基于深度学习的目标检测算法研究
2025-01-21曹斯茹金可艺陈惠妹





摘 要:为全面识别并检测摄像头拍摄的在城市道路上的车辆目标,本文提出一种基于YOLOv7的改进模型C-YOLOv7。在头部网络末端加入注意力机制模块,提高模型检测准确率。为减少YOLOv7算法的参数量,降低计算的复杂度,对改进后的模型进行剪枝轻量化。试验结果表示,与原模型相比,改进后的模型的平均精度(Average Precision,AP)、精度和召回率均有提高,与C-YOLOv7模型相比,轻量化后的模型的传输帧数增加,推理延迟和参数量减少。改进后的模型能够提高车辆检测的准确度,节省存储空间,在交通安全与管理领域发挥更大作用。
关键词:深度学习;目标检测;注意力机制;轻量化
中国分类号:TP 391 " " " 文献标志码:A
在快速发展的交通领域,车辆检测技术[1]是提升交通安全和效率的重要手段。深度学习基础的车辆检测算法具有出色的泛化能力,能够适应多变的环境条件。尽管已有算法在检测精度、检测速度及模型参数优化方面均有良好表现,但综合性能卓越的算法仍比较稀少。本文以城市道路车辆检测为应用场景,依托深度学习技术[2],旨在构建一种体积更小、部署范围更广的目标检测模型。该模型旨在克服传统目标检测方法中存在的准确度及计算效率偏低的问题,进而提升车辆目标检测的准确率。
1 基于改进的YOLOv7目标检测模型
YOLOv7[3]目标检测模型的检测速度较快,其采用多尺度特征融合策略,从不同层级的特征图中提取信息,能够检测不同尺度的目标,更好地处理目标的上下文信息。模型的网络结构比较简单,在不同的硬件平台和资源受限的设备上都可以运行。
1.1 YOLOv7的网络结构
YOLOv7网络模型主要包括3个部分,其特点如下。
1.1.1 骨干网络
骨干网络的主要任务是从输入图像中提取高质量的特征。YOLOv7使用优化的高效长距离网络(Efficient Long-Range Attention Network,ELAN)作为其骨干网络,这种设计使网络能够在更浅的网络层级收集更多的信息,并保持计算的高效性。
1.1.2 颈部网络
颈部网络的主要任务是将骨干网络提取的特征进行进一步处理和融合,以执行后续的检测任务。其中,下采样模块利用最大池化(Max Pool)操作扩张当前特征层的感受野,再与正常卷积处理后的特征信息进行融合,增强了网络的泛化性。
1.1.3 头部网络
头部网络的主要任务是对颈部网络输出的特征图进行物体检测。YOLOv7的头部网络采用多尺度的检测机制,分别在不同尺度的特征图中进行物体检测,提升检测的准确性。头部网络引入经过特殊设计的残差结构辅助训练,但是在转换过程中可能会产生一定的精度损失。
1.2 YOLOv7使用的损失函数
1.2.1 定位损失(Location Loss)
在目标形状不规则、大小不一致的情况下,CIoU的相似性度量更准确,能够更好地满足各种尺寸和形状的目标检测要求,因此在YOLOv7中使用CIoU损失计算定位损失。IoU 的计算过程如公式(1)所示。
(1)
式中:IoU 为交并比;A为预测框的面积;B为真实框的面积。
CIoU 的计算过程如公式(2)所示。
(2)
式中:CIoU 为完整的交并比;d为预测框与真实框中心点的距离;c为最小外接矩形的对角线距离;α为权重函数;v 为修正因子。
CIoU 损失函数的计算过程如公式(3)所示。
(3)
式中:LossCIoU为完整的交并比损失。
1.2.2 置信度损失(Confidence Loss)
置信度损失能够评估预测边界框的置信度与真实目标是否存在差距,并衡量其预测的准确性。本文采用二元交叉熵损失函数计算置信度损失,计算过程如公式(4)所示。
Lconf=-[ylog(p)+(1-y)log(1-p)] " " (4)
