基于Lucene的索引系统的设计与实现
2009-10-13黄少林王华张玉红蒋一峰
黄少林 王 华 张玉红 蒋一峰
〔摘 要〕索引系统是搜索引擎的数据大本营,在搜索引擎发展早期,能够索引的网页数量代表了整个行业的技术发展水平。Lucene全文检索技术是信息检索领域广泛使用的基本技术,它是一个优秀的开源全文本搜索技术框架,本文详细分析了索引系统相关技术和Lucene的索引系统结构。
〔关键词〕搜索引擎;索引;lucene;倒排索引
〔中图分类号〕TP393.09 〔文献标识码〕A 〔文章编号〕1008-0821(2009)07-0169-03
The Design and Implementation of Indexing System Based on LuceneHuang Shaolin Wang Hua Zhang Yuhong Jiang Yifeng
(School of Information Engineering,Capital Normal University,Beijing 100037,China)
〔Abstract〕Index system is the data center of the search engine,at the beginning of the search engine,the number of the pages that can be indexed to represent the technology level of the whole industry.Lucene full-text retrieval,as a basic skill,is widely used in the field of information retrieval;it is an excellent open-source full-text search technology framework.The paper analyzed Lucenes indexing system structure in detail and gave some introduction about the related technology of index system.
〔Key words〕search engine;index;lucene;inverted index
无论在工业界还是在学术界,搜索引擎一致地被认为分为下载、分析、索引和查询四大系统,这四大系统相互配合共同实现搜索引擎的快、全、准、稳的四大需求。索引系统是搜索引擎最核心的模块之一,索引过程就是将普通的文档形式转换为可快速检索的索引形式。例如,书目包含的目录。其中每一条目就是一个索引,用来标识某个章节的页码,帮助读者快速浏览,索引就是这样一个短小精炼的检索信息的信息。
1 lucene及索引技术介绍
1.1 lucene介绍
Lucene是apache软件基金会jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,它为数据访问和管理提供了简单的函数调用接口,可以方便的嵌入到各种应用中实现针对应用的全文索引/检索功能。Lucene的API接口设计得比较通用,输入输出结构都很像数据库的表、记录和字段,所以很多传统的应用的文件、数据库等都可以比较方便的映射到Lucene的存储结构或接口中。总体上看,可以先把Lucene当成一个支持全文索引的数据库系统。
1.2 索引技术
索引是在搜索时使用到的一种特殊的数据结构。当文档的数量相当庞大,并且这些文档中的信息相对稳定时,建立索引可以大大提高搜索时的效率。在使用索引进行查找时,首先对需要索引的文档进行预处理,建立关于这些文档的索引结构。索引技术主要有以下3种:倒排索引,后缀数组和签名文件。其中,倒排索引技术在当前大多数的信息检索系统中得到了广泛的应用,它对于关键词的搜索非常有效,在lucene中也是使用的这种技术。后缀数组技术在短语查询中具有很快的速度,但是这样的数据结构在构造和维护时都比较复杂一些。签名文件技术在20世纪80年代比较流行,但是后来倒排索引技术逐渐超越了它。
1.3 倒排索引技术
倒排索引是目前搜索引擎公司对搜索引擎最常用的存储方式,也是搜索引擎的核心内容,倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引。倒排索引是以关键字和文档编号结合,并以关键字作为主键的索引结构(见图1)。下面利用一个例子来说明倒排索引:
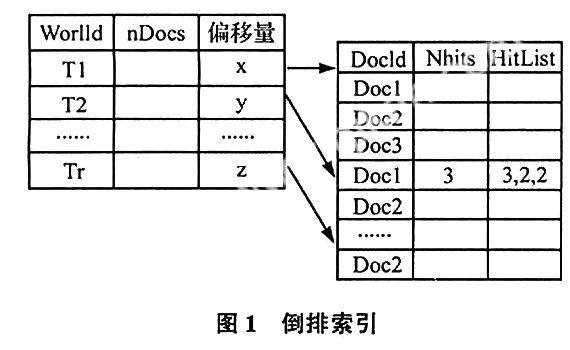
比如说有两个文档,doc1和doc2他们的内容分别如下:
Doc1:we are students。
Doc2:Are you student?
