基于对比学习的文本生成图像
2025-02-15周刚李捍东陈烨烨


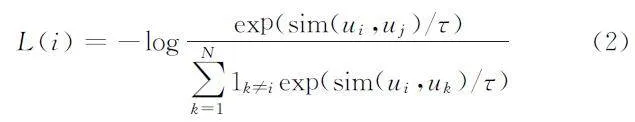

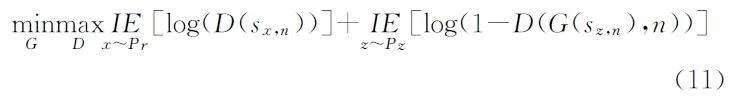

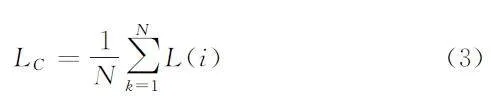
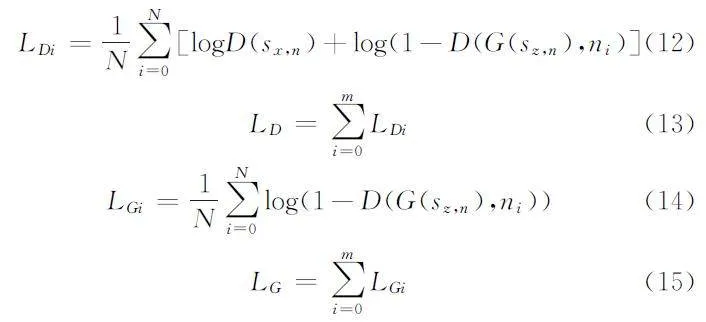
摘 要:针对在多目标文本生成图像和语义相关度高的情况下,于CUB数据集中进行实验时,发现生成的鸟图像中有许多“多头”“多脚”情况,文章在MA-GAN(多阶段注意力机制的生成对抗网络)模型上加入对比学习以优化图像生成。同时,采用特征插值方法增强图像的某些特征,从而提高语义一致性和文本辨识度。通过在CUB和COCO数据集上的实现验证,改进后模型的IS(InceptionScore)指标分别提高了0.11和2.58,而R 分数(Rprecision)指标分别提高了1.98和1.37,证明了改进后的模型能够解决图像质量和语义一致性问题。
关键词:文本生成图像;对比学习;文本特征表示;特征插值
中图分类号:TP393 文献标志码:A
0 引言(Introduction)
在文本生成图像的过程中,人为挑选同一类图片的文本特征词缺乏客观性,而在同一类图像的文本注释中,不同语义描述会造成生成图像的改变。为了使得到的图像质量更高和图文语义一致,代婷婷等[1]于2023年引入了对比学习方法以解决合成图像属性丢失的问题。曹寅等[2]于2024年提出了深度融合注意力的生成对抗网络。吴春燕等[3]于2023年提出了一种基于特征增强的生成对抗网络。贺小峰等[4]提出了一种语义-空间特征增强的生成对抗网络。MA等[5]提出了一种基于语义一致性的生成对抗网络。张佳等[6]于2023年提出了一种基于条件增强的深度融合生成对抗网络模型。因此,本文引入对比学习和特征插值方法对多阶段自注意力机制的文本生成图像模型进行优化。该方法能够增强语义一致性,并通过实验数据和图像结果验证方法的可行性[7]。
1 图文匹配算法(Imagematchingalgorithm)
图文匹配算法在跨模态中得到了广泛的运用,其主要作用是计算图像与文本的匹配程度。图文匹配算法就是用文本搜索许多与文本描述相一致的图像,在这个过程中,如何找到相似的图片,就依赖于文本与图片之间的关联度;与此类似,通过给定的一张图片,也可以找到与图片有关联的文本信息;在一些关于图像问答的任务中,可以通过图文两者之间的相关性得到图像中的信息。实际上,图文两者各自都代表了一种语言意义;而在跨模态的范围内,这两种模态的差异性能够呈现出千百种表现形式。
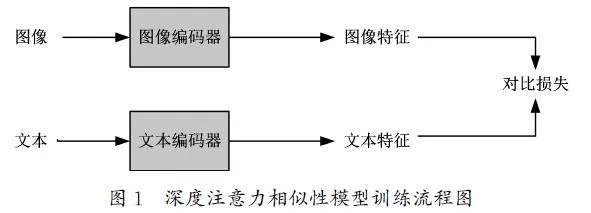
在文本到图像的生成过程中,关键在于图像和文本的精准匹配,在这个过程中实现对文本和图像的语义最大化处理。深度注意力多模态相似性模型的主要作用是对文本生成图像的细节进行优化。深度注意力相似性模型训练流程图如图1所示。深度注意力相似性模型[8](DAMSM)是通过训练不同的编码器来分别获取图像特征和文本特征,然后将两种特征编码到相同语义表达区间中,同时得到它们之间相似性的损失度。然而,对于同一个图像的文本描述是可以不同的,这就会造成生成图像背离原本图像的现象。为了解决这个问题,本文提出使用对比学习方法将同一图片对应的相似文本进行整合,并且抛弃那些和不同图片对应的文本表示。
2 MA-GAN模型架构(MA-GANmodelarchitecture)
