交通事故多发点(段)治理排序方法研究
2011-03-15韩凤春
刘 敏, 韩凤春
(中国人民公安大学,北京 102623)
0 引言
随着城市社会经济的快速发展,城市人口骤增,机动车拥有量也急剧增长,导致城市道路交通事故频发,严重影响了人民的生命财产安全。因此,各级政府无不把预防和减少交通事故作为重要的管理目标。道路交通管理成效最显著的是交通死亡事故的减少,而“事故多发点(段)”的消除是最有直接性和说服力的。第16届国际道路会议报告指出,事故黑点一般占路网总长的16%,事故数却占到了总数的25%[1],由此看出事故多发点(段)排查非常重要,多发点(段)治理刻不容缓。一般情况下,治理交通事故多发点(段)要投入大量资金。从理论上说,任何产生积极效果的治理措施都应实施,但是有限的资金限制了事故多发点(段)治理的数量和力度。因此对事故多发点(段)治理工作进行科学排序,制定事故多发点(段)整治计划是十分必要的。
目前国内外交通事故多发点(段)研究多侧重于事故成因分析、鉴别技术和防治措施,对事故多发点(段)治理排序方法研究较少。基于此,本文提出了交通事故多发点(段)治理排序方法,为确定事故多发点(段)治理顺序提供了理论依据。
1 交通事故多发点(段)治理排序指标分析
1.1 数据资料收集
开展交通事故多发点(段)治理排序工作,首先应综合分析交通事故信息资料,主要包括全部待治理多发点(段)的事故数据、道路信息及交通资料等。
(1)事故数据:多发点(段)处的交通事故起数,其中包括一般事故和严重事故(包括重大事故和特大事故)的起数、受伤人数、死亡人数、直接经济损失、事故发生的时间与地点、事故形态、事故类型、事故原因等。
(2)道路信息:多发点(段)所处地理位置、道路条件、环境特征等。
(3)交通资料:多发点(段)处年平均日交通量、车道分布、车速等。
1.2 指标影响因素
一般情况下,在进行交通事故多发点(段)治理排序时考虑以下因素:
(1)交通事故数量,是指事故多发点(段)发生的交通事故起数。
(2)事故严重程度[2],是指事故多发点(段)发生的交通事故中严重事故(重大事故和特大事故)占有率。
(3)事故伤亡率,是指事故多发点(段)的事故受伤人数与死亡人数之和占该多发点(段)事故总数的比例。
(4)事故多发点(段)治理效益,是指对事故多发点(段)的防治要考虑成本和效益,避免出现投入大,治理效果差的情况。本文仅从减少事故的直接经济效益这一方面考虑,治理次序的选取依据由下式确定[3]:

式中:Ni为第i处事故多发点(段)的效益成本比;Y为安全措施的组合;B(Y)为某处事故多发点(段)治理后获得的效益;C(Y)为某处事故多发点(段)的投入资金。B(Y)的计算相对比较抽象,这里只考虑减少事故数的直接经济效益。
通过计算得到Ni,对Ni值从高到低依次排序,对应事故多发点(段)序号i的先后即为多发点(段)治理顺序。
(5)交通事故多发点(段)位置重要性,是指事故多发点(段)所处位置对整个区域道路交通的影响大小。
(6)交通事故多发点(段)处的年平均日交通量,若AADT无法获取时,高峰小时交通量也可以反映出交通事故多发点(段)的交通运行状况。
(7)事故的直接经济损失,其大小也会影响多发点(段)治理顺序。
(8)方案的可操作性,针对事故多发点(段)制定的治理方案由于资金、施工难易等原因可能会导致治理方案拖延或无法实施。
1.3 指标选取原则
排序指标选取应遵循一定的原则,选择排序指标不仅要满足实际工作需要,还应具有可操作性。
(1)实用性。指标应实用性强,目的明确,能反映事故多发点(段)整治的客观实际。
(2)可测性。所选取指标,必须能够通过直接或间接方法得到量化数值,对于某些无法量化却又对排序影响较大的指标,可对其进行定性分析。
(3)独立性。指标之间要相互独立,避免指标的相互关联和重叠。
(4)系统性。所选评价指标要尽可能涵盖影响排序的所有方面,防止重要指标遗漏。
(5)代表性。为方便评价排序,所选排序指标数量不宜过多,每个指标应具有很强的代表性。
2 排序指标确定
2.1 定量指标
在对交通事故多发点(段)排序指标影响因素分析的基础上,依据排序指标对治理工作影响大小,选取以下六项指标作为定量指标。为更加客观准确地对交通事故多发点(段)治理进行排序,对排序指标无量纲化处理。量化指标如下:
(1)事故占有率