如果按照正常的索引建立如下所示:
文档名关键字次数
Doc1we1
Doc1are1
Doc2student1
Doc2Are1
……
这里索引的建立是以文档为标准的,这样当文档很多的时候数据量将非常的大,检索效率会明显下降的。
倒排索引是以单词为标准来进行索引的建立的。
还以上面的doc1和doc2为例:
关键字出现的文档次数
studentdoc21
wedoc11
Aredoc1 doc21?1
2 lucene索引建立
2.1 lucene索引结构
Lucene的索引结构在概念上即为传统的倒排索引结构。Lucene索引文件的概念组成和结构组成见图2。
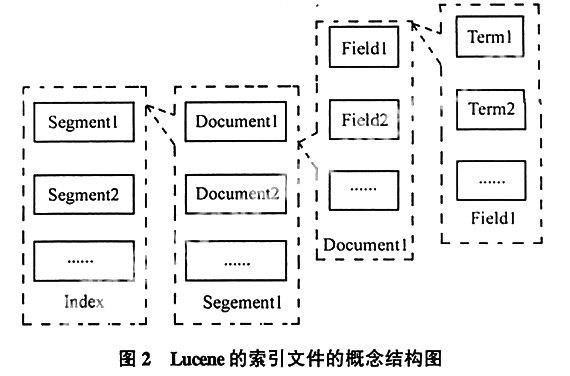
Lucene索引index由若干段(segment)组成,每一段由若干的文档(document)组成,每一个文档由若干的域(field)组成,每一个域由若干的项(term),组成。项是最小的索引概念单位,它直接代表了一个字符串以及其在文件中的位置、出现次数等信息。域是一个关联的元组,由一个域名和一个域值组成,域名是一个字串,域值是一个项,比如将“标题”和实际标题的项组成的域。文档是提取了某个文件中的所有信息之后的结果,这些组成了段,或者称为一个子索引。子索引可以组合为索引,也可以合并为一个新的包含了所有合并项内部元素的子索引。
2.2 lucene索引的建立
建立索引是使用搜索引擎的第一步,从整体上看,lucene建立索引的过程有以下4步(见图3):提取文本、构建Document、分析、建立索引。下面分别从这4个方面进行分析。
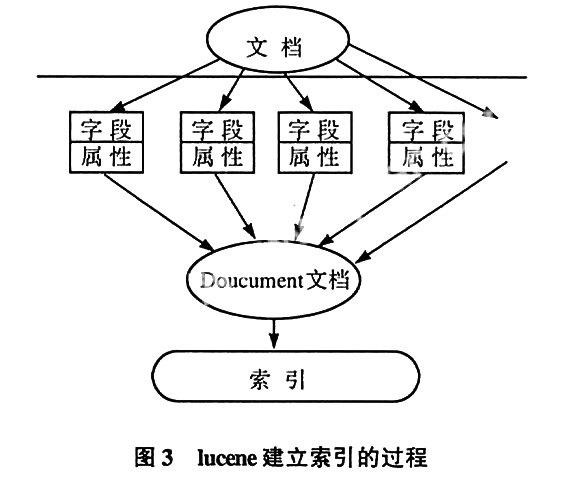
2.2.1 提取文本
为了使用Lucene对文档数据建立索引,第一步就是要把这些需要建立索引的文档数据转换成lucene可以处理的类型。假设现在的任务是对一系列PDF文档数据建立索引。首先为了使lucene能够对这些文档数据建立索引,必须想办法从这些PDF文档中提取文本信息,并且使用这些提取出来的信息构建lucene中的Document文档和Field。同样,当我们需要对word文档或者其它类型的文档建立索引时也面临着类似的问题。
2.2.2 构建Document
构建Document是索引建立的第二步。这一目的就是将前面所提取出来的文本组装成lucene可以识别的格式来为索引的建立做准备。
2.2.3 分析并建索引
在提取了需要lucene建立索引的数据并且构建了Document之后,接下来就可以调用IndexWriter类的addDocument()方法来使lucene建立索引了。在这样的调用中,lucene会首先对所要建立索引的数据进行分析以使得在建立索引时可以更加容易地处理这些数据,然后索引器会按lucene所规定的索引格式将数据写人索引文件。
2.3 lucene创建索引代码
public static void CreateIndex(File indexDir)
throws IOException
{
IndexWriter writer=new
IndexWriter(sDir,new
StandardAnalyzer(),true);
∥参数sDir是存放索引的目录。创建索引最重要的类是IndexWriter,其构造器有3个参∥数,第1个参数指定了存储索引文件的路径。第2个参数指定了在索引过程中使用什么∥样的分词器。第3个参数是个布尔变量,用于控制是重建索引,还是复用原有索引。
