岛式FPGA芯片布局布线改进的实现*
2012-03-15李明李艳陈亮于芳刘忠立
李明 李艳 陈亮 于芳 刘忠立
(中国科学院微电子研究所,北京100029)
自1984年Xilinx公司推出第一款商用现场可编程门阵列(FPGA)产品以来,FPGA芯片便以其灵活性、投入低、周期短及风险小等特性逐步占领中低端电路市场.随着半导体工艺的发展以及RAM/ DSP/MCU等硬核资源的嵌入,FPGA芯片的规模越来越大,功能越来越强.但与专用集成电路(ASIC)相比,FPGA在速度、功耗、面积等方面尚有不小的差距[1].FPGA芯片的性能除了与硬件设计有关外,与布局布线工具的质量亦是密不可分的.传统的布局器主要有3类:基于模拟退火算法的布局器[2-4]、最小割布局器[5]和解析布局器[6].随着软件技术的发展,又出现了基于遗传算法的布局器[7]、基于蚁群算法的布局器[8],甚至一些基于混合算法的布局器[9],其中基于模拟退火算法的布局器的运行结果最佳,但运行时间较长.布线器则大多为运行Dijkstra算法的迷宫布线器[10].绝大多数的布局布线工具将布局和布线分为两个阶段,它们之间的结合非常松散,致使布局布线结果不能达到最佳.如果能将布局和布线有效地结合起来,可以极大地提高FPGA性能.例如,布局兼布线器[11]将逻辑模块与布线资源作为一个整体考虑,与Xilinx XACT 5.0布局布线器相比,延迟降低了8%~15%,不过需要数倍的运行时间.
为了能够在不显著增加运行时间的条件下提高布局布线质量,文中针对一款自主研发并已经完成流片的岛式FPGA芯片VS1000,开发了一种基于VPR[12]的改进的布局布线工具IVPR,并在Windows VC2008平台上实现了该工具.
1 VS1000 FPGA的结构
如图1所示,VS1000是一款典型的岛式FPGA,芯片架构包括24×24的逻辑片阵列、208个可编程输入输出模块(IOB)、2个全局信号模块(GB).逻辑片作为FPGA的基本组成单元,包括1个逻辑模块(LB)、1个X方向的连接模块(CBX)、1个Y方向的连接模块(CBY)和一个开关模块(SB).其中,每个逻辑模块包括2个逻辑单元.输入输出模块提供芯片管脚和内部信号的连接通道.全局信号模块给每个逻辑单元块提供时钟信号.

图1 VS1000 FPGA结构简图Fig.1 VS1000 FPGA architecture
2 改进的布局延时预测方法
在基于模拟退火算法的布局过程中,每个温度下都会有大量的逻辑模块交换或移动,每次逻辑模块的交换或移动是否被接受,都是由成本函数差值来决定的.若成本函数差值为负,则此次交换或移动被接受;若成本函数差值为正,则此次交换或移动有一定几率被接受.成本函数差值为

式中,wt为时序因子,BB_Cost为边界框值,ΔBB_ Cost为模块移动前后的边界框差值,timingCost为与延迟相关的时序值,ΔtimingCost为模块移动前后的延迟差值.在布局阶段,由于无法确定每条线网所使用的互连线和引脚,故无法得出准确的布局延时值,从而造成了布局和布线连接非常松散的后果.
假设逻辑模块1与2有连接关系,将逻辑模块1放置于CLB0(如图2(a)所示),对基于VPR算法的布局器来说,CLB1和CLB2与CLB0位置的XY坐标差值都是1,因此逻辑模块2放置于CLB1或CLB2的位置是没有区别的,但这需要FPGA结构满足以下两个条件:(1)逻辑单元的源端和漏端都有机会连接到逻辑模块4个方向上的引脚;(2)逻辑单元的源端和漏端有充裕的布线资源可以连接到逻辑模块4个方向上的引脚.
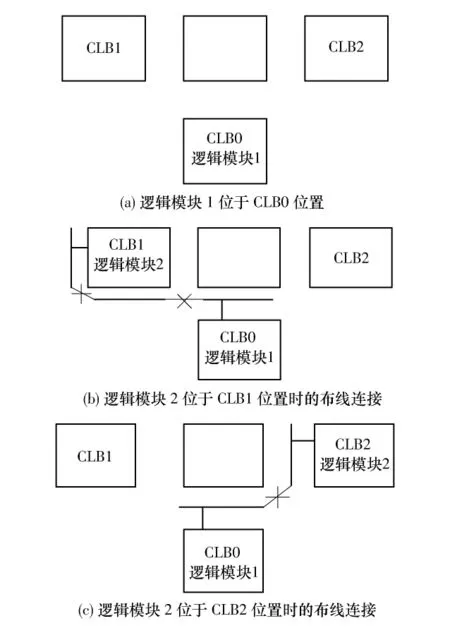
图2 逻辑模块在不同方向上的引脚对布局的影响Fig.2 Effects of pins at different sides of logic block on placement
由于芯片面积的限制,大多数岛式FPGA芯片不能满足上述两个条件.在这些限制条件下,如果逻辑模块1的输出引脚是在CLB0的上方,而逻辑模块2的输入引脚位在 CLB1或 CLB2左侧,如图2(b)、2(c)所示,很明显,当将逻辑模块2放置于CLB1时,会占用3段互连线和2个开关,而放置于CLB2时,只占用了2段互连线和1个开关.因此,在布局布线中逻辑模块引脚方向对布局结果会有显著的影响.
针对VPR未考虑逻辑模块引脚方向的缺点,文中在布局过程中加入了改进的布局延时预测,以使布局阶段能得到更为准确的延时预测值,并且在计算时序值时,根据源、漏端可能使用的引脚方向采用不同的布局延时值.
要得到更为准确的延时预测值,不仅要考虑XY坐标的差值,还需要考虑逻辑模块引脚的方向.具体实现方法如下:在计算延时预测值时,先建立时序图与布线资源图,再建立逻辑模块1和2,用一条线网连接;将逻辑模块1放置在CLB坐标为(1,1)的位置,逻辑模块2遍历其它所有CLB位置,通过布线器计算线网延时,此延时作为布局时的延时预测.伪代码如下:

