语言模型辅助的英语科技论文摘要语步语料库构建研究
2025-01-26李洪政王若锦刘芳冯冲


提 要:语步结构是学术论文中的文本语篇单位,在学术用途英语等方面具有重要价值。尽管关于学术论文的语步研究非常丰富,但语步标注数据资源仍然相对较少。本研究借助自然语言处理领域的语言模型构建了涵盖多个学科领域的英语科技论文摘要语步标注语料库,包括近3.4万个语步结构。语料库构建的第一阶段依靠专家标注形成高质量语料,在第二阶段也是主要阶段,采用基于BERT架构的自动标注模型,在保证标注质量的同时能够快速提升标注速度、扩大标注规模。本研究随后开展了摘要语步自动标注识别实验,对比自动标注模型与大语言模型ChatGPT和Claude3识别不同学科领域的语步结构的效果,验证了模型和语料库的价值。该研究能为科技论文写作智能批改等自然语言处理任务以及学术用途英语等外语教学与研究等提供必要的数据资源,也验证了大语言模型辅助构建语言资源的可能性,体现了语言智能驱动的智慧外语教育的重要性,能有效推动外语教育数字化转型。
关键词:语步结构;语料库;摘要文本;大语言模型
中图分类号:H08 """"文献标识码:A """"文章编号:1000-0100(2025)01-0029-10
DOI编码:10.16263/j.cnki.23-1071/h.2025.01.004
Research on Language Model-assisted Construction of Corpus for
Move Structures in Abstracts of English Scientific Articles
Li Hong-zheng1,2 Wang Ruo-jin1,2 Liu Fang1,2 Feng Chong3
(1.School of" Foreign Languages, Beijing Institute of Technology, Beijing 102488; 2.Key Laboratory of" Language,
Cognition and Computation Ministry of Industry and Information Technology, Beijing 102488;
3.School of Computer Science, Beijing Institute of Technology, Beijing 100081, China)
Move structures are discourse units in research articles (RA) and are of great value in English for Academic Purposes. Although there is abundant research on move structures in academic articles, there are still relatively few move annotation data resources. Based on Natural Language Processing (NLP) technologies, this research constructed a corpus for annotating move structures in English RA abstracts, and nearly 34,000 move structures from multi-disciplines were annotated. The first stage of corpus construction relied on manual expert annotation to form high-quality corpus data. In the second and main stage, a BERT-based automatic annotation model was adopted to improve the annotation speed and expand the annotation scale while ensuring the annotation quality. We then conducted move structure recognition experiments and compared the performance of our mo-del with large language models (LLM) including ChatGPT and Claude3, indicating the effectiveness of the proposed model. This research can provide necessary data resources for NLP related tasks such as intelligent assistance of English scientific articles writing. It is beneficial to foreign language teaching and research such as English for Academic Purposes, and verifies the possibility of" LLM to assist in the construction of language resources. It also shows the importance of intelligent foreign language education empowered by language intelligence and can effectively promote the digital transformation of foreign language education.
Key words:move structure; corpus; abstract texts; large language model
1 引言
语步(Move)指具有具体交际功能和目的的文本切分单位和语义片段,用来表示特定意义,代表着学术论文各章节的表述结构与序列(Swales 1990:83,2004:18)。语步能够有效表征论文语篇的宏观结构,并为实现整个语篇体裁的总体交际目的服务,揭示论文语篇的目的性、步骤性和规约性(杨延宁" 邹航" 2023:1)。科技学术论文,特别是研究论文(Research Article, 简称RA)是科技和学术交流的重要载体。在研究论文中,摘要是必不可少的组成部分,通过简洁、清晰而有说服力的段落传达整篇文章的核心思想和亮点。可读性好的摘要应该包括组织良好及逻辑合理的语步结构,分别论述论文的研究背景、目的、方法、结论等基本信息,以凸显文章的重要性和价值。
下面是自然语言处理(NLP)领域的一个英文论文摘要示例,其中清楚包含几种常见的语步结构。
①lt;背景gt;Previous works on cross-lingual NER are mostly based on label projection with pairwise texts or direct model transfer. lt;差距gt;" However, such methods either are not applicable if the labeled data in the source languages is unavailable, or do not leverage information contained in unlabeled data in the target language. lt;目的gt;In this paper, we propose a teacher-student learning method to address such limitations. lt;方法gt;NER models in the source languages are used as teachers to train a student model on unlabeled data in the target language.lt;结论gt;Extensive experiments for 3 target languages on benchmark datasets well demonstrate that our method outperforms existing state-of-the-art methods for both single-source and multi-source cross-lingual NER.