(2)重事故占有率

(3)多(段)亡率

(4)交通量占有率

(5)直接失率

(6)事故多发点(段)位置重要性,由于该指标不易通过计算进行量化,因此对多发点(段)位置重要性划分等级,并给出等级量化值,将事故多发点(段)位置重要性划分为五个等级:不重要、一般重要、比较重要、重要、特别重要。将以上五个等级分别赋予量化值,如表1所示。

表1 交通事故多发点(段)位置重要性量化值Fi
2.2 定性指标
交通事故多发点(段)治理排序不仅要进行定量分析,还要进行定性分析。有些指标无法量化,但会影响交通事故多发点(段)的治理顺序,定性指标确定如下:
(1)事故多发点(段)特征的显著性,是指对事故多发点(段)资料进行分析时,会发现某些事故多发点(段)的特征不明显,无法找到事故成因。对于这种事故成因不明的多发点(段)可暂缓治理。
(2)治理方案的可操作性。某些事故多发点(段)治理方案的实施要花费大量人力、物力和财力等,还会涉及到多部门之间的协调运作,导致治理工作难以开展。对于这种情况可以考虑推迟治理,避免出现中途停工现象。
(3)效益成本比。由于定量分析事故多发点(段)治理效益的误差很大,不便进行定量分析,以减少主观假设对客观结果的影响。在进行多发点(段)治理排序时,从定性角度来分析效益成本比。
2.3 确定排序指标
依据指标选取原则和影响因素分析,最终确定交通事故多发点(段)治理排序指标如图1所示。
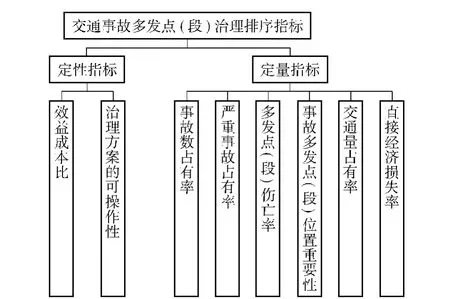
图1 交通事故多发点(段)治理排序指标
3 排序模型建立
综合考虑各个指标对事故多发点(段)治理排序影响,确保治理排序的客观性,从定量分析角度,对每个定量指标赋予一个权重系数,从而得到交通事故多发点(段)治理排序模型:
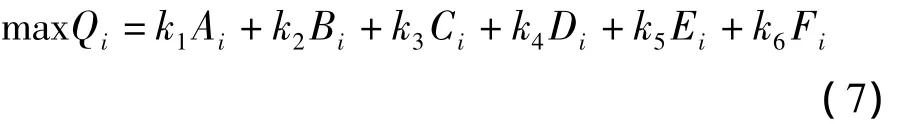
式中:Qi为第i个多发点(段)综合排序系数;Ai为第i个多发点(段)事故数占有率;Bi为第i个多发点(段)严重事故占有率;Ci为第i个多发点(段)事故伤亡率;Di为第i个多发点(段)交通量占有率;Ei为第i个多发点(段)直接经济损失率;Fi为第i个多发点(段)位置重要性(i=1,2,3,…,n);ki为每项指标的权重(i=1,2,3,4,5,6);其中权重 ki值的选取采用专家法、层次分析法等方法来确定。
4 实例
为验证排序模型的有效性及科学性,本文收集了张家口市区2007~2009年部分交通事故多发点(段)统计资料(见表2),应用事故多发点(段)治理排序模型进行分析。通过对张家口市区交通事故多发点(段)治理排序的研究,进一步验证模型的有效性。

