声传感网中的语义增强型信息融合方法
2011-03-26郭宝峰林岳松彭冬亮
郭宝峰,林岳松,彭冬亮
(杭州电子科技大学自动化学院信息与控制研究所,浙江杭州310018)
0 引言
声传感器网络通过拾音器或换能器阵列收集在一定区域内环境中产生的各种声信号,并应用信号处理技术来感知、分析目标在一定频率范围内的振动信息。声传感器网络具有设备相对廉价、性能稳定、易于构建、适应恶劣工作环境等特点,可以应用在很多领域。例如针对车辆行驶时的声音信号特征,可以将拾音器阵列布置在城市道路旁,获取车流量、车流速度等重要的交通流参数,从而实施对车辆的自动检测和智能交通监控等任务。在声传感器网络中,一般都是将拾音器或换能器等以阵列形式部署,以便满足空域滤波及目标定位、跟踪等要求。这种典型的多传感器配置方式自然而然地会产生对信息融合的需求[1]。传统语义分析和本体工程主要应用于自然语言理解、情报文献检索、互联网信息处理等领域。自2000年以来,国外深入开展了语义网技术[2、3]和本体工程[4]研究。国内也进行了面向互联网的语义Web研究[5]和相关本体学习研究[6]。本文通过开展面向声信息融合的语义分析和本体建模研究,来提高声传感器融合系统在目标识别和跟踪方面的准确性。由于在语义分析过程中,领域专家的知识可以得到有效、充分地表述,因而通过语义增强的信息融合将具有包含领域知识的功能,并且自然而然地沟通了信息在信号、数据层次上的表示以及信息在知识层次上的描述,可进一步增强融合系统的性能。
1 语义增强型信息融合方案
从实际应用和工程角度来看,在采用语义分析技术的过程中,常常会遇到以下几个困难:(1)语义概念的数量以及语义概念之间关系类型的数目难以确定。有时这些数目会很大,甚至达到无法处理的程度;(2)在定义语义概念和实现本体时,存在着可操作性较差、主观性偏大等问题;(3)对语义概念的完整性和本体设计的合理性缺乏客观和定量的检测、校验手段。本研究采取了以下思路和方法来克服或减轻语义分析技术应用中的上述困难。首先在语义分析过程中,采用最少设计原则:即以声传感器网络应用为背景,在合适的抽象层次上,归纳出一组最简单、最相关的信号数据语义概念,以减轻复杂度,即(1)中所提到的困难。其次,除了仍由领域专家来归纳语义概念和描述本体之外,采用机器学习算法来确定语义概念的具体属性、实现一个由数据驱动的本体,以减少语义分析中的主观性,缓解(2)中所提到的问题。最后,针对于问题(3),利用道路车辆声信号,对所提出的语义增强型信息融合方法进行了定量分析和校验。虽然本研究是以特定应用为背景,但其方法、思路、程序和工具仍都会具有一定的典型性,可以被推广或借鉴到其他信息融合应用中。
本文提出的针对陆地车辆声信号处理的语义增强型信息融合总体框架,如图1所示:
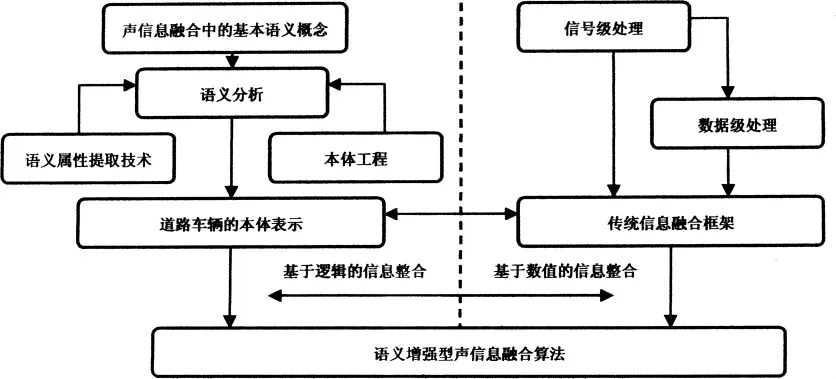
图1 语义增强型信息融合框架
在图1中的语义增强型声信息融合算法中,具体考虑了两种实现方式:(1)将语义属性看作一般的特征集,构建出待分类目标本体,然后将其应用于基于车辆声信号的特征级数据融合中,以改善车辆目标识别的准确性;(2)将语义属性看作一个特殊信息集,然后用以调整传统信息融合算法中的参数或者模型。针对实现方式2,本文提出了一个具体实现,即利用语义概念对决策级融合进行仲裁的方法。
