基于Java的代码混淆算法研究
2010-05-09李新良罗戈夕
李新良,罗戈夕
基于Java的代码混淆算法研究
李新良1,罗戈夕2
(1. 娄底职业技术学院 电子信息工程系, 湖南 娄底, 417000; 2. 涟源钢铁集团有限公司 信息自动化中心, 湖南 娄底, 417000)
首先介绍了混淆技术的现状、原理及分类,然后对标识符重命名的4种算法进行了深入研究,通过对算法的伪代码和性能分析,证明了4种混淆算法具有很好的混淆效果,能够很好地保护Java软件,为Java软件的反编译和逆向工程提高了程序复杂度、抗攻击能力,且不增加程序额外的执行开销. 本文研究的算法对移动代码和软件知识产权的保护能起到积极作用.
反编译;代码混淆;标识符重命名混淆
在分布式计算环境下,一个软件系统可能被部署在多台主机上,而这些主机并不能保证都是完全可信赖的. 在恶意主机环境下,软件系统可以被逆向工程或被篡改,其机密性、完整性与可用性受到威胁. 为了防止恶意主机对移动代理[1]有目的的篡改,代码混淆技术被提出,其基本做法是使用代码混淆技术对软件的代码进行混淆变换,使混淆变换后代码的分析难度增加,从而在一定程度上阻止对软件的篡改. 代码混淆技术实际上是一种用于对移动代码保护和软件知识产权进行保护的安全技术. 在实际应用中,对软件提供绝对的安全保护是不可能,也是没有必要的,只要能使攻击者的攻击付出较高的代价,就可以认为混淆技术达到了安全保护的作用. 因此,代码混淆技术就成为保护Java软件的有效且容易实现的保护技术. 通过对Java字节码混淆技术进行研究,可以保护Java软件开发者的知识产权,并保障信息安全. 同时在研究过程中发现新问题,在解决新问题的过程中也可以推动计算机科学的发展.
1 国内外混淆技术研究现状
对代码混淆技术的研究始于上世纪90年代,由Java语言的迅速发展而引起. 从1997年开始Collbe- rg等人[2]就对代码混淆技术进行了深入的基础性研究,并陆续发表了多篇文章,后来又有更多的人加入到代码混淆技术研究的队伍中,他们提出了许多好的混淆算法和研究方向,对代码混淆技术的发展起到了重要的作用. Collberg等人[2]给出了代码混淆变换的各种类型,以及代码混淆算法构造的具体过程,同时实现了针对Java字节码的混淆算法,后来Kelly等人[3]构造了一种混淆执行体机制,可以自动实现构造代码混淆算法,Tyma等人[3]根据Java语言的特点,提出了一种新的外形混淆技术.
最近国内的一些学者也认识到代码混淆技术在软件保护方面的重要性,并做了一些研究,比如,李永祥等人[4]提出并实现了多分支语句的控制流迷惑技术和基于函数指针数组的迷惑技术,李长青[5]等人提出了执行流重整混淆算法,高鹰[6]等人提出了基于抽象解释的代码迷惑有效性比较框架.同时也有一些学校或组织对代码混淆技术进行了研究和探索,如西北大学[7]、北京交通大学[8]、北京邮电大学[9]等. 目前对代码混淆的研究工作主要是基于软件保护的.
从上面介绍的国内外混淆技术的研究现状可以看出,由于代码混淆技术重要的应用前景使得越来越多的计算机科学工作者认识到了它的重要性,并且已经做了大量的研究,我们相信在不久的将来会有越来越多的人和机构参与到代码混淆技术研究的队伍中来.
本文提出基于标识符重命名混淆技术,并提出4种标识符重命名混淆算法,包括滥用标识符、重载无关联方法、非法标识符替换以及重写静态方法. 对混淆算法功能有效性和产生的性能过载进行简单分析,使用该技术能使攻击者的攻击付出较高的代价,从而达到了安全保护目的.
