基于依存句法分析的术语提取方法与传统方法的实证对比
2025-01-10郝韵涵李华东王朝莹张嘉




摘 要:文章讨论了基于依存句法分析的术语提取方法,以英文海事文本为语料,对比了该方法与传统的n元模式和基于主题性的提取方法的提取效果,以探索可供非专业术语提取者利用的综合效果最佳的术语提取方法或方法组合。研究结果表明,三种术语提取方法可互为补充,基于依存句法分析的术语提取效果最佳。对于非专业术语提取者而言,基于依存句法与基于主题性的术语抽取方法相结合,能在术语提取的效率、范围和准确性三者间取得最佳平衡。
关键词:依存句法分析;术语提取;英文海事文本
中图分类号:H083;U675.87" DOI:10.12339/j.issn.1673-8578.2025.01.016
Empirical Comparison of Term Extraction Methods Based on Dependency Syntactic Analysis with Traditional Methods//HAO Yunhan, LI Huadong, WANG Zhaoying, ZHANG Jia
Abstract: This paper introduces a terminology extraction method based on dependency parsing. An empirical study was conducted by using an English maritime text to compare this method with two traditional methods, namely the n-gram pattern method and the keyness analysis method. Our aim is to explore the most useful term extraction method or combination thereof for non-expert term extractors. The results indicate that the three methods complement each other, with the dependency parsing method showing the best performance. For non-expert term extractors, a combination of dependency parsing and keyness analysis achieves the optimal balance between efficiency, scope, and accuracy.
Keywords: dependency parsing; terminology extraction; English maritime texts
收稿日期:2024-02-02" 修回日期:2024-04-15
基金项目:2017年国家社会科学基金一般项目“基于语料库的大学英语教材与学术词汇覆盖率研究”(17BYY103)阶段性成果;2021年国家社会科学基金一般项目“海洋强国视域下海事语言标准化及国际海事话语研究”(21BYY017)阶段性成果;2023年国家建设高水平大学公派研究生项目(202308310262)阶段性成果
作者简介:郝韵涵(1998—),女,上海海事大学外国语学院在读博士研究生。研究方向为海事语言及应用,专门用途英语。通信方式:202240810001@stu.shmtu.edu.cn。*通迅作者:李华东(1970—),男,上海海事大学外国语学院教授,博士生导师。现任中国逻辑学会文体学专业委员会常务理事。研究方向为海事语言及应用、教材开发、语言测试、语用学等。通信方式:hdli@shmtu.edu.cn。
