基于云自适应遗传算法的改进BP算法
2011-02-03吴立锋程林辉
吴立锋,程林辉
(中南民族大学计算机科学学院,武汉430074)
BP算法(Back Propogation Algorithm)是目前应用最为广泛的神经网络学习算法,BP神经网络已成功的应用在人脸识别[1]、故障诊断[2]、入侵检测[3]和最优预测[4]等方面.但由于BP算法采用沿梯度下降的搜索算法,因而其结果对初始权值非常敏感,不同的初始权值可能导致不同的结果以及易陷入局部极小、收敛速度慢等.遗传算法采用群体进化方式,对目标函数空间进行多线索的并进式检查,并保留有竞争力的基因,是一种搜索范围广、搜索效率高、鲁棒性强的优化方法.因此,利用遗传算法优化神经网络成了目前研究的热点[5,6].
本文结合遗传算法以及正态云模型云滴的随机性和稳定倾向性特点[7],提出了云自适应遗传BP算法(CAG-BP).该算法首次将云模型和遗传算法结合起来调整神经网络的权值以及阈值,遗传算法中的改进交叉概率和变异概率由X条件云发生器产生.改进后能够使群体中平均适应度值的个体的交叉率和变异率不为零,并能使适度值小的个体有较大的交叉概率和变异概率,适度值大的个体交叉概率和变异概率则相对较小,从而加快收敛速度,不易陷入局部极小,得到正确的结果.
1 云模型
云模型是定性定量间的不确定性转移模型,它用期望值Ex、熵En和超熵He表征定性概念,将概念的模糊性和随机性集成在一起,为定性与定量相结合的信息处理提供了有力手段.期望值Ex反应了云层的重心位置;熵En反应了云层的陡峭程度,En越小越陡峭;超熵He反应了云层的厚度,He越大云层越厚,正态云模型的3个数字特征示意图如图1所示.图1表示当x=Ex时其确定度为1,当x>Ex时,确定度随着x的增大而减小.要使遗传算法的收敛速度加快,不易陷入局部极小,得到正确的结果,必须使适度值小的个体有较大的交叉概率和变异概率,适度值大的个体有相对较小的交叉概率和变异概率.从图1可以看出当x>Ex时云模型具有这一特点,可以将x作为遗传算法中两交叉个体的最大适应度以及变异个体的适应度,确定度作为交叉概率和变异概率,并且云模型中云滴集中在区间[Ex-3En,Ex+3En],云层厚度为He,具有很好的随机性和稳定倾向性.
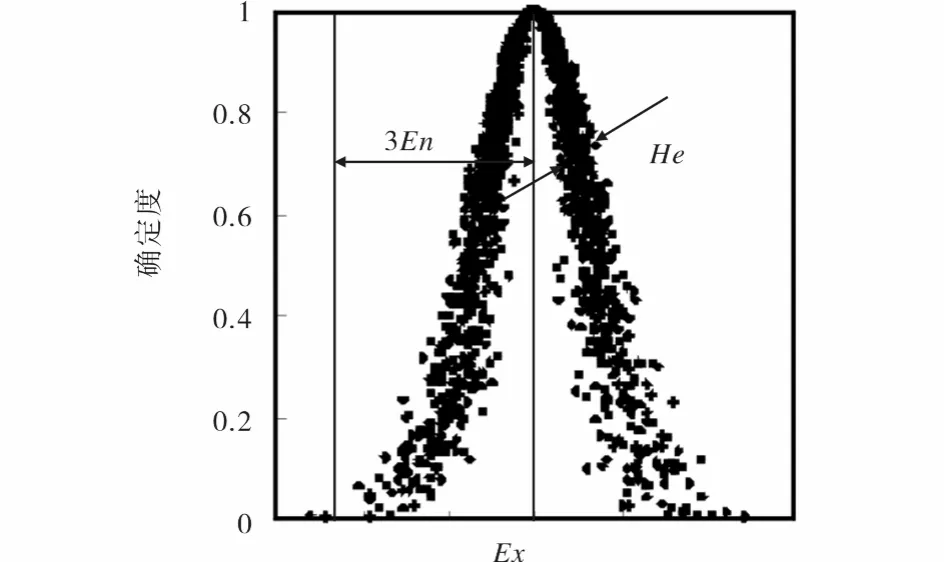
图1 正态云模型的3个数字特征示意图Fig.1 Diagram of three digital characteristics about normal cloud model
2 改进BP算法原理
2.1 标准BP算法
1985年Rumlhart等人提出的BP算法是目前神经网络学习算法中使用最为普遍的算法,其主要思想是利用已知确定的样本模式对网络进行训练,BP网络的训练过程就是修正各层神经元之间的连接权的系数过程.BP算法的学习过程由正向传播和反向传播组成,在正向传播过程中,输入信息要先从输入层结点传播到隐含层结点,经过作用函数后,再把隐含层结点的输出信息传播到输出层结点,最后给出输出结果.如果在输出层得不到期望输出,则转向反向传播,将误差信号沿原来的连接通路返回,通过修改各层神经单元的权系数和阈值,使误差信号最小.
