大语言模型对批评隐喻分析中隐喻识别的应用性研究
2025-01-26于艳春


提 要:批评隐喻分析(critical metaphor analysis, CMA)作为一种语篇的隐喻分析方法,意在揭示语言使用者的潜在意图,不但可深化我们对语言隐喻的理解,还能揭示隐喻在人类思维和交流中的重要作用。隐喻识别作为CMA分析框架中的一个关键步骤,为隐喻阐释和隐喻说明等后续研究工作提供了坚实基础,是CMA中极其重要且不可或缺的一部分。本研究首先对CMA中隐喻识别的融合性和枢纽性进行深入讨论,探究CMA中隐喻识别的发展特性,熟悉CMA的整个分析框架。同时,针对CMA在隐喻识别中存在的客观性不足问题,提出尝试结合大语言模型(ChatGPT)进行隐喻识别的方法,并基于真实研究案例了解该方法的具体实践操作。通过案例,本研究也对使用大语言模型(ChatGPT)进行隐喻识别过程中遇到的问题进行分析和总结,希望通过合理、恰当地应用技术手段,探索人机协作的最佳方式,以提升隐喻识别的客观性,完善CMA的分析框架,更深入地进行语篇的隐喻研究。
关键词:大语言模型;ChatGPT;批评隐喻分析;隐喻识别;隐喻阐释;隐喻说明
中图分类号:H08 """"文献标识码:A """"文章编号:1000-0100(2025)01-0047-10
DOI编码:10.16263/j.cnki.23-1071/h.2025.01.006
A Study on the Applicability of" Large Language Model(ChatGPT)to
Metaphor Identification in Critical Metaphor Analysis
Yu Yan-chun
(School of" Foreign Languages and Literature, Heilongjiang University," Harbin 150080, China;
School of Foreign Languages, Harbin University, Harbin 150080, China)
Critical Metaphor Analysis (CMA), an approach to metaphor analysis in discourse, aims to reveal the hidden intention of language users, which not only deepens our understanding of linguistic metaphors, but also reveals the important role of metaphor in human thinking and communication. As a key stage in CMA, metaphor identification provides a solid foundation for the subsequent research work such as metaphor interpretation and metaphor explanation, and is an extremely important and indispensable part of CMA. This paper first delves into integration and pivotability of metaphor identification in CMA, to explore the developmental characteristics of metaphor identification in CMA, and to become acquainted with the entire analytical framework of CMA. Then, the lack of objectivity of metaphor identification in CMA is discussed, and a method that attempts to apply Large Language Model (ChatGPT) to metaphor identification in CMA is proposed to address this issue. In the meantime, the specific practical operation of the method is demonstrated based on a real case study. It is found that, in addition to enhancing the objectivity of metaphor identification, ChatGPT mainly plays an enlightening role in the analytical process. At all once, three issues have emerged in the process of metaphor identification applying ChatGPT: First, the results of metaphor identification are not entirely consistent with expectations; Second, the frequency statistics of metaphor keywords are inaccurate; Third, the operation process is