网络新闻口语评论文本中人物对象识别方法
2010-07-18林琛李弼程周杰
林琛,李弼程,周杰
(解放军信息工程大学信息工程学院,河南郑州450002)
1 引言
随着互联网在全球范围内的飞速普及,它已成为人们发布、交流信息的重要渠道。社会舆情在互联网上反应为网络舆情,社会舆情和网络舆情在内容上具有一致性。但由于网络表达快捷、信息多元,方式互动等特点使得网络舆情形成迅速,对社会影响更巨大。
近年来,社会管理部门急需了解当前人们关注事件、舆论方向等信息,能够对出现的网络舆情进行及时地监控。2008年6月,胡主席在人民网与网友聊天,指出他上网主要关注人们关心什么问题,对这些问题的看法、态度、意见等。
目前,网络舆情分析技术正处于起步阶段,国内外研究不是很多,没有具体的研究内容和统一定义。网络新闻口语评论文本(以下简称网络新闻口语评论)的分析研究则更少,而它作为网民意见的最直接和最重要的载体,是舆情分析的重要内容。我们结合舆情学、舆论学[1-2]的研究成果,给出以下定义:
定义1:网络新闻口语评论分析
网络新闻口语评论分析是对突发、热点和重点网络新闻事件的相关评论进行分析,获取重要舆情信息,即评论者对评论对象的态度、情绪、意志等主观信息。
定义2:网络新闻口语评论对象
网络新闻口语评论对象是网民进行评论的对象,是评论内容的指向。
我们将新闻口语评论对象分为全局对象和局部对象。全局对象是指整个新闻事件;局部对象是指用户评论的与新闻事件相关的关键性人物、机构、话题等。通常,大部分评论不直接发表反对或支持全局对象,而是围绕一些局部对象进行讨论,其中很大一部分为人物对象。
这里,人物对象是指在评论中出现与新闻事件相关的,被网民使用和评论的人名。例如:“刘忠德批超女”事件中的“刘忠德、刘老、老刘、刘”;“逃跑老师范美忠”事件中的“范美忠、范跑跑、范”等。网络新闻口语评论中人物对象不同于传统的书面语人名,无论表达方式和所在的上下文环境都具有很强的口语化特点。
本文在分析人物对象特点的基础上,研究网络新闻口语评论中人物对象的自动识别方法。其他部分组织如下:第2节介绍相关研究;第3节分析网络新闻口语评论中人物对象特点;第4节提出一种人物对象自动识别方法;第5节在网络真实语料上进行实验检测方法有效性;最后总结全文并介绍下一步研究工作。
2 相关研究
目前还没有见到直接面向网络新闻口语评论的人物对象识别的研究报道。相关性研究主要是人名识别技术。目前人名识别技术主要面向书面语的新闻语料,语法规范,人物用名正规。研究方法包括:规则方法[3-4]、统计方法[5-6]和规则与统计结合的方法[7-8]。其中,基于规则的方法需要人为建立规则,方法简单、代价昂贵并且难以扩展;基于统计的方法利用人工标注语料,结合概率统计模型进行识别,但方法依赖于模型和训练语料质量和规模;规则与统计结合是主流识别技术,该类方法统计姓名用字概率以及姓名边界信息等大量的数据信息,然后根据阈值对候选姓名进行取舍,主要问题在于阈值设定不当会影响到性能。