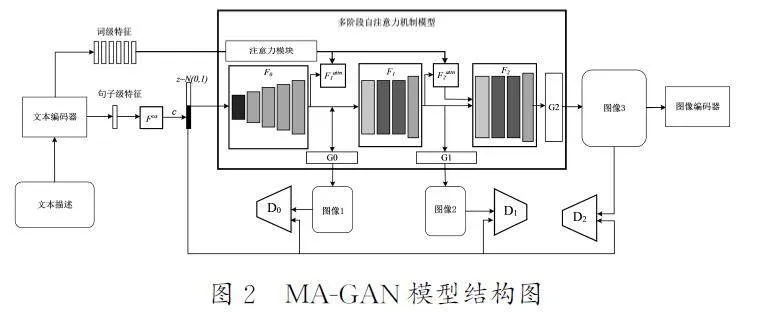
MA-GAN模型[9]加入了自注意力机制,其结构图如图2所示,注意力生成网络是这个模型的重要组成部分,加入自注意力机制的作用是用与图像最关联的单词生成图像的局部关键区域。该模型首先将输入的文本用相应编码器生成全局句子级特征向量,其中的关键词也会生成对应的词级特征向量。通过自注意力机制将句子级特征向量生成第一阶段的图像;其次利用生成的多个局部特征图像向量查找相关联的词级特征向量。最后利用生成的局部图像向量与对应的词级特征向量匹配得到多模态的特征向量。这个多模态特征向量能够使模型在附近的局部区间内合成与原图像不一样的特征。
3 模型训练(Modeltraining)
3.1 对比学习理论
对比学习方法因为具有自我监督的能力,所以在计算机视觉领域展现出巨大的吸引力。在众多对比学习方法中,比较有名的是SimCLR(SimpleContrastiveLearningofVisualRepresentations)模型,该模型能够在样本比较少的情况下较好地完成视觉方面的任务。在预训练相关模型中,SimCLR模型能够给出令人满意的答案。在SimCLR模型出现之前,有监督学习方式要比自监督的更具优势,而SimCLR模型的出现显著提高了自监督学习的性能,并且在图像进行分类任务中也有不错的表现。对比学习的过程,就是让机器学会区分两个样本的相似程度,对比学习原理图如图3所示。
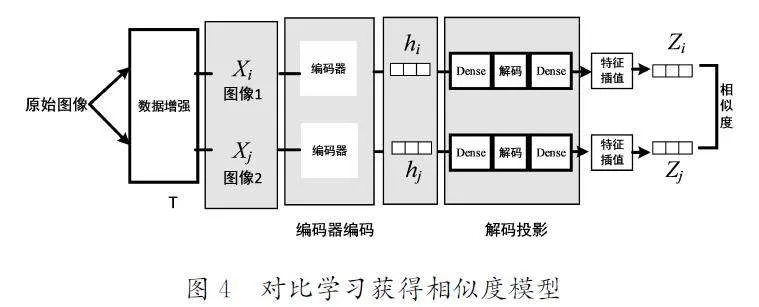
为了让机器学习更加准确地表示出样本的相似程度,我们需要解决几个关键问题。首先,要将相似的样本和不同的样本一起放入模型进行训练,这个过程需要用到无监督学习,而如何将这一学习方法融入模型是我们需要解决的第一个关键问题;其次,需要让机器学会如何识别图片中的有效信息,这是确保模型准确性的关键;最后,如何计算这些信息的相似度也是一个亟待解决的问题。为此,本文提出了一个有效的数据增强方案,首先输入一张原始图片,并对其进行数据增强处理,得到相应的增广图片,其次用基础编码器得到对应的图像信息,最后利用图像编码器以及特征插值生成对应的图像表现形式Z,其主要目的是得到原始图像处理后的不同图像的相似度。对比学习获得相似度模型如图4所示。
以原始图像为基础得到的图像hi 和hj 经过非线性处理后,将其依次进行解码,再经过特征插值对图像的特征进行增强并投影到不同的空间Z 中。不同空间中Z 的相似度计算运用如下面的余弦相似度公式:
Si,j= ZiTZj/τ‖Zi‖Zj‖ (1)
其中,τ 起到了一个调节输入的作用,并且余弦相似度的有效值也会随着其改变而改变。公式(1)用于计算出原始图像经过变体处理后得到的两个图像的余弦相似度,这种计算方式使得同类图片的相似度提升,而不同类图片的相似度下降。
3.2 模型预训练
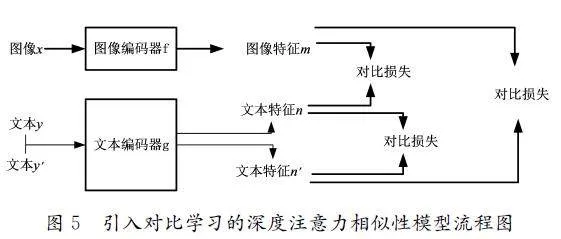
图像文本匹配的作用就是要让机器分辨出文本特征与图像特征的相似性。在文本生成图像的过程中,文本表示的特征作为生成图像的条件,本小节运用了一种更为有效的图文匹配模型。该模型运用了对比学习的思想,通过对应的解码器得到相对应的图像和文本特征,经过不同特征的两两对比,计算出相应的对比损失度。然而,相同的图像需要放入同一个空间中进行预训练处理,而不同图像的文本特征则是用对比损失度进行表示,损失度越高,则表明图文越不匹配。引入对比学习的深度注意力相似性模型流程图如图5所示。
