校园网园区搜索引擎的设计与实现
2011-12-09刘劲松张彬柴文磊魏建行刘振鹏
刘劲松,张彬,柴文磊,魏建行,刘振鹏
(河北大学网络中心,河北 保定 071002)
校园网园区搜索引擎的设计与实现
刘劲松,张彬,柴文磊,魏建行,刘振鹏
(河北大学网络中心,河北 保定 071002)
Google、百度等通用搜索引擎不能适用于所有的情况和需要,现有的校园网搜索引擎存在查准率、查全率不高,升级维护困难等局限性.本着整合校园网资源的目的,为方便广大师生对校园网信息的获取和使用,设计并实现了校园网园区搜索引擎中文检索系统.该系统由搜索引擎机器人、信息分析器和Web服务器查询软件3部分组成,能够对园区网上的中文网页进行采集、索引.系统实现了在河北大学校园网内的信息检索,具有检索结果查准率高、检索速度快等优点.
校园网;搜索引擎;信息检索;倒排
从搜索技术本身及搜索范围与深度来看,Google在国内外对搜索引擎研究是比较著名的.Google在低层次的智能搜索方面已经开始研究很多年了,实际的成果就是翻译方面,但更为重要的是 Google建立起来的海量搜索历史记录.如果把这些海量搜索历史记录当作词典,那么与搜索技术的结合发展成为低层次的智能搜索,应用范围将大大扩展.
国内比较著名的比如百度,更专注对中文的处理,并于2009年提出“框计算”理论.“框计算”理念的实现,能让搜索引擎主动识别用户信息需求,主动定位网络有用的资源和服务,从而更加精准便捷.而现阶段搜索引擎基本采用的都是“关键词查询+选择性浏览”的用户交互方式[1-2],这种交互方式无法主动识别用户需求,只能由用户选择自己所需的结果.为了满足用户更深层次的需求,国内的搜索引擎也在不断完善自己.如何将人类的知识和智能加入到检索中,如何使搜索引擎的质量产生一个质的飞跃,也是国内搜索引擎努力的方向.目前的框计算理念,应该是基于搜索引擎的下一代互联网系统结构框架和设计理念.
1 园区搜索引擎的设计
1.1 功能模块
搜索引擎的信息采集功能模块:完成校园网内网页的自动采集和现有网页的自动更新,并提供增量式处理策略.一般地,每个搜索引擎都派出被称为“搜索引擎机器人”[3]的网页搜索软件在各网址中爬行,访问网络中公开区域的每一个站点并记录其网址,或者将网页抓取到本地,创建出一个详尽的网络目录.
信息内容功能分析模块:对信息采集系统所采集的信息所有文本内容以及经过算法处理后的摘要等有用信息存入数据库以便于检索,同时数据库的内容必须经常更新、重建,以保持与信息世界的同步发展.和英文的Internet搜索索引相比,中文的信息分析具有自身的特点对中文搜索引擎建立索引构成了一定的障碍.
信息检索/发布/推送模块:提供多种功能的面向用户的检索、发布、推送服务.这一部分功能模块的性能主要表现在准确率、召回率和响应时间上,也是评价搜索引擎的主要性能标准.
1.2 园区搜索引擎数据结构
数据结构设计采用4个表(表1-4):Cache,URLindex,Dict和 Page,分别存储抓取回来的页面的全部信息、需要抓取的页面地址、字典和分开后的htm l标记和页面文字.

表1 存储抓取回来的页面的全部信息Tab.1 Grab the back pages stored all information

表2 存储需要抓取的页面地址Tab.2 To grab the pages stored address

表3 Dict 功能:存储字典Tab.3 Stored in the dictionary

表4 存储分开后的htm l标记和页面文字Tab.4 Htm l tags separated stored and page text
1.3 信息内容分析器
1.3.1 倒排文档的设计
通过对源信息文件进行文本分析生成倒排文件的方式建立检索项相关信息.倒排文档的建立应当有助于进行快速、有效地进行检索,同时应该考虑到在数据库中的索引数据表的规模,应当在尽可能小的空间里存储大容量的信息[4].
