改进的RBF文本分类算法
2011-08-04王欣欣赖惠成
王欣欣,赖惠成
(新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046)
0 引言
目前国内外基于内容信息过滤的研究主要集中在核心算法上,基本上可以概括用户模板的构建及其算法研究和用户模板与文本的匹配技术两个方面,这两个方面是文本信息过滤的两大关键技术。
很多分类技术应用到文本分类中,取得了良好的效果,包括神经网络、支持向量机[1]以及决策树方法等,而其中利用神经网络方法的文本分类,关键是提取出既能比较全面地反映文档类别的信息,又有利于神经网络学习的特征;其次对应着选取的特征,需要设计合适的网络结构来分类,因此提出一种基于互信息的特征提取[1],结合聚类算法的思想,采用基于样本中心的 RBF分类算法进行分类实验,并给出仿真结果。
1 文本分类系统
简单地说,文本分类系统的任务是:在给定的分类体系下,根据文本的内容自动地确定与文本关联的类别。自动文本分类即根据统计模式识别思想,将文本表示成特征向量,然后用训练文本对事先选定的分类器进行训练,直接或间接地提取出蕴涵在训练文本中有关各个文本类的统计特性,并根据这些特性确定出分类准则,最后依据这些准则对未知文本进行分类决策。一个典型的文本分类系统如图1所示。

图1 文本分类系统
2 聚类算法
典型的聚类过程主要包括数据(或称之为样本或模式)准备、特征选择和特征提取、接近度计算、聚类或分组、对聚类结果进行有效性评估等步骤[3]。
K-means聚类算法是聚类分析中使用最为广泛的算法之一[4],算法步骤如下:
②对每个样本 xi找到离它最近的聚类中心 zv,并将其分配到 zv所标明的类 uv;
③采取平均的方法计算重新分类后的各类心;
3 基于KPCA的RBF神经网络分类算法
比较常见的文本分类算法有:类中心向量、朴素贝叶斯、支撑向量机、决策树、神经网络、k最近邻、动态聚类等[5]。
核主成分分析(KPCA)是一种对多元数据进行统计分析的技术,利用输入空间中预先定义的核函数直接计算特征空间中的向量点积,可以对特征空间实施降噪、降维和去相关性。
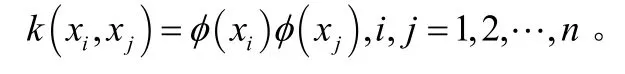
RBF神经网络是由输入层、隐层和输出层3层神经元构成的典型前向神经网络。
RBF神经网络中隐层和输入层之间权值(中心点 cj和中心宽度σj)的选择是影响整个网络性能优劣的关键。
(1) cj的确定
采用K-均值聚类算法[6]确定 cj,找到具有代表性的样本点作为RBF神经网络隐层神经元中心,从而可以极大地减少隐层神经元数目,降低网络复杂度。
(2)σj的确定
σj决定了RBF神经网络隐层神经元感受域的大小,对网络的精度有很大影响。通常应用K-均值聚类算法后,对每个cj,可以令相应的σj为cj与属于该类的训练样本之间的距离的平均值,即:cj和σj确定之后,采用梯度下降算法来获取权值wij。RBF神经网络的输出层对隐层神经元的输出进行线性加权组合,并增加一个偏移量 w0,可表示为:
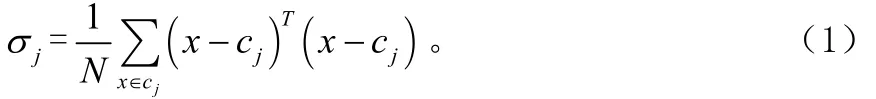
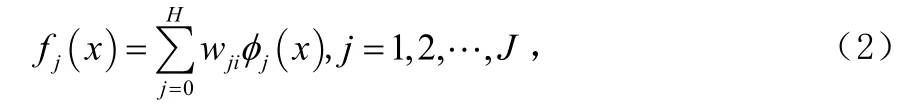
式中H和J分别表示隐层和输出层神经元个数,nxR∈表示输入向量,ijw为隐层第 j个神经元和输出层第i个神经元之间的连接权值。
4 实验设置
4.1 预处理模块
实验语料集的预处理采用中科院的ICTCLAS分词系统进行。目前,在文本信息处理问题上,文本的表示主要采用向量空间模型。向量空间模型的基本思想是以向量的形式来表示文本。
4.2 特征表示模块
常用的特征提取方法有:潜在语义索引,文档频数,信息增益,期望交叉熵,互信息,文本证据权,CHI统计等[7]。采用词和类别的互信息量作为特征项抽取的判断标准。其中:
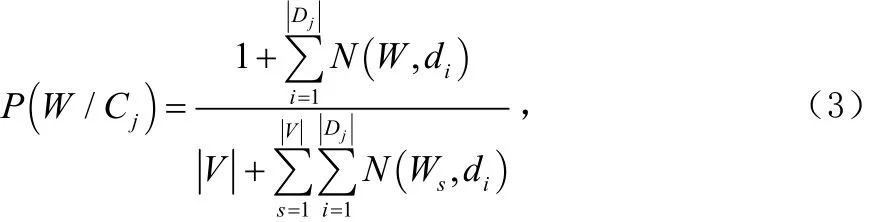
为词条W在类别 Cj中占的比重,Dj为 Cj类的训练文本数,N (W ,di)为词W在 di中的词频,V为 Cj类的总词数,为所有词在该类的词频和。
而P(W)与上面的计算公式相同,只是把所有的训练样本组成一个“总类”,就是计算词条在总类中的比重,即:
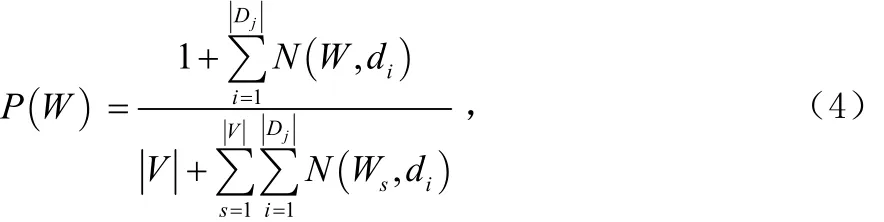
4.3 特征降维模块
考虑到输入空间mR 线性不可分,要在映射得到的特征空间F中变得线性可分,或者以较高的概率线性可分,核函数形式采用多项式核函数:其中θ取0,q取大于等于1的正整数。

