从句子图到篇章图
2025-01-26张艺璇李斌许智星




提 要:篇章级共指关系是语言学和计算语言学的研究难点之一。本文在梳理共指理论研究与趋势的基础上,回顾共指语料库的构建与自动解析方法,指出共指语料的构建主要存在以下两个问题:共指关系的标注较为粗疏,也基本不考虑与句子语义结构本身的关系。本文在句子级语义标注体系(中文抽象语义表示)的基础上,设计篇章共指的标注体系,以“概念同一性”为基本原则,从词形的异同和概念的表述角度区分9种篇章共指关系,标注了500个篇章的共指信息。与已完整标注的52种句内语义关系相结合,构建出带有篇章共指信息的篇章抽象语义图库。该语料库选自CTB新闻语料,体裁涵盖经济、体育及生活类,规模为6237句,16万词例。该语料库的构建为篇章级语义分析提供了新框架与数据资源。
关键词:篇章共指;抽象语义表示;概念同一性;篇章语义结构;语料库;中文信息处理
中图分类号:H08 """"文献标识码:A """"文章编号:1000-0100(2025)01-0019-10
DOI编码:10.16263/j.cnki.23-1071/h.2025.01.003
From Sentence Graphs to Discourse Graphs: Designing a Discourse-level
Coreference Annotation Framework" Based on Abstract Meaning Representation
Zhang Yi-xuan Li Bin Xu Zhi-xing
(School of" Chinese Language and Literature, Nanjing Normal University, Nanjing 210097, China;
Center for Language Big Data and Computational Humanities, Nanjing Normal University, Nanjing 210097, China)
Discourse-level coreference is a challenging research area in both linguistics and computational linguistics. This paper reviews coreference theories and their development trends, with a focus on the construction of coreference corpus and automatic resolution methods. We pointed out two main issues in the construction of coreference corpus: the annotation of coreference relationships tends to be coarse-grained, and the relationships between coreference and sentence-level semantic structures are largely neglected. To address these gaps, this study designs a discourse-level coreference annotation framework based on the sentence-level semantic annotation framework Chinese Abstract Meaning Representation. Guided by the principle of" “conceptual identity”, the framework categorizes nine types of discourse-level coreference relations from the perspectives of word type and concept consistency. Coreference information was annotated for 500 texts. By integrating 52 inner-sentence semantic relations already annotated, the study constructs a