基于双目视觉和改进YOLOv8n的火灾检测及测距方法
2025-01-25刘振董绍江罗家元孙世政潘学娇











摘 要:针对火灾检测出现的漏检误检、模型参数量大及定位困难的问题,基于双目视觉和改进YOLOv8n提出了一种轻量化火灾检测及测距方法.通过双目相机拍摄图片,使用改进的检测算法YOLOv8n-AEM和现有的测距算法SGBM进行检测和测距.首先,在主干网络中引入可变核卷积AKConv和EMA注意力机制,通过构建不规则卷积核有效提取火灾的特征;然后,在颈部网络中构建C2f-SCConv模块,通过特征重组降低模型参数,提高检测速度;其次,基于最小点距离改进损失函数,解决火源与光源重叠导致的漏检与误检问题;最后,增加小目标检测头,提高对小火苗的检测能力.实验结果表明,改进后的检测算法P、R、mAP分别为83.6%、76.4%、83.6%,分别提高了2.5%、3.6%、4.8%;参数量和模型大小分别为2.54 M和5.1 MB,分别降低了15.3%和15%;测距精度误差不超过2.5%,证明改进的方法能准确完成火灾的检测及测距.
关键词:火灾检测; 双目视觉; 测距; YOLOv8n; 轻量化
中图分类号:TP391.4
文献标志码: A
Fire detection and ranging method based on binocular vision and improved YOLOv8n
LIU Zhen, DONG Shao-jiang*, LUO Jia-yuan, SUN Shi-zheng, PAN Xue-jiao
(College of Mechatronics and Vehicle Engineering, Chongqing Jiaotong University, Chongqing 400074, China
)
Abstract:Aiming at the problems of missing detection and misdetection,large number of model parameters and difficult location in fire detection,a lightweight fire detection and ranging method based on binocular vision and improved YOLOv8n was proposed.Pictures were taken by binocular camera,and the improved detection algorithm YOLOv8n-AEM and the existing ranging algorithm SGBM were used for detection and ranging.Firstly,variable kernel convolution AKConv and EMA attention mechanisms are introduced into the backbone network to effectively extract fire features by constructing irregular convolutional nuclei.Then,the C2f-SCConv module is constructed in the neck network to reduce the model parameters and improve the detection speed through feature recombination.Secondly,the loss function is improved based on the minimum point distance to solve the problem of missing detection and 1 detection caused by overlapping fire source and light source.Finally,the detection head of small target is added to improve the detection ability of small flame.The experimental results show that the improved detection algorithms P,R and mAP are 83.6%,76.4% and 83.6% respectively,which are improved by 2.5%,3.6% and 4.8% respectively.The parameter number and model size were 2.54 M and 5.1 MB,which decreased by 15.3% and 15%,respectively.The accuracy error of ranging is less than 2.5%,which proves that the improved method can accurately complete the fire detection and ranging.
Key words:fire detection; binocular vision; distance measurement; YOLOv8n; light weight
0 引言
正确用火是人类进步的象征,火提供便捷的同时也会带来灾难.火灾规模虽不如其他自然灾害,但其发生更频繁.因此,火灾的准确快速预警具有重大意义.
随着计算机视觉的发展,火灾检测从传感器演变为基于深度学习的图像检测技术;速度快、成本低、可结合定位技术准确感知火灾的位置,其较好的应用属性使它逐渐成为了火灾检测预警的主流技术.He等[1]提出了一种基于改进的YOLOv5模型的火灾探测算法DCGC(Dual Channel Group Convolution)-YOLO,该算法检测精度高且鲁棒性好.Yang等[2]设计了一个结合CNN和Transformer的网络,该网络可以对全局和局部信息进行建模,并实现精度和速度的平衡.Zhao等[3]提出了一种改进的Fire-YOLO深度学习算法,针对森林火灾该算法有较好的性能表现.Sun等[4]提出了一种基于YOLOv7的微小火苗探测算法,有效提高了针对小火苗的检测精度.Yun等[5]提出了一种轻量级森林火灾探测模型,该算法结合知识蒸馏,有效降低误检率.Cao等[6]提出一种分段检测算法YOLO-SF,将实例分割技术与YOLOv7-Tiny目标检测算法相结合,提高了其准确性.Choutri等[7]基于无人机和YOLO模型提出新模型YOLO-NAS,将改进后的算法部署到自研无人机设备,有效检测野外火灾.
