针对淘宝商家客户管理系统的研究与开发
2011-05-01王存昕蒋文蓉
王存昕,蒋文蓉
(上海第二工业大学计算机与信息学院,上海 201209)
0 引言
客户资源决定企业的核心竞争力。淘宝上开店的商家们缺乏对自己以及同类网店销售情况的收集和分析,没有对产品进行促销的可靠参考数据资料,不能维护自己的客户资源。面对淘宝竞争日益激烈的状况,商家们需要维护自己的客户,关心他们的想法、需求、购买目的,并与客户建立良好的、长期的客户关系,强化与客户的沟通,留住老客户,拓展新客户,提升客户价值,从而全面提升竞争能力和盈利能力,由此本课题应运而生了。
1 相关研究
1.1 阿里旺旺
目前,针对C2C的网店的客户管理,淘宝网提供了阿里旺旺软件。通过使用这个软件,商家们可以添加买家账号为好友,可以给客户发信息,可以处理订单、发货、退货等,但是没有针对买家进行信息的统计、消费情况的分析,不能为商家的营销提供参考。
1.2 金算盘网站宝平台
这是一套功能强大的企业网站管理系统,集成网络营销思想,使用生成HTML静态页面、模板程序分离、强大内容标签技术,在建立网站和后天管理功能方面都很出色,但是没有针对客户的管理功能,不能对客户的信息进行分析和统计。
1.3 买买乐、拍拍、易趣等C2C网站
这些C2C网站尽管前台界面美观,后台管理功能也比较完善,但是没有对商家的客户进行管理、消费情况统计分析等功能。
1.4 本系统的优势
本课题研究开发的针对淘宝商家的客户管理系统,是专为淘宝商家量身打造的客户管理系统,能对商家客户个人信息、消费信息、商品信息等进行统计和管理,并能生成统计图及详细报表,可为商家进行产品营销提供参考。
2 信息抽取程序设计
本程序主要是运用Java技术来实现的,其界面部分使用的是JSP及AJAX技术,数据库使用MYSQL,操作系统使用WINDOWS 7。
2.1 信息抽取的基本流程
WEB信息的抽取分四个步骤:(1) WEB页面的抓取;(2) 页面的清洗;(3) 数据的抽取;(4) 数据的装载[1,2]。首先抓取WEB页面获取WEB数据源,然后使用网页预处理程序清洗页面,去除与信息无关的标记,生成结构化的HTML文档,最后再将HTML文档转化成为后续程序可以识别的标准结构,获取淘宝交易记录和客户信息等数据,加载到数据库。

图1 抽取流程图Fig.1 Extraction flow chart
2.2 网页抓取程序
网页抓取程序的功能就是通过URL将网页的HTML代码抽取出来保存到文本文档中。该程序会通过输入的URL自动获取该URL的域名地址,可以保证遍历网页抽取信息的范围在该站点中。这样可以更有效地针对一个网站进行信息抽取,也可以提高抽取的效率和准确性[3,4]。
2.3 网页预处理程序
网页的预处理在整个信息抽取过程中是一个很重要的部分。网页中大量有用的数据往往都被许多噪音数据所干扰,包括广告、导航条、版权说明等。尽管这些噪音数据对于在互联网上浏览的用户来说有一定的功能,但是它们也妨碍了网页数据的自动收集和挖掘,包括网页自动分类、聚类、信息抽取和信息检索等的准确性、效率和性能。网页的预处理主要包括HTML代码的修正和噪音数据的过滤。在这里我把预处理功能分成了三块:HTML代码修正、URL处理和信息数据处理[5,6]。
2.4 包装器
包装器是一种软件过程。这个过程使用已经定义好的信息抽取规则,将网络爬虫搜集到的WEB页面的信息数据抽取出来,转换为用特定的格式描述的信息。一个包装器一般针对某一种数据源中的一类页面。包装器运用规则执行程序对实际要抽取的数据源进行抽取。包装器一般由抽取规则和抽取器两部分构成[7]。
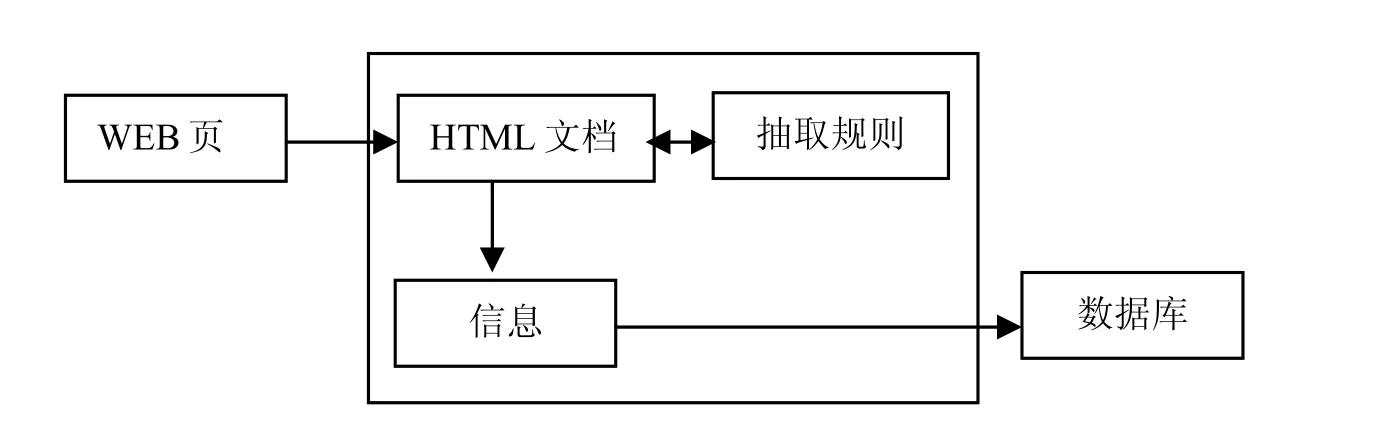
图2 包装器Fig.2 Wrapper
2.4.1 抽取规则的制定
抽取规则主要描述规则制定、抽取步骤、输出方式等。本程序的抽取规则主要是由两个方面组成的,一个是URL抽取规则,另一个是基于DOM树的抽取规则[8-12]。
URL抽取规则十分重要,是直接影响抽取效率的一个部分。根据淘宝网店中所有产品展示的页面数据特点,本程序进行了针对性的信息抽取,保证抽取的准确性和效率性。
基于DOM树的抽取规则是采用基于DOM树抽取路径表达式的抽取规则对网页内容进行抽取。下面是淘宝网店商品展示页面的HTML代码片段,对应的DOM树如图3所示。该DOM树中的每一个节点对应于HTML语法里的TAG元素,对于各个消息属性域有着共同的父节点,其路径为HTML[0].BODY[0].DIV[0],该节点以下所有子节点构成了所要抽取的信息块。淘宝网店商品展示页面的HTML代码片段如下:


图3 网页的DOM树Fig.3 DOM tree of the page
基于DOM树具有良好的结构性,可以根据树的节点准确定位HTML页面中的TAG标记,能够准确定位到所要抽取信息的位置。该抽取方法抽取数据明确,不会产生歧义。虽然不能动态适应HTML文档结构的变化,但是淘宝网页内容都为机器生产的统一标准的代码,结构很少发生变化。抽取规则的重点是将商品供应信息块和块内属性域利用路径表达式进行唯一性描述。
2.4.2 包装器的工作流程
当用户指定好包含抽取信息的URL时,包装器就会将URL进行规则提取。接着用户指定抽取样本,包装器又会将样本进行规则提取同时记录抽取规则。当抽取规则制定完毕后,程序将会根据选择抽取信息的条数来自动进行抽取,并存入对应的数据库[13,14]。
2.5 信息的存储
信息的抽取是根据抽取规则一条一条地抽取,但信息的存储则需要按数据表一行一行地插入。这样就造成了抽取和存储的不同步,因此在配置表里存储了所生成的数据表的字段数信息。在存储信息时,根据字段的数量进行循环拼接SQL语句,每次信息的规则比较就是一次循环,在循环的开始和结尾处将SQL语句补完,以确保语句的正确性。
3 数据维护及图表生成
对已经保存到数据库中的数据,进行进一步整理、维护[15,16],然后使用Google图表API生成统计图[17]。
3.1 数据的维护
主要是对淘宝买家的信息、消费记录和商品信息,进行查看、修改和更新。
3.2 图表的生成
经过分析可得到某淘宝网店的全部商品的交易记录信息。
淘宝网店“杜曼闪卡”的商品“圆点卡数字卡*全程教学计划”的部分交易记录数据如下:

表 1 交易记录表Tab.1 Transaction record table
可得到网店的淘宝买家信息。
淘宝网店“杜曼闪卡”的部分买家信息数据如表2所示。

表2 买家信息表Tab.2 Buyers’ information table
经数据分析生成的统计图表如图4所示[18,19]。

图4 数据统计图Fig.4 Data statistics chart
4 基于B/S结构的站点设计
淘宝客户管理系统总体框架如图5所示。
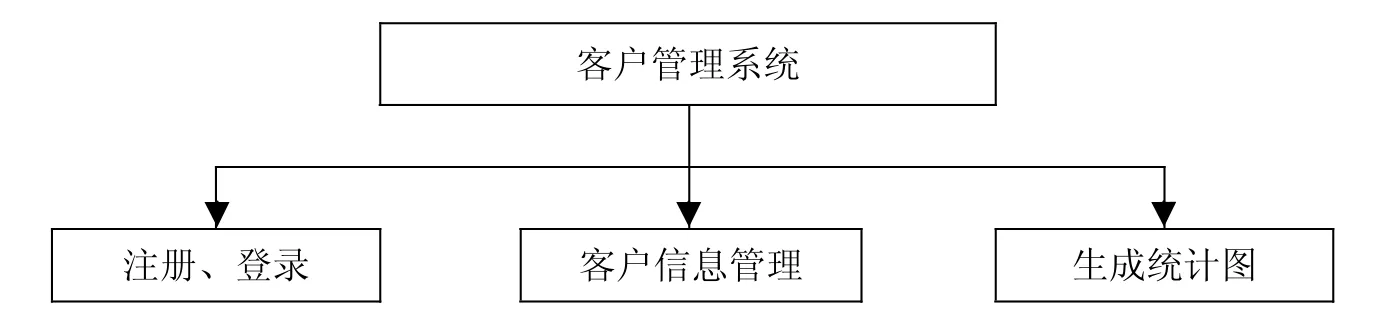
图5 客户管理系统总体框架Fig.5 Customer management system framework
图表显示页面见图6。

