半监督系数选择法的人脸识别
2012-03-23崔鹏张汝波
崔鹏,张汝波
(1.哈尔滨工程大学计算机科学与技术学院,黑龙江 哈尔滨150001;2.哈尔滨理工大学 计算机科学与技术学院,黑龙江哈尔滨150080)
主成分分析(principal component analysis,PCA)与线性判别分析(linear discriminant analysis, LDA)是基于子空间特征提取的2种重要方法,它们成功地用于人脸识别[1-4].然而PCA与LDA作用于图像时,产生的向量空间通常有非常高的维数,使得PCA与LDA难于执行[5-8].此外,由于PCA属于无监督学习,自动进行聚类,但其一旦偏离分类方向,会产生非常大的错误;LDA属于监督学习,需要人工对未标记数据进行大量的标注,需要耗费大量的人力和物力.半监督学习的训练样本由少量的有标记样本以及大量的无标记样本组成.在学习过程中,根据少量有标记样本选择初始的约束条件,进行聚类或分类[9-12].离散余弦变换(discrete cosine transform,DCT)的一些特殊属性使它成为人脸识别的一种有效变换,它能够降低数据维数以避免奇异性,并减少PCA以及LDA的计算代价[13-16].本文提出了一种约束聚类最优DCT(constrained clustering-based optimal discrete cosine transform,CCODCT)系数选择法,将每个DCT系数与判别系数(discriminant coefficient,DC)联系起来,通过选取较大DC值对应的DCT系数,得到最优DCT系数阵,实现数据降维.
1 CCODCT系数选择法人脸识别过程
本文提出的半监督CCODCT系数选择法的人脸识别的过程如下:
1)将图像数据库随机划分为训练集与测试集;
2)计算所有训练图像的DCT系数;
3)通过预掩模选择图像的DCT系数,选取中频有效信息;
4)根据有标记的训练样本种子集,计算初始聚类中心,采用半监督约束聚类对图像进行聚类;
5)根据获得的分类,计算判别系数,得到判别系数(DC)阵;
6)对DC阵的列向量按照降序排列,分别选取前n(n为想要的特征数)个最大值,并标记它们相应的位置;
7)选取每个列向量前n个最大值对应的DCT系数,得到n×P的最优DCT系数阵,其中n≪K;
8)对测试集用分类器计算识别率,文中采用的是最小欧式测度分类器.
2 离散余弦变换与半监督约束K-Means聚类
2.1 DCT系数阵以及掩模
DCT特征提取由2个阶段组成.在第1阶段,应用DCT到整个图像以获取DCT系数.然后,在第2阶段选择一些系数构建特征向量.DCT系数阵的维数与输入图像的维数相同.实际上,DCT自身并不能降低数据维数,它将大多数信号信息压缩在一个比较小的百分比中.一张M×N图像对应一个二维矩阵,其DCT系数阵可进行如下计算:

其中:

式中:A(m,n)是图像阵在位置(m,n)处的灰度值,D(p,q)是DCT系数阵在位置(p,q)处的值.因而对整张图像DCT变换,可以获得相同维数的系数阵.
通常DCT系数分成3个频带,即低频、中频及高频.低频与光照条件相关,高频表示噪声及小的变化,中频系数包含了有用信息及建立图像的基本结构.图1说明了一张典型的人脸图像和它的DCT系数的频率分布.图1(b)为第1阶段采用DCT变换后,DCT系数的频带分布.图1(c)为带状(ZM)掩模,通过带状掩模与原始图像相乘得到第2阶段选择的DCT系数,包括中频有效信息.可看出中频系数在人脸识别中是更适合的候选.

图1 典型图像DCT系数频率分布以及ZM掩模Fig.1 DCT frequency distribution of a typical image and ZM masking
图2为80×80图像,对应DCT阵在不同ZM掩模提取的图像.通过选择适当的掩模,可以达到降低数据维数的目的.

图2 80×80图像在不同ZM掩模下提取的图像Fig.2 80×80 image with different ZM maskings
2.2 基于DCT的半监督约束K-Means聚类
在前面对图像的DCT阵进行了预掩模,达到了维数的初步约简,接下来要对图像进行分类.本文采用半监督约束K-Means进行聚类.
1)首先计算各Sh的均值作为各个类别的初始聚类中心:

由式(2)得到k个初始类别中心.