语步研究在专门用途英语(English for Speci-fic Purposes, 简称ESP)和学术用途英语(English for Academic Purposes, 简称EAP)等领域具有比较久远的历史,在外语科技论文写作、语步分析等方面具有重要应用价值(Hyland 2008:5; Moreno, Swales 2018:40; Swales 2019:75)。自从语步被提出以来,很多研究基于不同学科领域学术论文的不同部分如摘要、引言、方法、结论等内容,针对语步、修辞结构和语言学特征等开展了比较详细的分析和讨论(Cotos et al. 2017:90; Lu et al. 2021:63; Alsharif 2023:1268)。近年来也有一些研究工作关注语步结构的检测与自动识别等(王东波等 2018:997; Alliheedi et al. 2019:113; 丁良萍等 2019:16; 王末等 2020:60; 杜新玉" 李宁" 2024:74; 张鑫等 2024:117)。语步结构识别可以使文献中蕴含的知识显式地体现出来,提高知识利用效率,是内容抽取、文本摘要等任务应用的重要基础性工作(黄红等" 2022:991)。但是之前的研究工作多只关注某一特定学科领域论文中特定部分的语步分析,或某个特定语步的识别,几乎没有跨学科对比研究和全面的语步结构研究;另一方面,目前面向学术写作的语步结构自动标注的研究相对较少,同时也缺乏针对科技研究论文摘要部分中的语步标注资源建设。这种不足为跨语言语步分析与识别、科技论文信息抽取等自然语言处理任务和计算机辅助语言学习(Computer-Assisted Language Learning, 简称CALL)等应用场景带来了很多挑战。
为了解决这些问题,本研究应用自然语言处理技术构建一个大规模、多领域的英语科技论文摘要语步标注语料库,当前已累计标注近3.4万个语步实例,涵盖人工智能、通信工程和机械工程等学科领域。标注主要分为两个阶段:在前期初始阶段,通过人工标注形成一部分高质量的标注数据;在后期阶段也是目前标注的主要阶段,在高质量标注数据的基础上,训练了一个基于BERT语言模型架构的自动标注模型,实现语步自动标注,然后人工进行干预,修正模型标注不准确或者错误的语步,在快速扩大标注数量和规模的同时也能够保证标注质量。随后开展了语步结构自动识别实验,对比我们的标注模型与GPT-4和Claude 3等大语言模型在不同学科领域的语步识别效果,并针对具体实例进行了比较详细的分析。
2 相关研究
2.1 语步分类
语步的概念最初来自修辞学,最早由美国语言学家J. Swales提出。Swales开创性地提出CARS语步模型(Swales 1990:141, 2004:228)和语步分类体系(Swales, Feak 2009:6),为后来的语步研究带来深远影响,此后不同时期的很多学者都在此基础上针对语步的特点不断改进语步的相关理论,并进行语步分类研究,包括Teufel等人提出的Argumentative Zoning (AZ) scheme(Teufel et al. 1999:110)及其修正后的理论等(Teufel et al. 2009:1493; Teufel 2010:443)。
2.2 语步标注
随着语步理论研究的发展,也出现一些在此类理论指导下建设的语步结构数据资源。Alliheedi等人重点关注生物化学领域论文方法部分中的语义角色和修辞语步(Alliheedi et al. 2019:113);刘霞(2016)构建了选自《应用语言学》(Applied Linguistics)期刊摘要的数据集;Viera等人(2020)通过构建摘要语料库,调查了在英语母语国家和非英语国家发表的研究论文摘要中的修辞。已有的语步结构语料库通常都是面向特定单一领域的,而且规模相对较小,目前仍然缺乏多领域大规模的摘要语步语料库。因此,有必要构建涵盖多个学科领域的论文摘要标注语料库。
3 语料库构建过程
3.1 理论基础
本研究构建语料库的主要理论基础是Hyland(Hyland 2000:132)关于论文摘要语步的五分类理论。他认为,之前有关学术论文全文的语步分类可能并不完全适合分析摘要部分的语步结构。经过对纯科学、应用科学、人文科学和社会科学等学科门类的论文摘要的考察,他提出学术论文摘要语步五分类法:
研究介绍(Introduction):论述研究说明,包括研究重要性、关键术语概念、研究差距等;
研究目的(Purpose):指出该研究的一般或者特别目的;
研究方法(Method):指明该研究的具体方法,包括数据、处理过程等;
研究产出(Product):讨论该研究的主要发现和结果;
研究结论(Conclusion):引出该研究的结论,包括研究重要性、研究不足、对未来研究的启示等。
根据前期调研和先导标注试验(Pilot Study),我们发现Hyland的分类无法完全适合特定领域的摘要语步,因此需要进一步的详细分类体系。如例②的类似表达在很多包括NLP在内的人工智能领域论文中都非常常见,一般是开源论文研究的相关信息,通常可以认为是对整个研究社区的贡献和价值,无法采用Hyland分类中的任何一种进行标注。
②" We release source code for our models and experiments at Github.
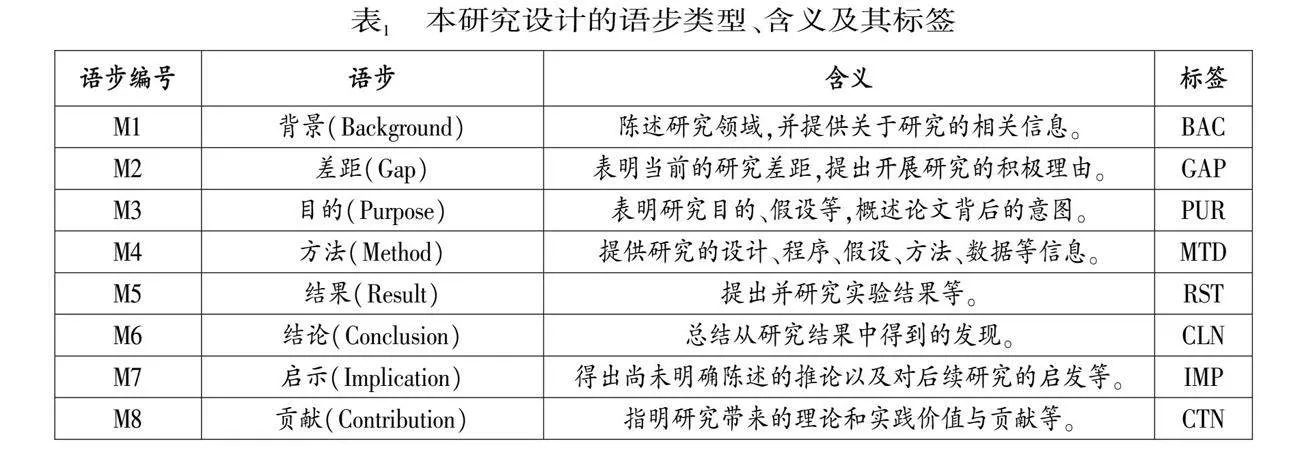
在Hyland分类的基础上,我们根据具体标注需求,对该分类方法进行调整和补充,提出表 1所示的8种基本语步类型,并为每种语步设置了标注标签。
