本体构建方法和开发工具研究
2009-11-19刘宇松
刘宇松
〔摘 要〕语义网的提出与发展促使了本体机制作为一种能够描述语义的新型知识组织方式受到了前所未有的重视,本体的构建及其应用成为知识工程领域的研究热点。本体构建是本体应用的基础,需要各领域的专家遵循一定的本体构建原则,在合理方法论的指导下,采用恰当的关键技术或使用便捷的本体开发工具加以实现。
〔关键词〕语义网;本体构建;指导原则;方法体系;开发工具
〔中图分类号〕G250 〔文献标识码〕A 〔文章编号〕1008-0821(2009)09-0017-08
Research of Approaches and Development Tools in Constructing OntologyLiu Yusong
(Library,Jiangsu Institute of Economic & Trade Technology,Nanjing 211168,China)
〔Abstract〕The advance and development of semantic web causes that importance has never been attached to ontology as a new mode of knowledge organization which could describe semantic.Ontology construction and ontology applications have been hot points of research on the field of knowledge engineering.Ontology construction is the base of ontology applications,and it is necessary for domain experts to use right key techniques or convenient development tools to constructing ontology,with following appointed principles and the guidance of reasoning methodology.
〔Key words〕semantic web;ontology construction;principle;method system;development tool
“信息爆炸”时代的到来,使得人们在互联网上进行数据检索、访问、显示、整合和维护都变得异常困难。在这种情况下,互联网的创始人Tim Berners-Lee在1998年首次提出了语义网(Semantic Web,SWeb)的概念[1],试图通过具有语义表达(这里指机器可处理)能力的元素来描述互联网中的信息,实现对异构、分布网络信息的有效访问、合理交换、语义处理和准确检索。Berners-Lee对SWeb的概念、特征以及体系结构作为完整的阐述,提出SWeb能够实现人与机器之间的语义交流,而具有语义描述能力的本体机制则是实现这种语义交流的关键,是解决语义层次上网络信息共享和交换的基础。随着SWeb的兴起和探讨,本体机制作为知识组织层面上的核心技术开始被人们广泛关注。
本体是描述概念模型(conceptualization)的明确清晰的规范说明(specification)[2],具有明确性、形式性和共享性3大特征。本体机制引入知识工程领域是上世纪90年代的事情,经过近二十年迅速发展,特别是受SWeb的影响,目前在国内外已经出现了很多成型的知识本体,典型的如WordNet,SENSUS,CYC,SUMO以及知网等。当前,对本体的研究主要集中在本体理论探索、本体构建、本体描述、本体映射、本体推理、本体应用等方面,而本体的构建及应用更是各大领域的研究热点。
本体构建是本体应用的基础。本体构建是一项庞大的系统工程,需要各领域的专家(领域专家、本体工程师等)按照一定的本体构建原则,在合理方法论的指导下,采用合适的关键技术或使用便捷的本体开发工具加以实现。
1 本体构建的指导思想和原则
出于对各自问题域(领域)和具体工程(任务)的考虑,本体构建的过程也是各不相同。由于没有一个标准的本体构建方法,研究人员从本体构建的实践出发,总结提出了不少有益于本体设计的指导思想,其中最有影响的是Gruber于1995年提出的5条原则[3]:
(1)明确性(Clarity):本体应该能够有效的表达术语的内在含义。本体的概念定义应该是客观的,即定义概念的动机可能起源于社会性情景或计算的需要,但应该独立于社会或计算环境;概念定义又应该是形式化的,即尽可能使用完整性定义(断言满足充要条件)代替局部性定义(断言仅满足充分或必要条件),必要时可以采用逻辑公理描述;所有客观的、形式化的语义定义都应该使用自然语言描述。
(2)一致性(Coherence):本体应该能够支持与定义相容的推理,使推理和定义本身不会产生矛盾。至少,定义的公理在逻辑上应该保持一致。
