论图书馆OPAC查询记录统计分析功能的缺失及改进
2012-06-28田禹
田 禹
(黑龙江东方学院,哈尔滨 150086)
1 引言
OPAC是图书馆提供馆藏信息的窗口,也是读者自助式查询图书馆馆藏文献信息的主要途径[1],OPAC查询日志是读者向图书馆提交信息需求请求的客观真实反映,是分析读者需求及馆藏覆盖情况的有力依据。
当今,网络文献检索最常用的方法就是关键词匹配检索和内容分类检索,它们都是直接使用自然语言的方法。机检中,自然语言对表征文献的主题内容具有实质意义[2]。所以,读者通过向检索入口输入检索语言来获得文献的同时,其实也是向图书馆直接表达自己的信息需求,而且,这种需求的迫切程度要远高于图书馆向读者征询时所得到的反馈情况。
OPAC检索框是读者向图书馆提交信息需求最直接最便捷的入口,读者点击检索按钮实际上就是向图书馆提交了那时那刻他最明确最迫切的想法,就是直接告诉了我们他最想要的是什么。遗憾的是,对于如此明确的信息要求,图书馆却没有给予足够的重视。现在多数图书馆对读者自主检索的做法并不关注,若检索没有命中也仿佛不干我事,若读者强烈需要的一些文献还需单独向资源建设部门荐购。
OPAC系统是以Web方式发布的,Web服务器上都存有结构性较好的访问日志(Weblog),每当有获取资源的请求时,Web服务器都将记录和积累这些数据,包括所请求的URL、发出请求的用户地址和时间戳等。不同的Web日志格式不尽相同,但内容上都大同小异。
汇文OPAC系统以Apache作为Web服务器,Apache的访问日志以文本形式存放于access.log文件中,每一行为一个访问记录,记录内容由7项构成,第一项是远程主机的地址;第二项用于记录浏览者的E-mail地址,目前这项几乎已是形同虚设;第三项是当网站的某些内容要求用户进行身份验证时,用于记录浏览者身份验证时提供的名字;第四项是请求的时间;第五项是反应服务器收到的是个什么样的请求,包括方法、资源、协议;第六项是状态代码,它告诉我们请求是否成功;第七项表示发送给客户端的总字节数[3]。尽管日志文件中包含着大量有用的信息,但这些信息是以文本方式存放在文件中的,并以流水账的方式呈现,所以我们不能马上从中得出结论。只有经过重新组织成结构化数据并深入挖掘之后才能够最大限度地发挥作用。在实际工作中,真正对OPAC查询日志有分析和统计需求的资源建设人员出于技术上和权限上的限制,其实很难对以文本形式存放于文件中的流水帐进行数据挖掘和分析,导致我们一边任由OPAC查询记录流失,一边又在另花功夫联系读者,希望他们提供文献需求信息。
