图模驱动的在线医疗健康智慧问答服务研究
2025-01-04张君冬刘江峰邓景鹏刘艳华黄奇

摘 要: [目的/ 意义] 学者们重视追求医疗智慧问答相关技术本身的前沿性, 对基础理论的探讨研究较少,两者未能融合发展。[方法/ 过程] 在辨析相关概念的基础上, 首先阐述在线医疗健康领域智慧问答服务的内涵及特征, 之后剖析知识图谱与大语言模型的联系及两者的互补融合思路, 最后提出图模驱动的在线医疗健康智慧问答服务。[结果/ 结论] 文章将医疗智慧问答服务理论特征贯穿智慧问答服务的全过程, 创新性地提出其智慧问答服务应包含大语言模型驱动的医疗知识图谱构建、知识图谱增强的医疗大模型训练、图模驱动的智慧问答服务流程三部分。本研究实现了理论与技术的有机结合, 研究成果可用于后续医疗智慧问答的实践性工作。
关键词: 知识图谱; 大语言模型; 在线医疗健康; 智慧问答服务
DOI:10.3969 / j.issn.1008-0821.2025.01.012
〔中图分类号〕R197. 3 〔文献标识码〕A 〔文章编号〕1008-0821 (2025) 01-0164-13
2019 年, 国务院印发《国务院关于实施健康中国行动的意见》, 指出要将优化健康服务、普及健康知识、构建健康环境放在更加突出的位置。近年来, 随着生活方式与生存环境的急剧变化, 以及互联网、大数据技术和移动设备的快速普及, 人们越来越倾向于通过在线医疗平台获得健康知识, 以实现对自身健康状况的控制和管理[1] 。就理论层面来讲, 智慧问答服务作为自动问答服务领域的高阶进程, 与当下主流的“智能问答” “智慧服务” 等概念息息相关, 尚未有学者对此进行辨析和梳理。就技术层面来讲, 学者们围绕各类相关技术进行了广泛地探索, 主要分为两类: 一类是以知识图谱驱动的自动问答研究, 如疾病知识图谱的自动问答系统优化研究[2] 、融合知识图谱的中文医疗社区自动问答研究[3] , 其优势在于答案准确度高, 可解释性强,但缺乏对复杂问题的处理能力及上下文信息的语义连贯性, 实际应用并不广泛; 另外一类是用于医疗健康领域自动问答的垂直大语言模型, 如ChatDoc⁃tor[4] 、BianQue[5] 等, 尽管凭借其强大的语义理解力获得广泛认可, 然而大模型回答的结果并不完全准确且缺乏可解释性, 用户很难理解模型如何得出特定结论或生成特定文本, 这也限制了模型在关键任务中的可用性。
其中, 一个共性的关键问题是: 人工智能技术的迅猛发展, 使得现有研究多追求技术本身的前沿性, 对基础理论的探讨研究较少, 两者未能融合发展, 这也使得现有的自动问答服务仍停留在“智能”而非“智慧” 层面。因此, 如何结合智慧问答理论内涵及特征, 融合现有主流的人工智能问答技术,设计出一套完整的服务模式以加速其智慧化转型,是当前医疗健康自动问答领域的重要问题。
综上, 本文在分析国内外现有研究的基础上,辨析在线医疗健康“智慧问答服务” 与“智能问答”“智慧服务” 等相关概念的区别, 探讨在线医疗健康领域智慧问答服务内涵, 阐述数智时代下医疗智慧问答服务所需特征, 深度剖析知识图谱和大语言模型的各自优势及两者在智慧问答领域的互补融合思路, 最终提出图模驱动的在线医疗健康智慧问答服务, 本研究实现了知识图谱与大语言模型的深度融合及优势互补, 突破了现有知识问答研究方法的局限, 可为医疗健康领域的智慧化转型贡献新的思路和方法。
1 相关研究
1. 1 理论概念辨析
1) 在线医疗健康“智慧问答” 与“智能问答”
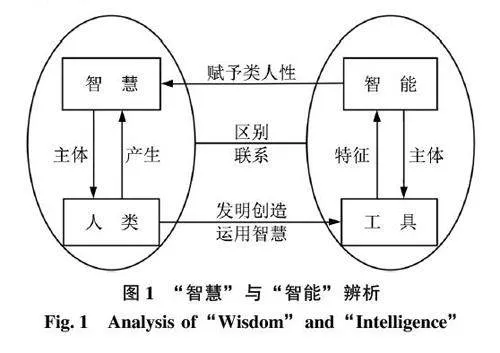
“智慧问答” 与“智能问答” 两者均属于自动问答, 其区别在于“智慧” 和“智能” 二词。图1列出了“智慧” 与“智能” 两者的辨析图, 可以发现“智慧” 与“智能” 两者虽相辅相成, 却各执其蕴。
“智慧” 一词在《辞海》中指人对事物能认识、辨析、判断处理和发明创造的能力[6] 。智慧体现为一种全新的创造性思维形式, 是人类在现有知识基础上, 通过大脑进行更高层次的加工和再运用, 以形成解决新问题的能力[7] 。人作为智慧的主体, 思考力、理解力都是其智慧的体现[8] 。“智能” 一词在《辞海》中的释义是智力与才能[6] , 与“智慧”相比, 其主题更多侧重于技术, 这类技术是人类运用智慧发明创造的产物, 可通过模拟人类处理数据的能力高效解决问题, 但不具备人类固有的思考能力及道德约束力, 仅可称之为工具[7] 。
因此, “智能” 并不等同于“智慧”, “智能”停留在工具自动化处理数据层面, 而“智慧” 一词本身仅针对人类, 不仅包含了知识和技能的应用,还涵盖了人类的思考力、理解力和创新能力。“智慧” 一词的范畴远远大于“智能”, “智能” 是模拟人类部分智慧能力的体现, 现有的智能技术、智能工具需要赋予其“类人性” 方能形成人类所具备的“智慧”。
具体到医疗健康领域, “智能问答” 更多地体现为通过机器学习、人工智能、自然语言处理等技术, 自动化处理各类医疗数据以提高医疗问答效率[9] 。“智慧问答” 则不仅仅是对医疗数据的分析和处理, 而需要深层次地理解医疗问题, 并针对患者的具体情况, 结合多维度信息(如病史、生活习惯、遗传信息等), 提供最适合的医疗建议和治疗方案。