2)数据集的K-Means聚类产生X的k个划分,以使K-Means目标函数是局部最小的(极小值).根据K-Means产生X的k个划分,每个划分为一个类集分配每个数据点到聚类(h*为类别标签):

3)根据得到k个划分,可计算t+1次迭代的聚类中心:
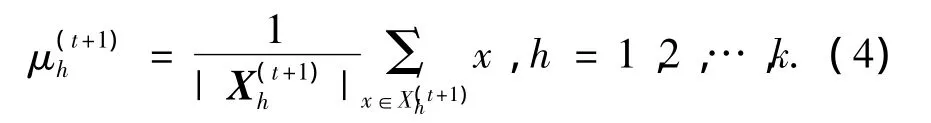
4)设定约束K-Means的收敛条件:
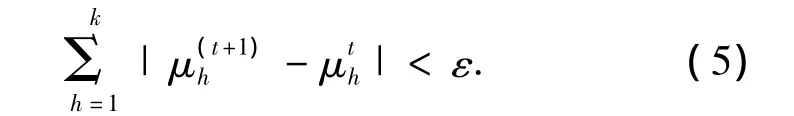
式中:ε为一个接近0的正数,重复执行2)~4)直至算法收敛.经过半监督约束聚类,对每个数据点进行了分类,类别标签为h.
3 基于判别系数最优DCT选择
传统系数选择法如Zigzag,ZM掩模以及对它们的修改选择DCT系数阵的固定元素,虽然它们很简单,但并不一定对所有数据库都高效.本文提出一种判别系数(DC)选择法,能够根据判别系数大小选择DCT系数,从而提高正确识别率.目的是要找到数据库的这些判别系数,并统计分析数据库中与每个DCT系数相关联的所有图像,称此方法为基于判别系数最优 DCT(optimal discrete cosine transform,ODCT)系数选择法.判别系数的特征是有最小的类内变化,最大的类间变化.ODCT与PCA、LDA等不同,它利用类间与类内方差.PCA与LDA试图获得变换域中能最大化特征判别的变换,而ODCT搜索原始域中最好的判别特征.DC选择法与预掩模组合使其对有限数量的训练样本健壮.ODCT没有基于LDA法中常见的奇异性问题.ODCT可作为一种独立的降低特征维数算法与其他方法组合,ODCT-PCA、ODCTLDA是PCA、LDA的2种改进方法.
3.1 计算DC值
定义DC值依赖于2种属性:类间的大变化与类内的小变化,可通过将类间方差与类内方差来估计DC值,其中图像类别为半监督聚类确定的类别.在此方式下,希望能估计判别系数的较大值.大小为M×N图像的DCT矩阵如下:
训练集的每个DCT系数aij(i=1,2,…,M,j= 1,2,…,N)的DC值,可进行如下估计.
1)将每张DCT图像由2D进行1D向量化,得到训练图像库的(M×N)×P维DCT阵T:
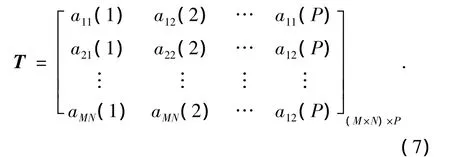
2)计算类内方差和:
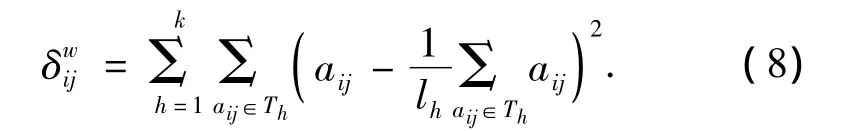
3)计算所有训练样本的方差:

4)计算位置(i,j)判别系数:
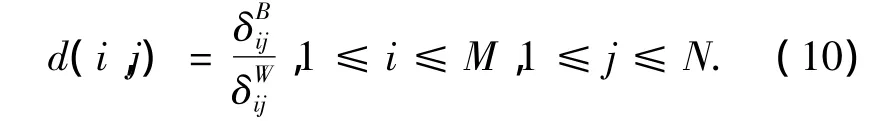
式中:d(i,j)表示判别系数阵M在位置(i,j)处的DC值.
5)判别系数阵M标准化:

式中:min(M(∶))表示M阵中的最小值,max(M(∶))表示M阵中的最大值.DC的高值意味着高判别能力,它们的值被标准化为0~1.
