海洋石油水下采油树视情维修决策智能优化方法
2025-02-13张妍平蔡宝平李清平袁晓兵林守强贾向锋隋中斐刘华祥吴小路邹哲先





摘要:传统的水下采油树视情维修决策方法通过设置固定的阈值制定维修策略,难以灵活应对水下采油树工作条件的变化。针对固定阈值的局限性提出基于强化学习的多组件系统视情维修决策智能优化方法,利用Gamma过程对系统组件的退化性能进行建模,采用深度Q学习算法建立基于神经网络的维修决策模型,以组件退化状态组合作为神经网络输入层,各组件维修决策组合作为输出层,并分别设置以生产收益和停产总损失为奖励的两种策略对决策模型进行训练;以水下采油树为研究案例,验证基于强化学习的多组件系统视情维修决策智能优化方法的可行性。结果表明,以停产总损失为奖励的优化方法更适合于水下采油树的维修决策智能优化。
关键词:视情维修; 强化学习; 多组件系统; 水下采油树系统
中图分类号:TE 937""" 文献标志码:A
引用格式:张妍平,蔡宝平,李清平,等.海洋石油水下采油树视情维修决策智能优化方法[J].中国石油大学学报(自然科学版),2025,49(1):169-177.
ZHANG Yanping, CAI Baoping, LI Qingping, et al. Intelligent condition-based maintenance optimization method for" offshore subsea X-tree system[J]. Journal of China University of Petroleum (Edition of Natural Science),2025,49(1):169-177.
Intelligent condition-based maintenance optimization method
for" offshore subsea X-tree system
ZHANG Yanping1, CAI Baoping1, LI Qingping2, YUAN Xiaobing3, LIN Shouqiang4, JIA Xiangfeng5, SUI Zhongfei6, LIU Huaxiang7, WU Xiaolu7, ZOU Zhexian7
(1.College of Mechanical and Electronic Engineering in China University of Petroleum (East China), Qingdao 266580, China;
2.CNOOC Research Institute Company Limited, Beijing 100028, China;
3.Shenzhen Technology Institute of Urban Public Safety, Shenzhen 518024, China;
4.COOEC Subsea Technology Company Limited, Shenzhen 721015, China;
5.Baoji Oilfield Machinery Company, Baoji 721002, China;
6.WEFIC Ocean Equipment Manufacturing Company Limited, Dongying 257082, China;
7.Shenzhen Branch of CNOOC (China) Company Limited, Shenzhen 518052, China)
