基于 XML 的 WEB信息自动抽取方法的研究
2010-10-22刘艳柳顾军华
宋 洁,张 娜,刘艳柳,顾军华
(河北工业大学 计算机科学与软件学院,天津 300401)
随着互联网的迅猛发展,WEB信息量呈爆炸式的增长,对信息抽取技术提出了更高的要求,如何直接而准确地从海量信息中抽取出用户感兴趣的数据变得尤为重要.基于本体实现表格信息抽取方法[1-2]不依赖于所抽取的WEB页面的设计格式,也没有对其内容提出任何表示限制,但该方法只适用于一定的应用领域,当应用领域改变时相应的本体需要重新构造.基于样本实例的抽取方法[3]不依赖于网页的结构特征,但这种方法需要较多的样本实例,增加了用户负担.基于网页结构特征分析的方法[4-5]采用统计聚类的思想,查全率较高,但在抽取信息时具有一定的盲目性,经常抽取出大量的无用信息.可见,现有的信息抽取技术难以同时满足网页信息自动抽取中查全率与查准率高、抽取信息量大、用户负担轻和无关于应用领域等要求.
通过对现有信息抽取方法的研究,本文提出了一种基于XML的WEB信息自动抽取方法,采用标准的XML技术来解决信息抽取问题.通过页面清洗技术将HTML文档标准化,利用归纳学习算法得到公共路径,获得用户感兴趣的目标区域,形成抽取规则库,从而实现对其它同类页面信息的自动抽取.该方法将网页结构特征分析与归纳学习相结合,具有较高的查全率与查准率;需要的样本实例少,减轻了用户负担;使用标准的XSLT作为信息抽取规则,复用性高、抽取结果具有自描述性.
1 信息抽取框架
本文提出的基于XML的WEB信息自动抽取框架,包括4个功能器:页面清洗器、页面结构分析器、规则学习器、抽取器,如图1所示.其中页面清洗器包括网页URL、XHTML文档;页面结构分析器主要是构建网页分析树;规则学习器包括学习样本实例、构建XPATH;抽取器包括XSLT模板规则库、抽取信息.
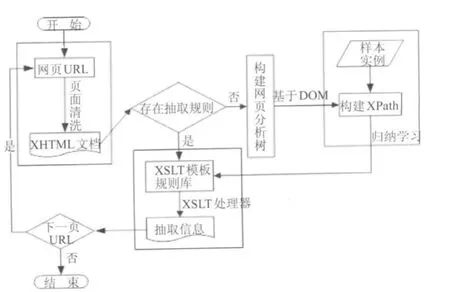
图1 Web信息自动抽取构架Fig.1 Automatic extraction of web information architecture
2 基于XML的信息自动抽取方法
基于XML的信息抽取方法在待抽取的数据源网页URL已获得的前提下,通过页面清洗器将源HTML文档标准化,过滤无用元素.如果该页不存在抽取规则,利用页面结构分析器将该页解析成一棵网页分析树,并根据样本实例学习公共的 XPATH,从而形成该页的抽取规则.如果已存在抽取规则,则直接进行抽取.由于待抽取的信息大都是通过后台数据库产生,即所谓的隐藏网页[6],一般有着较为统一的结构,因此依据生成的抽取规则,可以将网站中全部需要的信息抽取出来.
2.1 页面清洗
目前WEB上的数据大多都是HTML格式的,该标记语言缺乏对数据本身的描述,不含清晰的语义信息,对隐藏其中的数据难以检索或抽取.许多HTML文档没有完全遵守W3C网页标准,结构混乱,甚至含有错误,无法被转换成一棵网页解析树,因此在信息抽取前有必要进行页面的整理工作.
可扩展超文本标记语言(Extensible HyperText Markup Language,XHTML)是万维网联合会提出的新一代网页标准,从根本上解决了WEB文档和其他资源描述所面临的问题.因此在过滤脚本信息、图像信息等无用元素的基础上,将不规范HTML文档转换成标准的XHTML文档是页面清洗中的一项重要工作.
现有的WEB数据转换工具Tidy容错功能比较差,直接使用Tidy工具转换为XHTML文档后,解析比较困难,难以进行后续工作[7].本文给出了一种HTML页面清洗算法,主要实现步骤如下.
1)利用HTML解析器把HTML文档解析成一棵HTMLDOM树,并获得该树的根元素.
2)为文档添加XML文档声明和XSLT规则转换文件.
3)从树根开始,递归遍历HTMLDOM树,根据节点类型进行判断处理.
若是文本节点,则用实体引用代替特殊字符,并打印文本节点.
若是元素节点,则需判断节点类型是否是无用元素.若是无用节点,如Script、META、STYLE等,则直接过滤;否则,在取出元素节点之前先打印“<”,利用DOM中的get Node Name()方法获得元素节点名称,同时将其名称小写化.