2) 在线医疗健康“智慧问答服务” 与“智慧问答”
“智慧问答” 强调的是智慧化的回答, 侧重于回答质量的智慧性, 是提供智慧问答服务的前提条件。“智慧问答服务” 则以用户的需求为切入点,利用新的技术或手段, 完成产品的智慧化服务, 注重整个问答服务的全过程, 如程秀峰等[10] 认为, 智慧问答服务需要运用云计算、物联网和人工智能等关键技术, 感知用户需求, 识别用户兴趣偏好, 提供高准确性问答。刘泽等[11] 从数据驱动的视角出发, 构建了图书馆领域的智慧问答服务模型。张传洋等[12] 从数智化转型视角出发, 结合目前我国健康医疗信息化的发展现状, 依据信息生命周期管理理论, 构建了数智化医疗信息利用与服务模式框架。
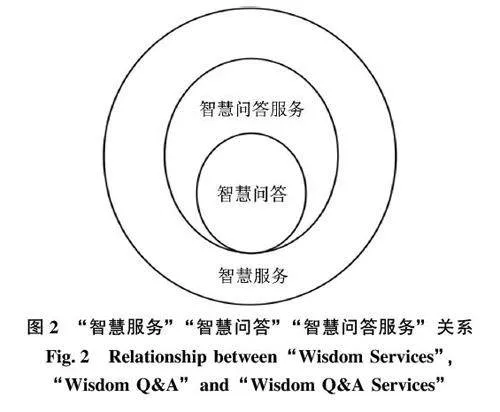
“智慧问答服务” 作为“智慧问答” 的延伸, 如图2 所示, 其智慧性不仅仅体现在回答内容, 更强调数智赋能服务模式的转变, 也是“智慧问答” 的最终落脚点。因此, 本文认为在线医疗健康领域的智慧问答服务是借助现代信息技术、网络技术、智能技术等, 基于不同的用户信息需求, 改进传统的医疗服务模式, 实现健康知识的学习、传播, 进而为用户自我健康管理提供便捷化的服务。
3) 在线医疗健康“智慧问答服务” 与“智慧服务”
近年来, 伴随着大数据技术、人工智能技术突飞猛进的发展, 特别是在深度学习、自然语言处理、知识融合、机器学习领域的研究取得了实质性的成果, 图书情报领域继文献服务、信息服务、知识服务后又迎来智慧服务这一新发展阶段[13] 。
目前, 图情领域学者们围绕“智慧服务” 这一概念已展开初步的理论探讨, 如苏新宁[14] 提出, 未来知识服务会突破文献服务的框架走向智慧服务新形态。柯平等[15] 强调了数据和智能技术为核心的数智融合, 认为智慧服务是后知识服务的重点内容。李晓妍[16] 认为, 智慧服务是面向内容理解的主动服务模式, 能够充分利用人工智能与大数据的技术跃迁, 嵌入产业技术创新全流程, 使情报服务具有超前研判、预测预警、前沿发现等智慧化能力, 提供技术决策布局、技术解决方案等具有智慧的情境服务。王秉等[17] 从情报安全的视角出发, 分析了智慧服务体系的运作过程与服务模式。郑荣等[18]从产业竞争情报的视角出发, 对智慧服务相关概念做出了界定。本文将前人已有相关研究观点迁移到医疗健康领域, 认为在线医疗健康领域的智慧服务以多源健康大数据为基础, 借助数智赋能的思想,依托人工智能、知识图谱等相关技术, 实现健康知识挖掘与发现, 从而完成自动化、精准化、个性化的健康服务。
“智慧问答服务” 与“智慧服务” 的区别在于“问答” 二字, 从表述上来看, “智慧服务” 涵盖了服务的所有模式或方法, 而“智慧问答服务” 仅专注于问答这一形式。因此, 智慧问答服务可以被视为智慧服务的一个具体实例或子集, 如图2 所示,专注于通过问答方式提供知识, 运用大数据、人工智能等先进技术来理解和回答用户的问题, 同时注重深层次的理解和情境分析, 智能化、敏捷化、自动化地分析, 力求为用户提供最优的解决方案和建议, 以满足用户的健康需求。
1. 2 在线医疗健康智慧问答相关技术研究进展
技术研究进展方面, 考虑到智慧问答属于自动问答发展的高阶进程, 而目前尚未有学者真正从实践层面上实现智慧问答, 因此, 本部分从涵盖范围最广的自动问答概念入手, 了解目前与智慧问答相关的前沿技术, 为后续在线医疗健康智慧问答服务模式的构建奠定技术基础。
传统依靠“人工疾病救治” 模式难以应对当前用户日益增长的健康保健和慢性病管理需求。近年来, 随着大数据、云计算、物联网、移动互联等现代信息技术的高速发展, 在线医疗健康自动问答服务应运而生, 早期的自动问答服务主要依靠关键词匹配的方式进行回答, 这种方法准确率相对较低, 难以处理复杂的用户咨询, 此后随着人工智能的进一步迅猛发展, 学者们集中研究如何通过前沿技术的利用进行自动问答, 如曹明宇等[19] 识别用户问题中的实体, 结合TF-IDF 和词向量生成句子向量, 匹配最相似的问题模板, 最后根据模板的语义及问题中的实体, 到知识图谱中检索答案。陈明等[20] 提出一种融合医疗知识图谱的命名实体识别模型, 以解析医疗问句中的实体和关系, 有效提升了现有医疗智能问答的准确率。
尽管现有诸多学者基于知识图谱对在线医疗健康自动问答领域进行了有效探索, 但仍存在以下问题[21] : ①用户的问题中可能包含模糊、多义性或特定领域的术语, 理解这些术语需要高级的自然语言处理能力; ②语境理解和长期依赖。用户的提问可能涉及上下文关系或需要长期记忆的理解, 传统知识图谱在处理这类需求时存在局限; ③交互性和对话管理。知识图谱通常不擅长处理连贯的对话或交互性问题。随着大语言模型时代的到来, 在线医疗健康自动问答领域迎来了新的发展机遇。