(3)可扩展性(Extendibility):本体在设计时应该能够预见共享词汇的用途,应该提供一个概念基础以满足可预见的任务,以扩展现有的概念体系。换句话说,向本体中添加专用术语时,不需要修改其已有的内容定义。
(4)最小编码倾向(Minimal encoding bias):本体的概念模型应该被描述为知识层次,而不依赖于符号层次的编码。编码主要是为了满足描述或执行的便利性。在本体设计中,编码应该倾向最小化,使得在不同编码或不同类型编码描述的系统中满足知识共享。
(5)最小本体化承诺(Minimal ontological commitment):本体应该要求最小本体化承诺以支持预期的知识共享行为。即仅需要定义知识交流所必需的术语即可。
Perez在Gruber本体构建5原则的基础上进行了适当修改和扩充,并融合其他学者如Arpirez[4]等的观点,提出了被实践所证明的本体构建10原则[5]:明确性和客观性(Clarity and Objectivity)、完全性(Completeness)、一致性(Coherence)、最大单调可扩展性(Maximum monotonic extendibility)、最小本体化承诺(Minimal ontological commitments)、本体差别原则(Ontological distinction principle)、层次变化性(Diversification of hierarchies)、最小模块耦合(Minimal modules coupling)、同属概念具有最小语义距离(Minimization of the semantic distance between sibling concepts)、命名尽可能标准化(Standardization of names whenever is possible)。
我国本体设计研究人员也在Gruber的5原则基础上进行了继承和发展,在本体设计实践中提出了更适于具体开展工作的指导思想。中国科学院文献情报中心李景在分析总结了本体构建的7种方法体系后,认为在本体设计时应该遵循6条原则[6]:①本体面向特定的应用目的;②基于一定的专业领域、学科背景或研究课题;③概念数目应该尽可能的最小化,尽可能地将冗余去除;④本体概念定义的规模应该是有限增长的;⑤“类”独立性原则,即这个类可以独立存在。不依赖于某个课题或者某个学科专业;⑥共享性原则,即类一旦被确立,就一定有被复用的可能和必要。
也有的国内学者对5原则进行了自我理解,认为本体设计应该满足[7]:①完整性:即本体是否包括了该领域重要概念,概念及其关系是否完整,概念的等级、层次是否多样化;②精确性:即本体中的术语是否被清晰无歧义的定义;③一致性:即本体中的概念间关系在逻辑上是否严密、一致,能否支持本体在语义逻辑上的推理;④可扩展性:即本体可否顺利实施进化,本体能否在层次结构上可扩充,在语义上可丰富与完善,能否加入新的术语概念;⑤兼容性。即本体的开放性和互操作性,本体能否和其他领域本体及相关资源系统进行映射,包括系统层、逻辑层、语义层、表现层等的兼容和互操作。
当前对本体构建的指导原则、方法过程以及方法的性能评估等都还没有一个统一的标准,各领域的学者都在自己的实践工作中总结经验作为指导方法。不过在构建特定领域本体的过程中,有一点是得到大家公认的,那就是需要该领域专家的参与。
2 本体构建的基本思路和方法体系
随着本体构建实践的逐步展开,研究人员在实际开发中总结了开发过程,得出了一些构建本体,特别是领域本体构建的基本思路,总结出了一系列本体构建方法。
2.1 构建本体的基本思路
目前,构建本体的基本思路包括:
(1)利用领域资源,包括非结构化文本,半结构化的网页、XML文档、词典等以及结构化的关系数据库等等,借助领域专家的帮助,从零开始构建本体,这是目前构建本体的最常用的方法。试图实现本体自动构建的本体学习技术也是基于这种思路开展的;
(2)将已有的叙词表或分类词表改造成本体,本体是对叙词表的有效扩展,可以认为叙词表是简化的本体,基于现有的叙词表构建本体可以利用叙词表中现成的概念和概念关系;
(3)综合现有的本体,经过本体合并,并有效组织后形成通用本体或参考本体。
2.2 构建本体的方法体系
当前典型的本体构建方法都是从具体的本体构建项目中总结获得的。最早出现的是1995年根据企业本体(Enterprise Ontology)和TOVE本体的开发过程获得的经验总结。此后,陆续出现了一些新的本体构建方法,如KACTUS工程法、METHONTOLOGY、SENSUS本体构建方法等等;此外,IEEE组织提出的软件开发过程标准(IEEE 1074-1995)虽然是针对软件开发,但是其过程对于本体构建具有一定指导意义。
2.2.1 IEEE 1074-1995