上述检测方法颇有成效,但仍存在问题.首先,对小火苗的检测效果不佳;其次,模型参数量大,不便于部署应用;最后,对火源进行测距及定位较困难.
针对目前火灾检测存在的问题,本研究提出了一种基于双目视觉和改进YOLOV8n的轻量化火灾检测及测距方法.
YOLO系列是目前图像检测技术应用的主流模型,而YOLOv8是目前YOLO系列模型中集成度最高、检测效果最好、泛用性最强的模型,共有YOLOv8-n、s、m、l、x五个版本,其中yolov8n是最轻量级的模型,拥有更快的检测速度和更低的资源消耗,适用于资源受限的移动设备部署应用.故本研究选用YOLOv8n为改进的基准模型,检测算法改进如下:
(1)火灾发生初期烟火像素占比低,特征不明显,增加一个检测头来提高模型对小目标的检测能力.
(2)利用可变核卷积AKConv优化主干网络中的普通卷积,有效降低模型参数量.
(3)在主干网络中引入EMA注意力机制,提高模型的特征提取能力.
(4)引入MPDIOU改进损失函数,防止火源与光源重叠出现漏检和误检.
(5)设计了C2f-SCConv模块,并引入到颈部网络中减少冗余特征处理,进一步降低模型参数.
1 检测算法改进
1.1 可变核卷积
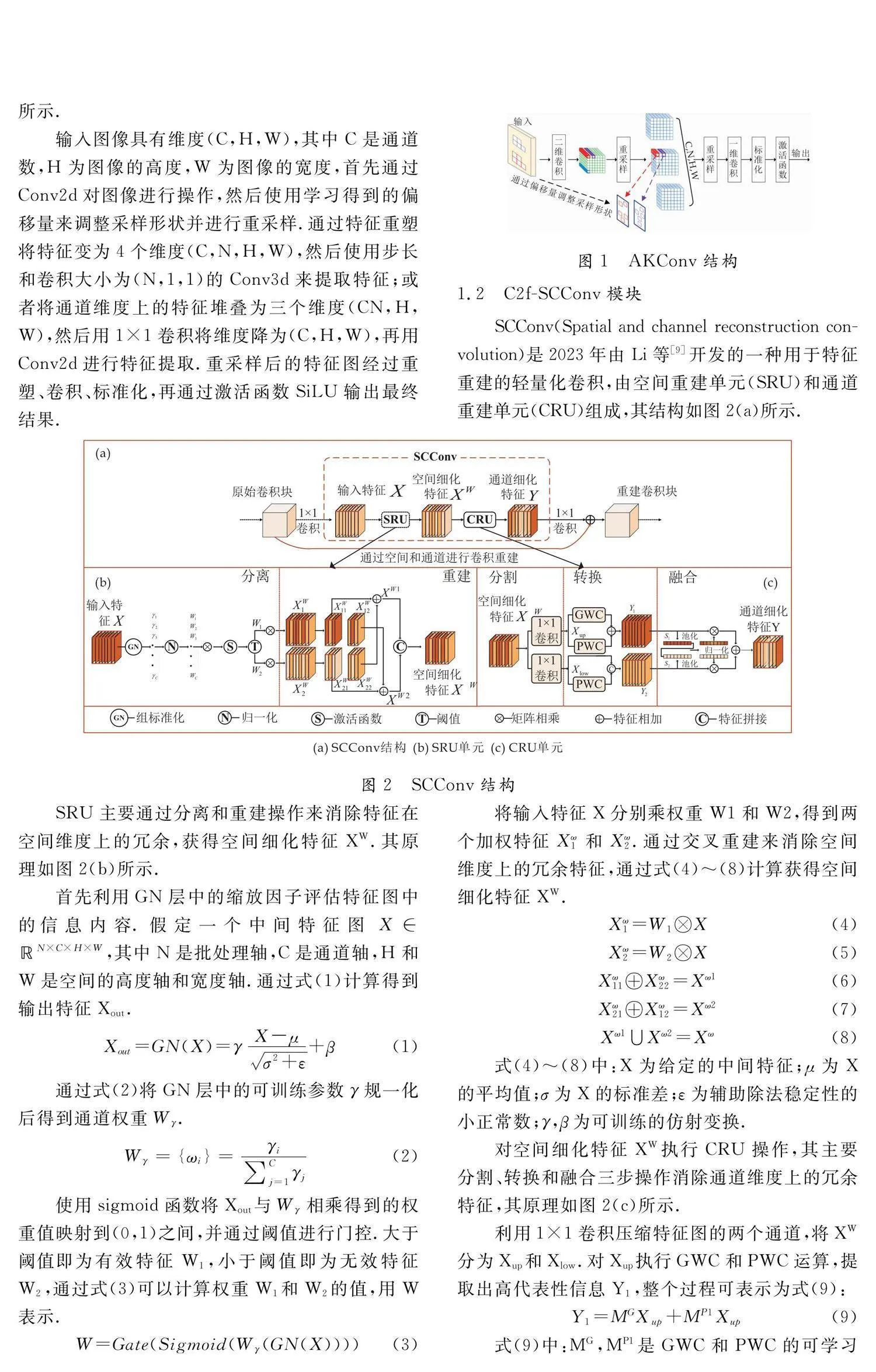
火灾具有多尺度特性,在模型中引入可变核卷积更准确地提取目标特征.AKConv(Convolutional Kernel with Arbitrary Sampled Shapes and Arbitrary Number of Parameters)是2023年由Zhang等[8]开发的一种可变核的灵活卷积,它允许卷积核具有任意采样形状和参数量.
AKConv将特征堆叠到行或列上,利用对应行、列卷积提取不规则采样形状的特征,如图1所示.