大语言模型(LLM, Large Language Model)是一种由包含数百亿以上权重的深度神经网络构建的语言模型, 采用自监督学习方法对大量无标记数据进行训练, 以递归的方式生成高质量的自然语言文本[22] 。自2022 年11 月ChatGPT(Chat GenerativePre-trained Transformer)发布以来, 大语言模型引起全世界广泛关注。用户可以通过自然语言的方式提问各种问题, 模型会尝试在理解问题的上下文语义的基础上生成相应的回答。大语言模型的引入解决了传统知识图谱面临的诸多挑战, 提高了对模糊、多义性查询的理解能力, 增强了语境理解和长期依赖的处理能力, 提升了交互性和对话管理的效率。然而用户和开发者难以理解其生成回答的具体原因。此外, 由于训练数据的质量差异导致大语言模型可能生成误导或偏差的信息, 这也限制了模型在关键任务的实际应用。
总的来说, 现有医疗智慧问答相关技术为本研究的开展提供了一定的基础, 但多停留在知识图谱或大语言模型等智能技术的直接利用, 本质上仍为“智能” 问答, 尚未触及智慧问答层面。因此, 有必要从理论角度厘清数智时代在线医疗健康智慧问答服务的核心内涵与理论特征, 在此基础上, 围绕其理论特征, 探索现有主流问答技术在医疗智慧问答领域的互补融合策略, 构建一个全面、高效、灵活的在线医疗健康智慧问答服务模式, 以满足当前用户日益增长的健康信息需求。
2 在线医疗健康智慧问答服务内涵及特征
2. 1 在线医疗健康智慧问答服务内涵
针对在线医疗健康领域, 智慧问答服务的应用广泛且多样, 如智能分诊、疾病诊断、保健养生等。鉴于学界对智慧问答服务尚未形成统一的概念界定,也未形成系统规范的智慧问答服务框架模型, 本文亦无意对其下精确的定义, 为方便理解, 这里仅说明对其的一些认识。
在前文所述的“智慧问答” “智慧服务” 等概念的基础上, 本文借鉴罗立群等[13] 对智慧服务认识的三层含义, 并将其迁移到在线医疗健康问答领域, 由此给出了本文在线医疗健康智慧问答服务的以下三层内涵:
1) 数据驱动的智能分析: 依托大数据、人工智能等技术处理来自医疗健康领域的多源大数据,如电子病历、药物反应数据等, 通过不断从数据中提炼信息、知识, 形成智慧, 为医疗决策、疾病诊断、治疗方案的制定和健康管理提供支持。
2) “类人” 的情报处理能力: 专注于模拟人脑情报对话及思维处理能力, 如对医疗数据的深度理解、逻辑推理和决策分析等方面。通过处理复杂的医疗信息, 理解患者的病史、诊断信息、治疗方案等, 并基于这些信息进行综合分析和推理。此外,还能参考最新的医疗研究成果, 为医生提供最优的治疗建议。
3) 符合人类价值观: 智慧问答服务不仅是技术和数据的集合, 更整合了文化、伦理、道德等诸多人类社会属性。文化方面, 在线医疗智慧问答服务需考虑不同地区患者的文化背景, 以提供符合用户习惯和期望的咨询服务。伦理方面, 智慧问答服务提供者必须遵循严格的伦理规范, 尊重患者的自主决策权, 确保他们在充分知情的情况下做出自己的医疗决定。道德方面, 在线医疗服务应坚持以人为本的原则, 服务提供者应确保信息的准确性和及时性, 不夸大或误导用户, 提供公平和无歧视的服务。
在此过程中, 医生、患者、医疗机构等各方主体共同参与, 形成了情报流、知识流、思想流的交互与融合。通过整合这些信息, 形成具有深度理解和智慧的情报产品, 以支持医疗决策、创新发现和问题解决, 实现知识价值的提升。
2. 2 在线医疗健康智慧问答服务特征
作为智能技术与人类智慧交叉融合的产物, 在线医疗健康智慧问答服务正逐渐成为医疗行业数字化转型的核心驱动力。这一服务模式不仅要求技术层面的创新, 更需要将人类的智慧特征与技术紧密结合, 从而提供医疗智慧化解决方案以满足用户深层次的需求。本研究通过梳理现有相关文献, 共总结数智时代下在线医疗健康智慧问答服务所需的6个关键特征, 旨在为后续服务模式的构建奠定坚实的理论基础。
1) 医学知识理解力
高级自然语言理解意味着模型不仅能够识别和处理用户的文字输入, 还能理解医学领域复杂的语言结构、隐含的意图和情感, 可以准确地捕捉到用户的信息需求, 从而提供更相关、更深入的回答[23] 。此外, 这种理解能力还包括对不同文化、地区习惯和语言差异的适应, 从而能够服务于更广泛、多样化的用户群体。
2) 医学对话能力
对话式可以使模型能够理解、记忆并参照历史, 从而在一系列相关问题中提供连续性和一致性的回答[24-25] 。此外, 能够更灵活地处理模糊或不完整的查询, 通过追加问题来精确用户的需求, 实现更加深入和个性化的信息交流。
3) 上下文感知
上下文感知确保问答服务能够理解和解释患者问题的具体上下文[26] , 如健康状况和症状的严重程度, 提供更准确和相关的信息。这种感知能力使得系统能够适应环境变化, 及时调整其回答和建议,甚至进行预测性分析, 识别潜在的健康风险[27] , 可以极大地提升智慧问答在医疗保健中的效能, 为实现更高效、更人性化的医疗保健提供了强有力的支持。
4) 医学知识准确性
准确性作为在线医疗健康智慧问答服务关键特征之一, 直接关系到服务的可靠性和用户的信任度。准确的医疗信息对于支持临床决策、患者教育和自我管理、增强公众健康意识以及避免信息过载和混淆至关重要[28] 。因此, 如何集成现有的技术深入理解用户的查询意图, 准确匹配并提供科学、合理的医疗建议是一大挑战。