式中:Lconf为二元交叉熵损失;y为真实标签;p为模型预测的概率,数值为0~1;log(1-p)为对模型预测的负类概率取自然对数。
1.2.3 类别损失(Class Loss)
类别损失的作用是衡量模型对目标类别的预测准确性。本文利用多类交叉熵损失来计算分类损失,损失函数计算过程如公式(5)所示。
(5)
式中:Lcls为多类交叉熵损失;C为类别总数;i为类别的索引,取值为1~C;yi为真实标签,当yi为1时表示真实类别,当yi为0时表示其他类别;pi为模型预测第i类的概率。
1.3 C-YOLOv7算法改进
1.3.1 引入注意力机制
Head部分利用卷积进行特征提取,可能会出现只在局部感知域内进行特征提取,不能全面考虑全局上下文信息,导致对整体信息捕捉不足的情况。针对这个问题本文提出C-YOLOv7目标检测框架,在Head部分融入注意力机制模块(Convolutional Block Attention Module,CBAM),提高对整体信息的捕获能力。CBAM由2个子模块组成:通道注意力模块(Channel Attention Module,CAM)和空间注意力模块(Spatial Attention Module,SAM)。CBAM引入注意力机制至特征图中,使网络能够更有效地聚焦于关键特征,达到检测效果。CBAM结构如图1所示。
在YOLOv7-Head部分卷积层中串联进CBAM,得到新的M-Conv卷积层,将M-Conv替换为原YOLOv7中的卷积层,得到C-YOLOv7模型,其结构如图2所示。
不同尺寸的特征图经过残差结构进入通道注意力模块,分别进行全局平均池化和全局最大池化,保留通道信息。分别将池化后的特征图送入多层感知机(Multilayer Perceptron,MLP)中提取特征。将MLP输出的特征进行加合,经过Sigmoid激活操作,得到通道注意力权重。通道注意力模块的计算过程如公式(6)所示。
Mc(F)=σ(MLP(AvgPool(F))+MLP(MaxPool(F))) (6)
式中:Mc(F)为特征图F的通道注意力;σ为Sigmoid激活函数;MLP为多层感知机;AvgPool(F)为F的全局平均池化;MaxPool(F)为F的全局最大池化。
将利用通道注意力计算后输出的特征图作为空间注意力模块输入的特征图,在通道维度分别进行全局平均池化和全局最大池化,保留空间信息。将这2个池化特征进行通道融合操作,利用卷积层操作提取特征。利用Sigmoid函数进行激活,得到包括通道注意力的空间注意力权重。在串行完成这2个步骤后,将空间注意力特征与原特征图相乘,得到最终的输出特征图。通道注意力模块的计算过程如公式(7)所示。
Ms(F)=σ(f 7*7([AvgPool(F));MaxPool(F)])) (7)
式中:Ms(F)为F的空间注意力;f 7*7为7*7的卷积操作。
1.3.2 模型轻量化
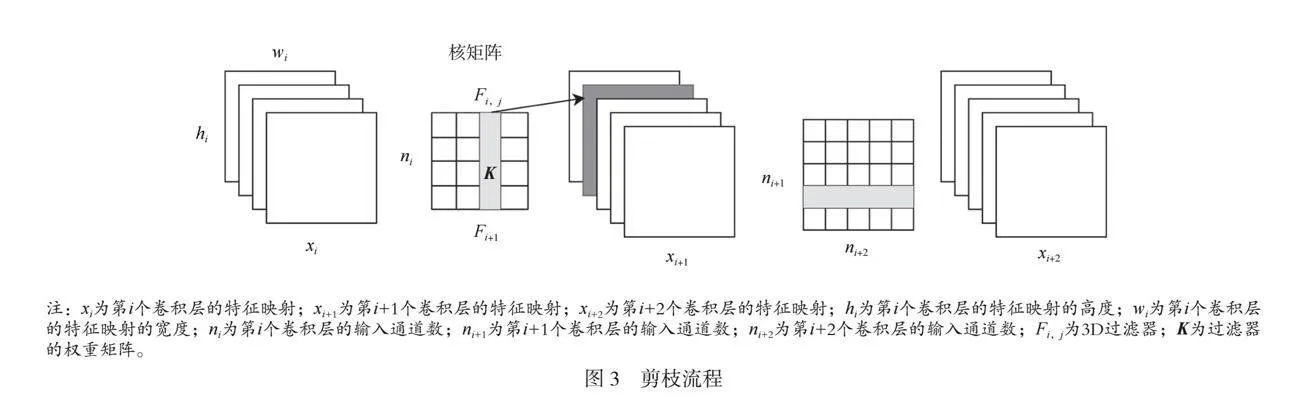
在深度学习模型中,剪枝[4]是一种重要的优化技术,其作用是减少模型的计算量和参数量,加快推理速度,缩小模型的存储空间。移除过滤器是一种适用于卷积神经网络的剪枝方法,通过识别并移除对最终模型影响较小的卷积核来减少模型的参数量。针对C-YOLOv7检测模型体积较大的问题,对C-YOLOv7进行剪枝操作,得到轻量化的目标检测模型PC-YOLOv7。
对过滤器进行剪枝,流程如图3所示。设ni为第i个卷积层的输入通道数,hi/wi为输入特征映射的高度/宽度。卷积层在ni个输入通道中应用ni+1个3D滤波器Fi,j,将输入特征映射xi转换为输出特征映射xi+1,生成的输出特征映射将作为下一层卷积层的输入特征映射。当对过滤器Fi,j进行剪枝时,去除其对应的特征映射,也去除下一个卷积层过滤器中特征映射的核。
