WISKI在降水量合理性检验中的应用研究
2010-04-25赵学丽王亚娟
蔡 乐,赵学丽,王亚娟
(北京市水文总站,100089,北京)
降水的形成机制和预报属于气象工作的研究内容,水文工作研究降水量时空分布特征和降水资料的整理及应用。降水量合理性检验是判断降水量数据异常的有效方法,也是发布实时水情信息和降水量资料整编的重要前提。传统的降水量合理性检验完全由人工完成,由于数据量很大,检验方法规则不统一,插补方式因人而异,从而导致效率低,数据的可靠性和准确性受到影响。因此,结合计算机的使用,寻求一种高效的降水量数据处理平台,对水情发报和资料整编都具有重要意义。
2007年引进的水文水环境基础信息管理系统(Water Management Information System Kisters,简称 WISKI)成功应用于北京水文、地下水、水环境业务系统。WISKI由德国Kisters公司研发,经过20多年的开发与应用,已成为一个比较完善的软件产品。该产品具有强大的业务扩展功能,可根据具体工作需要进行二次开发,进而配置出符合实际要求的各类统计、分析和纠错功能。WISKI平台的成功搭建为雨量合理性检验和插补工作提供了充分条件,同时也为寻求一种全新的水文数据整理模式提供了探索空间。
一、基本思路
WISKI系统在时序数据的基本运算和数据生成方面有独特之处,具有较强的整体功能和完整性。WISKI本身没有提供降水量合理性检测的解决方案,但它提供了时序计算平台和一系列通用的时序计算方法,可根据需求进行系统的二次开发,使得降水量合理性检验的适应性和灵活性更强。
根据合理性检验的需求,以独立的雨量站降水量时序为基本单位,选取相关性最好的雨量站作为关联站,进行每场次降水量数据的横向比较,通过数据值之间的定量关系判别异常数据类型,从而完成降水量合理性检验,完整实施流程见图1。
1.数据采集与错误数据类型

图1 WISKI进行降水量合理性分析流程图

表1 40a长时间序列雨量站之间相关系数所占总体百分比分布表
目前,北京市水文总站在全市范围内建设了121个遥测雨量站,雨量传感器的分辨率为0.5mm,并且在雨水情系统建设中首次使用了CDMA—1X网络作为主信道、GSM为备用信道的传输方案,针对目前的硬件设施情况和近年的使用经验,遥测降水量数据的错误主要有以下几种类型:
①迁站引起数据缺失。由于山区房屋改造,遥测雨量站被迫迁站而引起数据缺失。
②仪器堵塞引起数据异常。遥测仪器出现堵塞,会造成一次降水后遥测数据连续多日维持在一个较小值范围内,或者无遥测数据。
③设备故障引起数据异常。由于设备故障,在较长时间内没有遥测数据。
