期刊下载次数的布拉德福分布研究
2010-06-14刘思源刘新新王玲玉
●郭 强,赵 瑾,刘思源,张 芳,刘新新,王玲玉
(1.郑州大学 信息管理系,郑州 450001;2.中国人民解放军炮兵学院 军事运筹教研室,合肥 230031)
对期刊下载次数进行研究有一定的理论及实际意义。第一,从学术价值评价的角度,引文分析作为一种评价的方法有其局限性。例如,使用但未被引用的文献的学术价值应当如何去衡量,毕竟作者在最终成果中引用的文献往往只是其科研活动中所使用过的文献的一部分,而下载次数在一定程度上能够与文献的被阅读次数或者是受利用的程度相对应,当然这需要在网络环境下。再如,引文分析具有相对的滞后性,而利用文献的下载次数则有可能使对学术价值的评价有所提前。第二,下载次数是网络资源的基本属性,对下载次数的考察是网络计量学理论研究的组成部分,而且探讨下载次数所服从的规律会有助于对用户信息需求行为的理解,从而为资源配置的优化提供定量依据。对下载次数的已有研究主要包括对期刊下载频次在期刊中分布状况的考察,以及下载频次与其它评价指标之间的比较研究和等级相关分析,[1-3]其中的原始数据均取自《中国学术期刊网络计量测试报告》以及《中国学术期刊综合引证报告》。本文则侧重于随学科属性的不同下载次数在期刊中分布状况的差异,需要指出在对分布状况进行比较的过程中会涉及到期刊下载次数的概率分布。
1 期刊下载次数的概率分布
如果将期刊的下载次数视为随机变量,那么考察该变量的概率分布则具有较为基础的理论意义。《中国学术期刊网络出版总库》的镜像站版已对其入库期刊按照学科性质进行了分类,并且能够提供各期刊的下载次数,在这里我们将其作为数据来源,并得到下载次数在期刊中的频次分布。如图1所示,统计时间为2009年3月。

图1 期刊按下载次数的分布图
图1对不同的学科属性分别进行了考察,包括理工与人文,也包括学科界限较为明晰的农业科技以及相对模糊的信息科学,目的是希望得到一些具有共性的规律。从直观上来看,下载次数在期刊中并不服从正态分布,而是与负指数分布较为吻合,曲线拟合的结果也从侧面说明了这一点。比如对于基础科学类,拟合曲线为y=79.637exp(-x/8.768)-0.133,且判定系数为0.978;对于社会科学类,拟合曲线为y=103.085exp(-x/6.896)+0.119,且判定系数高达 0.998,对于图中其余的学科属性均具有类似的情形,其中x和y分别为下载次数和相应学科的期刊百分比。
下载次数的频次(概率)分布是对该随机变量进行统计分析的基础,由此种种较为成熟的统计分析方法才能够得以运用,毕竟每种方法都有其适用范围。例如对期刊的学术价值或是影响力等进行综合评价,在建立评价指标体系的过程中,不仅需要考察单个指标自身的性质,也需要考察指标之间的相互关系,从而对各指标的权重进行确定。因此需要对下载次数与其它文献计量指标,比如期刊的被引次数等,进行统计相关分析。一种方法是简单相关分析,但是该方法要求所考察的随机变量需要服从正态分布,对于期刊的下载次数与被引次数,尽管可以按照该方法,由所采集的期刊样本集来得到两个变量的样本对集合,并进行相应的相关系数计算以及假设检验,但是期刊的下载次数与被引次数作为随机变量未必服从正态分布。实际上,统计数据的经验考察结果往往表现为,对于下载次数较高(低)的期刊,其数量相对较少(多),从直观上频次的分布特征是与负指数分布较为吻合的,且能够较好地通过假设检验,对于期刊的被引次数同样有类似的情形。