非线性/非高斯序贯贝叶斯滤波
2011-03-26刘凤霞宫先仪
刘凤霞,宫先仪
(1.浙江大学信息与电子工程系,浙江杭州310027;2.杭州应用声学研究所,浙江杭州310012)
0 引言
很多科学和工程问题涉及的为动态系统,系统状态是随时间变化的。对于动态系统做分析,需要利用状态—空间模型对系统进行表征[1]。在很多应用中,为了精确地建模动态系统,需要采用非线性/非高斯状态—空间模型。序贯贝叶斯滤波为Bayesian滤波的递归实现,它对数据进行序贯处理,而不是批处理,即随着新数据的到来更新前面的滤波结果便可获得当前时刻状态的估计,不需要重新处理前面时刻的数据,为系统状态的在线跟踪提供了一个合理的框架。在线性高斯状态—空间模型下,最佳序贯贝叶斯滤波为卡尔曼滤波,在非线性/非高斯状态—空间模型下,最佳序贯贝叶斯滤波不存在通用的解析解,只能采用近似理论,基于卡尔曼滤波的方法和质点滤波方法,是两类比较常用的近似方法。扩展卡尔曼滤波、Unscented卡尔曼滤波等基于卡尔曼滤波的方法用高斯分布来近似后验密度;序贯重要性采样、序贯重要性重采样等质点滤波方法通过一系列的随机采样点和相应的权值来表征后验密度。基于卡尔曼滤波的方法和质点滤波方法各有各的优势,是相互补充的。本文采用扩展卡尔曼和序贯重要性重采样对两个非线性/非高斯系统的状态进行跟踪,来说明扩展卡尔曼和序贯重要性重采样的特点和适用范围。
1 序贯贝叶斯滤波
状态方程(状态过程演化):

测量方程(观察过程演化):

序贯贝叶斯滤波是基于状态—空间模型的,状态—空间模型包括两个方程:状态方程和测量方程,状态方程表征系统状态随时间的演化关系,测量方程表征测量数据和系统状态的关系。基于状态方程和测量方程可以递归得到滤波后验密度。在线性高斯状态—空间模型下,卡尔曼滤波为最佳序贯贝叶斯滤波,由于它的高斯特性,递归过程只需传递均值和协方差,容易实现。但是线性高斯假设约束性太强,很多实际应用中状态—空间模型为非线性/非高斯的。在非线性/非高斯状态空间模型下,最佳序贯贝叶斯滤波不存在解析解,只能采用近似理论,基于卡尔曼滤波的方法和质点滤波方法,是两类主要的近似方法。
1.1 基于卡尔曼滤波的方法
基于卡尔曼滤波的方法,后验密度采用高斯近似,序贯滤波过程只需递归传递均值和协方差,计算量低,但是这种高斯化在后验密度非高斯化比较严重时不能很好地描述后验密度(如多模或重拖尾)。

扩展卡尔曼将状态方程和测量方程通过一阶泰勒展开进行局部线性化,假定先验分布、过程噪声和测量噪声为高斯分布,后验密度便近似为高斯分布。扩展卡尔曼不具有最佳性,它的性能取决于线性化的精度。UKF利用UT变换来进行均值和协方差的传递。在UT变换中,精心挑选的一些加权sigma点代表状态变量经过非线性变换得到下一时刻的sigma点,用sigma点来捕捉状态变量的均值和协方差[2]。
1.2 质点滤波
质点滤波方法通过一系列的随机采样点和相应的权值离散加权表示后验密度,基于这些采样点和相应的权值进行状态的估计。随着采样数目的增多,后验密度的离散加权表征等效于真实的后验密度。