3.2 最优DCT掩模
由于DC系数选择法是一种统计分析,训练样本数影响其有效性.当每类有足够的样本数可用时,DC是一种优化的DCT系数选择法.
在前面提到DCT域被分为3个频带.在这些频带中,中频适合正确的识别.图3为在不同数据库中取前60个最大DC值对应的掩模.可以看出高DC值主要分布在低频以及中频部分,高频部分很少,这与DCT系数的分布相同.根据3个频带的属性,限定DC的搜索区域,避免由少量训练样本产生不合理结果.限定搜索区域会降低计算代价,在搜索区域取值1,其余位置取0,得到一个基于DC值的掩模,将掩模与DCT阵相乘,就可得到基于DC值的最优DCT系数阵.图3为ORL数据库图像以及在不同DCT掩模下的重构图像.
图4为ORL数据库图像以及在不同DCT掩模下的重构图像.
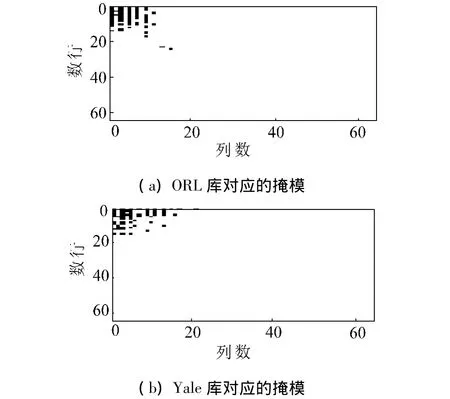
图3 不同数据库上选取前60个最大DC值对应的掩模Fig.3 Masking on different database with top 60 largest DC

图4 ORL数据库图像及在不同DCT掩模下重构的图像Fig.4 Images in ORL and reconstructed image with different DCT masking
图5为Yale数据库图像以及在不同DCT掩模下的重构图像.

图5 Yale数据库图像在不同DCT掩模下重构的图像Fig.5 Images in Yale and reconstructed image with different DCT masking
4 实验验证
为评估提出的方法,将提出的方法在人脸数据库上进行了仿真.实验用MATLAB7.0编程;在所有的仿真中采用了交叉校验的方法,将数据库分为训练集与测试集,在50组可能的训练与测试集下进行了仿真,结果为50轮运行结果的平均.为表示训练样本数量对不同方法的影响,每种方法使用不同训练图像数量执行仿真.
4.1 实验数据库
4.1.1 ORL人脸数据库
ORL数据库包含400张人脸图像,40个人每人10张图像.每人图像在表情、细节、姿势与尺寸等方面有变化.选取每人m(1≤m≤9)张图像,共40m张图像作为训练集图像;其余的40(10-m)张图像作为测试集.
4.1.2 Yale人脸数据库
Yale人脸数据库包含有重要变化的图像,包括对象戴眼镜、光照以及表情变化.数据库包括165张正面人脸图像,15个人每人11张图像.选取每人n (1≤n≤10)张图像,共15n张图像作为训练集图像;其余的15(11-n)张图像作为测试集.
4.2 实验结果
4.2.1 不同系数选择法的比较
传统方法系数选择法如Zigzag、ZM非常流行,比较了Zigzag以及ZM与ODCT法组合的6种方法识别率.ODCT为最优DCT系数选择法;ZM-ODCT先对DCT图像先进行 ZM预掩模,然后再进行ODCT系数选择;CCODCT为基于约束聚类最优DCT系数选择;ZM-CCODCT先对图像DCT阵进行ZM预掩模,然后进行CCODCT系数选择;Zigzag-CCODCT先进行Zigzag预掩模,然后进行CCODCT系数选择.
图6为6种不同方法在ORL与Yale人脸数据库上的识别率.由图6(a)可以看到Zigzag选择法的识别率最低.ODCT与ZM-ODCT的识别率较高,最高识别率达到95.5%.CCODCT与ZM-CCODCT在DCT数较少时,识别率稍低于ODCT与ZM-ODCT,但当DCT数达到60以上时,获得了接近ODCT的识别率.Zigzag-CCODCT表现不够稳定,在DCT数为20时达到最高识别率,而后随着DCT数增加,识别率反而下降.由图6(b)可以看出CCODCT的识别率优于其他方法,而采用Zigzag法以及Zigzag-CCODCT的识别率相对较低,这是由于Zigzag没有考虑到图像的先验信息;ZM-ODCT、ODCT以及ZMCCODCT也获得较好的识别率.