Abstract: For traditional condition-based maintenance (CBM) methods of the subsea X-tree, the maintenance strategy is decided through setting a fixed threshold value. The fixed threshold value is difficult to flexibly cope with the working condition changings for the subsea X-tree. To solve the limitation of the maintenance threshold, an intelligent CBM optimization method based on the reinforcement learning was proposed for the multi-component system. The Gamma process was used for simulating the degradation performance of components, and the deep Q learning algorithm was used to establish the maintenance decision model based on the neural network. Component degradation states were used as the neural network input layer, and the component maintenance decision was used as the output layer. The decision model was trained by setting up two reward strategies with the reward of production income and the reward of total shutdown loss. The subsea X-tree was used to demonstrate and validate the application of the reinforcement learning based on the intelligent maintenance optimization method. The results show that the optimization method with the total shutdown loss as the reward is more suitable for the intelligent optimization of maintenance decision of the subsea X-tree.
Keywords: condition-based maintenance; reinforcement learning; multi-component system; subsea X-tree system
收稿日期:2023-12-21
基金项目:国家自然科学基金面上项目(52171287);国家杰出青年科学基金项目(52325107)
第一作者:张妍平(1996-),女,博士研究生,研究方向为水下生产系统智能运维。E-mail:zhangyanping@s.upc.edu.cn。
通信作者:蔡宝平(1982-),男,教授,博士,博士生导师,研究方向为海洋油气装备技术。E-mail:caibaoping@upc.edu.cn。
文章编号:1673-5005(2025)01-0169-09""" doi:10.3969/j.issn.1673-5005.2025.01.018