输入图像具有维度(C,H,W),其中C是通道数,H为图像的高度,W为图像的宽度,首先通过Conv2d对图像进行操作,然后使用学习得到的偏移量来调整采样形状并进行重采样.通过特征重塑将特征变为4个维度(C,N,H,W),然后使用步长和卷积大小为(N,1,1)的Conv3d来提取特征;或者将通道维度上的特征堆叠为三个维度(CN,H,W),然后用1×1卷积将维度降为(C,H,W),再用Conv2d进行特征提取.重采样后的特征图经过重塑、卷积、标准化,再通过激活函数SiLU输出最终结果.
1.2 C2f-SCConv模块
SCConv(Spatial and channel reconstruction convolution)是2023年由Li等[9]开发的一种用于特征重建的轻量化卷积,由空间重建单元(SRU)和通道重建单元(CRU)组成,其结构如图2(a)所示.
式(4)~(8)中:X为给定的中间特征;μ为X的平均值;σ为X的标准差;ε为辅助除法稳定性的小正常数;γ,β为可训练的仿射变换.
对空间细化特征XW执行CRU操作,其主要分割、转换和融合三步操作消除通道维度上的冗余特征,其原理如图2(c)所示.
利用1×1卷积压缩特征图的两个通道,将XW分为Xup和Xlow.对Xup执行GWC和PWC运算,提取出高代表性信息Y1,整个过程可表示为式(9):
Y1=MGXup+MP1Xup
(9)
式(9)中:MG,MP1是GWC和PWC的可学习权重矩阵;Xup,Y1是上部输入和输出特征图.
对Xlow执行PWC,生成含隐藏细节的特征作为Xup的补充,将生成特征和Xlow结合形成特征Y2,概括为式(10):
Y2=MP2Xlow∪Xlow
(10)
式(10)中:MP2是PWC的可学习权重矩阵;Xlow,Y2是下部输入和输出特征图.
执行完分割和转换操作后,再利用简化的SKNet方法自适应地融合特征Y1和Y2,得到通道细化特征Y,自此完成对特征的重建.将SCConv模块融合进C2f模块,如图3所示.
