基于深度学习的咖啡果实成熟度检测方法
2025-02-15郑昊魏霖静



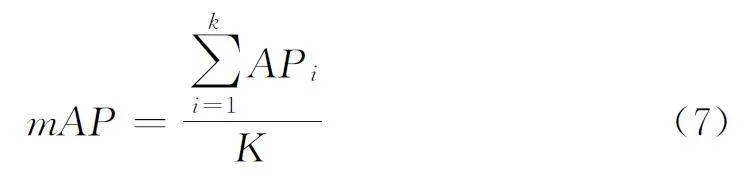


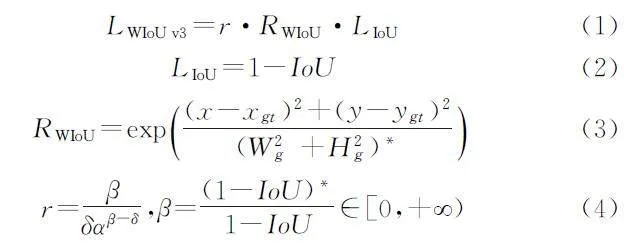
摘 要:针对目前咖啡果实的成熟度主要依赖人工判断且果实相互遮挡导致识别难度大的问题,文章提出一种改进的YOLOv8模型的咖啡果实成熟度检测方法。首先,在Backbone端使用iRMB(InvertedResidualMobileBlock)混合网络模块替换C2f(CSPBottleneckwith2Convolutions),增强模型特征表示能力;其次,引入BiFormer 注意力机制,增强对遮挡和小目标果实的检测能力,更换CARAFE(Content-AwareReAssemblyofFeatures)上采样算子,拓宽感受视野;最后,引入Wise-IOU损失函数,加速模型收敛。经验证,相比于原算法,改进算法的精确率、召回率、平均精确率分别提升了6.1百分点、1.0百分点、2.9百分点。研究结果表明,改进的YOLOv8模型可以为咖啡果实的成熟度检测提供有效参考。
关键词:咖啡果实;成熟度检测;YOLOv8;CARAFE;BiFormer
中图分类号:TP391 文献标志码:A
0 引言(Introduction)
咖啡作为我国热带地区的重要经济作物,其果实的成熟度直接影响咖啡豆的口感和香气。然而,在传统的咖啡果实的采摘过程中,工人主要依赖肉眼观察和个人经验来判断咖啡果实的成熟度,这种方式不仅效率低下,而且易受工人疲劳程度、光线条件等多种因素的影响,导致采摘的果实品质参差不齐。因此,有效地识别和分类咖啡果实的成熟度,对于确保咖啡的品质和提升其经济效益至关重要。
目前,用于果实检测的算法主要分为两种,即YOLO(YouOnlyLookOnce)系列算法、SSD(单激发多框检测)[1]等一阶段目标检测算法和FasterR-CNN(FasterRegion-basedConvolutionalNeuralNetworks)[2]等两阶段目标检测算法。相较于其他目标检测模型,YOLO系列算法在检测精度、多尺度检测能力、速度与性能的平衡以及适应性和灵活性等方面表现出色。尽管YOLO在检测全尺寸的目标上效果较好,但是当处理具有不同尺寸的特殊场景时,YOLO算法在检测小尺寸目标时表现不佳。咖啡果实的目标尺寸较小,而当前多数算法在检测小目标时精度普遍不高,这给模型准确检测并提取咖啡果实的特征带来了很大挑战。
1 相关研究(Relatedresearch)