IEEE 1074-1995[8]是IEEE组织在1995年制订的关于规范软件开发过程的国际标准。计算机程序、过程,以及和计算机系统运行相关的关联文档和数据等都可以称为软件[9]。本体可以认为是部分软件产品,因此其开发过程可以遵循IEEE的软件开发标准。因此,基于该标准的本体开发过程描述为[10]:
(1)本体生命周期建模阶段:选择一种本体开发的生命周期模型,确定开发步骤及各步骤执行的先后次序;
(2)项目管理阶段:对本体开发进行系统规划、控制、质量管理等;
(3)本体开发阶段:①在开发前期,考察本体运行的环境,回顾本体集成系统的可能性、针对本体类型进行可行性研究等;②在开发期间,进行需求分析(根据领域本体的需要指定本体工程师,确定领域专家等)、本体设计、本体实现(编码等);③在开发后期,进行本体的安装、操作、支持、维护。
(4)统一阶段:包括本体评价、文档完成、本体配置管理以及人员培训等。
2.2.2 骨架法
骨架法[11],也称为EO工程法,是Uschold和King在1995年开发EO(Enterprise Ontology,关于企业建模过程的本体,是相关商业企业间术语和定义的集合)中的经验总结,它提出了一种本体开发的具体步骤,其基本流程如图1所示:
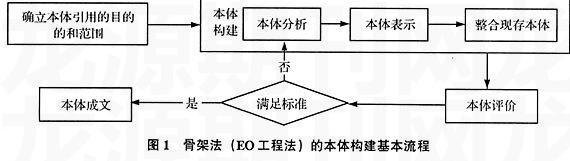
(1)明确本体应用的目的和范围:根据所研究的领域或任务,建立相应的领域本体或过程本体,领域越大,所建本体越大,因此需限制研究的范围。
(2)构建本体,该部分可以分为3个步骤:①本体分析,即识别目标领域范围内的关键概念及其关系;对概念和概念关系进行精确的描述和定义;获取概念及其关系的相关术语。在这个阶段,骨架法推荐采用中间扩展(middle-out)[12]的方法来获取概念,即先识别最重要的概念而不是最一般或最特殊的概念,然后基于重要概念以普遍化和特殊化的方法获取本体层次结构中的其他概念。该步骤需要领域专家的参与,对领域越了解,所建本体越完善。②本体表示(编码),使用形式化语言对获得概念及其关系(语义模型)进行明确描述。③整合现存本体,在分析和表示阶段,可以根据需要利用现存的本体。
(3)本体评价:建立本体评价标准(原则),满足评价标准,进入下一阶段;否则重新进行本体分析。需要说明的是,骨架法并没有提供评价标准。
(4)本体成文:符合本体评价要求的本体部分(概念和关系)以文件的形式存放。
使用骨架法开发的最重要的本体就是EO,该本体在爱丁堡大学的人工智能应用研究所以及IBM、Lloyds Register,Logica UK Limited,和Unilever等合作单位共同开发完成。骨架法清晰的描述了本体开发的具体实现步骤,对于当前本体开发实践具有重要指导意义。
2.2.3 TOVE法
TOVE法[13],也称为评价法,是Grüninger和Fox等开发TOVE工程本体(关于商业过程和活动建模的本体)的经验总结。这种方法并非直接构建以本体形式描述的知识的逻辑模型,而是先建立本体的非形式化描述说明,然后将这种描述形式化。这种方法的本体构建基本流程如下所示:
(1)激励情节的获取。Grüninger和Fox认为本体开发是由应用中的具体情节所驱动的。获取激励情节就是定义直接可能的应用和所有解决方案,提供潜在的非形式化的对象和关系的语义表示。
(2)非形式化能力问题的明确表达。将系统能力问题(能够回答)作为约束条件,包括能解决什么问题和如何解决,这里的问题用术语表示,答案用公理和形式化定义回答。由于是在没有形式化本体之前进行的,所以叫非形式化的能力问题。
(3)术语的规范化。从非形式化能力问题中抽取非形式化的术语,然后用本体形式化语言进行规范化定义。
(4)形式化能力问题的明确描述。一旦本体内的概念得到了定义,能力问题就脱离了非形式化,演变为形式化的能力问题。
(5)将规则形式化为公理。术语定义所遵循的公理用一阶谓词逻辑表示。
(6)调整能力问题解决方案的条件,从而使知识本体趋于完备。
2.2.4 KACTUS工程法
KACTUS工程法[14]是基于KACTUS(关于多用途复杂技术系统的知识建模)项目,由Berneras总结的。KACTUS项目的目的是开发出技术系统全生命周期的知识重用方法学,以便在设计、诊断、操作、维护、再设计和培训时使用同一知识库。该方法具体的开发过程包括:①应用的说明。提供应用的上下文和应用模型所需的组件;②相关本体范畴的初步设计。搜索已存在的本体,进行提炼、扩充;③本体的构造。用最小关联原则来确保模型既相互依赖,又尽可能一致,以达到最大限度的系统同构。
KACTUS工程法是在现存本体或应用知识库的基础上,通过抽象化(自底向上策略)过程构建本体的方法。越多的应用被实现,形成的本体就越普遍。
2.2.5 METHONTOLOGY法
METHONTOLOGY方法[15]由马德里技术大学(Polytechnic University of Madrid,UPM)人工智能实验室提出。METHONTOLOGY框架支持在知识的层次上完成本体构建,它根据基于进化原型的生命周期实现本体开发过程,并指定了生命周期各阶段中所需要的技术、输出结果和评价过程。基于生命周期的METHONTOLOGY方法的基本流程如下:
(1)工程管理阶段。这一阶段的活动包括:①规划(planning):明确本体开发的具体工作,包括工作安排以及完成它们所需要的时间和资源布置等,这个过程决定了本体的抽象程度;②控制(control):保证规划的工作可以按照预先设计的方式完成;③质量保证(Quality Assurance):确保满意的产品输出。
(2)本体开发阶段。包括①规范化(Specification):明确本体构建的目的、功能和最终用户等;②概念化(Conceptualization):将领域知识转化为知识层次的概念模型;③形式化(Formalization):将概念模型转化为形式化或半计算化的模型;④执行(Implementation):使用计算语言构建可计算的模型;⑤维护(Maintenance):修改和修正模型等5个过程。
(3)维护阶段。包括知识获取、系统集成、评价、文档说明、配置管理等支撑活动。
采用METHONTOLOGY方法开发的本体包括:化学本体(CHEMICALS,描述化学基础和晶体结构等领域知识)、环境污染本体(Environmental Pollutants Ontologies,描述了各种污染的有关保护措施的领域知识)、参考本体(Reference-Ontology,以一种逻辑组织方式将各种本体集合在一起,作为本体黄页的角色)等等[16]。
2.2.6 基于SENSUS的本体构建法
这种方法[17]是一种自顶向下的本体构建方法,即从原始本体(这里指SENSUS)中获得专用领域本体的过程。这种方法促进了知识的共享,可以从同一“原始本体”库中获得多个领域的“专用本体”库。为了能在SENSUS基础上构造特定领域本体,必须把不相关的术语从SENSUS中剪除。基于SENSUS的本体构建方法的基本步骤如下:
(1)确定与具体领域关联的一系列“种子”术语;
(2)将这些“种子”术语与原始本体(SENSUS)相关联;
(3)从“种子”概念到SENSUS的“根”概念路径上的所有概念作为领域本体的概念;
(4)如果与专用领域相关的术语没有添加到专用本体中,则手动添加;
(5)根据启发式思维“某节点如果有多条路径通过,那么以该节点为父节点的子树上的所有节点都与该领域相关”,将有很多条路径通过的概念节点的子树也作为领域本体的概念。
现存的基于SENSUS构造的本体如军用飞机战斗计划领域本体[18],包括常规武器、原油、飞机等子本体。
2.2.7 IDEF5法
该方法[19]是美国KBSI(Knowledge Based Systems Inc.)公司开发用于描述和获取企业本体时所采用的一种结构化的本体开发方法。IDEF5通过使用图表语言和细节说明语言,获取关于客观存在的概念、属性和概念间关系,并将它们形式化,作为知识本体的主要架构。IDEF5的本体构建方法流程如下:
(1)组织和范围:确定本体项目的目标、观点和语境,组织课题队伍并为组员分配角色。
(2)数据收集:收集本体建设需要的原始数据。
(3)数据分析:分析数据,为抽取本体做准备。
(4)知识本体的初步开发:从收集的数据当中建立一个初步的本体。
(5)本体的精炼与验证:完成本体建设过程。
2.2.8 AFM法
AFM(Activity-First Method)[20]是一种从技术文档中提取任务或领域本体的构建方法,是对Hozo本体构建的经验总结。AFM方法的基本思想在于:任务本体中存在角色集合,这些角色将任务中的领域概念有效的组织起来。AFM方法构建本体的基本步骤如下:
(1)任务单元的提取。将技术文档划分为小块便于抽取术语;在每个小块中抽取一个任务单元;将任务单元结合在一起形成一个称为具体任务流的流程图。
(2)任务活动的组织。在任务单元的动词中提取任务活动概念;将任务活动概念组织成一个ISzA层次结构;定义任务概念,将其称为任务活动角色,这些任务角色出现在任务活动的输入和输出中。
(3)任务结构的分析。将具体任务流一般化为通用任务流;描述对象流,这些对象流清楚的表达了任务活动的输入和输出之间的关系;在对象流的基础上定义任务上下文角色,通过这些任务上下文角色,我们得到了依赖于整个任务过程的角色概念;抽取领域概念,这些概念都扮演了任务上下文角色。
(4)领域概念的组织。将依赖于领域概念的角色和依赖于基本概念的角色区分开来;将领域概念组织成ISzA层次结构,该层次结构可以通过本体编辑器半自动化的转化为本体。
2.2.9 七步法
该方法[21]是斯坦福大学医学院提出的基于Protégé本体构建工具的一种领域本体构建方法。一共包括7个步骤,因此被称为七步法:①确定知识本体的专业领域和范畴;②考查复用现有知识本体的可能性;③列出本体中的重要术语;④定义类(Class)和类的等级(层次)体系;⑤定义类的属性;⑥定义属性的分面(Facets);⑦创建实例。
2.2.10 五步循环法