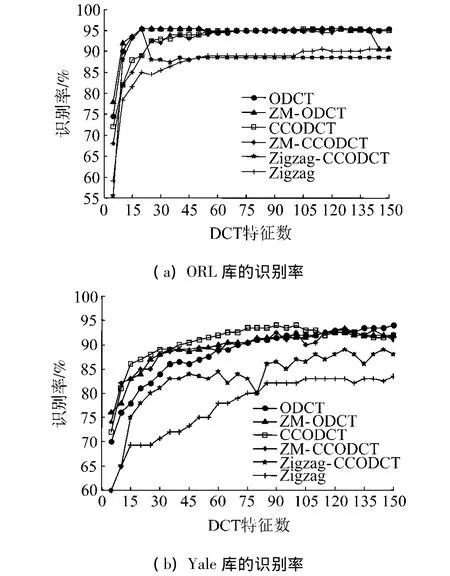
图6 6种不同系数选择法在ORL和Yale上的识别率Fig.6 Recognition rate of 6 different methods on ORL and Yale
4.2.2 系数选择法与PCA组合
传统的PCA是无监督学习,将系数选择法与其组合,得到4种组合方法,避免了小样本问题以及求解特征值的奇异性问题.ODCT-PCA先应用ODCT选择最优DCT系数,然后采用PCA投影;ZM-ODCTPCA先应用ZM预掩模选择DCT阵,并求最优DCT系数,然后应用PCA投影;Zigzag-PCA先应用Zigzag进行DCT系数选择,然后应用PCA投影;ZMCCODCT-PCA先应用ZM预掩模选择DCT系数,再应用CCODCT选择最优DCT系数,最后应用PCA投影.
图7为ODCT与PCA组合法在ORL与Yale人脸数据库上的识别率.由图7(a)中所示,Zigzag-PCA的识别率最差;ODCT的识别率最高,其在DCT数为5时,识别率就达到了82%,在20处就达到了峰值95%;ODCT-PCA、ZM-ODCT-PCA以及ZM-CCODCTPCA也获得了较高的识别率.在图7(b)中考虑了光照问题,Zigzag法放弃特征向量的前3个系数,ZM预掩模放弃DCT阵的前2行2列.在5种方法中,ZM-ODCT-PCA的识别率要优于其他方法;ZMCCODCT-PCA、ODCT-PCA以及ODCT的识别率接近最优;Zigzag-PCA的识别率最差,在DCT数5时仅为68%,峰值达到90%.
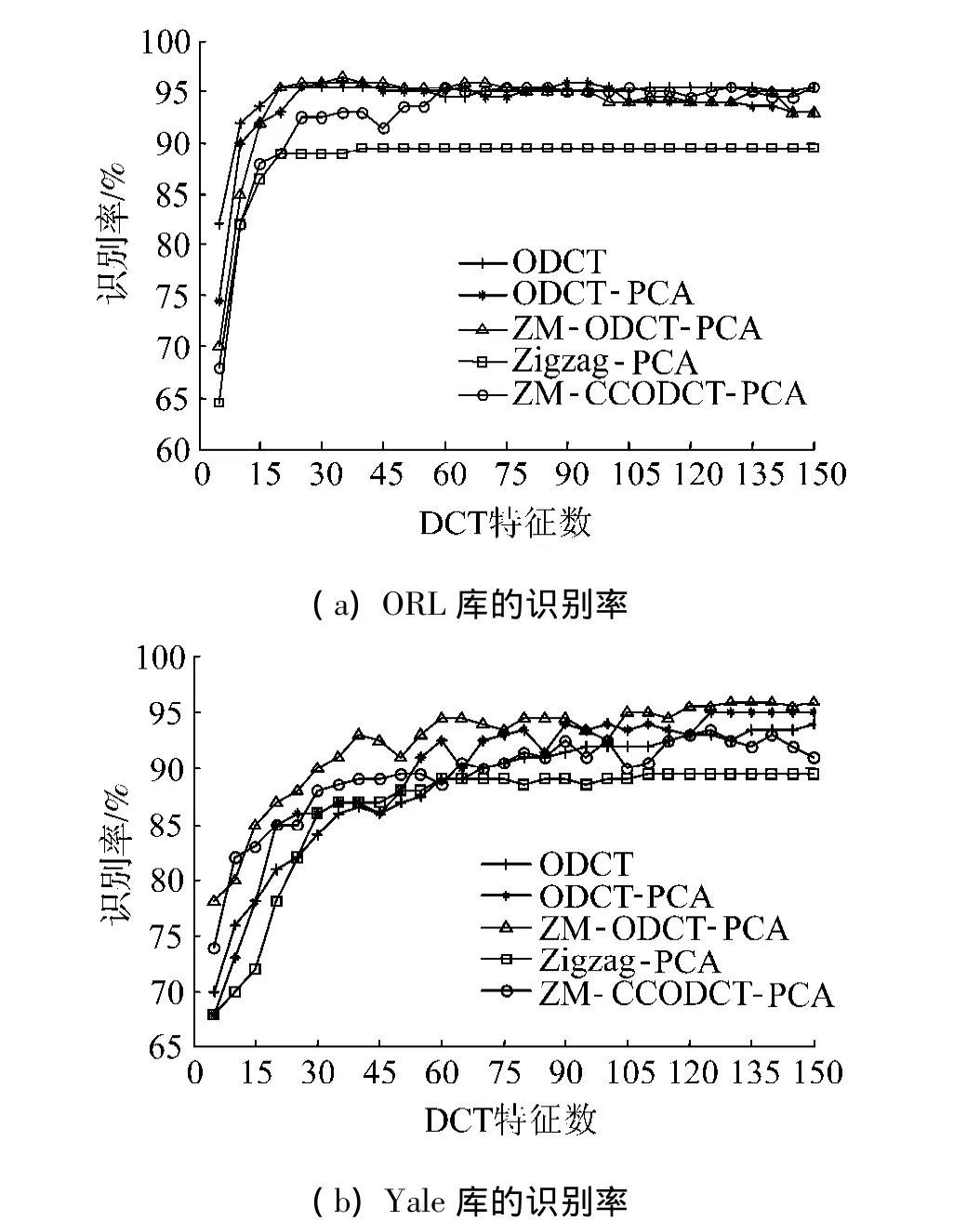
