信息熵方法在辽宁省不同分区雨量站网布设的应用研究
2021-04-12王鹏
王 鹏
(大洼区水利服务中心,辽宁 大洼 124200)
0 引 言
雨量站是气象服务、防汛抗旱、农业需水的重要数据基础,也是水文、气象、农业学者进行科学研究的数据来源[1]。雨量站信息数据的精准度对防汛抗旱、农业、气象工作研究的开展具有重要的影响[2]。然而近些年来,随着社会经济的快速发展,雨量站网布设的深层次问题逐步凸显,虽然当前有较为先进的数据存储和传输的仪器,但是在进行雨量信息的实际分析时,数据的可靠性和有效性在一些特殊情况下很难得到有效保障[3]。这些问题产生的原因在于对雨量站的布设为进行优化分析,存在一定的主观性,使得雨量信息出现缺失或者冗余的情况[4]。雨量站网优化布设的首要目的在于对雨量站的数量和位置进行优化,其原则在于满足区域雨量采集精度的前提下,通过尽量布设较少的雨量站点使得雨量站网获取更多的雨量信息数据[5]。目前,对于雨量站网优化布设的重要性已经得到广泛关注,但是对于雨量站优化布设的系统分析的研究还较少。当前,信息墒的方法逐步在一些领域监测站点的优化布设方案中得到应用,但是在辽宁地区雨量站的应用还较少[6-8]。20世纪初,辽宁海城牛庄设立了第一处雨量观测站。1949年建国前夕,全省雨量站增加到5处。1956年,辽宁水文首次科学地进行了站网规划,到1958年全省有雨量站共有257处。20世纪80年代初,计算机在水文工作中也得到了广泛应用,迈开了水文技术现代化步伐。20世纪80年代中期,全省建成了由1300多个各类站点组成的水文站网体系,站点密度逐步提升。为提升辽宁地区雨量站点的优化布局,提高雨量信息的采集精度及可靠度,文章结合信息墒方法首次在辽宁东、中、西、北四个分区开展雨量站信息墒的分析,从而提高辽宁地区雨量站布设的科学性。
1 雨量站点信息熵的计算方法
信息墒方法的计算原理为结合变量的概率密度分布函数对变量进行信息墒的目标求解,目标函数的方程为:
(1)
式中:P(x)为变量X的概率密度的分布函数,将变量的增量与目标函数进行相乘得到概率密度条件下的转换函数为:
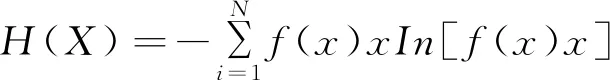