Maedche和Staab在研究基于语义网的本体学习时,提出了一种具有5个步骤的本体开发方法[22],并认为这5个步骤可以循环往复,直至本体构建完成或更新实现。
(1)本体导入(import)阶段:导入现有的本体,通过合并现存的本体结构进行本体重用;在现有的本体和结构之间定义规则图。
(2)本体抽取(extraction)阶段:通过学习网页文件,从中抽取大部分的本体概念,构建目标本体的模型。
(3)本体修剪(pruned)阶段:通过本体修剪,去除在本体导入和本体萃取阶段产生的不相关领域的本体(非研究对象),适当地缩小本体库的范围,使得目标本体库达到完整和不足的平衡,被调整至最好的效果。
(4)本体精细(refinement)阶段:通过对特定的领域本体的精细工作,根据具体的应用数据,调整目标本体库,使得本体处于一个好的粒度状态,更有利于用户的使用和其进一步的发展。调整、维护、扩展等工作都属于本体精细。
(5)本体评价阶段:通过对目标本体的应用服务,评价目标本体,从而确认最终的结果本体。
除了上面介绍的10种典型的本体构建方法外,还有很多本体研究学者,如Staab(提出了On-To-Knowledge方法)[23],Bachimont[24],Khan[25],Lonsdale[26]、Moldovan[27]等,在本体的实际开发过程中也都提出了具有一定应用范围的本体构建方法。此外,我国研究学者,如李景[28]、董慧[29]、刘柏嵩[30]、唐爱民[31]等,在借鉴国外本体构建方法的基础上,根据中文汉语本体构建的实际情况,也提出一些具有影响的本体构建方法。
3 本体构建的常用开发工具
随着本机机制研究的逐渐深入,越来越多的本体开发活动在国内外陆续开展。然而本体开发是一项庞大的知识工程,研究人员在采用上述方法构建本体的过程中遇到了各种问题,如一致性检查、本体展示等等,人们迫切希望产生一些工具帮助其完成本体开发任务。在这种情况下,本体构建工具应运而生,各研究单位都试图开发适合特定领域本体构建的环境,以支持本体开发过程中的多个环节。借助这些工具,本体构建者可以把精力集中在本体内容的组织上,而不必了解本体描述语言和描述方式等细节,极大地方便了本体的构建。目前,在国外已经出现了众多的本体构建工具,典型的包括OntoEdit、WebOnto、WebODE、KAON和Protégé等。
3.1 OntoEdit
OntoEdit[32]是由德国卡尔斯鲁厄大学开发的,支持本体开发和维护的一个图形环境。OntoEdit建于内部本体模型的顶层,在本体工程生命周期的不同阶段有不同的本体支持模型的图形视图;该工具允许用户编辑概念的层次结构,这些概念可以是抽象的也可以是具体的,具体概念可以直接包含实例,概念可以具有多个名称,即所谓的同义词;OntoEdit提供简单的复制、粘贴功能;基于灵活性大的插入式框架,可以以工具组建方式实现功能扩展,OntoEdit的插入式界面是公开的,用户可以方便的进行功能扩展,其插件集为用户提供了个性化的工具应用,可以根据不同的用途场景个性化进行插件组建;OntoEdit支持F-Logic、RDFS和DAML+OIL等描述语言,可以导入与对象有关的数据库模式和文档类型定义。
OntoEdit基于On-To-Knowledge项目(该项目起源于KADS工程)的本体构建方法。在本体获取(Capture)阶段,提供了2个工具:①OntoKick,适合熟悉软件开发过程的计算机工程师,用于构建非正式化本体概念描述的相关结构;②Mind2Onto则是一个图形化的界面,用于获取非正式化的概念关系,具有可视化界面并允许自由的概念关系定义;在本体精炼阶段则需要开发者使用编辑器精炼本体结构和概念及关系的定义,OntoEdit采用客户机/服务器模式,可以通过多个终端对存储在服务器中本体进行修改;OntoEdit允许用户形成一个实例和公理集合作为评价本体的测试集,并提供测试工具用于发现并修正本体错误部分。OntoEdit以F-Logic作为其推理引擎,用于在本体精炼和评价阶段处理公理。
3.2 WebOnto
WebOnto[33]起源于英国Open University开始于1997年的KMI项目,目的是开发一个基于Web的本体编辑器。它能提供比Ontolingua更为复杂的浏览、可视化和编辑能力;基于OCML推理引擎的知识模型,提供多重继承、锁机制,支持用户合作地浏览、构建和编辑本体;但是WebOnto没有提供源代码。
Ontolingua,Ontosaurus等系统使用浏览器作为客户端接口,导致3个问题:①数据的集中存放:由于所有数据集中存放于中央数据库,这样中间的用户修改就会被覆盖,而且无法提供迅速反馈的接口;②一次性连接:服务器仅仅对网页请求做出回应,这意味接口仅能对用户动作做出反应,因此本体构建工具无法包含异步通信(如周期地提醒存储数据),用户必须记住以前的页面;③浏览器展现的呆板:浏览器对于图形接口的支持非常有限。