在抽取时有些元素节点的属性值是必须的,如链接元素的属性值有利于获得下一页网页地址;而有些属性值只是用于字体样式,对抽取工作是无用的.因此,必须对元素节点的属性值进行优化处理.本方法判断元素类型是否为链接元素,若是,则提取链接元素所有的属性值.在XHTML中,属性值必须使用引号,并且必须有值.因此,在输出链接元素的属性时,首先打印一个引号,并取得属性值,对其进行特殊字符转换、小写化,再打印结束引号,最后打印“>”.
如果元素节点有子节点,则以同样方式递归打印出所有孩子节点,直到遍历结束,关闭元素节点.
4)待整个HTMLDOM树遍历结束,则形成了规范的XHTML文档.
例如,针对某网站经过该转换算法标准化后的XHTML文件片断如图2所示.
2.2 构建网页分析树
对XHTML文档进行解析,使用JTREE构建可视化的XML文档,以便获得实例样本,减轻用户负担.
构建网页分析树思想如下:
1)将页面清洗得到的XHTML文档解析成XMLDOM树,获得该树的根节点ROOT.
2)深度优先遍历该XMLDOM树.获得根节点的名称,如果该节点有孩子节点,递归处理该节点的孩子节点.如果该节点没有孩子节点,则直接加到当前节点下.最后把所有子节点加载到JTREE的根节点中生成整棵树.
3)显示整棵树.将图2中 XHTML文档构建网页分析树,其结果如图3所示.

图2 经过转换算法标准化后的XHTML文件片断Fig.2 the standard XHTML document segment
2.3 归纳学习XPATH
在获得样本实例的XPATH表达式的基础上,通过归纳学习得到公共XPATH.由于本方法只需获得样本实例的 XPATH的表达式,不需构建每个节点的XPATH,故执行速度较快.
1)生成样本XPATH
XPATH路径表达式可以看成定位XML文档各个节点的步骤顺序,这些步骤以“/”分开.如图3选中的节点,其XPATH表达式为“/html[1]/head[1]/title[1]”,表示选择“html”元素下“head”元素的“title”元素的叶子节点值,结果是图中的“笔记本电脑类目2,商品,尽在拍拍”节点.为了准确的定位信息点位置,本文提出了一种新的学习XPATH算法用于生成样本实例的XPATH,描述如下:


图3 使用JTREE构建的网页分析树Fig.3 Web analytics tree constructed by JTREE

2)学习公共XPATH
获得所有的样本实例后,通过学习算法归纳出公共 XPATH,本文涉及两种情况:网页级抽取和记录级抽取.本文中的网页级抽取是简单而有效的,主要目标是提取主题信息,而不是细粒度的数据.比如招聘信息一般可得到记录级的招聘列表,每个招聘信息都会有一个链接,以说明详细的招聘事宜,本文只需抽取出详细的招聘事宜即可.
若为记录级抽取,则至少需要2个样本实例.本方法利用网页分析树获得样本实例的 XPATH,并归纳学习出待抽取信息的公共路径.对于两个样本实例的XPATH表达式,从树根开始比较,如果节点名称和位置序号都相同,则记入公共XPATH表达式,若某个节点的节点名称相同,而位置序号不同,则说明待抽取信息位于以该节点表示的树节点及其兄弟为根的子树中,此时获得该节点的所有兄弟节点数,将该节点的孩子序号置为0,并写入公共XPATH表达式中;依次比较到XPATH表达式结束.有的页面需要学习多条XPATH,那么继续将样本实例的XPATH与已经得到的公共XPATH比较,从根节点开始,直到全部样本实例比较完毕,由此可得到全部样本实例的公共XPATH表达式.若抽取多个信息点则需要学习各个信息点的XPATH表达式.
若为网页级抽取,则样本实例至少需要1个.若为1个样本实例,它的公共XPATH就为此节点本身的XPATH表达式;若为多个样本实例,生成公共XPATH的方法和记录级抽取的生成方法相同.
2.4 抽取规则优化处理
由于XSLT具有强大灵活的语法结构,易于理解、修改和操纵文档中的数据,本文使用标准的XSLT作为信息抽取规则.通过对归纳学习得到的公共XPATH添加、合并或更新,生成抽取规则库,形成XSLT文件,利用其中的XPATH构件定位文档中节点的位置,从而实现了一次编写,多次重用.
在信息抽取中,一般记录条数较多,而在XSLT中,当XSLT处理器为执行转换而处理样式表的时候,它的值每次都可能发生变化.但是,一旦在某个转换中设定了这个值,就不再发生变化.因此,要把所有的记录条数全部抽取出来,必须使用模板递归调用.首先定义3个变量,保存起始孩子节点序号,孩子节点数以及步长值.然后设置公共路径里的参数,初始值为起始孩子节点序号,模板运行一次后将起始孩子节点序号按步长值增加,得到的结果作为参数递归调用模板,完成多条记录数的自动抽取.