(2)
式中:x1,x2,L,xN为函数的分析变量;y1≤y2≤L≤yN为不同变量的分析顺序,将M作为整数进行分析,模型变量参数的计算方程为:
(3)
其中:
(4)
在方程中将雨量信息作为模型的输入变量得到各雨量站点信息墒值。对于独立同分布的随机变量,对其信息墒的最优化值进行计算,各随机变量的概率分布为正态分布函数,正态分布的信息墒计算方程:
(5)
式中:Sc为不同变量矩阵相关参数;|Sc|为正数,且Sc为矩阵可逆参数;l表示为Sc相关矩阵的维数。对不同条件墒值的雨量站信息进行计算,首选需要对雨量墒值信息最小的站点进行计算,结合墒值最小的原理,与区域中心雨量站A1具有相同信息源的雨量站作为其信息墒计算的目标函数,信息墒最小计算方程为:
min{H(X1)-H(X1|X2)}=min{T(X1,X2)}
(6)
式中:X1、X2分别为雨量站点类别;T为信息墒目标值。在X1、X”2为雨量站信息墒最小值计算的基础上,再结合最小熵值信息原理确定第三个水文站点X3,雨点站点的信息墒目标值进行计算:
min{H(X1,X2)-H((X1,X2)|X3)}
=min{T(X1,X2),X3}
(7)
将区域内个雨量站进行重复信息墒值的计算,并按照重要程度对各雨量站点进行排序分析:
min{H(X1,L,Xj-1)-H((X1,L,Xj-1)|Xj)}
=min{T(X1,L,Xj-1),Xj}
(9)
信息墒分析方法不同雨量站点的信息墒进行正态分布的表征,正态分布的雨量站信息墒计算方程为:
(10)
式中:R为各雨量站点的信息墒相关系数值。
2 实例应用
2.1 雨量数据概况
辽宁省属于典型温带季风气候,降雨时空分布变化差异度较大,雨量不同年代际及年内分配十分不均匀,因此辽宁地区雨量站点的信息表现出较为明显的不确定性,考虑到样本数据系列的要求,文章对具有系列较长的雨量站点进行分析,按照辽宁省东、西、南、北四个分区分别选取4个雨量站点信息进行信息墒值的分析,各站点样本数据系列的长度均为10a。汛期全省暴雨历时短,降雨强度大,非汛期主要以降雪为主,文章将研究时段划分为汛期和非汛期,并对雨量记录的时间进行了不同尺度的划分[9]。