工程系统一般为多组件系统,组件之间可能存在多种依赖关系。组件之间的依赖关系可以分为经济依赖、结构依赖、随机依赖和资源依赖[1-3]。组件之间的配置关系和依赖关系对维修活动的影响至关重要。维修的前提是了解设备的退化状态[4-5]。设备的退化过程是诸多随机性事件共同作用的结果,因此可以利用随机过程对具有时间随机性的退化过程进行建模[6]。得到随机过程的参数估计值后计算与时间相关的可靠度函数,进而推导设备退化与失效过程的随机过程模型[7-11]。按照退化与失效过程的机制不同,所建立的随机过程模型可分为基于Wiener过程的退化模型、基于Gamma过程的退化模型、基于逆高斯过程的退化模型和基于泊松过程的累积损伤模型。视情维修是一种主动维护策略,需要根据系统中组件当前的状态制定相应的维修策略[12]。传统的视情维修方法多通过设置维修阈值的方法进行维修决策[13]。通过对维修阈值进行优化,可以得到维修费用最少,或者利润最高的维修阈值[14]。但是设置维修阈值的方式进行是否维修的判断可能并不是最优的,固定的阈值无法灵活应对系统工作条件的变化[15]。许多学者在马尔可夫决策过程和半马尔可夫决策过程框架下解决优化问题,突破了维修阈值的限制,但是马尔可夫决策过程面临着“维度的诅咒”,只能处理小规模的系统。随着机器学习技术的发展,基于强化学习的决策模型和系统不断地进行交互、训练和更新,使最终的决策模型收敛,实现多维度的维修决策优化问题[16]。强化学习方法能够较好地解决策略优化问题,智能体以不断“试错”的方式进行各状态下最优动作策略寻优,为视情维修决策优化提供了新的框架[17-18]。水下采油树是水下生产系统的重要组成部分。在海底低温、高压和腐蚀环境中,水下采油树承受着内部的油压、冲蚀以及涡流和内波流造成的振动,甚至弯曲变形,易引起水下采油树的故障[19-20]。作为水下生产系统的关键设备,开展水下采油树维修决策方法研究,对降低因故障造成的经济损失、减少环境破坏,保障水下生产系统安全运行,有重要意义。笔者提出基于强化学习的复杂装备视情维修决策智能优化方法,采用深度强化学习算法构建基于神经网络的维修决策模型,以组件退化状态组合作为神经网络输入层,各组件维修决策动作组合作为神经网络输出层。
1" 维修优化模型
建立基于深度Q学习的维修决策智能优化模型,设置了以生产收益和以停产总损失为奖励的两种奖励策略,通过迭代更新基于神经网络的维修决策模型,优化得到单位时间生产利润最大的维修策略。
1.1" 退化过程建模
Gamma过程是单调递增过程,多用于描述具有微小连续损伤累积的退化过程,例如磨损、疲劳、腐蚀等影响的物理退化现象,在退化建模中应用比较广泛。假设机械系统的组件退化服从Gamma过程,Gamma过程是一种退化量连续增加的退化过程,其增量独立且服从Gamma分布。
若随机变量X遵循Gamma分布,则其概率密度函数为
fX(x;α,β)=1Γ(α)1βαxα-1exp-xβI(0,∞)(x).(1)
式中,αgt;0,为形状参数;βgt;0,为尺度参数;Γ(x)为Gamma函数;I(0,∞)(x)为示性函数。
Gamma函数可以表示为
Γ(x)=∫∞0tx-1e-tdt.(2)
示性函数表示为
I(0,∞)(x)=1,x∈(0,∞);0,x(0,∞).(3)
为了方便研究,将组件的退化状态离散化。组件的故障阈值设为L,当组件的退化量属于区间[0, X1],[X1, X2],…,[XN-1, L],[L, ∞]时,组件的退化状态分别为1, 2,…, N和N+1,其中状态1到状态N为正常状态,状态N+1为故障状态。组件在没有被维修的情况下,退化状态只增不减。当组件的故障阈值固定时,组件的离散状态数目越多,越能反映出组件真实的退化状态。
1.2" 维修决策建模
强化学习是一种可以自主决策的智能算法,通过设置智能体和环境进行交互,智能体可以观察环境并根据观测进行动作,在动作之后得到奖励,同时进入下一个状态,智能体通过与环境的交互学习如何最大化奖励。强化学习框架中包括两个关键元素:奖励和策略。强化学习的目标是要最大化长时间的总奖励,策略是指决策者会根据不同的观测决定采用不同的动作,观测到动作的关系。
在时刻t依次发生以下事情:智能体通过观察状态St∈S的环境,得到观测Ot∈O,其中S为状态空间,表示状态取值的集合;O为观测空间,表示观测取值的集合。智能体根据观测决定做出动作At∈A,A为动作集合。环境根据智能体的动作,给予智能体奖励R
t+1∈R,并进入下一步的状态St+1,R为奖励空间,表示奖励取值的集合。以上过程可以表示为