repetitive. These issues have prompted us to further ponder. Firstly, LLM (ChatGPT) has not yet possessed fully developed human intelligence, and consequently it may have not been capable of independently completing the identification of complex me-taphor phenomena involving multiple dimensions such as language, culture, and cognition. It needs to be combined with human identification to play an auxiliary and enlightening role. Secondly, the application of technology to empower language research should be determined based on the research objectives and research questions. For frequency statistics tasks, it is possible to consider utilizing relatively mature tools such as Excel or Corpus to showcase their respective strengths. Thirdly, it is necessary to clarify the role that LLM (ChatGPT) plays in metaphor study, so that its potential capabilities can be better harnessed to serve as a copilot in such studies. Thus, it is hoped that, by employing technological means reasonably and appropriately, we can explore the optimal way for human-computer collaboration to enhance the objectivity of metaphor identification, refine the analytical framework of" CMA, and conduct more in-depth study of metaphor in discourse. Meanwhile, it is also hoped that CMA can conti-nue to conduct research across fields such as linguistics, cognitive science, sociology, and computer science, making CMA more satisfactory and providing a more comprehensive analytical perspective and a more objective analytical method for metaphor study in discourse.
Key words: large language models; ChatGPT; critical metaphor analysis; metaphor identification; metaphor interpretation; metaphor explanation
1 引言
批评隐喻分析(critical metaphor analysis, CMA)是由英国学者Charteris-Black(2004:34)2004年提出,不断发展的一种隐喻分析方法(Charteris-Black 2005, 2014, 2018)。CMA(Charteris-Black" 2018)认为隐喻的语篇功能是人们建立意识形态和修辞动机的基础,通常会围绕诸如:为什么这是隐喻,它是什么类型的隐喻,为什么选择这种类型的隐喻等一系列问题,深入探讨隐喻的识别标准、识别单位、类型特点、使用方式和原因、使用目的以及推理效应等相关话题。旨在识别出语篇中的隐喻,并根据使用者的交际目的及语境因素来解释隐喻选择的原因,进而揭示语篇中潜在的意识形态、态度和信念。CMA不仅深化我们对隐喻在语言和思维中作用的理解,也为语篇分析提供了新的视角。隐喻识别作为CMA分析框架中的一个关键步骤,为隐喻阐释和隐喻说明等后续研究工作提供坚实基础,是CMA中极其重要且不可或缺的一部分。不过,由于隐喻的隐蔽性和多义性、动态性和语境依赖性,隐喻识别易受个人经验和价值观的影响,因此,如何科学、客观、有效地识别出语篇中的隐喻是CMA的一个核心问题,也是当前隐喻研究的重点和难点。