2 OPAC查询日志统计分析的意义
(1)检索词是反映读者信息需求的第一紧要素材,这是检索行为本质决定的,不再赘述。
(2)检索语言的使用频次反应读者对该内容的需求程度。毋庸置疑,同一检索词使用一次和一万次意义是不同的。统计分析之后,对采访人员有很大的指导意义。
(3)某一时间段内的检索频次反应读者的关注程度,可以和热门借阅、热门搜索配合分析。
(4)检索词命中与否可反映馆藏覆盖率,为完善馆藏结构提供参考。
(5)检索命中记录与借阅记录配合分析可以看出同类文献的文献质量与读者偏好,如果某类文献较高的检索命中率与借阅次数无法匹配,则需分析这类文献是属于简单浏览没必要借阅还是因为文献质量与读者预期有较大差距。这里提到的文献质量包括文献适用水平、难易程度、开本大小、文献时效性、发行单位等等。
(6)查询记录与借阅记录配合分析可以为确定馆藏复本数是否合理提供依据,例如检索频次和借阅次数都很高的文献应该适当考虑增加复本。
(7)检索频次高低的周期性可用于确定文献的保障周期。例如读者对考试类参考书的需求具有很强的周期性,参考查询记录中检索词频次高低的周期性,可以拟定此类文献的最迟流通时间。
(8)具体借阅室内终端机的查询记录可用于分析馆藏文献布局是否合理。例如可探讨考研类图书是依分类法按学科分散排架还是入某一大类统一排架。
(9)可分析MARC规范语言与读者检索使用的自然语言之间的偏离程度,增强标引的规范性和全面度,同时也可以看出是否需加强读者培训,引导其规范检索行为,以提高其信息获取能力。
(10)有读者信息的查询记录反映出其独特明确的兴趣与偏好,可为图书馆开展个性化服务提供依据。读者的检索历史中包含有丰富的个性化信息,通过追踪和分析这些查询记录,可以从中挖掘出许多隐含的个性化信息。
3 图书馆自动化集成系统查询记录统计功能
笔者认为,当前主流图书管理系统对于查询记录的重要性有一定的认识,这一点体现在软件开发时对查询记录的统计功能有所考虑,但是功能的开发程度还不够,在应用中还没有形成成熟的分析利用方法。下面以国内图书馆应用比较广泛的汇文、金盘、ILASIII为例,分析图书管理系统的查询记录统计功能。
3.1 汇文
OPAC部分,馆藏书目检索界面的简单检索中,有热门检索词列表,如图1:
点击“more”后,结果如图2:

图1

图2
可以查看与某一具体检索词匹配的所有馆藏,例如查看曾国藩(7),显示如图3:
汇文系统能查看一个月以内的热门检索词,除此之外,用户登录后还可以查看自己所有的查询记录。
3.2 金盘
同样是OPAC部分,金盘系统书目查询界面如图4:
点击“更多”可以看到以下界面:
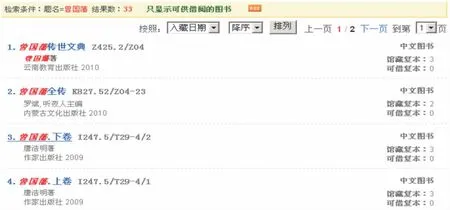
图3

图4
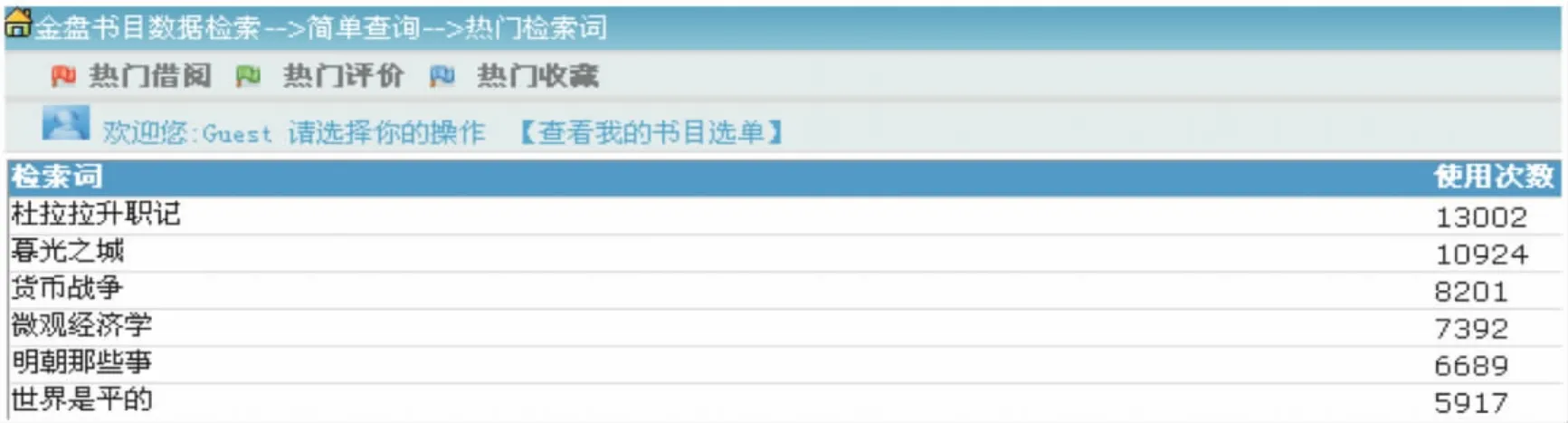
由此界面可以看到的是检索词和使用次数,系统并没有告诉我们检索词使用的起止时间,无法统计检索频次的周期性,也没有实现检索词和馆藏的链接,不能直接查看馆藏,如果想看与某一检索词匹配的馆藏信息,还需要重新进入书目查询界面查询。
3.3 ILASIII
ILASIII没有热门检索词的记忆统计功能,但无需用户登录,即可查看单机的检索历史,退出该界面后,检索历史记录消失,没有IP记忆功能。
综合以上国内几个主流图书馆自动化集成系统查询记录的显见统计功能,它们都是在书目查询入口进入;只限定在纸质文献的检索词统计,电子资源没有考虑在内;都有热门借阅、热门评价、热门收藏的推介栏目,是对读者检索的一种指引和展示,告诉他们近期什么比较热门,类似于一种推荐,而非图书馆工作人员的统计和分析,不是对读者需求全面、科学的量化反应,很难形成理性的思考和判断。
4 改进OPAC查询记录统计功能的设想
目前,国内知名的网上书店亚马逊和当当在顾客管理与需求分析上的做法有些是值得借鉴到图书馆查询记录统计功能的设计中的。信息时代,读者期望通过一个检索入口或者一次检索行为就能得到所需求的广泛信息,即通过统一的检索平台,不仅可以获取本馆馆藏书目记录,还可以获得本馆购买的电子资源、自建资源、光盘、多媒体资源并指向全文和链接[4],基于这个愿望的查询记录的统计和分析将更加有价值。
很多文献资源的需求是有其特定的周期的,那么,反应读者需求的检索频次是体现这个周期的有力证明。故笔者借鉴当当网的热搜词汇时间区间趋势图(图5),综合汇文和金盘系统热门检索词的统计功能,对图书馆在馆藏资源(印刷型资源和数字资源)整合之后的查询记录统计工作提出新的设想。
查看一年内该词的搜索趋势图,如图5所示:
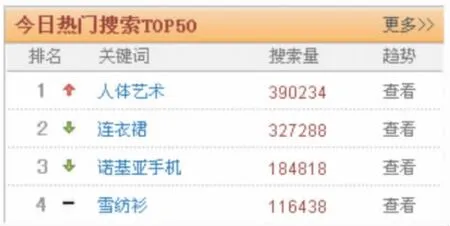