3.2 语料来源及处理
本研究选择各专业领域专家推荐的英文顶级期刊(JCR Q1)和国际知名顶级会议论文中的摘要作为标注语料,涵盖人工智能学科和工程学科两个大类。其中人工智能学科包括NLP和计算机视觉(CV)两个领域;工程大类包括通信工程(Communication Engineering, 简称CE)和机械工程(Mechanical Engineering, 简称ME)两个领域。
对于人工智能领域,考虑到会议论文具有更高的时效性以及相比期刊更大的录用比例,我们选择了两个顶级国际会议:国际计算语言学大会(ACL)主会论文和世界人工智能大会(AAAI)中CV Track的会议论文作为数据来源。从ACL会议论文收录平台ACL Anthology官网(https://aclanthology.org/)可以直接下载收录所有论文信息的文献文件(BibTex),从中筛选出3年(ACL2020-ACL2022)的长论文摘要作为标注数据;另外从AAAI 2022大会官网中获取CV Track的会议论文。对于工程大类领域,选择了3本顶级期刊(Journal of Mechanical Design, International Journal of Heat and Mass Transfer," IEEE Journal on Selected Areas in Communications)。在Web of Science (WOS)检索平台中检索每本期刊的信息,然后将检索得到的论文题目、摘要等基本信息进行处理。
为了方便标注语步结构,我们把两个学科领域的所有摘要文本段落根据主要的句末标点符号预处理为一句话一行的格式。同时在保留原文基本意义的前提下,对摘要文本进行必要的数据清洗,忽略可能会影响标注的特殊符号、引用格式等信息,以保证标注文本的质量。
3.3 语料库构建
语料库构建主要分为两个阶段:第一阶段是人工标注,第二阶段是系统自动标注+人工修正。我们采用开源标注工具Doccano作为在线标注平台,图1是该平台的标注界面。
3.3.1 人工标注
为了保证标注质量和准确性,我们的语料标注团队由外国语学院的4名专业教师和1名外语语言学专业的博士生组成,进行分工标注。同时每周举行例会讨论标注过程中存在的各种疑难问题。在标注过程中,原则上语步以完整的句子为单位,标注者需要为每个句子选择最合适的语步标签。在标注平台中,选中一个句子以后,平台即可弹出设计好的标注标签,标注者可以选择一个标签完成标注。如果需要修改,可以点击标签,选择其他合适的标签。
3.3.2 自动标注
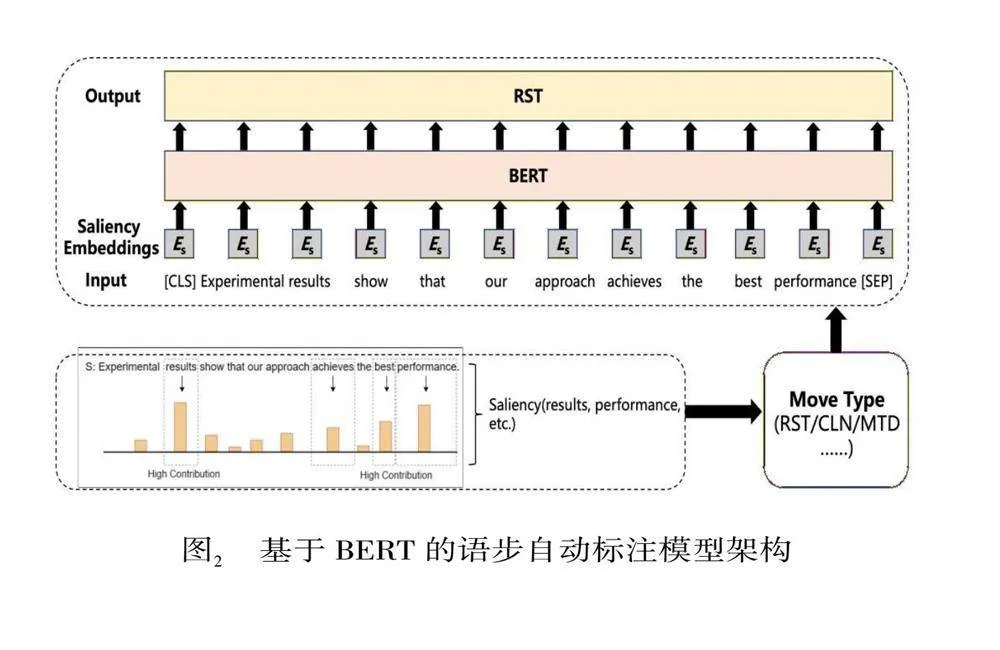
人工标注虽然能够保证标注质量,但无法提升标注速度和语料库标注规模,因此需要自动标注。本研究采用Lin等(2023)提出的基于BERT(Devlin et al. 2019)的语步自动标注模型(图 2),将语步识别标注视为多标签识别和分类问题。
值得注意的是,在标注识别语步的时候,句中的不同单词对于预测句子语步类型具有不同的影响。每种语步的表达也都依赖于一些特别的词语。像图2中的例句,句中有results,performance等非常明显的关键词,它们对于快速识别为结果语步类型具有更高的贡献程度。考虑到这种普遍情况,该模型引入显著性注意力(saliency attention),句子中的每个单词都被视为一个特征,并计算其对特定语步类型的贡献(显著性值)。模型从人工标注的高质量数据中学习句子的语义特征,每个句子首先被分配一个表达整体语义的语步标签,然后设计词语显著性向量(word saliency embeddings)与BERT模型的其他3种向量(即token,segment与position embeddings)一起作为输入表示来捕捉特定词语对于语步的贡献情况,从而提升模型识别语步的能力,最终完成语步识别和标注。
自动标注结果上传到标注平台以后,标注团队分工检查标注结果,并进行修正。标注模型根据人工反馈的数据,可以不断进行迭代优化,进一步提升标注效果。通过这种方式,可以快速提高标注速度和效率,在保证标注质量的同时扩大标注规模。语料标注完成以后,可以直接从标注平台中导出如例③所示的JSONL格式标注文件,其中包括标注数据的ID、数据文本及相应的标签等基本信息。
③ {\"id\": 20,
\"data\": \"Words can have multiple senses. Compositional distributional models of meaning have been argued to deal well with finer shades of meaning variation known as polysemy,but are not so well equipped to handle word senses that are etymologically unrelated, or homonymy.\",
\"label\": [[0, 31, \"BAC\"], [32, 265, \"GAP\"]]}
4 语料库数据统计
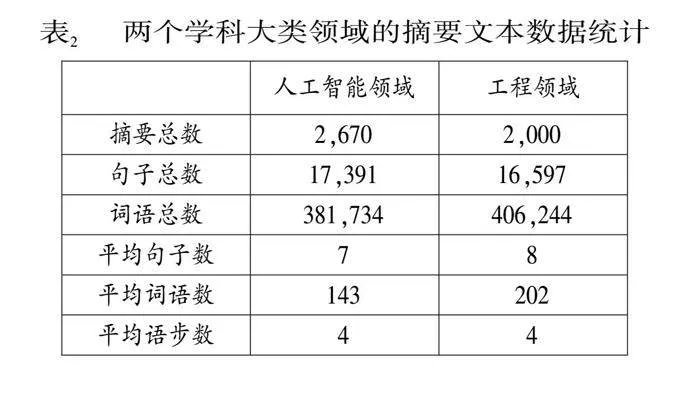
本研究目前已标注2,670篇人工智能学科(NLP方向1,340篇,CV方向1,330篇)和2,000篇工程学科(通信工程和信息工程各1,000篇)的论文摘要,共得到33,988个语步。两个学科领域论文摘要文本中的数据统计信息如表2所示。其中,平均句子数、平均词语数和平均语步数分别指每篇摘要中平均包含的句子数量、单词数量和语步数量。