从训练良好的模型中去除不重要的过滤器来提高计算效率。计算过滤器的绝对权重总和Σ|Fi,j|来衡量每一层中过滤器的相对重要性。由于各过滤器的输入通道数ni相同,因此Σ|Fi,j|也表示其平均核权重。与该层中的其他过滤器相比,核权重较小的过滤器倾向于生成弱激活的特征映射,该映射对最终结果影响较小,因此剪去核权重较小的过滤器。计算过滤器的绝对权重总和,如公式(8)所示。
(8)
式中:Sj为第i个过滤器的绝对值权重总和;Fi,j为第i个过滤器的第j个权重。
进行剪枝的具体步骤如下。1)统计卷积层的权重,计算每个卷积层权重的绝对值总和,将其作为剪枝依据。2)根据权重总和对过滤器进行排序,并选择一部分进行剪枝。percent参数决定需要剪枝的比例。本文将percent设为0.2。3)移除选择的卷积层中不重要的过滤器,创建一个新的卷积层,复制旧卷积层的权重和偏置来移除过滤器。4)将剪枝后的卷积层替换回模型中。
2 试验结果
2.1 试验环境
本文模型使用PyTorch语言编写算法的程序代码,操作系统为Windows 10,训练模型使用的GPU为NVIDIA 4060Ti GPU,初始学习率为0.000 1。在每次训练迭代中进行前向传播再进行反向传播,从而实现优化。
2.2 数据集选取
本文选择公开数据集Data for STREETS(A novel camera network dataset for traffic flow,STREETS)作为检测对象,该数据集包括5 249张训练集样本、291张测试集样本以及582张验证集样本。在数据集中有各种城市街道的交通场景,利用安装在城市街道重要道路和交通繁忙的路口的高清摄像头采集多样化的交通车辆数据,其包括不同天气条件、交通密度和时间段的数据类型。
2.3 各目标检测模型对比试验
C-YOLOv7与其他目标检测模型的试验对比结果见表1。
由表1可知,与原版本以及其衍生版本相比,改进后的C-YOLOv7在平均精度、精度以及召回率方面均有提高,精度为83.7%,说明改进后的模型在目标检测方面效果较好。
2.4 目标检测模型轻量化
使用轻量化目标检测模型PC-YOLOv7与C-YOLOv7进行试验,对比结果见表2,使用平均精度、传输帧数、推理延迟和参数量4个评价指标。试验结果表明,经过剪枝后的YOLOv7模型准确度较高,模型尺寸更小,计算复杂度更低。
表2 轻量化模型试验对比结果
模型 平均精度/% 传输帧数/(帧·s-1) 推理延迟/ms 参数量/G
C-YOLOv7 78.0 30 33 22.8
PC-YOLOv7 74.3 32 29 4.9
3 结论
本文提出一种改进的目标检测模型C-YOLOv7,在YOLOv7头部卷积层中添加CBAM,得到新的卷积层来替换YOLOv7中原来的卷积层,提高了模型的检测精度。对改进后的模型进行剪枝轻量化,减少模型参数量,使模型更易于部署。试验结果表明,与原模型相比,改进模型的平均精度、精度和召回率分别提升至78.0%、83.7%和74.0%;推理延迟缩短至29 ms,参数量为原模型的21.5%。
深度学习的车辆目标检测模型仍然有改进空间,例如结合视觉、雷达等多种传感器数据与检测模型进行多模态数据融合,以提高对车辆的识别能力和检测精度,并增强在各种环境条件下的适应性和鲁棒性。在保障数据安全的前提下,有效地利用大数据来提升检测算法的性能和智能化程度。
参考文献
[1]曹家乐,李亚利,孙汉卿,等.基于深度学习的视觉目标检测技术综述[J].中国图象图形学报,2022,27(6):1697-1722.
[2]张阳婷,黄德启,王东伟,等.基于深度学习的目标检测算法研究与应用综述[J].计算机工程与应用,2023,59(18):1-13.
[3]李长海.基于改进YOLOv7的红外行人目标检测方法[J].汽车工程师,2024(8):15-21.
[4]毛远宏,曹健,贺鹏超,等.深度神经网络剪枝方法综述[J].微电子学与计算机,2023,40(10):1-8.