discourse abstract meaning graph enriched with discourse-level coreference information. The corpus is derived from the Chinese Treebank news corpus, covering economics, sports, and daily life, with a total size of 6,237 sentences and 163,227 word tokens. This corpus provides a novel framework and valuable data resources for discourse-level semantic analysis.
Key words:discourse coreference; abstract meaning representation; conceptual consistency; discourse semantic structure; corpus; Chinese information processing
1 引言
共指(Coreference)指在同一个句子和篇章中相同概念由不同或相同的词语实例所指代的现象。共指不仅表现为语法上的替代关系或语义上的同指关系,还充当着话题转换的衔接手段,对挖掘篇章概念转移、推动语言教学和自然语言理解有重要意义,目前已成为理论语言学和计算语言学关注的热点问题之一。
鉴于研究目的与分析方法的差异,目前理论语言学和计算语言学在指代领域的术语使用有所区别。理论语言学常使用“回指”(Anaphora)来表示指代现象,广义的回指可分为直接回指和间接回指两类(Ariel 1990)。直接回指指两个语言成分之间的关系,对其中一个成分的解释,取决于对另一个成分的解释(Huang 1984);间接回指指回指语和先行语之间没有明显的指代关系,而需要经过语用推理才能建立指称关系(Erkü, Gundel 1987)。在计算语言学中,与“直接回指”相对应的是“共指”,与“间接回指”相对应的是“桥接关系”(Bridging)。但间接回指(桥接关系)由于其复杂性与模糊性,被学界研究长期排除在外,故相关研究发展缓慢。尽管理论语言学界已总结出常见的间接共指类别(Vieira, Poesio 2000;王军 2004,2013),计算语言学界也构建了一系列桥接关系语料库,如ISNotes(Mar-kert et al. 2012)、BASHI(Röesiger" 2018)、ARRAU(Poesio, Artstein 2008;Uryupina et al. 2016)和 SciCorp(Röesiger 2016)等。但并未对该现象的界定和标注方法达成一致,故本文仅讨论“直接回指”的共指标注问题。
计算语言学界对共指标注与自动消解的初步尝试是MUC(Message Understanding Conference,Chinchor 1998),但直到OntoNotes(Weischedel et al. 2013)的建构,该领域才迎来飞跃,涌现出大量共指语料库。OntoNotes打破历来共指仅标注名词、代词及其短语的限制,将标注范围扩大到动词、数量短语、时间短语,甚至是货币金额。不过,OntoNotes仅使用相同的共指编号来连结先行词与共指词,并未深入分析先行词与共指词之间的具体共指关系,且尚未结合句子内部的语义关系,无法形成篇章级语义关系的整体表示。
因此,本文将在句子级语义表示体系——中文抽象语义表示(Chinese Abstract Meaning Representation,简称CAMR)的基础之上构建篇章共指标注体系(Li et al. 2019)。CAMR是句子级语义标注的新体系,涵盖5种核心语义角色关系和47种非核心语义角色关系。该体系基于框架语义学和依存语法理论,可标注出整句的语义结构。目前,CAMR已经建设了规模为2万句的新闻语义库、1562句小王子语义库,在自动分析精度上已经取得0.81的成绩(Xu et al. 2023)。为此,本文将在CAMR的基础上,进一步设计和标注出跨句的共指关系,不仅可以完成篇章级共指关系的标注,更可以结合句子内部的语义关系,有效挖掘共指词所担任的语义角色,以及共指词之间的语义关系,从而形成篇章级语义表示。本体系以形式相同或不同的词语实例指称相同概念的“概念同一性”为共指标注的基本原则,从词语的形式差异和概念一致性角度区分9种共指关系。句内语义关系与篇章共指关系可与先行词、共指词一同搭建篇章共指语义图,以揭示篇章的概念转移,从语义角度归纳共指规律。基于本体系所构建的500篇共指语料库,可为共指解析提供数据支持。