4.1 各类语步结构在不同学科的标注情况
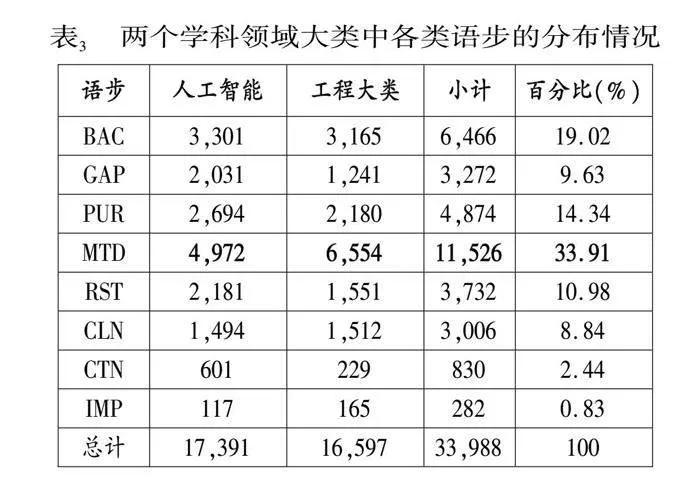
表3是语料库中标注的各类语步的分布情况。从表3中可以看到,在摘要中不同类型语步的分布存在很大差异。MTD语步在两个学科中的标注次数都是最多的,标注数量占比高约34%,甚至超过第二位BAC和第三位PUR的总和;而IMP的次数最少,只占低于1%的比例。表明不同领域的论文摘要均更关注MTD这一语步。这也跟直觉判断是一致的,因为方法确实是摘要中最有吸引力和最重要的部分之一,在摘要中通常会重点说明论文研究使用的方法,体现出该论文的价值和亮点。在标注过程中,我们也发现,很多论文摘要中的方法语步甚至包括不止一个句子。
对比两个学科领域可以看到不同学科的摘要文本特点和语步分布存在较大差异。结合表2和表3,工程领域的摘要文本数量比人工智能少了近700篇,但摘要文本的句子数量整体比人工智能领域多,而且平均词语数量也远高于人工智能,工程领域摘要的句子长度更长。语步分布上,工程领域的MTD语步数量远高于人工智能领域,其他语步如BAC,GAP,PUR等数量均少于人工智能。这表明通信工程和机械工程这两个工程学科的论文摘要更倾向用较多的语句来详细论述研究方法。标注团队在实践中也确实发现,很多论文摘要开头很少交代研究背景和研究差距,而是直接用一句话交代研究目的,随即用多个连续的句子讨论研究采用哪些方法,同时也不太注重提及研究本身的价值以及对于本领域的启发和贡献等。由于人工智能领域整体上具有明显的开源特点,很多论文摘要中经常提到研究相关的代码、数据等面向公众开源,体现了对于研究社区的贡献,我们会把这种表述统一标注为CTN,因此这一语步在人工智能领域的数量更多。
下面的两个标注实例对比了NLP和ME两个不同领域方向的摘要语步特点。
④"" [BAC]Knowledge graph (KG) entity ty-ping aims at inferring possible missing entity type instances in KG. [GAP]It is a very significant but still under-explored subtask of knowledge graph completion. [PUR]In this paper, we propose a novel approach for KG entity typing which is trained by jointly utilizing local typing knowledge from existing entity type assertions and global triple knowledge in KGs. [MTD]Specifically, we present two distinct knowledge-driven effective mechanisms of entity type inference ... [CLN]Experimental results on two real-world datasets (Freebase and YAGO) demonstrate the effectiveness of our proposed mechanisms and models for improving KG entity typing. [CTN]The source code and data of this paper can be obtained from GitHub...
⑤"" [PUR]This paper proposes a novel density-based method for structural design considering restrictions of multi-axis machining processes. [MTD]A new mathematical formulation based on Heaviside function is presented to transform the design field into a geometry which can be manufactured by multi-axis machining process. [MTD]The formulation is developed for 5-axis machining, which can be also applied to 2.5D milling restriction. The filter techniques are incorporated to effectively control the minimum size of void region. [MTD]The filter techniques are incorporated to effectively control the minimum size of void region. [CLN]The proposed method is demonstrated by solving the compliance minimization problem for different machinable freeform designs.