5) 医学知识可解释性
可解释性提高了智慧问答服务的信任和透明度,使得用户能够清楚地理解推荐或决策的逻辑和依据[28] 。同时, 对医疗专业人员在临床决策过程中的评估和验证提供了关键支持, 确保信息的来源可以被追踪和验证[29] , 这对于保持医疗行业的法规合规性和责任归属非常重要。此外, 可解释性还为医疗专业人员和患者提供了教育和培训价值, 有助于提高患者对健康建议的理解和遵循。总之, 可解释性是建立用户信任、支持临床决策、确保合规性、提高患者参与度的关键因素, 也是推动高效、负责任和用户友好医疗服务的关键环节。
6) 符合人类价值观
符合人类价值观要求医疗智慧问答服务必须建立在严格的道德约束之上, 确保所有医疗建议符合医学伦理原则[30] 。一方面, 不同文化背景的用户对疾病和治疗的理解与接受度可能有所不同, 因此,服务者必须充分考虑患者的文化背景和个人偏好,以提供符合患者文化习惯和期望的健康咨询服务;另一方面, 医疗智慧问答服务应遵守无伤害原则和有益原则, 确保所有建议和干预都是为了增进患者的健康和福祉, 始终以患者的最佳利益为重, 避免任何形式的歧视和偏见。
3 图模驱动的在线医疗健康智慧问答服务
3. 1 知识图谱与大语言模型的区别及联系
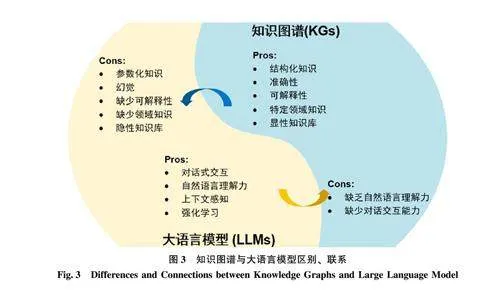
语言为“形”, 知识“立” 心, 图谱作“骨”。语言是知识的载体, 知识是智慧的根本, 图3 列出了知识图谱与大语言模型的区别及联系, 可以发现大语言模型和知识图谱作为知识表示和处理的计算手段, 两者虽有不同却可相互联系。知识图谱起源于语义网, 由谷歌(Google)公司于2012 年提出, 可以通过三元组的方式存储知识, 形成直观且易于理解的知识结构框架[31] , 从而对海量的数据有序化组织、关联和管理, 其本质是一种结构化显性知识库, 可解释性强, 特定领域知识准确性高, 但构建流程复杂, 缺乏自然语言理解力。相比之下, 大语言模型的兴起得益于深度学习和人工智能技术的进步, 与知识图谱不同的是, 大语言模型可以自动学习海量文本数据中的深层次语义特征, 通过动态的、概率性的知识表示方式[32] , 使得大语言模型在自然语言理解、上下文感知和对话式交互方面表现出色, 能够根据用户的具体情况和需求, 生成流畅且个性化的回答, 更具备“类人性”。但由于其隐式参数化的知识存储方式, 可能导致其提供的答案缺乏直接的可解释性和准确性。
3. 2 知识图谱与大语言模型在医疗智慧问答领域互补融合的必要性
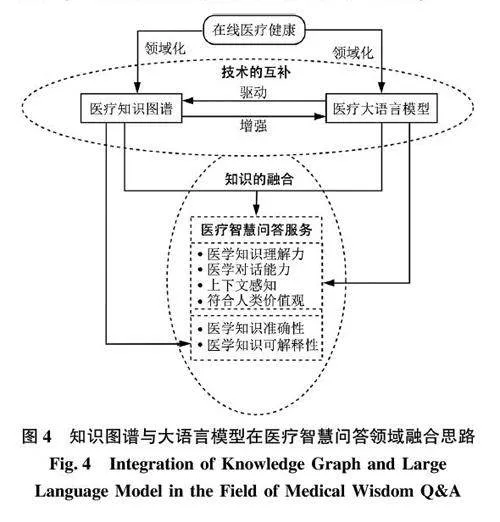
结合前期总结的医疗智慧问答服务的理论特征,可以发现, 知识图谱和大语言模型在医疗智慧问答领域扮演了独特而又互补的角色。知识图谱以其精准的结构化知识可以满足医疗智慧问答服务所需的医学知识准确性和医学知识可解释性, 确保回答的质量和可信度; 而大语言模型可利用其强大的自然语言处理能力, 满足医疗智慧问答服务所需的医学知识理解力、医学知识对话能力、上下文感知、符合人类价值观特征, 使得用户与模型交互更加流畅自然。图4 列出了知识图谱与大语言模型在医疗智慧问答领域互补融合思路, 包含技术的互补和知识的融合两部分, 技术的互补体现在实现智慧问答服务前期的准备过程, 分为领域化的医疗知识图谱构建和医疗大语言模型训练过程, 一方面, 利用现有通用大语言模型强大的任务处理能力, 优化非结构化数据的知识抽取、优化、融合等过程, 以降低医疗知识图谱构建成本; 另一方面, 利用已构建的医疗知识图谱中具备结构化特征的三元组, 增强医疗大模型继续预训练、有监督微调过程中的数据质量,以提升模型的质量。知识的融合体现在医疗健康智慧问答服务后期的实践框架上, 即如何设计一个管道式服务流程, 充分利用医疗知识图谱和医疗大语言模型各自优势来满足在线医疗智慧问答服务的6个理论特征, 构建出既符合人类交互习惯又能提供深入、可靠的医疗健康信息的智慧问答服务。
3. 3 图模驱动的在线医疗健康智慧问答服务模式
为实现在线医疗健康领域自动问答的智慧化转型, 本研究设计了图模驱动的在线医疗健康智慧问答服务模式, 主要分为三部分, 分别是大语言模型驱动医疗知识图谱构建、知识图谱增强医疗大语言模型训练以及图模驱动的在线医疗健康智慧问答服务流程。
3. 3. 1 大语言模型驱动医疗知识图谱构建
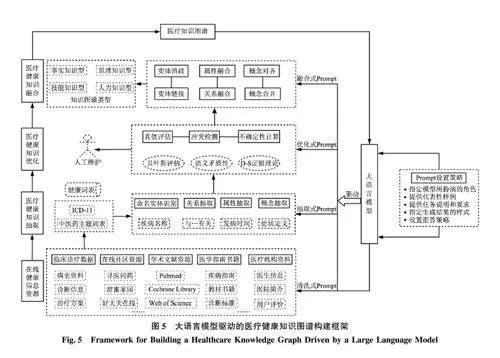
医疗知识图谱构建的主要目的在于借助其结构化的显性知识表达方式满足前期总结的智慧问答服务医学知识准确性、医学知识可解释性两个理论特征。当前, 已有诸多学者开展了知识图谱构建的相关理论探索, 如林海伦等[33] 探讨了开放网络环境下领域知识图谱的构建思路, 马海云等[34] 构建了面向用户需求的健康领域知识组织框架, 仔细分析可以发现, 其本质均为对现有多源异构的数据进行采集、抽取、重组、存储, 从而形成产品知识库的过程, 已有研究提示[35-37] , 以ChatGPT 为代表的大模型在政策、学术、医疗多个领域的命名实体识别、关系抽取等各类自然语言处理任务上表现卓越, 这也为知识图谱的自动构建提供了可能。据此,本研究将大模型贯穿医疗知识图谱构建的全流程,设计了大语言模型驱动的医疗健康知识图谱构建框架, 如图5 所示。