WebOnto可以解决上述问题。WebOnto由一个中央服务器和Java编写的客户端组成。它包括一个图形用户接口和用于存放细节数据的检查窗口。WebOnto提供大量定制信息表示类型的选项。最后它提供一个客户端的API,用于从WebOnto本体中检索信息,以及运行WebOnto建成的应用。
3.3 WebODE
WebODE[34]是西班牙马德里技术大学开发的一个综合性的本体建模工具,它集成了本体开发过程中的大多数行为,支持METHONTOLOGY本体构建方法论,目前只有WebODE和OntoEdit能够将本体开发环境和实际的本体构建方法相对应。
WebODE支持构建知识层次的本体,并可以将其转化为不同的本体语言加以描述。它不同于OntoEdit和Protégé的插件结构体系,而是采用客户机/服务器模式的体系结构,通过Java、RMI、COBRA、XML等技术实现,具有较高的可扩展性和可用性,允许添加新的服务;使用WebODE构建的本体以SQL数据库的形式存储,对于大规模本体来说具有较高的执行效率;通过定义实例集来提高概念模型的可重用性;支持多重继承、类型一致性、数值一致性、集合基一致性检查,并且提供了分类一致性验证机制。
如图2所示,WebODE体系结构分为4层:

(1)第一层基于本体的应用提供了用户接口。通过使用IE等Web浏览器提供接口,使用HTML或XML与其它应用进行交互。
(2)第二层本体中间件提供了业务逻辑,包括两个子层:逻辑子层,通过Minerva Application Server使用一组定义好API(如Ontology Selection Services等)来对本体进行直接访问;表示子层,生成需要在用户浏览器上显示的内容,并且处理客户端用户的请求。
(3)第三层是数据层,即本体库(Ontology Library),本体存储在SQL关系数据库中,通过JDBC访问。
(4)第四层是本体开发和管理层,负责本体的编辑、合并、转化、评价等等。
3.4 Protégé
Protégé[36]是斯坦福大学为知识获取而开发的一个工具,主要应用于知识的获取以及现存本体合并和排列,可以免费下载并公开源代码,再加上其支持中文,Protégé已经成为目前国内使用最为广泛的本体编辑工具和基于知识的框架。Protégé主要具有以下特征:
(1)可扩展的知识模型能够使用户重新定义原始知识集合;
(2)友好的本体导入导出功能,可以从RDFS、带DTD的XML文件、XML Schema等文件中导入本体,也可以将本体转化为多种形式化语言描述,如RDF(S)、OWL等。
(3)具有友好的开发界面。
(4)具有强大的功能插件体系和开放的模块化风格。基于开放式组件的体系结构使系统开发者可以通过生成恰当的插件以增加新的功能。
(5)提供一个半自动化工具PROMPT用于自动地执行本体的合并和排列。
(6)Protégé平台支持两种类型的本体建模:①Protégé-Frames编辑器用于构建基于框架的本体。在这种模型中,本体是由具有层次结构的类集合组成,类的槽(slots)集合表示概念的属性和关系;类的实例集合则表示概念的具有特定属性值的个体;Protégé-OWL编辑器则用于构建应用于语义网的本体。专门使用W3C的OWL语言描述,一个OWL本体包含类的描述、属性以及实例。
Protégé因其简单易用性、不断升级的品质、免费获取的特性以及强大的功能可扩展性使之成为国内最受欢迎的本体构建工具之一。
3.5 KAON
KAON[37]是德国Karlsruhe大学编制的一套用于语义网和本体研究的工具,包含各种模块用于本体的构建、存储、检索、维护以及应用,其中OI-Modeler是KAON模块集中的本体建模工具,可便捷的实现本体的创建和维护。KAON是当前比较好的本体构建和维护工具之一,其主要特性如下所示:
(1)OI-Modeler提供了方便的、可视化的添加概念、属性、实例和概念间关系的方法,并通过树形结构策略实现本体管理。由于具有图示区,可以清晰地反映本体概念的变化情况,增加了知识含义的直观性。
(2)可以导出成标准的RDF数据格式,使得本体可被其它标准软件重用和共享。
(3)支持多人在局域网上同时构建同一本体,这就为在资金和人员到位的前提下,快速构建本体论提供了可能;在进行本体合并后,需要对其中的语义含义和词间关系进行修改和矫正,尤其是一些相互矛盾的语义,在线同时构建并试图建立与已有语义矛盾的关系时,OI-Modeler会提示错误原因。
除了前面介绍的本体开发工具外,还存在Apollo、LinkFactory、OILEd、Ontolingua、OntoSaurus、OpenKnoME等等工具可用于本体的构建和管理。这些本体开发工具功能各不相同,对于本体语言的支持能力、表达能力、逻辑支持能力以及可扩展性、灵活性、易用性等都相差甚远。就目前而言,在国内Protégé和KAON的使用最为广泛。
4 结束语