4.2" 各类语步结构在不同学科的出现情况
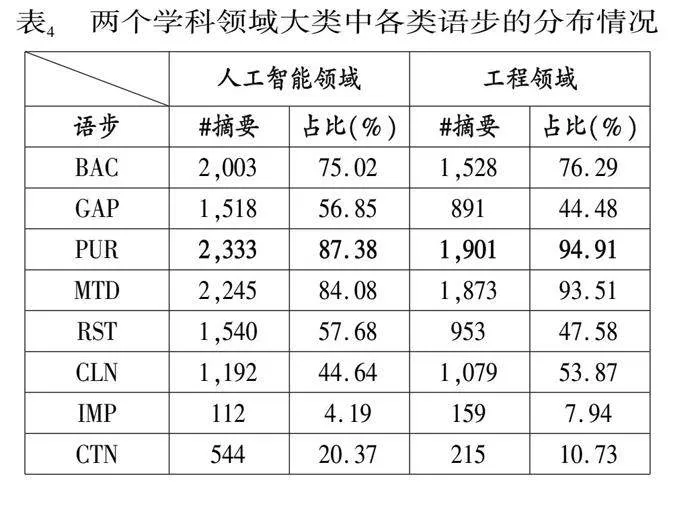
在语步分布的基础上,如果不考虑每种语步在摘要中的标注次数(一次或者多次),只要标注了该语步,则认为该摘要文本中包括该语步类型。我们也对这种情况进行统计。表4显示在2,670篇人工智能论文摘要和2,000篇工程领域论文摘要中,包括每种语步类型的摘要数量以及占全部摘要的比重。可以看到,标注PUR的摘要数量最多,超过2,300篇的人工智能论文摘要中都有该语步,工程领域论文也类似。两个领域中出现数量第二位的都是MTD. 对比表3和表4中的PUR和MTD语步,在全部摘要中标注数量最多的MTD高于PUR,是因为在一篇摘要中,通常只有一个句子被标注为PUR,但可能有多个句子被标注为MTD.
5 实验及分析
为了检验自动标注模型的效果,本部分基于已构建的语料库开展了语步结构的自动标注实验,分别从人工智能学科领域和工程学科领域中各抽样50篇研究论文摘要作为开放测试集,对比我们的标注模型与大语言模型ChatGPT(GPT-4)和Claude3(Opus)的标注效果。GPT-4和Claude3(Opus)分别是OpenAI和Claude两家竞争公司中目前最强大的模型。实验采用F1值作为评价指标。F1可根据精确率(Precision,P)和召回率(Recall,R),由下面的公式计算得出:
F1=2PRP+R
其中,精确率和召回率的计算方法如下:
P=模型标注每类语步的正确数量模型标注每类语步的总数量
R=模型标注每类语步的正确数量数据集中每类语步的标准数量
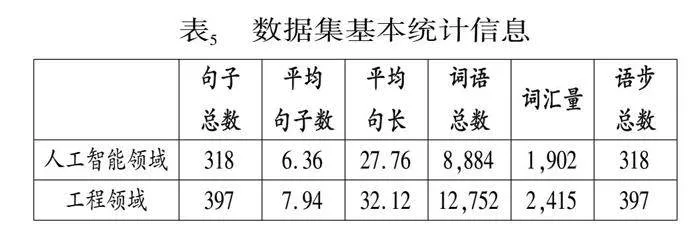
5.1 实验数据及设置
表5是实验数据的基本统计信息。平均句子数和平均句长分别是每篇摘要中平均包含的句子数量和句子中的单词数量。实验在两个大模型的官方网页界面进行。为了尽可能地提高大语言模型识别语步类型的准确性,我们为GPT-4和Claude3设计了下面的提示语(prompt),包括每种语步的含义以及通过示例告诉大模型标注语步的要求和格式等。大模型根据提示语给出反馈以后,正式开始语步识别与标注任务。
Move structures are important semantic and discourse units in research articles (RA). You are a senior expert in the field of EAP and are very good at analyzing the move structures in English RAs from different disciplines. You will analyze the move structures with the pre-defined move types and their labels as follows:
(1) Background (BAC): States the research area and provides any historical, theoretical, or empirical related information. (2) Gap (GAP): Establishes a niche: indicates a gap, adds to what is known, pre-sents positive justification. (3) Purpose (PUR): Indicates purpose, hypothesis, outlines the intention behind the paper. (4) Method (MTD): Provides information on design, procedures, assumptions, approach, data, etc. (5) Result (RST): States main findings or results or what was accomplished. (6) Conclusion (CLN): Summarizes the results or extends results beyond scope of paper. (7) Implication (IMP): Draws inferences which has not been explicitly stated. (8) Contribution (CTN): Points out the theoretical and practical value of the methods used in the articles.
Please identity the most suitable move type and annotate it for [each sentence] in the abstract texts. That is, every complete sentence [must] have a move label. Here is an example: [BAC] Recent neural models for relation extraction with distant supervision alleviate the impact of irrelevant sentences in a bag by learning importance weights for the sentences. [GAP]Efforts thus far have focused on improving extraction accuracy but little is known about their explanability.