从主要依靠直觉法辨别语篇中隐喻的传统隐喻识别研究,到近些年基于神经网络(Do Dinh, Gurevych" 2016)、自然语言学习(朱嘉莹等" 2020)等自然语言处理(natural language processing, NLP)的计算隐喻识别研究,语篇中的隐喻识别或者因识别过程的强主观性而受到质疑,或者因技术的强专业性而难以付诸实践。而Pragglejaz Group(2007:3)提出的MIP隐喻识别程序因操作相对简易,一经提出便成为隐喻识别的首选方法,不过在实践操作中其存在的词汇单元划分与计数标准不一等问题也较为明显。为此,Steen et al.(2010:25-42)提出对MIP进行改良补充的MIPVU. MIPVU除了对隐喻识别的词汇单元进行详细划分说明外,还提出对间接隐喻、直接隐喻和隐性隐喻的识别。这种细化隐喻的识别方法虽然有助于隐喻研究的纵深方向发展,但同时也增加了隐喻识别的难度和复杂度,而且隐喻识别的主观性问题一直存在,因此,真正运用MIPVU的隐喻研究目前国内还较少见。随着自动语义分析工具Wmatrix(Rayson 2008:519-549)的开发,部分学者(如孙亚 2012,陈朗" 2022)开始采用Wmatrix与MIP或MIPVU相结合的方法来识别语篇中的隐喻,减少隐喻识别的主观性。不过,Wmatrix在语境义和基本义的区分上仍需要人工进行判定,而且其预设的始源域范畴可能会导致新奇隐喻的遗漏。CMA作为一种普遍运用的语篇隐喻分析方法,对隐喻识别同样倾注了大量笔墨,形成具有特色的隐喻识别方法。本研究将基于对CMA中隐喻识别方法的讨论,探究CMA中隐喻识别的发展特性以及可能存在的局限性,并针对存在的问题尝试提出解决方法,同时,基于真实研究案例了解该方法的具体实践操作,以完善CMA的分析框架,更深入地进行语篇的隐喻研究。
2 CMA中隐喻识别的融合性和枢纽性
在批评话语分析(critical discourse analysis, CDA)影响下应运而生的CMA,基于概念隐喻理论(Conceptual Metaphor Theory, CMT)(Lakoff, Johnson 1980)的隐喻思维主张,认为隐喻源自人类的创造力,对不同现象之间关系的新奇语言编码、对刺激新的理解方式有启发作用,是思维和行动的新方式(Charteris-Black" 2004:21)。通过对隐喻的批判性分析,CMA将认知与包含历史和文化知识的语言资源整合,增加语篇说服力的同时,揭示语言使用者的潜在意图。可见,融合性是CMA的一个显著特性,它不仅贯穿于CMA的整个研究过程,更是渗透于CMA的隐喻识别阶段。通过运用融合方法识别隐喻,CMA实现在隐喻研究领域的新突破。同时,隐喻识别作为CMA(Charteris-Black" 2018)中连接语境分析与隐喻阐释和隐喻说明的关键环节,将语境提供的必要背景信息整合到隐喻的理解和分析中,彰显出隐喻识别的枢纽性。
2.1 CMA中隐喻识别的融合性
CMA中隐喻识别的融合性主要体现在理论和技术上的融合。首先,作为理解语言、思维和社会之间复杂关系的重要手段,CMA(Charteris-Black 2004:21, 2005:14)认为隐喻具有潜在的语言、语用和认知特征,隐喻识别需要考虑语义、语境和跨域映射,因此,CMA结合语义学、语用学和认知语言学,提出依据某一个单词或短语是否由于使用的语义域发生变化而导致语言、语用、认知三个层面的不协调(incongruity)或语义张力(semantic tension)来判断是否为隐喻的语言、语用、认知三个标准(Charteris-Black" 2004:21-35),体现出CMA中隐喻识别的理论融合。其次,CMA在语料库的推广应用及社会科学的影响下,借助语料库技术,提出运用人工分析语篇样本识别候选隐喻(candidate metaphors)与机读大型语料识别隐喻相结合的两步隐喻识别法(Charteris-Black" 2004:34)。该方法将隐喻识别从传统的直觉法转向结合语料库的社会实证视角,不但打破长久以来仅依靠人工识别隐喻的限制,也补充了隐喻研究的实证证据,是21世纪初隐喻研究的一个创新和突破,体现了CMA中隐喻识别的技术融合。
2.2 CMA中隐喻识别的枢纽性
CMA中隐喻识别的枢纽性凸显了隐喻识别在CMA中的核心地位和连接作用。一方面,隐喻识别不仅是CMA分析过程中的基点,也是驱动整个分析过程的核心动力,隐喻识别的准确性直接影响隐喻阐释和隐喻说明的深度和广度。另一方面,作为CMA(Charteris-Black" 2018)四步分析框架的一个中间环节,隐喻识别能够确保研究的连贯性,使得从语境分析到隐喻阐释再到隐喻说明形成一个有逻辑且相互支撑的分析链条。
具体来说,作为研究起点,语境分析通过在相关社会语境下对某一特定话题的分析,提出有关隐喻的研究问题。隐喻识别则结合语境信息识别出语篇中的隐喻。一旦识别出隐喻,CMA便运用CMT和概念整合理论(Conceptual Blending Theory, CBT)(Fauconnier, Turner 2002),进一步探讨隐喻所传达的隐喻意义、概念表征和评价意义,以及隐喻搭配或隐喻与其他语言形式互动所形成的积极评价或消极评价(Charteris-Black" 2005:22-23)。之后,CMA在社会语境基础上,运用目的隐喻(purposeful metaphor)(Charteris-Black" 2012)和社会认知(van Dijk 2008)概念从说话者和受众两个互补视角对隐喻选择进行解释说明,从而将隐喻的深层含义和意识形态联系起来。CMA(Charteris-Black" 2018)认为隐喻是出于某些现实目的而进行的语言交际,包括修辞目的(rhetorical)、启发性目的(heuristic)、谓词评价目的(predicative)、移情目的(empathetic)、美学目的(aesthetic)、意识形态目的(ideological)和神话目的(mythic)等动态互动的多个目的,它们之间通常由一个主要动机驱动,其他动机辅之。在解释说明某个特定隐喻的隐喻功能时,会受到更广泛社会背景的影响,而这恰好是最初研究问题的动机,因此可能会引发新一轮的隐喻识别,也可能通过积极或消极表征开始新的隐喻阐释循环。由此表明,CMA的语境分析、隐喻识别、隐喻阐释、隐喻说明四步骤之间虽然是依次描述的,但同时也是递归的。