S0,O0,A0,R1,S1,O1,A1,R2,…,ST=send.(4)
如果智能体可以完全观察到环境的状态,则环境是完全可观测的,完全可观测任务的轨道可简化为
S0,A0,R1,S1,A1,R2,…,ST=send.(5)
对于回合制任务,假设某一回合在第T步达到终止状态,则从步骤t(tlt;T)以后的回报Gt可以定义为未来奖励之和:
Gt=Rt+1+Rt+2+…+RT.(6)
为了处理未来奖励不确定性的影响,引入了折扣因子。通过引入折扣因子,模型更注重当前时刻的奖励,减少对不确定未来的过度依赖,从而使学习更加稳定。回报可以表示为
Gt=Rt+1+γRt+2+γ2Rt+3+…+
γT-1RT.(7)
其中折扣因子γ ∈[0, 1]。
基于回报的定义,可以进一步定义价值函数。对于给定的策略π,定义状态价值函数和动作价值函数,状态价值函数vπ(s)表示从状态s开始采用策略π的预期回报,表示为
vπ(s)=Eπ[GtSt=s].(8)
动作价值函数qπ(s, a)表示在状态s采取动作a后,采用策略π的预期回报,表示为
qπ(s,a)=Eπ[GtSt=s,At=a].(9)
从给定策略π的情况下动作价值的定义出发,可得到
qπ(s,a)=Eπ[Gt|St=s,At=a]=
Eπ[Rt+1+γGt+1|St=s,At=a].(10)
依据增量更新来学习动作价值函数,动作价值函数最终可以收敛,动作价值函数更新可以表示为
q(St,At)←q(St,At)+α[Gt-q(St,At)].(11)
式中,Gt为无偏回报样本。
无偏回报样本求取复杂,因此采用有偏回报样本Ut估计回报样本的值,表示为
Ut=Rt+1+γmaxa∈A(St+1)q(St+1,a),(12)
q(St,At)=q(St,At)+α[Ut-q(St,At)].(13)
智能体与环境不断交互,并迭代更新状态价值函数。当处于训练过程时,为了探索更多的动作可能带来的奖励,采用ε贪心策略,表示为
π(as)=1-ε+εA, a=argmaxa′q(s,a′);
εA,a≠argmaxa′q(s,a′).(14)
ε贪心策略把其中ε概率平均分配在各动作上,将剩下的(1-ε)概率分配给目前的最优动作上,即动作价值最大值对应的动作。通过上述算法进行策略评估和策略改进的强化学习算法称为Q学习算法。当系统中的状态太多时,Q学习算法无法对所有状态逐一进行更新,需要用函数近似方法来近似整个状态价值函数,并在每次学习时更新整个函数。利用人工神经网络作为动作价值函数的近似函数,构建深度Q网络
(DQN)。
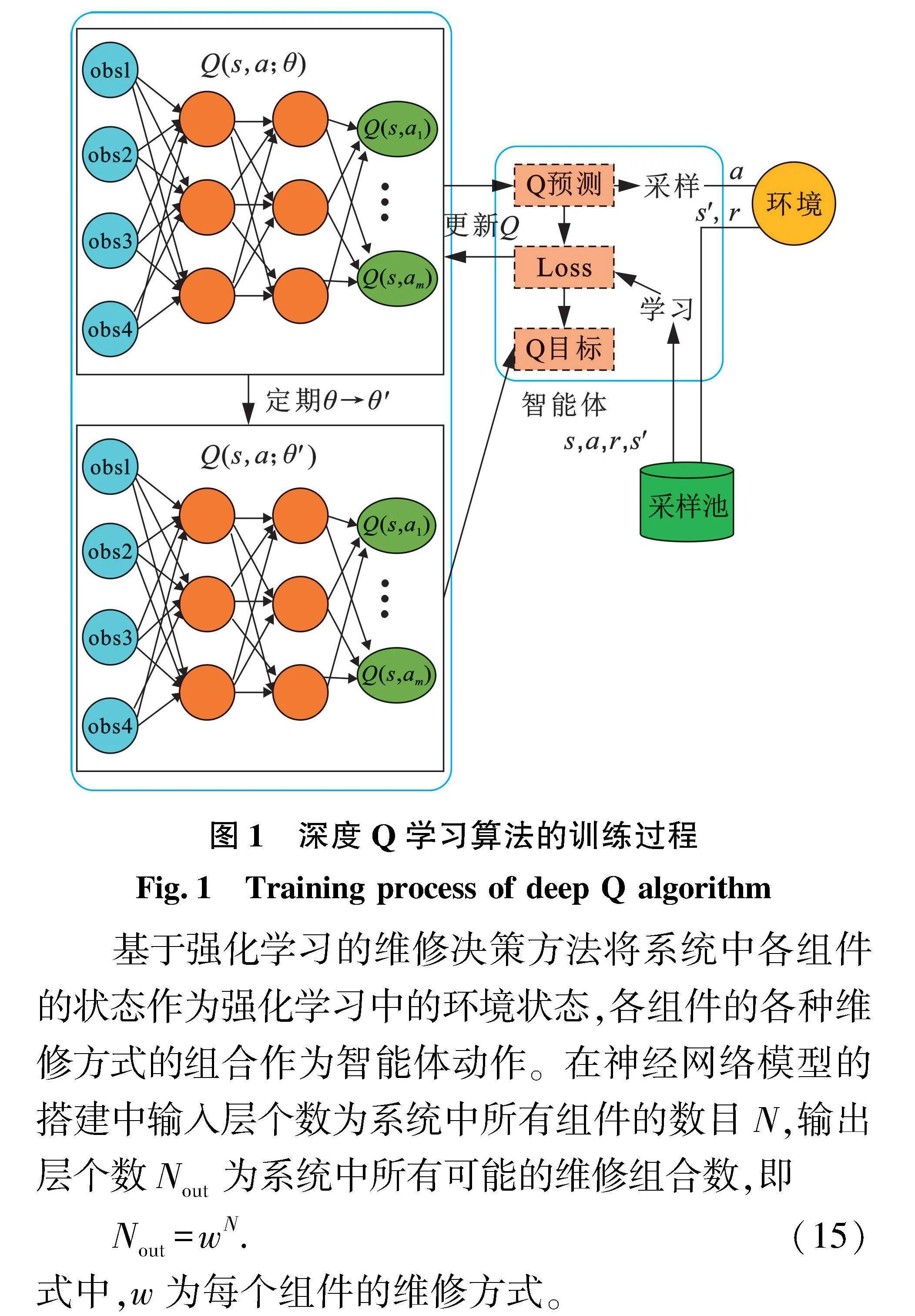
DQN的核心是用人工神经网络来代替动作价值函数Q(s,a; θ),θ为神经网络训练参数,如图1所示。为解决训练不稳定等问题,采用经验回放和目标网络方法。经验回放可以消除数据的关联,使得数据更像是独立同分布的,可以减少参数更新的方差,加快收敛,可以重复使用经验,尤其是对于数据获取困难的情况。目标网络是在原有的神经网络之外再搭建一份结构完全相同的网络,原有的神经网络称为评估网络。在学习过程中,使用目标网络进行自益得到回报的评估值,作为学习的目标。在更新过程中只更新评估网络Q(s, a; θ)的权重θ,目标网络Q*(s, a; θ′)的权重θ′保持不变。在更新一定次数后,再将更新过的评估网络的权重复制给目标网络,进行下一批更新,这样目标网络也能得到更新。由于在目标网络没有变化的一段时间内回报的目标值是相对固定的,目标网络的引入可以增加学习的稳定性。
基于强化学习的维修决策方法将系统中各组件的状态作为强化学习中的环境状态,各组件的各种维修方式的组合作为智能体动作。在神经网络模型的搭建中输入层个数为系统中所有组件的数目N,输出层个数Nout为系统中所有可能的维修组合数,即
Nout=wN.(15)
式中,w为每个组件的维修方式。