5.2 实验结果及分析
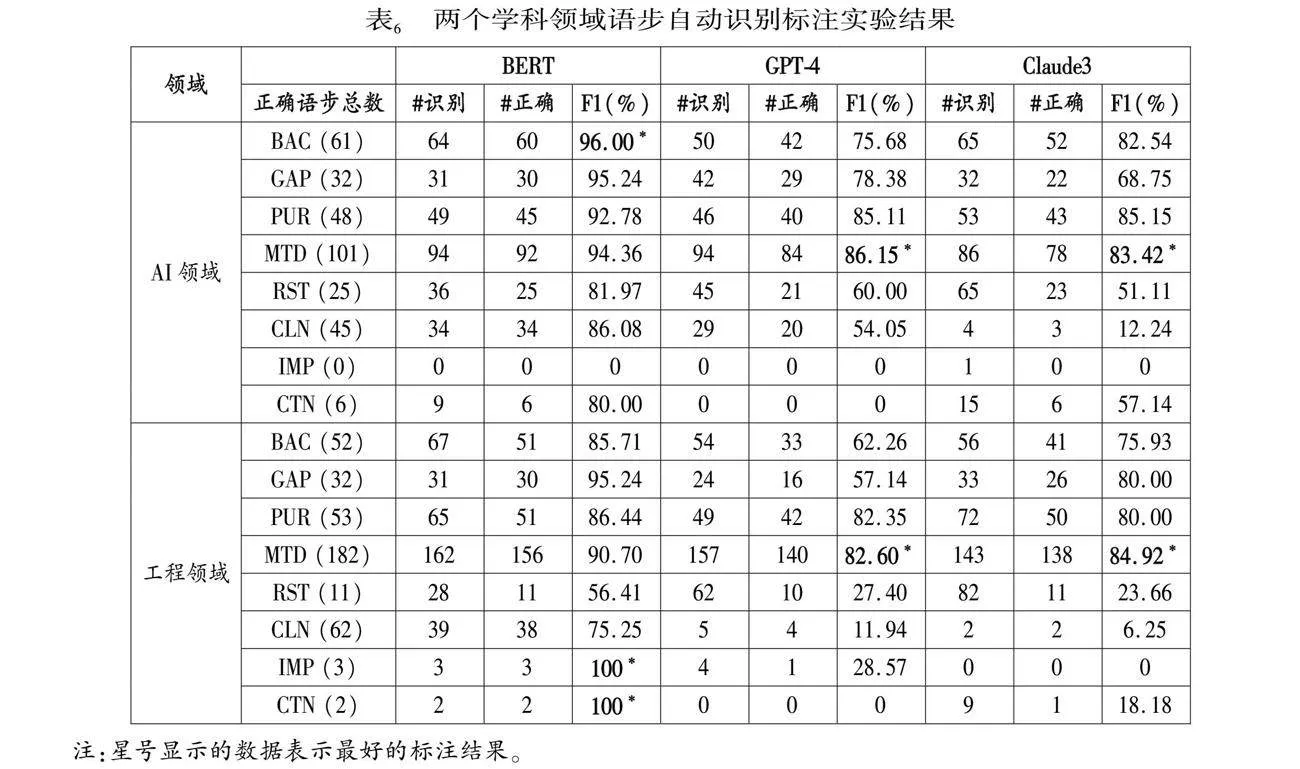
本研究的BERT标注模型与两个大语言模型的语步标注对比结果如表6所示。其中第二列是经人工核实后,数据集中每种语步类型的标准正确数量,其他几列分别是每个模型识别标注出来的语步总数量、正确数量及F1值。
5.2.1 自动标注模型与大语言模型标注效果对比
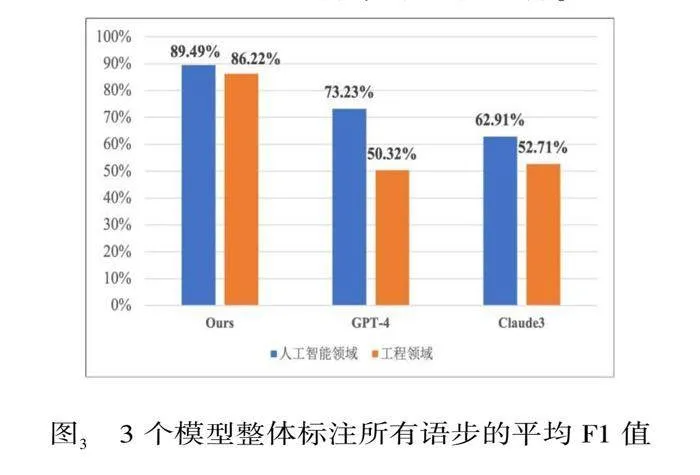
从表6中可以看到,在当前实验中,本研究的标注模型在两个领域的语步识别F1指标均明显地远高于两个大语言模型的结果,而且标注每种语步类型的F1也相对更加稳定。在人工智能领域和工程领域,识别效果最好的F1值均在95%以上,而GPT-4和Claude3的最高F1值仅接近85%。从图3显示的8种类型的语步整体识别的平均F1来看,也分别达到89%和86%(图3);GPT-4和Claude3的整体平均F1则更低。
但值得说明的是,并不是所有语步的识别效果都优于大模型。通过具体分析3个模型的识别结果,也发现在某些摘要文本的语步识别中存在我们的模型识别错误、而大模型识别正确的情况。例如下面的实例:
⑥ [PUR]In this paper, we propose a novel
bipartite flat-graph network (BiFlaG) for nested named entity recognition (NER), which contains two subgraph modules: a flat NER module for outermost entities and a graph module for all the entities located in inner layers. [MTD]Bidirectional LSTM (BiLSTM) and graph convolutional network (GCN) are adopted to jointly learn flat entities and their inner dependencies.