在专业领域,术语的使用非常频繁。术语是专业文本中结构化的知识单元,承载了文本的核心信息[1]。识别和收集这些术语可以帮助相关从业人员更好地理解和应用相关知识,提高工作效率与质量。英语是国际海事领域的通用语言[2-3],英文海事术语的提取可以规范和促进国际海事交流与合作。
传统上,术语的提取、收集和整理工作主要依靠相关领域的专家进行,这种工作方式可以保证较高的术语提取质量,但其缺点也很明显,成本高,速度慢[4]。在当今科技高速发展、新术语不断涌现的背景下,仅靠人工进行术语提取不切实际,必须借助基于计算机语言处理技术的提取方法[5]。
近年来涌现出大量的术语提取方法,在准确性和效率两个维度都取得了一定的成绩[6]。目前,术语提取方法可分为两大类:无监督方法和有监督方法。无监督方法通常将语言学与统计学相结合。该方法具有人工干预少、适用性和一致性强的优点。但其缺点在于术语提取的准确率和召回率较低。有监督方法则使用机器学习技术,通过学习训练文本的特征来实现术语提取[7]。相较于无监督方法,有监督方法术语提取的准确率和召回率较高,但该方法存在两方面的问题:一是需要大量已标记的训练数据,这在某些ESP领域如海事英语领域较难获取;二是时间和经济成本高昂,进行大规模的人工语料标注耗时费力。
除了全国科学技术名词审定委员会等权威术语机构有专业的术语工作者从事术语提取外,海事文本的翻译人员、海事教材的开发人员、有阅读和处理海事语料需求的学生等非专业英文海事术语的开发和使用人员同样具有提取术语并构建术语库的需求。针对后者,在缺乏大规模人工标注语料且需快速处理指定的海事文本的情况下,由于无监督方法的操作较为简单高效,还能缩减进行大规模海事语料标注所需的时间和经济成本,因此这种方法可能是更好的选择。本文主要关注如何利用无监督方法进行英文海事术语提取。
在利用无监督方法进行术语提取的研究中,Andersen[8]将基于单语海事文献的术语提取方法分为四种,分别是基于n元模式(n-gram)、主题性(keyness)、搭配(collocation)和词表(word list)的术语提取方法。俞琰等[7]在进行中文专利文献的术语提取时指出,较为常见的术语提取方法可分为n元模式、名词短语分块(NP-chunking)和词性模式匹配(POS tag pattern)。
上述学者提出的几种术语提取方法具体操作流程可以简述如下:n元模式的术语提取操作通常是先去除停用词、语义信息较少的词(如助词、语气词等),或人工选择构词能力较差的词,得到文本串片段,然后进行遍历①得到所有n元连续词语序列,按照一定规则选出符合要求的多元词组,如保留词频高的词语[7]。名词短语分块的术语提取方法通常采用模式匹配结合句法规则来识别由名词短语构成的术语。词性模式匹配术语提取的基本思想与名词短语分块相同,但其匹配模式一般更为复杂。主题性的术语提取方法需要依托主题词(key word)展开。主题词定义为在给定文本中频率不同寻常的词。该词不一定是高频词,而是与某参考语料库的同一词相比,其出现的频率显著凸显[9]。
以上几种术语提取方法虽然应用广泛,但都存在固有缺陷。n元模式虽然可以较为灵活地设置术语长度,但常常会引入大量非术语词串。名词短语分块和词性模式匹配的缺陷与n元模式类似,提取的术语往往不够准确,后期需要进行大量的人工筛选。而基于主题性的术语提取方法仅能提取出由单个单词构成的术语,这就限制了提取出的术语数量和范围。综上可见,目前的几种术语提取方法均存在一定缺陷,尤其是在精准识别术语方面需要进行提升。因此,本文考虑引入一种新的术语提取方法,即基于依存句法分析的术语提取方法,并探索这种新方法是否可以弥补现有术语提取方法的缺陷。