每经过采样间隔时间,决策模型会得到系统输出的所有组件当前时刻离散化的退化状态,输入最新的目标网络,得到当前退化状态下各种动作的动作状态值。系统得到智能体给出的动作,即各组件的维修方式后,对系统中各组件采取相应的维修方式,同时计算相应的维修费用。由于在维修之后系统不会再立即进行维修,因此系统会将维修动作之后经过采样间隔时间退化后的状态作为下一状态输出给决策模型。系统的奖励分别设置为基于生产收益和基于停产总损失两种。
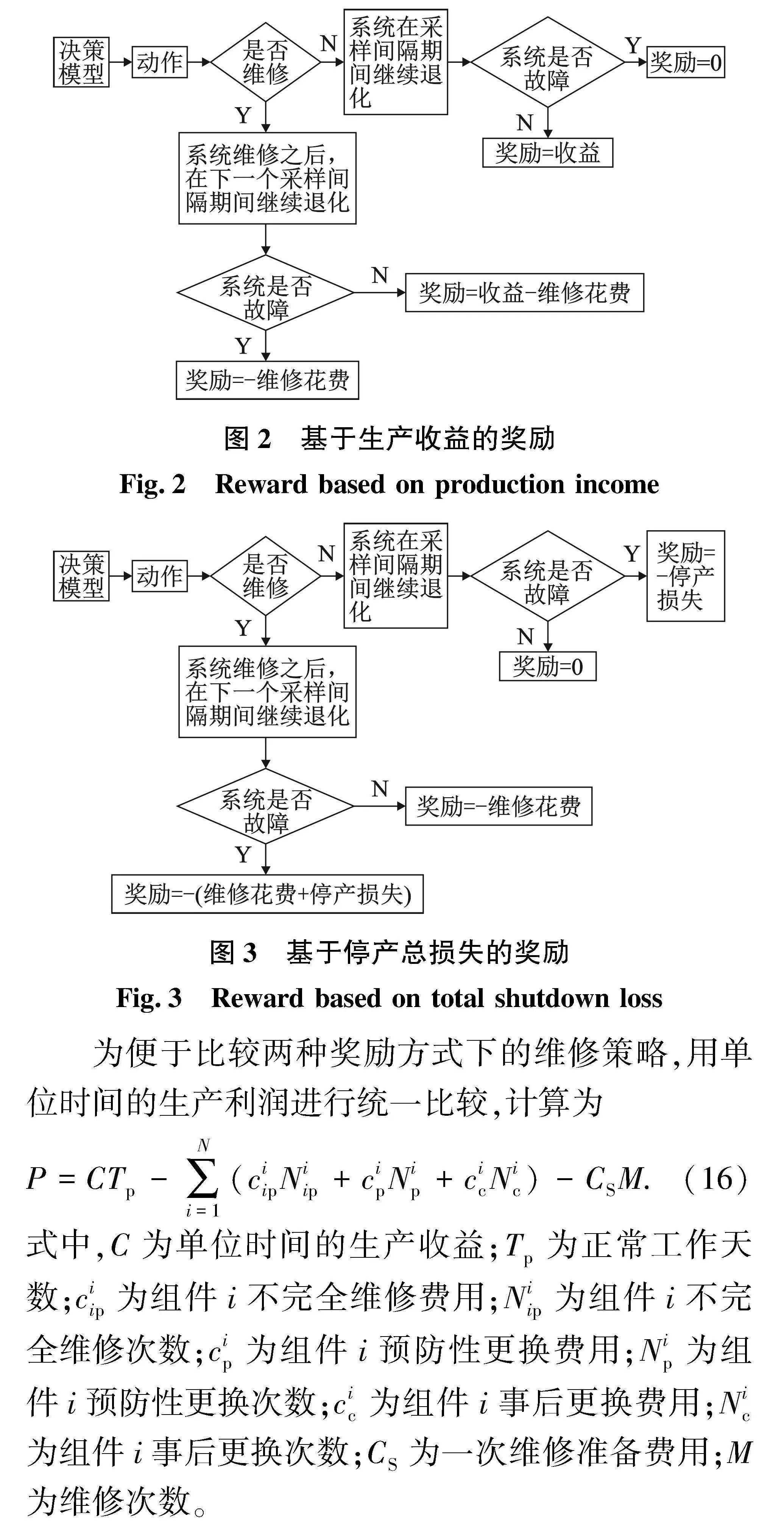
(1)基于生产收益的奖励。当决策模型输出的动作为不维修时,若系统在采样间隔时间正常工作,没有发生故障,系统返回的奖励为采样间隔时间的生产收益;如果系统在采样间隔时间发生故障,奖励为0。当决策模型输出的动作为维修时,如果在维修之后的采样间隔时间系统保持正常工作状态,返回的奖励为生产收益与维修费用的差值;如果在维修之后的采样间隔时间系统发生故障,返回的奖励为维修费用(负值),如图2所示。
(2)基于停产总损失的奖励。当决策模型输出的动作为不维修时,若系统在采样间隔时间正常工作,没有发生故障,系统返回的奖励为0;如果系统在采样间隔时间发生故障,奖励为停产损失(负值)。当决策模型输出的动作为维修时,如果在维修之后的采样间隔时间系统保持正常工作状态,返回的奖励为维修费用(负值);如果在维修之后的采样间隔时间系统发生故障,返回的奖励为维修费用与停产损失之和(负值),如图3所示。
为便于比较两种奖励方式下的维修策略,用单位时间的生产利润进行统一比较,计算为
P=CTp-∑Ni=1(
ciipNiip+cipNip+cicNic)-CSM.(16)
式中,C为单位时间的生产收益;Tp为正常工作天数;ciip为组件i不完全维修费用;Niip为组件i不完全维修次数;cip为组件i预防性更换费用;Nip为组件i预防性更换次数;cic为组件i事后更换费用;Nic为组件i事后更换次数;CS为一次维修准备费用;M为维修次数。
2" 水下采油树维修决策优化方法
2.1" 水下采油树组件退化模型建立
水下采油树是一组安装在水下井口系统上的阀组,连接油气井与依托设施[21]。水下采油树的结构简图如图4所示。将采油树简化为生产回路、环空回路、化学药剂注入回路。取水下采油树的5个阀件即生产主阀(PMV)、生产翼阀(PWV)、环空主阀(AMV)、环空翼阀(AWV)和转换阀(XOV)作为研究对象,分别标记为组件1~组件5,组件之间为串联关系,即任意组件故障都会造成采油树故障,导致停产。
组件的退化过程建模遵循Gamma过程,各个组件的退化参数如表1所示。依据Gamma过程,组件退化量从0开始,阀件的故障阈值设为100,每个状态的退化量跨度设为10,即将退化状态分为11个离散状态,其中状态1~状态10为正常工作状态,状态11为故障状态。
2.2" 水下采油树维修模型建立
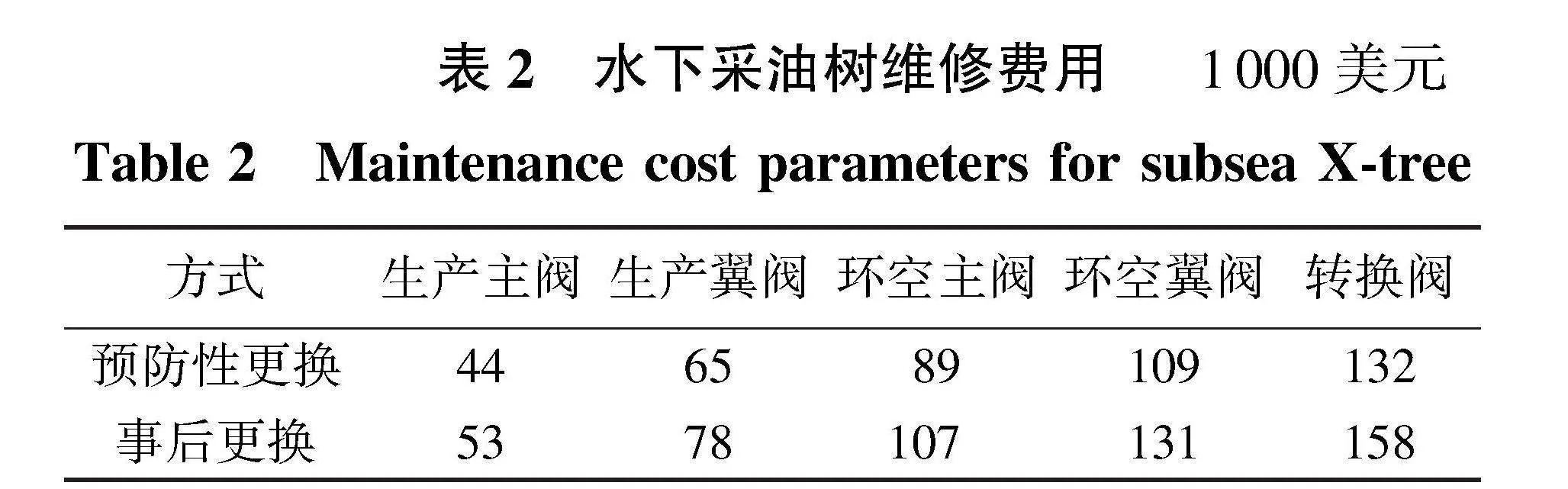
设置仿真单位时间为10 d,维修准备时间设为4×10 d,单位时间的生产收益设为200×1000美元,维修准备费用为1000×1000美元,仿真时间设置为1000×10 d,采样间隔时间设置为10 d,折扣因子设置为0.9。依据水下生产系统实际工程中维修案例与维修参数,组件的预防性更换和事后更换费用如表2所示。
2.2.1" 基于阈值的维修策略
维修策略一。设置维修准备阈值Ts和更换阈值
Tr。当采油树中某个组件的退化状态大于维修准备阈值Ts时,开始进行维修准备工作;维修准备期间,采油树保持工作状态,组件继续退化。维修准备工作完成之后,对采油树中的组件进行维修,当组件的退化状态大于更换阈值Tr时,对组件进行更换,组件的退化状态更新为初始状态,否则组件的退化状态保持不变。维修策略一需要优化的阈值为Ts和Tr。
维修策略二。由于组件之间具有差异性,处于相同状态下组件的剩余使用寿命不同,因此对所有组件设置相同的更换阈值不够合理,对维修策略一进行改进如下:对5个组件分别设置更换阈值Tr1、Tr2、Tr3、Tr4、Tr5,当维修准备工作完成之后,各组件根据自己的更换阈值判断是否进行更换。