图5 当当网热搜词汇的排名表
上图的箭头表示当前该搜索词使用频次的变化情况,以“连衣裙”的搜索趋势为例,点击查看,可以看到半年内该词的搜索趋势图,如图6所示:
图6和图7说明不同的时间范围内同一检索词的使用频次是不同的。同样图书馆检索词使用的周期性也应该在统计中有所反应,出于笔者所在高校图书馆假期时间安排情况的考虑,特将统计的时间区间设定为1-2月、3-6月、7-8月、9-12月和全年,以“身份”这一检索词为例,结果见表1:
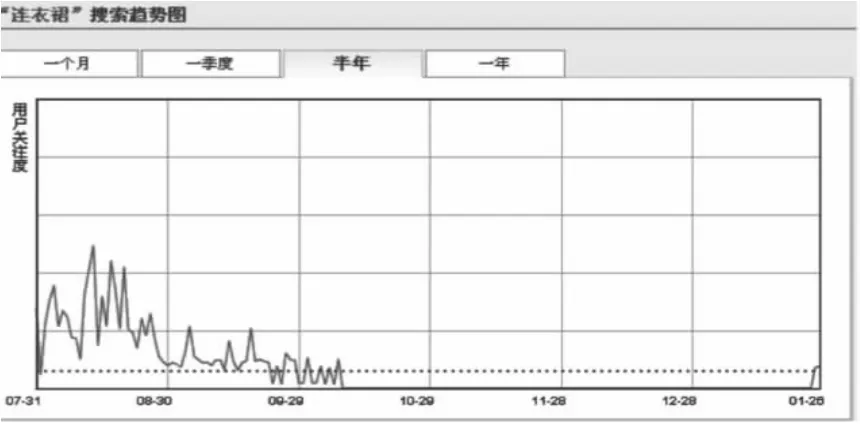
图6
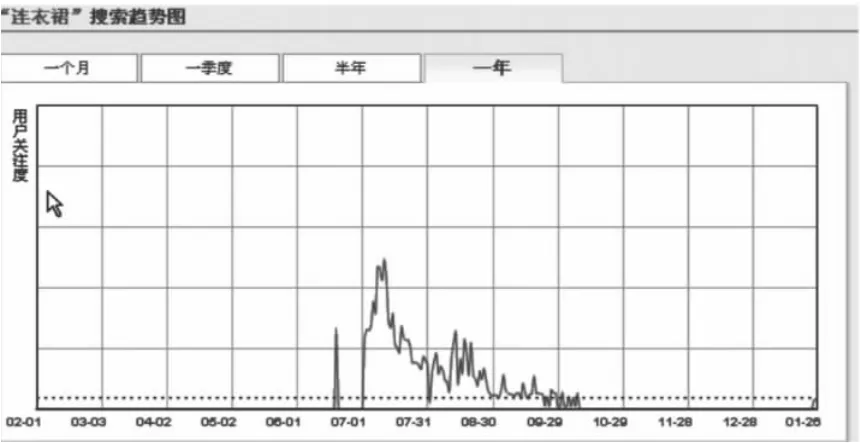
图7
与检索词匹配的命中结果可直接链接到馆藏信息,可显示包括命中记录的借阅情况、文献类型、分类、馆藏地点等等。例如点击命中结果数“印刷型9”,见图 8。
查看一年内该词的搜索趋势图,如图5所示:
图8是尚未实现印刷型资源和数字资源整合的检索结果,仅以此说明命中结果与馆藏信息的链接情况。

表1
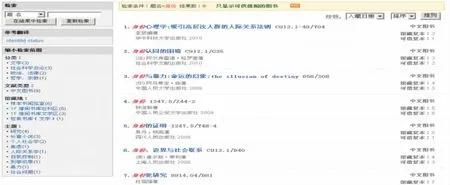
图8
从图8中可以清晰地反映某一时间段内与检索频率为3的检索词“身份”相匹配的馆藏资源有9条记录,其中9条都是印刷型,以及文献类型、借阅情况、馆藏地点等信息。
5 结论
OPAC查询记录是读者信息需求的客观反映。目前,国内图书馆对于查询记录的统计分析尚处在起步探索阶段,图书管理系统也没有为此功能的开展给予足够的支持。我们不能停止探索此领域的步伐,也应该明确,查询记录只是分析读者信息需求的依据之一。在我们统计分析OPAC查询记录的同时,也应该考虑读者利用馆藏资源的习惯不同、读者信息素养的千差万别以及读者检索时使用的自然语言与标引规范语言的偏离等因素对检索词使用的影响,让OPAC查询记录的统计和分析结果更好地为资源建设和信息服务所用。
[1]朱 茗.基于OPAC的书目信息推拉服务[J].图书馆学刊,2010,(8):70 -72.
[2]孔 莉,马莎莎.关键词检索特性的计量学分析[J].现代情报,2010,(3):19 -21.
[3]林绮屏.基于OPAC日志的读者需求分析[J].农业图书情报学刊,2006,(1):46 -49.
[4]曹 霞.OPAC基本功能研究概述[J].农业图书情报学刊,2008,(10):58 -60.