基于哈希表的动态向量降维方法的研究及应用
2011-10-20许云峰
王 伟,许云峰,高 凯
(河北科技大学信息科学与工程学院,河北石家庄 050018)
文档信息的特征表示方式有多种,常用的有布尔逻辑模型、向量空间模型、概率模型以及混合模型等[1]。其中向量空间模型VSM是应用较多且效果较好的方法[2]。向量空间模型表示方法的主要不足是文档特征向量具有惊人的高维次,因此在进行向量计算之前还必须对文档特征向量进行降维处理。文献[3]和文献[4]认为高维数据中通常含有许多冗余信息,其中起到实质作用的维数要远远小于原始的数据维数,所以高维向量的处理可以归结为通过相关的降维方法减少一些不太相关的维次数据,然后用低维向量的处理办法进行处理。文献[5]—文献[8]介绍了MDS,Isomap,LLE等3种高维数据的降维方法。文献[1]介绍了一种稀疏的空间向量表示方法。文献[9]提出了规则族之间相似度的构建准则。文献[10]介绍的特征脸方法大大降低了原始空间的维数。
在研究中发现,虽然文档特征向量空间的维次巨大,但具体到单个文档,绝大多数向量元素都为零,这就决定了单个文档的特征向量是一个稀疏向量。笔者在此提出并实现了一种基于哈希表的动态向量降维方法,用哈希表作为文档特征向量的存储数据结构,只将权重不为零的特征向量词条加入哈希表。实验证明这种向量表示方式大大减少了内存占用量,有效降低文档特征向量的维次,显著提高了文档特征向量相关算法的性能。
1 基于哈希表的动态向量降维算法
该算法利用了哈希表的键值和表项唯一对应的特性,将哈希表作为默认的向量模板,向量空间中每一维次在哈希表中都唯一对应一个表项,并且各个维次排列的先后顺序由哈希表的键值大小决定。
1.1 基于向量模板的向量空间模型算法
在传统的基于向量模板的向量空间模型算法中,首先利用分词技术对每篇文档进行分词,然后再用特征选择算法,去除掉信息含量少的词项,这一步骤相当于对文档向量空间做降维处理。其次,按照特征选择算法赋予每个词项的分值或者称为词项的权重大小,对保留下来的文档特征词项降序排序,根据用户设定的最大向量空间维数n,截取已排序的文档特征词数组的前n项作为文档向量模板。在这一步,截取的向量空间维数n的大小很关键,n的取值太大则文档向量的维数就会很大;n的取值太小则会导致许多含有丰富信息量的特征词丢失,从而降低文档向量对文档的标识性能。确定了文档向量模板就同时确定了文档向量空间的维数、各维次对应的特征词项,以及各维次排列的先后顺序。接下来就是参照文档向量模板实现各文档的向量化表示。但用这种方法生成的文档向量维数都是相等而且是稀疏的向量,当文档中含有向量模板里不存在的特征词时,尽管这个特征词含有丰富的信息也会被忽略掉。人为规定向量空间的最大维数,相当于对文档向量空间又进行了一次强制的降维。
1.2 算法描述
笔者提出的基于哈希表的动态向量降维算法中,通过在哈希表中只存储权重不为零的特征词,来实现稀疏向量的动态压缩存储。算法主要思想和步骤是:1)在确定了训练文档集后,利用分词技术对每篇文档进行分词,然后再用特征选择算法去除掉信息含量少的词项,在这一步实现了对文档向量空间的第1次降维处理;2)哈希表键值和表项是唯一对应的,但是这个特性必须在特定前提条件下才能实现,可以利用哈希表这一特性,将其视为一个无限维次的向量空间模型,就文档的特征词而言,在这个空间中,每一个特征词都有一个唯一对应的维次,并且各维次的先后顺序都由特征词的哈希值的排列顺序决定;3)将每一个文档的特征词存储在一个哈希表里,每一个文档都唯一对应一个哈希表。在这一步还采用了一个策略,即在哈希表里只存储权重不为零的特征词项。