基于校园卡数据挖掘的高校贫困生辅助判别研究
2012-06-01万里亚
周 皞,万里亚
高校贫困生资助是关系到教育公平的重要问题,而贫困生判别则是高校贫困生资助的前提和难点所在。贫困生判别问题的产生有其特定的社会背景,在某种意义上,它是资助资源稀缺的产物。面对资源有限和需求膨胀的矛盾,有效识别贫困生并将有限资源提供给最贫困者是教育资助的宗旨。笔者分析某高校1175位学生从2008年到2010年在校三年的校园一卡通消费数据,旨在如何利用校园卡消费数据来辅助评判学生(家庭)经济状况,为高校更有效的开展贫困生判别工作提供方法及实践参考。
一、贫困生判别方法述要
贫困生又称家庭经济困难学生,是指学生本人及其家庭所能筹集到的资金,难以支付其在校学习期间的学习和生活基本费用的学生(教财[2007]8号文)。贫困生判别是指依据一定的理论和方法,对贫困学生家庭经济困难程度所做的评价。从操作层面上而言,贫困生判别是指通过一定的方法把贫困生从学生总集合中选出来。
国内外关于贫困生判别方法有所不同。西方发达国家基于完善的税收机制,可以比较准确地掌握学生家庭的经济收支,多常用“公式法”(又称“模型法”)测算贫困生家庭经济状况由此来判别贫困生。
在我国各高校贫困生判别方法没有统一的标准,通常采用定性与定量结合的方法判别贫困生。[1]其具体实施步骤为三个方面:(1)各高校需了解学生经济情况。依靠学生入学时填写的《高等学校学生及家庭情况调查表》或者贫困证明,即高校对学生经济困难程度的判别,仅限于学生入学时提供的调查表或县乡村三级证明、相关困难证件(如《特困证》、《最低生活保障证》、《社会扶助证》等)证明;(2)依靠评价学生的经济消费,如饭卡监督、低保标准和月生活费监督等;(3)根据班主任、辅导员对学生了解情况等鉴别。
由此判别方法建立起来的评判指标体系虽可较全面反映学生(家庭)经济状况,但由于其所涉及的数据收集量过大,数据质量往往得不到保障,加上一些指标不易量化,且不同地区的情况可比性差等原因,致使实际工作中困难重重,可操作性较差,其效果并不理想。
二、校园一卡通及数据处理
随着教育信息化建设在高校的不断深入,许多高校已逐渐建立起了一系列功能日臻完善的校园一卡通系统。校园一卡通系统是学校重要的综合性信息管理系统,在学校信息化建设中占据着重要地位。目前,高校所建的校园一卡通系统一般提供消费缴费、身份识别以及信息管理三大功能,其中消费缴费功能较全面地反映持卡人在学校生活期间的总体消费额度和结构情况。[2]考虑到高校学生的生活消费基本上集中在校园内部,故可以基于校园卡的消费数据分析来辅助推测、评判学生(家庭)的经济状况。