图7 ODCT与PCA组合法在ORL和Yale上的识别率Fig.7 Recognition rate of ODCT and PCA combination methods on ORL and Yale
4.2.3 系数选择法与LDA组合
传统的LDA是监督学习,需要有所有训练样本的类别标记信息.对LDA组合法在人脸数据库上进行了测试.ODCT-LDA先应用ODCT系数选择,然后进行LDA投影;ZM-ODCT-LDA先应用ZM预掩模,接着利用ODCT系数选择,然后LDA投影;ZMCCODCT-LDA先应用 ZM 预掩模,接着应用CCODCT,然后进行LDA投影;Zigzag-LDA先应用Zigzag进行系数选择,然后进行LDA投影.
图8为ODCT与LDA组合法在ORL与Yale人脸数据库上的识别率.如图8(a)所示,ODCT在DCT数为5时,获得82%的识别率高于其他4种LDA法,当DCT数为20时,识别率达到95%,并随着DCT数的增加,识别率稳定在95%左右.ODCTLDA、ZM-ODCT-LDA以及Zigzag-LDA的初始识别率在70%左右,随着DCT数增加它们的识别率最高达到99%左右,当DCT数高100时,识别率开始下降,在DCT数30~105范围内,它们的识别率最高.ZM-CCODCT的初始阶段识别率为72%,当DCT数为50时,识别率达到95%,并随着DCT数增加,其识别率与ODCT接近在95%左右.由图8(b)可以看到ZM-CCODCT-LDA在开始阶段获得了较高的识别率,而ODCT随着DCT数增加,其识别率要优于其他方法;Zigzag-LDA的识别率最差,其最高达到85%左右;ZM-ODCT-LDA与ODCT-LDA的识别率最高达到88%左右.

