基于语义的语句相似度计算研究
2011-10-20王保民刘明生
王保民,刘明生,,邢 飞
(1.邯郸学院信息工程学院,河北邯郸 056005;2.石家庄铁道大学信息科学与技术学院,河北石家庄 050043)
相似度计算是自然语言处理领域一项核心的技术,决定着该领域工作的成败。例如,在机器翻译中,相似度计算主要是用来判断不同语言之间语义表达是否一致。在信息检索中,检索内容和检索目标是否相关是相似度计算的主要目的。在自动问答中,相似度计算主要用来判断是否所答即所问。在多文档文摘系统中,相似度计算能够识别全部内容的重要部分,从而可以提取到文章摘要。而在文本分类研究中,相似度计算可以通过特征的相似程度比较把目标文本归为某类已知文本中去。所以,从某种意义上讲,相似度计算的好坏直接影响到众多语言处理系统的发展。
在自然语言理解的智能化发展过程中,中文比大多数形合语言,如英文、法文、德文等,具有更大难度。这些形合语言,不要求严谨的逻辑,只追求结构连环。而中文是意合语言[1],词或句子的链接是通过其表达意思的逻辑性完成的,随意性强,灵活多变是其最大的特点。所以,研究汉语语句相似度计算必须考虑更多问题。业界关于中文语句相似度计算的方法很多,但由于没有完全涵盖所有问题,这些方法在效率和准确率方面还有许多不足。
基于向量空间模型的TF-IDF(term frequency-inverse document frequency)方法[2],将目标文本按组成顺序分成若干单词,并将每个单词依据其地位的高低加以权重,单词的多少决定相应坐标的坐标轴数量,权重是坐标轴上相应的值。由此,目标文本被投影到此坐标系中构成了1个矢量,同样比较样本也被投影到同一坐标系中构成1个矢量,计算2个矢量的夹角的余弦值,通过此值可以计算出两者的相似程度。这种方法的不足主要表现在2方面[3]。第一,采用该方法的前提条件是比较对象包括的词语数量必须足够多。当所面对的是单个句子时,这种方法往往不能表现出很好的效果。词频统计以及大容量语料库支持是其主要特点,单单构建如此庞大的语料库就是一件非常困难的事,需要更高的劳动和时间成本,并且还存在着数据稀疏等一系列问题。第二,TF-IDF方法对句子结构和语义不进行分析,只利用词频和词性等信息,从而存在很大的局限性。基于语义依存的语句相似度计算方法,只有在语句中作为支配作用的核心词汇以及完全隶属于它的有实际意义的词构成的搭配才被纳入依存分析计算相似度的范围内,其他成分忽略不计。也就是只是对词汇的语义进行分析计算,并不涉及句子成分间的相关性及其结构,更没有使用语言中的其他信息,因此计算结果并不令人满意[3]。编辑距离方法的主要缺点是没有对语义进行分析,仅仅是对单个没有实际意义的字进行编辑处理[4-5]。
很显然,为了满足具体应用,需要研究与之对应的相似度计算方法。例如:笔者在开发河北省某科技奖励网上评审系统时,需要提供的重要功能之一是对申报请奖的项目进行机辅形式审查工作。就本质而言,形式审查就是对本年度申报项目之间及本年度申报项目和历史项目之间包括项目名称、关键词、成果描述、成果佐证材料题录等信息,根据设定的审查规则进行自动比对,从而筛查出具有相同或相似内容的请奖项目。有些请奖者为了逃避机辅审查规则,利用意合型语言的特征,改变部分内容,使这些内容在意思上相同而字面上或语序上不同。此时,如果只对2个比较对象进行完全匹配比对,效率和准确率都会很低。为了满足实际应用要求,笔者提出了基于语义相似度的计算方法,此方法能够把语义上相同的内容查找出来,可大大提高形审质量。
1 基于语义的句子相似度计算模型及算法设计
为了克服业界常有相似度计算方法存在的不足,笔者依据中文语言的特点和组句规律,设计一套基于语义的句子相似度计算方法,以满足网上评审的需要。
1.1 语句相似度计算算法设计
语句相似度计算的前提条件是让计算机能够理解被比较的句子。要想理解一个自然语言表述的句子,一般要对其进行词法、语法及语义分析,其中的词法分析是整个理解过程的基础。特别是对于像汉语这样的自然语言显得尤为关键。汉语中词是最小的能够独立活动的有意义的语言成分,在一个汉语句子中,词与词之间没有明显的分隔符,而是连续的汉字串,这为词法分析带来了更多的困难。所以,第1步要做的就是对中文句子进行分词,在此基础上对词进行标注。
