用离散的概率,也可以用连续的概率密度来表示。一般来说,在语音合成中使用的是一个或者多个高斯混合密度,表示为:

式中,M是高斯核的个数,imw 是某一个高斯核的权重,imμ为这个高斯核的均值,imΣ是方差。
2 基于HMM的参数化语音合成
2.1 系统基本结构
基于HMM的参数化语音合成系统的基本结构如图2所示。系统可以分为训练和合成两个部分。从中不难看出,在训练过程中,语音信息经历了从原始波形信号到声学参数序列,再到统计模型集合的变化过程;与此相对应,在合成过程中,又经历了从统计模型集合到声学参数序列,再到合成波形信号的逆过程。
2.2 训练过程
在训练部分,首先从语料库录音数据中提取频谱和基频等声学参数。
然后根据ML准则,使用EM算法[2]训练声学参数向量序列的HMM模型。这个训练过程与语音识别种模型的训练过程非常相似,主要的不同在于语音识别中,一般只对谱参数进行建模,而在HMM合成系统中,使用一种多流 HMM为谱参数和基频参数建立统一的语境相关模型。另一个不同则是除了语音学特征之外,HMM合成系统还使用语言学和韵律学的特征描述语境。建模过程中,由于基频参数曲线的特殊性,无法使用离散或者连续分布描述,HMM合成系统使用多空间概率分布(MSD)[3]作为 HMM的状态输出概率分布。同时,系统使用高斯分布或者伽马分布建立状态时长模型来描述语音的时间结构。
最后,使用语境决策树分别对谱参数模型、基频参数模型和时长模型进行聚类。这就得到了合成使用的预测模型。
2.3 合成过程
在合成部分,首先使用文本分析工具将给定文本转换成包含语境描述信息的发音标注序列,使用前面得到的决策树预测出每个发音的语境相关 HMM模型,并连接成一个语句的HMM模型。
然后,使用参数生成算法从语句HMM中生成频谱和基频的参数序列。这个过程可以看做语音识别的逆过程,是求给定HMM模型的最大概率输出序列最后使用参数合成器将声学参数合成为语音信号。对于MCEP谱参数,可以使用Mel对数谱逼近(MLSA)滤波器[4],作为参数合成器。

图2 基于HMM的参数化语音合成系统结构
3 中文合成系统的构建
3.1 数据准备
训练样本集是整个语音合成中参数训练系统的基础,它质量的好坏,对语音合成系统的最终合成效果有着决定性的影响。在本节中,首先从原始数据库中对语音样本进行筛选,选择发音清晰、韵律平衡的样本作为语料库的原始数据,然后依照一定的策略,从原始数据库中提取对应样本的标注信息,生成适合于HMM参数训练的文本标注信息,并最终建立适合于中文 HMM参数化语音合成的语料库。
(1)语音样本的筛选
原始数据库中包含女声语音样本6 445个。每一个语音样本中具体包含如下信息。
1)语音波形数据。
2)基于音节的切分时长信息。
3)音节的有调拼音。
4)韵律词和韵律短语的切分信息。一个典型的音节和韵律标注文件如下所示:
/为临帖/他还|远游|西安|碑林/龙门|石窟/泰山|摩崖|石刻/./

文件包含两行,第一行是语音样本的中文信息和相应的韵律词和韵律短语的切分信息。其中,“/”为韵律短语的切分点;“|”为韵律词的切分点。第二行是语音样本对应的拼音标注。拼音标注以汉语拼音方案为基础,用附加在拼音后的数字表示声调,其中5表示轻声。
经过逐条筛选,剔除了录音不清晰、切分信息丢失和拼音标注不正确的样本,最终选择了其中的6 429个完整有效的样本建立语料库。
(2)语境标注信息提取
语境标注信息的内容主要包含当前音节的发音信息,例如拼音、声调、声母和韵母;语境发音信息,例如前后音节的拼音;时长信息,例如当前音节在语音波形数据中的起止时间;韵律切分信息,例如韵律词和韵律短语的划分。
3.2 声学参数提取
和波形拼接方案的语音合成系统不同,可训练的参数化语音合成系统不直接使用原始的波形数据建立发音单元模型,而是使用相应的声学参数建模。在文中构建的中文HMM参数化语音合成系统中,使用24阶Mel倒谱(MCEP)参数和基频F0参数作为原始语音数据的声学参数建立和训练HMM。
相对于其他声学参数,例如LSP参数,STRAIGHT参数,MCEP的主要优点在于其提取算法成熟,合成音质较高,计算复杂度低,能够实现实时合成等。
3.3 建模单元选择
HMM参数化语音合成系统中,首先要确定发音单元的尺度。发音单元作为HMM训练的基本单位,必须有一个合适的尺度,才能保证良好的训练效果和较短的训练时间。
英文和其他一些语言的合成系统中,常常使用音素作为基本发音单元。这是和语种相适应的。对于英语这样基于单词的语中,不同单词的发音结构和程度变化很大,建立统一的发音单元模型相当困难,因此必须使用较小的发音单元建模。音素,作为发音最小的单位,其发音结构简单,总数较少,比较适合于建立发音单元模型。
在中文的参数化语音合成系统中,也可以使用音素建模,但这个样做有以下几个不足。
1)以音素为单元建模,尺度较小,增加对原始语料库标注切分信息的难度。
2)以音素为单元建模,虽然模型的种数较少,但是在音素级别上,发音单元间的连接更加紧密,相互影响作用较强,在考虑上下文的训练系统中,需要花费大量的时间考虑音素的相连关系和相互影响,反而增加了模型的复杂度。基于以上两点,文中认为中文的HMM建模单元尺度应当选择的较大,例如声韵母单元或音节单元。对于汉语语音,无论是身韵母还是音节,都有较为统一的结构:典型的声母包括3个部分,典型的韵母包括5个部分,而绝大多数音节可以划分为8~9个部分。汉语语音的这种结构相对固定的特点,决定了在设计汉语语音的HMM单元时,可以使用声韵母或者音节作为基本发音单元。在进一步研究中,文中对比了使用声韵母和音节两种单位作为基本发音单元时,对合成质量的影响,如图3所示。在训练数据较少时,由于汉语音节较多,每个单元的训练数据相对更少,因此合成音质劣于以声韵母为单元的系统。随着训练数据的增多,音节级的系统音质迅速提高,而声韵母级的系统则因为发音单元尺寸较小,在韵律方面,尤其是声韵母时长比例上存在较多问题,因此总体得分不如音节级的系统。