对于稀疏的文档向量,当其存储为哈希表形式时,就自动过滤掉权值为零的特征词,实现了对稀疏文档向量的压缩存储,从而实现了对文档特征词向量的第2次降维。至此就完成了基于哈希表的文档向量空间模型的构建过程。在哈希算法性能良好和计算机硬件性能允许的前提下,可以认为基于哈希表的向量空间维数是无限的,无论有多少特征词都能在这个空间里找到所对应的维次,而不用再人为限定向量空间的最大维数,从而避免了将信息含量大的特征词丢失,并且这种方法也省略了构建向量模板的过程,直接由特征词生成文档向量,节省了计算机资源,提高了算法性能。值得强调的一点是,要想有效发挥基于哈希表的动态向量降维算法的作用,就必须保证特征词选择算法能够有效地选择出富含信息的特征词,并且保证特征词的数量远小于文档分词后的词项总数。图1显示了将文档向量化的过程。
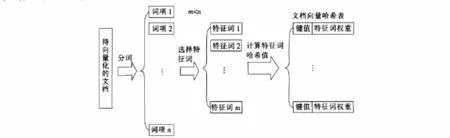
图1 文档的向量化表示过程Fig.1 Process of the document says as vector
2 算法性能实验
2.1 实验设计
在此使用相同的语料库和分类器,分别应用不同的文档向量表示方法,比较分类器对相同语料库的总处理时间和分类速率的差别,来观察2种向量表示方法的性能差异。这里采用灵玖中科软件有限公司提供的文本分类语料库作为测试语料,该语料库共包括10个类别2 816篇文档。笔者提到的文档分词和文档特征词选择任务由本课题组提供的主题词抽取模块完成,该模块集分词和主题词提取功能于一身,并且该模块的主题词提取算法是一种高性能的特征选择和降维算法,能够满足本文实验的要求。另一方面,主题词是一种性能良好的文档特征量,对文档有非常好的标引性和区分性,一般10个主题词就能很好地标引和区分不同文档了。考虑到主题词提取模块的性能,提取主题词个数越多,模块的处理速度就越慢,所以将提取的主题词的最多个数设定为30个。
笔者的基于文档向量模板的向量表示方法和基于哈希表的动态向量降维算法都在课题组提供的中心向量分类器中实现,采用了2种模块组合对比实验:1)主题词提取模块+基于文档向量模板的向量表示方法+中心向量分类器;2)主题词提取模块+基于哈希表的动态向量降维算法+中心向量分类器。
为了提高实验效率,预先提取了语料库每篇文档的主题词,并且保存在一个主题文件里。实验时只需从主题文件里读取每篇文档的主题词串然后进行分类处理就行了。通过多次实验,分别在不同的训练集规模、测试集规模和向量维数下对2种算法进行了性能测试,分别记录“总耗时”(即分类器对测试文档集内所有文档进行分类所耗费的总时间,单位为s)、“分类速率”(即分类器在1s内能够分类的文档篇数,单位为“篇/s”)、“F1评价值”(是对分类器总体分类正确率和总体查全率的综合评价,体现了分类器的综合性能)3项性能指标。需要说明的是,实验中分类器没有考虑兼类的情况,每篇测试文档只能归属唯一的类别。训练集和测试集都是按照不同的规模比例从同一个语料库中随机选择的,2个文档集中的文档没有重复,分类测试采用开放性测试。
2.2 数据分析
主要实验数据如表1所示。
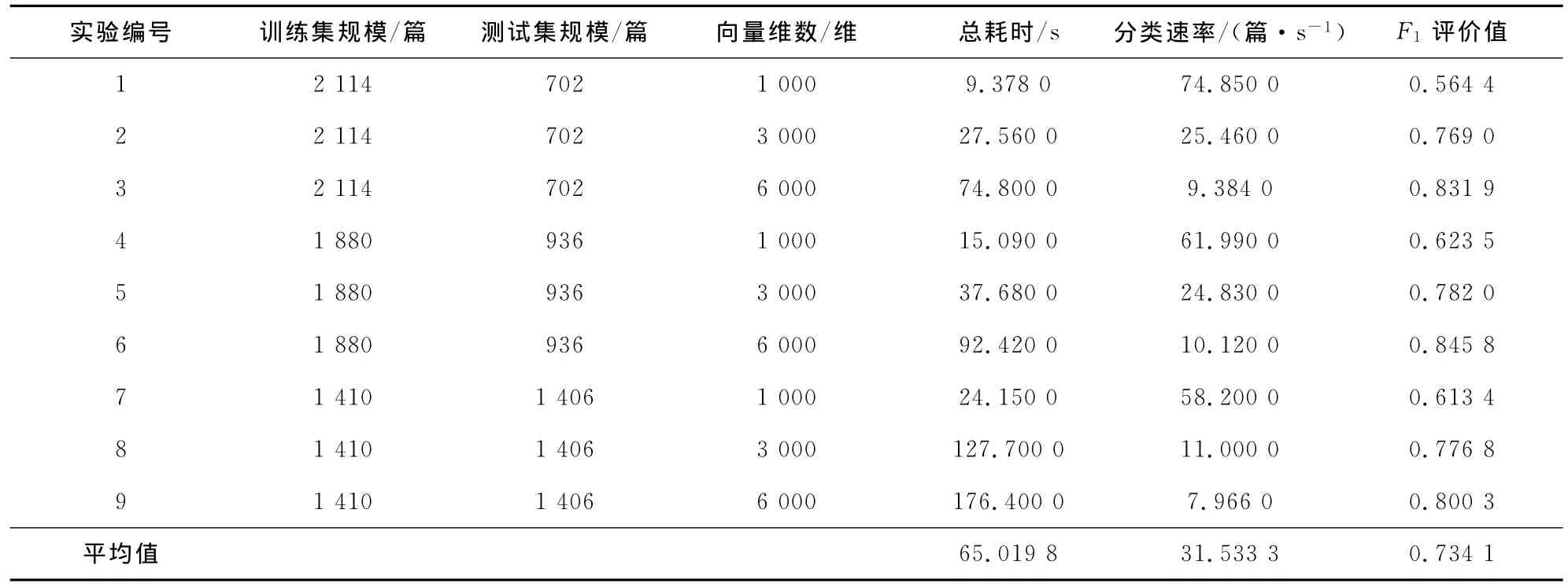
表1 采用基于文档向量模板的向量表示方法的测试结果Tab.1 Testing results of the vector representation method based on the document vector template