需要指出,期刊的下载次数是诸多影响因素共同作用的结果,包括期刊自身的学术质量、期刊所属学科的性质与发展状况、网络环境的改善与数字技术的更新以及用户的偏好等,所以下载次数的分布状况从直观上会有其复杂性;其次,虽然经验考察具有方法上的直观优势,但是在对一般性规律进行探讨时会有其局限性,对经验结果的深入理解以及对下载次数分布规律的本质探求需要对下载次数进行诸如基础模型的构建等解释性研究。尽管经验分析会有其不足,但是其结果至少能够从侧面反映,对于考察下载次数与其它文献计量指标的统计相关程度而言,简单相关分析会有其方法上的局限性,从而需要考虑到等级相关分析。[1,3]因为该方法适用于所考察的随机变量不服从正态分布或其分布为未知的情形。
图1给出了在特定学科中对应于不同下载次数的期刊数量,从另外一个角度来看,图1也是给出了在该学科中期刊具有不同的下载次数的概率分布,从而是将期刊的下载次数视为离散型随机变量,并给出了相应的分布列,由此可以求得在该学科中期刊下载次数的期望值,或是对期刊的下载次数进行估计,以及对不同学科属性的期刊下载特性进行比较。毕竟对于图书馆而言,不同学科属性的期刊效费比会有所不同,电子资源的购买与维护等成本需要与该电子资源的受利用程度相匹配,[4]而受利用的程度在不严格的意义下可以用下载次数来进行表征,这也是对电子期刊的下载状况进行考察的另外一个原因,特别是随着网络技术以及数字技术的发展,电子期刊因其在使用上所具有的便捷优势,使得图书馆往往会面临到这样的矛盾:一方面,用户对电子资源的使用偏好会导致对电子资源的使用量的逐渐增加,另一方面还需要考虑到电子资源的购置成本以及它对传统期刊购置经费的影响,[4]所以需要考察各类型电子期刊的效费比,以期为电子期刊的购置提供判据,目的是为了在经费给定的约束条件下实现资源配置的最优化。利用期刊下载次数的概率分布可以得到一些有意义的结论,诸如有80%的把握能够保证某学科期刊的下载次数不低于某数值,由此可用来估计该学科期刊的下载次数的下限,或者是某学科期刊的下载次数不低于某个计划数值的概率,即P(d≥a) =1-F(a),其中d为下载次数,a为计划数值,可以由该学科电子期刊的购置成本来进行计算,F为随机变量d的分布函数,具体的时间范围则要与概率分布的统计时间范围相一致。需要指出,图1的原始数据是取自CNKI镜像站,原始数据需要具有共同讨论的基础才能够进行相互间的比较,镜像站所提供的下载次数是期刊从其开始提供下载到统计截至时间的总的下载次数,但是不同期刊的入网时间会有差异,对于这种情形,在这里是采用统计对象为期刊的大样本集合且考察时间为足够长的方法,来尽可能消除由这种差异所带来的影响,毕竟截止于CNKI五年规划 (1999—2004) 的结束期,[5]CNKI在期刊网络出版方面的发展已经相对较为成熟,期刊的入网率也相对较高,从而能够近似保证原始数据相互之间的可比性。同时,如果期刊的下载量足够大,那么由误操作或是由人为提升下载次数等因素所带来的对统计特性的影响也可以忽略不计。另外,在图1中是对下载次数的取值范围进行了分区,并对各个小区间上的期刊分布状况分别进行了考察,因此是对下载次数进行了离散处理,这种方法有其直观性,但是也有其不足之处,毕竟期刊的下载次数在理论上是可以连续取值的,所以将下载次数视为连续型随机变量会更为合适。由此可以考察相应的连续型分布函数以及概率密度函数,而且这种连续性也使得微积分等数学工具可以运用进来,从而对下载次数的研究也可以更具可拓性。
2 期刊下载次数的布拉德福分布
布拉德福定律是文献计量学的基本规律,描述的是论文在所属期刊中的分布状况,体现了文献在相应期刊中的集中与分散状况的对立与统一。与期刊论文类似,期刊的下载次数同样可以视为期刊的信息产出,由此,进一步地,能否按照布拉德福定律来对期刊的下载次数进行考察,目的是为了得到关于下载次数的规律性认识,同时也能够使布拉德福定律的相关研究建立在更为宽泛的基础之上,对于该定律的理解也可以更为深入。