近年来,基于深度学习的目标检测技术发展迅速,TAMAYO-MONSALVE等[3]通过卷积神经网络和迁移学习,对不同成熟阶段的咖啡果实进行分类,平均精确度达到98%。KAZAMA等[4]为监测咖啡果实成熟度,将RFCAConv模块集成到YOLOv8n中,模型平均检测精度均值mAP为74.2%。RAMOS等[5]设计了一种多视图立体视觉(Multi-ViewStereo,MVS)模型,利用MVS技术赋予机器人三维空间感知能力,从而能够对咖啡果实进行精确计数,并评估其成熟度。然而,咖啡果簇中果实数量不定,从几颗到数十颗不等,并且果实之间通常紧密相邻,相互簇拥,加之光照和气候等因素的共同作用,果实开花的均匀性受到影响,导致同一果簇内的果实成熟程度不一致,相邻果实的成熟度差异并不明显。这些因素相互交织,使得上述模型在检测相近成熟度及部分被遮挡的果实时,其性能表现不佳。
为了解决这一问题,本研究提出了一种改进的YOLOv8模型,该模型针对咖啡果实成熟度检测进行了优化。在自然环境下,该模型能够有效地识别和分类咖啡果实的成熟度,展现出出色的检测效果,为咖啡果实的成熟度检测提供了有力的参考依据。
2 材料与方法(Materialsandmethods)
2.1 图像采集
本研究使用咖啡果实开源数据集,共获取不同植株及不同成熟度的咖啡果实图像1206张。采集图像类型包括枝叶遮挡图像和重果图像,咖啡果实样本图片如图1所示。
2.2 果实成熟度等级划分
咖啡果实的成熟过程是一个循序渐进的、富有变化的过程,这一过程主要经历了4个阶段:青涩期的果实为鲜绿色;进入生长期后,果实的颜色由绿转黄;进入转色期后,果实的颜色由黄变橙黄或红,标志着果实接近成熟;到了成熟期,果实呈现深红色或紫红色,此时需及时采摘[6]。咖啡果实4级成熟度如图2所示。
2.3 数据构建
为了提高所训练模型的泛化能力,避免网络发生过拟合现象,对所获得的图像进行数据增强,通过随机添加高斯模糊、调整亮度等操作,将数据集扩充至3618幅图像。增强后的数据图像如图3所示。在完成数据集建立后,使用LableImg软件对图像中的咖啡果实进行手动分类标注,并将标注信息存储为txt格式,最终以7∶2∶1的比例,随机地将数据集划分为训练集、验证集和测试集。
3 咖啡成熟度检测方法(Coffeeripenesstestmethod)
3.1 YOLOv8目标检测网络
YOLOv8[7]是Ultralytics公司推出的目标检测模型,它在前代YOLO 模型的基础上进行了较大的改进和创新。YOLOv8保持了YOLO系列一贯的高速度和高精度特性,模型的高性能意味着它可以处理大量图像数据,而高准确性则确保了检测结果的可靠性。YOLOv8采用了先进的骨干网络和颈部架构,提供了较强的特征提取能力,使其能够更准确地识别和定位咖啡果实。此外,YOLOv8提供了一系列预训练模型,这些模型已经针对多种任务进行了优化,使得研究者可以快速部署并适应特定的检测需求。综上所述,YOLOv8凭借其高性能、先进架构、丰富的预训练模型以及便捷的集成与部署特性,成为咖啡果实成熟度检测的理想选择。
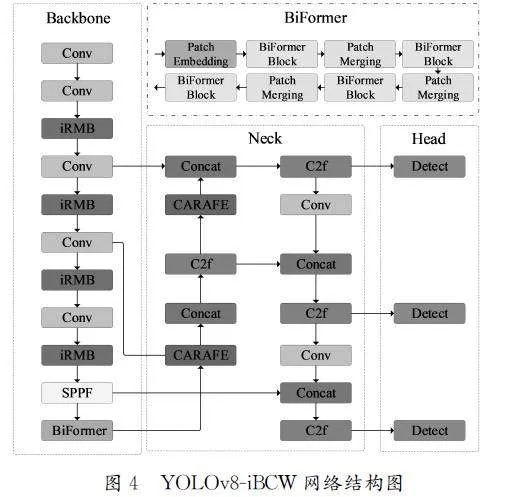