④人为注水调试引起数据异常。人为注水调试的数据一般会人工剔除,但也不免遗漏未剔除的人工注水数据。
⑤RTU硬件原因导致数据异常。由RTU的硬件原因导致的异常,主要表现为“跳数”,即数据出现较大的波动。
降水量合理性检验的核心工作就是对有以上问题而导致的异常数据值进行排查。
2.关联雨量站的选取
(1)相关系数的计算
传统人工进行雨量合理性检验是将同流域或者邻近雨量站之间的数据进行对比,这种比较多数情况下是可行的,但是缺乏有力的科学根据和足够的量化数据作支撑。雨量站之间距离的大小(地形条件)是降水是否同步的必要条件,而非充分条件,即关联性强的雨量站距离一定很近,但距离很近的雨量站关联性不一定强。我们需要引入一个具体的量化指标来判断雨量站之间关联性的强弱,因此,相关系数的计算是必不可少的。
选取长时间序列(1979—2009年)的日雨量值进行两站之间相关系数计算,同时间的降水量值分别为序列 x1,x2,x3…xn-1,xn和 y1,y2,y3…yn-1,yn,n的数值不取决于两个时间序列中的任何一个时序数,某时间序列的降水量值不为0,与其对应另一组时序便参与相关系数计算,无雨量取0值。采用EXCEL求相关系数方便快捷,CORREL函数自动将同为空白的信息滤掉,满足分析的要求。雨量站之间的相关系数分布情况见表1。通过计算可以得出,平原区雨量站之间的相关系数普遍较大,山区雨量站之间相关性不及平原区明显。通常相关系数大于0.8时,两组变量有很强的线性相关性,为了考虑山区雨量站相关性略低的影响,选取相关系数大于0.75的雨量站为候选关联雨量站。
(2)双累计分析
通过长时间序列求得的相关系数可有效反映日降水量数据相关性,关联雨量站的选取还需要在相关性较强的雨量站之间选择数据一致性好的。WISKI自带的双累计分析为数据一致性检查提供了有效方式。选取5分钟时段的雨量值进行双累计曲线分析,通过分析双累计曲线可知,相关系数高的雨量站之间双累积曲线形态一般较好,但也存在极个别特殊情况。浦洼站与十渡站40年降水量资料相关系数为0.92,但是双累计曲线形态不如与黄塔站的好,浦洼站与黄塔站40年降水量资料相关系数为0.88。
通过相关系数的计算和双累积曲线分析,每个雨量站选取相关系数高、双累积曲线形态较好的3个雨量站为其关联站,在WISKI中建立日雨量检查时序,配置该时序的源信息,时间序列配置为待检验雨量站及其关联站的日降水量值。
3.规则的制定
降水量合理性检验规则的制定是一个突破传统,由定性分析向定量分析转变的一个步骤。可参考现成的降水量合理性检查原则极少,降水量合理性检验规则的制定参考以往的工作经验进行。针对降水量数据可能出现的错误情况,共制定了如下几种异常值类型,并且统一编码,用异常代码的形式展示。将该雨量站的错误类型总体分为降水量大于0与等于0两大类,再细化分具体的异常类型(见表2)。