2.2 云自适应遗传BP算法
标准BP算法将学习过程分为正向传播和反向传播两个阶段,正向传播得到实际输出结果,反向传播用来修改权值和阈值.云自适应遗传BP算法首先利用标准BP算法试探出最好的隐层结点数以及正向传播得到的实际输出结果,然后利用CAG-BP算法在整体寻优的特点调整网络的权值以及阈值.
2.2.1 编码
采用实数编码,对于包含一层隐藏层模式为m-n-l多层神经网络共有q=m·n+n·l+n+l个权值和阈值需要优化,其中m为输入层结点数,n为隐藏层结点数,l为输出层结点数.将这q个权值和阈值记为W=(W1,W2,…,Wq),采用实数编码,将行向量W看作是一条染色体,而其中每个实数Wi(i=1,2,…,q)是染色体的一个基因位.
2.2.2 选择
采用轮盘赌和精英保留选择策略.每个染色体产生后代的数目正比于它的适应度的值的大小,并且每一代中染色体的总数保持不变,这种方法也称为轮盘赌选择.假设群体的大小为n,个体Ai的适应度值为f(Ai),则个体Ai被选择的概率P(Ai)为:显然适应度值高的个体被选中的概率越大,而且可能被选中;而适应度低的个体则很有可能被淘汰.
2.2.3 交叉
随机产生二串长度为q的二进制串,设有2个父代,P=(P1,P2,…,Pq) 以及M=(M1,M2,…,Mq),采用下面的方式得到两个子代:C=(C1,C2,…,Cq) 和D=(D1,D2,…,Dq),用其中的一个二进制串产生子代C,用另一个二进制串产生子代D.具体方法如下:如果对应二进制位为1,则Ci为Pi,对应二进制位为0,则Ci为Mi;如果对应二进制位为1,则Di为Mi,对应二进制位为 0,则Di为Pi.
改进交叉概率pc如公式(1)所示,从公式(1)可以看出当两交叉个体的最大适应度与群体平均适应度相等时,其交叉概率不为零;并且当两交叉个体的最大适应度大于群体平均适应度时,适应度越大交叉概率越小.
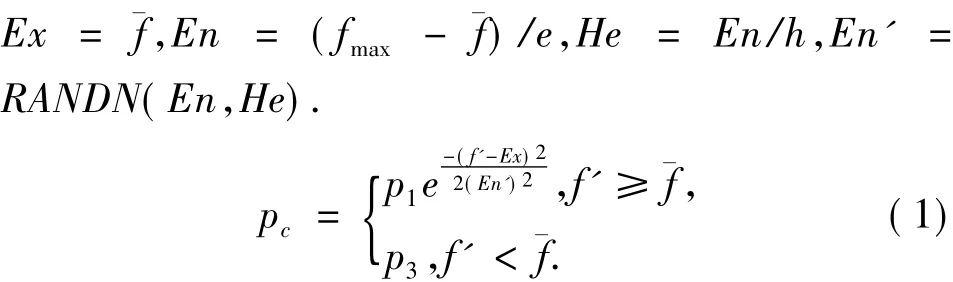
2.2.4 变异
变异采用非一致性变异算子[8],设父代W=(W1,W2,…,Wq),Wi被选出来作变异,若权值的变化范围是(LW,HW),则变异结果为:W'=W1,W2,…,W'i,…,Wq,其中t是 群体演化的代数,是
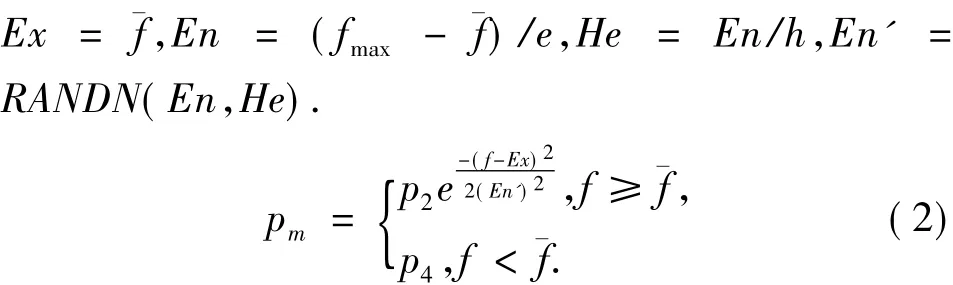
交叉概率和变异概率中的¯f为群体的平均适应度,fmax为群体的最大适应度,f为变异个体的适应度,f'为两交叉个体中的最大适应度值,e、h和pi(i=1,2,3,4)为控制参数,e用来控制云的陡峭程度,根据“3En”规则,一般取3,h用来控制云层的厚度,一般取10;pi可取0.9~1之间的常数,实验过程中根据具体情况调节参数的值.