高校在建设校园一卡通系统时所覆盖的校内消费缴费项目可能各有不同。一般来说,覆盖的消费缴费项目越多,其消费缴费数据反映学生(家庭)经济状况越准确。在众多消费缴费项目中,虽然有些的额度属于政策规定且相对固定的,有些消费的发生属于意外或随机的,但更多的则与学生的个人情况密切相关,所以通过合理分析和数据挖掘,可以测度出消费数据与学生经济状况的关联规则。
在校园一卡通系统中,消费数据具有明确的消费项目标识,原始数据是以流水记录形式存于数据库的。在使用消费数据进行数据分析前,需要对原始数据进行必要的整理,一般应按学生的卡号、班级、年级、院系、专业、性别与消费发生时间、额度、消费项目等重新组织流水记录,最好是另建数据仓库,以适应数据运算需要。数据处理工作主要由数据类型转换、缺失值处理和删除孤立点三部分组成,将“校园一卡通”消费原始数据进行初步的分类、合并、筛选以及整理,并将其保存在数据仓库中。实证研究中,笔者汇总了某高校1175位学生在校三年的一卡通消费情况,建立了数据仓库,数据仓库由Micro soft SQLS erver 2005 Analys is Services提供。
三、实证研究及研究结果
实证研究主要采用基于关联规则的分类算法:(1)将数据仓库中的数据分为训练样本和测试样本两大类;(2)通过关联规则挖掘算法在训练样本中找出与学生的经济情况有较强相关性的特征规则;(3)利用这些特征规则对测试样本进行预测分类,输出分类结果。简而言之,研究所要解决的问题是:给定一个学生的校园卡消费数据,将其分类为贫困生和非贫困生两类。也就是说,要解决的核心问题是如何定义一个学生基于消费数据的特征向量,然后找到特征向量与是否为贫困生之间的关联规则,并用这些规则去预测新学生是否为贫困生。
(一)基于关联规则的分类算法原理
给定一个数据类型为
算法的目标是在给定一个支持度阈值α和置信度阈值β的情况下,算法通过结合规则挖掘算法找到一系列满足这两个阈值的属性值与类别的对应规则,并通过这些规则判断未知类别的测试数据。其中,支持度是指属性值和某个类别之间的对应规则在整个训练集的出现概率,而置信度是指给定属性值的对应数据集合,属性值和某一类别之间的对应规则在这个集合中出现的概率。此类规则挖掘算法常用的有Apriori算法和F P-growth算法等。
(二)特征向量建立