考察下载次数在期刊中的分布状况,如果按照布拉德福定律的分区描述,则需要考察以下命题是否成立,给定有限长的考察时段,将特定学科或是主题的期刊按照在该时段内被下载的次数降序排列;若对所得期刊列表进行分区,且使各分区对应的累积下载频次相同,则各分区的期刊累积数会构成等比数列。也即若将总的下载次数p等分,则存在实数r与k使得期刊列表中的前r份期刊、其后的rk以及后续的rk2、一直到最后的rkp-1份期刊都对应相同的累积下载频次M/p,且r+rk+rk2+...+rkp-1=N,其中M为下载总次数,k为布拉德福常数,N为期刊总数。也可以对累积下载频次与期刊累积数之间的函数关系进行考察,并进行相应的曲线拟合,[1-3]在这里我们采取同样的方法,但是更加侧重于不同学科属性之间的相互比较。
仍然利用图1的原始数据,同样是因为选取期刊大样本,且截止到2004年CNKI的期刊数字化生产能力能够达到每月6000种,已经占到了当时期刊总量的75%,具有较高的期刊入网率,[5]再加上考察时间较长等原因,所以在这里是忽略了期刊入网时间的差异所带来的影响,从而近似认为数据集合中各期刊的起始考察时间相同,故能够近似满足在布拉德福定律中针对各期刊的相同考察时段这一要求。那么,作为下载次数在相应期刊中分布状况的一种表现,由图1中的原始数据可以得到期刊的累积下载频次与期刊累积数之间的关系如图2所示,其中n为期刊累积数。
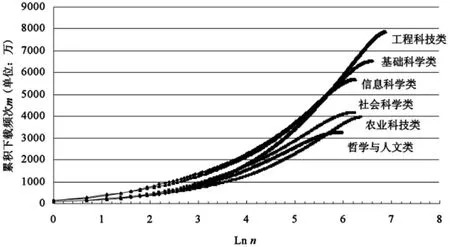
图2 累积下载频次与期刊累积数的关系图
在图2中,不同学科属性的Lnn与m之间的函数关系从直观上都能够与传统布拉德福定律的图像描述相吻合,而且格鲁斯下垂也能够纳入进来。同时曲线拟合的结果也与布鲁克斯公式相一致。例如对于基础科学类期刊,在布拉德福定律的分区描述中取p为3来确定期刊的核心区,所得核心以及非核心区的累计下载频次m与期刊累积数n之间的拟合关系分别为m=1866965.344n0.647以及m=18310431.901Lnn-53447472.841,核心与非核心区拟合结果的判定系数分别是0.977与0.994,且经F检验,是在显著性水平为0.05的条件下m与n之间分别存在幂函数以及对数函数关系。类似地,对于农业科技类期刊,核心与非核心区的拟合曲线分别为m=1108608.572n0.606以及m=12777331.067Lnn-40878815.751,且判定系数分别高达0.999与0.996,同样能够很好地通过假设检验,其它学科属性的期刊集合具有相似的拟合情形,所以从统计数据上看,可以认为下载次数在期刊中的布拉德福分布特性达到了显著水平,而这与下载次数的已有结论是相吻合的,[1-3]这种一致性也能够从侧面反映出原始数据的选取具有一定的合理性。
图2描述了期刊累积数与累积下载频次之间的关系,更确切地说,是累积下载频次随期刊累积数的增长情况,从直观上看,图2所显示的函数关系有一定的聚类特征,分别是{社会科学类、农业科技类、哲学与人文类},{基础科学类、信息科学类},以及{工程科技类}。在期刊累积数偏低的区域,基础科学类与信息科学类期刊的累积下载频次相对较高,一种可能的解释是,这两类学科属性往往会吸引更多的研究资源,从而产出的文献也会相对较多,所以与学科对应的下载频次或是累积下载频次亦会相对较高。