字检索是在建立索引时以字为检索项,但用户在进行查询时,均是输入关键词,因此在查询时,就需要把词拆分为单个汉字,从数据库中检索到相关记录后,再进行相反的配词运算,才能检索到用户需要的有效记录.在这种条件下,笔者决定在建立倒排文档时记录汉字在文件中的绝对位置信息,即该汉字距离文件首的字节数,其倒排文档格式如表5所示.

表5 倒排文档格式Tab.5 Inverted file format
在返回查询结果时,相关信息源的信息,如URL、标题、摘要等等,也将返回给用户,因此,还需要建立一份页面信息的倒排文档以记录所需要的主页信息,其结构设计如表6所示.
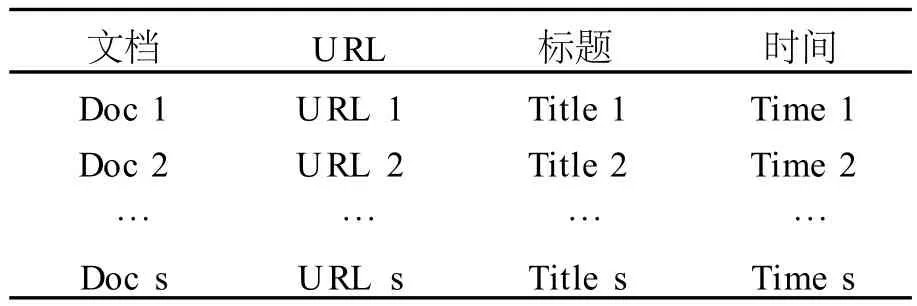
表6 页面信息的倒排文档Tab.6 Inverted file information page
其中Doc i就是字倒排文档中所记录的文章标识符,对于不同的URL其数值取值也是唯一的.Title是htm l文档中的标题信息,对于规范的主页文档都是能够具有该项关键信息的.Time元素是在更新数据库时是否对已存在的记录进行更新操作的判断标准,如果获取的主页信息比数据库中的信息新,则对数据库中相应的记录进行操作,否则仍保留原来的数据.
1.3.2 倒排文档生成算法
由于网络机器人在下载主页的时候已经对源文件进行了相关的处理,所以页面文档信息的倒排文档生成算法只需要对经过预处理[5-8],按照约定格式存储的文档进行必要操作即可.这种面向对象的编程方法极大地增强了程序的健壮性,同时使功能扩充也非常容易.
字信息倒排文档生成算法处理就较为复杂.汉字编码是双字节编码,即每1个汉字占用2个字节的存储单位,并且每1个字节按照8位二进制编码,其最高位必定为1,同时在汉字编码表中第1个汉字“啊”的16位编码是“B0A 1”,此前的符号都是汉字标点符号,其后的编码才代表了汉字.在程序中设置了2个指向字符型的指针,始终指向前后相邻的2个字节.如果2个指针所指向的对象中,有任何1个字节的编码最高位是0,则说明这2个字节既不是汉字也不是中文符号,此时前面的指针向后移动2位,重新进行测定.如果2个字节最高位编码都为1,再进一步与“B0A 1”比较,判断是否为汉字,如果是则记录其位置信息,并将2个指针同时后移2位,如果不是,则说明是中文标点符号,只需要对指针进行移动操作就可以了.
在记录汉字位置信息的过程中,每1条记录代表了1个汉字,为了适合工程的需要,从CObject类中派生了1个新类CCh Index专门记录汉字的信息,用该类生成的1个对象就记录了1个汉字的位置信息.该类中包括1个双字节长度的CString数据成员ChWord,另一个数据成员是一个CPoint数组WordPosA rray,记录了汉字的所有位置信息,并且在需要的时候随时可以改变长度.
2 查询检索算法
由于提供的搜索服务能够进行布尔逻辑查询,所以首先应当获取用户输入的所有字符,根据不同的逻辑方式的分隔符(如逻辑“与”操作是以空格为分隔符)把用户的输入子串分成多个子串[9],对每一个子串进行查询,然后对各个子串的查询结果进行逻辑处理,并将最终的结果生成一个htm l文件,返回给客户端;否则,对各种异常进行处理,生成错误信息htm l文件,返回给客户端.最后,退出检索程序,等待下一次查询,如图1所示.