该模型主要由3个部分组成。第一部分是采样过程,对于预训练过程来说,首先是对一小部分的图像和文本进行采样处理,而文本y 和文本y'匹配于图像x。在图文匹配过程中,不仅需要图像与文本的配对(xi,yi)和(xi,yi)作为正向匹配来计算图像xi的对比损失,而且还要通过正向的文本和文本的组合(yi,y'i )来得到对比损失度。第二部分是编码器,编码器的作用是提取出样本中的特征向量。图像编码器f是为了提取图像样本中全局和局部的视觉特征向量,而文本编码器g是用来提取出样本中全局和局部单词的特征向量表示[10]。如果文本编码器g能够在模型中实现为公共端口,那么整个框架就可以适用于多种神经网络模型。第三部分是损失函数,其值是通过不同样本之间的匹配结果计算得到的。计算损失度的损失函数如公式(2)所示:
其中:i 与j 互为正匹配关系;函数1k≠i只有在k≠i 时,才为1;τ 表示温度参数;N 为某一批次的数量。公式(3)用于计算最终的对比损失值,最终的对比损失通过计算一个小批量中的所有正配对损失得到。
在每次迭代过程中,给定图像编码器f、文本编码器g、温度参数及批次量N ,公式(4)和公式(5)分别是对小部分的图像x 和与之相关联的文本y 进行采样,而公式(6)是对与图像x有关的另一部分文本y'进行采样,然后使用公式(7)、公式(8)和公式(9)分别计算图像文本对的匹配损失度β1、β2 和β3,公式(10)用于计算总的损失度β。通过调整文本和图像编码器的参数,可以使得损失度β 降低。
m=f(y) (4)
n=g(y) (5)
n'=g(y') (6)
β1=DAMSM (m,n) (7)
β2=DAMSM (m,n') (8)
β3=NT-Xent(n,n') (9)
β=β1+β2+β3 (10)
预训练过程就是预先对其编码器进行训练的过程,一是学习如何将文本与图像有效匹配,掌握图文配对的内在表示方式;二是学习如何表达具有相同图像属性的文本,并探索比较不同图像属性差异的方法。编码器通过预训练后,能够在改进后的模型中得到图像和文本相匹配的属性,这样就可以用对比损失度减小与同一类图像关联的文本表示的差距,并且增大与不同类图像关联的文本表示的差距。
3.3 GAN训练的对比学习
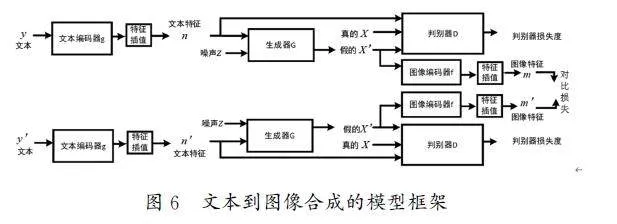
本文中COCO(CommonObjectsinContext)和CUB(Caltech-UCSDBirds-200-2011)数据集中的图片都是由人工标注,因此对相同图片的文本描述是有很大区别的。在复杂的场景中,文本单词的不同选择会引入主观因素的影响,导致同一图像可能产生多种不同的文本描述,这使得机器难以学到一致且准确的特征,进而影响最终模型生成的图像质量,使其可能不符合预期要求。在框架中增加对比学习方法能够使图像和对应文本的表示相关性更强,并且生成的图像更加真实。文本到图像合成的模型框架如图6所示。
(1)采样。采样过程中需要采样一小部分的图像x、文字y 和文字y',而文本y 和y'都与各自的图像x 相对应。模型的输入是文本y 和y',而图像x 和x'则是模型中生成器的输出。将图像特征对(mi,m'j)作为对比学习的正配对。
(2)模型架构。GAN(生成对抗网络)模型主要通过生成器与判别器之间的对抗机制生成逼真的数据。生成器G为判别器D提供判别的数据,而判别器D则是用真实训练样本判断新数据的有效性。该GAN方法使用的统一框架是从传统GAN扩展而来的,辅助信息n 是由文本y 通过编码器g转换得到的。GAN模型以此文本信息为基础,通过对抗训练的方式,不断优化生成的数据,过程如公式(11)所示:
(3)损失函数。除了对抗性损失,还有利用同一种文本得到的衍生图像之间的对比损失。通过对比损失,能够将两个不同文本表示生成的相同图像的差异性降到最低,并且把与之生成的不同图像的差异性提升至最高。这里同样运用了前文提出的归一化温标交叉熵损(NT-Xent)作为对比损失。
(4)相关公式。通过公式(2)和公式(3)能够推导出生成器G和判别器D的损失度公式,公式(12)至公式(15)分别用于计算判别器D和生成器G的损失度:
其中:sx,n是图像与文本特征的配对(xi,ni)在判别器D中的输入,而sz,n则是噪声与文本特征的配对(zi,ni)在生成器G中的输入。
4 实验结果分析(Analysisofexperimentalresults)
对比试验同样采用的是CUB数据集和COCO 数据集。实验主要是从两个角度对模型的性能进行对比。一是通过量化指标评估模型的性能,主要选取了初始分数(IS)指标和Rprecision[11]。初始分数是通过计算KL散度条件和边际概率分布得到的,该值越大,说明模型性能越好,生成的图像质量更好且具有多样性;R-precision指标则是用来评价文本和生成图像的匹配度,该值越高,说明输入的文本和生成的图像匹配度越高。二是通过直观的视觉效果评判模型性能的优劣,主要是通过模型最后生成的图像结果进行比较。
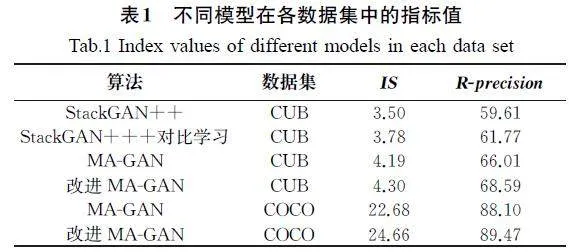
实验分别是在MA-GAN模型和StackGAN++(RealisticImageSynthesiswithStackedGenerativeAdversarialNetworks)模型[12]的基础上加入了对比学习的方法,MA-GAN模型使用了CUB和COCO数据集进行训练,而StackGAN++模型使用CUB数据集进行训练。为了实现模型的最优收敛速度,需要将生成器和对抗器的学习率都设为0.0002。实现运行环境选择在Colab平台进行,而模型训练则是依托NVIDIA显卡和Pytorch框架实现。不同模型在各数据集中的指标值如表1所示。根据表1中的实验结果可以看出,在加入对比学习方法后,MA-GAN和StackGAN++模型在CUB数据集中获得的IS和R-precision分别提高了0.11、2.58和0.12、2.16。MA-GAN模型在COCO数据集中获得的IS和R-precision分别提高了1.98和1.37。与CUB数据集相比,COCO数据集适用于更加复杂的场景。在加入对比学习方法后,模型在更为复杂的COCO数据集上依然表现出色。综上所述,从数据化层面来看,模型在加入了对比学习方法后,无论在CUB数据集还是COCO数据集,其各项指标都有了一定程度的提升。
为了进一步验证改进方法的可行性,我们分别在CUB数据集和COCO数据集上对改进前后的模型进行了图像生成结果的对比分析。通过对比生成的图像,可以明显看出改进后的模型生成的图像更加逼真,与文本描述更为契合,并且有效解决了生成图像中出现的“畸形”问题。
根据MA-GAN模型生成的图像可以明显看出多头现象的问题,改进前模型在CUB数据集中的效果图如图7所示。
在加入对比学习后,生成的图像中畸形现象显著减少,图像质量得到明显提升。改进后模型在CUB数据集中效果图如图8所示。
在COCO数据集中,模型改进前后的图像生成效果存在显著差异,改进前模型在COCO数据集中的效果图如图9所示。改进前,尽管草地等背景元素与文本描述相符,但是目标对象如牛的关键特征难以辨别,表明原MA-GAN模型在多目标场景中表现欠佳。在加入对比学习后,生成的图像中牛和草地的基本特征均清晰可见,图像质量得到显著提升。改进后模型在COCO数据集中的效果图如图10所示。无论是在CUB数据集还是在COCO数据集中,改进后的模型都能够生成更加清晰和逼真的图像。因此,从可视化角效果的层面来看,对比学习和特征插值方法的加入使得MA-GAN模型能够更好地解决效果图特征失效的问题。