基于依存句法分析的术语提取可通过语句单位内词语间的依存句法分析揭示词语间的语义修饰关系,进而实现对语义的理解,可以较为有效地弥补单纯依靠词性手段难以触及深层语义关系的不足[7,10]。近年来涌现出一些利用依存句法分析进行术语提取的相关研究,如俞琰等[7,10]就利用依存语法分析成功提取了中文专利文献和网络招聘文本中的中文术语,并证明了该种术语提取方法的优越性,即与现有以n元模式和名词短语分块为主的术语提取方法相比,利用依存句法分析进行术语提取具有更高的术语提取准确率。回顾以上文献,可以发现虽然利用依存句法分析进行术语提取已经得到了实际运用,但已有研究主要将这种方法应用于提取中文术语,对英文术语提取少有涉猎。Lei等人[11]构建了由4182篇国际期刊英语论文摘要构成的语料库,运用依存句法分析提取该语料库中的名词短语,根据高频名词短语梳理出会计学热门研究话题,但该文并未将术语提取作为研究目的。本文受其启发,拟借鉴Lei等用依存句法分析提取热门研究话题的有益尝试,把该方法转移到英文海事术语提取上,并同其他常见的无监督术语提取方法进行对比,以探索基于依存句法分析的术语提取方法是否具有优越性。
下文将首先介绍基于依存句法分析的术语提取方法的基本原理和算法。然后通过实验,对比传统方法和基于依存句法分析的方法进行术语提取的准确率,以确定基于依存句法分析的术语提取是否具有优越性,并为未来术语提取软件的规则编写与功能优化提供参考,也为术语提取技术的发展提供借鉴。
1" 实验过程
1.1 语料
选取合适的书面语料是进行术语提取的重要环节。本文拟以英文海事文本为例进行术语提取对比实验。首先需要对典型英文海事文本进行界定。
海事英语(Maritime English,ME)是一个伞式术语(umbrella term),也可称作一个术语集。Zhang和Cole[2]认为,海事英语是国际海事群体用于海上贸易和航行安全的语言。Andersen[8]未将海事英语局限于与海运贸易和航行安全的相关语言表达,而是进一步扩展了Zhang和Cole[2]的概念,他认为海事领域包括海面以上及以下的所有与海相关的文化及生物概念,包括海洋生物、自然资源、地形地貌、基础设施、航道等。用以阐述这些内容的英文文本就是英文海事文本。
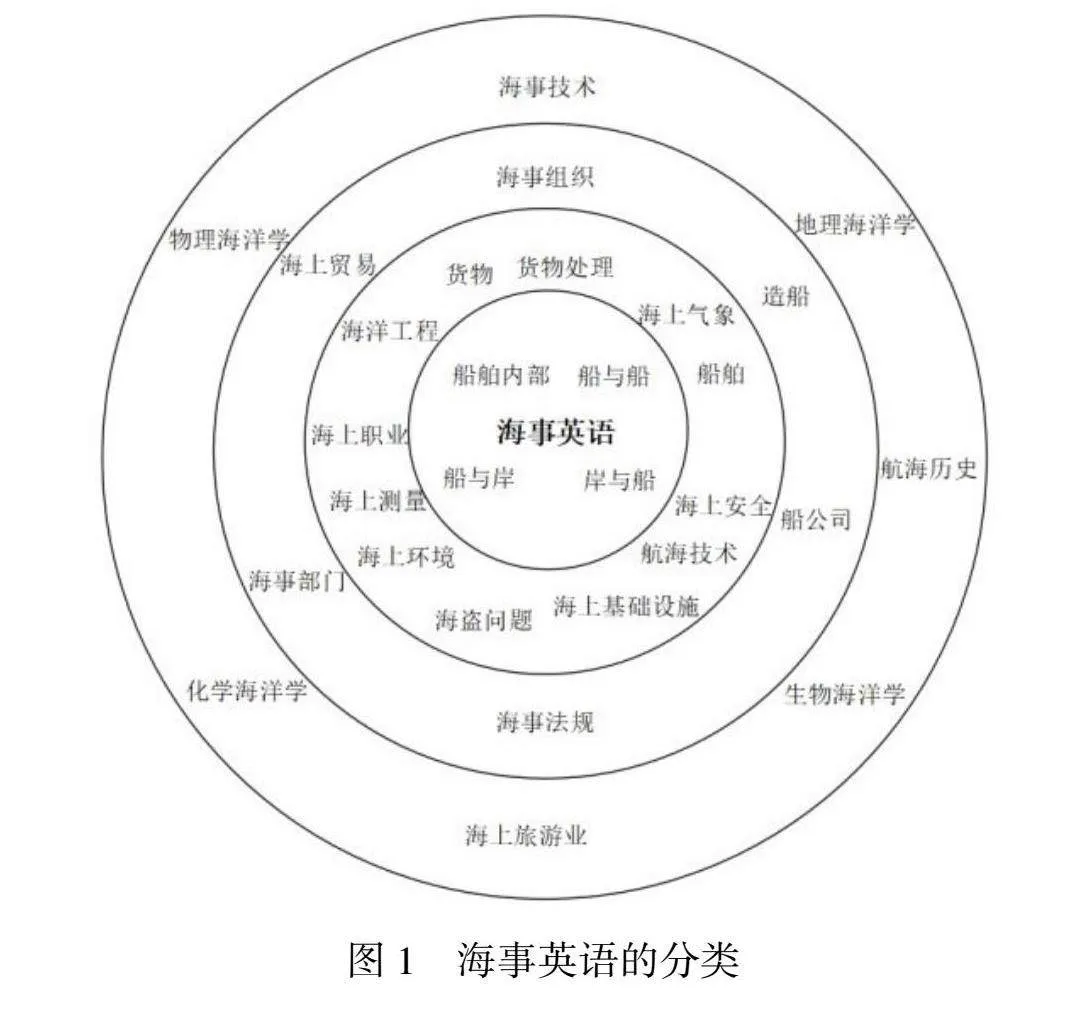
因此,本文在Andersen[8]定义的基础上,对海事英语的分类进行进一步阐述,如图1所示。即海事英语由圆心向外扩展可分为四个圈层。其中,海事英语最为核心的部分就是船舶内部、船与船、船与岸、岸与船之间的语言交际,这一圈层以口语交际为主。其次,围绕船舶航行这一主题,与货物、货物处理、船舶、海事安全、海上环境、海上气象相关的英语表达也是海事英语的重要组成部分;同心圆再向外拓展,则会涉及与航运贸易、造船、航运企业、海事法律、海事组织等相关的英文表达,这些内容也属于海事英语的范畴;同心圆最外层则是海洋历史、海上旅游、物理海洋学、化学海洋学、海洋生物学等与海洋相关的英语表达,虽然这些内容看起来与处于核心圈层的海事英语联系并不密切,但也属于海事英语。海事英语从中心开始向外扩展,其所涵盖的内容逐渐变得广泛,但这些内容与海事英语联系的紧密程度逐渐减弱。
本文将由上海海事局(Shanghai Maritime Safety Administration)于2022年12月26日发布的题为Notice of Shanghai Maritime Safety Administration on Further Strengthening Vessel Traffic Management in Changjiangkou and its Adjacent Waters的通告作为案例文本进行术语提取。该文本是上海海事局向长江口及附近水域船舶发布的交通管理通告,所有位于长江口及附近水域的船舶以及相关的船舶管理机构等都需要阅读并充分理解该通告的内容,以便对自身航行计划及船舶管理计划等进行相应调整。该文本是典型的英文海事文本。该文本若放置于图1同心圆中属于最接近核心圈层的第二层位置。由于核心圈层以口语为主,所以该文本属于最为典型的海事英语书面文本。