3.2 YOLOv8-iBCW 网络结构
首先,使用iRMB替换主干特征提取C2f,增强了模型的特征提取能力。其次,在SPFF(SpatialPyramidPoolingFast)后面添加BiFormer注意力机制,使模型能够更加集中地识别出与果实成熟度相关的特征,从而提升模型检测的精确度。最后,使用CARAFE替换原有的上采样方法,拓宽了感受视野,提升了特征图质量。YOLOv8-iBCW 网络结构如图4所示。
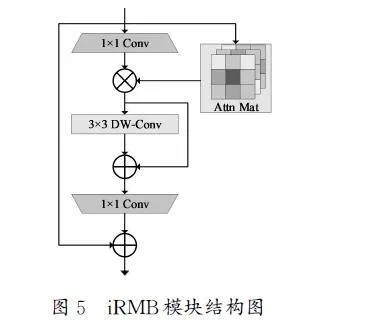
3.3iRMB倒置移动残差模块
为了解决传统C2f模块在进行特征融合时会增加模型计算量,导致模型训练和推理时间增加且不适合小目标检测的问题,引入iRMB(InvertedResidualMobileBlock)倒置移动残差模块[8]增强模型的特征表示能力,提升其对小尺寸咖啡果实的检测能力。iRMB结合了卷积神经网络(CNN)的轻量级特性和Transformer模型的动态处理能力,通过倒置残差(InvertedResidualBlock)设计改进了信息流的处理,提高了预测准确性。基于倒置残差结构,首先,特征图通过卷积层(PointwiseConvolution)使用1×1卷积核扩展通道数;其次,通过3×3的卷积核的深度可分离卷积(DepthwiseSeparableConvolution)提取特征,并通过pointwise卷积再次减少通道数;最后,特征图通过一个上采样操作恢复到原始的空间尺寸。iRMB模块结构图如图5所示。
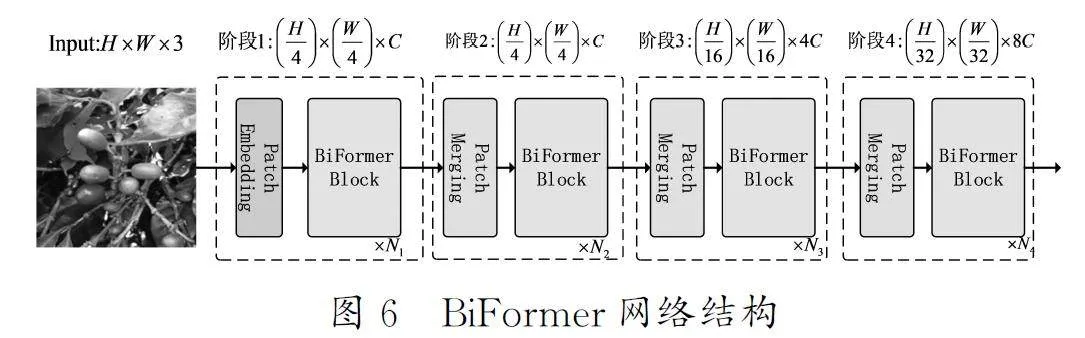
3.4BiFormer注意力机制
针对咖啡果实的小目标检测任务,为了同时提高对小目标的检测精度和模型的整体运行效率,本研究引入动态稀疏注意力BiFormer[9]。该机制能够有效去除冗余的背景特征,使模型聚焦于咖啡果实目标检测的关键区域,通过动态调整注意力分布,使得模型能够更加关注与目标检测相关的特征,从而提高检测的准确性。BiFormer采用4层金字塔结构,其网络结构如图6所示。在第一阶段,它使用重叠图像块嵌入技术捕捉局部特征;在第二阶段至第四阶段,通过图像合并模块降低分辨率并增加通道数,以捕获更丰富的特征信息。连续的BiFormerBlock通过转换输入数据的特征,从而进一步提升特征的表达能力。每个BiFormerBlock都是首先应用3×3深度可分离卷积,隐式编码相对位置信息。其次引入了BRA(Bi-LevelRoutingAttention)模块捕获双向相对注意力,使模型能够更深入地理解特征之间的关系。最后使用双层感知器模块进行关系建模和位置嵌入,从而进一步提升特征的语义信息。
3.5 上采样算子CARAFE
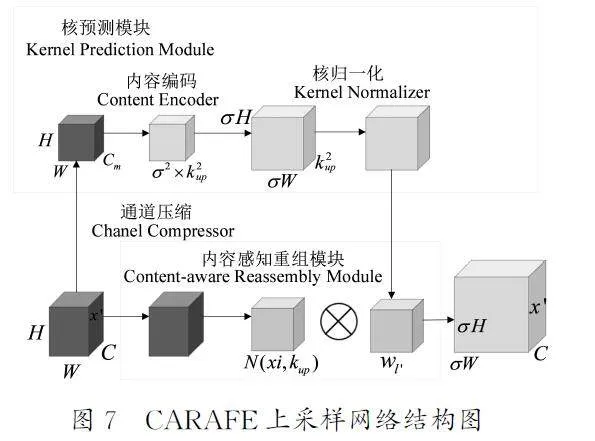