在例⑥中,第二个句子出现在PUR语步之后,而且句中存在单词adopted,是比较明显的方法语步的信号。这个语步被我们的模型错误识别为BAC,但被GPT-4正确地识别为MTD. 从中可以看出GPT对于文本语义的理解能力。
5.2.2" 不同学科领域的语步标注效果对比
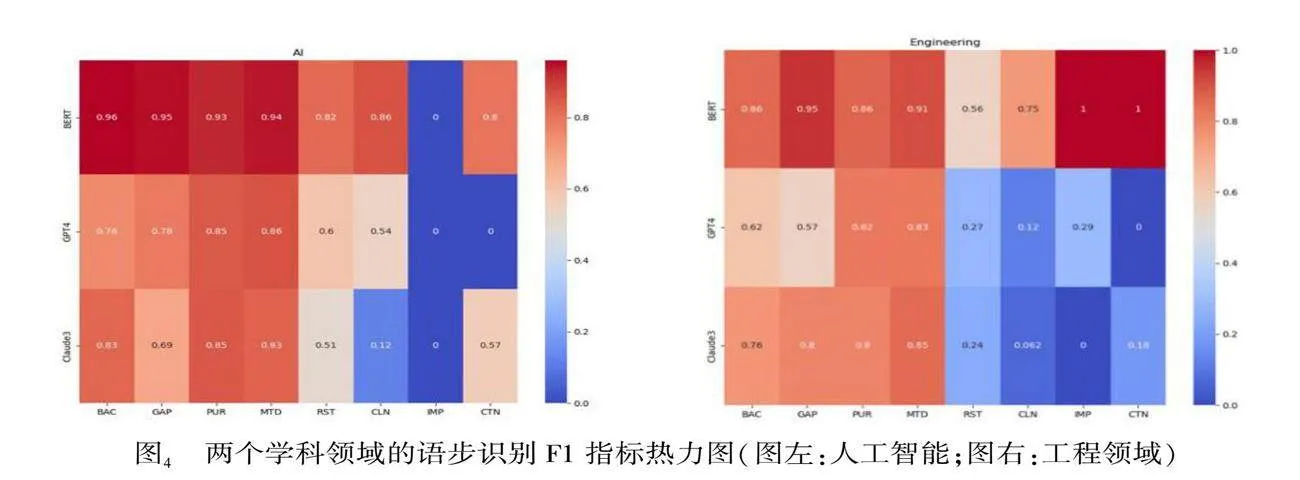
图4是根据表6绘制的语步识别F1指标热力图。3个模型在AI领域的语步识别效果均明显优于工程领域。特别是工程领域,蓝色部分显示的RST,CLN和CTN语步的识别效果都比较差。
具体从两个领域来看,领域内各类语步的识别情况存在较大差异。在AI领域中,3个模型识别效果最好的语步类型均不相同,分别是BAC(我们的模型)、MTD(GPT-4)和PUR(Claude3);在工程领域,我们的模型除了在IMP和CTN两个语步识别完全正确以外,识别最好的是GAP语步,其次是MTD,GPT4和Claude3则均在MTD上识别最好。这也再次说明MTD语步在不同领域论文摘要中的重要性以及在语句表达上有其特殊之处,比其他语步更容易被识别。
5.2.3 大语言模型之间的语步标注效果对比
接下来我们对比两个大模型的标注效果。图4显示,GPT-4在AI领域的识别效果明显好于Claude3,平均F1值比Claude3高10个百分点;而在工程领域,Claude3的效果略好于GPT-4,但二者都在50%附近,远低于AI领域的平均F1,主要是受到RST,CLN和CTN语步的影响。由此可见,整体上AI领域的摘要语步类型特征更加明显,更容易被识别出来。从摘要写作的规范性和可读性来看,可以认为AI领域论文摘要写作的规范性和可读性整体好于工程领域。
尽管两个大语言模型的识别效果在两个学科领域中存在差异,但二者的识别表现也具有一定的趋同性。例如:在两个领域中,结论语步(CLN)的识别数量及准确识别数量均远远低于标准的正确数量,甚至出现个位数的识别量,导致F1值急剧下降。我们试图跟GPT-4了解CLN识别过少的原因,它给出的解释是“CLN通常出现在章节或文档的末尾,如果提供的文本大部分来自文档的引言或方法部分,那么自然会导致CLN的实例减少”。 换句话说,由于我们在提示语中明确提到识别的是摘要文本中的语步,因此GPT-4认为摘要中不应该出现过多的CLN语步。
与CLN相反,两个领域中结果语步(RST)的识别数量则均超过标准正确数量,也就是把大量原本不属于RST的语步识别为RST. 这种情况在我们的识别模型中也很普遍。例如下面的实例:
⑦ [MTD]We propose a simple, effective transition-based model with generic neural encoding for discontinuous NER. [CLN]Through extensive experiments on three biomedical data sets, we show that our model can effectively recognize disconti-nuous mentions without sacrificing the accuracy on continuous mentions.
在例⑦中,第二个句子的语步都被两个大模型识别为RST,但实际应该是CLN. 因为如果句子中存在诸如show,demonstrate等单词,一般就能比较明确地判断为CLN.
我们分析了GPT和Claude识别效果不稳定的原因,认为可能主要表现在两个方面:第一,实验只使用了网页版的大模型聊天模式,并未像专门训练我们的BERT模型那样有针对性地训练大模型,因此大模型在一定程度上无法充分学习到摘要文本中的语义信息。第二,我们在提示语中也没有为大模型提供太多的提示信息,包括帮助识别某种语步结构的关键信息等,例如,show,demonstrate 等词语可以快速识别为CLN. 我们相信如果进一步优化prompt,将会提升大语言模型的语步识别效果。
6 结束语
本文面向英语科技论文写作,借助自然语言处理前沿技术构建了一个涵盖多个学科领域、较大规模的论文摘要语步结构标注语料库,同时检验了大语言模型在语步结构识别上的性能与效果。主要通过人工标注与自动标注+人工校对的方式构建,采用了基于BERT的语步自动识别与标注模型,能够保证语料库建设的规模和质量。在语步自动识别实验中,本文的模型在不同学科领域中的各类语步类型识别效果均优于大语言模型GPT4和Claude3的识别效果,体现了所构建的语料库和自动识别模型的有效性和价值。实验结果呈现出来的几个方面的结论对于研究者深入认识不同学科领域的语步结构和大模型的语义理解能力等也具有重要的启发作用。
该语料库能够为科技论文信息抽取、科技论文智能辅助写作和批改等自然语言处理任务以及跨学科领域语步分析等外语教学和研究提供必要的数据资源支持,帮助二语学习者更好地理解论文语步结构,提升写作能力以及国际学术交流能力等,同时通过语言智能技术赋能外语场景,有助于推动外语教育数字化转型,进一步实现智慧外语教育的目标。
在未来的研究中,我们将在现有工作成果的基础上继续标注更多学科领域的摘要文本语步结构,持续扩大语料库的规模。我们同时也考虑标注科技论文中的其他组成部分,例如引言和方法部分,目标是建设大规模、多领域、多元化的语步数据资源,为开展科技论文写作智能批改等后续研究提供坚实基础。
*刘芳为本文的通讯作者。
参考文献
丁良萍 张智雄 刘 欢. 影响支持向量机模型语步自动识别效果的因素研究[J]. 数据分析与知识发现, 2019(3).‖Ding, L.-P., Zhang, Z.-X., Liu, H. Factors Affecting Rhetorical Move Recognition with SVM Model[J]. Data Analysis and Knowledge Discovery, 2019(3).