但网络新闻口语评论中人物对象识别又不同于一般人名识别。与人名识别通常处理的书面语文本不同,网络新闻口语评论属于口语文本。目前,对评论性口语文本的分析称为意见挖掘,处理对象主要
为产品,例如:汽车、数码照相机的评论,研究集中在产品特征识别、情感倾向性分析等方面。其中,产品特征识别即识别产品评论对象,识别方法主要利用本体资源[9-10]、语法结构[11-12]、统计学习[13]。产品隶属特定领域,特征相对固定,而网络新闻不同评论者看待事件角度不同,对同一人物对象表达可能就不同,因此,评论中包含了大量口语特色的人名,给目前识别方法带来了挑战。
3 网络新闻口语评论中人物对象特点分析
文献[4]中提出基于角色标注的人名识别方法,取得了较高召回率。它包含在中国科学院计算技术研究所研制的汉语词法分析系统ICTCLAS(Institute of computing technology,Chinese Lexical A-nalysis System)中。下面利用该方法对网络新闻口语评论数据中人物对象进行识别,分析新数据环境下面临的问题及原因。
以代表性的网络新闻事件“逃跑老师范美忠”为例,利用ICTCLAS对其口语评论中人物对象进行识别。所有数据来自互联网,经过规范化预处理,主要是规范标点符号使用。因为有些网民在书写评论时随意添加各种符号、空格等,例如:“范美 忠应该 道 歉” 、“坚/决/支/持/范/跑/跑”,这些会影响ICTCLAS的识别结果。
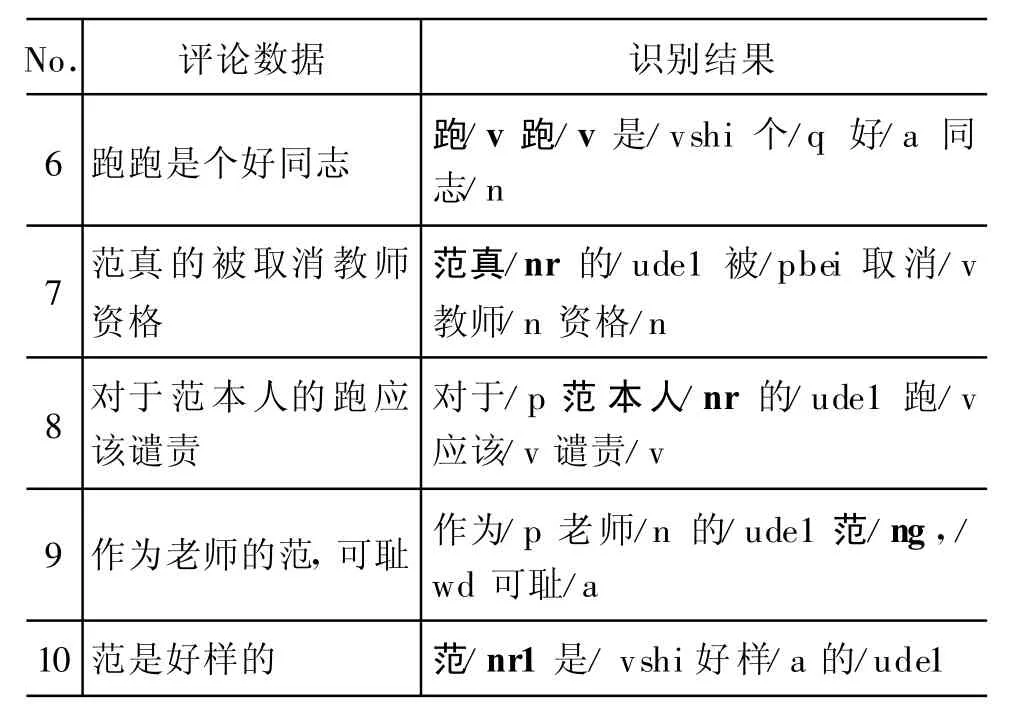
部分识别结果如表1。由表可见,文献[4]中方法对口语评论中的人物对象整体识别效果不理想,存在问题包括:
(1)对同一表达形式的人物对象识别结果不稳定,如表1中:1、2、3或 9、10;(2)无法完整识别人物对象的别称,如:4、5;(3)无法识别人物对象别称,如,6;(4)其他识别错误,如:7,8,9。

表1 基于角色标注方法的人物对象识别结果
续表
原因主要是网络新闻口语评论者来自社会各个阶层,对人物对象称呼的联想范围广泛,出现了大量的简称、别称等口语特色表达形式,且口语表达方式对词法、语法的使用要求不严格。而目前的识别方法均依赖于从大规模标注语料库抽取出的书面语人名统计数据和用字规律,无法适应口语人物表达不规范和形式多样的特点。
通过大量实际口语评论数据的统计分析,人物对象主要具有以下特点:(1)人物对象集中,一般评论者通常只围绕几个关键性人物进行讨论;(2)对同一人物对象表达形式多样,大部分表达形式围绕人姓或名的“变形”;(3)某些表达形式得到网民的肯定,评论中会大量重复出现;
网络新闻口语评论中人物对象的主要表达形式,如表2所示。

表2 网络新闻口语评论中人物对象表达形式
4 网络新闻口语评论中人物对象识别方法