而对于工程科技类期刊,尽管从其学科属性上来看应当具有类似的情形,但实际上,与期刊累积数偏低区域对应的累积下载次数却相对较少,且归属于{社会科学类、农业科技类、哲学与人文类}的情形,究其原因可能是由于该类学科有其自身独特的性质。在图2中,期刊首先是按照下载次数降序排列,然后才是对期刊累积数以及累积下载频次的计算,所以期刊累积数偏低的区域是与下载频次较高的期刊相对应的,因此对于工程科技类期刊,图2实际上是反映了按下载次数排名靠前的期刊,对应的论文数量相对较少。由于从直观上看,期刊的下载频次同样可以作为对期刊学术价值的一种侧面反映而被纳入到评价指标体系,而且按照上述的等级相关分析,对于本文所采用的镜像站原始数据集而言,期刊的下载频次与其被引频次之间存在一定的正相关性,所以不妨在这里近似认为期刊的下载频次能够在一定程度上与期刊的学术价值相对应。由此,图2也意味着对于工程科技类中评价较高的期刊,其论文数量会相对较少,一种可能的原因是:工程科技类的优秀成果并不一定总是以论文形式来给出的,相反,专利、程序包、实验系统,以及技术报告等成果形式所占的比例往往会很高,工程科技类学科属性所具有的这种特征使得该学科的优秀研究成果在其表现形式上可以有更多的选择方式,从而会造成从论文形式中的分流;另一个原因则是与工程科技类学科属性所可能具有的涉密性有关,保密要求会限制相关成果以论文等形式来公开发表,从而进一步增加了采取专利、内部科研报告等非公开形式的可能性,而且优秀的工程科技类成果往往会伴随着较高的密级。这类科研成果仅就其自身的学术质量而言本可以发表在评价较高的期刊上,但是实际上会受到一定的出版限制,所以对于工程科技类学科属性,在期刊累积数偏低的区域,科研产出并未像基础科学以及信息科学类那样更多地以论文形式来体现。
类似地,由于期刊是按照下载次数降序排列的,所以期刊累积数的逐渐居中也就意味着期刊的类型是从评价较高的期刊逐渐向评价一般的期刊来进行转变。在图2中期刊累积数居中的阶段,工程科技类学科的累积下载频次开始脱离{社会科学类、农业科技类、哲学与人文类}区域,并向{基础科学类、信息科学类}区域过渡,一方面的原因是由于工程科技类的阶段性成果以及一般的成果采取专利、技术报告等具有总结意义的产出形式在通常情况下并不合适,相反以论文作为科研产出在此时则显得相对较为适宜。同时,阶段性或是一般的成果更可能地是发表在评价相对一般的期刊上,所以此时其他成果形式的分流作用会逐渐减弱,或者说与期刊累积数偏低的区域相比论文形式的产出得到了有效释放,评价一般的期刊的论文数量也会相对较多,从而下载次数以及累积下载次数也会相应地有所增加。另一方面的原因则是在期刊累积数居中的阶段,阶段性或是一般的工程科技类成果与优秀的成果相比,其密级在通常情况下会相对较低,相应地,这类科研成果在其产出形式上所受到的出版限制也会有所减弱,从而在一定程度上会造成从内部科研报告等非公开形式向期刊论文形式的回流,由此论文的数量会相应有所增加,对期刊的下载量也会有正面的影响。
在期刊累积数偏高的区域,工程科技类期刊的累积下载频次已经归属于{基础科学类、信息科学类}所在的区域,究其原因,相类似地可能是由于论文产出的进一步释放,而另一方面则是考虑到该学科属性自身的实际发展规模,从而所得期刊下载频次的经验表象具有一定的合理性。
另外,传统的布拉德福定律描述了文献在所属期刊中的集中与分散现象,相类似地,期刊下载次数的布拉德福分布特性则意味着,对于特定的学科或主题,存在少部分的期刊下载频次会相对较高,同时也存在着大量的期刊,其下载次数会相对较少。以上图2考察的是期刊与下载频次这两个对象的累积数,体现的是两变量的绝对量之间的关系,为了更好地反映下载次数在期刊中的分布状况,则需要考察这两个变量的相对量,也即下载频次累积百分比与期刊累积百分比之间的关系,如图3所示。