2.2.2" 基于深度Q学习的维修策略
建立神经网络模型,采油树包括5个组件,将神经网络的输入层设置为5,经过4层隐藏层,前两个隐藏层神经元数目为64,后两个隐藏层神经元数目为128,由于每个组件都有两种维修方式,共有32种维修组合,将神经网络的输出层设置为32,其中第一个节点表示不进行维修,最后一个节点表示全部进行更换。
维修策略三为基于生产收益为奖励的深度Q学习维修策略,维修策略四为基于停产总损失为奖励的深度Q学习维修策略。
2.3" 维修结果
用4种维修策略对水下采油树进行维修,利用优化算法对维修策略一和维修策略二的决策变量进行优化;利用深度Q学习算法对维修策略三和维修策略四进行训练优化,训练次数为1000。维修策略一中所有组件的维修阈值为状态5,单位时间的生产利润为181.28×1000美元。维修策略二的5个组件的最优维修阈值分别为状态4、状态5、状态5、状态6和状态7,单位时间的生产利润为181.61×1000美元,采油树中退化速度较慢组件的最优维修阈值高于退化速度快的组件。维修策略三优化得到的单位时间生产利润为171.40×1000美元,比维修策略一和维修策略二的低。维修策略四优化得到的单位时间生产利润为184.25×1000美元,较维修策略三的生产利润提高约7.5%。可以看出,基于停产总损失的维修优化策略可以有效地提高水下采油树的最大生产利润。
2.3.1" 不同维修策略下组件性能变化趋势
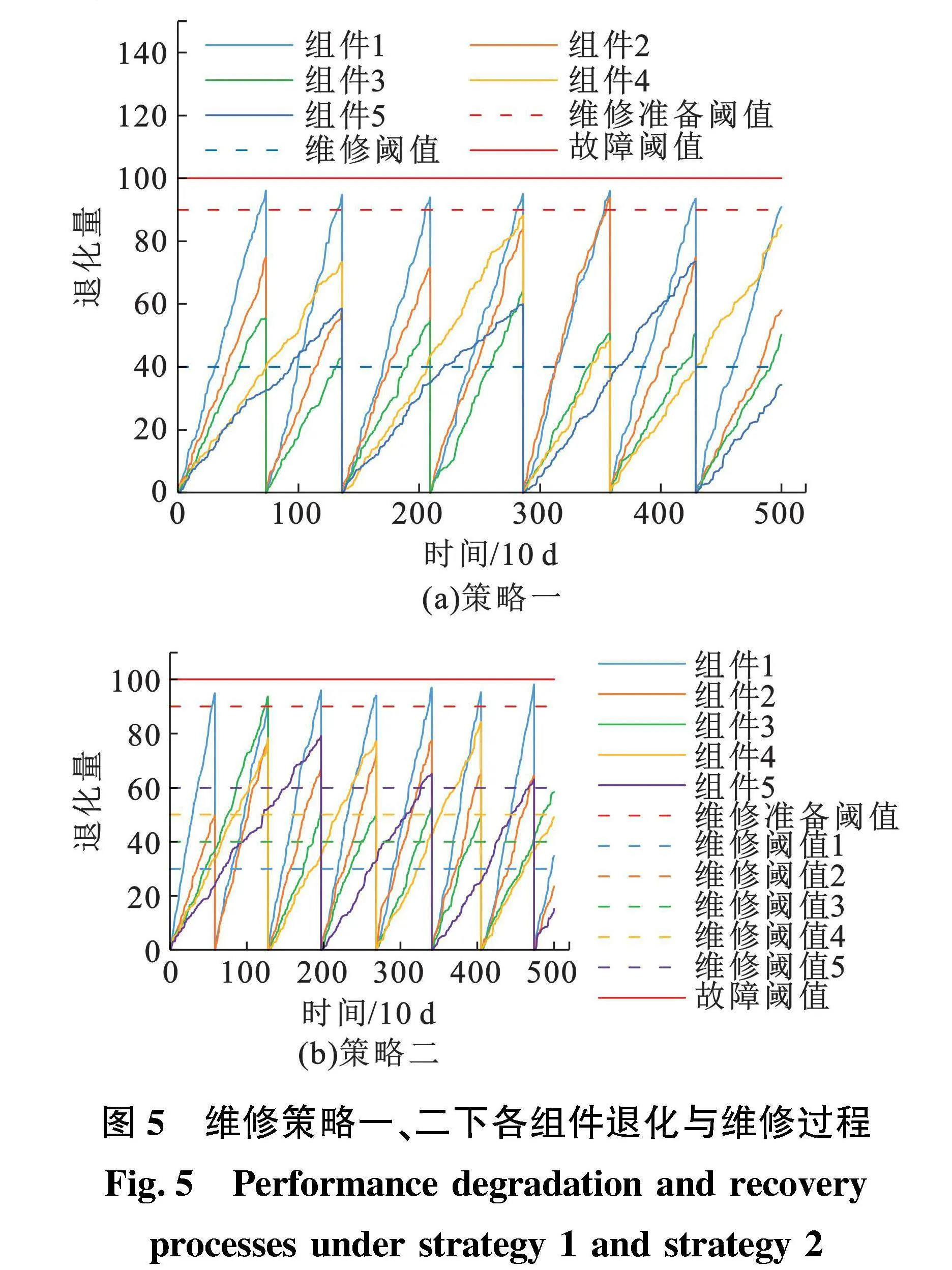
维修策略一、二下各组件性能变化趋势如图5所示。当所有组件中有组件的退化量超过维修准备阈值时,开始准备维修,在维修准备期间所有组件保持工作状态,并继续退化。由图5(a)可知,每次都是PMV的退化量高于维修准备阈值,然后退化量继续上升。维修准备工作结束之后,退化量超过维修阈值的组件被更换,退化量变为0。PMV、PWV和AMV在每次维修时都会被更换,AWV和XOV一般每两次维修后更换一次。
由图5(b)可知,由于维修策略二中的AWV和XOV的维修阈值高于维修策略一中的维修阈值。与维修策略一相比,XOV的维修频率发生变化。由于XOV的退化速度最慢,且维修阈值较高,直到第三次维修活动时才被维修。维修策略二中XOV的使用效率要明显高于维修策略一,因此在维修策略二中,其生产利润要略高于维修策略一。
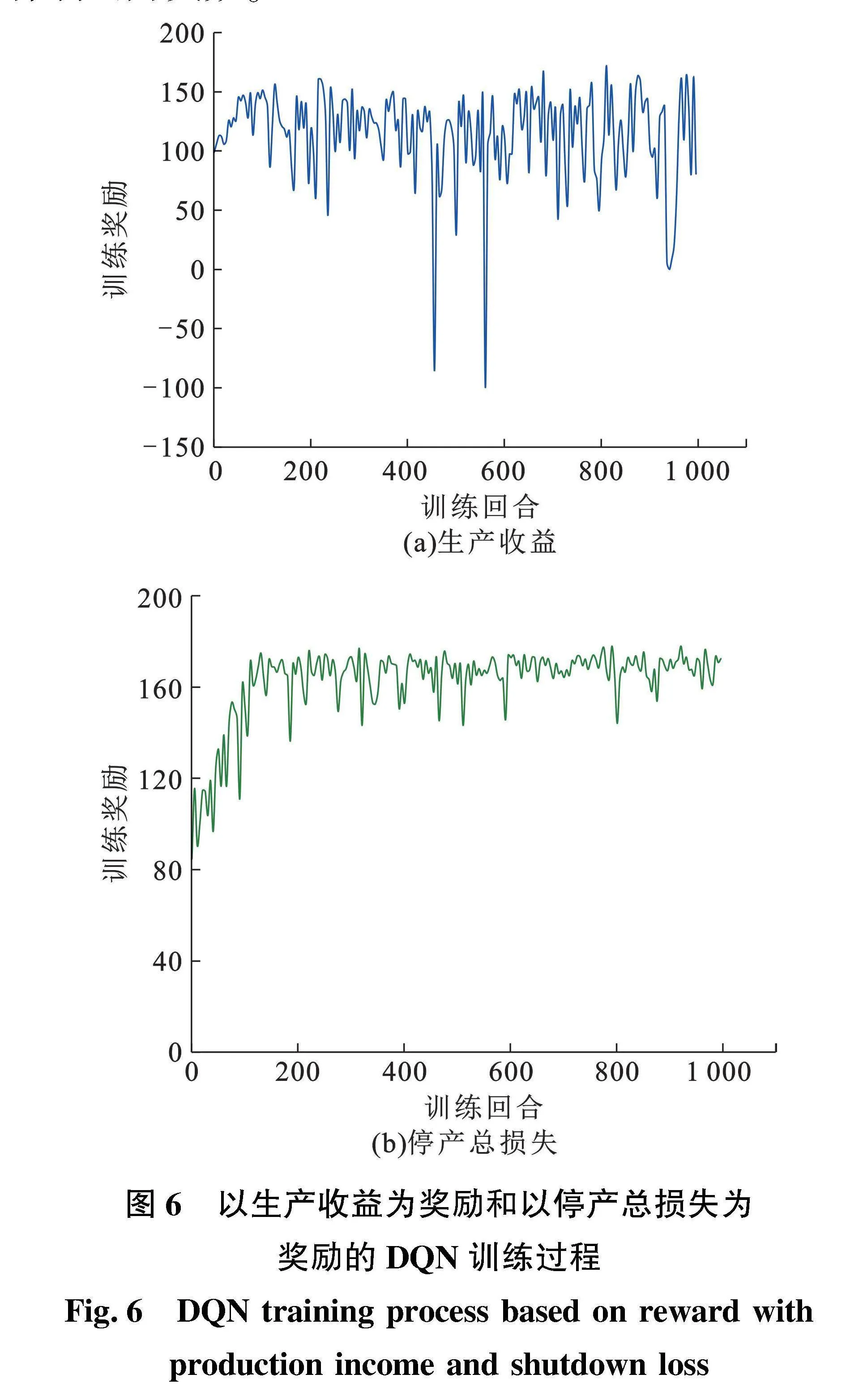
基于生产收益和以停产总损失为奖励的DQN维修策略的训练过程如图6所示。由图6(a)可知,在训练过程中,训练奖励波动比较大,有时甚至会出现奖励为负数的情况,这是因为在训练过程中有一定的概率会随机选取策略,而在32种动作中只有一种动作是不维修,维修动作被选中的概率更大,因此会出现更多维修的情况,造成维修次数过多,使得整体利润为负数。
训练次数为1000(图6(b)),以停产总损失为奖励的深度Q学习的训练过程相较于以生产收益为奖励的训练过程波动幅度更小,训练过程更加稳定,利润出现负值的概率更低,训练效率要优于以生产收益为奖励的强化学习。
在实际工程应用中水下采油树一般会采取定期检修的方法。虽然定期维修频次与基于停产总损失的智能维修方法得到的维修频次相差不大,但实际过程中一般采取的是完全维修方法,即更换组件,这会大大提升维修费用。水下组件的干预日费用高达20万美元。同时,在设备检修过程中需要停机,也会产生相应的停机损失和停产损失。基于停产总损失的智能维修优化方法可以优化全使用寿命周期内的维修频次,从而降低维修费用。
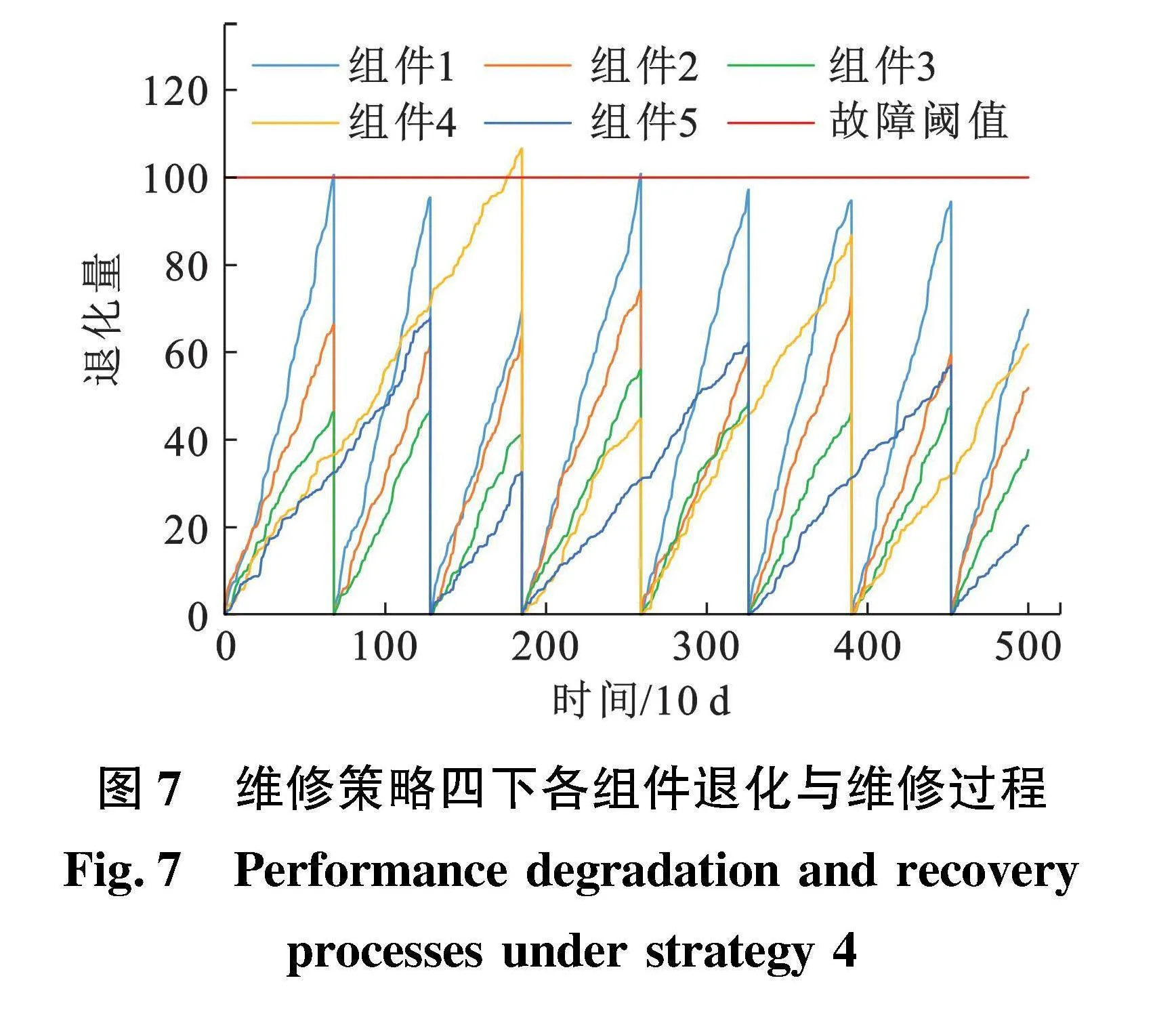
维修策略四下各组件的退化与维修过程如图7所示。由图7可知,由于没有阈值限制,维修策略四下组件出现故障的概率高于维修策略一和维修策略二。PMV、PWV和AMV的退化速度最快,每次维修都会被更换。XOV在第二次维修时,退化状态较好,但是被更换,显然这是一次较差的维修选择。这说明基于深度Q学习的维修策略在某些状态组合进行维修决策时可能并不是最优的。