为避免出现后续的标注和检索错误,需要对文本进行清洗和降噪,以获得可靠统计结果[12]。对文本进行预处理之后,表1列出了文本的相关数据。我们选取小而具有代表性的文本作为验证性研究的对象,以评估多种术语提取方法的准确性。选取小规模语料库是为了使研究者能够更专注于对比和分析各种方法的表现,从而更深入地理解其优劣所在,以避免处理大规模语料可能带来的噪声和复杂性干扰。值得一提的是,即便在这样一个小规模的语料库中,也成功提取出了近千个术语候选词。
1.2 术语提取方法
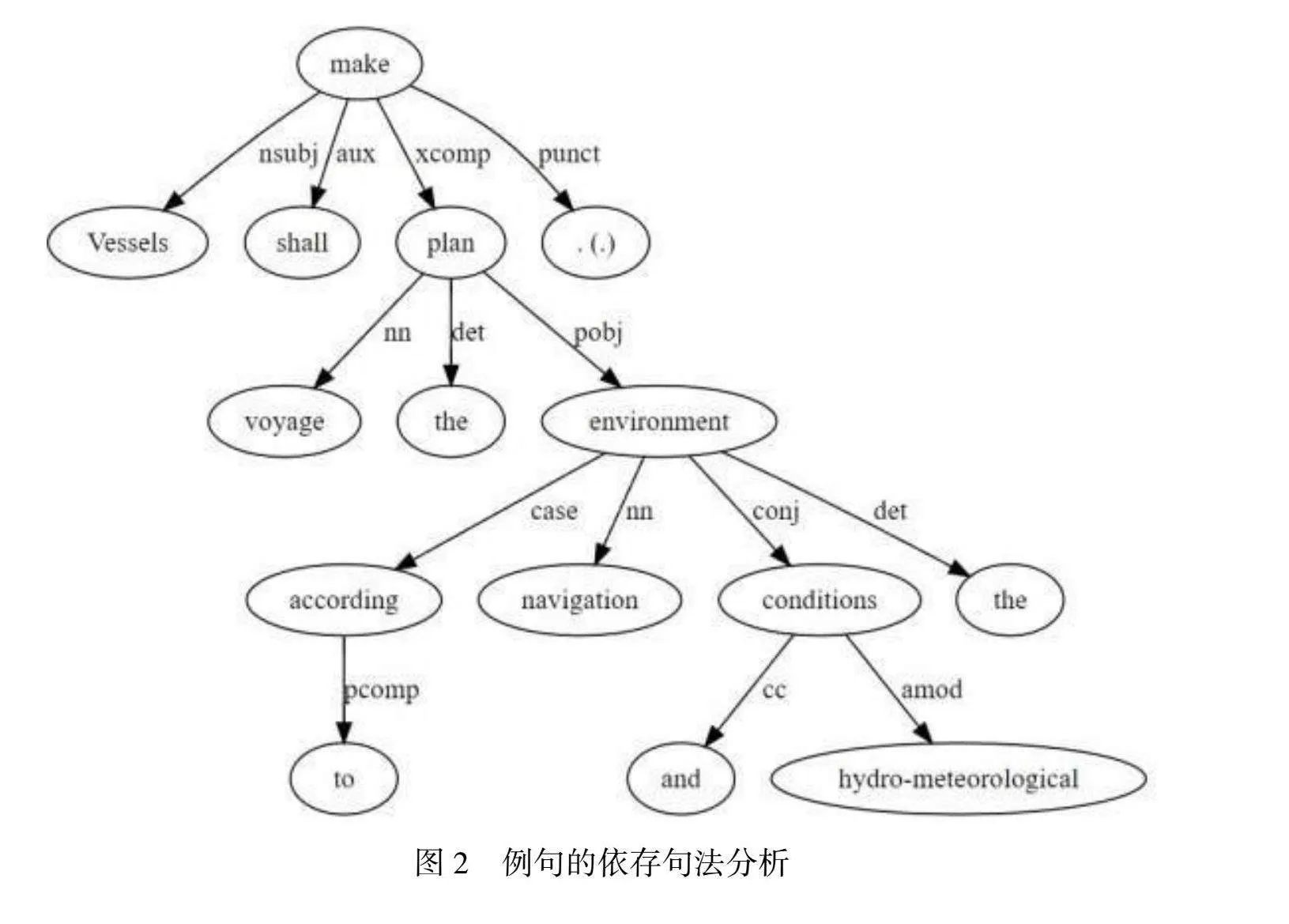
本文选取了两种传统的术语提取方法与基于依存句法分析的术语提取方法进行对比。这两种传统方法均以“词”为核心进行术语提取,分别是基于n元模式和基于主题性的术语提取方法。而基于依存句法分析的术语提取方法则突破了这一局限,更注重语句的句法特征和语义关系。依存句法结构的本质在于描述词之间的依存关系,其中一个词可能支配另一个词,这种支配关系被称为依存关系;根据依存句法假设,在语句中,核心动词是支配其他词汇的中心成分,而核心动词本身却不受其他词汇的支配,所有的受支配词语都以某种依存关系从属于支配词[7]。根据依存句法分析,句中的所有语义联系相互交织,形成了一种基于词语之间语义修饰关系的依存树结构。这种结构并不受词语在句子中的物理位置影响,能够更准确地反映句子中的语义信息[7]。本文将以案例文本中的句子“Vessels shall make the voyage plan according to the navigation environment and hydro-meteorological conditions”为例,展示基于依存句法分析的划分情况,具体如图2所示。
通过依存关系的句法分析,可以发现构成术语候选词的依存关系主要包括amod(形容词修饰语)、nn(名词复合修饰语)和poss(占有修饰语)这三种结构。具体解释如下:
(1)amod,即形容词修饰语,是指用来修饰名词短语的形容词短语[13]。以“Sam took out an unsecured loan”为例,其中的unsecured为loan的形容词修饰语。
(2)nn,即名词复合修饰语。一个名词短语的名词复合修饰语是指任何用来修饰核心名词(head noun)的名词,通常在句子中呈现“名词+名词”的搭配结构[13]。例如在“Oil price futures”这个短语中,oil同price、price同futures都可以构成nn的依存关系。
(3)poss,即占有修饰语,存在于名词短语的中心名词与其所有格限定词或所有格补语之间。以Bill’s clothes为例,Bill就是clothes的占有修饰语[13]。
根据图2的依存关系划分,可以发现“voyage plan”“hydro-meteorological conditions”这两个词可以构成术语候选词。“voyage plan”更倾向于构成nn的依存关系,而“hydro-meteorological conditions”则更符合amod的依存关系②。
本文利用Stanford Parser工具对案例文本进行基于依存句法分析的术语提取。为了与此方法进行对比,本文还利用语料库工具AntConc进行传统的术语提取,主要基于两种传统方法:即基于n元模式的术语提取和基于主题性的术语提取。在用这两种传统方法进行术语提取过程中,需要准备词元列表(Lemma List)和停用词表(Stoplist),以防止同一单词的不同词形和常用功能词对结果产生干扰。为了实现基于主题性的术语提取,需要选择一个参照语料库。本文选用英国国家语料库(British National Corpus,BNC)③作为参照语料库,它由多个权威机构共同创建,是目前全球最大的现代英语语料库之一。
1.3 术语的筛选、认定和评估标准
