糖尿病线性判别诊断模型的建立
2011-09-20魏玉辉傅松波武新安
李 雯,魏玉辉,傅松波,武新安
(兰州大学第一医院,甘肃 兰州 730000)
近年来,糖尿病发病率呈逐年上升趋势,已成为发达国家继心血管病和肿瘤之后的第三大非传染性疾病。流行病调查显示,我国目前大约有4000万糖尿病患者,预计到2025年,我国糖尿病患者将达到1 亿。因而对糖尿病进行早期诊断及分类研究非常重要[1]。分类体系在医学诊断中的应用日趋广泛,从患者临床检验数据到专家决策,均是临床评价的重要过程。机器学习算法可以通过大量临床检验数据和专家决策进行学习,寻找数据中存在的规律及影响疾病诊断的主要因素。目前,机器学习算法在疾病辅助诊断中的应用越来越广泛,使用的算法涉及人工神经网络(ANN)、支持向量基(SVM)、遗传算法(GA)、线性判别分析(LDA)等[2~8]。LDA 是用于判别个体所属群体的一种统计方法,是多元统计分析中判别样品所属类型的一种重要方法,特别适合多变量的两分类或多分类研究。目前,机器学习算法用于糖尿病诊断的研究少有报道[3]。本文采用临床常规检查指标(血常规、生化)与LDA 相结合的方法建立计算机辅助糖尿病诊断模型,取得了较为满意的结果。
1 研究资料
1.1 资料来源
研究病例来自兰州大学第一医院病历库,所收集的资料均为医院内分泌科、普外科2007年全年出院患者。
1.2 研究对象
均由有经验的内分泌科医师诊断。糖尿病病例352例,非糖尿病病例389例;男性428例,女性313例;年龄8~84岁,平均年龄(58 ±14)岁。录入信息包括患者基本情况(年龄、性别、入院日期、出院日期等)、血常规检查指标(白细胞、红细胞等)、生化检查指标(天冬氨酸氨基转移酶、丙氨酸氨基转移酶等)。
1.3 纳入及排除
分别以1型、2型糖尿病,其他特异性糖尿病及妊娠期糖尿病的临床诊断标准为纳入标准收集病例。由有经验的内分泌科医师诊断为糖尿病的出院患者、普外科出院患者,排除其中基本情况、血常规检查、生化检查指标不齐全者,其余均纳入研究。
2 研究方法
2.1 线性判别分析
判别分析是用于帮助研究者寻找区别各组差异的变量,将对象较准确地判入各组的方法[4]。判别分析最常见的应用是为了判定哪些变量具有组间判别效力而对研究对象中多个测量变量进行选择[3]。经过判别分析之后就会得到判别函数。判别分析适用于2组以上,且每个病例必须有2个以上变量的分类分析。
一般说来,我们可对2组间的判别拟合一个线性方程:Y=a+b1X1+b2X2+...+bnXn式中a 为常数,b1 到 bn 为回归系数。判别函数对2组判别问题的解释较直接,具有最大相关系数的变量对预测组别的贡献最大[3]。本实验为了研究方便,定义糖尿病病例为1,而非糖尿病病例为-1。
2.2 逐步判别原理
逐步判别分析是根据多元方差分析中的wilk′s 统计量及F 值进行变量的筛选。每一步选一个判别能力最大的指标进入判别函数,直到被引入模型的变量没有一个符合进入模型的条件时,变量引入过程结束。逐步判别分析以wilk′s 统计量最小者入选,本研究中模型引入变量的最小F 值为10,剔除变量的最大F 值为2.71。这样得到的判别函数所包含的指标都很重要。
2.3 病例收集与分类
按上述纳入与排除标准收集病例,结合临床检验结果与有经验临床医生的诊断对所收集病例进行分类,同时建立相应数据库。
2.4 训练集和测试集的选择
研究对象共741例,所有收集的病例以4∶1 比例分为训练集样本和测试集样本。为使计算机能更合理地从资料中获取信息,训练集样本应能很好地代表患者真实情况,因此,运用数据库中已知其类别的样本作为训练集,从741例样本中选择594例(糖尿病病例281例,非糖尿病病例313例)样本组成训练集。为了检验从训练集中得到识别函数的可靠程度,可利用一些未包括在训练集中的样本构成测试集,以检验其识别的可靠性,因此,将剩余147例(糖尿病病例71例,非糖尿病病例76例)样本构成测试集,以验证模型的预测能力。
2.5 判别函数的建立
通过训练集获得判别函数建立模型。将训练集患者的基本情况、血常规检查及生化检查信息从Microsoft-Excel 数据库导入SPSS 数据库。然后用SPSS 统计软件提供的判别分析方法对这些数据进行判别分析,选出对预测组别贡献较大的变量,建立判别函数。
2.6 模型的评价
用训练集与测试集的误判率对模型进行判别效果评价,并引入特异性和敏感性指标进一步判断LDA 的预测能力。
3 结果与讨论
3.1 特征变量及判别函数
经LDA 法进行判别分析后,逐步选出8项对区别各组贡献较大的变量。判别函数的变量及Wilk′s 值,见表1。
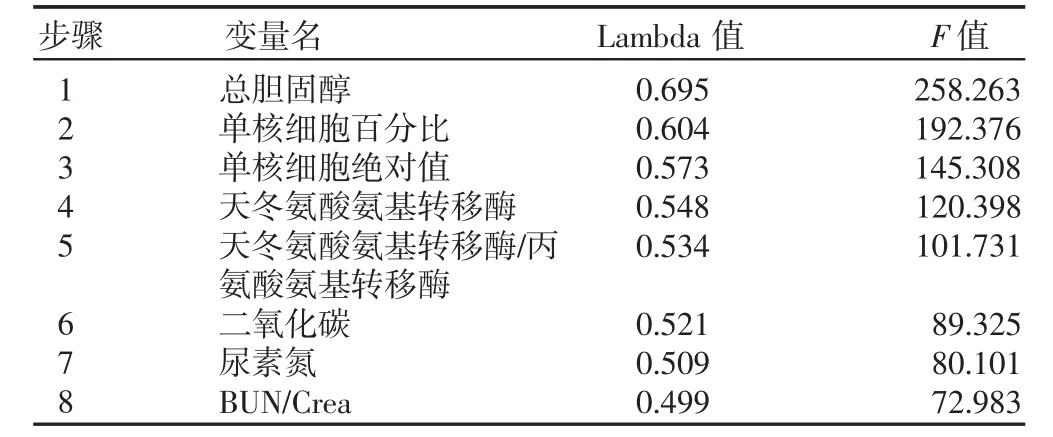
表1 逐步判别分析筛选出的特征变量
在疾病诊断中常需根据就诊者的检查指标、体征等的分析,作出是否患有某种疾病的诊断,这种问题就可用判别分析解决[5]。逐步判别分析可以筛选出对于鉴别2类具有不同属性的人群有较大贡献的变量,从而使其结果具有较好的区分度。表中F 的绝对值越大就意味着该变量对模型的贡献越大。由表1 中的F 值可知,变量总胆固醇比其他变量相对重要,这些变量所代表的临床意义与诊断模型之间的关系有待进一步研究。由8个特征变量相对应的判别函数系数建立的糖尿病与非糖尿病分类判别函数如下。