在YOLOv8中,传统的上采样层通常采用最近邻插值方法,但是最近邻插值仅依赖于最近的像素值进行放大,忽略了图像中的细微变化和密集语义信息,导致放大后的图像可能出现模糊和失真,尤其是在需要捕捉精细特征的场景下表现不佳。为了解决以上问题,本文采用了具有大感受野的上采样算子CARAFE(Content-Aware ReAssemblyofFeatures)[10]。CARAFE能够在整个图像范围内聚合语义信息,从而在上采样过程中保留更多的细节和语义信息,提高了图像质量。
首先,CARAFE采样核预测模块输入的特征图通过1×1卷积进行通道压缩,这一步骤有效减少了维度并降低了计算复杂度。其次,内容编码器根据压缩后的特征生成上采样核,得到上采样核大小为σH×σW ×K2up ,其中σ 是上采样率,Kup 是重组核的大小。这些核通过归一化操作确保其权重和为1,以便在后续的重组过程中进行有效的特征融合。特征重组模块将输出特征图映射回自身的输入特征图的相应区域中,将不同区域的Kup×Kup 与输入采样核进行点积,从而获得输出数据。最后,得出特征图像尺寸为σH ×σW ×C。采用这种方法,CARAFE可以更有效地提高特征图像的清晰度和增大信息量,并保证算法的轻量级。CARAFE上采样网络结构图如图7所示。
3.6 WIoU损失函数
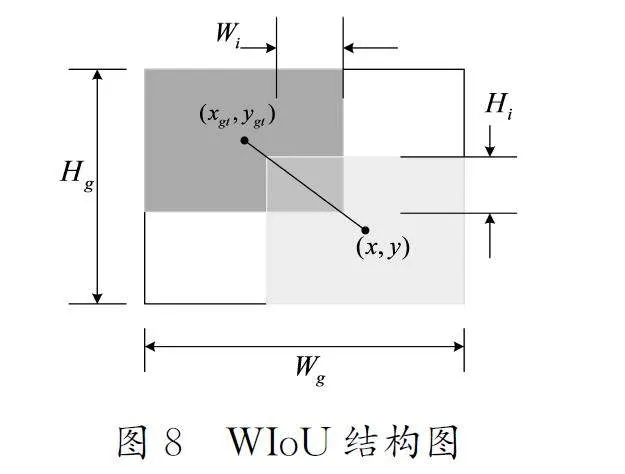
YOLOv8网络在预测边框坐标时使用了基于CIoU(CompleteIntersectionoverUnion)[11]的损失函数LCIoU。为提升边界框回归的准确性,CIoU考虑了重叠面积、中心点距离和宽高比3个几何因素。然而,CIoU在处理低质量锚框时,可能会施加过大的惩罚,进而影响模型的泛化能力。为了解决这种问题,本研究在改进的网络中使用了WIoU(Wise-IoU)[12]作为损失函数,WIoU结构图如图8所示。
WIoUv3边界框回归损失方法通过引入动态非单调机制和合理的梯度增益分配策略,优化了目标检测模型的训练过程。该方法特别针对样本中的极端样本问题,如大梯度或有害梯度,通过有效减少这些不利因素对模型训练的影响,增强了模型对普通质量样本的关注,从而提升了网络的泛化能力和整体性能。通过距离度量构建距离注意力,得到具有两层注意力机制的WIoUv3,WIoUv3的计算如公式(1)至公式(4)所示:
其中:r 为非单调聚焦系数;Wg 和Hg 分别表示最小包围框的宽和高,将Wg 和Hg 从计算图中分离出来,避免RWIoU产生阻碍收敛的梯度;*表示最小边界框的维度与计算图分离;(x,y)和(xgt,ygt)分别是预测框和真实框的中心点;IoU 是候选框与真实框的交并比;β 是离群度;δ 和α 是超参数。
与CIoU损失函数相比,WIoU损失函数通过动态调整梯度增益和减少离群度的影响,提高了模型对咖啡果实的定位精度和检测性能。
4 实验结果与分析(Experimentalresultsand