完成术语候选词的提取后,需要对其进行人工筛选和认定,这涉及术语审定工作。官方对术语的审定是一个严格且漫长的过程。根据《全国科学技术名词审定委员会科学技术名词审定原则及方法(修订稿)》,科技名词的审定工作首先需要确定学科,组建分委员会,进行三轮审定工作并多次召开审定工作会议之后才能进入批准预公布阶段。在经过1年的预公布期后,科技术语才能够被批准正式公布。
通常,官方认定的科技术语数量相对有限,且术语的产生和更新速度相对较慢。然而,每天都有大量的英文海事文本涌现,非专业术语开发和使用人员经常会遇到官方公布的科技术语表之外的术语候选词。因此,他们需要快速筛选和认定大量新术语。如果完全按照官方的术语审定流程确定术语并构建术语库,将导致他们的工作难以顺利进行。
针对上述问题,非专业术语开发和使用人员可以采用Andersen[8]提出的术语筛选和认定方法,将术语候选词分为三类:有效术语(Valid,简称V)、部分有效术语(Partially Valid,简称P)和非术语(Discarded,简称D)。石立坚[14]认为,术语可以分为一般术语和专业术语;一般术语适用于多个专业领域,而专业术语则主要适用于某一特定专业领域。专业术语在该特定专业领域的文本中通常具有较高的出现频率,而在其他领域文本中则较少出现[4]。在此背景下,本文中的有效术语相当于石立坚所指的专业术语,即明显属于海事领域的术语,如“vessels”“navigation”“sailing”等;部分有效术语相当于一般术语,这类术语不仅适用于海事领域,也适用于其他多个专业领域,如“traffic”“overall efficiency”等;而非术语则是指不具备术语性质的单词、短语或词串,如“on”“or the”“the tianjin”等。通过这种方式,非专业术语开发和使用人员能够更高效地进行术语筛选和认定工作。
本文将使用严格的术语准确率(strict accuracy,As)和宽松的术语准确率(lenient accuracy,Al)两种计算方法来评估各术语提取方法的准确率。
As=VV+P+D×100%""" (1)
Al=V+PV+P+D×100%""" (2)
2 实验结果与讨论
2.1 基于n元模式的术语提取
实验使用AntConc软件中的“n-gram”功能进行术语提取,并将n的取值范围设定为1~4[15-16]。由于基于n元模式的术语提取方法会产生大量术语候选词,为了提高筛选效率,实验规定术语候选词的出现频率需至少达到2次。表2为部分术语候选词列表及其标注情况(节选)④。
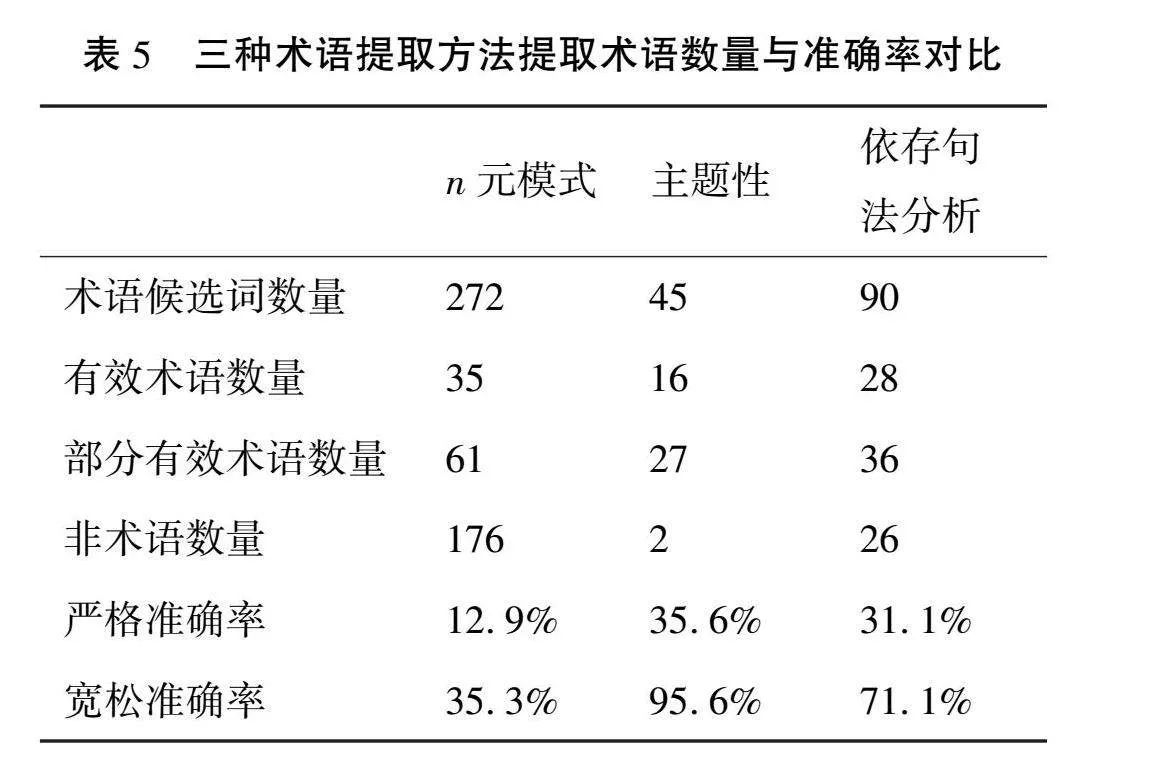
基于n元模式的术语提取方法,共提取出272个术语候选词。经过筛选和认定,其中35个为有效术语,61个为部分有效术语,而176个被判定为非术语。根据这些数据,严格术语准确率为12.9%,而宽松术语准确率为35.3%。
2.2 基于主题性的术语提取
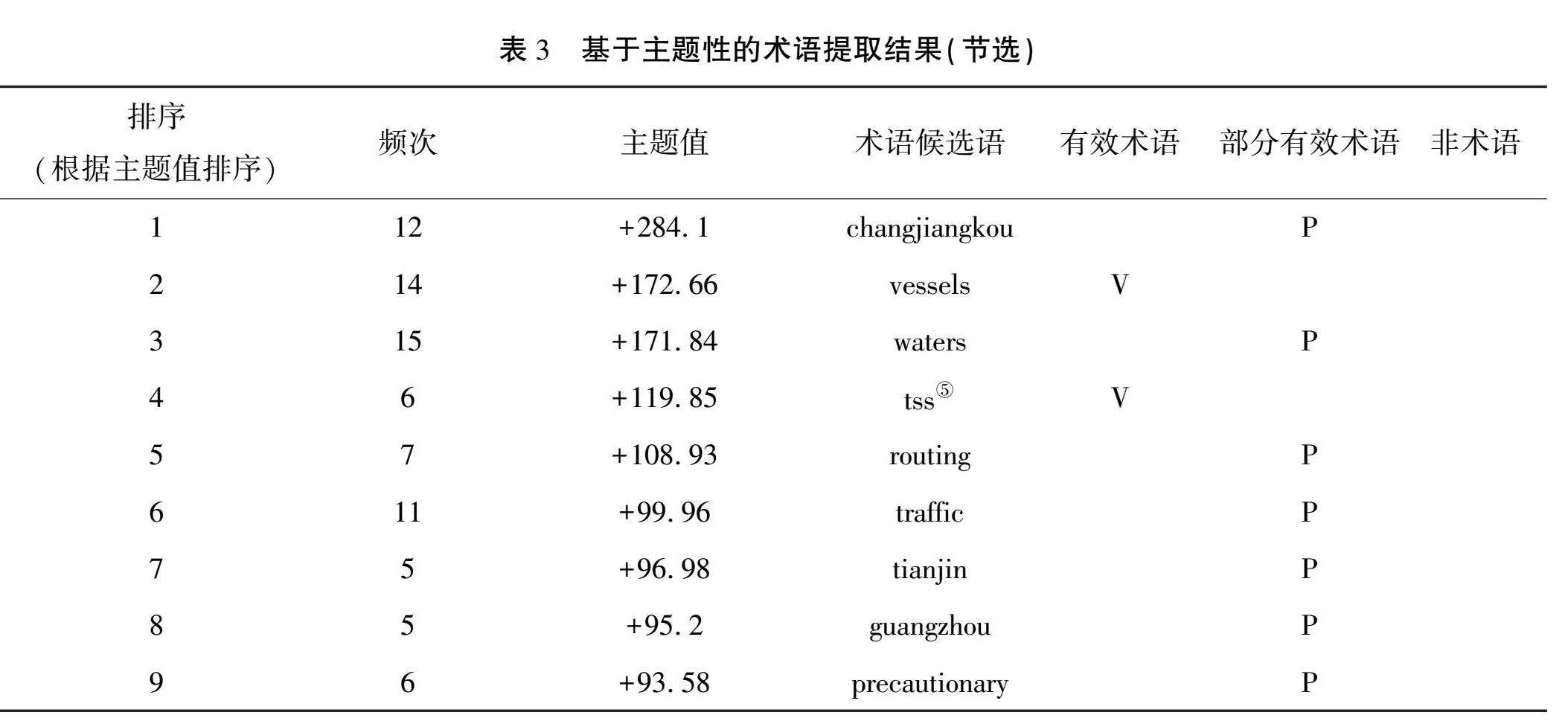
实验采用AntConc软件中的“Keyword List”功能进行术语提取,并上传了参考语料库BNC的词表,其中包含了各单词在BNC中的出现频率。以下是术语候选词列表及其标注情况(节选),具体内容如表3所示。
主题值带“+”符号,是因为与BNC参考语料库相比,这些术语候选词在案例文本中的出现频率明显较高,因此主题值为正值。
在表3中,出现了一些地名,如“changjiang-kou”“tianjin”“guangzhou”。对于这些地名,本文将其认定为部分有效术语。原因在于,“changjiang-kou(长江口)”作为长江黄金水道的咽喉,对长江中上游航运发展具有直接影响,因此与航运产业紧密相关,可视为部分有效术语。而“tianjin(天津)”“guangzhou(广州)”虽然是城市名,但天津和广州作为重要的港口城市,其港口与航运产业有着密切联系。天津港和广州港分别是京津冀地区和粤港澳大湾区的综合航运枢纽,是我国南北运输大通道的重要物流节点。因此,“tianjin”“guangzhou”也可视为部分有效术语。
