基于机器学习的冠心病风险预测模型构建与比较
2025-01-01岳海涛何婵婵成羽攸张森诚吴悠马晶
【摘要】 背景 冠状动脉粥样硬化性心脏病(以下简称冠心病)是全球重要的死亡原因之一。目前关于冠心病风险评估的研究在逐年增长。然而,在这些研究中常忽略了数据不平衡的问题,而解决该问题对于提高分类算法中识别冠心病风险的准确性至关重要。目的 探索冠心病的影响因素,通过使用2种平衡数据的方法,基于5种算法建立冠心病风险相关的预测模型,比较这5种模型对冠心病风险的预测价值。方法 基于2021年美国国家行为风险因素监测系统(BRFSS)横断面调查数据筛选出112 606名研究对象的健康相关风险行为、慢性健康状况等24个变量信息,结局指标为自我报告是否患有冠心病并据此分为冠心病组和非冠心病组。通过进行单因素分析和逐步Logistic回归分析探索冠心病发生的影响因素并筛选出纳入预测模型的变量。随机抽取112 606名受访者的10%(共计11 261名),以8∶2的比例随机划分为训练与测试的数据集,采用随机过采样和合成少数过采样技术(SMOTE)两种过采样的方法处理不平衡数据,基于k最邻近算法(KNN)、Logistic回归、支持向量机(SVM)、决策树和XGBoost算法分别建立冠心病预测模型。结果 两组年龄、性别、BMI、种族、婚姻状态、教育水平、收入水平、家里有几个孩子、是否被告知患高血压、是否被告知处于高血压前期、是否被告知患妊娠高血压、现在是否在服用高血压药物、是否被告知患有高脂血症、是否被告知患有糖尿病、吸烟情况、过去30 d内是否至少喝过1次酒、是否为重度饮酒者、是否为酗酒者、过去30 d内是否有体育锻炼、心理健康状况以及自我健康评价比较,差异有统计学意义(Plt;0.05)。逐步Logistic回归分析结果显示:年龄、性别、BMI、种族、教育水平、收入水平、是否被告知患高血压、是否被告知处于高血压前期、是否被告知患妊娠高血压、现在是否在服用高血压药物、是否被告知患有高脂血症、是否被告知患有糖尿病、吸烟情况、过去30 d内是否至少喝过1次酒、是否为重度饮酒者、是否为酗酒者以及自我健康评价为冠心病的影响因素(Plt;0.05)。风险模型构建的分析结果显示:k最邻近算法、Logistic 回归、支持向量机、决策树和XGBoost采用SMOTE处理不平衡数据的总体分类精度分别为59.2%、67.4%、66.2%、69.2%和85.9%,召回率分别为75.2%、71.4%、70.5%、62.9%和34.8%,精确度分别为15.4%、18.2%、17.5%、17.6%和28.7%,F值分别为0.256、0.290、0.280、0.275和0.315,受试者工作特征曲线下面积分别为0.80、0.78、0.72、0.72和0.82;采用随机过采样处理不平衡数据的总体分类精度分别为62.5%、68.5%、69.0%、60.2%和70.1%,召回率分别为70.0%、69.5%、71.9%、69.0%和67.6%;精确度分别为15.8%、18.4%、19.1%、14.8%和19.0%,F值分别为0.258、0.291、0.302、0.244和0.297,受试者工作特征曲线下面积分别为0.80、0.77、0.72、0.72和0.83。结论 本研究不仅确认了已知冠心病的影响因素,还发现了自我健康评价水平、收入水平和教育水平对冠心病具有潜在影响。在使用2种数据平衡方法后,5种算法的性能显著提高。其中XGBoost模型表现最佳,可作为未来优化冠心病预测模型的参考。此外,鉴于XGBoost模型的优异性能以及逐步Logistic回归的操作便捷和可解释性,推荐在冠心病风险预测模型中结合使用数据平衡后的XGBoost和逐步Logistic回归分析。
【关键词】 冠心病;机器学习;风险预测模型;Logistic回归;k最邻近算法;支持向量机;决策树;XGBoost
【中图分类号】 R 541.4 【文献标识码】 A DOI:10.12114/j.issn.1007-9572.2023.0323
Coronary Heart Disease Risk Prediction Model Based on Machine Learning
YUE Haitao1,HE Chanchan1,CHENG Yuyou1,ZHANG Sencheng1,WU You2*,MA Jing1*
1.Institute for Hospital Management,Tsinghua University,Shenzhen 518055,China
2.Institute for Hospital Management/ School of Medicine,Tsinghua University,Beijing 100084,China
*Corresponding authors:WU You,Doctoral supervisor;E-mail:youwu@tsinghua.edu.cn
MA Jing,Professor,Master supervisor;E-mail:jingma@sz.tsinghua.edu.cn
YUE Haitao and HE Chanchan are co-first authors
【Abstract】 Background Coronary atherosclerotic heart disease(CHD) is one of the leading causes of mortality worldwide,and research on risk assessment for CHD has been growing annually. However,the issue of data imbalance in these studies is often overlooked,despite its crucial role in enhancing the accuracy of CHD risk identification within classification algorithms. Objective To investigate the factors influencing CHD and to establish predictive models for CHD risk using two data balancing methods based on five algorithms,comparing the predictive value of these models for CHD risk.