表1一共进行了3组实验,分别对应于3种测试集规模:702篇、936篇和1 406篇;每组实验又包括3次实验,分别对应于3种向量维数:1 000维、3 000维和6 000维。由表1中的数据可以发现,随着向量维数的增大,分类的总耗时增加,分类的速率降低,这说明随着维数的增大,文档向量所包含的数据项数增加,与向量相关的计算量也增加了。同时还发现随着维数的增大,分类器的F1值增大,这说明随着维数的增大,人为舍弃的关键词的数量减少,同时每个文档向量包含的信息量增加,进而提高了分类的准确率和查全率,提高了分类器的性能。通过3组实验数据的对照比较可以看出,随着测试集规模的增大,分类总耗时相应增加,分类速率降低,这说明测试文档集规模的增大也会增加分类器的计算量。同时也发现随着测试文档集规模的增大,分类器F1值没有显著的变化,这说明分类器的性能受文档向量维数变化的影响最大。
表2是采用基于哈希表的动态向量降维算法的测试结果。一共进行了3次实验,分别对应于3种测试集规模,由于是采用动态降维算法,向量维数随着不同的文档而随时变化,不便于采集比较,所以在这组实验里不考虑向量维数。通过分析表2的实验数据,可知随着测试集规模的增大,分类总耗时有小幅度的增加,分类速率有小幅度的降低,这说明随着测试集规模的增大,与文档向量相关的计算量有小幅度的增加。同时也看到,随着测试集规模的增大,分类器的总体F1值没有显著的变化,这说明分类器的总体F1值与测试集规模的变化没有明显的关联,同时还说明该算法显著减小了向量维数变化对分类器性能的影响。

表2 采用基于哈希表的动态向量降维算法的测试结果Tab.2 Testing results of the vector dimension reduction algorithm based on hash table dynamic
图2是2种向量表示算法的性能比较,其中A算法代表基于哈希表的动态向量降维算法,B算法代表基于文档向量模板的向量表示方法,横坐标代表测试文档集的规模,纵坐标代表使用2种向量表示方法的文本分类器对同样的测试文档集进行分类所耗费的时间,也代表了使用2种向量表示方法的文本分类器对同样的测试文档集进行分类时的分类速率,其衡量指标是每秒分类的文档数。在此记录了3组数据,分别对应于3种测试文档集规模:702篇、936篇和1 406篇,通过2种算法实验数据的比较可以看出,基于哈希表的动态向量降维算法的性能显著优于基于文档向量模板的向量表示方法的性能。
表3分别记录了2种算法多次实验数据的平均值,分别代表了2种算法的平均性能。其中“↑”表示第2种算法与第1种算法相比较,性能指标提高的百分比;“↓”表示第2种算法与第1种算法相比较,性能指标降低的百分比。通过对2种算法平均实验数据的对比计算,得到了2种算法性能量化的比较结果。从表3最后一行的性能比较数据可以看出,基于哈希表的动态向量降维算法的性能显著优于基于文档向量模板的向量表示方法的性能,支持了图2显示的性能比较结论。
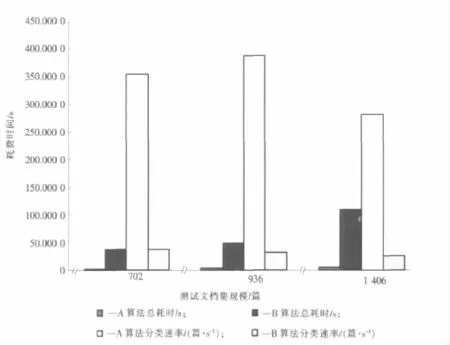
图2 2种向量表示算法的性能比较图Fig.2 Comparison of two vector says algorithm

表3 2种算法的量化性能比较Tab.3 Two algorithm′s quantitative performance comparison
3 结 语
在对向量空间模型的特性和哈希表的特性进行深入研究后,在综合考虑了基于文档向量模板的向量表示方法优缺点的基础上,提出并实现了一种基于哈希表的动态向量降维算法,并成功地将该算法应用到了中心向量分类器里。实验证明该算法有效降低了向量空间模型的维数,并且显著提高了基于向量空间模型分类算法的性能。