基于主题性的术语提取方法共提取出45个术语候选词。其中,有效术语16个,部分有效术语27个,非术语2个。根据这些数据,严格术语准确率为35.6%,而宽松术语准确率达95.6%。
2.3 基于依存句法分析的术语提取
实验使用Stanford Parser工具对案例文本进行依存句法分析,并提取了标记为amod、compound和poss这三类依存关系的术语候选词。以下是术语候选词列表及其部分标注情况(见表4)。
表4中可以看到“Precautionary A”,实际上在基于依存句法分析的术语提取完整列表中,还存在“Precautionary B”。这两个短语分别代表长江口的A警戒区和B警戒区。判定这两个短语是不是术语,需要了解术语和名称的区别。名称是继术语之后划分出来的一类专业词汇,它包括自然科学名称、技术产品名称以及商业名称,其中的自然科学名称就相当于术语[17]。列福尔马茨基[18]明确指出,术语与特定的科学概念系统紧密相关,而名称仅仅是为客体赋予标签。按一定顺序排列的一串字母(如维生素A、维生素B、维生素C等)或数字(如МАГ-5、МАГ-8等)以及其他随意规定的符号都属于名称,它们并不反映科学概念系统。在此背景下,案例文本中的“Precautionary A”“Precautionary B”更接近于名称概念,而非术语,因此在本文中这两个短语被认定为非术语。
与此相关,本案例中还出现了短语“Precautionary Areas(警戒区)”,它是不是有效术语呢?根据国际海事组织(IMO)[19]的解释,“Precautionary Areas”是指船舶在特定区域内航行时需要特别谨慎,并且建议按照推荐的交通流向行驶的区域。“Precautionary Areas”具有明显的海事专业特征,因此在本文中被认定为有效术语。
基于依存句法分析的方法共提取出90个术语候选词,其中有效术语28个,部分有效术语36个,非术语26个。根据这些数据,严格术语准确率为31.1%,而宽松术语准确率则为71.1%。
表5列出了三种术语提取方法准确率的对比。
就准确率而言,基于主题的术语提取方法在三种方法中表现最为出色,其次是基于依存句法分析的术语提取方法,最后是基于n元模式的术语提取方法。
然而,这并不意味着基于主题性的术语提取方法是最佳选择。虽然该方法提取出的术语准确性较高,但这些术语都由单个单词构成,导致大量由两个或多个单词构成的术语被排除在外,这不仅限制了术语提取范围,也大大限制了术语提取数量。由表5可见,这种方法提取到的有效术语和部分有效术语的数量都是最少的。
基于n元模式的术语提取方法存在明显的缺陷。该模式会提取出大量的非术语词串,导致术语提取准确率较低。在后续的术语筛选和术语表编制等工作中,需要大量人工介入。但该模式的优点在于可以通过调整n值灵活地提取出由单个、两个或多个单词构成的术语,这是基于主题性和基于依存句法分析的术语提取方法无法实现的。
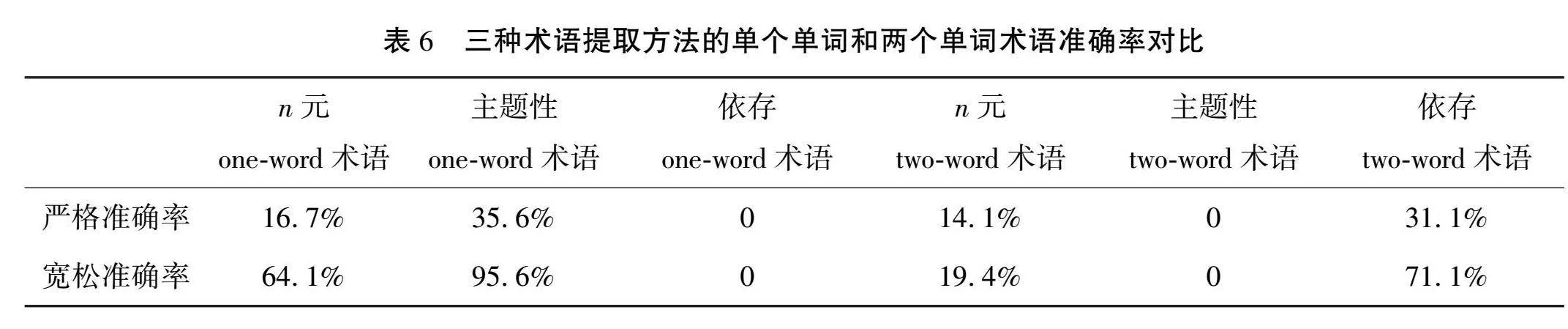
基于依存句法分析的术语提取方法在准确率方面表现良好,远超基于n元模式的方法,较为接近基于主题性的方法。在术语提取范围方面,该方法提取出的术语主要以两个单词构成的术语为主。
表6展示了使用三种术语提取方法提取出的术语候选词中,由单个单词和两个单词所构成术语的准确率情况。根据Justeson和Katz[20]的研究,英文术语普遍由两个单词构成,很少出现由单个单词构成的术语,因为这样的术语容易造成语义模糊。两个及以上单词构成的术语,往往语义更为明确,这样就可以确保每个术语只有一个明确的含义。从表6的数据可以看出,基于依存句法分析的术语提取方式在提取两个单词构成的术语时准确性最高,这说明基于依存句法分析的术语提取方法与另外两种方法相比具有明显的优越性,即符合普遍英文术语的双词构成模式,所提取的术语语义更为明确,有效术语更多[20]。