在布局阶段完成一次逻辑模块交换或移动后计算ΔtimingCost的伪代码如下:

在计算延时预测值时,因为有一个逻辑模块固定在CLB(1,1)位置,并以该模块为线网的源端,所以坐标差值全部为正值,但在实际布局过程中,坐标差值可能为负.为此,文中进行如下处理:如图3所示,当源端在CLB0、漏端在CLB3时,X坐标差值为负,引脚处于CLB3的左方,此时延时为lb_to_lb[-1][1][top][left].根据对称关系,CLB3的左方引脚对应于CLB1的右方引脚,因此实际延时为lb_to_lb[1][1][top][right].

图3 坐标差值为负时的延时预测示意图Fig.3 Schematic diagram of timing estimation when coordinate difference is negative
3 针对高扇出电路的布局布线改进方法
在FPGA的应用中,高扇出是指在打包之后的网表信息中,一个源端连接多个(通常超过10个)漏端的情况.高扇出要占用大量的布线资源,给布线过程带来额外的压力.在运行大量的例子后发现,除个别小电路外,绝大多数电路的关键路径中都包含高扇出的端点,也就是说高扇出对延时会有很大的影响.VPR对高扇出没有做出特殊处理,文中针对高扇出的特点,提出一种线网终端对齐并结合长线连接的改进方法.
3.1 线网终端对齐法
线网终端对齐是指线网的源端和漏端对应的逻辑模块处于水平或垂直方向,而宽松对齐是指在对齐方向上加减一行(或列),文中在布局过程中加入了线网终端对齐[13]和线网终端宽松对齐.如图4所示,线网A为线网终端水平对齐,线网C为线网终端垂直对齐,线网B为线网终端水平宽松对齐.为了更有效地利用线网终端对齐和使用长线连接法,文中的宽松对齐特指水平对齐方向上一行或垂直对齐方向右一列的对齐.

图4 线网终端对齐示意图Fig.4 Schematic diagram of net terminal alignment
在布局算法中,文中在成本函数(1)中加入对齐值,结果为

式中:wa为对齐因子,其值是经过运行多个例子后估算出来的;Alignment_Cost(vi)=∑δ(e),δ(e)为逻辑模块i和j之间的对齐值,

3.2 长线连接法
VPR的布线使用了路径搜索算法[14],为了加快布线速度,VPR还使用了波前扩展方法[12]:当到达一条线网的漏端时,布线器将所有连接到漏端的布线资源以0成本加入到波前优先队列,且不清空已有的波前,然后继续正常的扩展,由于波前的路径成本为0,所以布线器会围绕它来扩展,这样能够更快地找到下一个漏端,直到当前线网的所有漏端均找到为止.因为波前扩展方法采用逐步扩展的方式,所以当某条线网的多个终端处于对齐状态时,布线算法仍可能采用短线逐个连接,而不是用长线连接.
针对这种情况,文中动态评估长线连接的成本.如果一条线网是高扇出的,那么它要连接的下一个漏端位于线网终端对齐方向,此时先计算此方向上的漏端数目(该值越大,长线连接的成本越小且随着边界框值的增大而减小),当对齐方向上的漏端数目大于定值(一般大于等于4)时,长线连接的成本便小于短线连接的成本.此时,布线器在连接选择布线资源时便可以选择长线来连接源端和漏端,然后继续进行波前扩展以连接其它漏端.
4 实验结果与分析
在2.93GHz Intel(R)Core(TM)处理器、500GB硬盘、Windows XP操作系统的实验室环境下,根据VS1000芯片24×24的逻辑阵列规模,从IWLS和MCNC标准测试电路中选取了11个不同规模及类型的基准电路(见表1)进行测试,比较了经典VPR[12]、使用改进延时预测方法的VPR(IVPR1)、使用线网终端对齐法的VPR(IVPR2)、使用改进延时预测与线网终端对齐法的VPR(IVPR3)的布局布线质量,结果如表2所示,其中延时改进量和通道宽度改进量均是相对于经典VPR[12]的改进百分比.测试过程中,FPGA CAD流程中的综合、映射、布局布线都是针对VS1000 FPGA芯片架构.从表2可知:

表1 测试基准电路信息Table 1 Information of test benchmark circuits
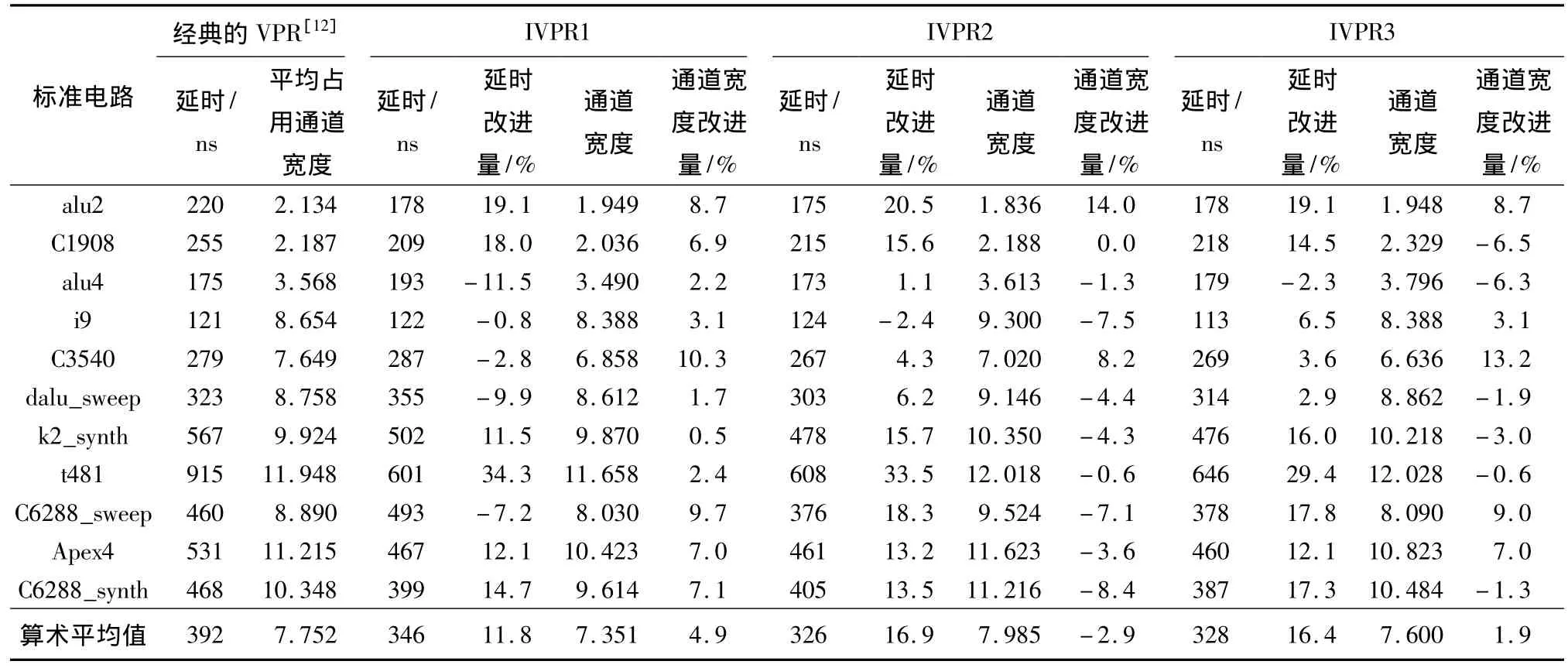
表2 IVPR1、IVPR2、IVPR3与经典的VPR[12]的布局布线质量比较Table 2 Comparison of placement and routing qualities among IVPR1,IVPR2,IVPR3 and typical VPR
1)在采用改进的延时预测方法后,IVPR1的平均电路延时降低了11.8%,布线资源利用率提高了4.9%,平均运行时间增加了近5%.改进的延时预测方法对布线资源利用率的改善效果良好,这是因为在布局阶段考虑布线可能使用的引脚方向后,减少了互连线的转弯,提高了布线资源利用率.在电路规模较小时,由于布线资源十分充裕,改进的延时预测方法对延时的改善效果较差,但随着电路规模的增大,改善效果也逐渐变得更好.
2)在加入线网终端对齐后,IVPR2的平均电路延时降低了16.9%,但布线资源利用率降低了2.9%,平均运行时间略有下降.线网终端对齐对电路延时的改善效果显著的主要原因有:(1)高扇出的特殊性,绝大多数电路在经过布局布线阶段后的关键路径中都包含高扇出的端点,而线网终端对齐及长线连接能够有效地减小高扇出线网的延时,因此能够有效地改善电路延时;(2)布局阶段的关键路径和次关键路径在布线阶段会优先使用最快的互连线连接,因此布线后的关键路径在布局阶段是次关键路径或非关键路径,在布局阶段,线网终端对齐能够在不影响关键路径的情况下有效地改善次关键路径和非关键路径的延时.
3)使用改进的延时预测和线网终端对齐后,IVPR3的平均电路延时降低了16.4%,布线资源利用率提高了1.9%,平均运行时间增加了近5%.
5 结语
为了克服布局与布线之间连接松散的缺点,文中针对岛式FPGA芯片VS1000的架构,对经典的VPR进行了如下改进:在布局过程采用更为准确的延时预测,同时对逻辑模块引脚的使用做了预测;对于高扇出的线网采用线网终端对齐法,并在布线时优先采用长线连接.实验结果表明,这两种改进明显提高了布线资源利用率,降低了电路延时.文中提出的这些改进方法对岛式FPGA芯片的布局布线具有一定的通用性.
[1] Kuon Ian,Rose Jonathan.Measuring the gap between FPGAs and ASICs[J].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2007,26(2): 203-215.
[2] LeeSang-Joon,RaahemifarKaamran.FPGA placement optimization methodology survey[C]∥Proceedings of Canadian Conference on Electrical and Computer Engineering.Ottawa:IEEE,2008:1981-1986.
[3] Vorwerk Kristofer,Kennings Andrew,Greene Jonathan W.Improving simulated annealing-based FPGA placement with directed moves[J].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2009,28(2):179-192.
[4] 刘战,须自明,王国章.一种用于FPGA布局的模拟退火算法[J].微计算机信息,2007,24(5):184-186.Liu Zhan,Xu Zi-ming,Wang Guo-zhang.An efficient simulate annealing algorithm for the placement of FPGA[J].Control and Automation,2007,24(5):184-186.
[5] Huang D J H,Kahng A B.Partitioning-based standard-cell global placement with an exact objective[C]∥Proceedings of International Symposium on Physical and Design.New York:ACM,1997:18-25.