实验验证,q取3时RBF神经网络分类器取得较好的分类性能.
4.4 分类算法模块
分类算法是文本分类系统的关键所在,除RBF神经网络外,还对BP神经网络分类算法进行了试验。对10个分类只建立一个网络,其中输入层神经元数和输入向量的特征维数一致,输出层神经元数等于总类别数,为10,隐层神经元取64,η取0.05,minE取0.1,maxT 取3 000,径向基函数采用高斯核函数,即:

5 实验与分析
对581个文本样本进行信息编码,得到10维文本的信息编码向量581个,其中140个作为训练样本,其余441个作为测试样本,在matlab环境下分别进行BP和RBF神经网络的分类算法实现,再利用K-means聚类方法作为RBF神经网络分类算法的核心思想,进行RBF分类,并与BP分类算法比较。进一步改变高斯函数宽度参数进行试验,观察其对分类结果的影响。
文本分类系统的最主要的两个指标是查准率和查全率,所谓的分类正确就是指自动分类结果与人工分类结果吻合。取其中3类的统计结果见表1。
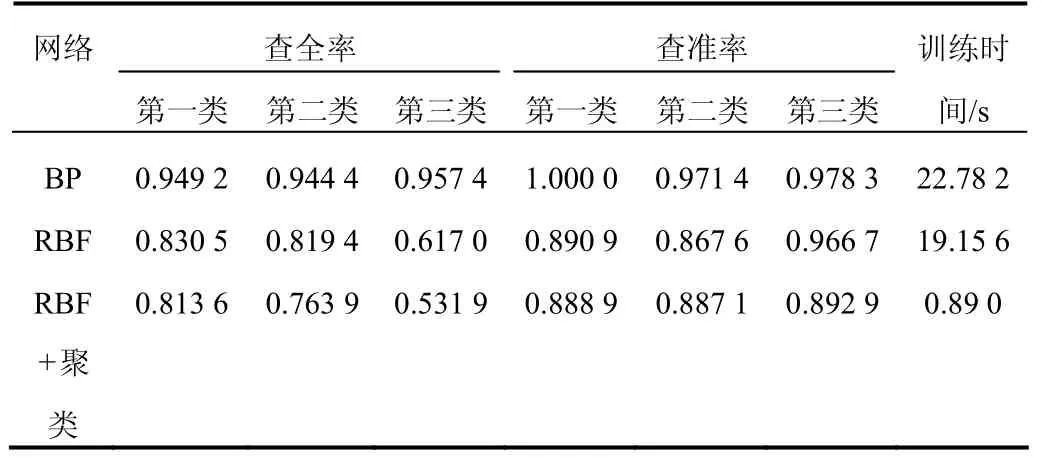
表1 分类中3类的统计结果
由表 1可以看出,RBF网络分类结果不如 BP网络的好,但使用给定样本特征值的平均值作为聚类中心的径向基网络分类结果较好,且训练时间很短。
对以上 3类样本在利用结合聚类的 RBF文本分类算法时,修改高斯函数宽度参数,查全率与查准率难以同步改善,宽度参数变大时,高斯函数区分能力降低,误差减小速度变快,最终误差变小。
6 结语
以基于核主成分分析的神经网络为基础,借鉴了聚类算法的思想,采用样本中心作为 RBF分类算法的核心,并和 BP神经网络分类算法进行了比较,从实验得出的误差曲线图和统计表格可以看出,在收敛速度和分类效果上,结合聚类的 RBF文本分类算法要好于 BP神经网络分类算法,充分体现了改进后 RBF分类算法的简洁和时效性。径向基函数的宽度参数会影响分类的准确程度和实验误差,查全率和查准率不能同时提高,随着宽度参数的增大,误差会变小。实验结果表明,通过结合聚类算法和基于核主成分分析的特征抽取算法,RBF神经网络分类算法能有效地对输入空间进行特征降维,并能改善 RBF神经网络分类算法的分类性能。
[1] KUFIK T, BOGER Z, SHOVAL P. Filtering Search Results Using an Optimal Set of Terms Identified by an Artificial Neural Network[J].Information Processing and Management, 2006(42):469-483.
[2] HUANG J J, CAI Y Z, XU X M. A Hybrid Genetic Algorithm for Feature Selection Wrapper based on Mutual Information[J].Pattern Recognition Letters,2007,28(13):1825-1844.
[3] 孙吉贵,刘杰,赵连宇.聚类算法研究[J].软件学报,2008,19(01):49-52.
[4] 蒋盛益,郑琪,张倩生.基于聚类的特征选择方法[J].电子学报,2008,36(12A):157.
[5] 杨俊. 基于核主成分分析和径向基神经网络的文本分类研究[D].安徽: 中国科学技术大学, 2009.
[6] 李燕, 张月国, 李生红. 基于蚁群算法的文本分类和聚类[J]. 信息安全与通信保密,2009(10):57-58.
[7] 朱杰,刘功申,陈卓.中文文本倾向性分类技术比较研究[J].信息安全与通信保密,2010(04):56-58.