综上所述,基于主题性的术语提取方法将术语以词表形式展示,基于依存句法分析的术语提取方法主要提取出由两个单词构成的术语,而基于n元模式的方法则可以提取出由三个或更多单词构成的术语。如果目标是编制术语表或构建术语库,这三种术语提取方法可以相互补充,以满足不同的需求。
然而,需要注意的是,基于主题性的术语提取方法仅能提取出由单个单词构成的术语,这可能导致语义模糊。同样,基于n元模式的方法在提取术语时的准确率较低。相比之下,基于依存句法分析的术语提取方法在准确率、术语范围和数量方面的表现均较为出色。该方法提取出的术语符合普遍的英文术语构成模式,其含义和语义都较为明确。因此,基于依存句法分析的术语提取方法具有一定的优越性。
对于非专业的英文术语开发与使用者而言,将基于依存句法分析的方法与基于主题性的方法相结合进行术语抽取是一种比较可靠的方法。该方法既能保证较高的准确率,同时又能涵盖由单个单词和两个单词构成的术语范围,从而实现术语提取效率、范围和准确性三者之间的最大平衡。
3 结论
本文利用AntConc和Stanford Parser软件,以上海海事局发布的长江口及其附近水域船舶交通管理通告的英文文本作为语料进行了三种术语提取方法的实践,并对这三种方法的提取效果进行了对比。研究发现,三种方法可以互为补充,而基于依存句法分析的术语提取效果更佳。对于非专业的英文海事术语开发及使用人员来说,将基于依存句法分析的方法与基于主题性的方法结合起来进行术语抽取是一种相对可靠的策略。
虽然之前已有研究者利用依存句法分析在中文术语和英文研究热点话题提取方面取得了一些成果,但本文首次将依存句法分析应用于术语提取。通过对比实验发现,基于依存句法分析的术语提取方法在效果上优于一些传统的无监督方法。这一发现不仅为术语提取软件的规则编写和功能优化提供了指导,同时也为术语提取技术的进一步发展提供了启示。
在后续研究中,建议使用更多无监督方法,针对更大规模、更多语类的语料进行实验,以评估这些无监督术语提取方法在更复杂、更多样场景下的表现。通过更加客观、全面的对比,可以较为准确地了解基于依存句法分析的术语提取方法是否具有优越性。
注释
① 遍历是指按照一定的规则和顺序访问一个数据结构中的所有元素。具体来说,使用n元方法进行术语提取时,遍历指的是对文本中的每个可能的n元组合进行逐个检查,以确定它们是否构成术语。
② 值得注意的是,上述示例对依存关系的划分存在一定的争议。例如“voyage plan”应被界定为nn还是amod的依存关系尚无定论。但无论界定为何种依存关系,都不影响术语提取的准确性。
③ 英国国家语料库由英国牛津出版社﹑朗文出版公司﹑牛津大学计算机服务中心﹑兰卡斯特大学英语计算机中心以及大英图书馆等联合开发建立,于1994年完成。BNC是目前网络可直接使用的最大的语料库之一,也是目前世界上最具代表性的当代英语语料库之一。
④ 由于完整的列表较长,表2、3、4仅展示部分容易引起争议的术语候选词。
⑤ tss(Traffic Separation Scheme)的中文名称为分道通航制,是由国际海事组织(IMO)所设置的海上交通管理路线系统。该系统用分隔带、分隔线、天然障碍物或明显的地理物标等将航道分隔成左右两个通航分道,实行单向通航。
参考文献
[1] 赵志刚. 英语海事公文的语言特点及翻译[J]. 上海海事大学学报, 2014, 35(2): 89-94.
[2] ZHANG Y, COLE C. Maritime English as a code-tailored ESP[J]. Ibérica, 2018, 35: 145-170.
[3] 李天娇,尚新.中国海事英语研究的知识图谱分析[J].上海海事大学学报, 2019, 40(4):118-124.