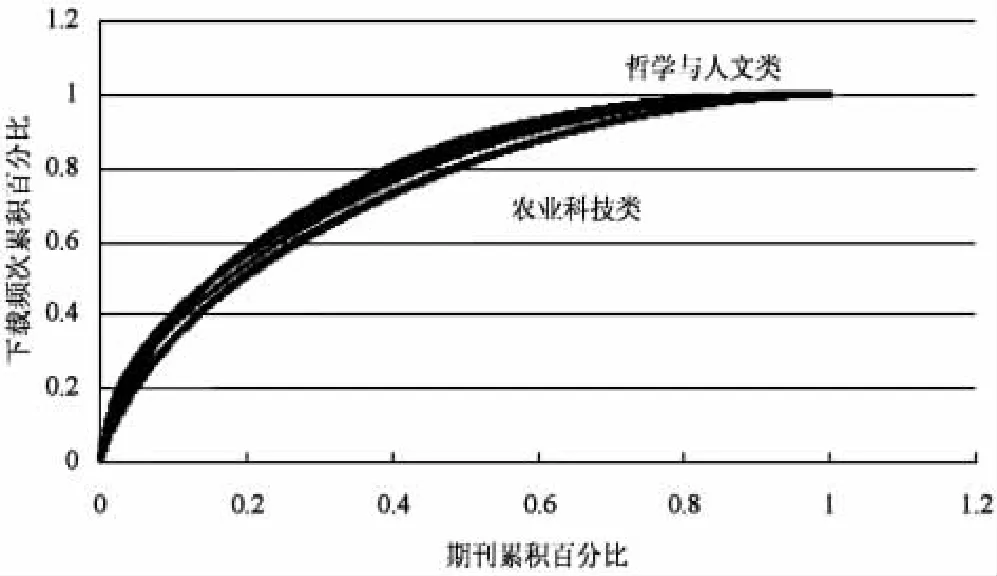
图3 下载频次与期刊的累积百分比关系图
从直观上看,累积比重之间的函数关系是随着学科属性的不同而在较为狭窄的范围内变动,变动范围的上下界分别为农业科技类以及哲学与人文类的情形,与图2类似,所得累积比重之间的关系是建立在对期刊按照下载次数降序排列的基础之上,所以函数关系向上弯曲的程度越高则意味着下载次数在期刊中的分布就越集中,极限的情况是图中点(0,0)、(0,1)以及(1,1)的连线,对于这种情形,仅一份期刊能够就与其所属学科的总的下载次数相对应。若不严格地,在图3中,期刊与下载频次累积百分比之间的关系受学科因素的影响似乎并不显著,一种可能的原因是由于科学的统一性,理论与实践共同形成的正反馈机制不仅促使着人们对自然以及社会的规律性内容进行探求,而且也推动着已有规律性认识的分化与综合,这种认识上的分化或是认识精细程度的增加会孕育着相应专门学科的产生,所以种种学科有其同一性的基础,而且专门学科的进一步细化或是分支现象也不影响这种性质。学科的发展往往会经历萌芽、成长以及成熟等阶段,学科从其独立到最终的成熟,研究方法上的形而下学趋势会使得研究对象更具多样性,而研究内容的宽泛化则可能会导致学科的进一步分化,以至该学科的下属分支学科的产生,比如牛顿—莱布尼茨公式体现了微积分的基本内涵,如果按照这种内涵并将考察变量的取值范围从实数域拓展到复数域,则相应地会有复变函数的产生,毕竟复数域有其自身独特的性质,而该过程的驱动力仍然是理论与实践所形成的正反馈机制,仍然是出自对自然规律的进一步认识,毕竟对于复数域的连续性考察有其实际意义。较为根本地,对学科间具备同一性的认同也是建立在对大统一理论存在的信仰基础之上的。而对于不同的学科属性,学科之间的同一性会使得下载次数在期刊中的分布状况有趋于一致的倾向,最起码地,如果考察极端的情形,即所讨论的学科实为同一学科或者是具有相同的学科属性,那么下载次数在期刊中的分布状况当然也会相同,累积比重之间的函数关系则相互重合。更何况,随着学科之间交叉程度的上升,相互间的同一性趋势也会逐渐增强。进一步地,例如存在两类属性不同的学科,按照上文中对布拉德福定律的分区描述,如果给定分区数p,所得的参数k则可以用来对下载次数在期刊中分散或是集中的程度做近似的描述,对于这两类学科,不妨设相应的参数分别为k1和k2,假设存在某一学科,且该学科的期刊与下载次数为这两类学科的并集,或者说是将这两类学科按照同一学科来进行处理,则此时需要对该学科(属性)的期刊以及相应的下载次数重新进行分区,将初始两学科的期刊列表合并且同样按照下载次数降序排列。如果此时仍然服从布拉德福定律,那么可以求得该学科的k参数,假设埃格希和鲁索给出的k=(eγym)1/p对于下载频次也同样适用,其中ym相应地为期刊的最大下载频次,γ为欧拉常数,那么在p给定的情况下该学科的k值应取k1或是k2。由此该学科与除了初始两学科以外的其它学科之间的k值差异没有得到扩大,而且初始两学科的k值差异在该学科中也得到了消除。所以从整体上看,各学科间集中或是分散程度的区别会有所减少,从而从侧面说明了学科之间的同一性对于学科之间k值差异的缩减作用,以及同一性对于k值的变化有其约束作用。
