基于极小阈值和曲线拟合的垂直投影汉字切分
2011-02-03王江晴
王江晴,曹 卫
(中南民族大学计算机科学学院,武汉430074)
关于脱机手写体汉字的切分目前有多种,包括基于直方图投影[1]的切分方法、基于连通域分析的切分[2]方法、基于笔画跟踪[3]的切分方法等,其直方图投影切分法是利用相邻字符间的间隔进行字符切分的.此算法简单快速、实现容易,但在一定程度上依赖于手写汉字文本的书写质量和规范,而汉字结构的多样性和书写者书写习惯的各异性,均对汉字书写质量有很大的影响,进而影响汉字字符的切分正确率.
本文针对传统的直方图投影切分法的不足,提出了基于极小阈值和曲线拟合的垂直投影汉字切分算法_.在行切分中,该算法在传统的直方图投影切分法的基础上,通过曲线拟合来寻找曲线的极小值点,从而来确定行切分点,最终得到准确的单行字符.在单字切分中,确定单个像素为极小阈值,利用极小阈值来进行垂直投影切分.由于阈值极小,故切分结果中易出现过短切分块,对此,利用最近距离最小段聚类法进行合并.而对于字符行中由于粘连和重叠汉字导致的过长切分块,则通过对该块的垂直投影曲线进行曲线拟合来实现再切分,相比于传统的垂直投影切分法,利用局部极小投影值点[4]来实现粘连或者重叠汉字的切分,该法对粘连和重叠汉字的切分更为准确.
1 图像预处理
实验中使用的样本库为哈尔滨工业大学人工智能研究室发布的 HIT-MW 库[5,6].图像在扫描过程中不可避免地会带来噪声,这些噪声会影响到图像的扫描质量,从而造成字符切分的错误.因此在切分之前,对文本图像进行一定的预处理是十分必要的.本文在图像预处理时采用高斯低通滤波器进行了图像增强.
由于汉字字符切分主要处理的是图像中的字体对象,对字体对象和背景对象之外的颜色信息不作考虑,所以必须对扫描得到的文本图像进行二值化处理.二值化的方法可分为局部比较法和全局阈值法.本文是根据文本图像的灰度直方图及灰度空间分布来确定全局阈值,进而实现图像的二值化处理的.
2 基于极小阈值和曲线拟合的垂直投影汉字切分算法
2.1 基于水平投影和曲线拟合的字符行切分
在字符切分中,处理的对象是字体,而通常情况下的字符文本图像是白色背景、黑色字体.为了实现方便,鉴于数字图像中黑白像素点的灰度值分别为0和1,通过取反操作将黑色像素点的灰度值设置为1,白色像素点的灰度值设置为0,从而达到将字体笔画点的灰度值取为1、背景点的灰度值取为0的目的,方便后期处理.
行切分中,利用汉字文本图像逐行分布的特点,在对该行全部字符像素点的灰度值进行横向累计求和的情况下,字符所在行的灰度和十分大,而行间空隙的灰度和几乎为零.累计求和表现为水平投影直方图,如图1(a)所示,并且还可发现,通过水平投影直方图可以明确每个波谷位置即为字符行切分点.
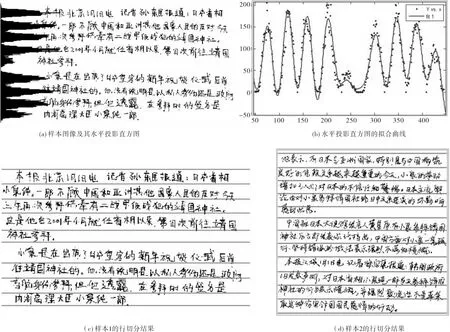
图1 基于水平投影和曲线拟合的行切分Fig.1 Line segmentation based on the horizontal projection and curve-fitting
对水平投影直方图选择正弦和函数(sum of sin function)进行曲线拟合,得到的拟合曲线如图1(b),拟合度为0.901,虽然拟合度并未达到100%,但是在此拟合度下,曲线的极小值点的横坐标已与被拟合对象(原水平投影直方图)的波谷的横坐标几乎接近,利用数学方法求得该拟合函数的极小值点,即可准确得到字符图像水平投影直方图的一系列的波谷点,即为行切分点,从而实现对汉字文本图像进行单行切分的目的.图1(a)的文本图像利用曲线拟合进行切分的结果如图1(c),图1(d)是利用该方法对另一样本进行切分的结果.由行切分的结果可见,利用曲线拟合实现行切分简单方便,准确率高.
2.2 基于垂直投影和极小阈值的初切分
对于单行字符,先由上向下对图像进行扫描直至找到第1个字体像素点,并由下向上对图像进行扫描直至找到最末的字体像素点,根据这2个像素点的坐标信息,就可以对图像大致的高度和宽度范围作精确定位,之后的操作就是针对这个比较精确了的图像区域,可减少不必要的操作,从而进一步提高切分速度.
设定阈值为单个像素大小,故叫极小阈值.对字符行进行垂直投影,当空白间隙大于或等于极小阈值,就进行切分.具体实现如下:对图像区域内的像素矩阵求列和,并将每列的和值保存到同样大小的一维数组中,称之为列和数组.从左到右遍历列和数组,当列和数组中的连续零像素点大于等于极小阈值时,则认为这是一个字符空隙,把此时的遍历指针所在位置作为切分点进行切分.初切分的结果见图2.