Methods Utilizing cross-sectional survey data from the 2021 Behavioral Risk Factor Surveillance System(BRFSS) in the United States,a cohort of 112 606 participants was identified,featuring 24 variables related to risk behaviors and health status,with self-reported coronary heart disease(CHD) as the outcome measure. Factors influencing the incidence of CHD were explored through univariate analysis and stepwise logistic regression to select pertinent variables for inclusion in the predictive model. A random sample comprising 10% of the participants(11 261 individuals) was drawn and then randomly divided into training and testing datasets at an 8∶2 ratio. To address data imbalance,two over-sampling techniques were employed:random oversampling and the Synthetic Minority Over-sampling Technique(SMOTE). Based on these methods,CHD predictive models were constructed using five different algorithms:K-Nearest Neighbors(KNN),Logistic Regression,Support Vector Machine(SVM),Decision Tree,and XGBoost. Results Univariate analysis revealed significant differences(Plt;0.05) between the CHD and non-CHD groups across all input variables except for rental housing and being informed of prediabetic status. Stepwise Logistic regression identified age,gender,BMI,ethnicity,education level,income level,being informed of hypertension,being informed of prehypertension,being informed of pregnancy-induced hypertension,current use of antihypertensive medication,being informed of hyperlipidemia,being informed of diabetes,smoking status,alcohol consumption within the last 30 days,heavy drinking status,and self-assessed health as factors influencing CHD. The performance of risk models using SMOTE showed overall classification accuracies of 59.2%,67.4%,66.2%,69.2%,and 85.9%;recall rates of 75.2%,71.4%,70.5%,62.9%,and 34.8%;precision of 15.4%,18.2%,17.5%,17.6%,and 28.7%;F-values of 0.256,0.290,0.280,0.275,and 0.315;and AUC values of 0.80,0.78,0.72,0.72,and 0.82,respectively. Using