本文重点对本体构建过程中采用的指导思想、方法以及常用的工具进行了研究综述。认为现有的常用的本体构建工具往往支持本体开发的各个环节,因此在构建原则的指导下,选择适合特定领域本体构建的方法,使用支持该方法的构建工具,领域专家可以方便、可视化的开发特定领域的本体。
然而,需要指出的是,本体开发工具提供的仅仅是本体的编辑和管理功能,支持的是本体开发人员(包括领域专家)手工构建本体的方式,即人为的从文档中识别领域中每个概念以及概念的名字、约束、属性以及关系等内容,在逐个地输入和编辑以生成本体。显然上述方法费时、费力,而且专家建模往往带有偏见、具有误差倾向,使得基于领域文档实现本体构建特别是大型本体构建成为一项非常艰巨的任务。因此,如何利用知识自动获取技术来降低本体构建的开销成为一个很有意义的研究方向,即本体学习(ontology learning,OL)技术。随着语言学方法、数学方法不断引入OL中,机器自动化处理技术的逐渐成熟,半自动化或自动化构建领域本体的方法必将取代繁杂的手工操作,成为本体构建的主流技术。
参考文献
[1]http:∥www.w3.org/DesignIssues/Semantic.html[EB].Accessed:2007.10.
[2]T.R.Gruber.A Translation Approach to Portable Ontology Specifications[J].Knowledge Acquisition,1993,5:199-220.
[3]T.R.Gruber.Towards Principles for the Design of Ontologies Used for Knowledge Sharing[J].International Journal of Human Computer Studies,1995,43:907-928.
[4]J.Arpirez,A.Gomez-Perez,A.Lozano,and S.Pinto.(onto)2agent:An ontology-based www broker to select ontologies.In A.Gomez-Perez and V.R.Benjamins,editors,Proceedings of the Workshop on Applications of Ontologies and Problem-Solving Methods[J].held in conjunction with ECAI-98,16-24,Brighton,UK,August 1998.ECAI.
[5]A.G.Perez,V.R.Benjamins.Overview of Knowledge Sharing and Reuse Components:Ontologies and Problem Solving Methods[J].In:V.R.Stockholm,B.Benjamins,A.Chandrasekaran,eds.Proceedings of the IJCAI2 99 workshop on Ontologies and Problem2Solving Methods(KRR5),1999:1-15.
[6]李景,孟连生.构建知识本体方法体系的比较研究[J].现代图书情报技术,2004,(7):17-22.
[7]刘炜.信息资源组织方法论本体方法[EB].http:∥www.libnet.sh.cn/sztsg/ko/ch4本体方法.ppt.Accessed:2008.2.
[8]IEEE Standard for Developing Software Life Cycle Processes[J].IEEE Computer Society.New York(USA).April 26,1996.
[9]IEEE Standard Glossary of Software Engineering Terminology[J].IEEE Computer Society.New York(USA),1990.
[10]杨秋芬,陈跃新.Ontology方法学综述[J].计算机应用研究,2002,(4):5-7.
[11]M.Fernández López,Overview Of Methodologies For Building Ontologies[J].Proceedings of the IJCAI-99 workshop on Ontologies and Problem-Solving Methods(KRR5)Stockholm,Sweden,1999.8.
[12]M.Uschold,M.King.Towards a methodology for building ontologies[J].In Work shop on Basic Onto logical Issues in Know ledge Sharing,held in conjunction with IJCA I-95,Montreal,Canada,1995.