4.1 实验环境与参数设置
本实验在Windows11操作系统上进行,采用Pytorch深度学习框架作为实现基础,使用了NVIDIAGeForceRTX4060GPU,CPU为i7-13650HX,Python版本为3.8,Epochs迭代次数为300,训练批次设置为8,学习率设置为0.01,优化器为SGD。
4.2 模型评价指标
为了全面评估模型的检测性能,本研究引入了准确率(Precision)、召回率(Recall)、平均精度均值(meanAveragePrecision,mAP)作为核心评价指标。准确率是指在评估模型为正类的样本,与实际为正类的样本的比率,其公式如公式(5)所示。召回率是指在所有的真实为正类样本中,根据模型真实发现并估计的为正类的比率,其公式如公式(6)所示:
Precision= TP/TP+FP (5)
Recall= TP/TP+FN (6)
mAP是目标检测领域中一个重要的性能评估指标,它用于衡量检测算法在多个类别和不同IoU(交并比)阈值下的平均精度。mAP的计算方式如公式(7)所示:
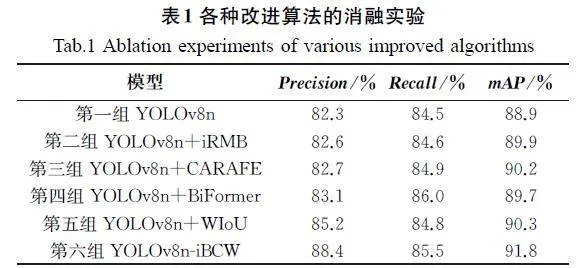
4.3 消融实验
为了验证本文提出改进的YOLOv8算法的检测性能,设计以下6组消融实验。从表1可以看出,各种改进算法的精确率、召回率、mAP均高于YOLOv8原始模型的相应指标。在第二组实验中将C2f替换为iRMB模块后,模型的精确率、召回率、mAP分别提升了0.3百分点、0.1百分点、1.0百分点。在第三组实验中引入上采样算子CARAFE后,模型的精确率、召回率、mAP分别提升了0.4百分点、0.4百分点、1.3百分点。在第四组实验中引入BiFormer注意力机制后,模型的精确率、召回率、mAP分别提升了0.8百分点、1.5百分点、0.8百分点。在第五组实验中引入WIoU损失函数后,模型的精确率、召回率、mAP分别提升了2.9百分点、0.3百分点、1.4百分点。在第六组实验中,YOLOv8n-iBCW 在融合多个模块的优势后,其精确率、召回率、mAP分别提升了6.1百分点、1.0百分点、2.9百分点。
4.4 损失函数对比
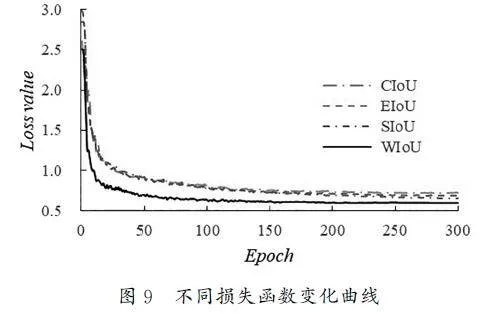
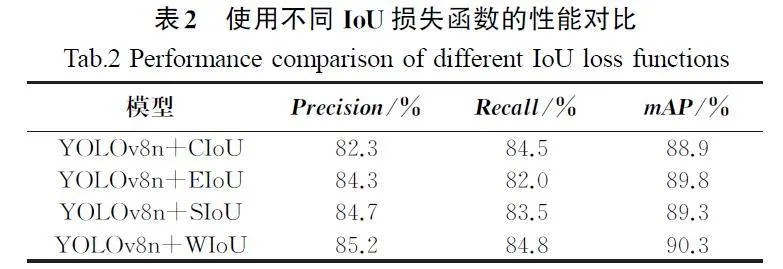
YOLOv8原模型使用CIoU作为边框回归损失函数,在模型预测边界框的宽高比时用相对值描述,导致计算过程中有许多不确定性。本试验针对改进的YOLOv8n模型,对比了使用不同IoU损失函数(包括WIoU、CIoU、EIoU[13]、SIoU[14])的性能和收敛情况,其对比结果如表2所示,使用WIoU损失函数的改进YOLOv8n模型在精确率、召回率及mAP等关键指标上均有提升。