造成图3中下载次数在期刊中的分布状况随学科的不同变化相对不大的另外一个原因,则可能与期刊下载次数这个统计变量自身有关。随着网络与数字技术的发展,各个学科所面临的相同下载环境使得期刊的下载特征可能会具有一定的共性;另一方面,期刊的下载次数反映的是期刊的受利用程度,由于各个学科之间的交叉与融合,期刊的使用会存在一定的联动性,从而与期刊的被引频次相比,关于下载次数的累积比重之间的函数关系会有趋于一致的倾向,毕竟期刊的被引频次是与期刊的学术价值相对应。再者,在各类学科中,下载次数在期刊中的分散程度在一般情况下要比被引频次的分散程度要高,究其原因,首先是因为这两者分别是与期刊的利用以及学术价值两个概念相对应,与后者相比,前一个概念自身就具有相对较强的期刊分散性;另一方面则是由于在网络环境下评价一般的期刊的获取便捷性、分散性的增加意味着排序靠后的期刊受到了更多的重视,而这部分期刊恰恰是多具交叉或是融合特性的期刊,而非专门面向某个学科的期刊,所以各学科期刊的受利用程度或是下载次数的联动性会进一步得到增强。
3 结束语
从理论上说,期刊下载次数的概率分布对于下载次数的统计性质研究会具有一定的基础意义,例如这里对下载次数在期刊中的布拉德福分布所进行的考察就会对其有所涉及。针对所选取的原始数据,不同学科属性的期刊下载次数从直观上都能够较为显著地表现出布拉德福分布的特征,当然具体的分布状况也会随着学科属性的不同而存在一定的差异,需要对这种学科性差异进行分析与解释,以期对下载次数这个随机变量可以有更为深入的认识,毕竟从直观上看,下载次数的统计性质与期刊所属学科包括学科的类型以及学科的不同发展阶段、期刊及其论文的学术价值、网络以及数字技术的发展等因素具有较强的相关性,或者说期刊下载次数所表现出来的统计性质是这些影响因素所共同作用的结果,对各个自变量的变化所导致的因变量的改变进行考察是为进一步建立变量相互之间的定量关系作准备。
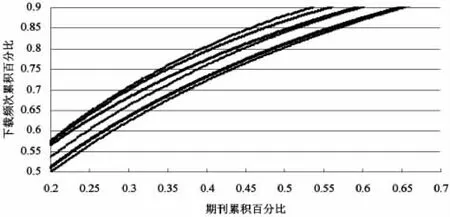
图4 下载频次与期刊的累积百分比关系图(截取自图3)
在图3中,尽管学科因素的影响从直观上看并不是十分显著,但若是更为精确地,对于期刊与下载次数的累积比重之间的函数关系,仍然需要对其所受到的学科因素的影响来进行探讨,毕竟对于不同的学科属性,下载次数的集中或是分散的程度也会有所不同。另外,图3中较为狭窄的变化范围也从侧面反映了学科之间统一性以及差异性的对立与统一。
在图4中,学科属性自上而下依次为哲学与人文类、社会科学类、基础科学类、信息科学类、工程科技类以及农业科技类,对于这种学科之间的排列关系以及从直观上可能会存在的聚类关系等表象还需要作进一步的探讨,而且需要指出,经验考察的精确度提高往往需要对原始数据进行更为严格的选取,包括选取的范围、原则以及过程等,从而使统计结果或是所得经验表象可以更具合理性,置信度也能够得到提高。
[1]张洋.期刊Web下载总频次的布拉德福分布研究[J].图书情报知识,2006(6):38-42,60.
[2]万锦堃,等.期刊论文被引用及其Web全文下载的文献计量分析[J].现代图书情报技术,2005(4):58-62.
[3]庞景安.中文科技期刊下载计量指标与引用计量指标的比较研究[J].情报理论与实践,2006,29(1):44-48.
[4]刘丽丽编译,强自力审校.利用电子期刊使用量的比较研究评价“大宗交易”[EB/OL].[2009-04-19].http://162.105.140.111/info/detail.asp?str-TypeCode=publish_73&lngID=430.
[5]王明亮,等.中国知识基础设施工程五年规划的可行性研究[C]//第二届海峡两岸科技资讯研讨会暨第十三届全国计算机情报管理学术研讨会论文集.北京:中国科学技术情报学会,1999:113-122.
