基于C#的字符编码映射系统
2010-02-23童天添
童天添
(江苏科技大学学报编辑部, 江苏 镇江 212003)
0 引 言
任何计算机软件都需要在指定的字符编码支持下才能运行,在互联网环境下,涉及跨国用户的计算机软件,更应该注意它使用了怎样的字符代码体系.计算机用户在使用计算机时常会遇到字符“乱码”,特别是在涉外的计算机通讯中尤为常见[1-3].当今中国有GB2312简体中文字符集,日本有Shift-JIS字符集,国际上类似这样一个国家对应一套或数套字符集的现象很多.Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案,它用数字0~0x10FFFF来映射这些字符,最多可以容纳1 114 112个字符,或者说有1 114 112个码位.码位就是可以分配给字符的数字.UTF-8,UTF-16,UTF-32都是将数字转换到程序数据的编码方案.Unicode字符集简写为UCS(Unicode Character Set).Unicode标准有UCS-2,UCS-4.UCS-2用两个字节编码,UCS-4用4个字节编码.由于 Unicode 版本的发展原因,很多浏览器只能显示 UCS-2 的完整字符集,即现在使用的 Unicode 版本中的一个子集.为此,本文以双字节编码空间为研究对象,用Visual Studio 2005 中的C#语言编写了字符编码映射系统,分别展示出GB2312 和UCS-2字符集中的所有字符,结果证明了Unicode字符集在当前系统资源充足的情况下,相比其他字符集具有跨语言、跨平台进行文本转换、处理的优越性.该系统为进一步研究实现期刊采编系统等软件的国际化奠定了基础.
1 字符编码映射系统的理论分析与设计
1.1 UCS-2字符集的区域划分
UCS-2字符集用一个16位的值来表示每个字符,它已经为欧洲拉丁文、扩充拉丁文、阿拉伯文、泰文、日文、韩文等外文字母定义了Unicode代码点.该字符集中还包含了大量的标点符号、数学符号、技术符号、箭头、装饰标志、区分标志和其他许多字符.现在USC-2字符集的65 536个代码绝大部分已经被分配了字符,其中中国汉字、日文汉字、韩文就占用了超过一半的代码[4],这65 536个字符可以分成不同的区域.表1显示了其中的部分区域的代码范围以及分配给这些区域的字符.
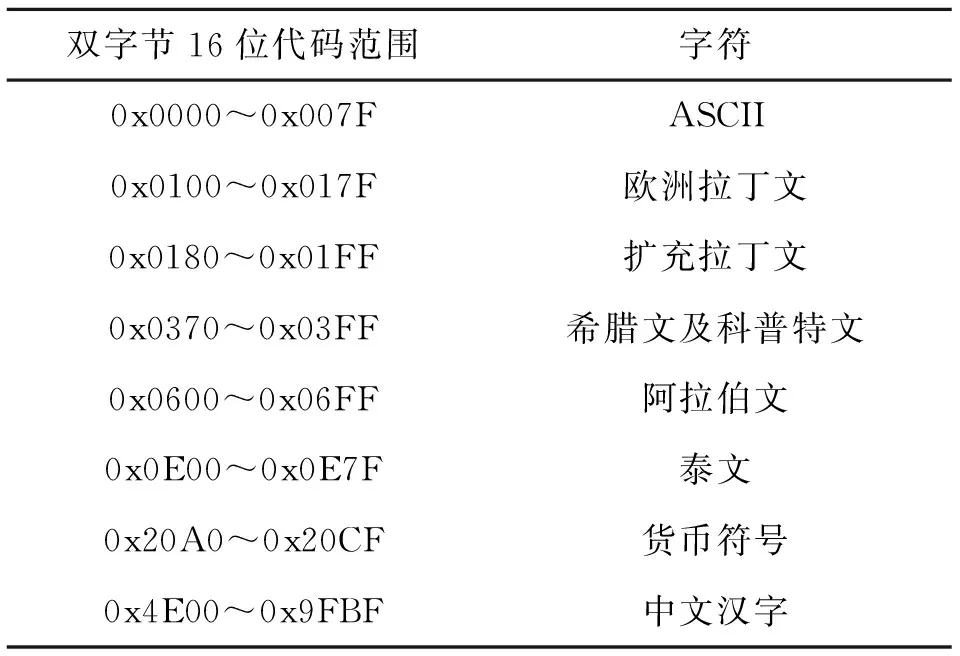
表1 UCS-2字符集区域分布
1.2 Unicode字符集转换格式
Unicode字符集转换格式(UCS Transformation Format,UTF)用来规定怎样将Unicode定义的数字转换成程序数据,包括:UTF-8,UTF-16,UTF-32.例如,“汉字”对应的数字是0x6c49和0x5b57,而编码的程序数据是:
BYTE data_UTF8[] = {0xE6, 0xB1, 0x89, 0xE5, 0xAD, 0x97}; // UTF-8编码
WORD data_ UTF16[] = {0x6c49, 0x5b57}; // UTF-16编码
DWORD data_ UTF32[] = {0x00006c49, 0x00005b57}; // UTF-32编码
把Unicode编码记作U.对于U<0x10000,UTF-8,UTF-16,UTF-32的编码规则分别如下:
(1)UTF-8以字节为单位对Unicode进行编码,从U到UTF-8的编码方式如下:
U║ UTF-8 字节流(二进制)
0x0000~0x007F ║ 0xxxxxxxB
0x0080~0x07FF ║ 110xxxxxB10xxxxxxB
0x0800~0xFFFF ║ 1110xxxxB10xxxxxxB10xxxxxxB
(2)UTF-16编码以16位无符号整数为单位.U的UTF-16编码就是U对应的16位无符号整数.