3 CMA中隐喻识别客观性的不足及大语言模型(ChatGPT)的应用
随着实践应用的推广,CMA中隐喻识别的局限性逐渐显露,面临着隐喻识别客观性不足的挑战。而随着人工智能(artificial intelligence, AI)技术的飞速发展,大语言模型(large language models, LLMs)为我们提供新的视角和工具。
3.1 CMA中隐喻识别客观性的不足
CMA中隐喻识别客观性的不足主要源于隐喻识别标准不够细致以及缺乏科学理据。首先,CMA虽然提出从语言、语用和认知三个维度进行隐喻识别,也将单词尤其是短语作为隐喻识别的语言单位,但却没有对此作出详尽说明,仅凭借“语义不协调或语义张力”来判断是否为隐喻,而对语义张力的判断又带有明显的主观性,会被质疑为一种“有依据的直觉”(Deignan 1999:180)。因此,在实际操作中可能会因人工识别标准不一而影响研究结果的可信度。其次,发展的CMA(Charteris-Black" 2018)通过摒弃借助语料库识别隐喻的两步法,提出强调识别隐喻类型的五步隐喻识别法,弥补了之前可能由于某些隐喻关键词的遗漏而导致隐喻识别不全面的缺陷,但是,CMA对隐喻类型的划分标准缺乏科学依据和理据说明,仅依据一个隐喻在100个语料库词条样本中出现的次数来确定其为新奇隐喻(novel me-taphor)(少于5次的)、规约隐喻(conventional me-taphor)(5次至50次的)还是固定隐喻(entrenched metaphor)(超过50次的)。该识别标准的实际效用及科学性值得商榷。另外,CMA虽然在五步隐喻识别法中提出由几位隐喻学者分别进行隐喻识别来增加研究的可信度,但这种完全依赖人工识别隐喻的过程,难免会存在主观性问题,影响后续隐喻阐释及隐喻说明的准确性。因此,如何提升CMA中隐喻识别客观性的问题再次成为讨论的焦点。
3.2 大语言模型(ChatGPT)应用于CMA中的隐喻识别
数智时代,随着计算语言学、NLP及AI领域研究的重大进展,特别是随着LLMs对传统NLP流水线(pipeline)范式的颠覆和取代(袁毓林" 2024a:3)以及LLMs在语言理解、语言生成、语言翻译以及文本分类等方面取得的巨大进步,语言的多语义识别仅通过输入适当的提示语(prompt)(程兵" 2023),便可较好地完成任务。因此,可以尝试突破仅依靠人工的方式,借助LLMs对隐喻进行识别。
3.2.1 ChatGPT应用于CMA中隐喻识别的可行性
LLMs的标志性模型是2022年OpenAI推出的ChatGPT,从初次亮相到几次迭代更新,ChatGPT被广大用户进行过各种测评(焦建利等" 2023:21),例如,通过对包括ChatGPT-3.5在内的16个LLMs进行文本翻译和标题生成等语言处理任务的评测,ChatGPT-4呈现的语义效果最佳(赵雪等 2023),不但指标稳定性方面能够保持客观一致(李春涛等" 2024),而且还能够识别出语篇中的隐喻、转喻、夸张等(秦洪武 周霞" 2024,许家金等" 2024)。最重要的是,ChatGPT在语义理解和常识推理方面有着卓越表现(袁毓林" 2024b:62),其语言使用能力在很大程度上和人类接近(袁毓林" 2023:649)。况且,从理论上讲,AI语言模型的研究目标与人类语言学的研究目标并不抵触,可以互相补充,因为前者是为人类自然语言建立可计算的数学模型,后者是用以揭示人类自然语言的结构、功能和发展规律(袁毓林" 2024b:50),因此,可以尝试将ChatGPT应用于CMA中进行隐喻识别。
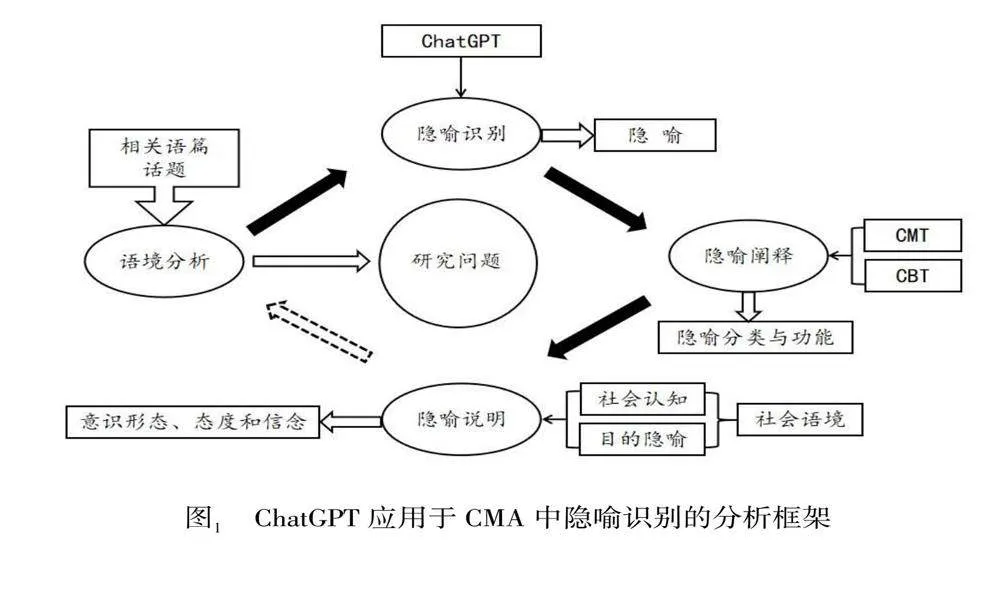
在CMA中结合ChatGPT进行隐喻识别,不但能够提高隐喻识别的客观性和工作效率,还能够促进隐喻研究的创新和发展。首先,ChatGPT是通过大规模文本数据预训练来学习隐喻遵循的特定语言模式,因此,在执行任务时能够减少由于个人经验、情感或偏见带来的偏差,减少个体差异的影响,从而提高隐喻识别的客观性;其次,ChatGPT通过其强大的自然语言处理能力,能够快速处理大量文本数据,自动识别出语境中的隐喻性语言结构,从而极大地节省人力和时间,而且,ChatGPT一旦训练完成,对于相同的语言结构会产生一致的结果,这不但能够确保隐喻识别的一致性,为隐喻研究提供更加可靠的数据基础,同时,也提高了隐喻识别的效率;再次,ChatGPT是在不断优化和迭代升级中通过持续学习来适应新的语言现象和隐喻表达,这种动态更新能够确保ChatGPT对隐喻识别的时效性和适应性,从而促进隐喻研究的创新和发展。图1为ChatGPT应用于CMA中隐喻识别的分析框架。
3.2.2 ChatGPT应用于CMA中隐喻识别的关键点
在CMA中结合ChatGPT进行隐喻识别时,提示语的输入是非常关键的一个环节。它是研究者与ChatGPT对话交互的起始点,直接决定隐喻识别结果的范围和深度。因此,编写合理准确、符合规范的提示语是提高ChatGPT识别结果质量和品质的关键。