例如,在基于停产总损失的深度Q学习训练过程中,状态[1,1,1,1,1]、状态[8,8,7,7,7]和状态[10,10,10,9,9]的最大动作状态值(Q(s,a))的变化情况如图8所示。由图8可知,在训练过程中3种状态的动作状态值逐渐下降,然后趋于收敛。状态[1,1,1,1,1]的收敛程度更好,这是因为该状态组合下的最优动作比较容易确定,即不维修,在训练过程中不容易改变。状态[8,8,7,7,7]和状态[10,10,10,9,9]的最优动作难以确定,在训练过程中反复选择,因此动作状态值波动比较大,会造成维修决策结果并不是最优。
2.3.2" 不同状态离散情况下维修结果
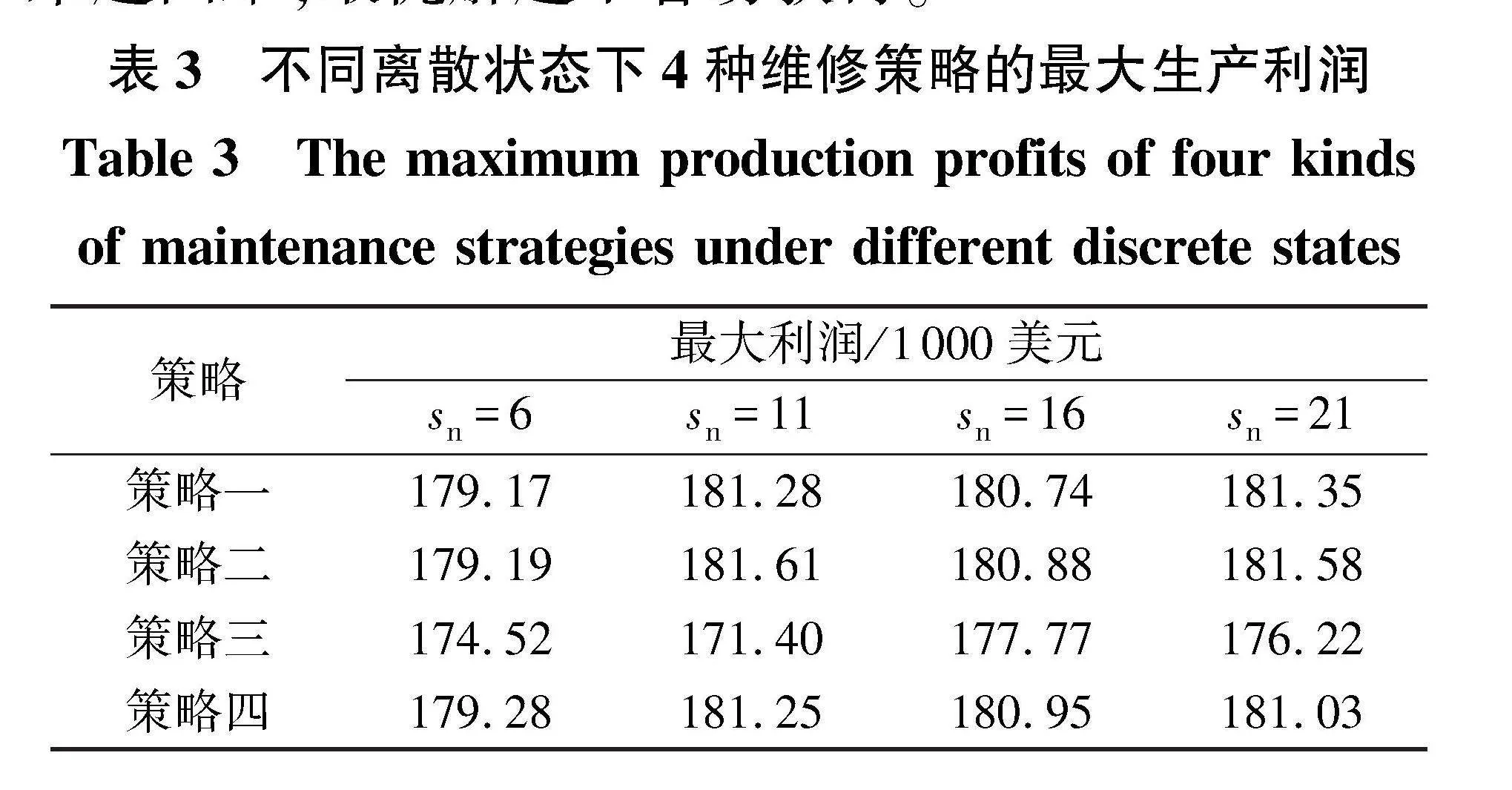
在退化阈值不变的情况下,当划分的离散状态数目增加时,每一个状态的跨度缩短,可使得决策更加灵活,表3为不同离散状态数(sn)时4种维修策略的最优利润。由表3可知,随着离散状态总数增加,维修策略一和维修策略二的最优利润在离散状态总数为16时均小于离散状态总数为11时,说明离散状态数目多时的单位时间最大生产利润不一定高于离散状态少时的单位时间最大生产利润,因为离散状态虽然多,但是状态区间的划分不一定合理。维修策略四在离散状态总数为11时单位时间最大生产利润大于离散状态总数为21时单位时间最大生产利润,是因为离散数目越多解空间越大,求解起来越困难,最优解越不容易获得。
2.3.3" 维修准备费用对单位时间生产利润影响
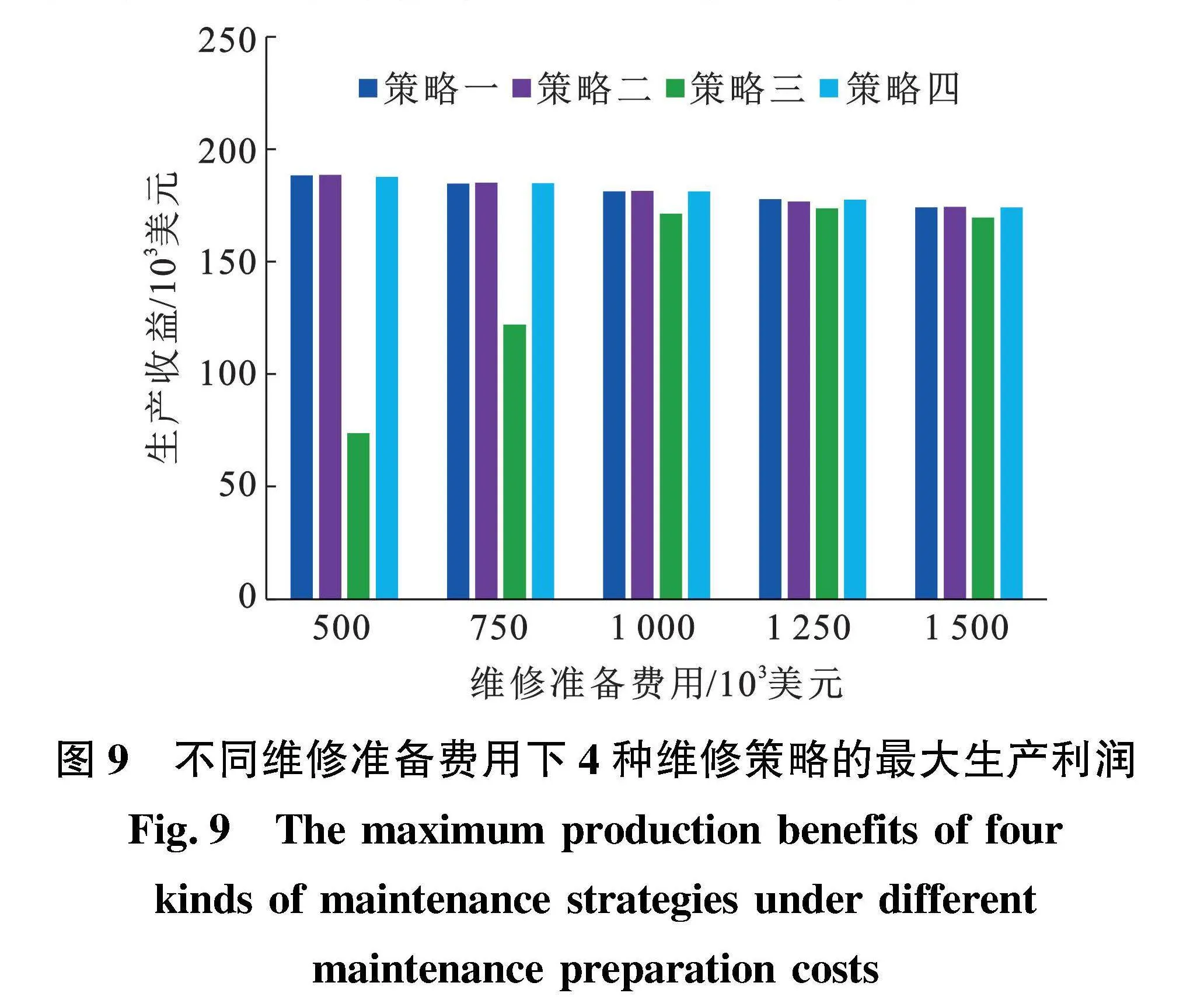
随着维修准备费用增加,4种维修策略的单位时间最大生产利润变化如图9所示。从图9中可以看出:维修策略一、维修策略二和维修策略四在维修准备费用增加时最优利润均下降;维修策略三在维修准备费用为500×1000和750×1000美元时,最优利润明显差于维修策略一和维修策略二。
在维修准备期间,采油树正常工作并产生收益,维修准备结束之后进行维修,输出的奖励为维修准备期间产生的收益与维修费用之差,当维修准备费用较低时,输出的奖励高于不维修且采油树正常工作时输出的单位时间的收益,因此模型会认为维修产生的奖励更多,更偏向于输出维修动作,显然维修次数增加必然导致整体收益下降,因此当维修准备费用较低时,维修策略三的利润非常低,而以费用为奖励的维修策略四的生产收益没有因为维修准备费用下降而受到影响。
3" 结论及展望
(1)在水下采油树系统的维修案例中,以停产总损失为奖励的基于深度Q学习的维修策略的训练过程相较于以生产收益为奖励的训练过程波动幅度更小,训练过程更加稳定,收益出现负值的概率更低,训练效率更高;同时以停产总损失为奖励的维修策略优化得到的单位时间生产利润较以生产收益为奖励的维修策略中的生产利润提高了约7.5%。
(2)基于深度Q学习的维修决策方法在离散状态数目增加时,单位时间最大生产收益并未一直保持增加,离散状态数目增加一方面使得退化状态更加准确,一方面也增加了寻找最优解的难度,可能使得最终的维修策略差于离散状态较少时得到的维修策略。
(3)对于具有高维状态空间和复杂动作集合的策略优化问题,会导致传统的Q-Learning算法的维度灾难;针对多组件工程系统高维状态空间和动作空间的特点,未来的研究可以考虑将单智能体决策扩展为多智能体决策,将强化学习扩展到高维的状态和动作空间中;在水下采油树视情维修方法应用过程中,要进一步考虑水下环境中可能发生的灾害风险,制定紧急应对计划,提高水下采油树维修的抗灾能力。
参考文献:
[1]" OLDE K, TEUNTER R H, VELDMAN J, et al. Condition-based maintenance for systems with economic dependence and load sharing[J]. International Journal of Production Economics, 2018,195:319-327.