糖尿病判别函数:Y=-55.570+0.168X1+3.610X2+0.413X3+0.004X4-0.030X5+2.278X6+0.083X7+1.405X8
非糖尿病判别函数:Y=-42.9820+0.115X1+2.849X2+0.372X3+0.008X4-0.010X5+2.149X6+0.071X7+0.871X8
3.2 判别结果及判别正确率
将741例合格病例以4∶1 比例分为训练集样本和测试集样本,经交互检验法验证可得训练集的预测情况,见表2。
由表2可知,训练集和测试集的预测准确率分别是85.7%和81.6%,模型总判别准确率为84.9%。

表2 LDA 判别模型预测准确率
3.3 特异性和敏感性
LDA 对于糖尿病和非糖尿病的判别效果较好,为了进一步判断LDA 的预测能力,实验引入了特异性(Specificity)和敏感性(Sensitivity)指标。
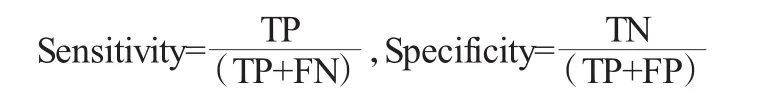
其中TP 指真阳性数,FN 指假阴性数,TN 指真阴性数,FP指假阳性数。在LDA 法判断结果中,测试集的假阳性病例是31例,假阴性病例是54例。由此求得测试集样本的敏感性是0.75,特异性是 0.88。
4 结论
本文是首次源于临床常规检查指标(血常规、生化)与机器学习算法相结合建立计算机辅助糖尿病诊断模型。逐步判别分析的总判别准确率达到84.9%,虽然判别效果较好,但还可通过进一步扩大样本量,或采用更加适合的机器学习算法提高判别能力。
[1]陈文彬.诊断学[M].第5版.北京:人民卫生出版社,2004.
[2]Kemal Polat,Salih Gunes,Ahmet Arslan.A cascade learning system for classification of diabetes disease:Generalized Discriminant Analysis and Least Square Support Vector Machine[J].Expert Systems with Applications,2008(34):482~487.
[3]J Liang,R Du.Model-based Fault Detection and Diagnosis of HVAC systems using Support Vector Machine method[J].International Journal of Refrigeration,2007(30):1104~1114.
[4]Kemal Polat,Salih Gune.Breast cancer diagnosis using least square support vector machine[J].Digital Signal Processing,2007(17):694~701.
[5]Tim W,Nattkemper,Bert Arnrich,et al.Evaluation of radiological features for breast tumour classification in clinical screening with machine learning methods[J].Artificial Intelligence in Medicine,2005(34):129~139.
[6]Weida Tong,Qian Xie.Using Decision Forest to Clissify Prostate Cancer Samples on Basis of SELDI-TOF MS Data:Assessing Chance Correlation and Prediction Confidence[J].Environmental Health Perspectives,2004(112):1622~1627.
[7]Kemal Polat,Salih Gunes.Computer aided medical diagnosis systerm based on principal component analysis and artificial immune recognition systerm classifier algorithm[J].Expert Systems with Applications,2008(34):773~779.
[8]Marco A,M énde z,Christian Hodar,et al.Discriminant analysis to evaluate clustering of gene expression data[J].FEBS Letters,2002(522):24~28.