首先,要明确任务目标。清晰明确的提示语能够帮助ChatGPT理解用户需求,从而避免因误解而产生错误,减少出错率,因此,要清晰明确地表达希望ChatGPT执行的任务,例如,“请基于Lakoff和Johnson的隐喻定义帮助识别出下面语篇中的隐喻性表达。Lakoff和Johnson认为,隐喻是人类思维的一种方式,是通过两个概念域之间不同角色的对应,从一个概念域(始源域)映射到另一个概念域(目标域)的过程,隐喻性表达是实现这种跨域映射的语言形式(词、短语或句子)。”通过在提示语中运用专业术语,还能够向ChatGPT明确指示所需分析的领域和目标。其次,要提供足够的上下文信息。隐喻的理解往往依赖于丰富的上下文,因此,向ChatGPT提供足够的背景信息,可以帮助它更准确地识别和解读隐喻。同时,也可以提供具体的文本片段作为示例,帮助ChatGPT更好地理解隐喻识别的具体要求。再次,要适当地调整交互。作为人机交互方式上的“革命性变化”(焦建利等" 2023:21),ChatGPT与研究者之间的多轮次对话交互成为一种常见模式,因此,根据ChatGPT的输出结果,对于需要更深入的解释或对某一解释有疑问时,要调整提示语,或通过提出更多问题以及提供更多信息继续与ChatGPT进行交互式讨论,使其输出的回应尽量达到满意结果。总之,提示语在ChatGPT执行任务时至关重要,提示语的质量直接影响最终的分析结果,恰当合理的提示语是输出较好隐喻识别结果的关键点。
4 研究案例
为全面解析ChatGPT应用于CMA中隐喻识别的操作过程,本文以樊登2024全民阅读大会的演讲(以下简称F演讲)为例进行说明。
4.1 语境分析
全民阅读自2014年开始,连续10次被写入政府工作报告。《中华人民共和国国民经济和社会发展第十四个五年规划和2035年远景目标纲要》明确指出,要“深入推进全民阅读,建设‘书香中国’”。全民阅读大会由此产生,旨在推动全民多读书,读好书,正如帆书一直倡导的“人生如海,好书如帆”。帆书,原名为樊登读书,源于樊登在2013年发起的樊登读书会,于2023年更名为帆书,通过精选好书与深入浅出的解读方式,引领阅读新模式,响应国家全民阅读号召。樊登也于2019年开始,每年都会进行相关主题的演讲。根据百度百科,截至2022年9月,帆书APP总注册用户数突破6000万。今年,樊登继续在全民阅读大会上作了题为《答案在书里》的演讲,一以惯之地倡导多读书、读好书。对此话题,在本次演讲中樊登使用了哪些隐喻?这些隐喻有何功能?为何使用这些隐喻?本文拟围绕这3个问题展开讨论。
4.2 隐喻识别
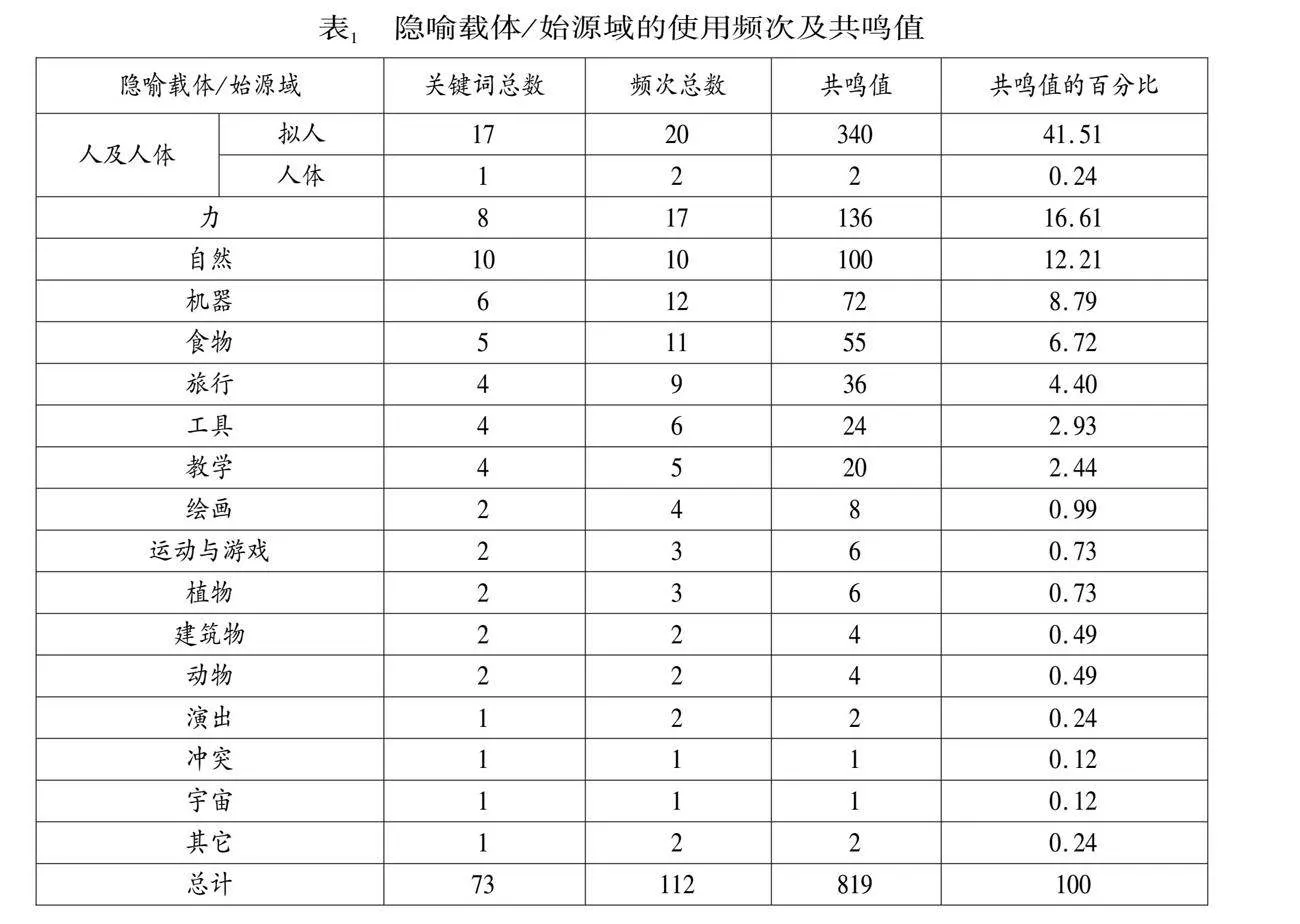
CMA对隐喻的识别标准是基于语言、语用和认知三个层次的标准,因此,在ChatGPT-4o的对话框内可以输入提示语“Can you annotate the metaphor cases in the following text according to the criterion of metaphor? And please classify source domain and target domain respectively in the following text. A metaphor is a linguistic representation that results from the shift in the use of a word or phrase from the context or domain in which it is expected to occur to another context or domain where it is not expected to occur, thereby causing semantic tension. It may have any or all of the linguistic, pragmatic and cognitive characteristics. Here is the text:”及F演讲语篇,并对上述问题进行多轮对话交互,得到如图2例示的隐喻识别结果。通过与人工识别结果比对修正后,得到隐喻句共112个,隐喻关键词共73个,隐喻关键词包括隐喻载体和适用于隐喻载体的表达,由此确定隐喻载体。
继续输入提示语“Please classify the following expressions according to:自然、人及人体、健康与疾病、动物、植物、食物、建筑、工具、机器、旅行、运动与游戏、演出、冲突、绘画、教学、热和冷、光和暗、力、颜色、宇宙、经贸及其他”及确定的隐喻载体后,得到隐喻始源域的归类结果如图3例示。隐喻始源域的分类标准是参考Kövecses(2010:18)列出的13类常见隐喻始源域来源,并结合《现代汉语分类词典》确定。
通过查阅词典,最后识别出的隐喻类别共16类(见表1),像Charteris-Black(2004, 2005)在分析政治演讲时所识别出的诸如冲突隐喻、演出隐喻、动物隐喻、建筑物隐喻等,在F演讲中也都被识别出,只是比重稍低。而共鸣值位居前5位的分别是拟人隐喻、力隐喻、自然隐喻、机器隐喻及食物隐喻。隐喻始源域的共鸣值(resonance of source domains)(Charteris-Black" 2004:89)是用于衡量始源域生产力的一个参数,由隐喻关键词的类型之和乘以隐喻关键词的频次之和得出。
4.3 隐喻阐释
作为一名倡导多读好书的阅读运动发起者,樊登的演讲均是围绕与阅读相关的主题展开,本次演讲的主题主要包括:阅读与幂次法则、幂次法则与健康、幂次法则与大脑等。根据表1,F演讲围绕各主题运用丰富的隐喻,来揭示演讲者的思想、观点和信念。
4.3.1 阅读与幂次法则
在F演讲开篇,读书便被映射为物理学中的幂次法则(例①),幂次法则的累积效应同时也映射至读书日积月累带来的影响。对于幂次法则的作用,F演讲运用隐喻关键词“主宰”和程度副词“几乎”(例②)使幂次法则被映射为具有超能力的支配地位,与阅读、健康、大脑都紧密相关,表达了演讲者对幂次法则的积极评价。同时,幂次法则还被描述为一条“曲线”,曲线具有的弧度及连续性映射着幂次法则的高低点及递进性,使听众头脑中呈现出曲线的轮廓,形成对幂次法则的基本认识。