图6 商家客户消费统计图Fig.6 Consumer business customers statistics chart
5 结论
5.1 总结
根据交易记录,统计生成商家客户购买商品的种类、数量,就可以看出最优客户、顾客忠诚度及购买的产品特征,可向这些顾客推荐优惠活动及感兴趣的促销产品;根据淘宝买家信息,统计出他们的居住地,可据此向顾客居住地密集的地域推出包邮促销活动;统计出购买某商品的性别特征,商家可调整与这种商品配套的相关产品的推荐促销。
5.2 展望
使用第三方统计分析工具对现在淘宝、买买乐等平台上的C2C网店进行分析,对商家的客户进行管理,成本低,效率高,易用性强。然而,这种基于对WEB信息进行抽取的客户信息管理系统,最主要的问题仍是信息抽取的准确性和健壮性有待提高,以及信息的加密和访问权限等问题。本系统的功能比较有限,还可以朝多样化、全面化、智能化等方向发展,尚有很大的开发空间。
[1]柳佳刚, 刘高嵩, 贺令亚, 等.基于Web的信息抽取技术现状与发展[J].福建电脑, 2007, (7):48-49.
[2]李保利, 陈玉忠, 俞士汶.信息抽取研究综述[J].计算机工程与应用, 2003, 39(10):1-5, 66.
[3]苗颖.Web页面信息自主抽取技术的研究[J].中国科技信息, 2007, 10(23):104-105.
[4]王锟.WEB文档信息抽取方法研究[J].福建电脑, 2008, 3(3):133-134.
[5]陈天, 黄敏.Web信息抽取中的数据交叉定位[J].华南理工大学学报:自然科学版, 2008, 5(5):43-47.
[6]色菲, 王佳, 潘超.基于XML描述的WEB信息抽取技术研究[J].计算机与信息技术, 2007, 11(34):380,403.
[7]周顺先, 林亚平, 王雷.Web信息抽取中基于页面特性的包装器平衡算法[J].计算机工程与应用, 2006(36):144-147.
[8]冀高峰, 汤庸, 道炜, 等.基于XML的自动学习Web信息抽取[J].计算机科学, 2008, 11(35):87-90.
[9]吴扬扬, 陈锻生.识别和抽取web列表中的关系信息[J].计算机科学, 2003, 31(6):86-88.
[10]黄健斌, 姬红兵, 孙鹤立.Web网页中动态数据区域的识别与抽取[J].软件技术与数据库, 2007.6(11):53-55.
[11]徐云风, 蒋文蓉.Web页面抽取的分析与研究[J].信息化纵横, 2008, 672(12):20-21.
[12]林科锵.Web页中表格结构识别的研究与实现[D].成都:电子科技大学, 2006.
[13]PIRRONE R, CARERI G, FABIANO F S.Real-time low level feature extraction for on-board robot vision systems[C]//Computer Architecture for Machine Perception, 2005, Palermo, Italy, IEEE Press:99-104.
[14]POL K, PATL N A ,PATANKAR S, et al.Survey on Web contentmining and extraction of structured and semistructured data, emerging trends in engineering and technology[C]//ICETET '08, 2008, Ghrce Nagpur, India, IEEE Press:543–546.
[15]JIANG W R, YAN J H.Implementation of static web-pages generator using JavaScript [J].Applied Mechanics and Materials, 2010, 39(11):588-591.
[16]JIANG W R, CHEN J, PAN H L.Develop the e-commerce website rapidly based on open-source system zen cart[C]//The 15th Conference on the Wireless across the Taiwan Straits (WRTS-2010), Kunming, China, Scientific Research Publishing, Inc, 2010(9):285-289.
[17]JIANG W R, WANG A B, WU C H, et al.Approach for name ambiguity problem using a multiple-layer clustering[C]//The 2009 IEEE International Conference on Social Computing (SocialCom-09), Vancouver, Canada, IEEE Press, 2009(8):874-878.
[18]梁海燕, 赵嵩正.基于JSP技术工程项目甘特图的设计与实现[J].计算机应用与软件, 2006, (8):43-44,59.
[19]王睿, 张能立, 万歆.一种基于JFreeChart的Web统计图表[J].微机发展,2005, (3):117-120.