图2 运用极小阈值进行初切分的结果Fig.2 Result of original segmentation usingminimum threshold
2.3 基于最近距离最小段聚类法的过短切分块的合并
在初切分阶段,通过极小阈值来进行初切分,切分结果会出现过切分[7]现象.对于过切分导致的一系列过切分块,按最近距离最小段聚类法来进行合并.具体实现如下:先对初切分阶段的切分子块进行遍历,找出需要进行合并的过短切分块.过短切分块定义为:比切分块长度均值的0.6倍还要小的切分块.然后按最近距离最小段聚类法对过短切分块进行合并,即寻找与该过短切分块距离最近的切分块进行合并,或者寻找与该过短切分块距离次近但块长较小的切分块进行合并,这里需要说明的是,对于位于首部或尾部的过短切分块,则只能与其右邻或左邻进行合并.合并结果如图3所示,可以看出,初切分阶段的很多过短切分块都得到了正确地合并.

图3 合并过切分后的结果Fig.3 Merging result of the over-segmented blocks
2.4 基于曲线拟合的粘连字符切分
通过图3,我们同时可以观察到,“是与”这两个汉字由于粘连,未能切分开.对此,本算法根据曲线拟合方法寻找过长切分块的最佳切分点,从而实现粘连字符的切分.
过长切分块定义为:比切分块长度均值的1.2倍还要长的切分块.先对所有切分块进行遍历,找出需要进行再次切分的过长切分块.然后对过长切分块的字符垂直投影直方图用正弦和函数做曲线拟合,选择拟合度最高的拟合函数,求出该拟合函数的极小值点,该点即为可能的再切分点,再根据该点位置做假设性切分,并求出相应的切分块均值和方差,如果假设性切分可以降低切分块的方差,则认为假设性切分有效,做相应切分,并更新切分块的均值和方差,否则不做任何处理.上阶段的切分结果利用曲线拟合再次切分的结果如图4所示,通过再次切分,粘连字符“是与”得到了准确的切分,同时该字符行中的第2个标点符号也得以切分.

图4 单行汉字的最终切分结果Fig.4 Final segmentation result of single-line characters
3 实验结果及算法分析
本文通过极小阈值和曲线拟合来进行投影切分,对于单行切分简单高效,但对于书写行有倾斜的情况会出现些许误差,如通过图1(d)我们可以发现,由于有些书写行倾斜了的缘故,该文本图像的第6、7、9、10这4行的切分有些偏差,此问题可以通过在对单行进行保存时,将被保存区域的首行坐标适当缩小、而末行坐标适当放大的方法来解决.
而对于单字切分,在初切分时,由于使用极小阈值来进行,避免了汉字部件[8]的疏密情况导致的误切分,而由之出现的过切分现象和粘连字符无法切分的问题,通过合并法则和拟合曲线也得到了较好地解决.对于一般性的较规整的样本,本算法的切分效果十分理想,而对于存在粘连和重叠现象的样本,本算法的优势也十分明显.如图5、图6所示,是针对存在粘连和重叠现象的各种手写体汉字样本,利用传统的投影切分算法和本文的改进算法进行切分的最终结果.通过两者的对比和分析,可见本文的算法在粘连和重叠汉字的切分上有很大的优势.

图5 传统算法对不同手写体汉字样本进行切分的最终结果Fig.5 Final segmentation results of single-line characters samples using traditional algorithm

图6 本算法对不同手写体汉字样本进行切分的最终结果Fig.6 Final segmentation results of single-line characters samples using improved algorithm
4 结语
较高的字符切分效率对后期识别的准确度十分关键,垂直投影汉字切分算法简单快速,但该法在对非规整的文本进行切分时,容易出现误切,尤其对于粘连或重叠字符,无法切分,切分效率不高.因此,本文提出一个基于极小阈值和曲线拟合的垂直投影汉字切分算法,该算法利用极小阈值和拟合曲线极小值点等方法,来克服传统方法的不足,并取得了较好的切分效果,但是由于使用了极小阈值,故在某些样本中存在过切分现象,故为了进一步完善该方法,如何制定更有效的合并规则来减少过切分现象是该算法今后改进的方向.
[1]Lu Y.Machine printed character segmentation——an overview[J].Pattern Recognition,1995,28(1):67-80.
[2]刘 赛,朱宗晓,马志强.基于连通域的彝文文字切分算法的设计与实现[J].中南民族大学学报:自然科学版,2009,28(2):86-89.
[3]丁 杰,娄 震,杨静宇.基于笔划组合的手写数字切分[J].中国图象图形学报,2009,14(8):1609-1614.
[4]高彦宇,杨 扬.无约束手写体汉字切分方法综述[J].计算机工程,2004,30(5):144-146.
[5]Su Tonghua,Zhang Tianwen,Guan Dejun.Corpus-based HIT-MW database for offline recognition of generalpurpose Chinese handwritten text line[J].International Journal of Document Analysis and Recognition,2007,10(1):27-38.
[6]Su Tonghua,Zhang Tianwen,Guan Dejun,et al.Gaborbased recognizer for Chinese handwriting from segmentation-free strategy[C]//CAIP.Proceedings of the 12th International Conference on Computer Analysis of Images and Patterns.Vienna:CAIP,2007:539-546.
[7]苏统华.脱机中文手写识别——从孤立汉字到真实文本[D].哈尔滨:哈尔滨工业大学博士学位论文,2008:62-64.
[8]吕 岳,施鹏飞.基于汉字结构特征的自由格式手写体汉字切分[J].电子学报,2000,28(5):102-104.