2.2.5 适应度函数
遗传算法搜索目标是所有进化代中使网络均方差最小的网络权重,而遗传算法只能朝着使适应度函数值增大的方向进化.所以,可以根据产生的权值和阈值所对应的神经网络计算出BP网络的均方差,适应度函数采用均方差的倒数,即:
2.2.6 算法步骤
CAG-BP算法具体过程如下:首先初始化CAGBP算法中各个参数的值,然后随机产生一群染色体(个体),进行实数编码;接着依次输入训练样本,计算适应度值,当某代的最优个体的适度值大于或等于预先给定的值,或者算法给定的迭代次数已用完,算法结束;否则按照以上2.2.2至2.2.4中提到的方法进行选择、交叉和变异,更新种群,直至算法结束.
3 实验结果
采用文献[9]中提供的实验数据,将4位自然二进制码转化为四位格雷码,加上噪音位共有32组数据,32组数据如表1所示,用其中的28组数据进行训练,剩余的4组数据用来测试.根据表1确定输入层结点数为5,输出层结点数为4,隐层单元数人工调节,对隐藏层结点数为2~10的情况进行了实验,其中隐藏层结点数为8时获得最好的效果.输入数据中的第1位为噪音位,与输出没有关系,输出只与输入的后4位有关.分别采用标准的BP算法和CAG-BP算法进行训练,均方差MSE(Mean Square Error)设为10-4,经过训练92次,CAG-BP算法收敛并且其MSE=0.000088,而标准的BP算法最好情况下则需要3437次,2种算法的迭代次数与MSE之间的曲线对比如图2所示,很明显CAG-BP算法在收敛速度上要远远优于标准的BP算法.训练结束后,用剩余的4组数据进行测试,CAG-BP算法的测试结果如表2,显然,测试结果正确.一个在范围(0,η)内取值的函数,T是演化的最大代数,b是系统参数,一般取2.
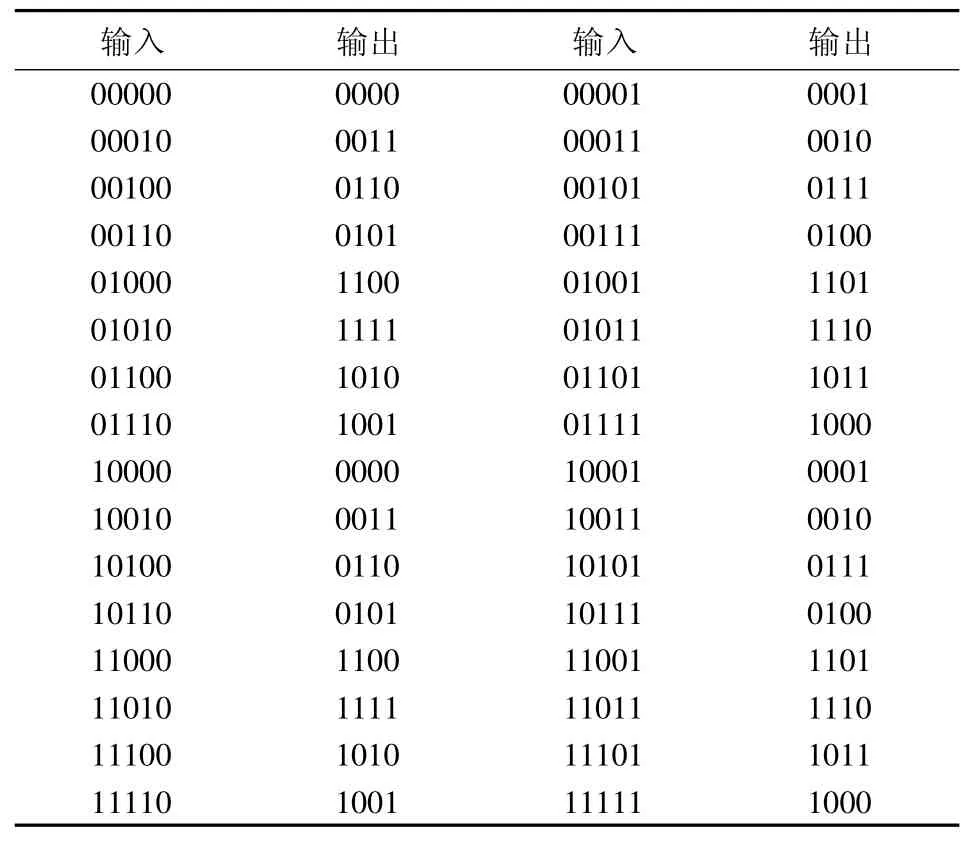
表1 自然二进制与格雷码对照表Tab.1 Comparison table about natural binary and gray code
改进变异概率pm如公式(2)所示,从公式(2)可以看出当变异个体的最大适应度与群体平均适应度相等时,其变异概率不为零,并且当变异个体的最大适应度大于群体平均适应度时,适应度越大变异概率越小.