先将Bottleneck模块中的普通卷积替换为SCConv,得到Bottleneck-SC模块,再将改进后的Bottleneck-SC模块引入C2f模块中替换Bottleneck模块,得到改进后的C2f-SCConv模块.该模块消除了模型对冗余特征的处理过程,提高了计算速度,减少了模型参数量.
1.3 损失函数改进
当前大多数损失函数梯度相似,导致梯度稀疏、减缓边界框回归的收敛速度和准确性;针对这一问题,Siliang等[10]在2023年提出了一种准确有效的损失函数MPDIOU.它是基于最小点距离的损失函数,可以直接最小化预测边界框与真实边界框之间的左上角与右下角的点距离,具体计算公式如式(11)~(13)所示:
d21=(xB1-xA1)2+(yB1-yA1)2
(11)
d22=(xB2-xA2)2+(yB2-yA2)2
(12)
MPDIoU=A∩BA∪B-d21w2+h2-d22w2+h2
(13)
式(11)~(13)中:A,B为任意的两个凸形状;W,h为输入图像的宽度和高低;(xA1,yA1),(xA2,yA2)为A的左上角和右下角坐标;(xB1,yB1),(xB2,yB2)为B的左上角和右下角坐标.
引入MPDIOU简化了边界框之间的相似性比较,帮助选择最佳边界框以实现准确定位.当火源与其他光源重叠时,使用MPDIOU可以有效解决检测框失真问题,降低漏检率和误检率.
1.4 EMA注意力机制
EMA(Efficient Multi-Scale Attention Module with Cross-Spatial Learning)是Ouyang等[11]在2023年提出的一种高效多尺度注意力模块,其结构如图4所示.
该模块结合了多尺度注意力机制,能在不同空间尺度上有效捕捉特征.通过多通道加权最大限度的保留了每个通道的特征信息,使模型能更全面地理解和处理不同大小和复杂度的火灾.
1.5 添加小目标检测头
改进后的检测算法整体模型如图5所示.
火灾检测更多的是火灾预防,是针对火源的检测,而火源检测隶属于多尺度小目标的检测.当火灾刚发生时,视觉传感器能捕捉到的画面是大场景下的小目标.火焰和烟雾表现出的特征在输入图像中占比很小、像素覆盖率很低,YOLOv8n现有的三种检测头针对小目标的检测效果不佳,会出现漏检和误检.本研究通过调整网络结构,添加一个检测头,重新定义了四个检测头的检测模型.提高了模型对小目标的检测能力,降低了模型的误检率和漏检率.
2 测距功能实现
2.1 双目相机标定及校正
视觉测距是利用摄像头获取图像信息来估计物体距离的方法.常见的视觉测距方法包括:
单目视觉测距:通过单个摄像头获取的图像,利用物体在图像中的大小和视角信息推断其距离.通常需要知道物体的实际尺寸或参考物体,如标定板.
双目视觉测距:利用双目立体视觉系统中左右两个摄像头的视差来计算物体的深度信息.需要进行摄像头的精确标定.
本研究采用英特尔实感深度双目相机完成对目标的测距任务,该相机能够同时获取同一场景的两幅图像,通过分析这些图像之间的视差,可以计算出场景中不同物体的距离和深度信息.实物如图6所示.
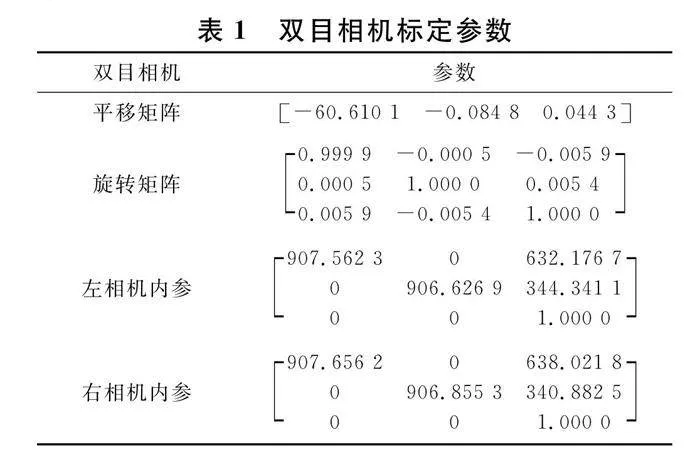
使用相机前首先标定相机系统的参数,包括内参和外参,通过拍摄棋盘格并借助MATLAB自带工具箱对相机进行标定,来确定相机的内参矩阵、畸变参数、外参矩阵,过程如图7所示.