序贯重要性采样算法,随着测量数据的获得,递归传播采样点和权值,得到每时刻后验密度的离散加权表示。它是质点滤波的基本形式,其余形式的质点滤波可认为是它的特例。序贯重要性采样质点滤波存在褪化问题,褪化问题是指经过许多轮的迭代后,几乎所有采样点的权值都接近于0,只有少数几个采样点的权值具有较大的值。解决这个问题有两种方法:一种是选择好的重要性密度,另一种是当褪化问题严重到一定程度时进行重采样[3]。重采样的基本思想为舍掉权值小的采样点,对权值大的采样点进行复制。在序贯重要性采样算法的更新步骤后加入重采样过程即为序贯重要性重采样算法。
2 仿真
举两个仿真的例子,来比较扩展卡尔曼算法和序贯重要性重采样算法的性能。第一个例子是单变量一阶Markov过程,第二个例子是一个实际的问题——纯方位目标跟踪。
2.1 一阶Markov过程
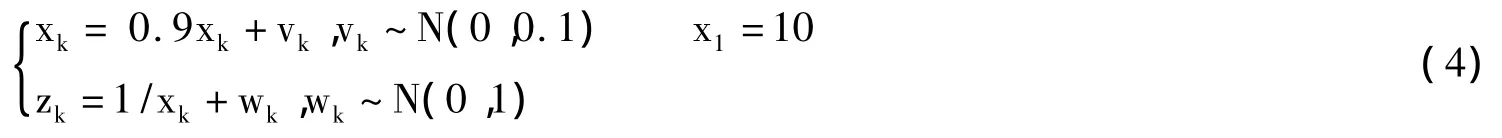
xk为系统状态,zk为测量数据。实现步数为30次,质点数目为300个,Monte Carlo仿真次数为200次。序贯重要性重采样算法对系统状态进行估计时采用MMSE准则。真实的状态值和扩展卡尔曼和序贯重要性重采样估计值如图1所示。系统状态扩展卡尔曼和序贯重要性重采样估计均方根误差(RMS)如图2所示。由仿真可以看出扩展卡尔曼和序贯重要性重采样的性能相近。
2.2 纯方位跟踪
纯方位跟踪讨论的是对目标的方位和距离的跟踪。因目标的运动具有一定的规律性,将这个规律性知识给利用上,利用方位信息便可以实现目标的纯方位跟踪。这里假设目标为恒速运动模型,状态方程对目标的运动规律进行了表征。x、y为目标的笛卡尔坐标,vx、vy为目标的速度。ak代表x和y方向的加速度,用来表征可能的速度变化。测量方程表征了测量方位和状态向量的关系,观测点固定于原点处,测量数据为目标的方位。
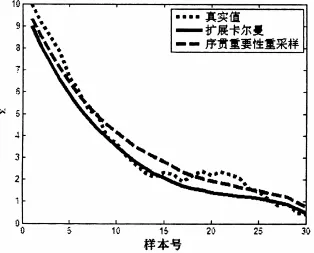
图1 状态真值和估计值
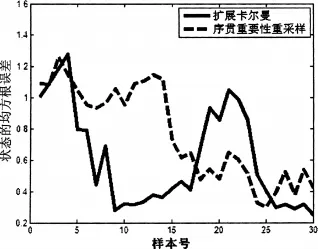
图2 状态的均方根误差
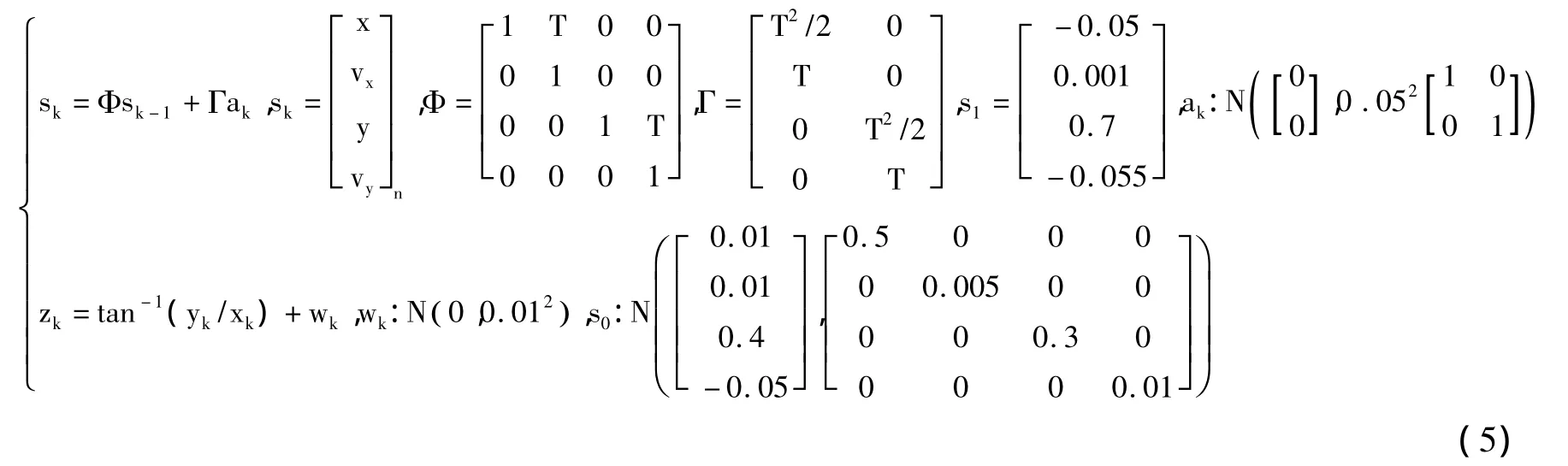
目标位置扩展卡尔曼和序贯重要性重采样估计均方根误差(RMS)如图3、4所示。目标速度扩展卡尔曼和序贯重要性重采样估计的均方根误差(RMS)如图5、6所示。由仿真结果可以看出序贯重要性重采样性能明显优于扩展卡尔曼。
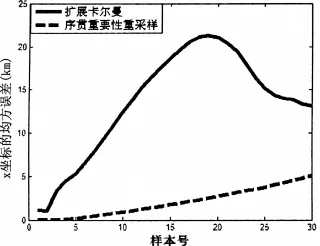
图3 x坐标的均方根误差
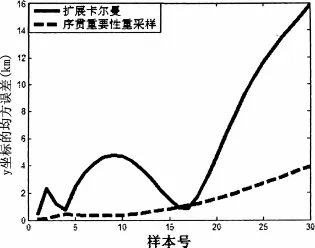
图4 y坐标的均方根误差
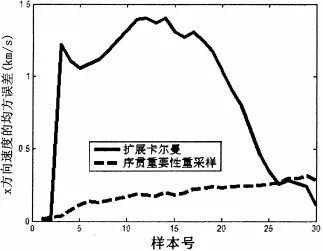
图5 vx的均方根误差

图6 vy的均方根误差