我们结合网络新闻口语评论中人物对象的表达特点,在ICTCLAS切分基础上提出一种人物对象识别方法。该方法首先从ICTCLAS切分结果提取单字,利用基于多频率综合判别的单字可靠度评估方法,提取人物对象识别线索;然后,以线索为中心划定处理窗口,结合人物对象表达相邻、有序、频繁的特点,利用改进的频繁项挖掘算法生成候选人物对象;最后,对候选人物对象中的冗余进行优化,确定人物对象。
4.1 识别线索提取
网络新闻口语评论经ICTCLAS切分后,人物对象存在于切分产生的碎片中,识别可以看作某个区域内重新组合字串碎片将其连接起来构成整体对象的过程。
从表1可以看出,ICTCLAS对某些表达形式的人物对象虽无法完整识别,但可将其“部分”识别出来,例如:姓氏“范”:
早/tg就/d该/v把/pba范/nr1跑/v跑/v炒/v掉/v
坚决/ad支持/v取消/v范/nr1美/b忠/vg教师/n资格/n
大部分/m老师/n认为/v范/nr1美/b忠言/n论/v不当/a
在实际评论数据中,人物对象的表达大部分是围绕人姓氏或名的“变形”。因此,从ICTCLAS识别结果中提取可靠度高的人物对象识别线索,以线索为中心划定对象获取区域,这样既能缩小识别范围,降低了处理复杂度,同时最大程度地减少冗余。
本文选用切分结果中的单字作为线索单元。一般而言,某单字在切分结果中出现的次数越多说明用户使用率越高,作为对象组成部分的可能性就越大,书面语文本中可以直接采用其评估可靠度,但对于口语评论文本,不能简单的应用。因为口语表达随意,评论者可能在一个评论中大量重复同一对象,而该对象只存在于这一个评论中,并不受其他评论者关注,为评论无关对象,但在切分结果中表现为该对象包含的某个单字出现频率很高,这样势必影响评估结果的可信性。针对上述问题,我们结合新闻口语评论文本和人物对象表达特点,提出以下两个假设:
(1)人物对象表达形式越多样越重要;
(2)人物对象在评论中分布越广越重要。
以此分别对应引入两个度量值,即出现某单字的切分结果个数、出现包含某单字的切分结果的评论条数。结合以上反映单字作为人物对象组成部分可能性的三个因素,对单字可靠度进行评估,计算表达式如式(1)。
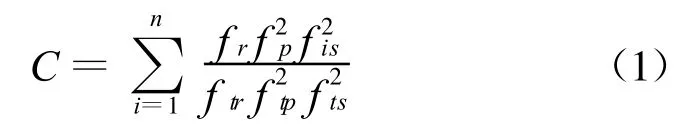
其中,fr为某单字在切分结果中出现的次数,ftr为所有单字在切分结果中出现的次数和,fp为出现某单字的切分结果个数,ftp为切分结果的个数;fis为出现包含某单字的第i个切分结果的评论条数,fts为评论总条数。fp ftp f is fts采用平方运算是为了体现其对可靠度的影响更大。
4.2 生成候选人物对象
关联规则挖掘[14-15]表述如下:设I={i1,i2,…im}是所有项目的集合,D={T1,T2,…Tn}是所有事务的集合,每个事务 T是一些项目的集合,T⊆I。若X⊂T则称事务T支持X。关联规则形如X⇒Y的蕴涵关系,其中X⊂I,Y⊂I且X∩Y=Ø。如果D有s%的事务同时支持X和Y,s%称为关联规则X⇒Y的支持度。如果D中支持X的事务中,有c%的事务同时也支持Y,c%称为关联规则X⇒Y的可信度。可信度是对关联规则准确度的衡量,支持度是对关联规则重要性的衡量。