5 结论(Conclusion)
本文在MA-GAN模型的基础上引入了对比学习和特征插值的方法,使得生成的图像拥有更高的质量和文本描述匹配度。通过对比改进前后模型的实验结果,我们采用两个数据化评价指标验证了改进模型的性能,同时从视觉层面也确认了改进模型能够有效解决生成图像“畸形”的问题。尽管引入对比学习后,生成的图像与文本描述高度一致,但是我们发现改变文本描述无法控制其图像的局部特征改变,例如在CUB数据集中,如果改变鸟冠颜色的描述,那么鸟的其他特征也会相应改变,就无法只改变所描述部分的局部特征。改变鸟的羽毛特征描述,也会出现同样的结果。这表明,改进后的模型在根据局部特征描述控制生成图像局部特征方面仍存在不足。因此,如何更精准地依据文本描述控制生成图像的局部特征,仍是未来研究需要深入探索的方向。
参考文献(References)
[1]代婷婷,范菁,曲金帅,等.基于Transformer和对比学习的文本生成图像方法[J].中国科技论文,2023,18(7):793-798,812.
[2]曹寅,秦俊平,高彤,等.基于生成对抗网络的文本两阶段生成高质量图像方法[J].浙江大学学报(工学版),2024,58(4):674-683.
[3]吴春燕,潘龙越,杨有.基于特征增强生成对抗网络的文本生成图像方法[J].微电子学与计算机,2023,40(6):51-61.
[4]贺小峰,毛琳,杨大伟.文本生成图像中语义-空间特征增
[5]MAY,LIUL,ZHANGHX,etal.Generativeadversarialnetworkbasedonsemanticconsistencyfortext-to-imagegeneration[J].Appliedintelligence,2023,53(4):4703-4716.
[6]张佳,张丽红.基于条件增强和注意力机制的文本生成图
[7]谭红臣.文本至图像生成的语义一致性研究[D].大连:大连理工大学,2021.
[8]李校林,高雨薇,付国庆.基于生成对抗网络的文本转图像研究[J].计算机应用与软件,2024,41(3):188-193,219.
[9]何义.基于生成对抗网络的文本图像研究[D].贵阳:贵州
[10]何丽.基于多模态神经网络的图文摘要生成方法研究
[11]SINGHV,TIWARYUS.Visualcontentgenerationfromtextualdescriptionusingimprovedadversarialnetwork[J].Multimediatoolsandapplications,2023,82(7):10943-10960.
[12]ZHANG H,XU T,LIH S,etal.StackGAN:realisticimagesynthesiswithstackedgenerativeadversarialnetworks[J].IEEEtransactionsonpatternanalysisandmachineintelligence,2019,41(8):1947-1962.
作者简介:
周 刚(1998-),男(汉族),广安,硕士生。研究领域:计算机控制,自动化控制。
李捍东(1966-),男(汉族),遵义,教授。研究领域:计算机控制,嵌入式系统。
陈烨烨(1998-),女(汉族),遵义,硕士。研究领域:控制工程,新能源技术。