第一个仿真例子非线性/非高斯不严重,高斯分布可以较好的近似真实的后验分布,所以扩展卡尔曼和序贯重要性重采样性能相近,但是由于扩展卡尔曼计算量低,所以选择扩展卡尔曼比较合适,第二个例子非线性/非高斯情况比较严重,高斯分布不能很好的近似真实的后验分布,序贯重要性重采样性能明显优于扩展卡尔曼,采用序贯重要性重采样算法比较合适。
3 结束语
本文对非线性/非高斯序贯贝叶斯滤波理论进行了总结,主要讨论了基于卡尔曼滤波的方法和质点滤波方法。基于卡尔曼滤波的方法,后验密度采用高斯近似,计算量低,但是这种高斯化在后验密度非高斯化比较严重时不能很好地描述后验密度。质点滤波是一种宽容性的方法,一切情况的非线性/非高斯情况都可以处理,但是计算量比较大。它们各有各的优势,是相互补充的。
本文采用扩展卡尔曼和序贯重要性重采样对两个非线性/非高斯系统的状态进行跟踪,仿真表明系统非线性/非高斯不严重时采用扩展卡尔曼和序贯重要性重采样性能相近,但是扩展卡尔曼计算量低,采用扩展卡尔曼算法比较合适;非线性/非高斯较严重时采用序贯重要性重采样性能明显优于扩展卡尔曼,采用序贯重要性重采样比较合适。
[1]Gordon N J,Salmond D J,Smith A F M.Novel approach to nonlinear/non-Gaussian Bayesian state estimation[J].IEEE Proceedings-F,1993,140(2):107-113.
[2]Yardim Caglar,Michalopoulou Zoi-Heleni,Gerstoft Peter.Peer-Reviewed Technical Communication-An Overview of Sequential Bayesian Filtering in Ocean Acoustics[J].IEEE Journal of Oceanic Engneering,2011,36(1):107-113.
[3]Arulampalam M S,Maskell S,Gordon N,etal.A tutorial on particle filters for online Nonlinear/Non-Gaussian Bayesian Tracking[J].IEEE Transactions on Signal Processing,2002,50(2):174-188.
[4]Carpenter J,Clifford P,Fearnhead P.Improved particle filter for non-linear problems[J].IEEE Radar Sonar and Navigation,1999,146(1):2-7
[5]Candy Jmes V.Bootstrap particle filtering[J].IEEE Transactions on Signal Processing,2007,24(4):73-85.