基于已有的贫困生和非贫困生数据,可以分析建立相关特征向量,然后计算出特征向量与贫困生之间的关联规则。基于关联规则和新的学生的消费数据,再来辅助判断新学生是否是贫困生。假设挖掘出一条规则“{三个学年的总消费金额<5000;三个学年平均每次消费金额<5}==>贫困生”,那么满足这条规则的学生,可以判断其为贫困生,然后将此规则判断结果提交给学校相关部门作为辅助决策。
经过分析,研究建立的特征向量如下表所示,其中的特征代码和数值级在实验结果中解释。特征向量可以根据实际的情况不断调整(增加、修改或者删除),从而使得算法不断优化。
(三)实验结果及分析
训练数据中,学生数量为1175个,其中非贫困生数量为743,贫困生数量为432。因此,非贫困生规则选择的置信度至少是743/1175=0.63以上,贫困生规则选择的置信度至少是432/1175=0.37以上。根据实际情况可以提高置信度阈值进一步筛选,目前在支持度阈值为0.1和底限置信度阈值的基础上得到关联规则若干条,举例如下。
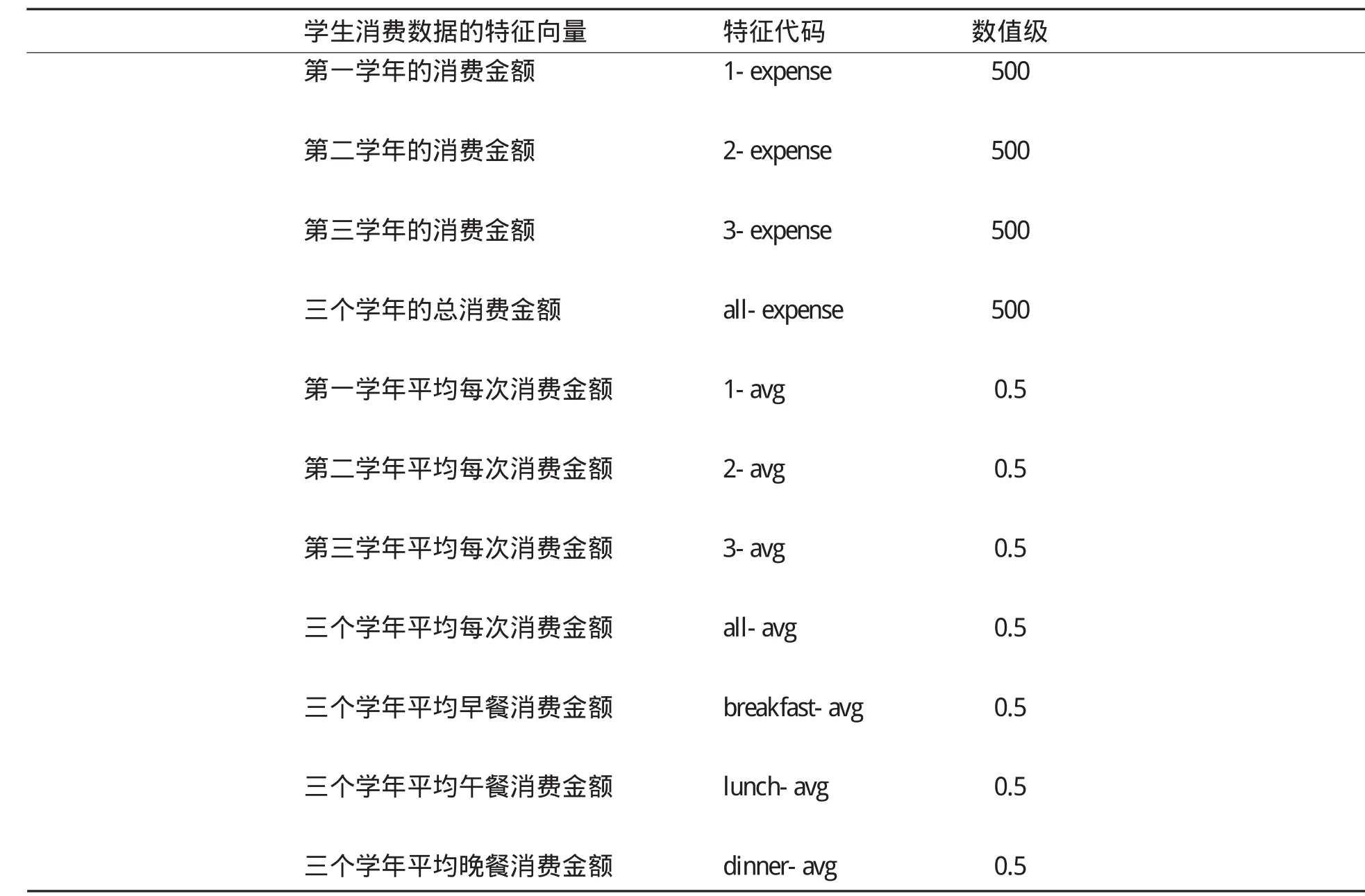
表1 消费数据的特征向量

该规则的解释如下,“1-avg”是特征代码,对应表中的“第一学年平均每次消费金额”特征向量,数量级为0.5,1-avg=6表示消费金额在6*0.5到7*0.5之间;“lunch-avg”对应表中的“三个学年平均午餐消费金额”特征向量,数量级为0.5,lunch-avg=8表示消费金额在8*0.5到9*0.5之间。满足此条件的学生个数为162个,其中非贫困生128个,置信度为0.79。

该规则的解释如下,all-avg在5*0.5到6*0.5之间,满足此条件的学生个数为297个,其中非贫困生129个,置信度为0.43。
类似关联规则可以通过调整特征向量和支持度和置信度阈值来不断优化,再利用这些关联规则对测试样本进行预测分类,用于贫困生判别辅助决策。
综上所述,以高校学生校园一卡通消费数据为基础,提出了将数据挖掘技术应用于高校贫困生辅助判别的一种新思路。笔者设计了基于数据挖掘技术中的分类预测和关联规则的数据挖掘模型,并利用该模型对实际数据进行挖掘计算,并以期挖掘贫困生判别的关联规则,作为贫困生评定工作提供辅助依据。数据挖掘模型的使用效率,可以通过调整特征向量和支持度和置信度阈值来提高,这也将是课题组今后研究工作需要进一步关注的重要内容之一。
[1]毕鹤霞.中国高校贫困生判别方法及其认同度的实证研究[J].高教探索,2011(4):118-123.
[2]宋德昌.基于校园卡的学生经济状况评价方法研究[J].中山大学学报(自然科学版),2009(S 1):9-11.