2 软件混淆技术介绍
2.1 混淆变换原理
代码混淆技术是一种重要的软件保护方法,其实质是指对应用程序P进行保持语义的变换T,使得变换后的程序P′和原来的程序P具有相同的功能,即如果P错误地终止或不能终止,则P′也错误地终止或不能终止,否则,P′必须终止且产生与P相同的输出结果,经过混淆后的P′则更难被静态分析和逆向工程所攻击[10]. 具体的原理如图1所示. 由图1可以看出,混淆后程序P′由源程序P经混淆变换T处理后得到,在对P′和P给予相同的输出A后都得到了相同的输出B,在这种情况下,源程序P的任何非功能性信息都被丢失,从而增加了对程序的分析难度,有效地保护了软件.
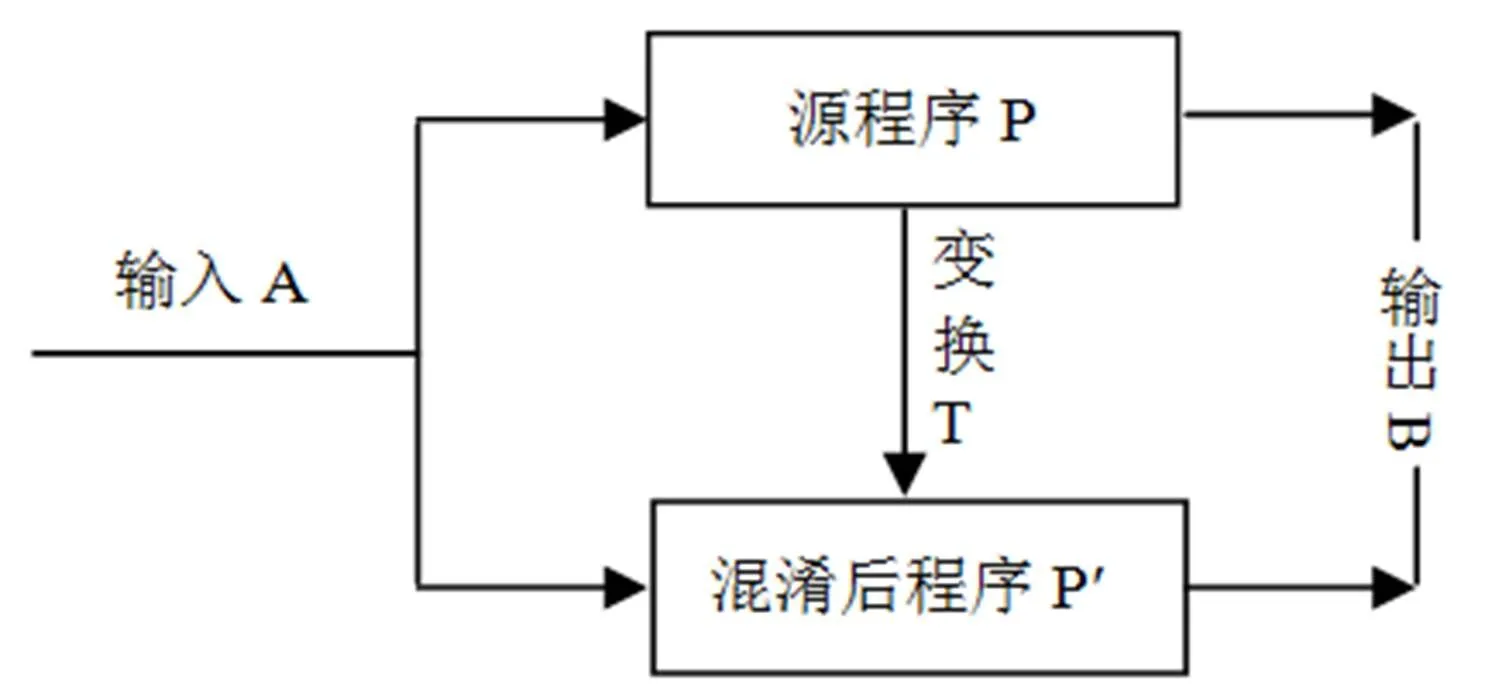
图1 混淆变换原理图
2.2 代码混淆的性能指标
对程序作混淆变换后的效果如何,通常从强度(potency)、耐受性(resilience)、开销(cost)、隐蔽性(stealth)等4个方面来评估. 强度是指混淆变换究竟给原始的程序加上了多大的复杂度; 耐受性是指变换后的程序对使用自动去混淆工具进行攻击的抵抗度; 开销是指经过混淆变换后的程序在执行时由变换所带来的额外执行时间和所需存储空间开销; 隐蔽性是与程序的上下文高度相关的.
