一种新颖的基于马氏距离的文本分类方法的研究
2011-03-12张素莉
张素莉,潘 欣
(长春工程学院电气与信息工程学院,长春 130012)
0 引言
et al.,1994)、支持向量机SVM 算法[3](Joachims,1998)、遗传算法[4](Svingen,1998)、KNN 算法 、基自组织映射算法[5](Hyotyniemi,1996)、贝叶斯算法[6](Lam,1997)及其朴素贝叶斯算法(Nigam,1999)等,其中KNN(k最近邻算法)算法是最成熟最简单的分类方法之一。而KNN分类器对分类过程中所使用的距离参数十分敏感[3](Jahromia etal.,2009),这一缺点不但降低了对文本分类的精度,而且也限制了KNN分类器在文本分类中的应用。
本文提出了一种新颖的基于马氏距离的KNN文本分类方法(M ahalanobis distance KNN,MDKNN)。该分类器不需使用距离函数的参数K,而是通过整个训练集的分布情况来决定分类的种类。实验表明,与传统的KNN 和Naïve Bayes分类算法相比,MDKNN在文本分类的精度和稳定性上有所提高。
1 马氏距离及其分类算法
文本数据挖掘可以广义地定义为一个知识密集的过程,即用户通过使用一套分析工具与文档交互[1](Ronen and James,2007)。文本分类(TC)是文本数据挖掘研究中最常见的研究问题之一。如何从信息源中提取具有准确性和时效性的文本分类知识有赖于分类技术的使用,因此,如何提高文本分类的精度是当前文本数据挖掘研究的热点问题之一。
目前,常用的文本分类技术主要有:基于神经网络(NN)的文本分类算法[2](Liet al.,1991;Farkas
1.1 马氏距离
M ahalanobis距离(马氏距离)是由印度统计学家马哈拉诺比斯[7](P.C.Mahalanobis)于1936年提出的,表示数据的协方差距离。它是一种有效的计算2个未知样本集的相似度的方法。与欧式距离不同的是它考虑到各种特性之间的联系,并且是尺度无关的,即独立于测量尺度。如果列向量 x=(x1,x2,…,xN)T的每一项均是随机变量,且均是有限方差,则协方差矩阵S的每一项(i,j)都是协方差向量,可以用式(1)来表示:
Sij=cov(Xi,Xj)=E[(Xi-μi)(X j-μj)](1)
其中用μi=E(Xi)表示每一个向量X的期望值,则我们可以用式(2)表示协方差矩阵S:
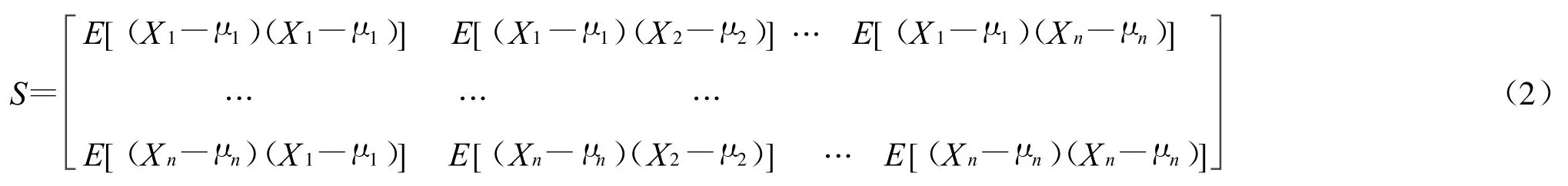
因此,多变量向量x=(x1,x2,…,xN)T的马氏距离可以通过一组均值数据 μ=(μ1,μ2,…,μN)T和协方差矩阵S表示,如式(3)所示:

我们可以使用式(3)来分析简单情况下的马氏距离,并将其与欧氏距离进行对比。马氏距离充分考虑了N维欧式空间的测试点属于该集合的可能性问题,在这里我们给出了一些明确属于马氏距离集合的样本,其中离大多数样本中心越近的点,属于这个集合的可能性越大。可以通过一组二维数据X(在图中标记为圆圈)来比较马氏距离和欧式距离,共有100个的样本训练集,其均值为 μ=[0;0],并且θ=[1 0.9;0.9 1];,有4个样本数据Y(用星号标记),分别是[1 1;1-1;-1 1;-1-1]。
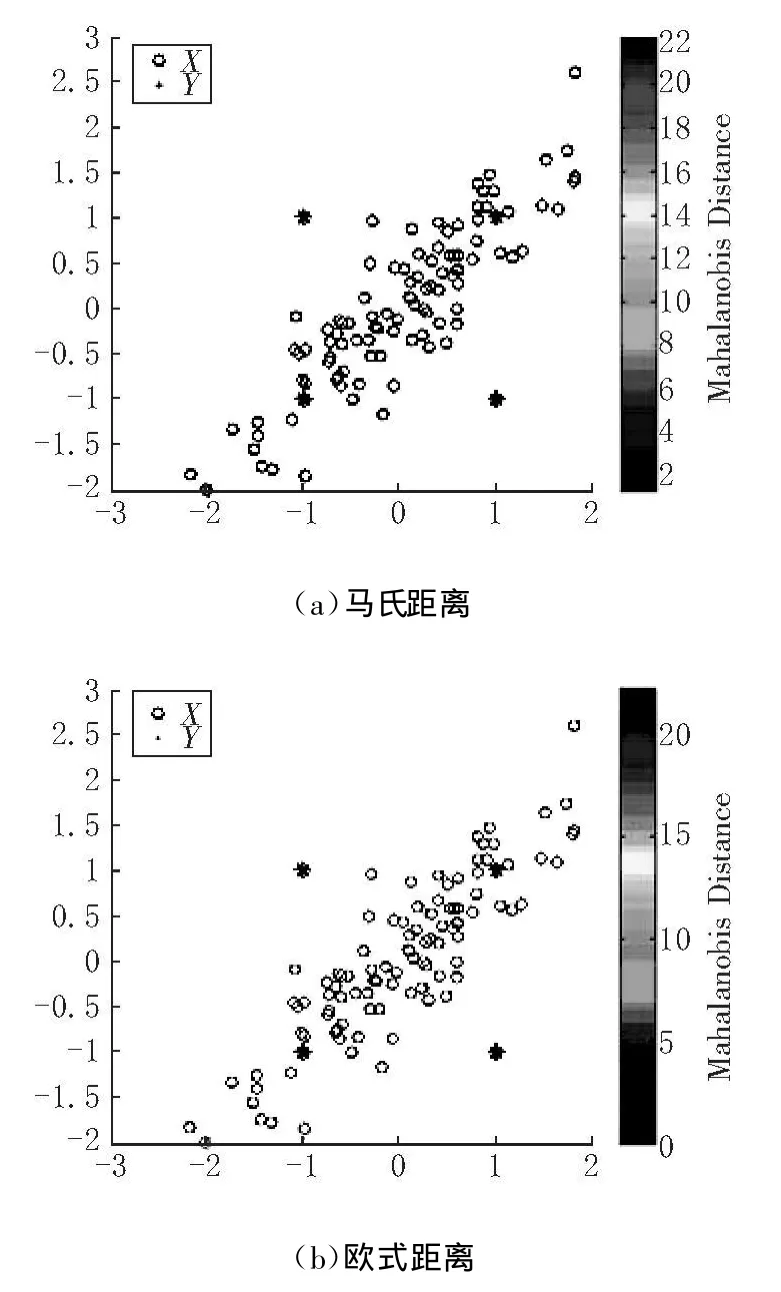
图1 训练集Y和X
从图1中,我们可以看出,Y 1和Y 3在 X样本集附近,而Y 2和Y 4点远离X样本集。欧式距离仅仅能够比较2个样本的距离,即能得到X的均值是[0;0]和Y与X的均值是D=sqrt(2),不能展示Y和X之间的关系。当我们使用马氏距离的时候,它不仅能够描述一个样本和所有样本X之间的距离D=[1.34;17.22;18.66;1.05],也能通过马氏距离真正地反应Y和X之间的关系。
1.2 分类算法
根据式(2)和式(3),我们构建了基于KNN分类器的马氏距离(MDKNN),该算法的训练和分类过程如下:
(1)训练阶段:
输入:多维向量的训练集合 T=(X1,X2,…,XN),训练集合中的每一个XN一定属于某一个分类集,其中N表示分类号。
根据式(2)可以计算出每一个分类的协方差矩阵S=(S1,S2,…,SN)。其中 SN对应第N个分类。
输出:每一个分类的协方差矩阵。
(2)分类阶段:
输入:多维向量Y;
a.根据式(3)和训练阶段得到的协方差矩阵,计算每一个分类和Y的马氏距离;
b.找到离Y最近的最小距离;
输出:决定具有最小马氏距离的分类。
根据这个算法,分类器不需要提前计算参数K,就可以根据分散的训练样本集计算出样本的种类。
2 文本表示
文本表示是文档分析和处理中的关键问题。文本表示也是文本分类、信息过滤、信息检索、知识发现等领域的基础。对于中文语料集中的文本,计算机不能够直接进行处理,因此在进行中文文本分类
之前,必须要对中文语料集中的文本进行一些处理。采取合理的方式将中文文本转化成计算机能够处理的形式,这个过程就是文本表示。因此,作为文本分类的一个预处理步骤,文档可以用特征向量来表示。Combarro在2005年指出,特征加权方法 TF-IDF方法在绝大多数情况下都是最有效最简单的文本特征化的方法。
TFI-DF方法是通过特征词的词频(TF)和反文档频率(IDF)来计算特征词的权重。特征词频率TF(t,d)表示特征词t在文档d中出现的频率(出现的次数)。文档频率DF(t)是在所有文本中特征词t出现的频率,反文档频率IDF(t)可以通过如下的公式计算:
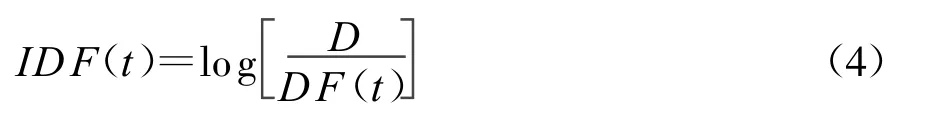
式中:D——文档的个数;
IDF(t)——特征词 t在整个文档中的离散度。
在文档的d中特征词t的权重可以通过如下的式(5)计算:
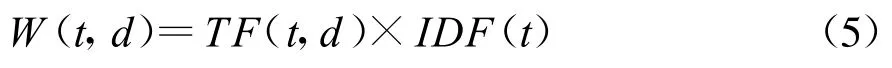
在上述公式中,W(t,d)的值越大,表示特征词t在文档d中出现的频率越高。
3 文本分类的处理步骤
文本分类的处理步骤可以如图2所示:
图2 获得分类模型的过程
首先,从训练样本集中去除所有的停词,利用TF-IDF方法的式(4)和式(5)构建权重表;然后,将所有文档向量化;训练分类器并获得分类模型。用该模型可以表示文本向量的分类。
4 实验和结论
本研究选取Internet网上的热点新闻作为分类目标,其基本分类类别包括:IT、健康、运动、教育和军事。本次实验共获取1 000个文本样本,其中的500个样本作为训练集,剩余的500个作为测试集。为更好地验证分类算法和样本数量之间的关系,将500个训练样本集进一步细分为100,150,200,250,300,350,400,450,500,样本数量是随机的。我们将MDKNN算法与传统KNN分类器(N=5 to 20,并且选择最佳的N作为分类精度)及其Naïve Bayes分类器进行比较。3种分类算法的分类精度比较如下图3所示:
从图3中可以看出,在文本数量较多的情况下,MDKNN分类器获得了比 KNN分类器和Naïve Bayes分类器更高的分类景区。在样本数 350到500之间,MDKNN分类器达到了分类精度的90%,远高于其他两类分类器。Naïve Bayes分类器随着样本数的持续增加呈现了不稳定性;KNN分类器必须选择最佳的 N进行测试和改错。由此可见,MDKNN分类器在文本分类中具有较好的稳定性和较高的分类精度。
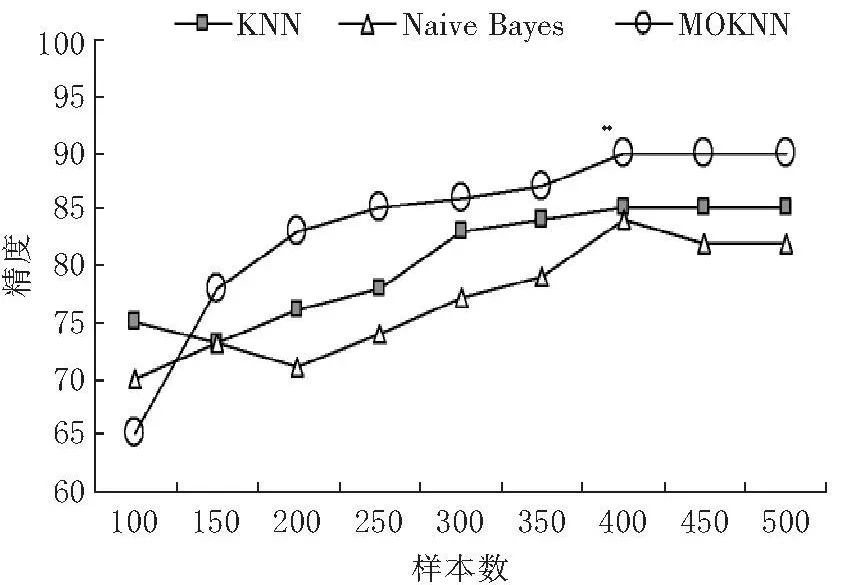
图3 3种分类算法的分类精度比较
[1]Ronen Feldman,James Sanger.THE TEXT M INING HANDBOOK:Advanced Approaches in Analyzing Unstructured Data[M].CAMBRIDGE:CAMBRIDGE UN IVERSITY PRESS,2007:401-402.