[1] 姚清耘,刘功申,李 翔.基于向量空间模型的文本聚类算法[J].计算机工程(Computer Engineering),2008,34(18):40-41,44.
[2] HAMADI R,BENATALLAH B.A petri Net-based model for web service composition[A]Proc of the 14th Australasian Database Conference on Research and Practice in Information Technology[C].Adelaide:[s.n.],2003.191-200.
[3] SAMARASENA B,NEIL D,RAY J,et al.Dimensionality reduction of face Images for cender classification[EB/OL].http://homepages.Feis,herts.ac.Uk/~nngroup/pubs/papers/Buchala2IS04.pdf,2006-03-20.
[4] LESPINATS S,GIRON A,FERTIL B.Visualization and exploration of high-dimensional data using a“force directed placement”method:Application to the analysis of genomic signatures[EB/OL].http://asmda2005.enst-bretagne.Fr/IMG/pdf/proceedings/230.pdf,2006-03-24.
[5] TENENBAUM J B,VIN de Silva,JOHN C L.A global geometric framework for nonlinear dimensionality reduction[J].Science,2000,290:2 319-2 323.
[6] VIN de Silva,JOSHUA B T.Global versus local methods in non-linear dimensionality reduction[EB/OL].http://web.mit.edu/cocosci/Papers/nips02-localglobal-in-press.pdf,2006-03-24.
[7] ROWEIS S,SAUL L.Nonlinear dimensionality reduction by locally linear embedding[J].Science,2000,290:2 323-2 326.
[8] LAWRENCE K Saul,SAM T Roweis.An introduction to locally linear embedding[EB/OL].http://www.pami.sjtu.edu.Cn/people/xzj/introducelle.htm,2006-03-24.
[9] 李 萍,李法朝.基于决策树的知识表示模型及其应用[J].河北科技大学学报(Journal of Hebei University of Science and Technology),2009,30(2):87-91.
[10] 李春明,李玉山,庄庆德,等.人脸识别技术的研究[J].河北科技大学学报(Journal of Hebei University of Science and Technology),2003,24(3):1-6.