2 直接回指的理论研究
已有大量学者从句法、认知、功能和篇章等角度探索回指理论,其中影响深远的是认知角度的可及性理论(Ariel 1990)与篇章角度的话题延续性模式(Givón" 1983)。在两大理论提出的“可及性规律”与“话题延续性量表”的基础之上,学界逐步确定了频次、位置、间隔距离、语篇结构、干扰数量和句法成分等回指计量指标,但这些指标大都是对表层信息的统计,尚未从较深的语义层次上标注和统计。
纵观回指计量研究的发展历程,研究焦点主要有三大趋势变化:其一,逐渐从名词和代词等具体实体的标注与计量转向概述回指等抽象类别(寇鑫 徐坤宇" 2023)。其二,逐渐跳出专研某种特定回指类型的局限,将回指现象放入句法、句式等宏观视野中分析。如冉晨(2024)分析数量名回指语的指称性质与回指确认方式。其三,研究视角逐渐从本体研究扩展到语言教学与应用中。如杨永生和肖奚强(2020)基于回指确认考察韩国学生汉语“这/那”句的习得情况。
3 共指的计算资源构建与自动解析研究
计算语言学借鉴现有理论标注名词、代词、零形式等常见体词共指,并进一步探索动词等谓词共指,一定程度上推动了共指研究。但谓词共指由于存在意义实虚难以界定等问题,仍处于探索阶段,体词共指的标注仍为研究主流。这些语料库的标注信息相对粗疏,还需要深入地标注与分析。
3.1 共指相关的语料库构建
面向计算建模的共指语料库可分为两类:一类是以OntoNotes为代表的共指语料库,一类是以AMR为代表的包含共指信息的句子语义语料库(Banarescu et al. 2013)。前者细致标注共指现象,却忽略了整句的语义表示;后者标注了整个句子的语义关系,对共指现象的标注却仍待深化。这两类语料库只标注了表层的共指关系,没有对共指链中共指词与先行词之间的具体关系作进一步分析。
3.1.1 共指语料库
OntoNotes(Weischedel et al. 2013)语料库是目前共指评测认可度最高的数据集。其标注规范成为众多共指标注体系的范例,使共指语料库迈向多语言数据时代。尽管语料库的数量、规模以及语种均不断扩大,但标注内容和标注方法变化不大。该类语料库除早期共指语料库MUC、ACE(Automatic Content Extraction,Doddington et al. 2004)及OntoNotes系列语料库之外,还有一些标注单一类型的共指语料库,如汉语零指代语料库(孔芳等 2021)、法汉指称链条平行语料库(胡霄钦 王秀丽 2021)。
MUC开创了语料库的共指标注体系。尽管其标签分类较为简单,但研究学者已逐渐认识到共指的复杂性,并有了灵活表示共指词的倾向性(如设置“MIN”标签以表示包含在整词之内的部分字符串)。但其细则也存在值得商榷之处,如将人物与其头衔等职位标注为共指关系、不补充标注零形式等问题。ACE对关系作细致标注,其中在MUC6的基础之上进一步标注了共指关系。其语料不再局限于英语,而是扩展至多语言资源的构建,ACE也是最早针对中文指代消解的国际评测语料资源。
OntoNotes的构建打破MUC、ACE的局限,实现共指标注的变革。该体系取消对共指标注的限制,除名词和代词外,还可标注动词、数字、时间等信息,对指代消解有新的推进。在共指层主要标注两类信息,即同一性(IDENT)和同位语(APPOS)。同一性共指用于指代共指,意味着代词、名词性和特定所指对象的命名提及之间的联系,不包括一般的、未指定的或抽象实体。同位语逻辑上代表属性,因此被单独处理。自OntoNotes问世之后,主要有3大研究趋势:其一,在OntoNotes标注规范的基础之上构建许多大型语料库。如Ghaddar和Langlais(2016)继承OntoNotes标注方法,以维基百科为语料构建了WikiCoref语料库;Chen等(2018)在OntoNotes规范的基础之上改良并构建了目前最大规模的PreCo英语共指语料库;Poesio等(2019)基于游戏化众包的方法构建了共指语料库。其二,近三年的共指资源扩大到英语以外的语言,以实现跨语言共指解析。这些语料库包括俄语共指语料库RuCoCo(Dobrovolskii et al. 2022)、涵盖英法德葡4种语言的多语言共指语料库ParCorFull2.0(Lapshinova-Koltunski et al. 2022)等。基于UD(Universal Dependencies)构建的多语言句子依存和共指消解的语料库CorefUD(Nedoluzhko, Ferreira 2022)。其三,共指研究从单一篇章逐渐扩展为多篇章。如荷兰语跨文本事件共指解析大型数据集(Langhe et al. 2023)等数据资源。