2.3 混淆的分类
根据混淆对象和原理的不同,可将代码混淆技术分为外形混淆、数据混淆、控制混淆和预防混淆4种.
外形混淆. 外形混淆的基本原理是对函数和变量的名称进行替换,使其违背见名知义的软件工程原则,从而达到增大攻击难度的目的. 外形混淆是当前Java混淆器所使用的典型方法. 这种混淆变换去除了Java类文件中所包含的源代码格式信息,它是一种“单向”变换,因为最初的格式信息一旦被移除,就无法再次恢复. 由于这种变换没有任何额外执行代价,因此程序的时间和空间复杂度将不会受到任何影响. 目前的Java字节码混淆工具大多支持这一功能,可见外形混淆具有良好的可行性. 外形混淆有很多分类,其中标识符重命名混淆是它的一个很重要的分支. 标识符重命名技术的基本原理是使用简单无意义的名字或特殊的名字替换源程序字节码中的标识符. 在本文下面的章节中将主要研究这种标识符重命名混淆技术.
数据混淆. 数据混淆是利用数据流分析中难点问题,向程序中引入引起程序分析精度降低或难度增加的一些因素,从而影响对程序的分析结果. 由于正常的程序以符合逻辑的方式来组织数据,因此为了增加攻击者获取信息的难度,实现对程序的有效混淆,数据混淆将不对程序的代码进行特意修改, 只针对程序中出现的各种数据结构进行变换.
控制混淆. 控制混淆是一种被广泛使用的代码混淆方法,其基本原理是通过改变程序的判断条件, 或向程序中添加可控的判断条件来增加程序的复杂度, 并且可以通过对程序的结构和执行流程的调
整来增加反编译工具对程序的反编译时间.
预防混淆. 预防混淆通常针对一些专用的反编译工具而设计. 一般情况下,预防混淆技术利用反编译工具的弱点来设计混淆方案.
下面对4种混淆技术进行简单的分析,外形混淆主要应用于迷惑解读程序的攻击者,同时在抵抗反编译工具领域也起到一定作用;数据混淆目前主要针对的是对布尔变量的替换;控制混淆是应用比较广泛的一种混淆技术,主要是通过增加程序的复杂度来增强程序的抗攻击能力;预防混淆是针对不同的反编译软件而设计的.
数据混淆和控制混淆为了提高混淆后程序的复杂度,通常都会在程序中引入大量的布尔变量或源程序以外的结构,大大增加了程序的代码量和程序的时空执行开销,虽然也增加了程序抗攻击性, 但程序的执行效率也大大降低. 而一般的外形混淆技术虽然没有增加程序的执行开销,但程序的复杂度却不高.
因此,根据上面的分析,本文将研究一种既能提高程序抗攻击能力,同时也不会降低程序执行效率的混淆技术,即标识符重命名混淆技术,该混淆技术是外形混淆的一个重要研究方向.
3 标识符重命名混淆算法研究
标识符重命名混淆的基本原理是使用简单无意义的名字替换字节码文件中的类名、接口名、方法名以及字段名等. 当前的标识符重命名混淆技术只对字节码中的标识符进行简单的名字替换,虽然没有引入额外的执行开销,但抗攻击能力不高. 为了弥补以上情况的不足,本节将提出4种标识符重命名混淆算法,这4种混淆算法具有较高的抗攻击能力,同时也不会带来额外的执行开销.
3.1 重命名的目的
重命名方法的目的是使大型的Java程序更难理解或者更难被反编译,但不会引入程序的额外执行开销. 首先,这些原始的标识符被一些无意义或者混乱的标识符代替,使得攻击者要想恢复这些原始的标识符变得不可能,因为跟标识符相关的信息在重命名后完全消失. 另外,这种方法也使得一个反编译器将字节码文件转换成Java源代码变得很困难甚至不可能,或者使被反编译的源代码不能被重新编译. 在这2种情况下,对标识符进行重命名并不会影响被混淆程序的行为.