本研究采用6行*9列棋盘格作为标定物,每个方格尺寸为270 mm*270 mm.通过标定得到双目相机各项参数如表1所示.
相机镜头的畸变会使得图像的几何形状发生变化,从而影响视差计算的准确性.通过使用标定得到的畸变参数,对图像进行校正,修正这些畸变,使得图像更加接近实际场景,从而提高后续计算的准确性.
2.2 双测距算法实现
深度双目相机测距的原理基于立体视觉技术,核心在于通过两个相机从不同角度拍摄同一场景,利用这些图像之间的视差和深度信息来计算场景中物体的实际距离.视差是指在左右相机拍摄的同一场景中,同一物体的图像之间的像素偏移量,计算视差的过程称为立体匹配.
立体匹配算法主要分为局部、半全局和全局立体匹配.Xu等[12]对局部匹配进行了全面的概述,就是在像素周围进行小区域约束匹配,适用于有明显特征的场景;Chen等[13]介绍了全局匹配的概念,对整幅图像进行约束匹配,计算复杂度高.Hirschmuller等[14]阐述了半全局匹配算法SGBM(Semi-Global Block Matching),其结合了预处理、代价计算、动态规划和后处理步骤,既优于局部匹配算法,又复杂度低于全局匹配算法.本研究选择SGBM作为立体匹配算法,以满足对精确度和效率的双重需求,立体匹配结果如图8所示.
3 实验数据及环境配置
3.1 实验数据获取
所用数据部分来自Wu等[15]在2022年发表的论文中公开的火焰和烟雾的数据集;部分使用网络爬虫获取.共计5 250张图片,包括城市、森林、房屋等火灾场景;为了提高模型性能,加入其他类似火源的图片做干扰项,共计1 293张图片,两种数据图片共计6 543张图片.
使用MakeSense工具手动标注;本实验共有三种标签类别:fire、smoke、other.为保证数据集分布均匀,分别将两类图片按照80%、10%、10%的比例分为训练集、验证集和测试集,再进行混合完成实验.在测试集中加入偶然拍得真实火灾场景图片共24张,验证模型的泛化能力.
3.2 环境配置
在本研究中,模型的训练和测试都在同一环境.设备的操作系统为Windows10,GPU的型号为NVIDIA GeForce GTX 1050 Ti,CPU的型号为Intel(R) Core(TM) i5-8300H CPU @2.30 GHz,内存为16 G;使用Python 3.9版本,pytorch版本为1.9.1,Cuda版本为11.1;Epoch设置为300轮,batch size设置为16,其余参数均为默认初始值.
4 实验设计及结果分析
4.1 模型评估标准
本研究使用目标检测常用的性能评价指标来对模型进行评价,包括精确度(Precision)、召回率(Recall)、平均精度均值(Mean average precision)、模型参数量(Parameter)、模型计算量(Floating point of operations)、每秒帧率FPS(Frames Per Second).
4.2 注意力机制对比
为了验证本研究所提出模型中引入的EMA注意力机制的有效性,设计了几组添加不同注意力机制的对比实验.在模型的同一个位置添加引入四种不同注意力机制模块,分别将添加了注意力机制的模型和原模型的训练结果进行对比分析,表2显示了引入不同注意力机制后模型的效果.
由表2可以看出,将四种注意力机制分别引入到YOLOv8n的模型中,对模型的性能都有一定程度的提升.其中对平均精度均值mAP提升较大的是CBAM模块和EMA模块,分别提升了1.7%和1.8%;但是EMA模块引入的参数量更少,模型的计算复杂度更低,更有利用模型的轻量化.