这类语料库专注于共指标注与解析,极大推动共指研究的发展。但它们仅将词汇语义纳入标注范围,未结合句子自身的语义结构来探析共指的概念转移,也没有深入分析常见的共指关系。
3.1.2 包含共指信息的语料库
以布拉格树库PDT(Prague Dependency Treebank,Mikulová 2006)、统一语义表示UMR(Uniform Meaning Representation,Van Gysel et al. 2021)和多句抽象语义表示MS-AMR(Multi-Sentence AMR,O’Gorman et al. 2018)为代表的语料库是句子级语义标注的语料库,自身带有句子级的共指信息。
PDT中的共指信息有3种,即语法共指、文本共指和特殊类型共指,主要标注代词、动词、省略、概述共指等共指信息。UMR是建立在AMR基础之上、具有跨语言特性的篇章级语义表示方法,在共指方面采用关系三元组的形式标注实体共指和事件共指,另外还标注概念之间的子集(Subset)关系。MS-AMR参考OntoNotes的标注方式在句子级AMR基础之上扩展句间共指信息。该体系的共指信息参考OntoNotes的标注方法,标注了部分—整体、组织—成员两类桥接关系。这类语料库长于结构化的句子语义分析,一定程度上弥补了共指语料库缺乏整句语义信息的不足,但仍未对共指关系做出细致分类和深入分析。
3.2 共指关系的自动标注
从数学角度而言,共指关系实质是一种等价关系,因此消解过程就是等价类划分的过程(宋洋 王厚峰 2015)。随着算力不断提升,共指解析已经从基于规则的方法发展到基于机器学习的方法。基于规则特征的泛化能力较差,理解和实现比较简单(郎君等 2007),基于机器学习的方法开始引入开放知识作为额外特征,改善模型效果高度依赖特征工程的弊端。近年来采用深度学习算法,如多层感知器、循环神经网络方法、基于知识的方法等(Liu et al. 2023),逐渐突破人工标注语料库规模的限制,大大增强模型的深层语义学习能力和泛化性能(陈远哲等 2019)。
Liu等(2023)总结出共指自动标注的5点挑战及发展方向,即:下游任务缺乏带有共指标注的数据集;缺乏符号特征与子符号特征的组合;需结合现有语言研究及认知直觉;当前模型需压缩所用资源以实现多任务学习;仍需超大规模语言模型的支撑。总之,尽管已有大量研究成果为数据标注和模型设计奠定了理论基础,但这些语言和认知发现却很少被纳入基于深度学习的共指解析模型中,未来可结合符号特征(如语义特征和知识表示)和词向量等方法(Mao et al. 2018;Mao et al. 2022),以解决共指数据稀疏问题,提高共指消解的精度。因此,亟需构建结合句内语义关系和篇章共指关系的标注框架和语言资源。
4 篇章级共指标注体系
本文基于句子级语义标注体系(中文抽象语义表示)构建篇章共指标注体系,涵盖句子语义信息与篇章共指信息,为共指消解提供新路径。
4.1 句子级CAMR的标注体系
Abstract Meaning Representation(AMR)是一种句子级语义标注体系,采用单根有向无环图的表示方法,图中节点表示概念,边表示概念之间的关系(Banarescu et al. 2013)。AMR忽略语义较虚的成分(如冠词、单复数、时态等等)和形态变化,不拘泥于原句词语,从原句中抽象出概念,允许对其进行增添、删减和改动等操作以便表示语义关系。Li等(Li et al. 2019)在AMR的基础之上结合汉语的语言特点继承并发展出CAMR(Chinese AMR)。其中,共包括5种核心语义角色关系(arg0-arg4)、47种非核心语义角色关系。
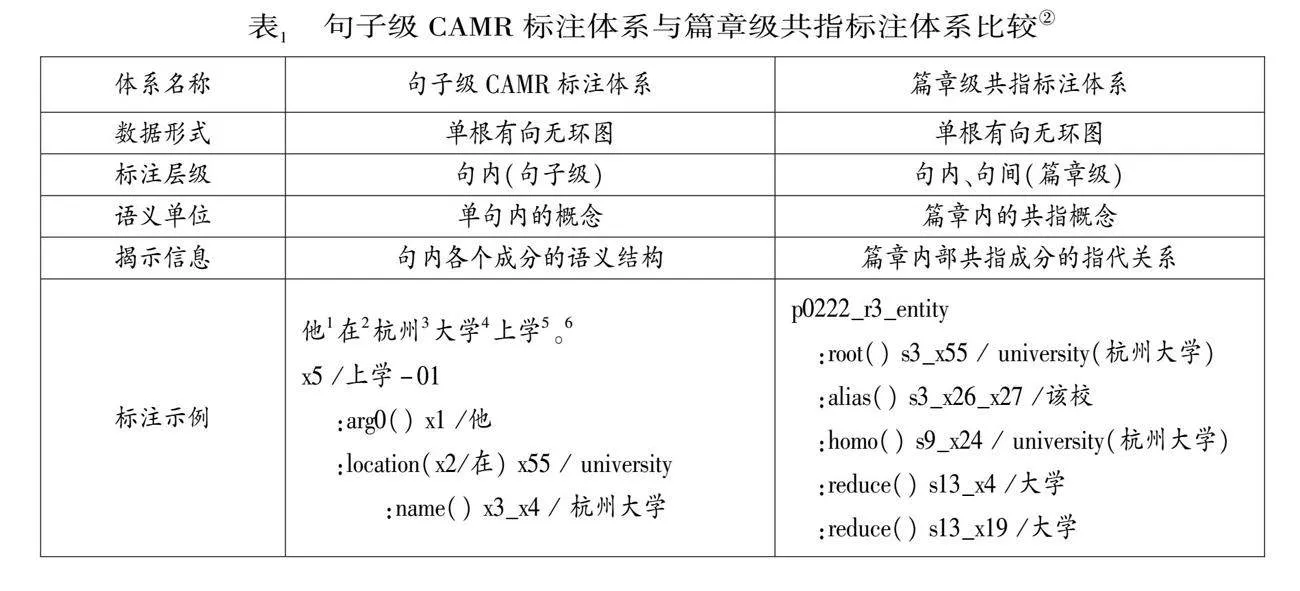
句子级CAMR已经提供了句子内部的语义结构关系,特别是已经标注了句子内部的共指关系,是篇章共指标注体系的构建基础。篇章级共指标注则提供了不同句子之间概念同指的关系,有利于在复杂的语言表达中确定先行词与共指词①,提供二者具体的共指关系。表1为句子级CAMR标注体系和篇章级共指标注体系比较。
4.2 共指标注原则