2.2 雨量站选取方法
信息墒雨量信息分析按照以下顺序进行分析:
1)结合不同雨量站信息的记录时段,对不同雨量站点的边际墒雨量序列的标准值进行计算,按照熵值最大原理,对最大信息熵值的雨量站点进行分析,确定为A1雨量站点,将它定为雨量站的中心站点进行分析。
2)计算第一个雨量站点与其他分析雨量站点之间的熵条件值,对信息墒最小的站点进行分析,按照信息墒最小的计算原则,将中心雨量站相同信息墒值的雨量站设置为二类重要的站点进行信息熵分析。
3)将不同目标雨量站作为确定站点,并与其他站点进行联合分析,确定信息墒最下的第三类雨量站点,将流域内的其他雨量站点按照此类方法进行重复计算分析,从而确定区域内雨量站点的排序,并对各雨量站点相关系数进行分析。
2.3 辽宁省不同分区雨量信息熵计算结果
结合信息熵计算方法对辽宁省不同分区汛期和非汛期的雨量信息熵值进行分析,分析结果见表1、表2以及表3。
从汛期各分区雨量熵值分析结果可看出,中心雨量站点信息熵值变化存在以下变化特点:①汛期和非汛期不同雨量记录时段下的条件熵随着降雨时段的递增而增加,这与信息熵值变化的规律较为一致。雨量记录时段的增加使得信息条件熵逐步增加。②在同一个计算时段,汛期雨量站点的信息熵值要大于非汛期雨量信息的熵值,且随着雨量站点数量的增加,汛期雨量站点信息熵减小的比例要小于非汛期递减幅度[10-12]。雨量站数目增加对汛期的影响显著性要高于非汛期。
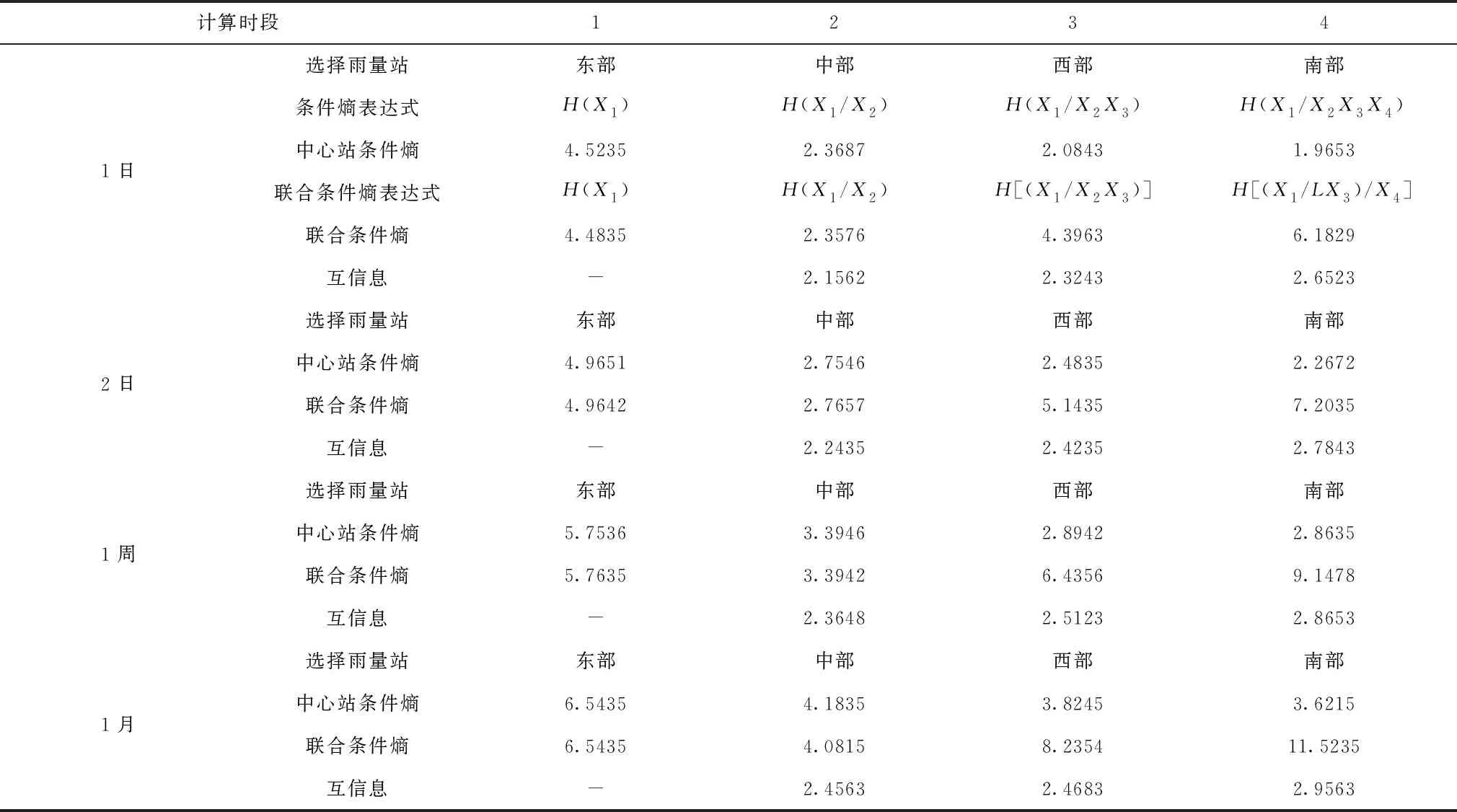
表1 辽宁省汛期各分区雨量条件熵计算结果
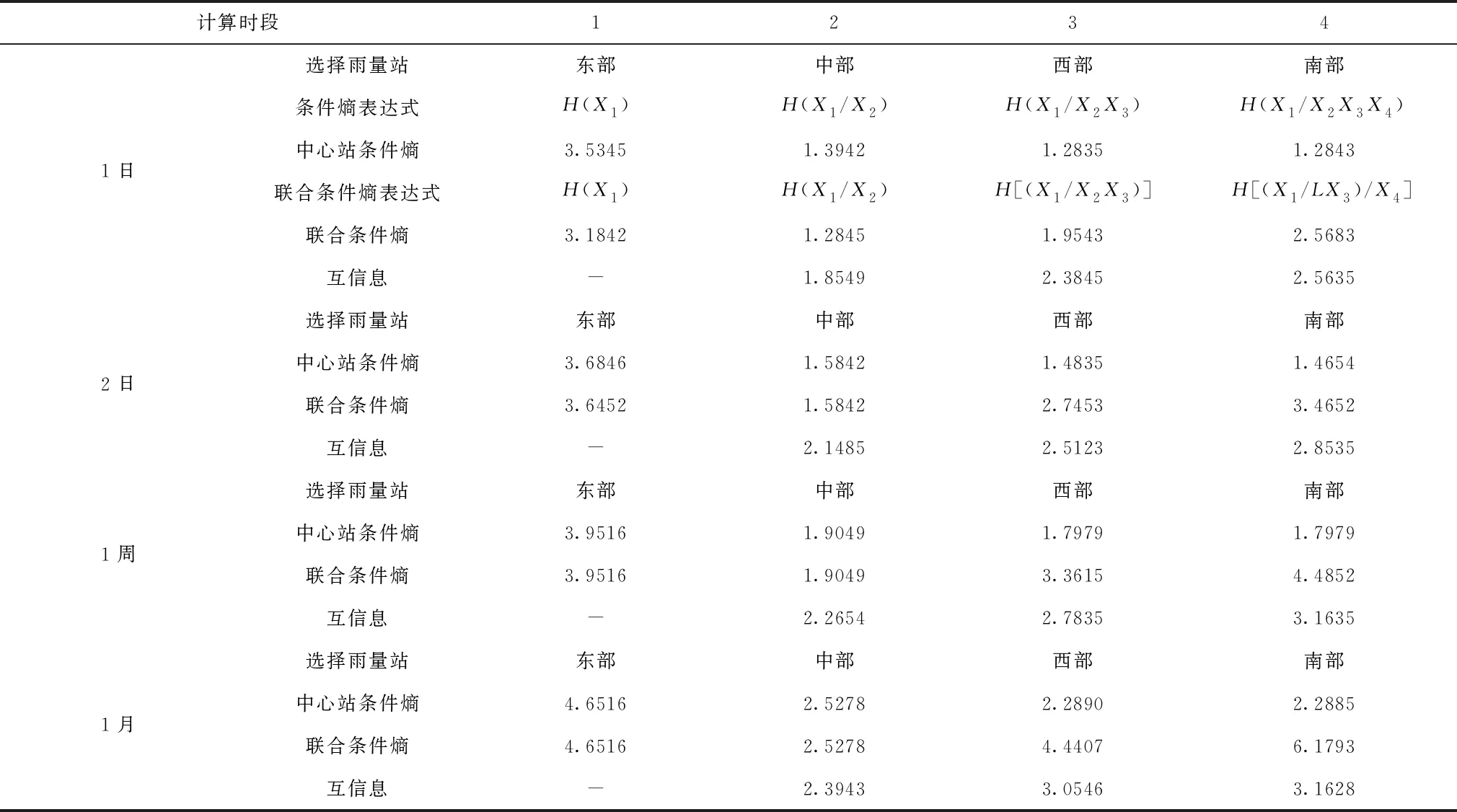
表2 辽宁省非汛期各分区雨量条件熵计算结果
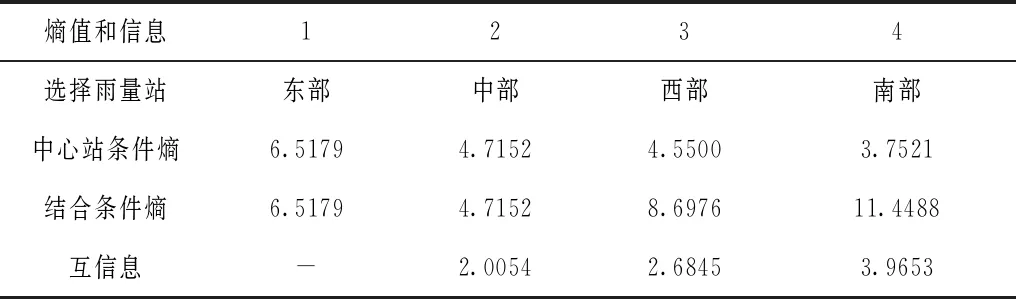
表3 辽宁省不同分区逐年雨量信息墒值分析结果
对于雨量站点的相互墒信息可分析出:①雨量站数目的增加会加大信息传递的数量,且随着雨量记录时段的增加信息传递的数量也将得到明显提升;②各雨量站点在同一个季节相互墒信息要高于非汛期,且在同一雨量记录时段下,非汛期大部分雨量站点相互墒信息要高于汛期。