当把组成一个句子的所有词进行了一一标注后,会发现另外一个汉语语言特点,那就是相同的词在不同的语境下会产生不同的意思,即歧义词。如果不对这些歧义词汇进行意思明确,计算机在进行相似度计算时,将产生语义理解混乱,即会认为2个字面上相同的词会有相同的意思,显然语境对词义理解的影响造成了相似度计算准确率的下降。解决这个问题的办法就是第2步所要做的词义消歧。
中文分词技术和词义消歧技术都已被研究许多年了,不管是从技术层面还是从应用方面上来说,已经相当成熟。笔者选择中国科学院计算技术研究所研发的汉语词法分析系统(ICTCLAS)[6]和哈尔滨工业大学计算机科学与技术学院信息检索研究室所做的词义消歧系统[7-8],作为语句相似度计算模型的支撑算法。
设2个句子A和B,A包含的词为x1,x2,…,xm,B包含的词为y1,y2,…,yn。经过分词和词义消歧后,句子A和B中的词分别被标注了语义号,语义号相同的词被认为是语义相同的词。词xi(1≤i≤m)和yj(1≤j≤n)之间是否语义相同用S(xi,yj)来表示,如果语义相同,则S(xi,yj)=1,否则S(xi,yj)=0。设词语x1,x2,…,xm的权重为W1,W2,…,Wm,可得到A和B的语句相似度公式为

式(1)中,权重值Wi不是单纯一种词性的权重而是这种词性下每个词的权重,这样设计的目的是由于每种词性下词的个数不同,在进行相似度比较时,不会因为词的数量或个别词语义计算的差异导致相似度计算值有大幅波动。如果在一个语句中有多个词义相同的词,如语句A中词语x1和x2的语义号相同,它们又分别和语句B中的y1的语义相同,那么在计算过程中只算作1次相同,即不重复计算。在词义消歧过程中,经常会给出语义号为“-1”的情况,“-1”表示词语本身就代表其意,所以在遇到这种情况时,直接用这个词进行相似度比较,而不用无实际意义的语义号。
为了提高相似度计算的准确率,在计算过程中,要让被比句与每一个比较句进行相似度比较,并且分别计算被比句与比较句的相似度。被比句中相似度大于指定值时,把计算的2个值保存为一组,然后进行选择,找出最大可能相似比较结果,选择算法如下:
① 是否存在2个以上的保存组,如果存在选择前2个被比句相似度值最大组进行比较,否则如果只有1个保存组,选择后转到④,如果为空,则转到⑤;
② 是否这2组中被比句的相似度值相差不大(一般不超过20%),并且2个比较句的相似度值第1组比第2组小,否则选择被比句相似度值最大的一组转到④;
③ 分别计算这2组中被比句和比较句的差,选择差的绝对值最小那一组;
④ 保存结果;
⑤ 进行下一语句的相似度计算。
1.2 权重设计
句子中的每一个词根据其词性的不同在句中的成分也不同。例如:名词往往作主语或宾语,动词常常作谓语,形容词作定语等。不同成分对句子意思的构成影响的重要程度是不同的。主语、谓语、宾语是一个句子的主干,定语、状语、补语对主干起修饰作用。因此,在进行2个句间相似度比较时,不同成分之间是否相同会造成相似度计算的差异。为了反映这种差异,必须给每个词赋予一个权值。如果让计算机计算词在句子中作什么成分是非常困难的,又因为词性是决定句子成分的关键因素,所以要依据每个词的词性为其加权。
现代汉语的词可以分为实词和虚词2大类。实词包括名词、动词、形容词、数词、量词和代词,虚词包括副词、介词、连词、助词、拟声词和叹词。实词指有实在意义,能够单独充当句子成分,一般能单独回答问题的词语。虚词指不表示实在意义而表示语法意义的词,它不能充当句法成分。实词在句子中的地位比虚词重要得多,相应地其权重值也要比虚词大。
相似本身是一个非常模糊的概念,它带有很强的主观因素。所以,词性权重值的计算要根据具体实验得到,然后与客户进行共同协商确定。笔者只给实词和虚词中的副词赋以权重,其他虚词忽略,并且把代词归为名词来考虑,权重总值为1。从句子的结构来看,副词、形容词、数词和量词在句义表达上所起的作用有限,给它们分配的权重值为每种词性0.05。相关资料以及经验表明,动词在句子语义表达中起核心作用,名词其次,所以动词分配的权重要大于名词。但是从大量实验结果看,如果赋予动词权重值比名词过大,消歧时又出现了意思上的偏差,也就是计算机对于动词词义理解不准确,从而会使语句相似度计算出现错误。因此,当句子中的每个动词的权重是名词的1.5倍时是最合适的。权重计算公式为

式中:M和N分别表示句子中名词以及动词的数量;wx表示名词的权重;wy表示动词的权重。