关联规则挖掘就是从事务集合D中找出满足用户指定的最小支持度s%和最小可信度c%的关联规则,主要包含以下两个步骤:(1)发现所有的频繁项集,项集的频度至少应等于s%;(2)根据所获得的频繁项集,产生相对应的强关联规则,规则必须满足c%。目前关联规则挖掘研究基本围绕(1)进行,称为频繁项集挖掘。通常,最小支持度s%的值由用户或专家设定。本文主要利用(1)获取候选人物对象,其中支持度取经验最优值5%。
一般而言,中文人物对象字符不超过3个。这里,我们假设完整人物对象包含单字数不多于3个。针对某些得到网民的肯定的人物对象表达形式会在评论中大量重复出现的特点,以3.1提取的线索为中心左右划入2个字符,组成处理窗口,对处理窗口中的字符串利用繁项集挖掘算法获取频繁项作为候选人物对象。其中,为了尽量减少处理窗口中单字数量,降低结果冗余,考虑到评论头位置、标点符号一定程度上提供了完整人物对象的边界信息,例如:“范是人民”、“门.范跑跑”、“反对范美忠!”,方法在划定处理窗口时,将其作为一个字符划入。
经典频繁项集挖掘算法所处理的事务中各项是无序的,且所抽取频繁项集中的各项在原事务中不相邻,也没有先后次序。而人物对象是由组成对象的各个单字的字义、字与字之间相邻有序的关系决定。不同于经典的频繁项集挖掘算法,本文所处理的事务是包含人物对象的单字串,它们之间具有相对固定的顺序;所提取的频繁字串,即候选人物对象,是由处理窗口中相邻、有序、频繁出现的单字组成。
针对这一特点,方法对Ap riori频繁项集挖掘算法中每次扫描生成的候选字符串进行判断,只保留相邻、有序候选字符串。对候选字符串的筛选同时解决了Apriori算法由于候选项过多而造成的算法效率低下问题。本文算法具体步骤如下:
(1)对评论数据进行扫描,获取线索w i为中心
的处理窗口[w i-2 wi-1 wiw i+1 wi+2];
(2)扫描所有处理窗口,生成1-候选项集C1,统计各字符出现频次,根据设定最小支持度确定1-频繁集L1;
(3)由1-频繁集L1确定候选集C2,对处理窗口进行扫描,统计C2中每个候选项相邻、有序出现的频次,由频次大于最小支持度的候选项组成2-频繁集L2;
(4)循环依照上述步骤产生频繁集L3;
(5)将频繁集Li(i=1,2,3)不包括标点符号的频繁项作为候选人物对象。
4.3 人物对象优化
4.2节所述方法已较大程度地减少了频繁项集中的冗余项,但由于Ap ririo算法中频繁项集的所有非空子集一定是频繁字串,决定了生成的候选人物对象中还存在很多冗余。例如:“刘忠德”被选定,则“刘忠”、“忠德”一定被选中。如果评论中没有独立出现这类称呼,即使为正确的称呼,如“忠德”,也认为选错,应该删除。
为了提高人物对象质量,需要对结果进一步处理。由于假设完整人物对象包含单字数不多于3个,这里分别对频繁项集Li(i=1~3)中频繁项,即候选人物对象进行优化,删除冗余项,获取单字、双字和三字人物对象。优化策略如下:
(1)单字人物对象选取