图1 查询程序总体流程Fig.1 Query overall process
对于基于字所建立的索引进行查询,最重要的处理过程就是配词算法[5-6],如图2.把每一个查询关键词子串分解为单个的汉字,从数据库表格中查到相关的记录后,再把字还原成词,找到符合用户要求的记录,返回其中对用户有用或感兴趣的元素.
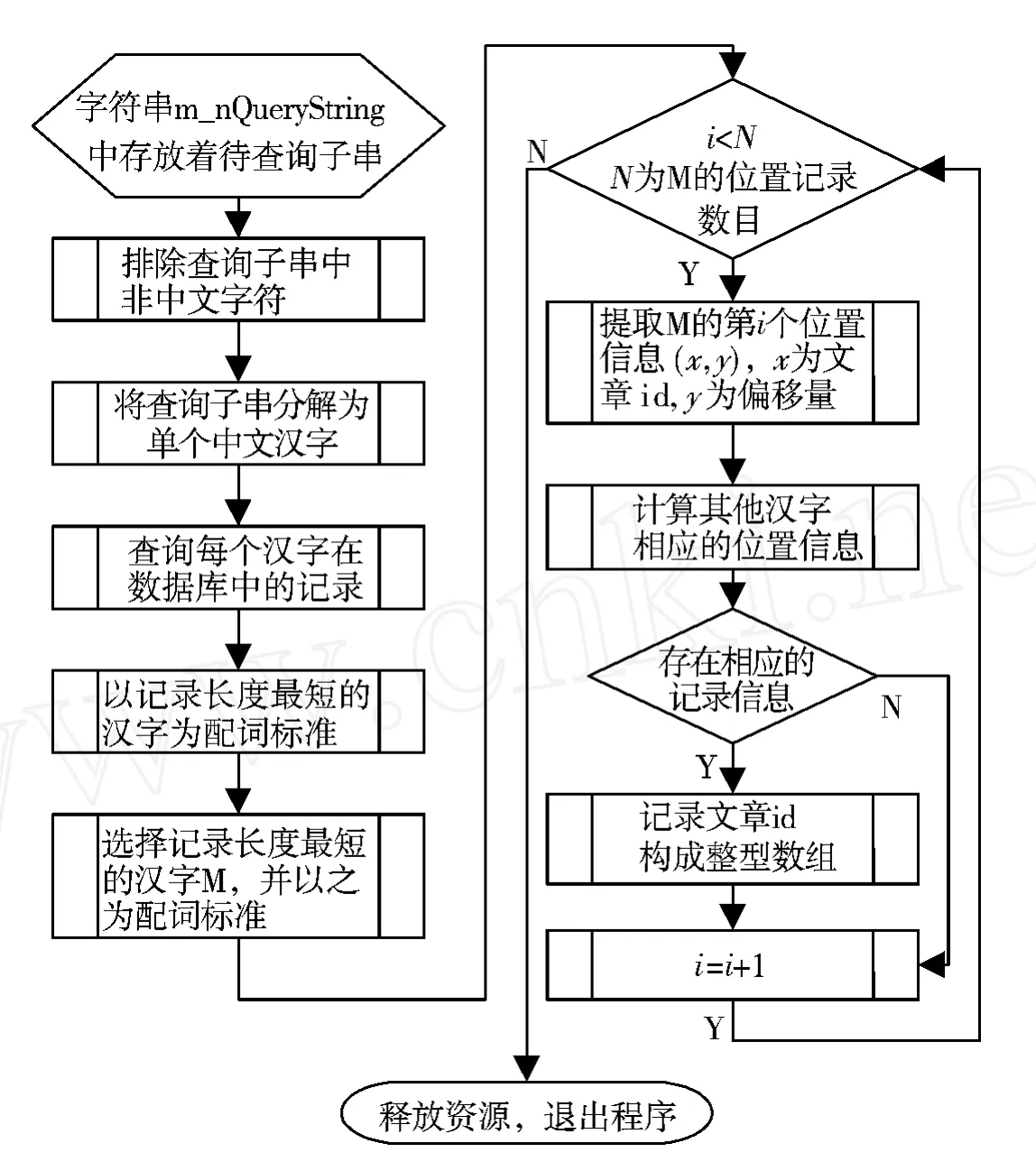
图2 子串检索配词算法Fig.2 Clauses retrieval algorithm with words
3 系统实现及性能测试
3.1 系统实现
本系统采用多线程及Socket编程技术,基于上述方案,成功地实现了对中文网页的搜索功能,建立了一个小规模的中文搜索引擎网站,实现了在河北大学校园网的园区搜索.例如用户输入“河北大学”,检索程序将该词分解为4个汉字.经过查询数据库中Word Info表,发现“北”字的记录最少,便以它为配词基本点.提取“北”的第1个位置信息,如(1,54),表示“北”字在第1篇文章第54个字节.接着,如果在第1篇文章中有“河北大学”记录,那么,“河”的记录中应当含有(1,52)的位置信息,“大”的记录中应有(1,56),“学”的记录中应含有(1,58)的位置信息.分别对其他3个字的记录进行搜索,发现全部能够匹配,则说明在第1篇文章内存在“河北大学”的关键词,所以可以查询Page Info表,把与第1篇文章相关的信息返回给用户.这样反复循环,直到把“北”字的所有位置信息均查询一遍,就完成了对“河北大学”关键词的查询.