从不同时段雨量联合条件熵值分析结果可看出:①雨量站点数目的增加可以提高各雨量站点条件信息熵值,但这种方式下会使得雨量站点的不确定性提高;②各季节相同条件下,雨量记录时段越长,站点信息的不确定程度越高;③在同一个计算时段下,汛期雨量站点信息的不确定度要高于非汛期,雨量信息的时空分布差异程度也将加大。
从对雨量选取的次序进行分析表明:①汛期不同雨量记录时段下东部雨量站点均处于中心区域,其次为西部、北部和中部;②非汛期同样以东部为雨量为中心站点,综合对比不同雨量记录时段的排序依次为:东部、西部、北部、中部。③当雨量记录时段为1年的情况下,雨量站点的排序和非汛期雨量站点排序一致,随着雨量记录时段的额变化,雨量站点的设置也需进行相应程度的调整。
2.4 雨量站点未传递信息系数分析
为了降低雨量站个数对雨量信息的影响度,采用定量分析的方法对辽宁省不同分区4种雨量站点数量下的雨量未传递信息的系数进行测算,测算结果分别见表4、表5、表6及表7。

表4 辽东不同雨量站个数下的未传递系数分析结果

表5 辽西不同雨量站个数下的未传递系数分析结果

表6 辽北不同雨量站个数下的未传递系数分析结果

表7 辽中不同雨量站个数下的未传递系数分析结果
从不同分区各雨量站数目下的雨量未传递系数的分析结果可看出,汛期各分区雨量信息未传递系数随着雨量站数量的增加具有相同的变化趋势,当雨量站的数目达到最大值未传递系数值最小。非汛期不同雨量记录时段下的未传递信息系数达到500时出现未传递系数的最小值。相同的雨量记录时段内,汛期未传递系数的最小值高于非汛期,因此可以表明非汛期雨量站点的代表性更为明显,因此需要将非汛期的雨量站点的布设方案进行优先考虑。
3 主要结论
1)对于辽宁地区而言,汛期雨量站点的信息熵值要大于非汛期雨量信息的熵值,且随着雨量站点数量的增加,汛期雨量站点信息熵减小的比例要小于非汛期递减幅度。雨量站数目增加对汛期的影响显著性要高于非汛期。
2)汛期各分区雨量信息未传递系数随着雨量站数量的增加具有相同的变化趋势,相同的雨量记录时段内,汛期未传递系数的最小值高于非汛期,因此非汛期雨量站点的代表性更为明显。