for(int i=0;i { Document doc=new Document();∥初始化一个Document Product product=(Product)prodList.get(i); File Field_name=Field.Text(“Field_name”,product.getFieldName);∥建立一个Field_name字段 Field Field_desc=Field.Text(“Field_desc”,product.getFieldDesc);∥建立一个Field_desc字段 doc.add(Field_name);∥将字段添加至这个Document doc.add(Field_desc);∥将字段添加至这个Document writer.addDocument(doc);∥将这个Document写入索引 } writer.optimize();∥索引优化 writer.close();∥关闭这个 indexWriter } 首先创建了类Document的一个实例,它由1个或者多个的域组成。你可以把这个类想象成代表了一个实际的文档,比如1条数据库记录,1个HTML页面,1个PDF文档,或者1个文本文件。而类Document中的域一般就是实际文档的一些属性。我们可以用不同类型的Field来控制文档的哪些内容应该索引,哪些内容应该存储。其次向文档中添加域,每个域包含两个属性,分别是域的名字和域的内容。在我们的例子中域的名字分别是Field_name和Field_desc。最后把准备好的文档添加到了索引当中。当把索引文档都添加到索引中后,要关闭索引,这样才保证lucene把添加的文档写回到硬盘上。 另外,在创建索引的工程中你可以充分利用机器的硬件资源来提高索引的效率当需要索引大量的文件时,索引过程的瓶颈是在往磁盘上写索引文件的过程中。为了解决这个问题,lucene在内存中持有一块缓冲区。lucene的类IndexWriter提供了3个参数mergeFactor、minMergeDocs、maxMergeDocs用来调整缓冲区的大小以及往磁盘上写索引文件的频率。 Lucene提供了删除索引的API可以删除文档,当需要更新文档时可以通过先删除再增加的方式来实现。这样索引构建模块就能够达到动态的更新索引的目的。 3 总 结 本文从lucene索引系统结构出发,分析了常用的索引相关技术,并详细阐述了一个基于lucene全文检索系统的索引模块设计以及实现。本文介绍的索引技术的实际应用可推广至许多其它的应用实例的设计与实现中,从而实现对目标文档的检索管理,提高检索效率。 参考文献 [1]梁斌.走进搜索引擎[M].北京:电子工业出版社,2007.10(1). [2]李刚,宋伟,邱哲.Ajax+Lucene构建搜索引擎[M].北京:人民邮电出版社,2006.4(1). [3]卢亮,张博文.搜索引擎原理、实践与应用[M].北京:电子工业出版社,2007.9(1). [4]孙西全,马瑞芳,李燕灵.基于Lucene的信息检索的研究与应用[J].情报理论与实践,2006,(1):125-128. [5]管建和,甘剑峰.基于Lucene全文检索引擎的应用研究与实现[J].计算机工程与设计,2007,(2):489-491. [6]王莉云,王华,陈刚,等.基于lucene的全文检索系统的设计与实现[J].计算机工程与设计,2007,(24):5959-5961.