在前人研究中,共指大多被定义为“话语中表示相同特定实体或事件的语言表达”,并作为语料库的基本标注原则。但事实上,许多共指语料库除标注指代相同概念的情况外,还会标注实体—属性、整体—部分等桥接关系,导致共指关系定义粗疏、桥接关系覆盖面窄等问题。因此,为深入分析共指关系,本体系将以“概念同一性”为基本原则标注共指现象,暂不将桥接关系考虑在内。
4.2.1 概念同一性
“概念同一性”指不同或相同的词语实例在同一篇章中指代相同的概念。一般而言,相同的词例或词语实例更倾向于指代相同概念,但也存在指代不同概念的例外情况,典型代表便是代词、普通名词等。而不同的词语实例也可能指代相同的概念。本体系遵守“概念同一性”原则,只标注指代相同概念的词语实例。如表2文本中与“福利院”有关的词语共出现7次,有6次(位于s3 、s6、s7、s8、s8、s11)指代“杭州市儿童福利院(位于s3)”,构成共指链2;有一次(位于s4)指国内的福利院,在本文中与“中国孤儿院(位于s1)”形成共指关系,构成共指链1。
4.2.2 共指词、共指链可嵌套
由于语言递归性,词语嵌套是语言表达的常用方式,因此极易出现共指词或共指链嵌套的情况。当多个共指链的每一个共指词均存在嵌套现象时,则这些共指链存在嵌套现象。表3的例子共出现两条共指链,下标相同即为同一条共指链。s17中的“其名”即存在共指词的嵌套现象:“其”指代“小海龟”,为共指链2的共指词;“其名”指代“卡洛塔”,为共指链1的共指词。
4.2.3 区分概念同一性和概念相关性
一般而言,同一篇章提及的概念大多有相同或相关性。这些大量存在的、指代不同但关系密切的概念极易对共指链的标注造成混淆。因此,本体系仅标注基于概念同一性原则的共指现象。如表3中存在的两条共指链,一条是实体链(“小海龟”链),一条是实体名称链(“卡洛塔”链),即为指代不同但关系密切的共指链。
4.3 共指关系类型
本体系依据先行词和共指词的变化设计了9个类别标签,分别为先行词(:root)、同形(:homo)、增加(:add)、删减(:reduce)、替换(:alias)、零形式(:zero)、代词(:pro)、阐述(:illustrate)和概述(:encap)(见表4)。
4.4 语义关系类型
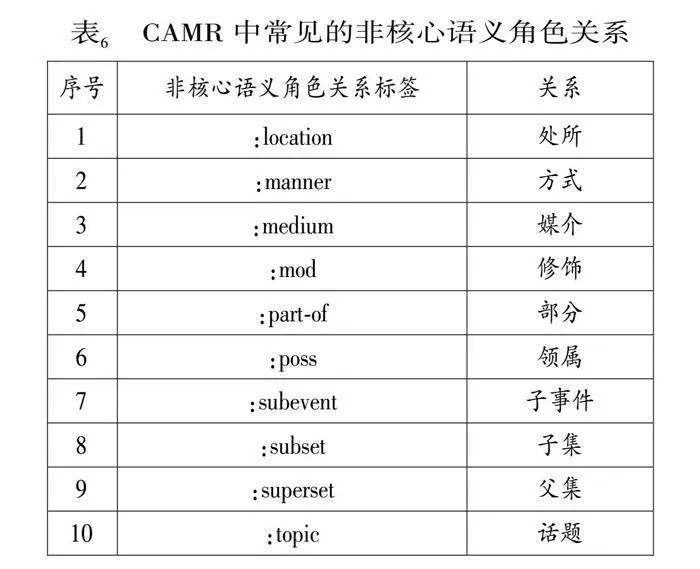
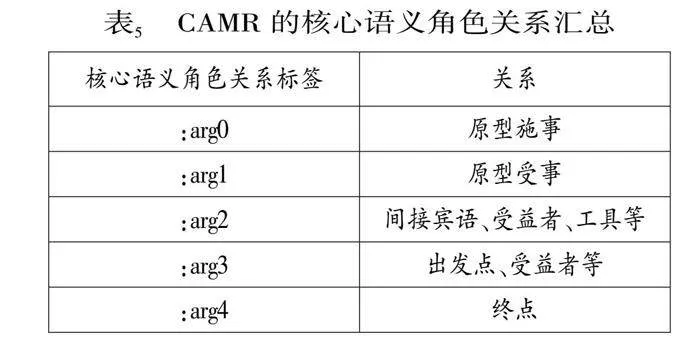
本体系继承了句子级CAMR的句内语义关系,以探析先行词、共指词在句中担任的语义角色。句内语义关系也可以和篇章共指关系相互连结,成为篇章共指语义图的基本骨架。CAMR共有5种核心语义角色关系和47种非核心语义角色关系。核心语义角色关系沿用OntoNotes体系的核心语义角色关系,标签及其代表关系如表5所示。CAMR共有47种非核心语义关系,理论上均可在共指标注中使用,但常见的非核心语义角色关系主要有10种(见表6)。
5.1 语料选择
我们从CAMR v2.0语料中选取500篇文本进行共指标注,该语料库涵盖经济、体育及生活类,在宾州中文树库(Chinese Treebank,简称CTB)的编号为chtb0001-chtb0659(chtb语料部分编号非连续,chtb0045、chtb0205因篇幅过短不予标注),经整理后共6,237句,163,227词。由于该语料库已经标注了句法信息和CAMR语义信息,可为共指标注与后期的计量研究提供便利。主要是因为,其一,句法结构信息为共指词提供精确结构定位;其二,CAMR在CTB基础之上提供语义结构信息,可揭示共指词语义上的变化规律。
5.2 规范制定与标注过程
标注工作分为3个阶段。(1)观察语料阶段。该阶段的主要工作是分析大量生语料,观察并标注出篇章中具有概念同一性的语言单位,在充分考虑语料质量与标注信息可操作性的基础之上,形成初步的标注规范。(2)预标注阶段。该阶段将通过实践确认标注者对规范的理解,同时检验规范的通用性与可操作性,并在标注过程中及时调整规范,得到最终的标注规范。(3)正式标注阶段。经过前期的观察与标注工作,正式标注阶段采用了“编程粗提取+人工细校对”的方式,以相同词形为依据,在CAMR v2.0语料中提取潜在共指词,建构粗糙的依存三元组,然后人工调整修改,确保共指链标注基本无遗漏。最终形成完整的抽象语义表示篇章共指语料库。
5.3 计量指标与计量信息
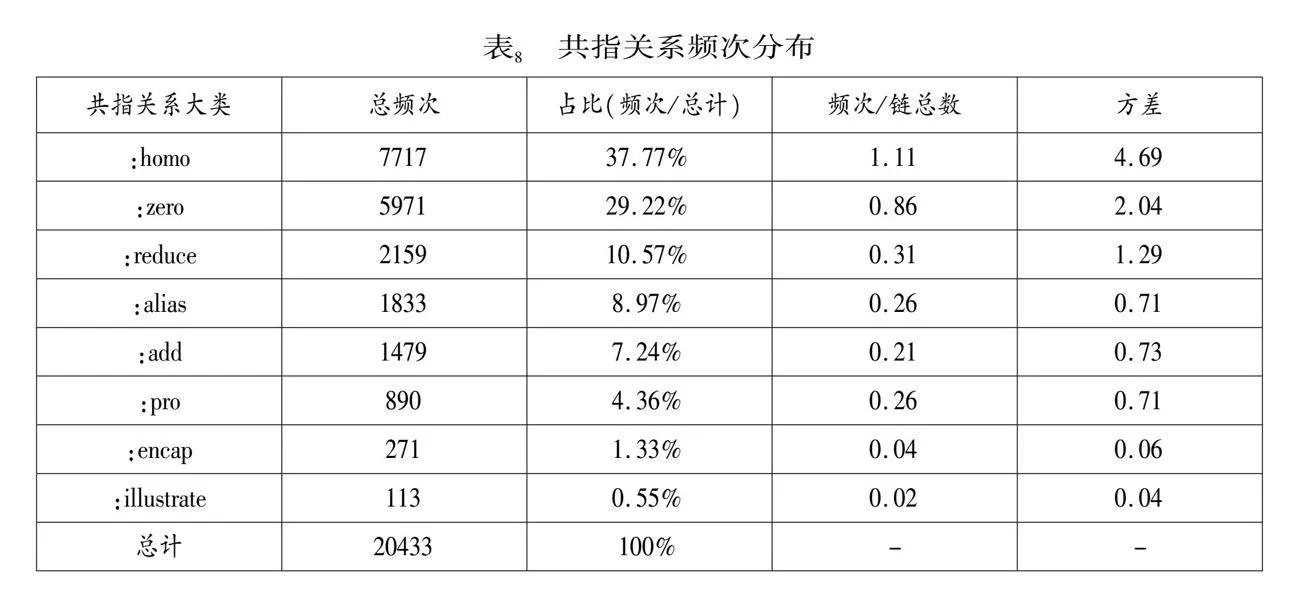
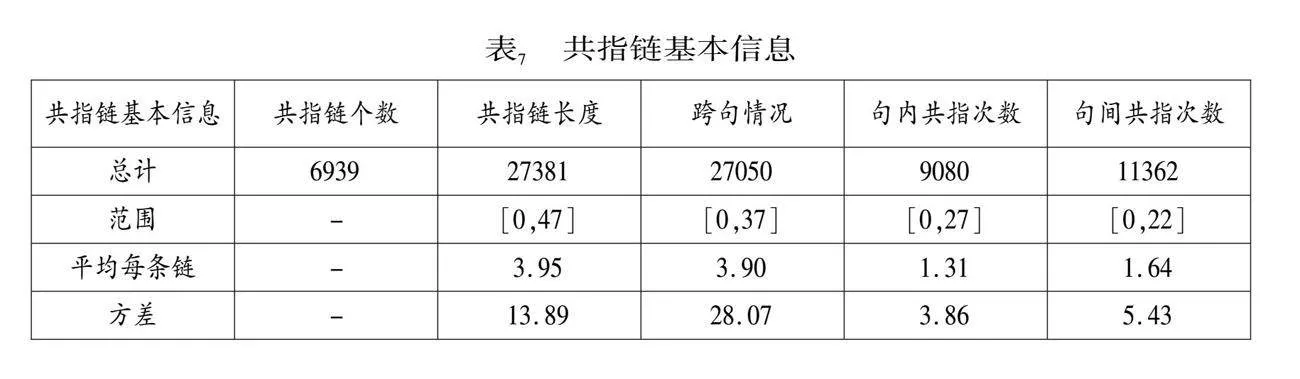