表2 雨量站遥测数据异常代码统计表
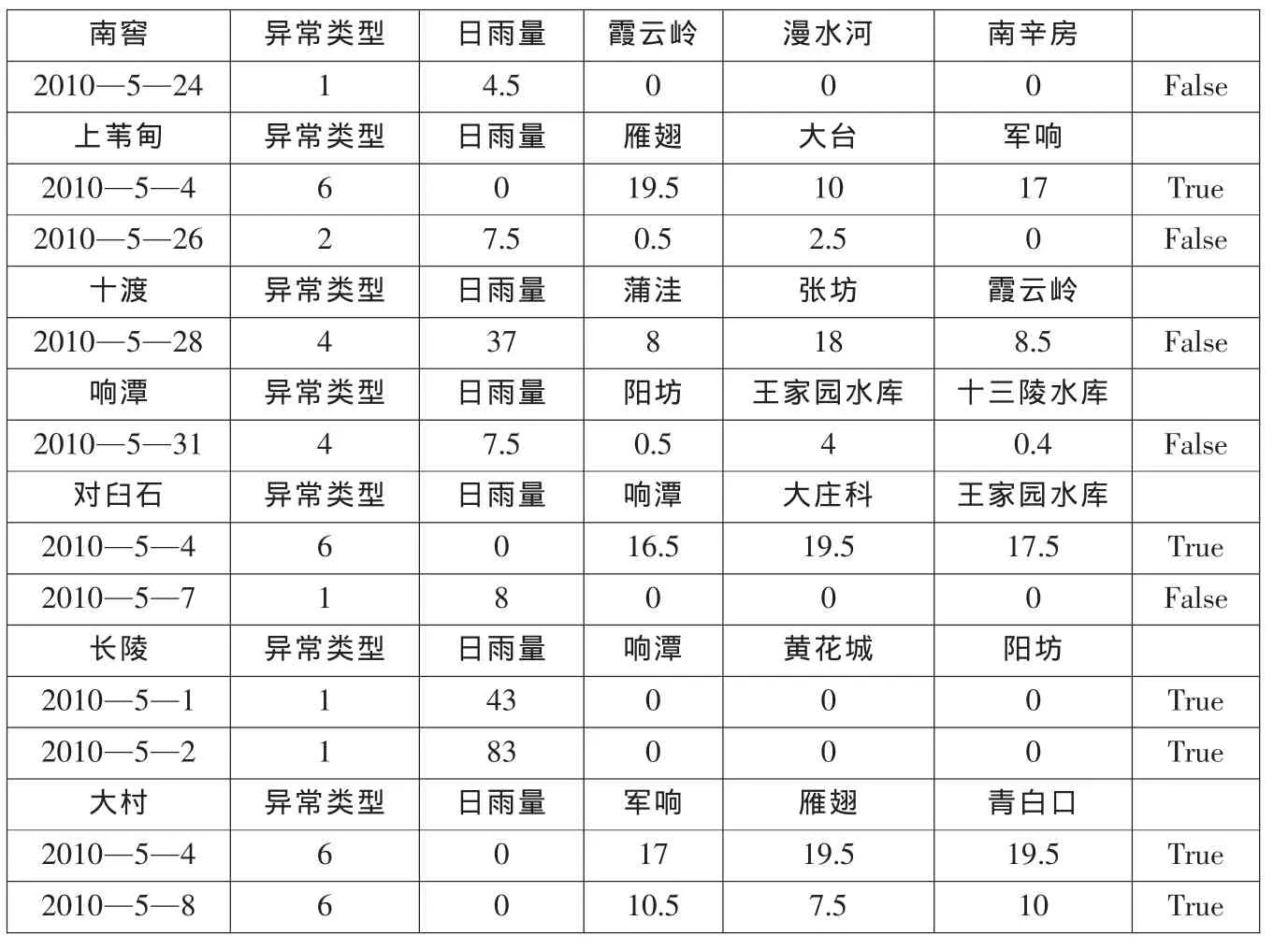
表3 5月降水量合理性检查成果表(部分)(异常值成立:true,不成立:false)
4.成果输出
WISKI将所有的测量值和计算值都以时序数据方式保存,每个时序数据对应于一个站点的指定参数,可以配置多种数据输出模式,根据参数与时段生成相关的报表,并且可以设置在指定的时间自动生成报表,为成果自动输出提供了一个合理的解决方案。由于降水量合理性检查没有具体的定量指标来判别异常值一定成立,所以最终输出的成果还需要进行人工校核,但如果在检验规则较为完善的前提下,人工校核的工作量就会很小。首先经WISKI平台自动将疑似异常值的数据从海量的降水量数据库中挑出,再根据人工的经验对WISKI挑选的异常值进行排查,可有效减少数据的遗漏,进而达到提高效率、减少错误的目的。
二、应用实例
表3是运用WISKI生成的5月降水量合理性检查成果表的部分信息,经人工校核,WISKI自动生成的成果表1/2以上的异常值均成立,并且无一异常值被遗漏。
三、结 语
①二次开发WISKI使其应用于雨量合理性检验是可行的。这种全新的数据处理方式将以往大量繁杂的人工工作通过计算机平台实现,减轻了工作强度,提高了时效性,同时也提高了水文资料处理的先进性、科学性,具有积极的意义。
②由于WISKI平台二次开发具有很强的灵活性,雨量合理性检验规则可根据实际需求具体制定,并可以根据工作经验不断完善,使其更接近于真实的降水情况。当然,使用计算机平台进行水文资料的处理代替了大量人工工作量,但其中人的作用还是不可或缺的,还需要经验丰富的水文工作人员对从海量数据中提取的异常值进行排查。这样人工经验和计算机运用得到了有机结合,提高了水文数据处理的可靠性。
③WISKI应用于雨量合理性检验仅是二次开发WISKI平台的探索之一。根据水文工作的实际需求对WISKI进行有目的的二次开发,可实现很多水文数据的分析计算功能。除WISKI之外的一些平台也可经过开发代替部分人工劳作,可应用到水文数据的处理工作中,促进水文行业信息化技术的发展。
[1]降水量测验规范(SL 21—2006)[M].北京:中国水利水电出版社,2006.
[2]水文资料整编规范(SL 247—1999)[M].北京:中国水利水电出版社,2000.
[3]赵学丽,池宸星,吴海山.WISKI在北京水文数据管理中的应用[J].北京水务,2008(6).
[4]吴金塔.水文遥测数据智能纠错及插补技术在洪水预报中的应用研究[J].水利水电科技,2005(11).