4.3 损失函数对比
针对目标重叠导致的漏检误检问题,本研究改进提出的模型中引入了MPDIOU损失函数,为了验证它在本模型中的有效性,以YOLOv8n为基础模型设计了几组引入不同损失函数的对比实验,结果如表3所示.
表3结果显示,本实验对比的其他损失函数在本模型中的表现都不及MPDIOU.分析原因可能是本研究使用的数据集中存在大量被检测目标之间交错重叠的现象,所以聚焦于边框相似性比较的MPDIOU表现效果更好,精确度为79.3%,召回率为72.9%,mAP为79.8%,mAP50-90为%51.3%,各项指标都最高.
4.4 不同模型对比
为了验证本研究改进提出的算法模型综合性能的优越性,设计了几种不同模型的预测结果对比实验.由于本研究主要做模型轻量化改进,故选取参数量相当的YOLO系列模型作为实验对象;此外,为了验证本研究提出模型在火灾监测领域的科学性和有效性,对比了三种现有文献提出的火灾检测算法,实验结果如表4所示.
从表4可以看出,在参数量相当的各种YOLO模型和现有的火灾检测算法中,本研究所改进提出的模型是综合性能最优的.相较于YOLOv5s、YOLOv6n、YOLOv7-tiny、YOLOv8n、YOLOv9s和三种现有火灾检测算法,mAP均有一定程度的提升,分别提升了0.6%、3.8%、3.5%、4.8%、3%、14.7%、3.2%和1.9%.其中YOLOv8n的GFLOPs是最优的,模型复杂度最小,但mAP不及改进后的模型;而文献\中提出的模型参数量和检测时间是最优的,但精度不及本研究提出的模型.本研究改进模型的mAP值在所对比的9种模型算法中排第一位,检测精度较高;浮点运算量GFLOPs排在第二位,计算复杂度较低,且模型的参数量较少;模型中借鉴特征重组的思想引入了C2f-SCConv模块,剔除了信息较少的冗余特征处理,所以检测时间短,FPS值也优于对比的其他算法模型.综合来看,本研究改进的模型YOLOv8n-AEM提高了检测精度,降低了模型的参数量,减少了计算时间成本,能有效满足实时准确检测.
4.5 消融实验
为了进一步探究本研究中各模块的改进对最终模型的影响,以YOLOv8n为基础模型设计一组消融实验进行对比分析.其中A表示添加小目标检测头,B表示改进AKConv卷积,C表示引入设计的C2f-SCConv模块,D表示添加EMA注意力机制,E表示改进MPDIOU损失函数.为保证实验结果的准确性,所有实验均在同一环境下进行.实验结果如表5所示.
由表5可以看出,增加小目标检测头,虽然模型的参数量增加了0.2 M,但mAP50提升了2.8%,表明火灾检测更多的是小目标检测;改进AKConv卷积,模型的参数量降低了0.48 M并且mAP提升了1.1%,因为AKConv提供不规则卷积核,能更好的应对火灾的多尺度特征提取,并且AKConv允许参数线性变化,所以提高mAP的同时,参数量也大幅度下降;在此基础上使用融合了SCConv卷积的C2f-SCConv模块,mAP值基本不变,但是参数量降低了0.21 M,分析原因可能是因为SCConv模块本身是用于特征重建的轻量化卷积,本研究中实验对象的特征较为分明,所以去除的冗余特征较少,mAP基本不变同时参数量下降;最后改进MPDIOU损失函数作为检测框回归函数,主要是针对火源与其他光源检测框重叠导致的漏检和误检,mAP提升了0.7%,说明改进是有效果的.
4.6 损失函数可视化
在火灾检测任务中,光源与火源重叠通常会导致漏检甚至误检情况出现,为了有效解决这一问题,本研究基于最小点距离的思想引入MPDIOU改进了损失函数的回归检测框.以YOLOv8n为基础模型,分析改进MPDIOU损失函数前后模型对相同场景的检测结果,验证了本研究改进的合理性与有效性.实验所用的测试集数据是来自网上的视频分帧截取和开源火灾数据集,在所有检测图片中选择两张有代表性的图片分析,结果对比如图9所示.