在这500篇文本中,共标注6,939条共指链。每篇平均13.88条共指链。共指链基本信息如表7所示。通过观察表7的方差数据可知,共指链的长度、跨句情况等信息差异极大,分布不等且不均。
各共指关系的出现频次见表8(已按频次进行降序排列),由于“:root”代表根节点,在每条链中均出现1次,因此不列入统计。观察表8可知:首先,在共指关系中,共指词与先行词同形的情况占比最高,共出现7,717次,但其方差也最高(4.69),说明这种共指关系出现次数最多,但在共指链中变化波动最大。其次,“:zero”关系次之,共出现5,971次,这与汉语多“无主句”的语言特点有关。再次“:reduce”关系排名第三,这可能与新闻语料的语言风格相关。即在论述某一概念时,新闻通常在首次提及时便提供最为详细的信息,在后续提及中会逐渐压缩修饰语;由于新闻语料论证严密的特点,该语料库中代词共指仅占4.36%。
6 篇章共指语义图构建示例
本体系构建的篇章共指语义图为单根有向无环图,图中节点为篇章中所出现的共指概念,边表示共指概念之间的关系,即横向的句内语义关系和纵向的篇章共指关系。本文将从横纵角度探讨篇章共指语义图结构,以揭示篇章结构中共指链的动态变化。
我们选用CTB8.0中第0226篇新闻,该文本中含有共指链13条,共指链长度为2-7不等,跨句共指的情况为1-9句不等,共出现7次句内共指和47次句间共指。我们依据共指关系类型与句内语义关系,构建出该文本的篇章共指语义图③,如图1所示。图1以句子为基本单元,每一个虚线框都代表一个句子平面,框的左上部为文本原句,虚线框内不同颜色的实线框为该文本中的共指词,已用颜色高亮加以区别,且标注在文本原句中。图1中的有向实线分为横纵两个方向,横向表示共指词的句内语义关系(如“:arg0”标签),纵向表示共指词之间的共指关系(如“:homo”标签)。下面将以该文本为示例,从横纵角度探讨篇章共指语义图结构。
第一,横向揭示句子内部共指信息。横向以句子为基本单元,可揭示:(1)每句共指词的数量及嵌套情况。如s1句共分布有5种共指现象,其中有3种存在层层嵌套关系。(2)每句的句内共指情况。如s3中“两军两国之间的合作”和“上述问题”具有概念同一性,为句内共指。(3)共指词的句内语义关系。如在s1中,“迟浩田”的句内语义关系为“:arg0(施事)”,“坦桑”的句内语义关系为“:mod(修饰)”。
第二,纵向揭示句子之间共指信息。纵向以共指链为基本单元,可以揭示:(1)共指链的起止、长度及其分布。如“会谈”共指链,始于s1,终于s9,跨句情况为9句;共含有3个共指词,分布于s1、s3、s9,尽管出现次数较少,但几乎贯穿本篇始终。(2)共指词之间的共指关系。如“会谈”共指链内部的共指关系均为“:homo(同形)”;如“两国”共指链在全文中常通过零形和阐述共指形式交替出现。
7 结束语
本文为解决共指关系较为粗疏以及与句子内部句法语义关系脱节的问题,在句子级语义表示CAMR的基础上探索共指标注体系,利用整句语义结构来探索篇章级共指现象。本体系区分9种共指关系类型,能够有效表示出共指的内部差异,构建了500篇新闻共指语料库。统计结果表明,同形共指和零形式占60%以上,形式增减约占17%。其次,结合句内语义关系,构建出篇章语义结构图。未来,我们将从以下3个方面开展工作:首先,将尝试标注记叙文、小说等共指现象丰富的语料,完善共指标注方案并扩大语料库规模;其次,综合考虑句子语义结构来探索篇章级共指语义的动态发展问题;最后,进一步探索更为复杂的篇章级句群关系和修辞关系,以建构出完整的篇章语义结构图。
注释
①在篇章中,共指现象往往以词语而不只是单个词的形式出现。但为与学界术语统一,本文仍然使用“先行词”和“共指词”的概念。
②在表1的文本示例中,句子级CAMR标注体系展示的是单句的语义结构,而篇章级共指标注体系的示例则展示了在同一个篇章中指代“杭州大学”的所有用例。左侧,形如“:arg0”的标签为句内语义关系;右侧,形如“:alias”的标签为篇章共指关系。
③该图高清版请查阅:https://www.camrp.tech/DAMR/
*李斌为本文的通讯作者。
参考文献
陈远哲 匡 俊 刘婷婷. 共指消解技术综述[J]. 华东师范大学学报(自然科学版), 2019(5).‖Chen, Y.-Z., Kuang, J., Liu, T.-T. et al. A Survey on Coreference Resolution[J]. Journal of East China Normal University (Natural Science), 2019(5).