3.2 代码混淆的范围
代码混淆的范围即在一个应用程序中能被混淆工具混淆的那部分代码就是程序的混淆范围,一般情况下只有程序员自己开发的代码部分才会被保护,而标准库和第三方库中的代码不会被保护. 但是混淆的范围并不会只局限于程序员自己写的代码部分,而用到的标准库和第三方库中的代码也可以被包含到混淆的范围中,但需要取得标准库和第三方库的所属组织或个人的同意. 默认情况下,参数标识符和本地变量不在这一混淆系列中,因为当字节码被编译的时候这些信息将会被剥离掉. 一个程序的混淆范围可以通过对程序中所有的标识符分组来建立,然后剔除掉那些在重命名后会带来错误或者误差行为的标识符.
3.3 标识符重命名混淆算法
以前提到的基于标识符重命名的混淆技术所使用的普遍方法是,尽可能重复地使用相同的标识符来重命名在Java字节码混淆范围内的标识符. 由于这些标识符的冗余度,攻击者很难理解被反编译的程序. 此外,通过检查使用同一标识符的无关实体, 反编译器也会被欺骗. 我们所期望的效果是, 现存的反编译技术很难或者完全不能对混淆过的程序反编译,因此攻击者不得不花费更多时间去理解和手工调试被反编译的程序. 事实上,可以通过灵巧地对Java字节码中标识很难或者完全不能对混淆过的程序反编译,因此攻击者不得不花费更多时问去理解和手工调试被反编译的程序. 事实上, 可以通过灵巧地对Java字节码中标识符重命名来达到这样的效果. 因此本节提出了4种标识符重命名算法. 表1给出了4种算法伪代码实现中用到的主要符号.

表1 算法中使用的主要符号

(续表1)
3.3.1 滥用标识符算法
Java源程序被编译成Java字节码后仍然保留着类、接口、方法等的名字信息,而字节码被反编译后这些名字信息依然清晰可见(例如方法名:getNa- me),因此攻击者很容易读懂反编译后的程序. 为了阻止解读程序的静态攻击者,就需要对字节码中的标识符进行重命名,因此就出现了滥用标识符混淆技术[5]. 滥用标识符混淆技术是通过对Java字节码中的标识符重命名来实现的,其目的是最大限度地重复使用同一个标识符代替一个类中出现的所有标识符. 该策略之所以能够迷惑攻击者,是因为攻击者不得不去理解被反编译程序中出现的每个标识符的行为,同时,标识符所表示的意思跟它出现的上下文有关. 滥用标识符算法使用随机生成的名字替换混淆范围内的标识符,随机生成名字的机制是:首先使用随机生成的单个字母进行替换,如果同一个包中类的个数大于能够使用的字母个数,则剩余类中的标识符将会使用2个字母的随机组合进行替换,以此类推,使用3个字母、4个字母以及更多个字母的随机组合进行替换. 随机生成的名字根本没有规律可循,因此提高了静态攻击的难度,延长程序破解的时间. 下面是算法的伪代码实现:
算法1:
输入:混淆前程序
输出:混淆后程序
l Foreach C in P //遍历每个包中的类或接口
2 s=random() //随机生成名字
3 Replace C with S //使用S替换遍历过的每个类或接口名
4 Put C<->s into mapping文件//保存映射关系
5 Foreach m in C//遍历类或接口C中的所有成员
6 Replace m with s //用s替换遍历到的m
7 Put m<->s into mapping文件
8 Foreach t in S //遍历继承关系集合S
9 If t equals m //如果m和t具有继承关系
10 Replace t 对应的子类或超类with S //用上面生成S替换t
11 Put t<->s into mapping文件
12 根据mapping文件更新跟混淆内容有关的字节码文件和重写P
13 end
3.3.2 重载无关联方法算法
重载无关联方法的混淆方法,通过使用相同的标识符重命名被混淆类中的所有实体方法实现,这种方法在任何情况下都适用. 而这种改变并不影响字节码的行为,因为Java程序中的方法实体,在执行混淆操作之前的某个编译时刻通过一个象征性的参考, 必然会被执行. 相反,如果用这种混淆方法操作过的程序被反编译并被重新编译执行时,这种改变将会彻底改变程序的行为.