(3)UTF-32编码以32位无符号整数为单位.U的UTF-32编码就是其对应的32位无符号整数.
1.3 字符集的映射
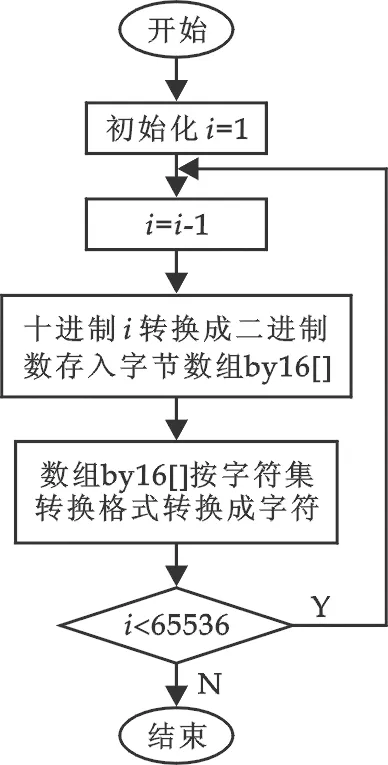
图1 字符生成流程图
图1为字符编码映射系统中的字符生成流程图.从开始到结束,完成一套双字节编码空间字符集的生成过程,所使用的Unicode字符集转换格式为UTF-16.图2 为字符编码映射系统显示USC-2字符集的运行截图.程序用dataGridView控件的单元格存放生成的字符.dataGridView控件每行存放32个字符,列头标以0x00~0x1F连续编号.以UCS-2字符集为例,UCS-2字符集共有65 536个码位,所以dataGridView控件的总行数为65 535/16=4 096行,行头标以0x0000~0xFFE0非连续编号.点击“显示USC-2字符集”按纽和“显示GB2312字符集”按纽,分别在dataGridView控件中显示相应字符集的所有字符.
显示USC-2字符集的程序代码如下:
private void button1_Click(object sender, EventArgs e)
{
byte[] by16=new byte[2];
for (int i = 0; i < 65536; i++)
{
by16[0] = Convert.ToByte(i% 256); //i取余给底字节
by16[1] = Convert.ToByte(i/256); //i取整给高字节
dataGridView1[i% 32, i/32].Value = ncoding.Unicode.GetString(by16);//UNICODE字符赋给单元格
}
}
显示GB2312字符集的程序代码如下:
private void button2_Click(object sender,EventArgs e)
{
byte[] by16 = new byte[2];
for (int i = 0; i < 65536; i++)
{
by16[0] = Convert.ToByte(i% 256); //i取余给底字节
by16[1] = Convert.ToByte(i/256); //i取整给高字节
dataGridView1[i% 32, i/32].Value =
Encoding.GetEncoding(“GB2312”).GetString(by16); //GB2312字符赋给单元格
}
}

图2 字符编码映射系统运行截图
2 结果的分析
下面是通过本文设计的字符编码映射系统生成的一部分Unicode字符,最前面的十六进制数字是后面32个字符中第一个字符的编码.

通过了解Unicode的设计初衷和用设计的程序验证USC-2字符集中的字符,我们可以知道Unicode是一种在计算机上使用的字符编码,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求.Unicode标准有UCS-2和UCS-4.UCS-2用两个字节编码,UCS-4用4个字节编码.Unicode还在不断的发展,Unicode 4.1.0版本于2005年3月31日推出.另外,5.0 Beta版本于2005年12月12日推出,5.2版本于2009年10月1日正式推出.
Unicode技术有其广泛的应用价值,它是今后软件设计中字符编码方式的一种趋势.本文所设计的映射系统是进行软件国际化研究工作的基础.以学报采编系统为例,我国科技期刊的编委和审稿几乎均局限在国内,难以争取境外稿源,也不可能在国际市场上畅销[5].从采编系统的技术层面分析,编委、审稿人队伍的国际化,稿源的国际化,销售市场的国际化,必然要求能兼容世界各国语言的统一编码标准,这正是Unicode编码标准所能满足我们的.
3 结束语
(1)本文以双字节编码空间为研究对象,用其编码空间映射出GB2312 和USC-2字符集中的所有字符,所用的方法具有通用性.对于其他的字符集,如日文Shift-JIS字符集,用该方法同样可以获得相应字符集中的所有字符.
(2)本文所设计的字符编码映射系统是研究软件系统跨语言、跨平台运用的基础.它作为一个工具,在今后的相关软件的研发中必将经常使用到.
(3)Unicode具有跨语言、跨平台进行文本转换、处理的特性.虽然在USC-4标准中每个字符有4个字节编码,较其他编码方案更加消耗存储空间,但在当前系统资源充足的情况下,它将是今后软件中字符编码的一种趋势.
参考文献
[1]高 炜, 刘 伟,赵长青.基于Windows的中文软件移植到UNICODE的方法研究[J].软件导刊,2008,(5):19-20.
[2]张爱优.图书馆自动化管理系统的新型编码系统[J].图书馆杂志,2001,20(12):19-21.
[3]马玉芝, 李 俊.基于UNICODE的多民族文字处理在移动终端上的实现[J].计算机应用,2006,26(1):234-236.
[4] 李建文,张成现.实用网络通信编程技术[M]. 北京:北京邮电大学出版社,2006.
[5]余丽清.我国科技期刊国际化探讨[J].中国科技期刊研究,2006,17(3):495-497.