胡霄钦 王秀丽. 法汉指称链条平行语料库的建设与应用[J]. 语料库语言学, 2021(1).‖Hu, X.-Q., Wang, X.-L. Construction and Application of a Parallel Corpus of French-Chinese Reference Chains[J]. Corpus Linguistics, 2021(1).
孔 芳 葛海柱 周国栋. 篇章视角的汉语零指代语料库构建[J]. 软件学报, 2021(12).‖Kong, F., Ge, H.-Z., Zhou, G.-D. Corpus Construction for Chinese Zero Anaphora from Discourse Perspective[J]. Journal of Software, 2021(12).
寇 鑫 徐坤宇. 抽象回指的指称内容与可及性研究——以“这”和“这件事”为例[J]. 语言教学与研究, 2023(6).‖Kou, X., Xu, K.-Y. A Study on the Referential Contents and Accessibility of Abstract Anaphora: Using the “Zhe” and “Zhe Jian Shi”as Illustrations[J]. Language Teaching and Linguistic Studies, 2023(6).
郎 君 忻 舟 秦 兵等. 集成多种背景语义知识的共指消解[J]. 中文信息学报, 2009(23).‖Lang, J., Xin, Z., Qin, B. et al. Intra-document Coreference Resolution: The State of the Art[J]. Journal of Chinese Language and Computing. 2007(4).
冉 晨. 现代汉语中数量名回指语的指称性质与回指确认方式[J]. 语言教学与研究, 2024(1).‖Ran, C." The Referential Properties and Means of" Co-referring of‘Num-Cl-NP’ Anaphors[J]. Language Teaching and Linguistic Studies, 2024(1).
宋 洋 王厚峰. 共指消解研究方法综述[J]. 中文信息学报, 2015(1).‖Song, Y., Wang, H.-F. A Survey of Coreference Resolution Research Methods[J]. Journal of Chinese Information Processing, 2015(1).
王 军. 英语叙事篇章中间接回指释义的认知研究[M]. 苏州:苏州大学出版社, 2004.‖Wang, J. A Cognitive Approach to Indirect Anaphora Resolution in English Narrative Discourses[M]. Suzhou: Soochow University Press, 2004.
王 军. 英汉语篇间接回指[M]. 北京:商务印书馆, 2013.‖Wang, J. Indirect Anaphora in English and Chinese[M]. Beijing: The Commercial Press, 2013.
徐赳赳. 现代汉语篇章回指研究[M]. 北京:中国社会科学出版社, 2003.‖Xu, J.-J. Anaphora in Chinese Texts[M]. Beijing: China Social Sciences Press, 2003.
杨永生 肖奚强. 韩国学生汉语“这/那”句习得考察[J]. 华文教学与研究, 2020(1).‖Yang, Y.-S., Xiao, X.-Q. An Investigation of Korean Students’ Acquisition of the “zhe/na”-clause in Chinese[J]. TCSOL Studies, 2020(1).
Ariel, M. Accessing Noun-Phrase Antecedents[M]. London: Routlege, 1990.
Banarescu, L., Bonial, C., Cai, S. et al. Abstract Meaning Representation for Sembanking[A]. Proceedings of the 7th Linguistic Annotation Workshop and Interoperability with Discourse[C]. Sofia: Association for Computational Linguistics, 2013.
Chen, H., Fan, Z., Lu, H. et al. PreCo: A Large-scale Dataset in Preschool Vocabulary for Coreference Resolution[OL]. arXiv preprint arXiv:1810.09807, 2018.
Chinchor, N. Overview of" MUC-7[A]. Seventh Message Understanding Conference (MUC-7)[C]. Fairfax: Science Applications International Corporation, 1998.
Dobrovolskii," V., Michurina, M., Ivoylova, A. RuCoCo: A New Russian Corpus with Coreference Annotation[OL]. arXiv Preprint arXiv:2206.04925, 2022.