图9(a)、(b)中左侧图片是在夜晚城市路口发生的车辆起火,火势较大,包含有火焰、烟雾和其他光源三种检测目标.图9(a)左侧图片是引入MPDIOU损失函数前的模型检测效果,虽然能检测到三种目标存在,但是由于火势太大,火焰与路灯的光影出现交错和部分重叠,错误的将路灯检测为火焰;图9(b)左侧图片是引入MPDIOU损失函数后的检测效果,能准确的将光影与火源区分开,不仅准确的检测到了三种目标,而且置信度更高,有效改善了目标重叠引起的误检情况.
图9(a)、(b)中右侧图片是夜晚路边的物体起火,火势较小.图9(a)右侧图片是改进前的检测效果,准确检测到火焰和其他干扰项,但是由于火势不大,烟雾并未呈现黑褐色,与夜晚的背景类似,所以并未检测到烟雾存在;图9(b)右侧图片是改进后的检测效果,在暖色背景下准确检测出了三种目标的存在,并且置信度更高,有效改善了背景相似引起的漏检情况.
通过损失函数改进的可视化实验,验证了本研究针对目标交错重叠导致的漏检和误检情况而引入的MPDIOU损失函数改进是有效的.
4.7 检测算法可视化
为了更直观的表现本研究改进提出的算法YOLOv8n-AEM的有效性,将相同测试集分别用不同算法进行预测,其中部分来自偶然拍得真实火灾场景的视频中分帧截取.选取三张具有代表性的预测结果图进行对比分析,如图10所示.
图10(a)~(i)中左侧图片场景是在白天熙攘的街道上,远处的房屋起火,火势较小,有出现明烟,但火焰的像素占比低,目标小.在对比的9种算法中,只有本研究提出的YOLOv8n-AEM完成了所有目标的检测,如图10(a)左侧图片所示.其他8种算法都只检测到了烟雾或是类似火焰的干扰项,分析原因应该是图中的火焰目标较小,属于小目标检测的范畴,而本研究针对小火苗检测任务在模型中增加了小目标检测头,所以能准确的完成对小火苗的检测任务;
图10(a)~(i)中中间图片场景是在夜晚的道路上,远处的楼房起火,图片中存在许多光源干扰项,肉眼看不出有明烟出现,在对比的算法中,只有本研究的算法、YOLOv9s、YOLOv5s和文献\中提出的算法完成了对远处火焰目标的准确检测,分别如图10(a)、(c)、(d)、(i)的中间图片所示.但本研究算法检测到其他光源干扰项更多,模型性能更好且置信度更高.
图10中(a)~(i)中右侧图片是偶然拍到的真实火灾场景.图片是在上午拍摄的,火灾发生的场景是一般住房区的集中快递站,火势较小,但已经出现明火和烟雾,现场存在类似火焰颜色的红色横幅和黄色交通指示牌.检测结果显示,由于图片中的各种被检测目标特征较为明显,对比的所有算法模型都完成了全部目标的检测,但本研究提出的算法检测到烟雾区域更多、更细致,并且置信度更高.
通过设计9种检测算法对比实验及可视化分析,验证了本研究提出算法YOLOv8n-AEM的科学性和有效性;不仅提高了检测精度,提高了对小目标的检测能力,并且检测结果的置信度更高,还能有效避免漏检和误检.
4.8 测距结果可视化
由于火灾数据的特殊性,实验通过人为制造检测目标进行结果可视化分析,如图11所示.
图11(a)中三张图片是在试验场地实际拍摄,被燃物是蘸酒精的卫生纸,不同角度不同距离拍摄了三张图片.左侧图片为俯视,检测距离显示1.26 m,实测大约在1.28 m左右;中间图片是侧视,检测距离显示2.16 m,实测大约2.20 m左右;右侧图片也是侧视,检测距离为2.24 m,实测大约在2.22 m左右.
图11(b)是将带有三种被检测目标图片放置在显示器上,通过拍摄显示器进行实验.结果显示三种目标都被检测到,能准确完成对目标的检测任务;算法测量得到的距离为1.18 m,实测距离大约在1.21 m左右,能实现对目标的精确测距.