考虑口语中比较普遍地直接使用姓氏作为人物对象。假设某单字候选人物对象w1出现频次f(w1),统计w1作为所有二字候选人物对象头和尾的频次>∑f(w jw1)且f(w1)-∑f(w1 wi)≥β,即w1作为头且频次超过阈值时为单字人物对象。
(2)双字人物对象选取
设二字候选人物对象w1 w2,频次为 f(w1 w2),统计w1 w2在所有三字候选人物对象中作为头两个字和后两个字的频次 ∑ f(w1 w2 w i)、∑f(w jw1 w2)。
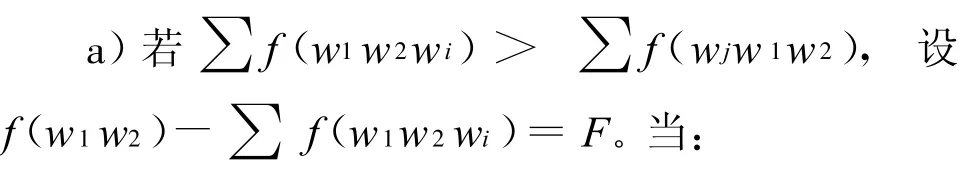
F<α,w1w2不为双字候选人物对象;
F≥β,w1 w2直接作为双字人物对象,其个数为F;
α≤F<β,取窗口中w1w2后面第一个单字(wi除外),统计各单字出现频次。若某单字w频次 f(w)≥0.5F,即某单字数量超过所有单字数量的50%,则w1 w2 w为个数为 f(w)的三字人物对象,同时将w1 w2从双字候选对象中去除,否则直接作为双字人物对象。
b)若 ∑f(w1w2wi)≤∑f(wjw1w2),则同a)处理;
c)若∑f(w1 w2 w i)=∑f(w j w1 w2)=0,即w1 w2没有被包含在三字候选对象,则直接作为双字人物对象;
(3)三字人物对象选取
设三字候选人物对象w1 w2 w3出现频次为f(w1 w2 w3),f(w1 w2)、f(w2 w3)为其有序子串w1w2、w2w3在双字候选对象中出现的频次。
计算 f(w1 w2 w3)3/f(w1 w2)f(w2 w3),其值越大说明w1 w2 w3越紧密,若值大于阈值β,则判定为三字人物对象。其中,f(w1w2w3)/f(w1w2)反映w3字与 w1 w2字串的紧密度,而 f(w1 w2 w3)/f(w2w3)反映w1字与w2w3字串的紧密度。
规则(1)~(3)中相关阈值α、β取经验最优值,α=20,β=5%×δ(其中,δ为某线索为中心提取的处理窗口数目)。
5 实验结果与分析
5.1 数据准备
实验使用了包括“逃跑老师范美忠”、“刘忠德批超女”、“周正龙假华南虎照”、“刘翔退赛”等4个热点新闻事件的中文评论数据。所有数据为从网易、强国论坛等中文评论网站采集。
语料采集后,通过网页分析进行数据抽取,去重和规范化处理后转换为同一文本格式,并进行人工标注,最终得到实验使用的数据集。人工标注样本数目见表3。
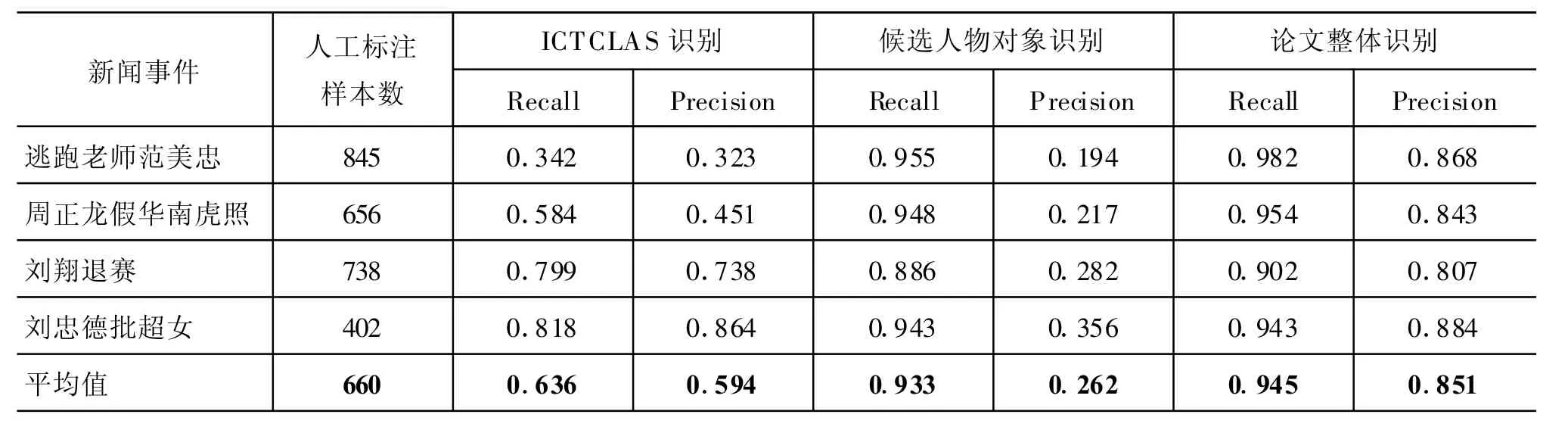
表3 人物对象识别性能比较
5.2 性能评价指标
实验采用召回率(recall)、准确率(precision)对识别方法的性能进行评价,计算表达式如下:
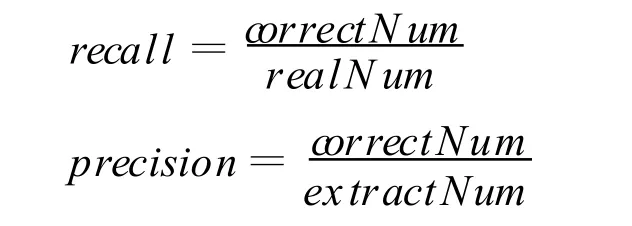
其中,correctNum为正确识别的人物对象数目;rea lNum为人工标注人物对象的数目;ex tract-Num为识别出的人物对象数目。召回率反映识别结果的完整程度,准确率反映识别结果的准确程度。