[13]M.Grüninger,M.S.Fox.Methodology for the Design and Evaluation of Ontologies[J].Workshop on Basic Ontological Issues in Knowledge Sharing,IJCAI-95,Montreal,1995.
[14]A.Bemaras,et al.Building and reusing ontologies for electrical network applications[J].In:Proc.of the European Conf on Artificial Intelligence.Budapest,Hungary:John Wiley and Sons,1996:298-302.
[15]M.Fernández,A.Gómez-Pérez,N.Juristo.METHONTOLOGY:From Ontological Art Towards Ontological Engineering[J].Symposium on Ontological Engineering of AAAI.Stanford(California).March 1997.
[16]M.Fernández López,Overview Of Methodologies For Building Ontologies[J].Proceedings of the IJCAI-99 workshop on Ontologies and Problem-Solving Methods(KRR5)Stockholm,Sweden,1999.8.
[17]B.Swartout,P.Ramesh,K.Knight,T.Russ.Toward Distributed Use of Large-Scale Ontologies.Symposium on Ontological Engineering of AAAI[J].Stanford(California).Mars,1997.
[18]A.Valente,T.Russ,R.McGregor,W.Swartout.Building and(Re)Using an Ontology of Air Campaign Planning[J].IEEE Intelligent Systems & their applications.January/February 1999.
[19]http:∥www.idef.com/idef5.html[EB].Accessed:2008.2.
[20]R.Mizoguchi,M.Ikeda,K.Seta and J.Vanwelkenhuysen,Ontology for Modeling the World from Problem Solving Perspectives[J].Proc.of IJCAI-95 Workshop on Basic OntologicalIssues in Knowledge Sharing,1995:1-12.
[21]Natalya F.Noy,Deborah L.McGuinness.Ontology Development 101:A Guide to Creating Your First Ontology[DB].2001.8.http:∥protege.stanford.edu/publications/ontologyzdevelopment/ontology101.pdf,Accessed:2008.2.
[22]A.Maedche and S.Staab.Learning ontologies for the semantic web[J].In Workshop on the Semantic Web(SemWeb),2001.
[23]S.Staab,H.-P.Schunurr,R.Studer and Y.Sure,Knowledge processes and ontologies[J].IEEE Intelligent Systems,Special Issue on Knowledge Management,2001,16(1):26-34.
[24]B.Bachimont,A.Isaac,and Troncy R.Semantic commitment for designing ontologies:a proposal[J].In A.Gomez-Perez and V.R.Benjamins(Eds.):EKAW 2002,LNAI 2473,2002:114-121.
[25]L.Khan,F.Luo.Ontology Construction for Information Selection[J].In Proc.of 14th IEEE International Conference on Tools with Artificial Intelligence,122-127,Washington DC,November 2002.
[26]D.Lonsdale,Ding Y,D.W.Embley,and A.Melby.Peppering Knowledge Sources with SALT;Boosting Conceptual Content for Ontology Generation[J].Proceedings of the AAAI Workshop on Semantic Web Meets Language Resources,Edmonton,Alberta,Canada,July 2002.
[27]D.I.Moldovan,R.C.Girju.An interactive tool for the rapid development of knowledge Bases[J].In International Journal on Artificial Intelligence Tools(IJAIT),vol 10.,no.1-2,March 2001.
[28]李景,苏晓鹭,钱平.构建领域本体的方法[J].计算机与农业,2003,(7):7-10.
[29]董慧,等.基于本体的数字图书馆检索模型研究(Ⅲ)——历史领域资源本体构建[J].情报学报,2006,(5):564-574.
[30]刘柏嵩.面向数字图书馆的本体学习研究[J].大学图书馆学报,2006,(6):30-34,38.
[31]唐爱民,真溱,樊静.基于叙词表的领域本体构建研究[J].现代图书情报技术,2005,(4):1-5.
[32]Y.Sure,S.Staab,M.Erdmann,J.Angele,R.Studer and D.Wenke,OntoEdit:Collaborative ontology development for the semantic web[J].Proc.of ISWC2002,2002:221-235.
[33]http:∥kmi.open.ac.uk/projects/webonto/[EB].Accessed:2008.2.
[34]http:∥webode.dia.fi.upm.es/WebODEWeb/index.html[EB].Accessed:2008.2.
[35]O.Corcho,M.Fernandez-Lopez,A.Gomez-Perez and O.Vicente,WebODE:An Integrated Workbench for Ontology Representation,Reasoning and Exchange[J].Prof.of EKAW2002,Springer LNAI 2473,2002:138-153.
[36]http:∥Protege.stanford.edu[EB].Accessed:2008.2.
[37]http:∥kaon.semanticweb.org[EB].Accessed:2008.2.