表22007~2009年张家口市交通事故多发点(段)原始数据表
根据公式(2)~(6)及表1,对张家口市区2007~2009年交通事故多发点(段)数据进行无量纲化处理,得到数据如表3。

表3 张家口市交通事故多发点(段)无量纲化数据分析表
本文采用层次分析法[4]确定各指标的权重值。层次分析法把复杂系统的决策思维进行层次化,把决策过程中定性和定量的因素有机地结合起来。通过判断矩阵的建立、排序计算和一致性检验得到的最后结果具有说服力。首先建立多发点(段)治理排序指标的权重值体系,如图2。
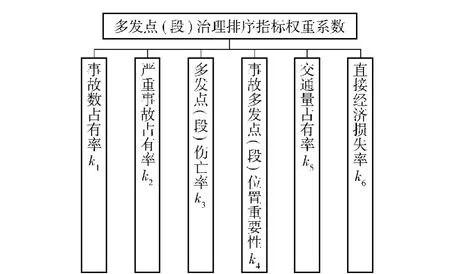
图2 多发点(段)治理排序指标的权重值体系图
其次,通过比较指标间两两重要程度,采用1~9标度法得到判断矩阵A,根据专家意见,判断矩阵如下所示。

最后计算各排序指标的权重值为:
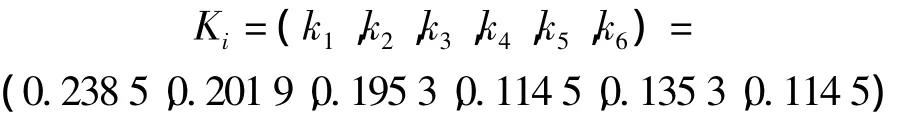
其中,最大特征根λmax=6.0737,一致性指标CI=0.0117,随机一致性指标RI=1.24,所以一致性比率为CR=0.0117/1.24=0.0094<0.1,因此通过一致性检验。
将权重值代入多发点(段)治理排序模型得:

将5个事故多发点(段)数据代入模型得:

由此确定交通事故多发点(段)的治理顺序如表4所示。

表4 交通事故多发点(段)治理顺序表
从定性角度分析,根据收集得到的交通事故资料描述,这5个事故多发点的特征都比较显著,都能清晰地找出事故成因,提出治理方案,都具有很强的可操作性。因此根据上述治理顺序,尽快开展交通事故多发点(段)治理工作。
5 结语
交通事故多发点(段)的治理工作应有条不紊地按计划分步实施,从而保证事故多发点(段)的治理效果。本文提出了事故多发点(段)治理排序模型,重点在于排序指标的选取及模型建立方法,交通事故多发点(段)治理排序应注重定量分析和定性分析的紧密结合,同时兼顾实际情况进行综合考虑。
交通事故多发点(段)治理排序方法排除了人为因素的影响,既客观又考虑了实际可操作性,使决策者更准确、更科学地对治理顺序做出判断,为有计划地开展交通事故多发点(段)治理工作提供了理论依据,具有一定现实意义。
[1]过秀成,盛玉刚.公路交通事故黑点分析技术[M].南京:东南大学出版,2009:10-13;144-145.
[2]胡江碧,费雪良,等.道路交通事故多发点统计鉴别与对策方法[J].北京工业大学学报,2007,33(5):465.
[3]盛玉刚,过秀成.公路交通事故黑点治理技术[C]∥陈洁.奥运、交通、和谐——2008第三届中国国际交通安全论坛论文集.北京:中国人民公安大学出版社,2008:258-259.
[4]朱茵,孟志勇,阚叔愚.用层次分析法计算权重[J].北方交通大学学报,1999,23(5):120 -121.