1) Prompt 提示词介绍及设置策略
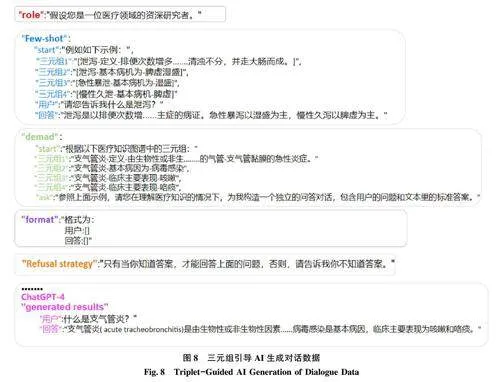
Prompt 提示词是用户与AI 沟通的桥梁, 通常是一种输入提示或指令, 用于引导模型精准把握用户意图, 生成富有洞察力的回答, 甚至能够促使AI跨越简单的信息检索, 达到深入的思考和创意性回复。一般来说, 其设计步骤主要分为以下5 个步骤:①指定模型所扮演的角色(Role): 针对任务明确模型的身份或职责, 有助于确保生成的内容符合用户的期望和要求。②提供代表性的样例(Few-shotPrompt): 为AI 提供一个参考示例, 使其充分理解要求, 提升模型性能表现。③提供任务说明和要求(Demand): 提供给ChatGPT 语句流畅、意图清晰、表达精简的任务描述。④指定生成结果的格式(For⁃mat): 通过显示规定模型返回结果的格式, 以便于后续统计分析。⑤设置拒答策略(Refusal Strategy):虽然ChatGPT 设置了诸如“我的知识截至2021 年9 月…” 类似的拒答策略, 但仍无法完全避免大模型幻觉问题的产生。因此, 手动设置拒答策略, 让模型在没有把握的时候拒绝回答问题, 提高处理任务的能力。以医疗健康知识抽取环节为例, 图6 列出了“大模型(如ChatGPT-4)+抽取式Prompt” 进行命名实体识别和关系抽取的具体过程。
2) 医疗知识图谱构建过程
具体来讲, 医疗知识图谱的构建主要分为以下4 个步骤: ①健康信息资源收集: 大数据时代下,医学知识来源复杂、质量参差不齐、分布稀疏等特点造成了医疗健康知识图谱需要收集多方资源, 包含临床诊疗数据、在线社区网站、学术文献知识等,之后通过“大模型+清洗式Prompt” 的方式进行数据清洗, 如冗余数据删除、数据脱敏等, 为健康知识的抽取奠定基础。②医疗健康知识抽取: 知识抽取阶段的主要内容是在健康领域专家的指导下, 从不同来源、形式的数据资源中抽取出健康知识的元集和属性, 形成初步的健康知识体系结构。首先通过自动抽取, 利用“大模型+抽取式Prompt” 来进行命名实体识别、关系抽取、属性抽取等, 以提高知识抽取效率, 缩短知识组织构建时间, 之后让健康知识背景的专业人员人工标注处理模型难以识别的部分, 并审核模型抽取的结果。③医疗健康知识优化: 知识优化建立在知识抽取的基础上, 对提高医疗知识图谱的可靠性、置信度和实用性至关重要,在这一过程可利用“大模型+优化式Prompt” 通过贝叶斯估计、D-S 证据理论等方法进行真值评估、冲突性检测、不确定性计算, 以消除知识理解的模糊性, 保留知识的真值。④医疗健康知识融合: 考虑到不同数据源中实体、语义关系及语义粒度等并不完全相同。因此, 知识融合主要是消除异构数据源中实体指向不明、关系冗余等问题。在此基础上,基于本体论的知识表示视角, 利用“大模型+融合式Prompt” 通过实例融合、属性融合、关系融合、概念融合, 从语义层面解决知识结构的差异性问题。经历多次迭代后, 逐步拓展形成能够解决具体医疗健康领域问题的知识图谱, 如健康事实知识图谱、健康原理知识图谱、健康技能知识图谱、健康人力知识图谱等, 为后续智慧化的问答服务提供准确、可解释性的数据支持。
3. 3. 2 知识图谱增强医疗大语言模型训练
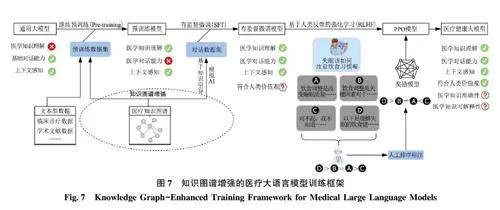
医疗大语言模型训练的本质是将通用基座模型医学化, 通过继续预训练、有监督微调、基于人类反馈的强化学习满足前期总结的医疗健康智慧问答中的医学知识理解力、医学对话能力、上下文感知、符合人类价值观4 个理论特征, 其中上下文感知来源于通用基座模型, 其余特征则是通过模型二次训练获得。图7 列出了知识图谱增强的医疗大语言模型训练框架。
1) 具备医学知识理解力—继续预训练
继续预训练(Continually Pre-Training)是模型知识积累的重要阶段, 模型所具备的医学知识理解力几乎都是在预训练阶段中习得[38] 。若跳过预训练阶段, 直接进行有监督微调, 模型往往只是机械地记住了问题和答案, 而没有领悟其中的深层次知识, 且易出现过拟合现象[39] 。已有研究表明, 优质的预训练语料对于大语言模型来说至关重要, 可显著提高模型的性能, 甚至有可能在某种程度上突破Scaling Laws 的限制[40] 。因此, 在这一阶段, 需要收集广泛多样的高质量文本数据, 包含非结构化和结构化两类, 其中非结构化数据可加强模型在医学领域术语理解和表达能力, 如临床诊疗数据、学术文献数据、医学指南书籍等, 结构化数据则以前期构建的医疗健康知识图谱为代表, 有助于模型理解各个实体属性、概念及不同实体间的关系, 进而提升模型在医学领域的推理能力。之后随机混合数据, 在具备上下文感知能力的基座模型上继续预训练, 形成具备医学语言理解力的预训练模型。