3.2 性能测试
对于系统的运行效率,测试采用的衡量尺度是单次查询的执行时间.利用Apache JM eter,可以简单模拟对查询服务的访问[10],表7列出了不同数量的文档集合对系统处理时间的影响.

表7 查询执行时间Tab.7 Inquires the execution Time
测试结果表明在其他参数不变的情况下,系统的执行时间与文档数量成正比,对于小规模的文档集合,检索速度快.系统使用SQL Server数据库管理器和DLL作为网关程序,响应速度快,配词算法性能优越,一般查询在4 s左右均能返回查询结果,在中低压力的情况下,系统可以提供稳定的搜索服务.
评价信息检索性能的主要指标为查准率和查全率.查准率是指检索到的相关文档与检索到的全部文档的比率,查全率是指检索到的相关文档与所有满足条件的文档数目的比例.在测试中,从资料中获取有关Web文档1 200篇,采用计算机中的常用词组1 500个,建立索引特征项库,并利用不同的相似度阀值分别进行测试,得到的传统搜索引擎和本系统的查全率和查准率,如表8所示.
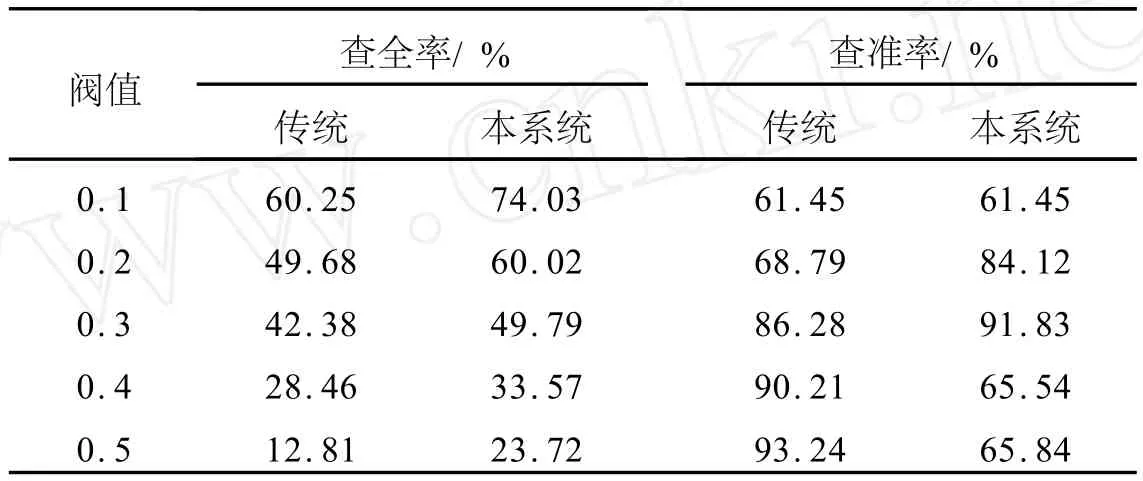
表8 传统搜索与本系统的性能比较Tab.8 Traditional search performance comparison with this system
表8的测试结果表明,检索结果查准率高.系统采用二值型布尔式检索模型,返回结果中一定含有待查询字符串,不会出现误差,这一点性能要远优于词检索模型.