在生成抽取规则时可以定制待抽取节点的节点名称,使其作为结果XML文件的元素名称,保证了抽取结果具有自描述性.
2.5 抽取信息
根据抽取规则库里的规则,利用XSLT和XPATH在数据转换和数据定位方面的优势,通过输出文件函数实现信息抽取.将抽取结果存入XML文件中,用于观察数据抽取的正确性和二次处理.
3 实验结果及分析
利用基于XML的WEB信息自动抽取方法,采用JAVA语言开发了信息抽取原型系统.该系统界面简单友好,在页面结构发生变化时,也能利用原型系统快速构建新的抽取规则库,具有较高的查准率和查全率.
本文利用原型系统进行了4个网站26个页面的实验,如表1和表2所示,其中待抽取数据共423个,由于2688网店和卓越亚马逊的信息点具有两种格式,当其提供的样本实例数为2个时,实际抽出共366个,正确抽出共360个,平均F值为75.23%;当其提供的样本实例为3个时,平均查全率为99.17%,平均查准率为99.17%,平均F值为99.17%.对于一般网站而言,一个信息点本方法最多提供3个样本实例,便可完成较高查全率和查准率的抽取.基于上述试验结果,本文的信息抽取方法是有效且可行的.

表1 测试原型系统的网站Tab.1 test prototype website
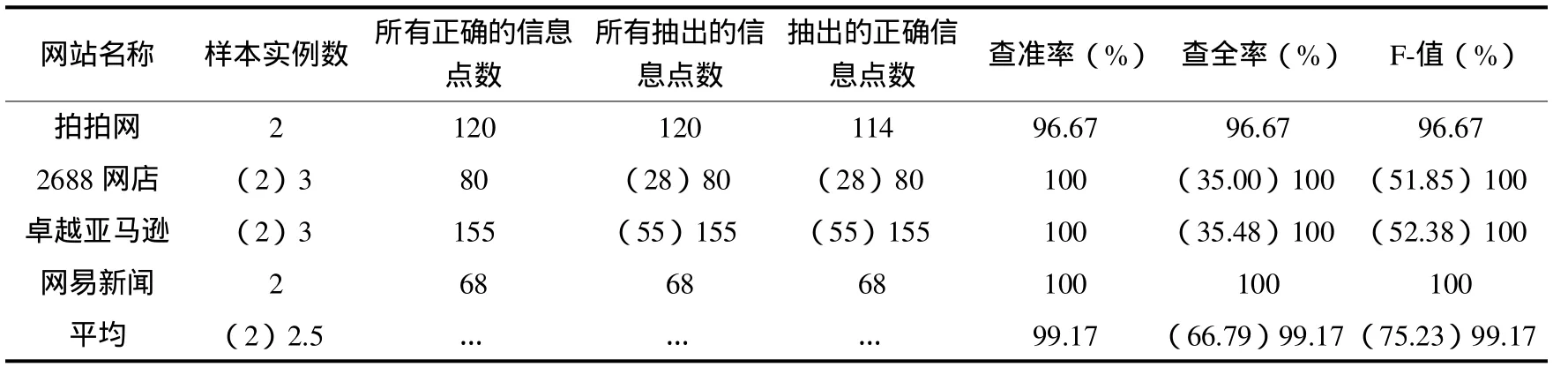
表2 抽取测试效果的评价Tab.2 Evaluation of test results
4 结束语
本文给出的基于XML的WEB信息自动抽取方法,利用XML的标准技术,通过数据转换算法和XPATH学习算法获得公共路径,并结合XSLT和XPATH在数据转换和信息定位方面的优势,实现了对WEB信息的自动抽取.实验结果表明,该方法查全率和查准率高,抽取结果具有自描述性,易于建立各个领域的数据抽取系统.
[1]王放,顾宁,吴国文.基于本体的WEB表格信息抽取 [J].小型微型计算机系统,2003,24(12):2142-2146.
[2]毕蕾,沈洁,徐法艳,等.领域本体指导的Web商品信息抽取 [J].计算机工程与设计,2008,29(24):6393-6396.
[3]张绍华,徐林昊,杨文柱,等.基于样本实例的WEB信息抽取 [J].河北大学学报(自然科学版),2001,21(4):431-437.
[4]David Buttler,Ling Liu and Calton Pu.A fully automated object extraction system for the world wide web[C].International Conference on Distributed Computing Systems,2001.
[5]于鲁波,陈超.互联网商品信息抽取技术 [J].计算机工程,2008,34(5):274-276.
[6]Raghavan S,Garcia-Molina H.Crawling the Hidden Web[EB/OL].(2000-12-08).http://dbpubs.stanford.edu:8090/pub/2000-36.
[7]轩艳艳.基于XML的WEB信息抽取研究与实现 [D].武汉:武汉理工大学,2008.