由图9可知,采用CIoU时,模型的收敛速度最慢且收敛后的损失值最高,采用EIoU和SIoU的收敛速度略高于CIoU的收敛速度。采用WIoU 后,模型在训练时的梯度下降速度最快,在前20轮迭代周期快速收敛,收敛后的损失值远小于另外3种损失函数。由此可知,WIoU更适用于咖啡果实成熟度检测数据集。
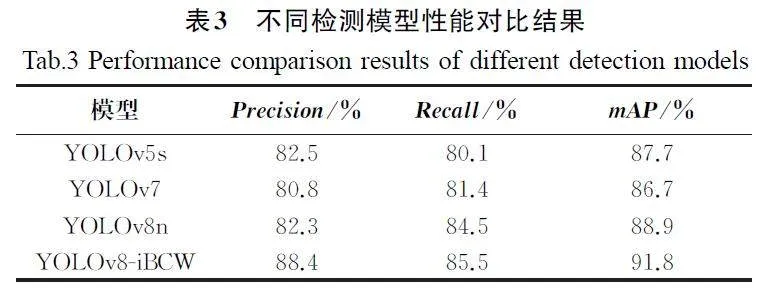
4.5 不同目标检测网络对比结果分析
为定量比较改进模型的性能,将改进模型与YOLOv5s模型、YOLOv7[15]模型以及原始YOLOv8n模型在测试集上进行性能比较。不同模型在测试集上的性能对比结果如图10所示。从图10中可以看出,YOLOv5s和YOLOv7模型虽然能够较好地识别小目标,但是重果识别效果较差,部分图像中将叶片误判为果实,存在误识别和漏检的情况。YOLOv8n模型对重果、枝叶遮挡、多目标情况的识别效果较好,但对小目标存在误检和漏检情况。相比于以上算法,改进的YOLOv8-iBCW算法针对小尺寸目标的识别表现良好,对于重叠果实、枝叶遮挡以及多目标场景的识别同样展现了较高的准确性。
不同检测模型性能对比结果如表3所示。从表3中的数据可知,与其他模型相比,改进的YOLOv8n模型在精确率、召回率、平均精度指标方面都是最优的,分别为88.4%、85.5%和91.8%,其平均精度均值mAP与YOLOv5s、YOLOv7及原始YOLOv8n模型的平均精度均值相比,分别提升4.1百分点、5.1百分点和2.9百分点。通过以上分析可见,本文提出的YOLOv8-iBCW 算法在多个指标方面均展现出优越性,实现了对咖啡果实成熟度高效、准确的识别,验证了本研究提出的改进模型更适用于咖啡果实成熟度检测任务。
5 结论(Conclusion)
本研究针对咖啡果实成熟度检测问题,提出一种改进的YOLOv8算法,即YOLOv8-iBCW 模型。将传统的C2f主干特征提取模块替换为iRMB模块,有效地增强了模型对复杂背景中小目标的特征提取能力。引入BiFormer注意力机制,使模型能够更加关注图像中与成熟度判断相关的区域,增强了对遮挡和小目标果实的检测能力。将传统的上采样方法替换为CARAFE上采样算子,在提升特征图分辨率的同时,还保证了计算效率。引入Wise-IOU损失函数,提高了模型的泛化能力和整体性能。实验结果表明,改进的YOLOv8-iBCW 模型获得的mAP为91.8%,与YOLOv5s、YOLOv7和YOLOv8n相比,分别提高了4.1百分点、5.1百分点和2.9百分点;改进后模型的精确度等指标均优于对比算法的相关指标,为咖啡果实成熟度检测提供了方法支持。
参考文献(References)
[1]JINL,LIUGD.AnapproachonimageprocessingofdeeplearningbasedonimprovedSSD[J].Symmetry,2021,13 (3):495.