5.3 识别方法性能
表3为ICTCLAS识别[4]、候选对象识别、论文整体方法识别的性能比较。表4为部分识别结果。从表3中可以看出:对于不同的网络新闻事件,ICTCLAS方法识别性能不稳定,主要是受口语评论中人物对象表达形式的影响。一方面,若别称使用频率较高,则ICTCLAS识别效果不理想。如:"逃跑老师范美忠",其人物对象识别的召回率和正确率均不足35%,主要是评论中大量别称的使用,其中"范跑跑"就占了人物对象总数的45%。另一方面若书面语人名使用频率高,则ICTCLAS识别的效果较好。如:“刘忠德批超女”、“刘翔退赛”中,使用了较多“刘忠德”、“刘翔”等ICTCLAS能够识别出的书面语称呼。

表4 识别的部分人物对象
与ICTCLAS方法相比,本文方法具有较较高的稳定度和识别率。其中,候选人物对象识别作为方法的一部分,有效地提高召回率,能够发现包括单字姓氏、双字和三字别称等多种表达形式的人物对象。
但由于单字、双字、三字候选人物对象存在的大量冗余项,其准确率低下,如:单字“老”、“有”、“多” ;双字“刘忠”、“周正” 、“范真” ;三字“得范美” 、“支持刘”等。方法通过对候选人物对象的一系列优化处理,删除结果冗余项来提升识别的准确率。与此同时,召回率得到小幅度提升,主要是由于双字人物对象选择策略中发现了部分非频繁项的三字人物对象。如:“范美忠”频次129,二字候选人物对象“范美”频次 152。差值大于阈值β,查找“范美”后面的第一个单字(除候选对象中已包含的单字)。其中,“中”频次为20,超过单字总数 50%,“范美中”视为三字人物对象。
总之,新方法能够较好地适应网络新闻口语评论中的人物对象特点,稳定、完整地提取出不同网络新闻事件下的核心人物对象。
6 结束语
网络新闻口语评论中人物对象是网络舆情的重要内容,对需求者及时掌握舆情具有重要意义。
本文结合口语评论中人物对象特点,以分词为基础,提出一种网络新闻口语评论中的人物对象自动识别方法。在网络真实语料上进行实验,新方法取得了良好的识别效果。在下一步工作中,还需要对同一人物对象的各种表达形式进行聚合处理,即合并不同称呼的同一目标对象,例如:“范跑跑”、“范美忠”、“范”,以满足情感倾向性分析的需要。
[1] 刘毅.网络舆情研究概论[M].天津:天津人民出版社,2007.
[2] 韩运荣,喻国明.舆论学[M].北京:中国传媒大学出版社,2005.
[3] 吕雅娟,等.基于分解与动态规划策略的汉语未登录词识别[J].中文信息学报,2001,15(1):33-38.
[4] Jin Rong,Yan Rong,Zhmag Jian.A faster iterative scaling algorithm for conditional exponential model[C]//Proceedings of the Twentieth International Conference on M achine Learning(ICM L-2003),Washington DC,2003.