[2]" VERBERT K, DE SCHUTTER B, BABUKA R. Timely condition-based maintenance planning for multi-component systems[J]. Reliability Engineering amp; System Safety, 2017,159:310-321.
[3]" ZHANG N, SI W. Deep reinforcement learning for condition-based maintenance planning of multi-component systems under dependent competing risks[J]. Reliability Engineering amp; System Safety, 2020,203:107094.
[4]" 袁晓兵,陈国明,王远东,等.基于关键水平的水下采油树预防性维修决策方法[J].中国海洋平台,2020,35(3):43-48,56.
YUAN Xiaobing, CHEN Guoming, WANG Yuandong, et al. Preventive maintenance decision making method for subsea tree based on critical level[J]. China Offshore Platform, 2020,35(3):43-48,56.
[5]" CAI B, FAN H, SHAO X, et al. Remaining useful life re-prediction methodology based on Wiener process: subsea Christmas tree system as a case study[J]. Computers amp; Industrial Engineering, 2021,151:106983.
[6]" 李京峰,陈云翔,项华春,等.考虑随机冲击影响的多部件系统视情维修与备件库存联合优化[J].系统工程与电子技术,2022,44(3):875-883.
LI Jingfeng, CHEN Yunxiang, XIANG Huachun, et al. Joint optimization of condition maintenance method and spare parts inventory for the multi-component system considering random impact[J]. Systems Engineering and Electronics, 2022,44(3):875-883.
[7]" 林程,魏汝祥,蒋铁军.基于性能退化模型的船舶部件维修决策决策优化[J].中国修船,2021,34(2):33-36.
LIN Cheng, WEI Ruxiang, JIANG Tiejun. Decision optimization of ship parts maintenance based on performance degradation model[J]. China Ship Repair, 2021,34(2):33-36.
[8]" DUAN C, LI Z, LIU F. Condition-based maintenance for ship pumps subject to competing risks under stochastic maintenance quality[J]. Ocean Engineering, 2020,218:108180.
[9]" HUYNH K T. Modeling past-dependent partial repairs for condition-based maintenance of continuously deteriorating systems[J]. European Journal of Operational Research, 2020,280(1):152-163.
[10]" WANG Y, LIU Y, CHEN J, et al. Reliability and condition-based maintenance modeling for systems operating under performance-based contracting[J]. Computers amp; Industrial Engineering, 2020,142:106344.
[11]" ZHAO X, HE S, HE Z, et al. Optimal condition-based maintenance policy with delay for systems subject to competing failures under continuous monitoring[J]. Computers amp; Industrial Engineering, 2018,124:535-544.
[12]" 葛伟凤,孟庭宇,罗衡,等.水下生产系统关键设备维修策略优化方法[J].科学技术与工程,2020,20(4):1400-1408.
GE Weifeng, MENG Tingyu, LUO Heng, et al. Optimization method of key equipment maintenance strategy for subsea production system[J]. Science Technology and Engineering,2020,20(4):1400-1408.
[13]" 裴峻峰,郑庆元,姜海一,等.离心式压缩机定期维修周期及可靠性研究[J].中国石油大学学报(自然科学版),2014,38(6):127-133.
PEI Junfeng, ZHENG Qingyuan, JIANG Haiyi, et al. Research on regular maintenance cycle and reliability for centrifugal compressors[J]. Journal of China University of Petroleum (Edition of Natural Science), 2014,38(6):127-133.
[14]" 贾宝惠,唐庭均,卢翔.航线维修任务人力资源多目标优化模型研究[J].科学技术与工程,2020,20(30):12630-12635.
JIA Baohui, TANG Tingjun, LU Xiang. Research on multi-objective optimization model of human resources for airline maintenance tasks[J].Science Technology and Engineering, 2020,20(30):12630-12635.
[15]" 范霖,苏怀,彭世亮,等.基于供气可靠性的天然气管道系统预防性维护方案智能优化方法[J].中国石油大学学报(自然科学版),2023,47(1):134-140.
FAN Lin, SU Huai, PENG Shiliang, et al. Supply-reliability based method of intellectual optimization on preventive maintenance strategy for natural gas pipeline system[J]. Journal of China University of Petroleum (Edition of Natural Science), 2023,47(1):134-140.
[16]" MAHMOODZADEH Z, WU K, LOPEZ D, et al. Condition-based maintenance with reinforcement learning for dry gas pipeline subject to internal corrosion[J]. Sensors, 2020,20(19):5708.
[17]" ZHOU Y, LI B, LIN T R. Maintenance optimization of multicomponent systems using hierarchical coordinated reinforcement learning[J]. Reliability Engineering amp; System Safety, 2022,217:108078.
[18]" PENG S, FENG Q. Reinforcement learning with Gaussian processes for condition-based maintenance[J]. Computers amp; Industrial Engineering, 2021,158:107321.
[19]" 任冠龙,孟文波,王宇,等.水下采油树生产通道流动安全分析与应用[J].石油机械,2023,51(9):64-70.
REN Guanlong, MENG Wenbo, WANG Yu, et al. Flow safety analysis and application of production fairway of subsea Christmas tree[J]. China Petroleum Machinery, 2023,51(9):64-70.
[20]" 王莹莹,刘书杰,张崇,等.水下采油树过流通道温变规律和计算方法[J].中国石油大学学报(自然科学版),2022,46(3):148-157.
WANG Yingying, LIU Shujie, ZHANG Chong, et al. Law of temperature change and calculation method in subsea Christmas tree internal overflow channel[J]. Journal of China University of Petroleum (Edition of Natural Science), 2022,46(3):148-157.
[21]" 刘超,刘健,肖文生,等.基于FFTA和FMEA的水下采油树系统可靠性分析[J].石油机械,2022,50(4):63-71.
LIU Chao, LIU Jian, XIAO Wensheng, et al. Reliability analysis of subsea Christmas tree system based on FFTA and FMEA[J]. China Petroleum Machinery, 2022,50(4):63-71.
(编辑" 沈玉英)