[4] 常宝宝.科技术语自动提取技术: 现状与思考[J].中国科技术语, 2022, 24(1):3-13.
[5] 卡拉·沃伯顿,宋楠楠,朱波. 面向翻译管道的术语加工[J]. 中国科技术语, 2019, 21(5):16-21, 27.
[6] 张雪,孙宏宇,辛东兴,等.自动术语抽取研究综述[J]. 软件学报, 2020, 31(7): 2062-2094.
[7] 俞琰,陈磊,姜金德,等.基于依存句法分析的中文专利候选术语选取研究[J]. 图书情报工作, 2019, 63(18):109-118.
[8] ANDERSEN G. Utilising heterogeneous language resources for term extraction in maritime domains[J]. Terminology, 2022, 28(1): 1-36.
[9] SCOTT M. PC analysis of key words: and key key words[J]. System, 1997, 25(2): 233-245.
[10] 俞琰, 陈磊, 姜金德, 等. 网络招聘文本技能信息自动抽取研究[J]. 图书情报工作, 2019, 63(13): 105-113.
[11] LEI L, DENG Y, LIU D. Examining research topics with a dependency-based noun phrase extraction method: a case in accounting[J]. Library hi tech, 2023, 41(2): 570-582.
[12] 卢一鑫. 基于语料库的对外汉语教学领域术语提取[J].中国科技术语, 2024, 26(1):11-18.
[13] DE MARNEFFE M C, MANNING C D. Stanford typed dependencies manual [R]. Technical report, Stanford University, 2008.
[14] 石立坚. 有关术语的几个问题[J]. 自然科学术语研究, 1988(2): 26-34.
[15] SINCLAIR J, JONES S, DALEY R. English Collocation Studies: The OSTI Report [M]. London: Continuum, 2004.
[16] STUBBS M. Words and phrases: Corpus studies of lexical semantics [M]. Oxford: Blackwell publishers, 2001.
[17] 曲唱,孙寰. 基于《冰区船舶快速性》文本的俄汉双语术语库建设研究: 以创建“海冰”主题术语表为例[J]. 中国科技术语, 2022, 24(2):55-64.
[18] 列福尔马茨基А A. 什么是术语和术语集[J]. 叶其松, 译. 俄语语言文学研究, 2011, 34(4): 65-70.
[19] International Maritime Organization (IMO). Ships’ routeing [EB/OL]. [2024-01-06]. https://www.imo.org/en/OurWork/Safety/Pages/ShipsRouteing.aspx.
[20] JUSTESON J S, KATZ S M. Technical terminology: some linguistic properties and an algorithm for identification in text[J]. Natural Language Engineering, 1995, 1(1): 9-27.