random oversampling,the models achieved classification accuracies of 62.5%,68.5%,69.0%,60.2%,and 70.1%;recall rates of 70.0%,69.5%,71.9%,69.0%,and 67.6%;precision of 15.8%,18.4%,19.1%,14.8%,and 19.0%;F-values of 0.258,0.291,0.302,0.244,and 0.297;and AUC values of 0.80,0.77,0.72,0.72,and 0.83,respectively. Conclusion This study not only confirmed known factors affecting CHD but also identified potential impacts of self-assessed health level,income level,and education level on CHD. The performance of the five algorithms was significantly enhanced after employing two data balancing methods. Among them,the XGBoost model exhibited superior performance and can be referenced for future optimization of CHD prediction models. Additionally,considering the excellent performance of the XGBoost model and the convenience and interpretability of stepwise logistic regression,a combined use of these approaches after data balancing is recommended in CHD risk prediction models.
【Key words】 Coronary disease;Machine learning;Risk prediction model;Logistic regression;K-nearest neighbor;Support vector machine;Decision tree;XGBoost
冠状动脉粥样硬化性心脏病(简称冠心病),居全球死亡原因之首。2019年,全球冠心病患者约有1.97亿例,因冠心病死亡人数约914万例。中国正面临人口老龄化和心脑血管疾病危险因素增多的双重压力,致使这类疾病的发病率与患病率持续增长[1]。据统计,目前冠心病患者已达1 139万例[2],死亡风险居高不下。在过去三十年间,全球增加的冠心病死亡病例中,38.2%来自中国[3]。与此同时,高发病率和高死亡率伴随的还有沉重的经济负担:1990年至2019年间,全球因冠心病引发的经济负担增加了82%,年均达到1.82亿美元[2]。然而,从健康状态转变为冠心病常通常历时数十年,在此期间有充足的机会采取有效措施进行干预,因此,建立冠心病风险预测模型可以尽早发现患病高危人群,并针对其发病风险进行个性化干预,从而预防冠心病的发生。
目前冠心病的早期风险评估研究在逐年增长,国际上比较成熟的心血管疾病风险预测模型包括弗雷明汉风险评分(FRS)[4]、汇总队列方程[5]以及欧洲冠心病风险评分系统[6]等,但这些模型开发时间较早,且随着社会经济发展冠心病的影响因素也在发生变化,此外,这些模型主要是基于特定地区的研究,所覆盖的区域较窄。
近年来,随着医疗数据的深入挖掘,越来越多的机器学习算法在冠心病人群中开发、验证[6-7]。然而,大多数研究仅采用了逻辑回归算法[8-9]。此外,许多研究忽视了数据分布不平衡的问题[10-12],导致采用整体分类准确性为目标的机器学习算法在训练过程中忽视少数类,使其性能不佳[13],而采用过采样方法进行样本重构是提高模型性能的关键。此外,一些研究显示部分分类算法在识别风险时准确性较差,且这些研究主要集中于心血管疾病的预测[14],对于更为细分的冠心病领域研究较少,考虑到冠心病复杂性,探索其危险因素十分必要。