2) 赋予医学对话能力—有监督微调
有监督微调(Supervised Finetuning, SFT)是赋予大语言模型医学对话能力的关键环节, 在这一阶段需要利用标注精良的医疗对话数据对模型进一步地微调, 触发模型预训练阶段学习到的知识, 从而获得医学对话能力[38] 。当前, 市面上已有的数据多为无监督文本数据, 并不具备监督微调阶段所需的对话特征, 部分学者提出了“Self-instruction”[41] 方法来缓解这一问题, 其本质上仍是模型内部“已有知识” 的蒸馏, 无法控制生成对话数据的领域覆盖和正确性。为保证对话数据的准确性和可靠性,本研究设计了知识图谱中三元组引导的对话数据生成, 如图8 所示, 以医疗知识图谱中准确的结构化知识为数据来源, 利用通用大模型强大的生成能力,通过Prompt 提示词的方式, 引导模型自问自答, 生成逻辑关系相关的若干问题和答案, 从而大幅度降低对话数据的标注成本和难度。
3) 符合人类价值观—基于人类反馈的强化学习
尽管通过预训练和有监督微调, 模型已经具备了医学知识理解力和医学对话能力, 但模型仍然可能无法理解用户意图, 导致生成的输出与人类期望不符[37] 。因此, 在这一阶段需要采用来自人类反馈的强化学习(RLHF, Reinforcement Learning fromHuman Feedback)这一技术, 首先将奖励模型拟合到人类手工标注的偏好数据集上, 之后使用强化学习优化语言模型, 以产生分配给高奖励的应答, 同时又不过分偏离原始模型, 最终驱使人工智能生成的答案与人类价值观相一致。
3. 4 图模驱动的在线医疗健康智慧问答服务流程
在上述两个阶段完成之后, 医疗知识图谱可以为智慧问答服务提供准确、可解释性的医疗知识,而医疗大模型则可以满足医疗健康智慧问答所需上下文感知、医学知识理解力、医学对话能力、符合人类价值观4 个特征。
3. 4. 1 用户问答场景模式
“场景” 一词最早出自传播学[42] , 指特定的情形或情景, 用于描述一个实体所处状态的相关信息,也是社会环境的构成物或一种可被构建的要素, 具有促发行为改变的工具性价值[43] 。在信息服务和知识服务领域, 场景思维的运用是在挖掘用户需求的基础上, 更加关注“场景识别—服务适配” 的整体过程[44] 。由此可见, 不同的用户需求决定了最终服务场景的选择。
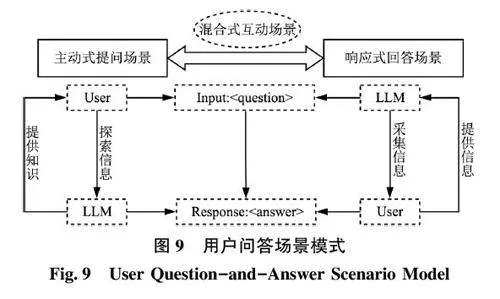
综合现有研究来看, 现有主流的问答场景均为“用户提问—模型回答” 这种以用户为主导的传统式提问场景, 然而在实际在线医疗健康问答环境中,用户往往并不能准确了解到自己的身体情况, 如医疗问诊环节, 医生需要通过不同角度的提问来引导用户准确而清晰地表述自己的健康症状, 很明显此时医生扮演主导者, 用户仅仅作为辅助者的角色。因此, 本文将在线医疗健康智慧问答交互场景分为以下3 种, 如图9 所示: ①主动式提问场景: 这类场景下, 用户通常有更明确的信息需求, 例如, 了解特定疾病的症状、治疗方法或预防措施等事实型健康知识问答, 用户主导对话的方向并提出具体问题, 寻求信息或解决方案。用户是信息的探索者, 模型则是知识的提供者; ②响应式回答场景: 这种场景下, 用户通常需要即时地回答模型的问题。模型引导用户提供一些个人健康信息, 如症状或具体情况, 然后模型基于这些信息提供建议、分析或解答。模型主导对话的方向并提出具体问题, 用户在这里是信息的提供者, 而模型扮演引导者的角色, 以便为用户提供个性化的建议或分析; ③混合式互动场景: 既包含了主动式提问场景, 又包含了响应式回答场景, 实际应用中, 用户的需求往往随着交互的深入而演变, 从而导致场景模式的迅速变化。例如,一个最初寻求疾病信息的用户可能会逐渐转向寻求更深入的医疗问诊服务, 这就从一个主动式的提问场景转变为响应式的回答场景。因此, 面向在线医疗健康的智慧问答服务流程需要智能识别、自动定位场景模式, 促使场景与用户实际健康需求相匹配。
3. 4. 2 智慧问答服务流程
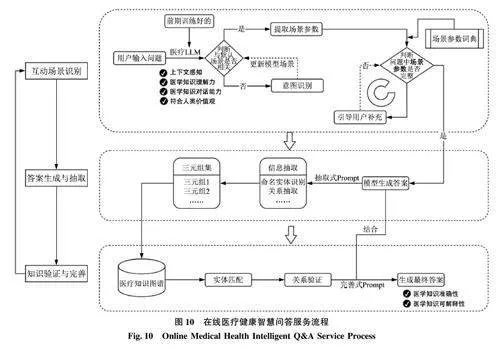
为提高在线医疗健康智慧问答服务的有效性和可操作性, 本研究结合前文阐述的用户实际问答场景模式, 充分利用已构建医疗知识图谱和医疗大语言模型各自的优势, 设计了一个管道循环式在线医疗健康智慧问答服务流程, 如图10 所示, 包含互动场景识别、答案生成与抽取、知识验证与完善3个阶段。
1) 互动场景识别
首先利用前期训练好的具备上下文感知能力、医学知识理解力、医学知识对话能力、符合人类价值观的医疗大语言模型, 通过语义解析、关键词提取等技术, 将用户的问题与预定义的模型场景进行匹配, 判断用户问题是否与当前模型场景相关, 如果不相关, 则通过意图识别技术更新模型应用场景,直到与用户问题所需场景相一致为止; 之后基于场景参数词典判断场景参数是否完整, 在主动式提问场景下, 场景参数为无, 而在响应式回答场景下(如医疗问诊场景), 则需要判断场景参数(如睡眠状况、四肢症状等)是否完整询问, 如果缺失, 则引导用户补充必要信息, 直至场景参数完整为止。