2 实验结果与分析
由于没有语句相似度测试的标准测试语料,所以实验所用的语料由系统开发人员自己构造。本文实验所用的测试集,是笔者利用河北省科技进步奖当年(2010年)请奖项目库和往年请奖项目库构建的600个语句。这些句子分成2个部分,其中550句为噪音句子,构成噪音集,另外50个是随机选取的句子,构成标准集。对50个标准集中的句子人为构造与之相似的句子,形成一对一的相似关系,构成比对集。
测试实验是这样进行的。把比对集中的50个句子按顺序抽出一个句子分别和600个测试集中的句子进行相似度计算,并按照相似值的大小对测试集中的句子进行排序,然后观察输出结果,如果具有最大相似值的句子就是标准集中的句子,那么认为相似度计算成功,否则失败。在此分别用TF-IDF方法、语义依存方法、编辑距离方法和笔者提出的方法做了实验,并把实验结果进行了对比,如表1所示。
从表1可以看出,在实验条件相同的情况下,笔者采用的算法所得的准确率要远远高于其他3个方法。原因在于,笔者在语义相似度计算中不仅考虑了词语的语义,还考虑了句子不同组成成分对句子语义理解所产生的影响不同,因此,计算得到的加权语义相似度更具有合理性。此外,每一种算法都有其优缺点,在不同的应用领域,应根据需要选择不同的计算方法,这样就可以更加全面、准确地衡量句子之间的相似度。将该计算方法应用到2010年度河北省科技进步奖的形式审查中,在不同的查重规则下,均表现出理想的审核结果,平均查准率高达99.98%。
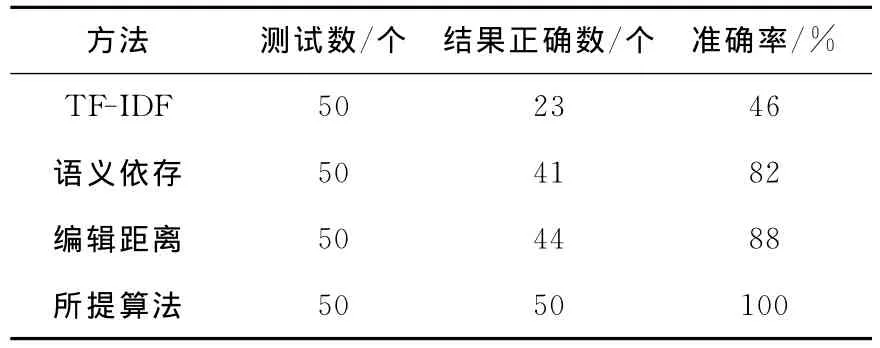
表1 实验结果对照表Tab.1 Comparison of the test results
3 结 语
采用基于语义的语句相似度计算方法,该方法把语义与词语在语句中所作成分的重要性结合起来,有效地分析了语句的表达意思。在计算相似度时,针对汉语由语素构成词语、由词语构成语句的特点,分别对汉语中的词语、词义、句子3个层次进行了研究。这三者层次不同,但是联系密切,由部分构成一个有机的整体,整个计算过程每一步都利用上一步的计算结果,在实验测试和实际应用中均取得满意结果。
[1] 刘 颖.计算语言学[M].北京:清华大学出版社,2002.
[2] 张玉芳,彭时名,吕 佳.基于文本分类 TF-IDF方法的改进与应用[J].计算机工程(Computer Engineering),2006,32(19):76-78.
[3] 秦 兵,刘 挺,王 洋,等.基于常问问题集的中文问答系统研究[J].哈尔滨工业大学学报(Journal of Harbin Institute of Technology),2003,35(10):1 179-1 182.
[4] LEUSCH G,UEFFING N,NEY H,et al.A novel string-to-string distance measure with applications to machine translation evaluation[A].Machine Translation SummitⅨ[C].New Orleans:[s.n.],2003.240-247.
[5] 崔春生.基于可拓的 Vague相似度计算[J].河北科技大学学报(Journal of Hebei University of Science and Technology),2010,31(2):108-111.
[6] 刘 群,张华平,俞鸿魁,等.基于层叠隐马模型的汉语词法分析[J].计算机研究与发展(Journal of Computer Research and Development),2004,41(8):1 421-1 429.
[7] LIU Ting,LU Zhi-mao,LI Sheng.Word sense disambiguation based on improved bayesian classifiers[J].Journal of Electronics,2006,23(3):394-398.
[8] 张立岩,吕 玲,王井阳.基于最大熵算法的全文检索研究[J].河北科技大学学报(Journal of Hebei University of Science and Technology),2009,30(2):112-115.