为了解决上述研究中数据集不平衡性问题并探索冠心病的更多潜在影响因素,本研究使用2021年美国行为风险因素监测系统(Behavioral Risk Factor Surveillance System,BRFSS)的大规模人群数据,通过采用2种过采样方法平衡数据,基于K最邻近算法(KNN)、支持向量机(SVM)、决策树、Logistic回归和XGBoost,构建冠心病的预测模型并通过混淆矩阵和受试者工作特征(receiver operating characteristic curve,ROC)曲线确定最优模型。
1 资料与方法
1.1 数据来源
数据集是从2021年美国BRFSS横断面调查数据中获取[15]。BRFSS是美国首要的健康相关电话调查系统,主要收集有关美国居民健康相关风险行为、慢性健康状况等[16]。
1.2 研究对象
本研究选取对象为2021年美国BRFSS的112 606名受访者。排除标准:(1)小于45岁;(2)本研究的24个变量有信息缺失的受访者。采用随机抽样的方式,从112 606名受访者中抽取了10%的样本,即11 261
名,以此作为研究的代表性训练和测试集。在样本抽取过程中,设定固定随机种子为42,以确保抽样的可复制性。
1.3 变量选择
以受访者是否被告知患有冠心病为因变量(输出变量),并以此为根据将受访者分为冠心病组和非冠心病组。通过查阅冠心病危险因素的相关文献,选择23个自变量(输入变量),包括年龄、性别、BMI、种族、婚姻状态、教育水平、收入水平、家里有几个孩子、是否租房、吸烟情况、过去30 d内是否至少喝过1次酒、是否为重度饮酒者、是否为酗酒者、自我健康评价、心理健康状况、过去30 d内是否有体育锻炼、是否被告知患高血压、是否被告知患妊娠高血压、是否被告知处于高血压前期、现在是否在服用高血压药物、是否被告知患有高脂血症、是否被告知患有糖尿病和是否被告知处于糖尿病前期,详见表1。
1.4 统计学方法
使用R 4.1.3和Python 3.9.13软件完成所有的数据统计分析,计量资料采用(x-±s)表示,计数资料采用相对数表示。通过单因素分析将删除Pgt;0.01的变量,此外,采用逐步Logistic回归分析确定最终纳入预测模型的变量,每个变量选择一个类别作为对照,并计算其他类别的OR值和95%CI。