图3 不同的建模单元对合成质量的影响
在文中的HMM语音合成的训练系统中,使用音节作为基本的发音单元建立 HMM,包括描述静音段的发音单元模型在内,共有音节标注775个。使用音节作为HMM基本单元,在训练时只用考虑音节之间的相互影响,而实际上,在汉语标准普通话中,音节间的相互影响较少,这样的设计也有助于获得较好的训练结果,并最终得到高质量的合成语音。
3.4 HMM拓扑结构选择
如前文所述,HMM拓扑结构主要指 HMM中的隐藏状态数目和状态之间的跳转关系。
在以音节为单位的HMM建模中,音节内部一般不存在发音相同但间隔排列的音素,以HMM的状态转移描述时,就不应当存在转移至曾经经历过的状态这种情况。因此HMM对语音建模一般使用从左至右各态经历的结构。
模型的状态数目应当根据发音单元的尺寸来选择。状态数目太少,不足以描述相对变化较为复杂的发音单元;状态数目太多,则会增加不必要的训练时间。在以音素为HMM单元建模的语音合成系统中,由于音素的时域结构相对简单,状态数一般取3~5,就能得到不错的结果。当发音单元尺度增加时,状态数目也应当相应的增加,以便很好的描述更加复杂的大尺度的发音单元。考虑到音节内部的划分情况,文中使用10状态HMM对音节进行建模。
4 结语
近几年来,语音合成技术有了长足的进步和发展。目前,在一些特定情况下,大语料库的拼接合成技术已经能满足部分应用需求。文中分析了基于HMM的参数化语音合成系统的基本结构和构建流程[5-8],并以此为基础,针对中文语音的特点,构建了中文HMM语音合成系统,并从数据准备,声学参数提取,建模单元和HMM拓扑结构选择等几个方面探讨并确定了适合于中文系统构建的参数,拓广了可训练化语音合成技术在中文语种的应用。而在韵律建模和时长模型方面,仍然需要进一步的研究,以提高中文语音合成的自然度和可懂性。
[1] RABINER L. A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition[J].Proc. IEEE, 1989,77(02):257-286.
[2] DEMPSTER A, LAIRD N, RUBIN D.Maximum Likelihood from Incomplete Data via the EM Algorithm[J].Journal of Royal Statistics Society,1977(39):1-38.
[3] TOKUDA K,MASUKO T,MIYAZAKI N,et al.Multi-space Probability Distribution HMM[J]. IEICE Trans. Inf.Syst., 2002, E85-D(03):455-464.
[4] IMAI S, SUMITA K, FURUICHI C. Mel Log Spectrum Approximation (MLSA) Filter for Speech Synthesis[J]. Electronics and Communications in Japan, 1983,66(02):10-18.
[5] 卡斯木江·卡迪尔,古丽娜尔·艾力,艾斯卡尔·艾木都拉.基于最对合成单元的维吾尔音库设计[J]. 通信技术,2012,45(04):83-85.
[6] 俞一彪,段凯宇,石汝杰.吴语文语转换中的语音韵律控制[J].通信技术,2002(10):1-3,9.
[7] 胡晓荷.周光召和柳传志对“语音云”寄予厚望——移动互联网步入“语音云”时代[J]. 信息安全与通信保密,2010(12):39-41.
[8] 刘帅,王以刚.VoIP的语音动态加密方法研究[J]. 信息安全与通信保密,2009(02):74-75.