[2]李翠明,杨柯,申涛,等.基于改进FasterR-CNN的苹果采摘视觉定位与检测方法[J].农业机械学报,2024,55(1):47-54.
[3]TAMAYO-MONSALVEMA,MERCADO-RUIZE,VILLA-PULGARINJP,etal.Coffeematurityclassificationusingconvolutionalneuralnetworksandtransferlearning[J].IEEEaccess,2022,10:42971-42982.
[4]KAZAMAEH,TEDESCOD,DOSSANTOSCARREIRAV,etal.Monitoringcoffeefruitmaturityusinganenhancedconvolutionalneuralnetworkunderdifferentimageacquisitionsettings[J].Scientiahorticulturae,2024,328:112957.
[5]RAMOSPJ,PRIETOFA,MONTOYAEC,etal.Automaticfruitcountoncoffeebranchesusingcomputervision[J].Computersandelectronicsinagriculture,2017,137:9-22.
[6]李亚麒,娄予强,何红艳,等.咖啡果实不同成熟度对其品质的影响[J].种子,2022,41(12):78-84,92.
[7]TERVENJ,CÓRDOVA-ESPARZADM,ROMERO-GONZÁLEZJA.AcomprehensivereviewofYOLOarchitecturesincomputervision:fromYOLOv1toYOLOv8andYOLO-NAS[J].Machinelearningandknowledgeextraction,2023,5(4):1680-1716.
[8]齐瑞洁,袁玉英,孙立云,等.基于改进YOLOv8n的施工现场安全帽检测算法[J].电子测量技术,2024,47(13):100-109.
[9]张林鍹,巴音塔娜,曾庆松.基于StyleGAN2-ADA和改进YOLOv7的葡萄叶片早期病害检测方法[J].农业机械学报,2024,55(1):241-252
[10]马超伟,张浩,马新明,等.基于改进YOLOv8的轻量化小麦病害检测方法[J].农业工程学报,2024,40(5):187-195.
[11]乔钰彬,范菁,张宜,等.基于改进YOLOv5的绝缘子掉串缺陷识别研究[J].计算机仿真,2023,40(7):132-137.
[12]徐杨,熊举举,李论,等.采用改进的YOLOv5s检测花椒簇[J].农业工程学报,2023,39(16):283-290.
[13]ZHANGYF,RENWQ,ZHANGZ,etal.FocalandefficientIOUlossforaccurateboundingboxregression[J].Neurocomputing,2022,506:146-157.
[14]刘春霞,李超,潘理虎,等.改进YOLOv5s的煤矿烟火检测算法[J].计算机工程与应用,2023,59(17):286-294.
[15]刘鑫,马本学,李玉洁,等.基于改进YOLOv7-ByteTrack的干制哈密大枣缺陷检测与计数系统[J].农业工程学报,2024,40(3):303-312.
作者简介:
郑 昊(1999-),男(汉族),蚌埠,硕士生。研究领域:农业信息化。
魏霖静(1977-),女(汉族),兰州,教授,博士。研究领域:智能计算,农业信息化,生物信息学。
基金项目:2021年度兰州市人才创新创业项目(2021-RC-47);2022年度科技部国家外专项目(G2022042005L);2023年甘肃省高等学校产业支撑项目(2023CYZC-54);2023年甘肃省重点研发计划(23YFWA0013);2023年甘肃农业大学美育和劳动教育教学改革项目(2023-09)