Doddington, G., Mitchell, A., Przybocki, M. et al. The Automatic Content Extraction (ACE) Program —" Tasks, Data, and Evaluation[A]. Proceedings of the 4th International Conference on Language Resources and Eva-luation[C]. Lisbon: European Language Resources Association, 2004.
Erkü, F., Gundel, J.K. The Pragmatics of Indirect Anaphors[A]. In: Verschueren, I., Bertuccelli, P.M.(Eds.), The Pragmatic Perspective[C]. Amsterdam: John Benjamins BV, 1987.
Ghaddar, A., Langlais, P. Wikicoref: An English Corefe-rence-annotated Corpus of Wikipedia Articles[A]. Proceedings of the 10th International Conference on Language Resources and Evaluation [C]. Paris: European Language Resources Association, 2016.
Givón, T. Topic Continuity in Discourse[M]. Amsterdam: John Benjamins BV, 1983.
Huang, C.T.J." On the Distribution and Reference of" Empty Pronouns[J]. Linguistic Inquiry, 1984(4).
Langhe, L.D., Clercq, O.D., Hoste, V. Constructing A Cross-document Event Coreference Corpus for Dutch[J]. Language Resources and Evaluation, 2023(2).
Lapshinova-Koltunski, E., Ferreira, P.A. ParCorFull2.0: A Parallel Corpus Annotated with Full Coreference[A]. Proceedings of the 13th Language Resources and Evaluation Conference[C]. Marseille: European Language Resources Association, 2022.
Li, B., Wen, Y., Song, L. et al. Building A Chinese AMR Bank with Concept and Relation Alignments[J]. Linguistic Issues in Language Technology, 2019(18).
Liu, R., Mao, R., Luu, A.T. et al. A Brief Survey on Recent Advances in Coreference Resolution[J]. Artificial Intelligence Review, 2023(12).
Mao, R., Li, X., Ge, M. et al. Metapro: A Computational Metaphor Processing Model for Text Pre-processing[J]. Information Fusion, 2022(86).
Mao, R., Lin, C., Guerin, F. Word Embedding and WordNet Based Metaphor Identification and Interpretation[A]. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)[C]. Melbourne: Association for Computational Linguistics, 2018.
Markert, K., Hou, Y., Strube, M. Collective Classification for Fine-grained Information Status[A]. Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics[C]. Jeju Island: Association for Computational Linguistics, 2012.
Mikulová, M., Bémová, A., HajiAcˇG1, J. et al. Annotation on the Tectogrammatical Level in the Prague Dependency Treebank[OL]. Annotation Manual. Technical Report, 2006.
Nedoluzhko, A., Novák, M., Popel, M. et al. CorefUD 1.0: Coreference Meets Universal Dependencies[A]. Proceedings of the 13th Language Resources and Evaluation Conference[C]. Marseille: European Language Resources Association, 2022.
O’Gorman, T., Regan, M., Griffitt, K., et al. AMR Beyond the Sentence: the Multi-sentence AMR corpus[A]. Proceedings of the 27th International Conference on Computational Linguistics[C]. Santa Fe: Association for Computational Linguistics, 2018.
Poesio, M., Artstein, R. Anaphoric Annotation in the ARRAU Corpus[A]. Proceedings of the 6th International Conference on Language Resources and Evaluation (LREC’08)[C]. Marrakech: European Language Resources Association, 2008.
Poesio, M., Chamberlain, J., Paun, S. A Crowdsourced Corpus of Multiple Judgments and Disagreement on Anaphoric Interpretation[A]. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers)[C]. Minneapolis: Association for Computational Linguistics, 2019.
Rösiger, I. BASHI: A Corpus of" Wall Street Journal Articles Annotated with Bridging Links[A]. Proceedings of the 11th International Conference on Language Resources and Evaluation (LREC 2018)[C]. Miyazaki: European Language Resources Association (ELRA), 2018.
Rösiger, I. SciCorp: A Corpus of" English Scientific Articles Annotated for Information Status Analysis[A]. Procee-dings of the 10th International Conference on Language Resources and Evaluation[C]. Portoro: European Language Resources Association, 2016.
Uryupina, O., Artstein, R., Bristot, A. et al. ARRAU: Linguistically-motivated Annotation of" Anaphoric Descriptions[A]. Proceedings of the 10th International Confe-rence on Language Resources and Evaluation (LREC’16)[C]. Portoro: European Language Resources Association, 2016.
Van Gysel," J.E.L., Vigus M., Chun J., et al. Designing a Uniform Meaning Representation for Natural Language Processing[J]. KI - Künstliche Intelligenz, 2021(35).
Vieira, R., Poesio, M. An Empirically-based System for Processing Definite Descriptions[J]. Computational Linguistics, 2000(4).
Weischedel, R., Palmer, M., Marcus, M. et al. Ontonotes Release 5.0 LDC2013T19[OL]. https://catalog.ldc.upenn.edu/LDC2013T19, 2013.
Xu, Z., Zhang, Y., Li, B, et al. Overview of CCL23-Eval Task 2: The Third Chinese Abstract Meaning Representation Parsing Evaluation[A]. Proceedings of the 22nd Chinese National Conference on Computational Linguistics(Volume 3:Evaluations)[C]. Harbin: Chinese Information Processing Society of China, 2023.
定稿日期:2024-12-10【责任编辑 陈庆斌】