[5] 张华平,刘群.基于角色标注的中国人名自动识别研究[J].计算机学报,2004,27(1):85-91.
[6] 王振华,孔祥龙,等.结合决策树方法的中文姓名识别[J].中文信息学报,2004,18(6):10-15.
[7] 李中国,刘颖.基于边界模版和局部统计相结合的中国人名识别[J].中文信息学报,2006,20(5):44-50.
[8] 季姬,罗振声.基于统计与规则的中文姓名自动辨识别[J].语言文字应用,2001,31(1):14-18.
[9] X.Cheng.Automatic topic term detection and sentiment classification for opinion mining[D].Master Thesis.Saarbr cken,Germany:The University of Sarrland,2007.
[10] 姚天昉,娄德成.汉语语句主题语义倾向分析方法的研究[J].中文信息学报,2007,21(5):73-79.
[11] Ana-M aria Popescu and Oren Etzioni.Extracting Produc t Features and Opinion from Review s[C]//Proceedings of the H uman Language Technology Conference on Empirical Methods in Natural Language Processing.Vancouver,Canada,2005:339-346.
[12] J.Yi,Nasukawa,R.Bunescu,and E.N iblack.Sentiment Analyzer:Extracting sentiments about a given topic using natural languages processing Techniques[C]//Proceeding of the 3rdIEEE International Conference on Data M ining.Me lbourne,USA.2003:427-434.
[13] 刘非凡,赵军,等.面向商务信息抽取的产品命名实体识别研究[J].中文信息学报,2006,20(1):7-13.
[14] H an J W,Kember M.Data M ining Concep ts and Techniques[M].Beijing:H igher Education Press.2001:240-243.
[15] 朱明.数据挖掘[M].合肥:中国科学技术大学出版社.2002:135-141.
附录A
在进行人物对象人工标注时,考虑到后续情感倾向性分析研究需要,构建了网络新闻口语评论情感语料库。人工标注样例如下:



表A1 语料标注参数说明