[6] Sigl G,Doll K,Johannes F.Analytical placement:a linear or a quafratic objective function[C]∥Proceedings of the 28th ACM/IEEE Design Automation Conference.San Francisco:IEEE,1991:427-432.
[7] Yang M,Almaini A E A,Wang L,et al.FPGA placement using genetic algorithm with simulated annealing[C]∥Proceedings of the 6th International Conference on ASIC.Shanghai:IEEE,2005:808-811.
[8] 赵军,贾智平.蚁群与粒子群混合的FPGA布局算法[J].计算机工程与应用,2009,45(18):70-72.Zhao Jun,Jia Zhi-ping.Mixed ant colony and particle swarm FPGA placement algorithm[J].Computer Engineering and Application,2009,45(18):70-72.
[9] 隋文涛,董社勤,边计年.岛式FPGA线长驱动快速布局算法[J].计算机辅助设计与图形学学报,2009,21 (9):1275-1282.Sui Wen-tao,Dong She-qin,Bian Ji-nian.Wirelengthdriven fast placement algorithm for island style FPGAs[J].Journal of Computer-Aided Design and Computer Graphics,2009,21(9):1275-1282.
[10] Lee C Y.An algorithm for path connections and its applications[J].IRE Transactions on Electronic Computers,1961,10(3):346-365.
[11] Nag Sudip K,Rutenbar Rob A.Performance-driven simultaneous placement and routing for FPGA’s[J].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,1998,17(6):499-518.
[12] Betz V,Rose J.VPR:a new packing,placement and routing tool for FPGA research[C]∥Proceedings of the 7th International Workshop on Field Programmable Logic and Applications.London:Springer,1997:213-222.
[13] Maidee Pongstorn,Ababei Cristinel,Bazargan Kia.Timing-driven partitioning-based placement for island style FPGAs[J].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2005,24(3): 395-406.
[14] McMurchie L,Ebeling C.PathFinder:a negotiation-based performance-driven router for FPGAs[C]∥Proceeding of the ACM/SIGDA Third International Symposium on Field-Programmable Gate Arrays.New York:ACM,1995: 111-117.