[2]LiW ei,Lee Bob,K rausz,etc.Text Classification by a Neural Netw ork[A].Dale P.Proceedings of the 1991 Summer Computer Simulation Con ference[C].Tw enty-Third Annual Summer Computer Simulation Conference,1991:313-318.
[3]Joachim s,Thorsten.Tex t Categorization with Support Vector M achines:Learning w ith Many Relevant Features[A].Claire N,Celine R.Machine Learning:ECM L-98.10th European Conference on Machine Learning[C].California:Springer,1998:137.
[4]Svingen,B.Using genetic programm ing for document classification[A].Diane JC.FLAIRS-98.Proceedings o f the Eleventh International Florida A rtificial Intelligence Research[C].Florida:AAA IPress,1998:63-67.[5]Hyotyniemi,H.Text document classification with self-organizingmaps[A].JarmoA,Timo H,Matti J.STeP'96-Genes,Nets and Symbols.Finnish A rtificial Intelligence Con ference[C].Vaasa:Finnish A rtificial Inteel-igence society,1996:64-72.
[6]N igam K,Maccallum,A K,etc.Text Classification from Labeled and Unlabeled Documents using EM[A].To appear in the Machine Learning Journal[C].Boston:K luwer A cadem ic Publishers,1999:1-34.
[7]M ahalanobis,PC.On the generalised distance in statistics[J].Proceedings of the National Institute of Sciences of India,1936,12(1):49-55.