为了解释上面这种情况,假设在源代码中有这样的方法,这些方法的名字截然不同,但参数类型和个数完全相同. 通过对这些方法用相同的名字重命名后,这些方法将变成重载方法. 现在,重新编译的时侯,源代码中这些重载方法被处理时将会变得很棘手,此时,Java编译器不得不选择那些能够和参数类型完全匹配的重载方法. 事实上,并不能保证原始(即正确)的方法会被编译器选择,因为可能会有和输入类型能够更好匹配的其它方法存在. 重载无关联方法的混淆算法不仅使类中的方法具有了重载关系,同时避免了破坏超类和子类之间的继承关系. 下面是该算法的伪代码实现.
算法2:
输入:混淆前程序
输出:混淆后程序
1 Foreach C in P //遍历每个包中的类或接口
2 s=random() //随机生成名字
3 Replace C with s //用s替换类或接口名
4 Put C<->s into mapping文件//保存映射关系
5 Foreach m in C
6 Replace m with s //用S替换类成员
7 Put m<->s into mapping文件
8 根据集合O,将具有重写关系的方法用上面生成的S代替
9 根据mapping文件更新跟混淆内容有关的字节码文件和重写P
10 End
3.3.3 非法标识符替换算法
前面提出的2种标识符混淆算法增加了攻击者对程序的解读难度, 下面提出的标识符混淆算法将会增加反编译工具的反编译难度. 非法标识符替换合法标识符的混淆算伪代码实现如下.
算法3:
输入:混淆前程序
输出:混淆后程序
l Foreach C in P //遍历每个包中的类或接口
2 p=produce(key[],Illeagal[]) //生成关键字跟非法字符串结合的名字
3 Replace C with P //名字替换
4 Put C<->p into mapping文件∥保存映射关系
5 Foreach m in C
6 Replace m with P //使用P替换类成员
7 Put m<->p to mapping文件
8 根据mapping文件更新跟混淆内容有关的字节码文件和重写P
9 End
3.3.4 重写静态方法算法
Java语言规范规定,超类中的静态方法不能被子类中的实体方法重写,相反,超类中的实体方法也不能被子类中的静态方法重写. 而Java字节码中并没有这种限制,在这种情况下,静态方法和实例方法之间不存在任何模棱两可,因为Java虚拟机使用不同的指令来调用它们中的任意一个. 因此,在这种情况下出现了重写静态方法的混淆算法,对静态方法重命名的混淆方法,会处理一系列被编译过的Java类,并且在任何可能的情况下,都可以使用定义在一个超类以及具有相同数量和形参的实例方法的名字来重命名静态方法. 反编译存在实例方法被静态方法重写的混淆代码,将会产生一种不正确的Java源代码.