2) 答案生成与抽取
在通过意图识别, 选择合适的场景后, 医疗大模型通过推理会生成相应的答案, 之后利用抽取模块, 通过命名实体识别、关系抽取等技术, 从非结构化的自然语言回答中提取出关键的医学实体及其相互之间的关系, 形成机器易于处理的三元组集合, 为后续知识的可解释性验证和知识完善环节奠定基础。
3) 知识验证与完善
知识验证主要是将前期抽取出来的三元组集与已有医疗知识图谱进行匹配, 获取相关节点数据,进行对比, 以验证大模型回答的可解释性, 主要包括实体匹配和关系验证两方面。实体匹配是指将抽取出来的实体与知识图谱中已有的实体进行对比,识别出未知实体或者错误的实体命名; 关系验证则是分析实体之间抽取出的关系是否准确, 是否与现有知识图谱中的关系一致。在知识验证完成之后,根据知识图谱中的正确知识结合“完善式Prompt”纠正并更新模型生成的原始答案, 最终形成用户满意的准确性、可解释性的医学知识内容。
4 结 语
学者们多追求医疗智慧问答技术本身的前沿性,忽略了对其基础理论的深入探讨, 使得现有的智慧问答仍停留在“智能” 而非“智慧” 层面。针对这一现实问题, 本文在梳理前人已有研究的基础上, 厘清在线医疗健康“智慧问答服务” 与“智能问答” “智慧服务” 等相关概念的区别, 探讨数智时代下在线医疗智慧问答的理论内涵及特征, 之后, 紧扣医学知识理解力、医学对话能力、上下文感知、医学知识准确性等6 个理论特征, 分析知识图谱和大语言模型在技术演进上的联系及两者在在线医疗健康智慧问答领域的互补融合思路, 最后提出图模驱动的在线医疗健康智慧问答服务, 包含大语言模型驱动医疗知识图谱构建、知识图谱增强医疗大语言模型训练、图模驱动的在线医疗健康智慧问答服务流程三部分, 其中, 大语言模型驱动医疗知识图谱构建、知识图谱增强医疗大语言模型训练两阶段是在线医疗健康智慧问答的前期准备过程,图模驱动的在线医疗健康智慧问答服务流程则是为提高在线医疗健康智慧问答服务的有效性和可操作性, 结合用户问答场景模式, 充分发挥知识图谱和大语言模型优势而构建的一个管道循环式服务流程。本研究将在线医疗健康智慧问答特征贯穿于整个服务流程的构建, 实现了智慧问答服务理论和技术的有机结合, 可为医疗健康问答领域的智慧化转型贡献新的思路和方法。在后续研究中, 将基于具体医疗场景, 尝试对本文所提出的图模驱动的在线医疗健康智慧问答服务开展应用实证, 以期在实践中不断完善并优化智慧问答理论特征及服务流程。
参考文献
[1] 马费成, 周利琴. 面向智慧健康的知识管理与服务[ J]. 中国
图书馆学报, 2018, 44 (5): 4-19.
[2] 李贺, 刘嘉宇, 李世钰, 等. 基于疾病知识图谱的自动问答系统
优化研究[J]. 数据分析与知识发现, 2021, 5 (5): 115-126.
[3] 王寅秋, 虞为, 陈俊鹏. 融合知识图谱的中文医疗问答社区自动
问答研究[J]. 数据分析与知识发现, 2023, 7 (3): 97-109.
[4] Li Y X, Li Z H, Zhang K, et al. ChatDoctor: A Medical Chat
Model Fine-tuned on Llama Model Using Medical Domain Knowl⁃
edge [ EB/ OL]. https: / / arxiv. org/ ftp/ arxiv/ papers/2303/2303.
14070.pdf, 2023-06-24.
[5] Chen Y R, Wang Z Y, Xing X F, et al. BianQue: Balancing the
Questioning and Suggestion Ability of Health LLMs with Multi-turn
Health Conversations Polished by ChatGPT [ J]. arXiv Preprint
arXiv: 2310.15896, 2023.
[6] 辞海委员会. 辞海[M]. 上海: 上海辞书出版社, 2000.
[7] 汪凤炎, 郑红. 品德与才智一体: 智慧的本质与范畴[ J]. 南
京社会科学, 2015, (3): 127-133.
[8] 初景利, 任娇菡, 王译晗. 从数字图书馆到智慧图书馆[ J].
大学图书馆学报, 2022, 40 (2): 52-58.
[9] 王延飞, 赵柯然, 何芳. 重视智能技术 凝练情报智慧———情报、
智能、智慧关系辨析[J]. 情报理论与实践, 2016, 39 (2):
1-4.
[10] 程秀峰, 周玮珽, 张小龙, 等. 基于用户画像的图书馆智慧参
考咨询服务模式研究[J]. 图书馆学研究, 2021, (2): 86-93,
101.
[11] 刘泽, 邵波, 王怡. 数据驱动下图书馆智慧参考咨询服务模
式研究[J]. 情报理论与实践, 2023, 46 (5): 176-184.