此外,由于受试者中冠心病组占比较低(约为9.35%),属于非平衡数据,为解决数据集不平衡的问题,本研究分别通过随机过采样(random oversampling)和合成少数过采样技术(synthetic minority over-sampling technique,SMOTE)处理训练集,其中随机过采样技术是解决数据集类别不平衡问题的一种基本方法,主要通过复制少数类样本以平衡类别分布。而SMOTE由CHAWLA等[17]于2002年提出,该技术通过在位置相近的少数类样本间进行插值生成新样本点,以此来实现数据的平衡,改善模型对少数类别的预测能力。在2种采样方法处理后的训练集中利用筛选出的变量选择k最邻近算法、支持向量机、决策树、Logistic回归和XGBoost进行建模,各模型训练集和测试集按8∶2比例,9 009例样本用于训练,2 252例样本用于预测。在测试集中采用混淆矩阵和ROC曲线对模型进行评价,所有检验为双侧检验,检验水准α=0.05。
2 结果
2.1 两组基本特征比较
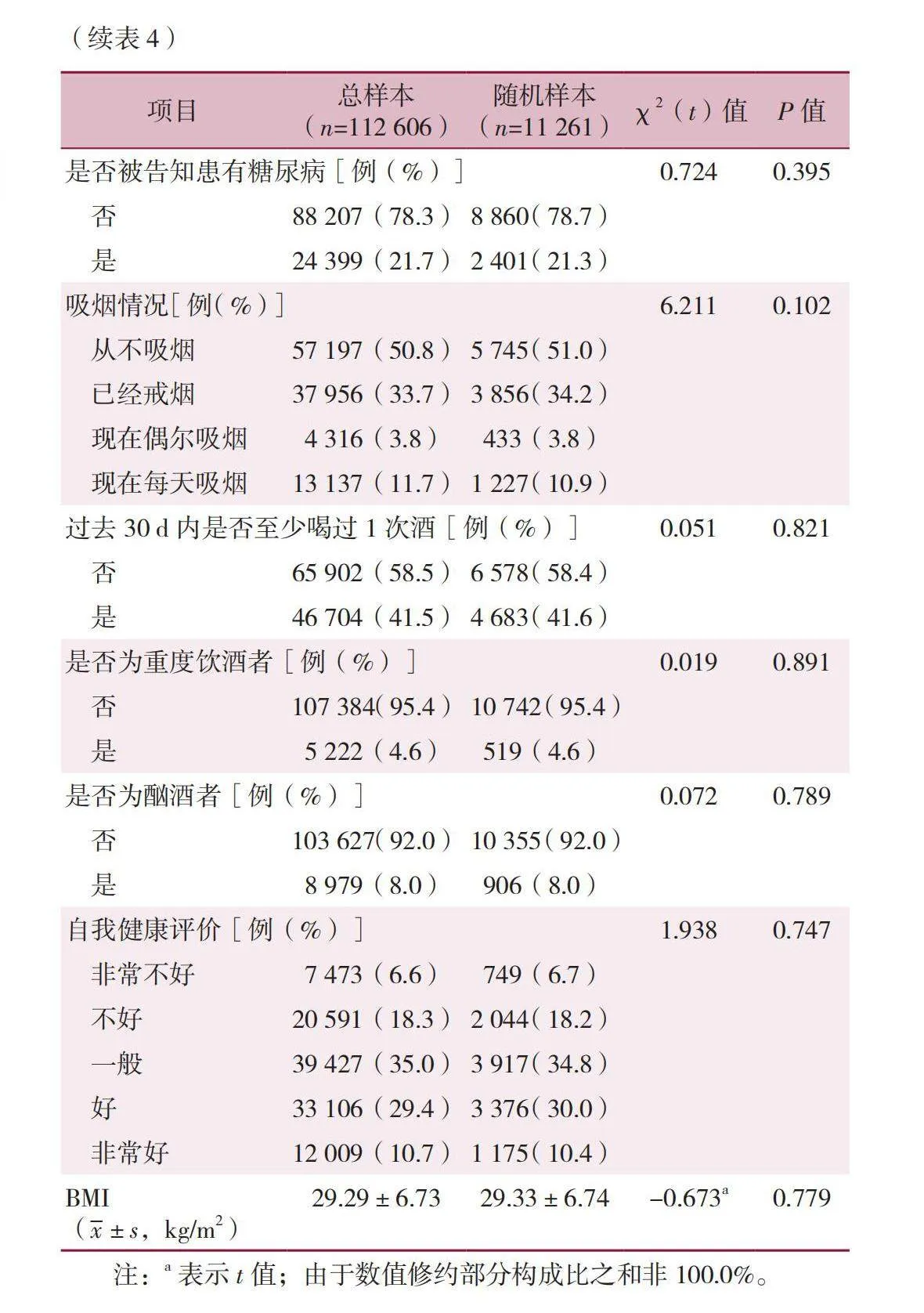
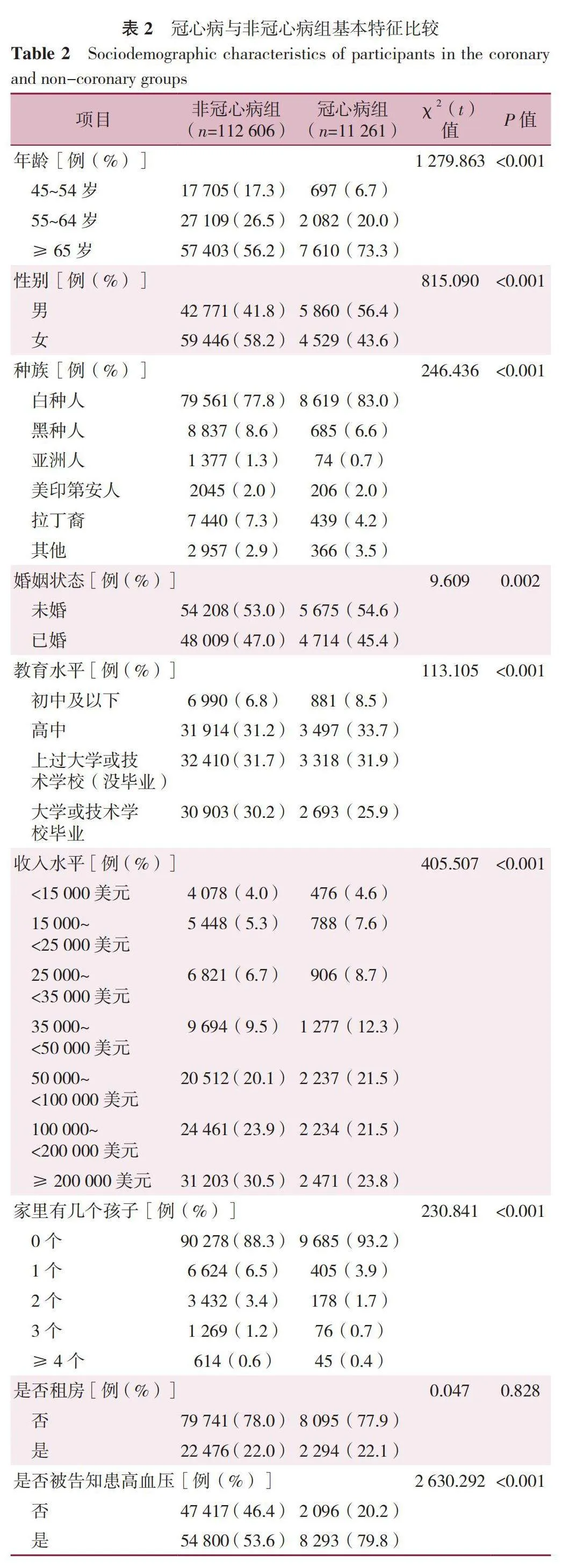
两组年龄、性别、BMI、种族、婚姻状态、教育水平、收入水平、家里有几个孩子、是否被告知患高血压、是否被告知处于高血压前期、是否被告知患妊娠高血压、现在是否在服用高血压药物、是否被告知患有高脂血症、是否被告知患有糖尿病、吸烟情况、过去30 d内是否至少喝过1次酒、是否为重度饮酒者、是否为酗酒者、过去30 d内是否有体育锻炼、心理健康状况以及自我健康评价比较,差异有统计学意义(Plt;0.05);两组是否租房以及是否被告知处于糖尿病前期比较,差异无统计学意义(Pgt;0.05),见表2。
2.2 Logistic回归分析
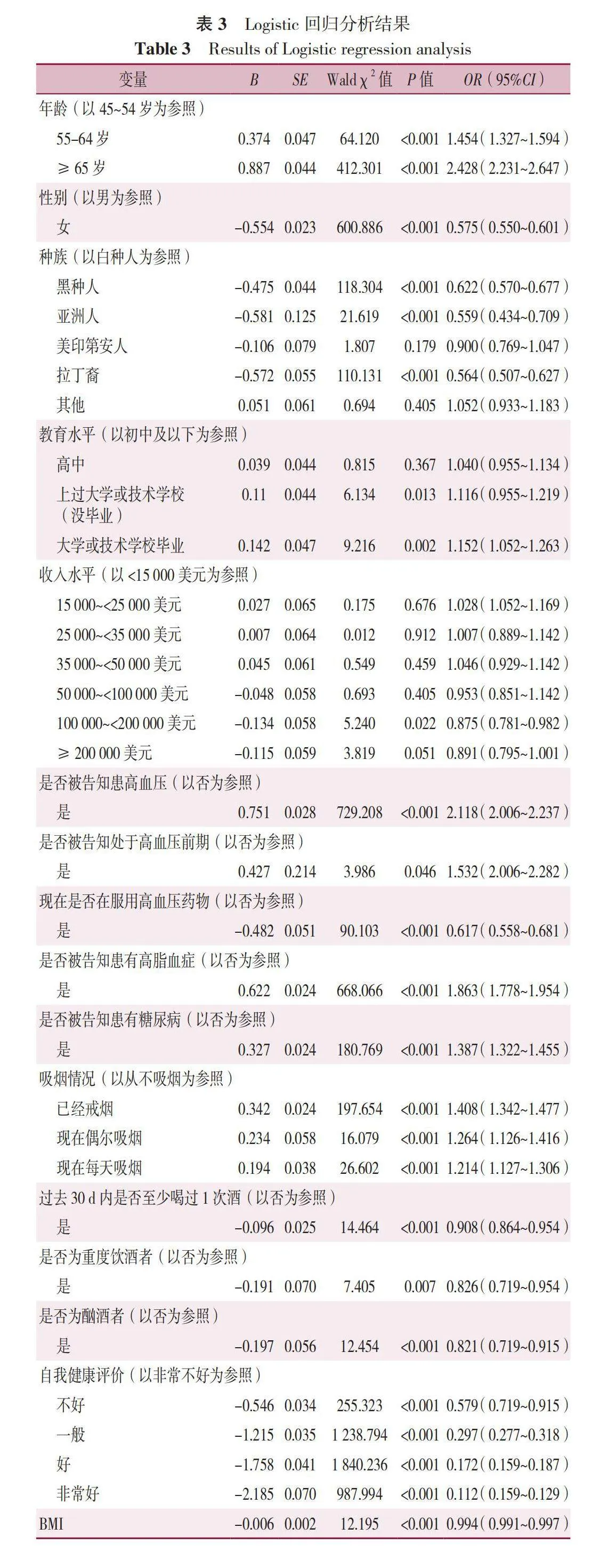
将单因素分析中Plt;0.01的21个变量纳入逐步Logistic回归分析中进行变量筛选,结果显示,年龄、性别、BMI、种族、教育水平、收入水平、是否被告知患高血压、是否被告知处于高血压前期、是否被告知患妊娠高血压、现在是否在服用高血压药物、是否被告知患有高脂血症、是否被告知患有糖尿病、吸烟情况、过去30 d内是否至少喝过1次酒、是否为重度饮酒者、是否为酗酒者以及自我健康评价为冠心病的影响因素(Plt;0.05,见表3)。