实验结果表明,本研究提出的火灾检测及测距方法能完成对火灾的准确检测;测距精度误差不超过2.5%,在可接受误差范围内也能完成测距.
5 结论
本研究基于双目视觉和改进YOLOv8n提出了一种轻量化火灾检测及测距方法.主要工作如下:
(1)基于YOLOv8n改进了火灾检测算法.在主干网络中引入可变核卷积并结合EMA注意力机制,提高模型的特征提取能力,更好的应对火灾的多尺度特性;将SCConv模块融合到颈部网络中的C2f模块,通过特征重组保留有效信息的同时减少了模型参数量;基于最小点距离思想对损失函数进行改进,降低算法对重叠目标的误检率.
通过实验验证,改进算法的P、R、mAP分别为83.6%、76.4%、83.6%,比原模型提高了2.5%、3.6%、4.8%;参数量和模型大小分别为2.54 M和5.1 MB,比原模型降低了15.3%和15%.
(2)将改进后的检测算法YOLOv8n-AEM和现有的测距算法SGBM结合深度双目相机设计实验应用.
通过实验验证,本研究提出的方法在误差可接受范围内能完成对火灾的准确检测及测距.
参考文献
[1] He Y,Hu J,Zeng M,et al.DCGC-YOLO:The efficient dual-channel bottleneck structure YOLO detection algorithm for fire detection[J].IEEE Access,2024,12:65 254-65 265.
[2] Yang C,Pan Y,Cao Y,et al.CNN-transformer hybrid architecture for early fire detection[C]//International Conference on Artificial Neural Networks.Cham:Springer Nature Switzerland,2022:570-581.
[3] Zhao L,Zhi L,Zhao C,et al.Fire-YOLO:A small target object detection method for fire inspection[J].Sustainability,2022,14(9):4 930.
[4] Sun B,Bi K,Wang Q.YOLOv7-FIRE:A tiny-fire identification and detection method applied on UAV[J].Aims Mathematics,2024,9(5):10 775-10 801.
[5] Yun B,Zheng Y,Lin Z,et al.FFYOLO:A lightweight forest fire detection model based on YOLOv8[J].Fire,2024,7(3):93.
[6] Cao X,Su Y,Geng X,et al.YOLO-SF:YOLO for fire segmentation detection[J].IEEE Access,2023,11:111 079-111 092.
[7] Choutri K,Lagha M,Meshoul S,et al.Fire detection and geo-localization using UAV′s aerial images and yolo-based models[J].Applied Sciences,2023,13(20):11 548.
[8] Zhang X,Song Y,Song T,et al.AKConv:Convolutional kernel with arbitrary sampled shapes and arbitrary number of parameters[J].Arxiv Preprint Arxiv,2023,23(11):11 587.
[9] Li J,Wen Y,He L.Scconv:spatial and channel reconstruction convolution for feature redundancy[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Vancouver,BC,Canada:IEEE,2023:6 153-6 162.
[10] Siliang M,Yong X.MPDIOU:A loss for efficient and accurate bounding box regression[J].Arxiv Preprint Arxiv,2023,23(7):7 662.
[11] Ouyang D,He S,Zhang G,et al.Efficient multi-scale attention module with cross-spatial learning[C]//ICASSP 2023-2023 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP).Rhodes Island,Greece:IEEE,2023:1-5.
[12] Xu S,Chen S,Xu R,et al.Local feature matching using deep learning:A survey[J].Information Fusion,2024,107:102 344.
[13] Chen Q,Yao J,Long J.Similar image matching via global topology consensus[J].The Visual Computer,2024,40(2):937-952.
[14] Hirschmuller H.Accurate and efficient stereo processing by semi-global matching and mutual information[C]//2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR′05).San Diego,CA,USA:IEEE,2005:807-814.
[15] Wu S,Zhang X,Liu R,et al.A dataset for fire and smoke object detection[J].Multimedia Tools and Applications,2023,82(5):6 707-6 726.
【责任编辑:陈 佳】
