基于C语言的自适应Huffman编码算法分析及实现研究
2011-01-15文国知
文国知
(武汉工业学院数理科学系,湖北武汉430023)
基于C语言的自适应Huffman编码算法分析及实现研究
文国知
(武汉工业学院数理科学系,湖北武汉430023)
通过C语言程序,动态统计信源符号概率,逐步构造Huffman编码树,实现了自适应Huffman编码,解决了静态编码树不能根据信源符号的局部变化做出相应变化的主要问题。结果表明,自适应Huffman编码算法压缩率很大,能进一步提高数据传输的效率。
Huffman编码;自适应;无损压缩
随着信息技术的快速发展,日常需要处理或者传输的数据越来越多,由于数字化的多媒体信息尤其是数字音频、视频信号的数据量特别庞大,大数据量的信息会给存储器的存储容量、通讯干线信道的带宽以及计算机的处理速度增加极大的压力。如何采用有效的数据压缩技术来节省存储空间和网络传送时间已越来越引起人们的重视[1-3]。自适应Huffman编码方法,就是根据离散信源符号的产生概率,动态对信源符号进行编码,使产生概率小的信源符号编的码字长,产生概率大的信源符号编的码字短,这样就可以达到提高信息传输效率的目的[4]。
1 静态Huffman编码树的构造原理
Huffman编码树是按照信源符号权重值的大小将信源符号进行排序,取出权重值最小的两个信源符号作为叶节点组成一棵子树,子树的权重值为两个叶节点即权重值最小的两个信源符号权重值之和;然后将新产生的子树放回原来的集合,仍然按照信源符号权重值的大小将信源符号进行排序。重复以上方法,直至信源符号集合中只剩下一个符号。
以abcddbb作为待编码的原始信源数据串符号为例。首先,统计出a、b、c、d四个符号在原始数据串中的权重,结果如表1所示。

表1 数据串abcddbb的概率统计
按照前面提到的构造方法,可获得基于表1权重统计的静态Huffman编码树,如图1所示。

图1 静态Huffman编码树
从Huffman编码树的根结点出发,经过右子树、左子树、左子树三步,到达包含字符a的叶结点,获得a字符的二进制编码:100。下一个字符b,从根节点出发向左子树前进一步,达到b的叶节点,二进制编码为0。类似,将所有的信源数据经编码后,得到编码结果为:1000101111100。