图8 ODCT与LDA组合法在ORL和Yale上的识别率Fig.8 Recognition rate of ODCT and LDA combination methods on ORL and Yale
4.3 实验结果评价

表1 不同方法在ORL数据库上的识别率Table 1 Recognition rate of different methods on ORL%
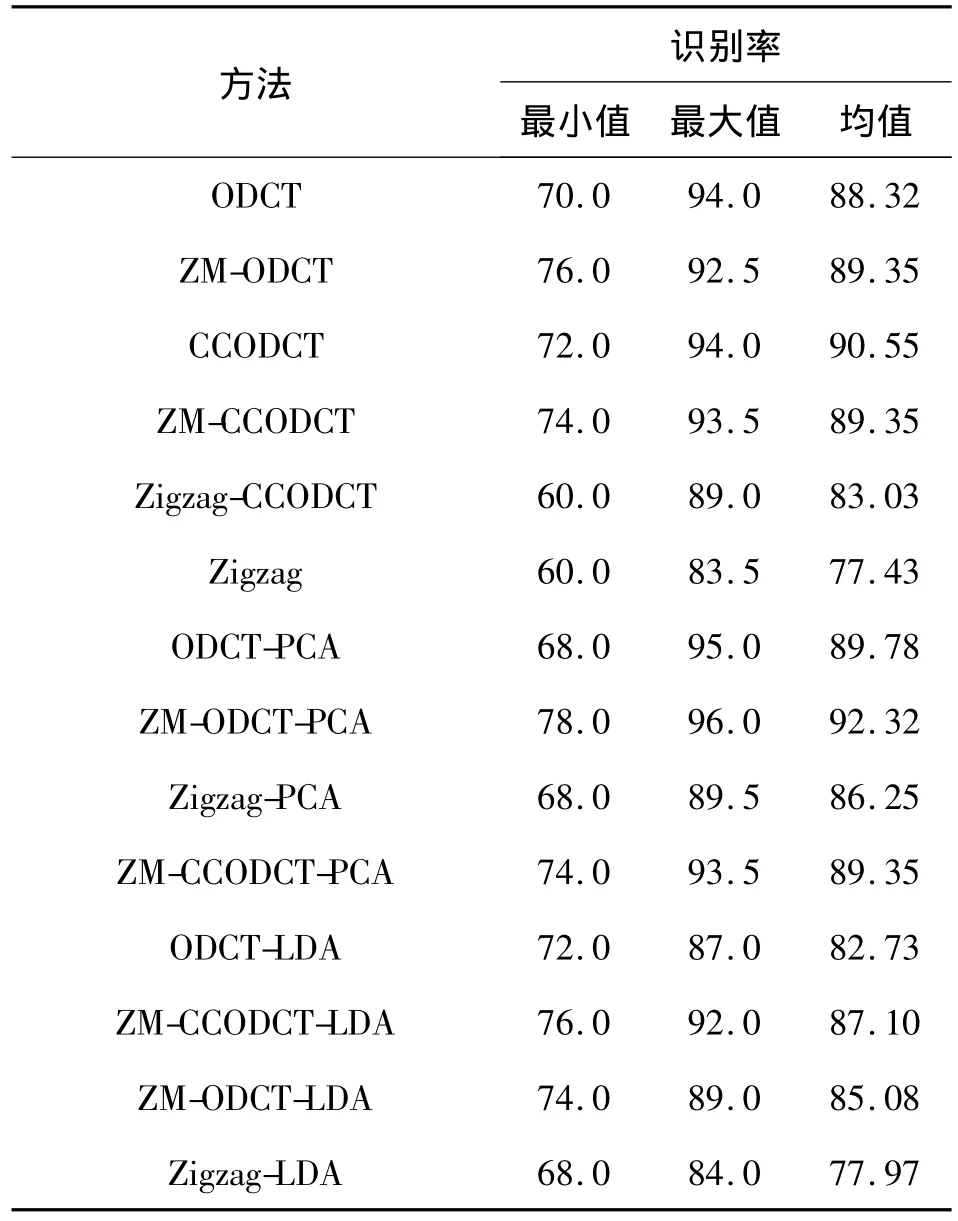
表2 不同方法在Yale数据库上的识别率Table 2 Recognition rate of different methods on Yale%
表1和表2为不同方法在ORL以及Yale数据库上的识别率比较.可以看到Zigzag与Zigzag-PCA作为无监督学习方法,它们的识别率最低;ODCT、ZM-ODCT、ODCT-LDA、ZM-ODCT-LDA以及Zigzag-LDA为监督学习方法,它们的识别率最高; CCODCT、 ZM-CCODCT、 Zigzag-CCODCT、 ZMCCODCT-PCA以及ZM-CCODCT-LDA为半监督学习方法.在算法的执行时间上,虽然半监督学习方法的执行时间稍高于监督学习方法,但它们用较小的代价,获得了与监督学习方法近似的识别率.