① 读书……是物理学当中一个非常重要的现象,叫做幂次法则。
② 幂次法则构成的:y等于n的x次方,这条曲线主宰着几乎整个自然界……
4.3.2 幂次法则与健康
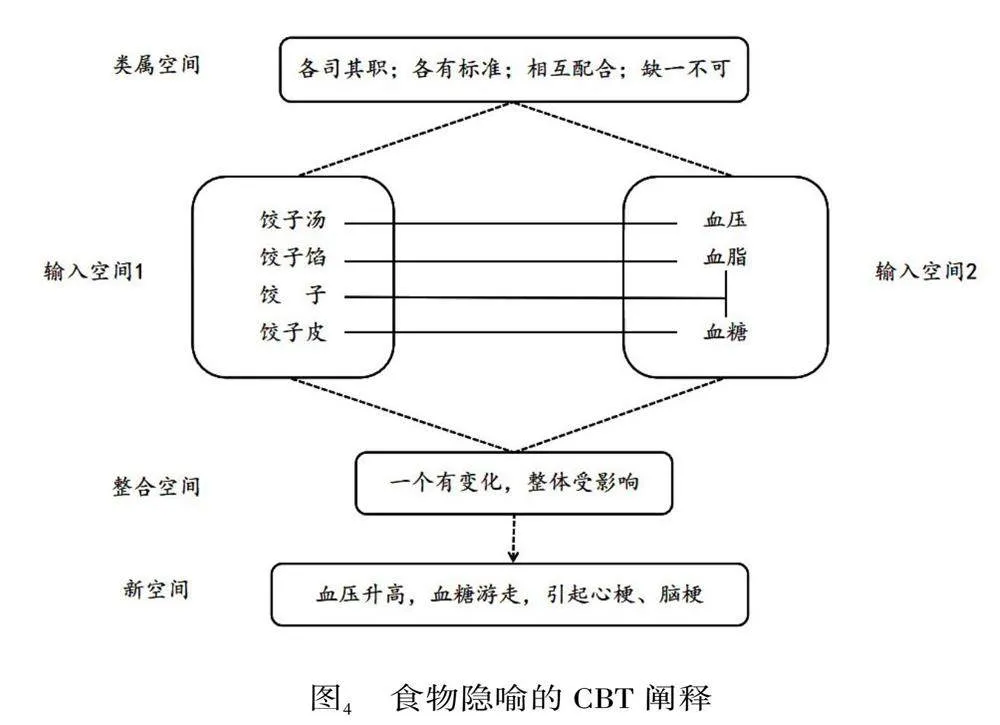
健康对于我们来说是最重要的,在描述幂次法则与健康的关系时,F演讲首先运用隐喻搭配:自然隐喻[烟雾是水]①和[烟雾是泥沙]+工具隐喻[血管是橡皮管子]+旅行隐喻[血管是路]为听众搭建一个花园浇花的场景。水的运动性和灵活性、泥沙的黏着性和不规则性同时映射在烟雾上,橡皮管子的运送功能和可能存在的堵塞隐患、道路的平坦与否和出行的通畅与否同时映射在血管上。如果烟雾进入血管中,其黏着性会使其沉积在血管壁上,长此以往,会导致血管壁不光滑,影响血液流动。烟雾对血管的伤害通过隐喻搭配清晰地展现出来,也表达了演讲者对吸烟行为的消极评价。基于血管的运送功能,受到伤害的血管会导致血糖、血脂、血压发生异常。F演讲运用一系列的食物隐喻将复杂的医学专业问题生活化。如图4所示,医学域与饺子域的各元素之间存在着映射关系,同饺子皮、饺子馅、饺子汤一样,血糖、血脂、血压也都有自己的作用,有各自的健康指标,它们共同维护人体的健康,如果一个发生变化,整体都会受到影响。正如,饺子煮漏会导致饺子汤浑浊、饺子馅漂浮,如果血压升高,血糖血脂便会分离,堵塞在血管的某处,引起心梗、脑梗等疾病。F演讲运用我们熟悉的饮食域映射抽象的医学概念,使其更易理解的同时,指出读书获取的医学知识对于我们健康生活的重要性,表达演讲者对读书的积极评价。
而心梗、脑梗之类疾病的发生同样与幂次法则有关,特别是让人闻风色变的癌症,它们表面上是“断崖式”的突然发生,其实,都源于累积效应。F演讲运用大量的拟人隐喻[细胞是人]描述癌症的累积源由,将人类的主观能动性、人类的思维能力及具体人物特征映射至细胞上。细胞便具有人类“大公无私”(例③)、“宽容体谅”(例④)的特征,它们会规律性地生长、死亡,同时也具有人的情感,会“难受”、会“痛苦”(例⑤),如果长期遭受外来伤害,它们也会思考(例⑥)、会“叛变”(例⑦),最终以一种新的形象存在:癌细胞。例⑥中指称代词“我”的搭配使用,更强化了细胞的思维能力,使医学知识具象化的同时,更加深入人心。
③ 我们人类的细胞……最大的特点是“大公无私”,……
④ 比如说你的手被刀子划破了,把很多细胞直接杀死了,没关系,它会长好,它会原谅你。
⑤ 假如你……让这些细胞很难受、很痛苦,它就会突然改变性状。
⑥ 这群细胞突然之间不想跟你们合作了,我不想做多细胞生物了,我打算做单细胞生物。
⑦ 当我们的细胞在遭受着长期的非致命性伤害的时候,他就决定叛变了。
4.3.3 幂次法则与大脑
F演讲从孩子的教育入手谈论幂次法则与大脑的关系。同样地,不当教育行为的累积效应也会导致孩子突然出现心理问题、学习问题,造成教育的失败。F演讲首先运用隐喻链,即教育要盯住→盯住就上来→不盯就下去(例⑧),表明严格管理的必要性,同时,力隐喻[严格监督就是眼睛盯住]与连词“一……就……”“不……就……”的互动也暗示部分父母虽然重视孩子教育,但却选择了错误的教育方式,无形中给孩子施加了更大的压力,而过大的压力则意味着对大脑的不良影响。容器隐喻[感官系统是容器](例⑨)表明大脑面对过大压力时,能够像容器一样被封闭起来,选择隔断与外界的联系。机器隐喻[感官系统是机器](例⑩)表明感官系统各部分会如同机器般统一选择开或关。动物隐喻[孩子是野兽](例B11)和拟人隐喻[身体是人](例B12)暗指当孩子在全部感官系统关闭后出现的暴力行径或自残行为,这就是不良累积效应。多种隐喻的搭配使用形象描述了孩子在错误教育方式下可能产生的不良后果,表明了演讲者对部分家长教育方式的消极评价,并以此暗示家长读书获取的教育知识对于提升健康教育意识和采取积极教育行为对孩子健康成长的重要性。
⑧ 甚至有很多家长认为,真正有效的教育就是“盯住”,因为一盯住成绩就上来,不盯就下去。
⑨ 当一个人觉得很痛苦时,为了自我保护,他会封闭掉所有的感官系统。
⑩ 他身上针对所有快乐的感受器也都被关掉了。
B11 很多校园霸凌的新闻……会有那么多的人像野兽一样的去打自己的同类。
B12 自残……会让他觉得有意义……,他的身体还在爱着他……
为避免教育悲剧的发生,F演讲继续运用旅行隐喻[孩子的成长是旅行]→[孩子头脑的变化是方向或路径的转变](例B13)告诫家长,要提前预知可能发生的事,并及时采取有效措施,以免孩子心理突然发生变化。同时,运用自然隐喻[人脑是微缩的自然界](例B14)提醒家长,孩子的成长是有规律性的,强行干扰会造成意想不到的后果。还运用机器隐喻[人是复杂体系](例B15)再次提醒家长,孩子不是“汽车”,不要试图“掌控”孩子,要适当的“放手”,给孩子一定的成长空间,只有这样,孩子的人生之路才能“走好”。最后,F演讲运用动物隐喻[信息封闭是信息茧房](例B16)希望听众们不做茧房里的茧,突破自己,读“破圈”之书,做“破圈”之人,表达了演讲者对读书的积极评价和强烈推荐。
B13" 想要让所有的家长,能提前到幂次曲线拐弯的地方看一眼。
B14 人脑就是一个微缩的自然界。
B15 人的一生属于复杂体系。
B16 只读自己喜欢的书,会陷入在一个封闭的信息茧房里边。
4.4 隐喻说明
通过对F演讲中隐喻概念表征及评价意义的分析阐释,我们可以揭示出演讲文本中的隐喻所构建的思想、观点和信念。
首先,从当前形势上看,随着信息技术的快速发展,网络短视频、碎片化信息已成为人们日常生活中不可或缺的一部分。面对大量扑面而来、应接不睱的信息,学会甄别尤为重要。而甄别信息所需要的独立思考能力,除通过经验、阅历积累外,读书培养是最为重要的途径。F演讲运用长期读书所产生的幂次效应激励听众要多读好书,读破圈之书。在帮助听众理解两者之间的关系时,F演讲运用拟人隐喻、隐喻搭配以及隐喻链,将抽象知识具体化、复杂知识直观化、专业知识生活化,激活听众对阅读的新认知,调整或扩展听众的认知结构,从而深化听众对阅读价值的理解,形成更广泛的阅读认同和重视阅读的社会氛围,更好地传达“读书让我们更具深度、理性和智慧”的思想。