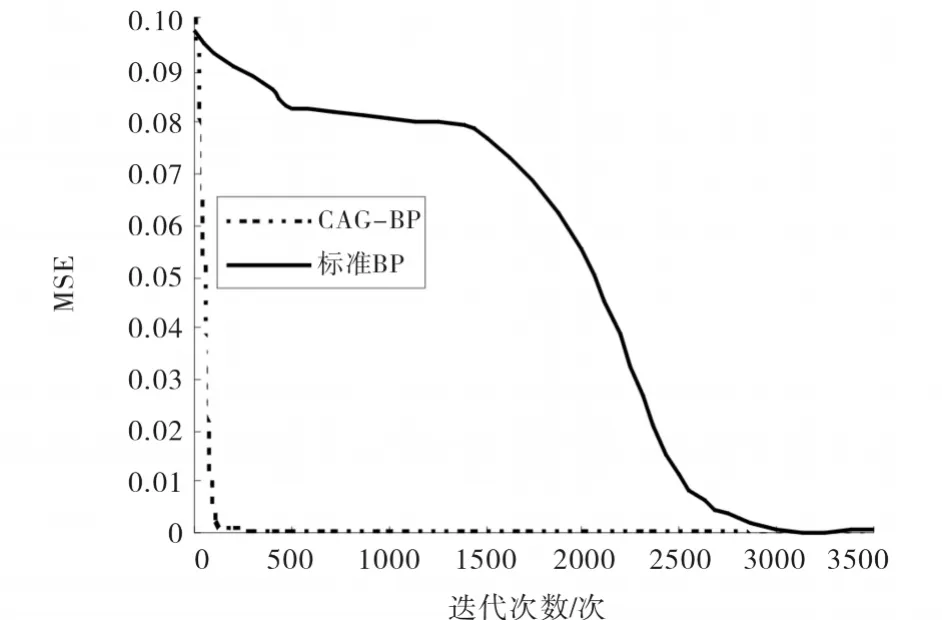
图2 2种算法的迭代次数与MSE对比图Fig.2 Comparison chart of iteration times and MSE of two algorithms

表2 CAG-BP算法测试结果Tab.2 Test results of CAG-BP algorithm
4 结语
由X条件云发生器产生改进的自适应交叉概率和变异概率,能够使适应度大的采用小的交叉和变异概率,适应度小的采用大的交叉和变异概率,在一定程度上保证群体的多样性,避免早熟,提高其全局搜索能力.实验结果表明,CAG-BP利用了正态云模型云滴的随机性和稳定倾向性特点,结合遗传算法训练BP神经网络,取得了比标准BP算法更优的结果.
[1]Liu Yanxi.The BP neural network classification method under Linex loss function and the application to face recognition[C]//IEEE.Proceedings of the IEEE International Conference on Computer and Automation Engineering (ICCAE) .Singapore: IEEE,2010:592-595.
[2]Qu Bo,Gu Huijuan.IVC fault diagnosis based on the improved BP neural network[C]//IEEE.Proceedings of the IEEE International Conference on Industrial and Information Systems(IIS).Dalian:Industry Applications Society-IA,2010:256-258.
[3]Li Hua,Zhao Jianping.Distributed intrusion detection system based on BP neural network[C]//IEEE.Proceedings of the IEEE International Conference on Computational Intelligence and Software Engineering.Sanya:CiSE,2009:1-6.
[4]Wang Guangming,Zheng Xiangna.The unemployment rate forecastmodel basing on BP neural network[C]//IEEE.Proceedings of the IEEE International Conference on Electronic Computer Technology.Macau:IEEE,2009:475-478.
[5]张立毅,刘 婷,孙云山,等.遗传算法优化神经网络权值盲均衡算法的研究[J].计算机工程与应用,2009,45(11):162-164.
[6]施化吉,尹纪军,李星毅,等.利用影响因子遗传算法优化前馈神经网络[J].计算机应用研究,2007,24(11):103-105.
[7]刘常昱,李德毅,杜 鹢,等.正态云模型的统计分析[J].信息与控制,2005,34(2):236-239.
[8]王保中,康立山,何 巍.基于实数编码遗传算法的多层神经网络BP算法[J].武汉大学学报:自然科学版,1998,44(03):289-291.
[9]Yan Taishan.An improved genetic algorithm and its blending application with neural network[C]//IEEE.Proceedings of the IEEE International Conference on Intelligent Systems and Applications.Wuhan:ISA,2010:1-4.