2 语义仲裁决策级融合方法
在决策级信息融合中利用语义概念的一个实现方案如图2所示。
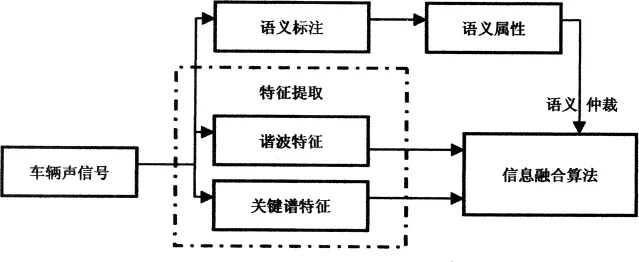
图2 语义仲裁信息融合方案
在图2所示的方案中,从车辆声信号中要提取出两组特征,分别是谐波特征X1和关键谱特征X2。在每一种特征的基础上,利用模式识别算法对数据进行一次初分类。这样就会得到两组中间决策,然后可以利用传统的Bayes决策级融合算法将所获的两组中间决策组合起来,得到一个最终融合结果。针对两组数据,一个典型的Bayes求和融合规则如下所示:
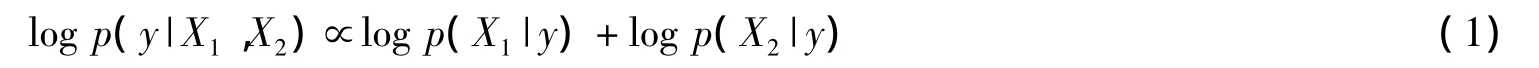
式中,X1和X2是两个特征集,y为代表目标类别的随机变量,p(y)为概率密度函数。在声信号模式识别中,由于谐波特征X1和关键谱特征X2所起的作用并不是一样的,所以往往会采用加权求和融合规则,即:
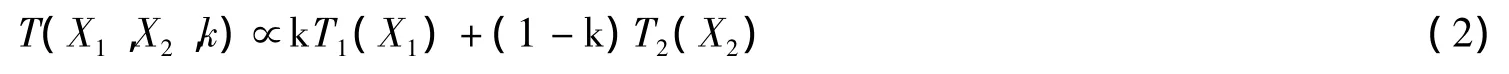
式中,k代表一个融合权系数,0<k<1`,T(.)代表模式分类函数。如果能够将语义属性和融合权系数联系起来,即可将高层次语义信息嵌入到上述的决策级融合之中。可以看到,这种语义特征嵌入是对融合规则起隐性作用,也就是用于调整求和融合规则中的权系数,所以称之为语义仲裁型信息融合。一种将语义属性影射为融合权系数的方法详述如下。
在所讨论的利用声传感器组网探测车辆的应用中,典型的语义属性可以有:车辆类型(小轿车、卡车、拖拉机等),车辆尺寸,发动机类型(汽油机、柴油机)。如何获取这些语义属性是正在研究的一个课题。其中的一个途径是应用有监督学习算法,即从已知样本中发掘出可利用的语义属性来,这也是本文采用的方法。对描述车辆驱动的具体语义s,即轮式/履带特征,给定一个二元分类器g,用于学习此语义属性:

用Length(X)表示特征X的维数。可以利用式3检测出的语义属性来控制式2中描述的两信息源加权求和融合规则中的融合比例k。具体过程如下:
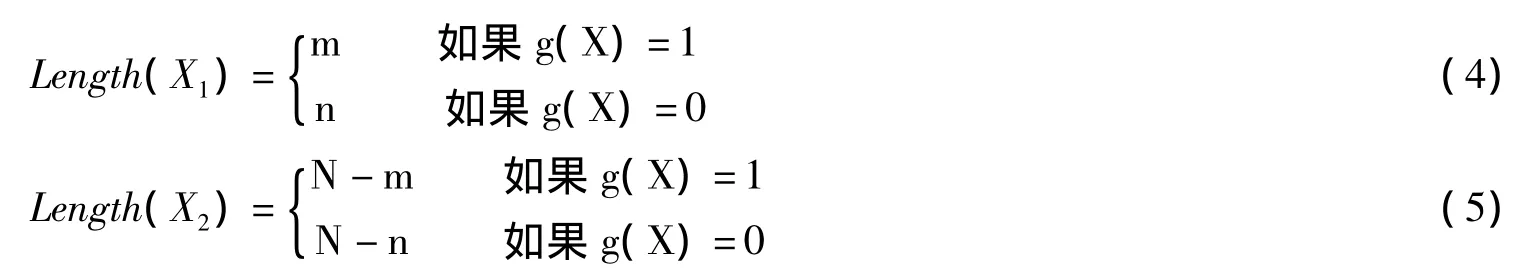
式中,N代表一个固定的特征总维数。式3-5实际上是利用一个语义属性来调整、控制两个信息源的维数。改变信息源维数会起到类似改变信息源权重的效果。因此,根据语义属性的不同实现了不同的加权效果。
3 实验仿真
在一个车辆声数据库中测试了算法。该声数据库记录了5种车辆运行时发出的声信号。5辆车包含2辆履带车和3辆轮式车。在一个操场上布置好声传感器后,然后5辆车分别在操场上绕行,它们发出的声音被声传感器记录存储。以1号麦克风为例,所采集的信号如图3所示。

图3 车辆声信号