其次,从隐喻的现实交际目的上看,在F演讲中,演讲者以隐喻方式激励听众要多读好书,讲述与读书密切相关的幂次法则故事。在讲述花园浇花、包饺子和煮饺子的生活故事时,隐喻将听众拉进生活,增添亲切感的同时,引起听众注意,建立信任感,实现隐喻修辞目的的同时,让听众感受到读书在获取知识、内化知识、培养思考能力过程中起到的重要作用,实现其意识形态目的。在讲述孩子教育问题时,隐喻将累积效应发生后的悲惨故事展示在听众面前,激起听众悲伤情绪的同时,也启发听众、激励听众采取积极措施,实现隐喻的移情目的和启发性目的。在讲述细胞故事时,隐喻使用描写人类动作、情感的动词和形容词,例如,“不想”“决定”“难受”等,拉近与听众距离的同时也提醒听众要避免长期伤害,实现隐喻的谓词评价目的。而所有故事的讲述都是在演讲者意识形态目的下进行的神话叙事,即多读书、读好书。
通过运用结合ChatGPT的CMA分析F演讲,本文将LLM(ChatGPT)运用到CMA的隐喻识别中。我们发现ChatGPT除了提高隐喻识别的客观性之外,最大助力是对分析过程起到的启示作用。同时,也遇到3个问题:一是隐喻识别的结果与预期不完全一致;二是对隐喻关键词的频次统计结果不准确;三是操作过程的反复性。这在某种程度上表明,第一,LLM(ChatGPT)还不具备完善的人类智能(冯志伟" 2024:89),对于涉及语言、文化、认知等多个层面复杂隐喻现象的识别,目前机器尚无法独立完成,还需要与人工识别相结合,发挥其辅助和启示作用;第二,运用何种技术赋能语言研究要根据研究目的和研究问题来确定,对于频次统计类任务,可以运用技术较为成熟的Excel或语料库等工具来完成,展示其各有所长;第三,要明确LLM(ChatGPT)在隐喻研究中所扮演的角色。LLM(ChatGPT)虽然功能强大,但现阶段仍然受控于使用者的指令来完成任务,因此,我们要利用LLM(ChatGPT)的超强能力,同时也要保持自己的特色(Mollick" 2024),使LLM(ChatGPT)在隐喻研究中发挥副驾驶(copilot)作用(袁毓林" 2024c:576),即,研究人员与LLM(ChatGPT)形成伙伴关系,二者全程参与任务,LLM(ChatGPT)可以完成一些重复性的工作,研究人员则专注于更高级别的思考和创新,并运用专业知识和判断,确保隐喻分析的深度和准确性,同时也通过LLM(ChatGPT)的提示,获得新观点,补充或修正自己的结论,实现人机协作的最佳方式。
5 结束语
CMA作为一种普遍运用的语篇隐喻分析方法,不但深化我们对语言隐喻的理解,还揭示隐喻在人类思维和交流中的重要作用。隐喻识别作为CMA分析框架中的一个关键环节,发挥着至关重要的作用。本研究首先就CMA中隐喻识别的融合性和枢纽性进行深入讨论,了解CMA中隐喻识别的发展特性,熟悉CMA的整个分析框架。同时,针对CMA中隐喻识别客观性不足的问题,本研究提出在CMA中运用LLM(ChatGPT)进行隐喻识别的解决方法,并基于真实研究案例了解该方法的具体实践操作。通过案例,本研究也对运用LLM(ChatGPT)进行隐喻识别过程中遇到的问题加以分析和总结,希望通过合理、恰当地运用技术手段,探索人机协作的最优路径,从而提升隐喻识别的客观性,完善CMA的分析框架,更深入地进行语篇的隐喻研究。同时,也希望CMA能继续跨语言学、认知科学、社会学和计算机科学等领域的研究,使CMA更加完善,为语篇的隐喻研究提供更全面的分析视角、更客观的隐喻识别方法。
注释
①符号[]为概念隐喻标识。
参考文献
陈 朗. 从MIP到MIPVU: 隐喻识别的方法、应用与问题[J]. 外语学刊, 2022(5).‖Chen, L. From MIP to MIPVU: Approach, Practice and Issues in Metaphor Identification Procedure[J]. Foreign Language Research, 2022(5).
程 兵." 以ChatGPT为代表的大语言模型打开了经济学和其他社会科学研究范式的巨大新空间[J]. 计量经济学报, 2023(3).‖Cheng, B. Artificial Intelligence Generative Content (AIGC) Including ChatGPT Opens a New Big Paradigm Space of Economics and Social Science Research[J]. China Journal of Econometrics, 2023(3).
冯志伟. 从ChatGPT到Sora发展中的术语问题[J]. 中国科技术语, 2024(2).‖Feng, Z.-W. Term Problem in the Development from ChatGPT to Sora[J]. China Terminology, 2024(2).
焦建利 陈 丽 吴伟伟. 由ChatGPT引发的教育之问:可能影响与应对之策[J]. 中国教育信息化, 2023(3).‖Jiao, J.-L.," Chen, L., Wu, W.-W." Educational Issues Triggered by ChatGPT: Possible Impacts and Counter Measures[J]. Chinese Journal of ICT in Education, 2023(3).