5 结论
本文提出了一种CCODCT系数选择法.其优点在于:
1)利用少量的标记信息作为约束集,减少了人工标记样本的工作量.
2)对DCT阵进行预掩模,达到降低计算代价的目的.
3)通过计算判别系数,选择少量的最优DCT系数,进一步降低数据维数;由于无需计算特征值问题,有效地解决了小样本问题.
4)ODCT是数据依赖的,其性能优于传统系数选择法,能根据数据库的不同,选择不同的掩模.
5)将此系数选择法与PCA和LDA进行组合,可用于解决任何特征提取问题.
由于CCODCT需要聚类,因而标记信息的选取、时间复杂度以及对不同数据库的鲁棒性问题都影响着算法的性能.今后的工作是降低算法的时间复杂度,并在有光照、表情以及姿态变化的大型人脸数据库上对其进行评估,以使算法具有更好的鲁棒性.
[1]KIRBY M,SIROVICH L.Application of the Karhunen-Loeve procedure for the characterization of human faces[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1990,12(1):103-108.
[2]牛星,席志红,金子正秀.基于改进AAM的人脸特征点提取[J].应用科技,2011,38(4):35-38.
NIU Xing,XI Zhihong,MASAHIDE Kaneko.Face feature points extraction based on refined AAM[J].Applied Science and Technology,2011,38(4):35-38.
[3]TURK M,PENTLAND A.Eigenfaces for recognition[J].International Journal of Cognitive Neuroscience,1991,3 (1):71-86.
[4]苏景龙,林天威,王科俊,等.视频流下的人脸检测与跟踪[J].应用科技,2011,38(3):5-11.
SU Jinglong,LIN Tianwei,WANG Keijun,et al.Face detection and tracking in video[J].Applied Science and Technology,2011,38(3):5-11.
[5]ZHUANG X S,DAI D Q.Improved discriminant analysis for high-dimensional data and its application to face recognition[J].Pattern Recognition,2007,40(5):1570-1578.
[6]GAO Q X,ZHANG L,ZHANG D.Face recognition using FLDA with single training image per-person[J].Applied Mathematics and Computation,2008,205(12):726-734.
[7]ZHAO H T,YUEN P C.Incremental linear discriminant analysis for face recognition[J].IEEE Trans Syst Man Cybern B,2008,38(1):210-211.
[8]赵颖.基于改进的核判别分析的人脸识别算法研究[J].哈尔滨理工大学学报,2010,15(3):19-22.
ZHAO Ying.Research on the improved kernel discriminant analysis based on face recognition algorithm[J].Journal of Harbin University of Science and Technology,2010,15 (3):19-22.
[9]BASU S.Semi-supervised clustering:probabilistic models,algorithms and experiments[D].Austin:The University of Texas,2005:32-33.
[10]ZHU X J.Semi-supervised learning literature survey[R].Madison:University of Wisconsin-Madison,2005:28-31.
[11]ZHANG S W,LEI Y K,WU Y H.Semi-supervised locally discriminant projection for classification and recognition[J].Knowledge-Based Systems,2011,24(2):341-346.
[12]CAI D,HE X F,HAN J W.Semi-supervised discriminant analysis[C]//IEEE International Conference on Computer Vision.Rio de Janeiro,Brazil,2007:205-211.
[13]DABBAGHCHIAN S,GHAEMMAGHAMI M,AGHAGOLZADEH A.Feature extraction using discrete cosine transform and discrimination power analysis with a face recognition technology[J].Pattern Recognition,2010,43:1431-1440.
[14]CHEN W,ER M J,WU S.PCA and LDA in DCT domain[J].Pattern Recognition Letters,2005,26:2474-2482.
[15]JIANG J,FENG G.Robustness analysis on facial image description in DCT domain[J].Electronics Letters,2007,43(24):356-357.
[16]CHOI J,CHUNG Y S,KIM K H.Face recognition using energy probability in DCT domain[C]//IEEE International Conference on Multimedia and Expo.Toronto,2006: 1549-1552.