静态Huffman编码算法给出的编码树构造方法,要求在实际编码之前统计被编码对象中符号出现的概率,并据此进行编码树的构造,这在许多实际应用场合是不能接受的,同时这种方法也不能对字符串局部统计规律发生变化时做出反应。因此,为改进该编码算法,提出了自适应Huffman编码方案。
2 自适应Huffman编码过程
编码树初始化时,由于只对信源数据流进行一次扫描,不可能预先知道各符号的出现概率。为对所有符号一致,令Huffman编码树初始状态只包含一个叶结点,记为符号NYT,权重值为0。将一个新符号插入编码树时,相应符号的出现次数增加了1,编码树中各符号的出现概率发生了改变。原有Huffman编码树已经不一定符合具有最小加权路径长度这一条件,需要进行调整,以保持合法Huffman编码树的状态。
仍以abcddbb作为待编码的原始信源数据串为例,自适应Huffman编码过程如图2所示。
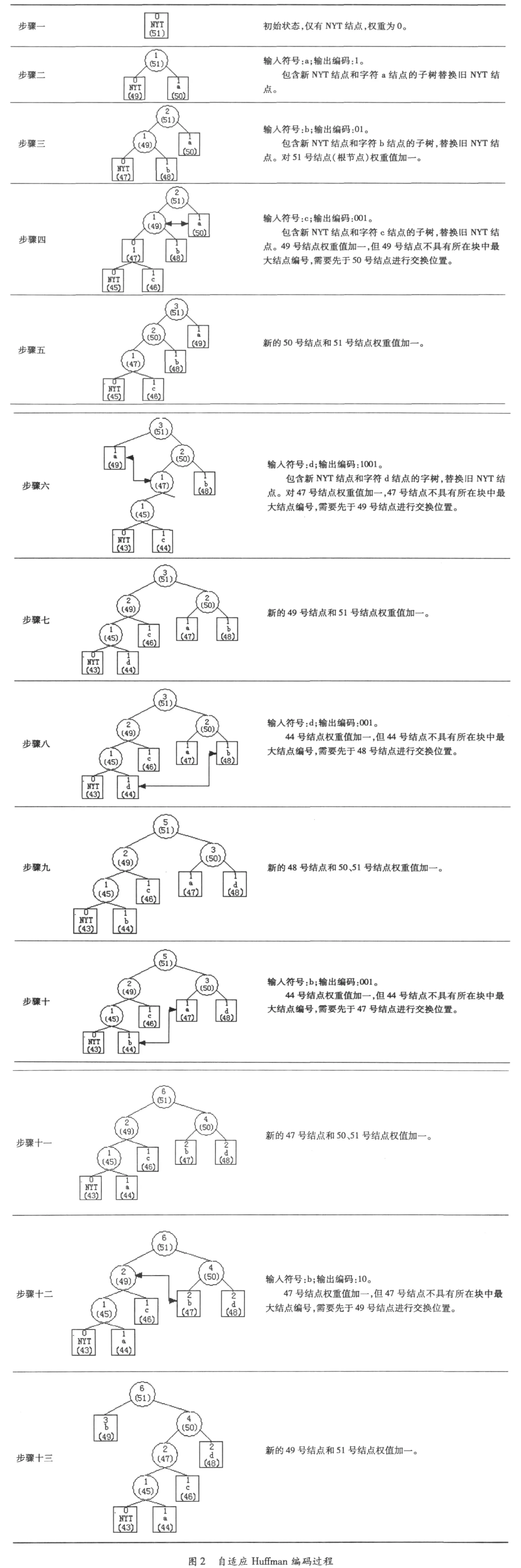
通过观察以上步骤,容易发现自适应Huffman编码的几个特征:①步骤13的编码树与静态Huffman编码树基本相同,除NYT节点和符号a节点组成的子树替代静态Huffman编码树中的符号a的叶节点之外;②每一次输入新的符号之前,Huffman编码树都处于完整可用的正常状态;③同一个输入符号,可能产生多种不同的输出;④同样输出结果,可能由不同的输入产生。
3 自适应Huffman压缩编码的C语言实现及程序结果
自适应Huffman编码算法程序如下所示。
初始化Huffman树:
对每一个输入符号
{
对符号编码;
更新Huffman树;
}
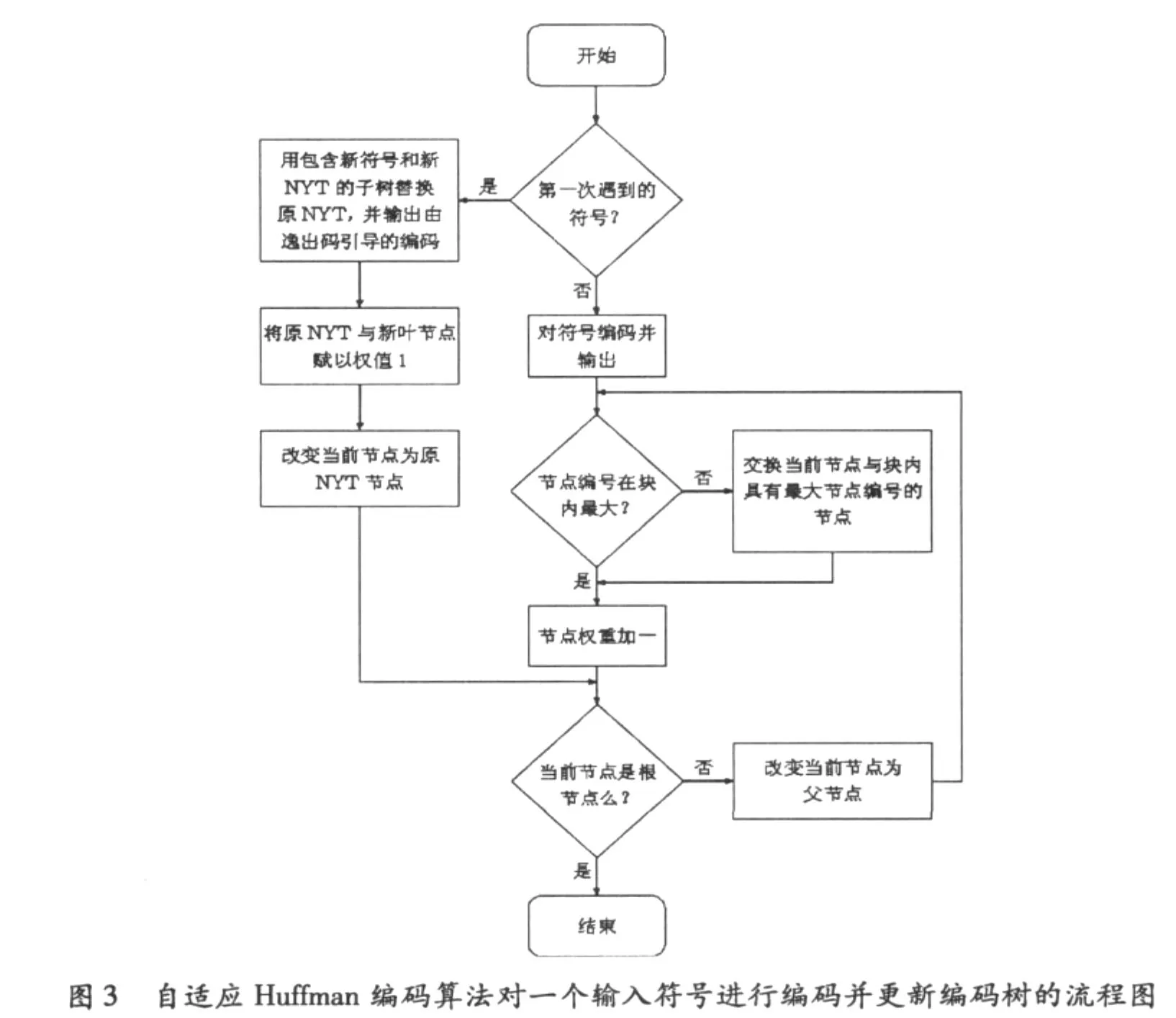
对一个输入符号进行Huffman编码并更新编码树的流程图如图3所示,自适应Huffman编码算法的程序结果如图4所示。

由此可见,自适应Huffman压缩编码算法在压缩比上尽管不能和有损压缩相比,但它改进了静态Huffman编码算法,更大程度上压缩了图像网络传输的冗余信息而减小了网络传输的信息量,从而能进一步提高通信质量和网络传输数据的效率。
[1] 陈衍仪.图像压缩的分形理论和方法[M].北京:国防工业出版社,1997:216-232.
[2] 马小虎.多媒体数据压缩标准及实现[M].北京:电子工业出版杜,1996:194-198.
[3] 黎洪松.数字视频技术及其应用[M].北京:清华大学出版社,1988:375-397.
[4] 傅组芸.信息论与编码[M].北京:电子工业出版社,2007:259-267.
An algorithm to achieve adaptive Huffman coding with C language
WEN Guo-zhi
(Department of Mathematics and Physics ,Wuhan Polytechnic University,Wuhan 430023,China)
The algorithm of adaptive Huffman coding is studied by dynamical statistics of the probability of source symbols and construction of the Huffman coding tree step by step with the C language.A solution is proposed about static source code tree which could not make the corresponding revision when the source symbol changes in the local.The results show that adaptive Huffman coding algorithm could further improve the compression ratio and enhance the efficiency of data transmission.
Huffman coding;adaptive;lossless compression
TN 911.21
A
1009-4881(2011)02-0053-05
10.3969/j.issn.1009-4881.2011.02.014
2010-11-19.
2011-03-25.
文国知(1973 -),男,博士研究生,E-mail:wenguozhi@hotmail.com.