李春涛 闫续文 张学人." GPT在文本分析中的应用:一个基于Stata的集成命令用法介绍[J]. 数量经济技术经济研究, 2024(5).‖Li, C.-T.," Yan, X.-W.," Zhang, X.-R." Application of GPT in Textual Analysis: An Introduction to A Community Developed Command within Stata[J]. Journal of Quantitative amp; Technological Economics, 2024(5).
秦洪武 周 霞." 大语言模型与语言对比研究[J]. 外语教学与研究, 2024(2).‖Qin, H.-W.," Zhou, X." Large Language Models for Contrastive Linguistics[J]. Foreign Language Teaching and Research, 2024(2).
孙 亚. 基于语料库方法的隐喻使用研究:以中美媒体甲流新闻为例[J]. 外语学刊, 2012(1).‖Sun, Y. A Corpus-based Approach to Metaphor Use: A Case Study of H1N1 Flu Discourse in Chinese and American Media[J]. Foreign Language Research, 2012(1).
许家金 赵 冲 孙铭辰." 大语言模型的外语教学与研究应用[M]. 北京:外语教学与研究出版社, 2024.‖Xu, J.-J.," Zhao, C.," Sun, M.-C. Applications of Large Language Models in Foreign Language Teaching and Research[M]. Beijing: Foreign Language Teaching and Research Press, 2024.
袁毓林. 超越聊天机器人,走向通用人工智能——ChatGPT的成功之道及其对语言学的启示[J]. 当代语言学, 2023(5).‖Yuan, Y.-L. Beyond Chatbots and Towards Artificial General Intelligence (AGI): The Success of ChatGPT and Its Implications for Linguistics[J]. Contemporary Linguistics, 2023(5).
袁毓林. ChatGPT等大型语言模型对语言学理论的挑战与警示[J]. 当代修辞学, 2024a(1).‖Yuan, Y.-L. Challenges and Warnings from Large Language Models like ChatGPT on Linguistics Theories[J]. Contemporary Rhetoric, 2024a(1).
袁毓林. 如何测试ChatGPT的语义理解与常识推理水平?——兼谈大语言模型时代语言学的挑战与机会[J]. 语言战略研究, 2024b(1).‖Yuan, Y.-L. How to Test ChatGPT’s Performance in Semantic Understan-ding and Common-Sense Reasoning: Challenges and Opportunities of Linguistics in the Era of Large Language Models[J]. Chinese Journal of Language Policy and Planning, 2024b(1).
袁毓林. ChatGPT语境下语言学的挑战和出路[J]. 现代外语, 2024c(4).‖Yuan, Y.-L. Challenges and Prospects for Linguistics in the Context of ChatGPT[J]. Modern Foreign Languages, 2024c(4).
赵 雪 赵志枭 孙凤兰 王东波. 面向语言文学领域的大语言模型性能评测研究[J]. 外语电化教学, 2023(6).‖Zhao, X.," Zhao, Z.-X.," Sun, F.-L.," Wang, D.-B. Performance Evaluation Study of" Large Language Models for the Field of Language and Literature[J]. Technology Enhanced Foreign Language Education, 2023(6).
朱嘉莹 王荣波 黄孝喜 谌志群." 基于Bi-LSTM的多层隐喻识别方法[J]. 大连理工大学学报, 2020(2).‖Zhu, J.-Y.," Wang, R.-B.," Huang, X.-X.,""" Chen, Z.-Q." Multi-level Metaphor Detection Method Based on Bi-LSTM[J]. Journal of Dalian University of Technology, 2020(2).
Charteris-Black, J. Corpus Approaches to Critical Metaphor Analysis[M]. Hampshire: Palgrave Macmillan, 2004.
Charteris-Black," J. Politicians and Rhetoric: The Persuasive Power of Metaphor[M]. Hampshire: Palgrave Macmillan, 2005.
Charteris-Black, J. Forensic Deliberations on “Purposeful Metaphor”[J]. Metaphor and the Social World, 2012(2).
Charteris-Black, J. Analyzing Political Speeches: Rhetoric, Discourse and Metaphor[M]. Basingstoke amp; New York: Palgrave MacMillan, 2014.
Charteris-Black," J. Analysing Political Speeches: Rhetoric, Discourse and Metaphor(2nd Edition)[M]. Hampshire: Palgrave Macmillan, 2018.
Deignan, A. Corpus-based Research into Metaphor[A]. In: Cameron, L., Low, G.(Eds.), Researching and Appl-ying Metaphor[C]. Cambridge: Cambridge Press, 1999.
Do, Dinh, E.L., Gurevych, I. Token-Level Metaphor Detection Using Neural Networks[A]. In: Klebanov, B., Shutova, E., Lichtenste, P.(Eds.), Proceedings of the Fourth Workshop on Metaphor in NLP[C]. San Diego: Association for Computational Linguistics, 2016.
Fauconnier, G., Turner, M." The Way We Think — Concep-tual Blending and the Mind’s Hidden Complexities[M]. New York: Basic Books, 2002.
Kövecses, Z. Metaphor: A Practical Introduction(2nd Edition)[M]. New York: Oxford University Press, 2010.
Lakoff, G., Johnson," M. Metaphors We Live By[M]. Chicago and London: The University of Chicago Press, 1980.
Mollick, E. Co-Intelligence: Living and Working with AI[M]. WH Allen, 2024.
Pragglejaz Group. MIP: AMethod for Identifying Metaphorically Used Words in Discourse[J]. Metaphor and Symbol, 2007(1).
Rayson, P. From Key Words to Key Semantic Domains[J]. International Journal of Corpus Linguistics, 2008(4).
Steen, G.J., Dorst, A.G., Herrmann, J.B.," Kaal, A.A.," Krennmayr, T.," Pasma, T." A Method for Linguistic Me-taphor Identification: From MIP to MIPVU[M]. Amsterdam: John Benjamins, 2010.
van Dijk, T. Discourse and Context: A Sociocognitive Approach[M]. Cambridge: Cambridge University Press, 2008.
定稿日期:2024-12-10【责任编辑 孙 颖】