[12] 张传洋, 郭宇, 庞宇飞, 等. 数智化医疗信息利用与服务模
式框架构建[J]. 图书情报工作, 2023, 67 (13): 49-58.
[13] 罗立群, 李广建. 智慧情报服务与知识融合[ J]. 情报资料
工作, 2019, 40 (2): 87-94.
[14] 苏新宁. 大数据时代情报学与情报工作的回归[ J]. 情报学
报, 2017, 36 (4): 331-337.
[15] 柯平, 邹金汇. 后知识服务时代的图书馆转型[ J]. 中国图
书馆学报, 2019, 45 (1): 4-17.
[16] 李晓妍. 面向产业技术创新的智慧情报服务生态系统构建及
系统动力学分析[J]. 情报科学, 2024, 42 (5): 120-129.
[17] 王秉, 陈超群. 智慧安全情报服务体系研究[J]. 现代情报,
2021, 41 (4): 3-9, 164.
[18] 郑荣, 高志豪, 魏明珠, 等. 面向国家重大战略的智慧情报服
务: 内涵界定、赋能机制与逻辑进路[J]. 图书与情报, 2022,
(5): 115-124.
[19] 曹明宇, 李青青, 杨志豪, 等. 基于知识图谱的原发性肝癌
知识问答系统[J]. 中文信息学报, 2019, 33 (6): 88-93.
[20] 陈明, 刘蓉, 熊回香. 基于医疗知识图谱的智能问答系统研
究[J]. 情报科学, 2023, 41 (12): 118-126.
[21] 闫悦, 郭晓然, 王铁君, 等. 问答系统研究综述[ J]. 计算
机系统应用, 2023, 32 (8): 1-18.
[22] Chang Y, Wang X, Wang J, et al. A Survey on Evaluation of
Large Language Models [ J]. arXiv Preprint arXiv: 2307.03109,
2023.
[23] Sfakianaki P, Koumakis L, Sfakianakis S, et al. Semantic Bio⁃
medical Resource Discovery: A Natural Language Processing Frame⁃
work [J]. BMC Medical Informatics and Decision Making, 2015,
15: 1-14.
[24] Motger Q, Franch X, Marco J. Software-based Dialogue Sys⁃
tems: Survey, Taxonomy, and Challenges [ J]. ACM Computing
Surveys, 2022, 55 (5): 1-42.
[25] Laranjo L, Dunn A G, Tong H L, et al. Conversational Agents
in Healthcare: A Systematic Review [J]. Journal of the American
Medical Informatics Association, 2018, 25 (9): 1248-1258.
[26] Yin K, Laranjo L, Tong H L, et al. Context-aware Systems for
Chronic Disease Patients: Scoping Review [ J]. Journal of Medi⁃
cal Internet Research, 2019, 21 (6): e10896.
[27] Gubert L C, Costa C A, Righi R R. Context Awareness in Health⁃
care: A Systematic Literature Review [J]. Universal Access in the
Information Society, 2020, 19 (2): 245-259.
[28] 陈剑锋. 大语言模型在临床医学的可应用性探讨[ J]. 医学
与哲学, 2023, 44 (21): 1-6.
[29] Frasca M, La Torre D, Pravettoni G, et al. Explainable and In⁃
terpretable Artificial Intelligence in Medicine: A Systematic Biblio⁃
metric Review [J]. Discover Artificial Intelligence, 2024, 4 (1):
15.
[30] 阮彤, 卞俣昂, 余广涯, 等. 医学大语言模型研究与应用综
述[J]. 中国卫生信息管理杂志, 2023, 20 (6): 853-861.
[31] 张吉祥, 张祥森, 武长旭, 等. 知识图谱构建技术综述[ J].
计算机工程, 2022, 48 (3): 23-37.
[32] 陈慧敏, 刘知远, 孙茂松. 大语言模型时代的社会机遇与挑
战[J]. 计算机研究与发展, 2024, 61 (5): 1094-1103.
[33] 林海伦, 王元卓, 贾岩涛, 等. 面向网络大数据的知识融合
方法综述[J]. 计算机学报, 2017, 40 (1): 1-27.
[34] 马海云, 曹思源, 薛翔. 面向用户需求的健康领域知识组织与
服务框架研究[J]. 情报资料工作, 2022, 43 (2): 84-92.
[35] 张华平, 李林翰, 李春锦. ChatGPT 中文性能测评与风险应
对[J]. 数据分析与知识发现, 2023, 7 (3): 16-25.
[36] 张颖怡, 章成志, 周毅, 等. 基于ChatGPT 的多视角学术论
文实体识别: 性能测评与可用性研究[ J]. 数据分析与知识
发现, 2023, 7 (9): 12-24.
[37] 鲍彤, 章成志. ChatGPT 中文信息抽取能力测评———以三种典
型的抽取任务为例[J]. 数据分析与知识发现, 2023, 7 (9):
1-11.
[38] Cao Y, Kang Y, Sun L. Instruction Mining: High-Quality In⁃
struction Data Selection for Large Language Models [J]. arXiv Pre⁃
print arXiv: 2307.06290, 2023.
[39] 张君冬, 杨松桦, 刘江峰, 等. AIGC 赋能中医古籍活化:
Huang-Di 大模型的构建[ J]. 图书馆论坛, 2024, 44 (10):
103-112.
[40] Wang Y, Zhong W, Li L, et al. Aligning Large Language Models
with Human: A Survey [ J]. arXiv Preprint arXiv: 2307.12966,
2023.
[41] Wang Y, Kordi Y, Mishra S, et al. Self - instruct: Aligning
Language Model with Self Generated Instructions [ J]. arXiv Pre⁃
print arXiv: 2212.10560, 2022.
[42] 约书亚·梅罗维茨. 消失的地域: 电子媒介对社会行为的影响
[M]. 肖志军, 译. 北京: 清华大学出版社, 2022.
[43] 刘晗. 场景服务创新: 移动网络信息治理的场景化转型[ J].
学习与实践, 2020, (9): 98-106.
[44] 郑荣, 王晓宇, 高志豪, 等. 面向国家战略的产业竞争情报场
景化智慧服务模式研究[J]. 情报学报, 2024, 43 (2): 198-
213.
(责任编辑: 郭沫含)