4 结语
随着搜索引擎技术的不断商业化,信息检索技术已经进入了发展的黄金时期,而Internet在中国的发展也是日新月异,大量涌现的中文信息需要性能优良的中文搜索引擎.而把搜索引擎技术和自然语言处理技术结合起来,提高中文搜索引擎的检索效果不仅是Internet信息检索技术发展的趋势,同样使用了这种技术的搜索引擎也必然具有巨大的市场和广阔的发展前景.
[1]马费成,望俊成,吴克文,等.国外搜索引擎检索效能研究述评[J].中国图书馆学报,2009(4):73-80.
[2]张军华,韩全会.中文五大综合搜索引擎主要性能测评[J].情报科学,2008,26(10):1540-1542.
[3]姚全珠,彭程,宋志理,等.基于关联规则的搜索引擎方法[J].计算机工程与应用,2011,47(9):134-136.
[4]陈华,李仁发,刘钰峰,等.个性化搜索引擎推荐算法研究[J].计算机应用研究,2010(1):48-50.
[5]聂靖,李强,庞力,等.移动元搜索引擎中网页内容提取算法研究[J].现代图书情报技术,2010,26(10):54-58.
[6]AHM ET U YAR.Investigation of the accuracy of search engine hit counts[J].Journalof Information Science,2009,35(4):321-325.
[7]CHRISTOPHER N.Op timize your web site fo r search engines[J].PCWORLD,2009,27(3):527-533.
[8]薛晔伟,沈钧毅,张云.一种编辑距离算法及其在网页搜索中的应用[J].西安交通大学学报,2008,42(12):1450-1454.
[9]李红梅,丁振国,周水生,等.搜索引擎中的聚类浏览技术[J].中文信息学报,2008,22(3):56-63.
[10]刘奕群,岑荣伟,张敏,等.基于用户行为分析的搜索引擎自动性能评价[J].软件学报,2008,19(11):3023-3032.
Design and Emplement of Search Engine on the Campus Network Park
LIU Jin-song,ZHANGBin,CHAIWen-lei,WEIJian-hang,LIU Zhen-peng
(Network Center,Hebei University,Baoding 071002,China)
Google and baidu universal search engines and soon can't be app lied to meet the needs of all the situation,the existing campus network search engines exist p recision and recall are not high,it is difficult to upgrademaintenance.In line w ith the purpose of netwo rk resources integration,fo r the convenience of teachers and students of campus network info rmation acquisition and use,we design and imp lement the campus network park search engine Chinese retrieval system.This system consistsof search engine robots,info rmation analyzer and web server inquires the softw are of three parts,fo r the Chinese w eb page in park online collection and index.System realizes the campus in Hebei University in information retrieval,and the retrieval results w ith high p recision,retrieval speed,etc.
campus netwo rk;search engines;info rmation retrieval;inverted
TP 391
A
1000-1565(2011)04-0439-06
2011-01-20
国家自然科学基金专项基金资助项目(J0921020)
刘劲松(1978-),男,河北保定人,河北大学实验师,主要从事网络信息化方向研究.
E-mail:ljs@hbu.cn
为一自然数Doci,该标识符是区别不同文档的唯一依据;Posi则表明该汉字在文档i中的绝对位置.这样每一对数值构成了一个汉字的唯一坐标信息.
孟素兰)