杜新玉 李 宁. 中文学术论文全文语步识别研究[J]. 数据分析与知识发现, 2024(8).‖Du, X.-Y., Li, N. Identifying Moves in Full-text Chinese Academic Papers[J]. Data Analysis and Knowledge Discovery, 2024(8).
黄 红 陈 冲 张婧莹. 科技文献内容语义识别研究综述[J]. 情报学报, 2022(1).‖Huang, H., Chen, C., Zhang, J.-Y." Review on Identifying the Semantics of Scientific Literature Content[J]. Journal of the China Society for Scientific and Technical Information, 2022(1).
刘 霞. 英语学术论文摘要语步结构自动识别模型的构建[D]. 北京外国语大学博士学位论文, 2016.‖Liu, X." Constructing a Model for the Automatic Identification of Move Structure in English Research Articles Abstracts[D]. Beijing Foreign Studies University, 2016.
王东波 高瑞卿 叶文豪 周 鑫 朱丹浩. 不同特征下的学术文本结构功能自动识别研究[J]. 情报学报, 2018(37).‖Wang, D.-B., Gao, R.-Q., Ye, W.-H., Zhou, X., Zhu, D.-H. Research on the Structure Re-cognition of Academic Texts Under Different Characteristics[J]. Journal of the China Society for Scientific and Technical Information, 2018(37).
王 末 崔运鹏 陈 丽 李 欢. 基于深度学习的学术论文语步结构分类方法研究[J]. 数据分析与知识发现, 2020(4).‖Wang," M., Cui, Y.-P., Chen, L.," Li, H. A Deep Learning-based Method of Argumentative" Zoning for Research Articles[J]. Data Analysis and Knowledge Discovery, 2020(4).
杨延宁 邹 航. 基于语步结构的学术论文语篇构式研究[J]. 外语教学理论与实践, 2023(2).‖Yang, Y.-N.," Zou, H. A Study of" Move-based Academic Discourse Construction[J]. Foreign Language Learning Theory and Practice, 2023(2).
张 鑫 许海云 杨 宁 方 肖 赵 爽. 有限样本下的科技文献语步识别方法探讨[J]. 图书情报工作, 2024(8).‖Zhang, X., Xu, H.-Y., Yang, N., Fang, X., Zhao, S. Discussion of Moves Recognition of Scientific Documents Under Limited Samples[J]. Library and Information Service, 2024(8).
Alliheedi, M., Mercer, R., Cohen, R. Annotation of" Rheto-rical Moves in Biochemistry Articles[R]. Proceedings of the 6th Workshop on Argument Mining, 2019.
Alsharif, M. Rhetorical Move Structure in Business Management Research Article Introductions[J]. Journal of" Language" and Linguistic Studies, 2023(4).
Cotos," E., Huffman, S., Link, S." A Move/Step Model for Methods Sections: Demonstrating Rigour and Credibility[J]. English for Specific Purposes, 2017(6).
Devlin, J., Chang," M., Lee, K., Toutanova, K. Bert: Pre-training of" Deep Bidirectional Transformers for Language Understanding[R]. Proceedings of NAACL-HLT, 2019.
Hyland," K." Disciplinary Discourses: Social Interactions in Academic Writing[M]. London: Longman, 2000.
Hyland, K. As Can Be Seen: Lexical Bundles and Disciplinary Variation[J]. English for Specific Purposes, 2008(1).
Lin, J., Li, H., Feng, C., et al. Move Structure Recognition in Scientific Papers with Saliency Attribution[R]. Proceedings of China Conference on Knowledge Graph and Semantic Computing, 2023.
Lu, X., Yoon, J., Kisselev, O. Matching Phrase-frames to Rhetorical Moves in Social Science Research Article Introductions[J]. English for Specific Purposes, 2021(1).
Moreno, A., Swales, J. Strengthening Move Analysis Met-hodology Towards Bridging the Function-form Gap[J]. English for Specific Purposes, 2018(5).
Swales, J. Genre Analysis: English in Academic and Research Settings[M]. Cambridge: Cambridge University Press, 1990.
Swales, J." Research Genres: Explorations and Applications[M]. Cambridge: Cambridge University Press, 2004.
Swales, J." The Futures of EAP Genre Studies: A Personal Viewpoint[J]. Journal of English for Academic Purposes, 2019(8).
Swales, J., Feak, C." Abstracts and the Writing of Abstracts[M]. London: University of Michigan Press, 2009.
Teufel, S. The Structure of Scientific Articles: Applications to Citation Indexing and Summarization[M]. Stanford: CSLI Publications, 2010.
Teufel, S., Carletta, J., Moens, M. An Annotation Scheme for Discourse-level Argumentation in Research Articles[R]. Ninth Conference of the European Chapter of the Association for Computational Linguistics, 1999.
Teufel, S., Siddharthan, A., Batchelor, C. Towards Domain-Independent Argumentative Zoning: Evidence from Chemistry and Computational Linguistics[R]. Procee-dings of the 2009 Conference on Empirical Methods in Natural Language Processing, 2009.
Viera, R. Rhetorical Move Structure in Abstracts of" Research Articles Published in Ecuadorian and American English-Speaking Contexts[J]. Arab World English Journal (AWEJ), 2020(10).
定稿日期:2024-12-10【责任编辑 谢 群】