本文使用了两种有监督分类器作为语义属性提取算法,分别是支持向量机和多变量高斯分类器。其中支持向量机提取语义属性效果较好,语义属性分类错误较低,称之为‘强’分类器;多变量高斯分类器提取的效果较差,语义属性分类错误较高,相应地称为‘弱’分类器。利用支持向量机和多变量高斯分类器提取语义信息,学习后得到的结果为:当信号来自于轮式车时,谐波特征维数为m=21;当信号来自于履带车时,谐波特征维数为n=17,即完成了式3、4。本文测试了提出的语义仲裁型信息融合方法,并与其它方法做了比较,结果如表1所示。

表1 针对5类车辆、2特征源信息融合分类结果(%)
表1中第一列为直接利用语义属性进行融合所获的结果,即将提取出的语义属性看作一种普通二元特征,然后把它加入到已有的谐波特征集中进行特征层次信息融合。第二列是使用基于本体的融合方法所获结果,相当于先利用‘强’、‘弱’分类器对信号进行一次预分类,将所有车辆分成轮式和履带两类,然后再进一步细分,把每一轮式子类和履带子类车分开。由于‘弱’分类器提取语义属性准确性较低,所以其结果要低于使用‘强’分类器(79.1%<84.5%)。第三列是语义仲裁型融合方法的结果,高于直接融合的结果,但略低于基于本体融合方法中的最佳结果。需要注意的是:虽然在‘强’分类器条件下,基于本体的融合方法获得了最佳结果,但其在‘弱’分类器条件下的结果却是最差,说明预分类的误差会传导到下一层中的细分类中。而语义仲裁型融合方法在‘强’、‘弱’分类器下的性能都近似,表明其间接利用语义属性的方式会带来性能稳定的优点。
4 结束语
语义分析技术是基于逻辑和符号体系的,而传统的信息融合主要倾向于利用概率和数值表述;两者在分析模式上有互补关系。通过语义增强的信息融合方法可以综合利用两种分析模式的优势。本文在对声传感器车辆监测进行语义分析的基础上,为车辆声信息融合提供一个新思路和实现方法。在加权求和融合规则中,通过调整不同特征集的维数,实现了不同的加权效果。通过对5辆车运行声信号进行采集,完成了对所提算法的仿真验证。结果表明语义增强型信息融合方法可以在一定程度上改进对声识别车辆的准确性。然而目前本方法对识别率的改善程度还不够显著,将研究如何更大程度地提高识别准确性。
[1]杨万海.多传感器数据融合及其应用[M].西安:西安电子科技大学出版社,2004:1-50.
[2]Berners-Lee T,Hendler J,Lassila O.The Semantic Web[J].Scientific American,2001,(5):35-43.
[3]Shadbolt N,Hall W,Berners-Lee T.The Semantic Web Revisited[J].IEEE Intelligent Systems,2006,21(3):96-101.
[4]陆建江,张亚非,苗壮.语义网原理与技术[M].北京:科学出版社,2007:23-55.
[5]Uschold M,Gruninger M.Ontologies:principles,methods,and applications[J].Knowledge Engineering Review,1996,11(2):93-155.
[6]杜小勇,李曼,王珊.本体学习研究综述[J].软件学报,2006,17(9):1 837-1 847.