以前提出的重写静态方法的策略,仅仅单纯地使用实例方法或静态方法重写超类或子类中的静态方法或实体方法,虽然也增加了反编译工具的破解难度,但仍然容易被有经验的攻击者觉察. 而本文提出的重写静态方法混淆算法在此基础之上对重写的方法进行了修改,使得修改后的重写方法稍微不同于被重写的方法,这种细微的修改使得混淆变化不易被察觉,这样也就额外地增加了静态攻击者的难度. 下面是重写静态方法混淆算法的伪代码实现:
算法4:
输入:混淆前程序
输出:混淆后程序
1 Foreach t in S //遍历继承关系集合中的类t
2 Foreach s_m in t //遍历类t中的静态或实体方法
3 If s_m is 静态方法and u_m 存在//如果s_m是静态方法并且跟t对应的子类中存在相同签名的实体方法
4 s=random() //生成随机名字
5 Replace u_m and s_m with S //使用相同的名字替换u_m和s_m
6 Put s<->u_m and s<->s_m to mapping文件
7 else
8 If s_m is静态(或实体)方法//如果u_m不存在
9 s_m’=produceFakeMethod(s_m) //伪造同s_m相似的方法
10 Add s_m’to t’ //将伪造的方法插入到类t的超类或子类t’中
11 根据mapping文件更新跟混淆内容有关的字节码文件和重写P
12 End
3.4 算法分析
程序执行开销是衡量一个混淆方法性能好坏的重要指标. 本文提出的滥用标识符混淆算法和重载无关联方法混淆算法,主要致力于消除字节码常量池中的象征性信息,而非法标识符替换和重写静态方法这2种混淆算法将会使被反编译的程序产生语法和语义错误. 前两种混淆算法主要是针对静态攻击而设计的,由它们混淆过的字节码被反编译后生成的代码对于解读程序的攻击者来说更难理解, 同时由于使用简短的名字代替原来的名字,字节码文件变得更小. 后2种混淆算法主要是针对反编译工具而设计的,被这2种算法混淆过的字节码被反编译且重新编译的时候会产生编译错误,以至攻击者不得不花费大量的时间和精力调试被反编译的程序.
因此,本文提出的混淆算法在保证混淆后程序复杂度的前提下,减小了字节码大小和程序的加载时间,最终降低程序的执行开销.
4 结论
本文首先分析了代码混淆技术的现状、原理及分类,指出了标识符重命名混淆技术的目的, 然后介绍了重命名混淆的范围. 最后提出了滥用标识符、重载无关联方法、非法标识符替换和重写静态方法4种标识符重命名混淆算法. 通过对提出算法的性能分析,证明了4种混淆算法具有很好的混淆效果,因此能够很好地保护Java软件.
[1] 朱正平. 移动代理安全之代码迷惑技术研究[D]. 南宁:广西大学,2006.
[2] Collberg C, Thomborson C, Low D. A Taxonomy of Obfuscating Transformations[R]. New Zealand: DePt. of Computer Science,University of Auckland, 1997.
[3] Barak B, Goldreich O, Impagliazzo R, et al. On the (Im) possibility of obfuscating Programs[A]. Advances in Cryptology-Crypto 2001[C]. USA: Springer-Verlag, 2001: 57-59.
[4] 李永祥. 代码迷惑技术研究[D]. 合肥: 中国科学技术大学, 2005.
[5] 李长青,李晓永,韩臻. 基于控制转换的软件保护研究[J]. 信息安全与通信保密, 2006(10): 146-149.
[6] 高鹰, 陈意云. 基于抽象解释的代码迷惑有效性比较框架[J]. 计算机学报, 2007, 30(5): 806-808.
[7] 宋亚奇. 基于代码混淆的软件保护技术研究[D]. 西安:西北大学, 2005.
[8] 李长青. 基于控制转换的混淆器构造[D]. 北京: 北京交通大学, 2006.
[9] 王飞. Java软件保护技术研究及实现[D]. 北京: 北京邮电大学, 2007.
[10] 刁俊峰. 软件安全中的若干关键技术研究[D]. 北京: 北京邮电大学, 2007.
The study of Java code obfuscation algorithm
LI Xin- liang1, LUO Ge-xi2
(1. Departmen of Electronic and Information Engineering, Loudi Vocational and Technical College, Loudi 417000,China; 2. Information Center, Lianyuan Steel Co.Ltd, Loudi 417000,China)
The status of confusing technology, principles and classification was introduced, and then the identifier rename the four algorithm was studied deeply. Based on the algorithm of pseudo-code and performance analysis, it proven that four kinds of confusion algorithm had very good effect of confusion, and perfectly protected Java software, the software for Java decompilation and reverse engineering to improve the process capability, complexity, and attack the additional costs increased program execution. The algorithm is studied in this paper for mobile code and software protection of intellectual property rights can play a positive role.
de-compilation;code obfuscation; identifier renaming obfuscation
TP 309
A
1672-6146(2010)03-0064-06
10.3969/j.issn.1672-6146.2010.03.017
2010-07-13
李新良(1974-), 女,副教授,硕士研究生,研究方向为软件开发与软件测试.