2.3 冠心病预测模型结果分析
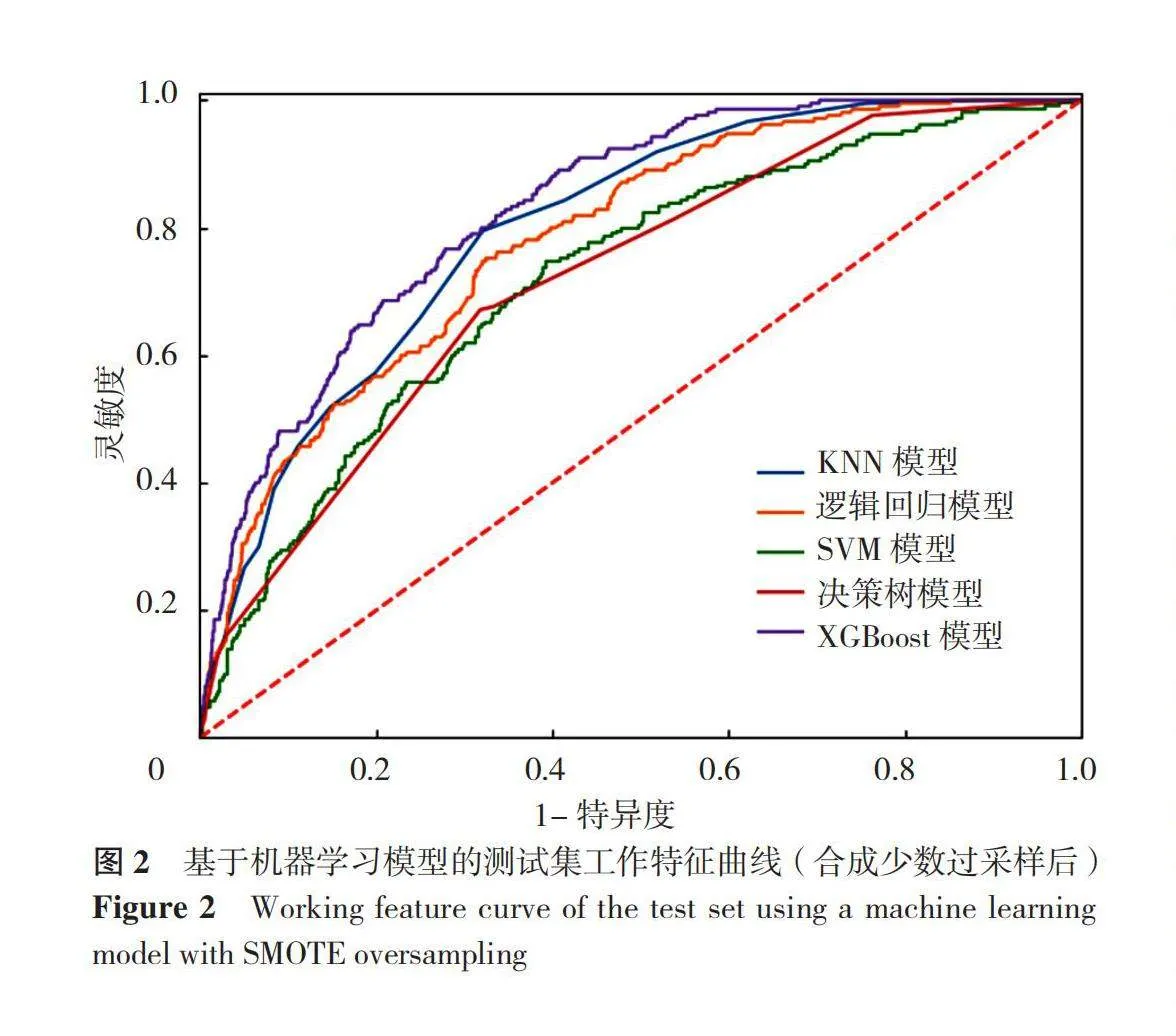
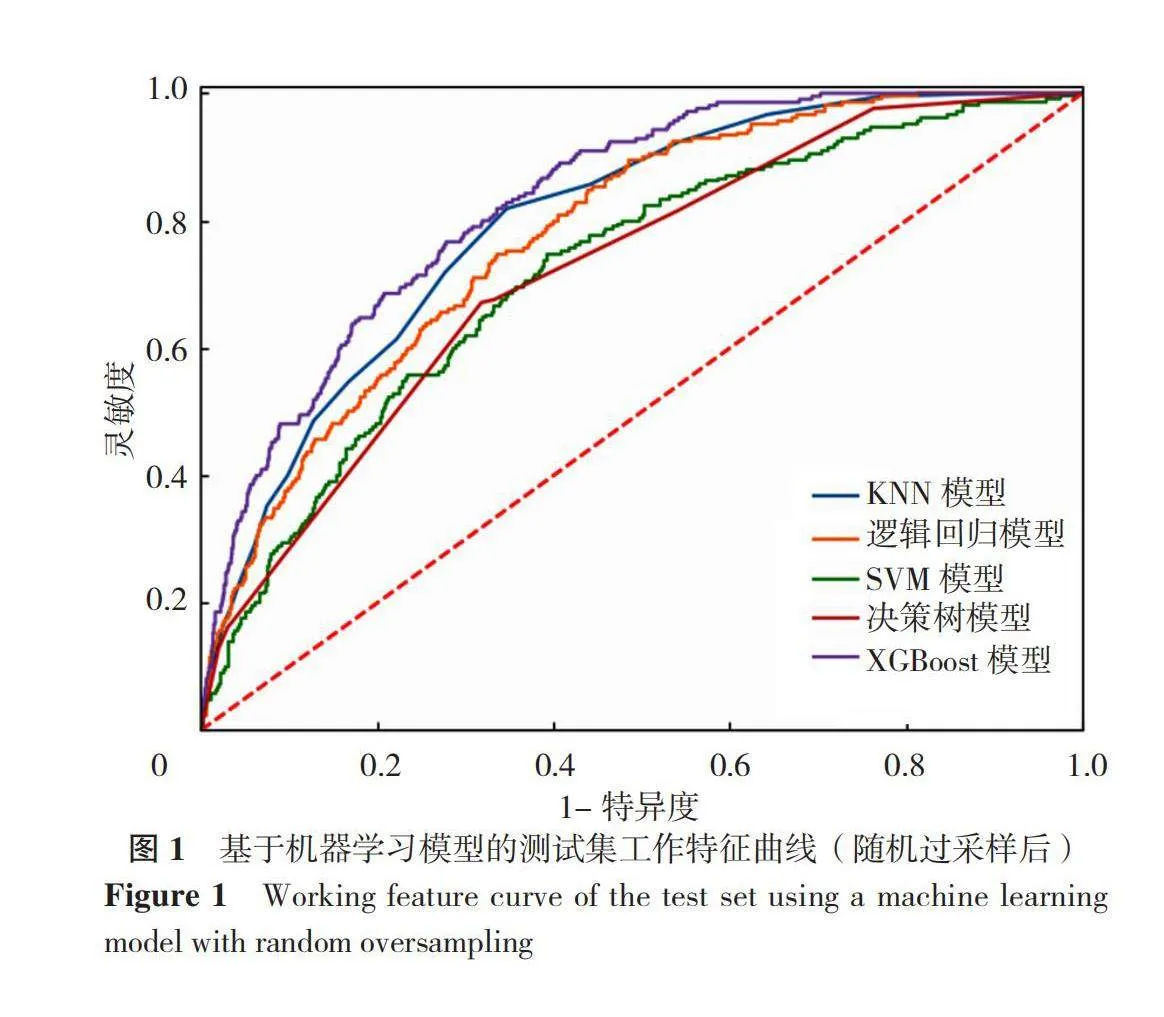
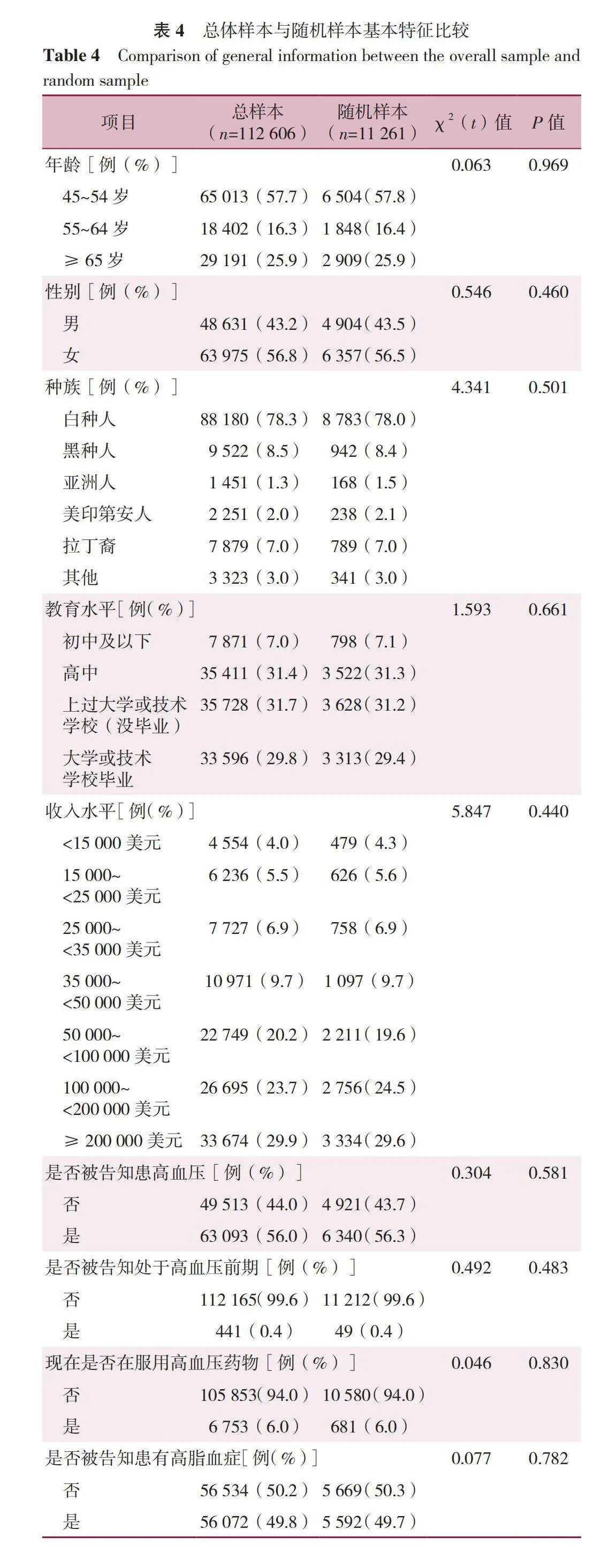
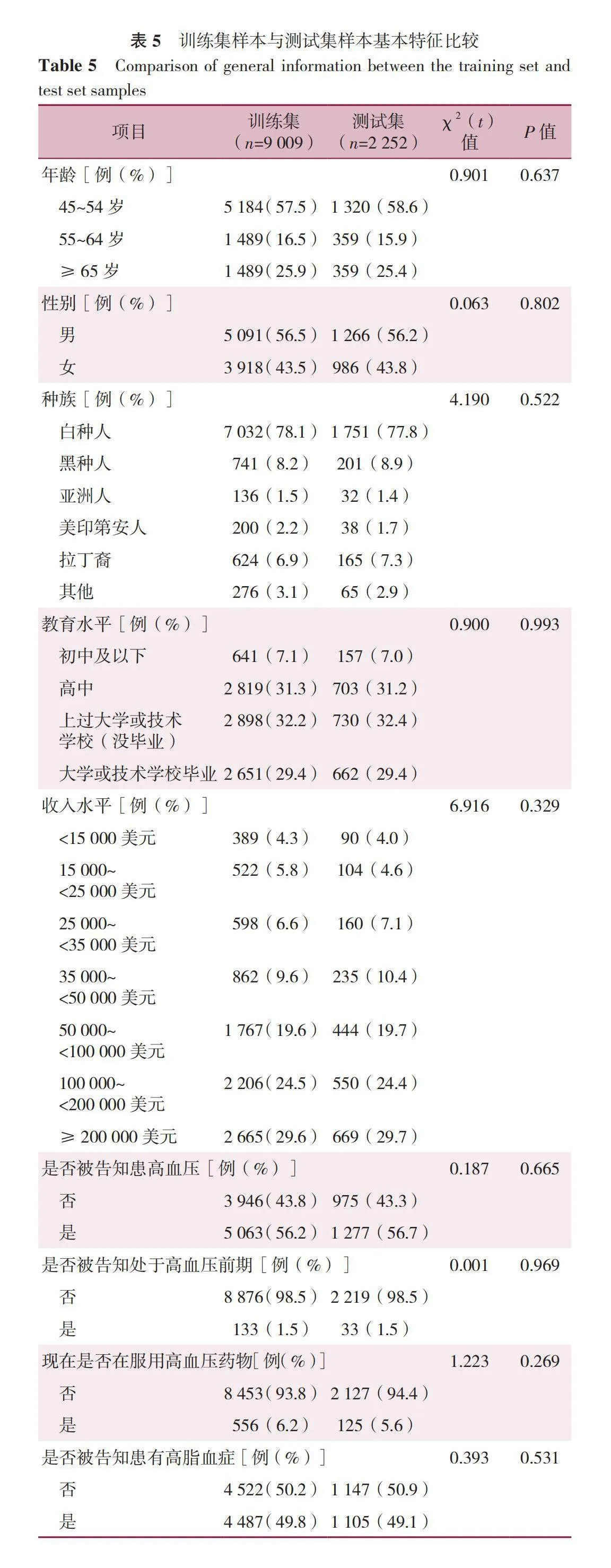
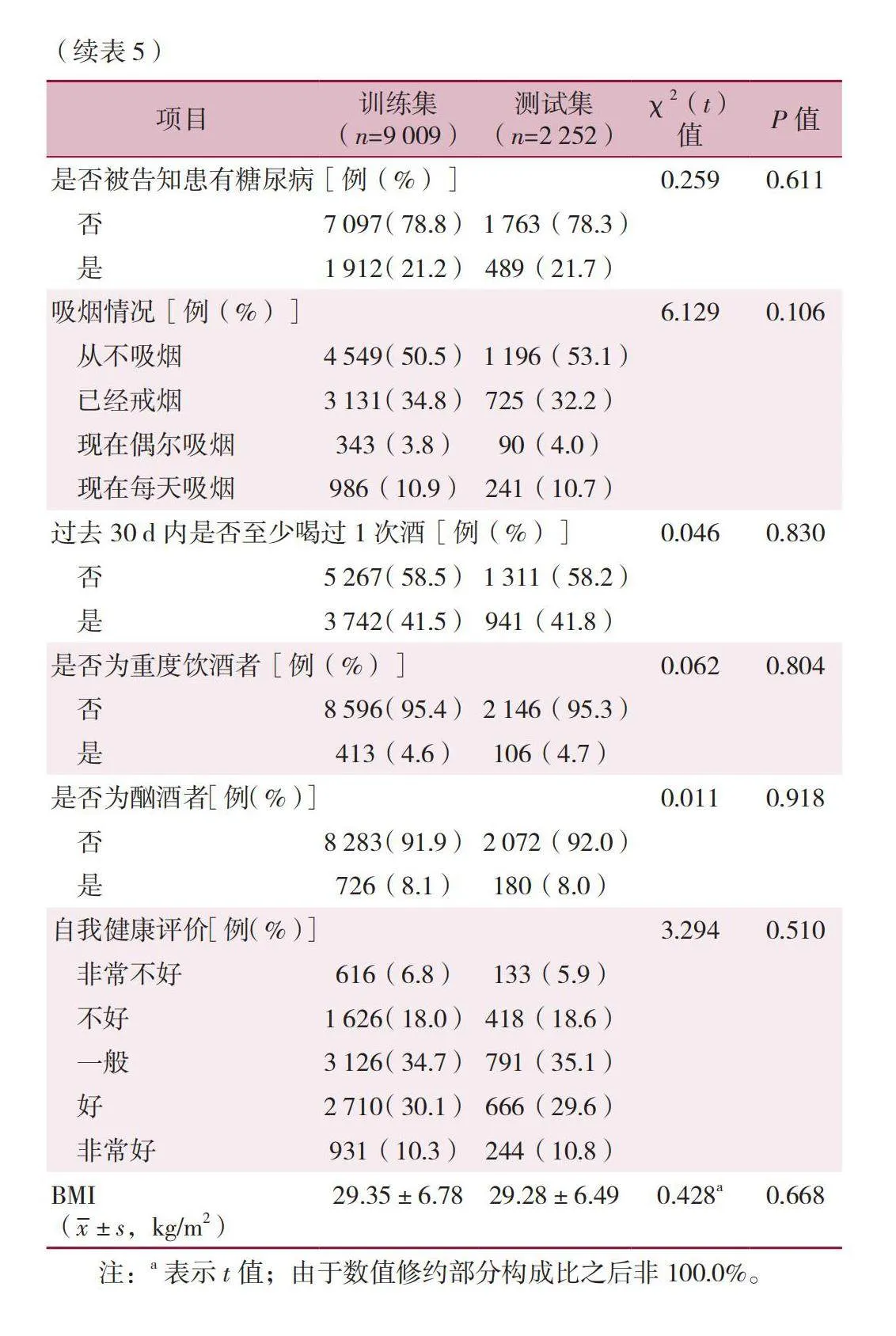
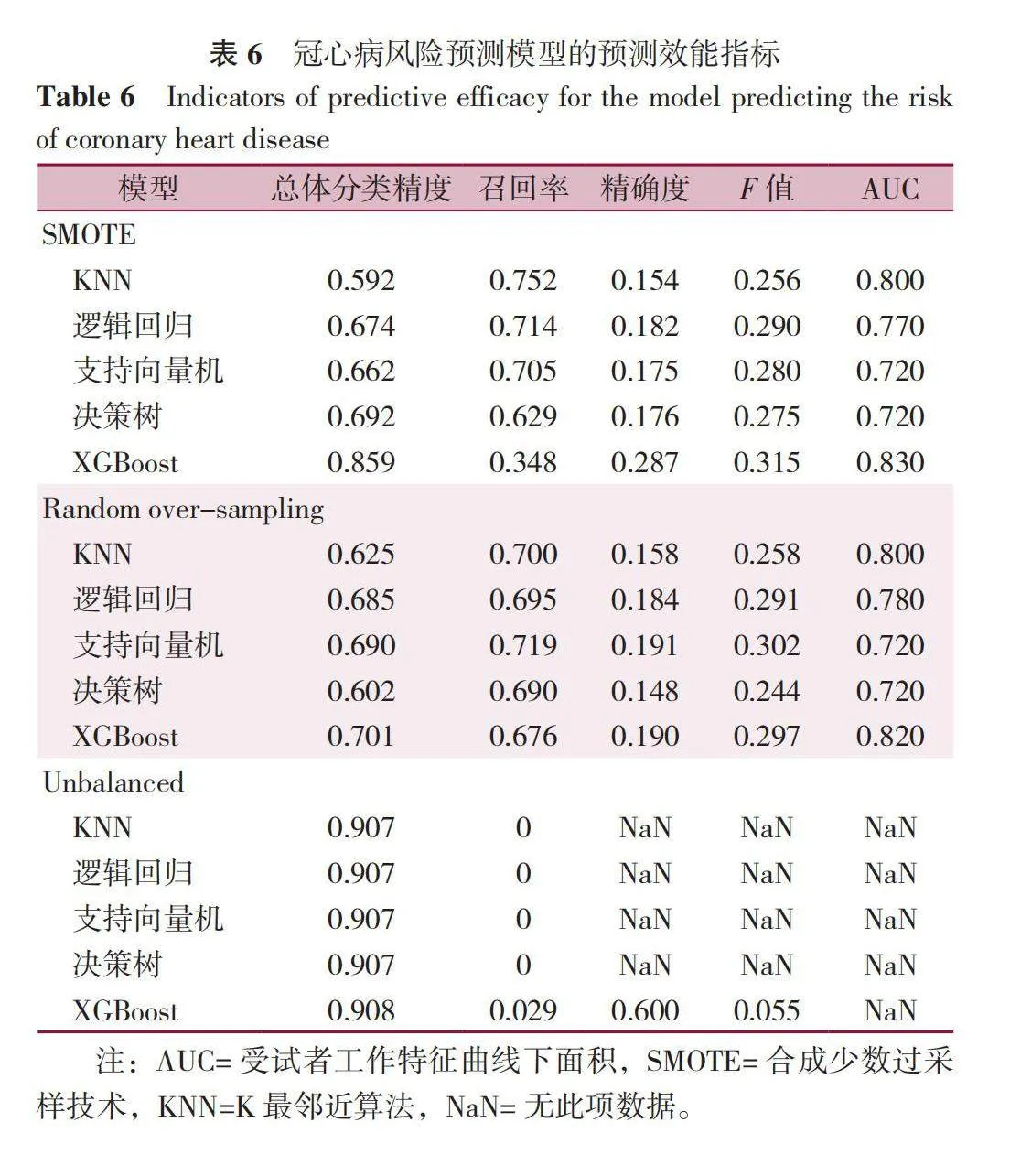
本研究采用随机抽样方法,从112 606名受访者中选取了10%(即11 261名)的样本,以构建代表性的训练集和测试集。对比总体样本(n=112 606)与随机抽取的样本(n=11 261)在预测模型的17个变量上的差异,结果显示差异无统计学意义(Pgt;0.05),详见表4。此外,按照8∶2的比例将数据随机抽取样本分为训练集(80%)和测试集(20%),并对训练集样本(n=9 009)与测试集样本(n=2 252)在预测模型的17个变量上进行比较,结果显示差异无统计学意义(Pgt;0.05),详见表5。分别利用5种算法对原始数据集和平衡后的数据集构建冠心病预测模型,预测模型的总体分类精度、精确度、召回率、F值见表6。在不平衡数据集中使用机器学习方法建模后,测试集中预测模型的召回率、精确度、F值较低。相比之下,经过数据平衡处理后,机器学习方法建立模型的整体效能提高,尤其是对于阳性样本的分类正确率。在采用Rand-Oversample和SMOTE过采样方法训练的5种算法中,XGBoost模型在预测冠心病方面表现最出色,其测试集的ROC曲线下面积(AUC)达到0.83。其次是KNN模型,测试集中AUC为0.80。在测试集中,除支持向量机模型与决策树模型在预测冠心病风险方面表现较差,AUC仅为0.72外,其余几种机器学习算法建立的冠心病预测模型的效能均较佳。两种不同采样方法下的各个模型的测试集工作特征曲线如下图1和图2所示。
3 讨论
本研究探索了多种冠心病发病的影响因素,通过使用随机过采样和SMOTE两种数据平衡方法,建立了基于5种不同算法的冠心病风险预测模型,并对其预测价值进行了比较。结果表明,数据平衡显著提升了模型的性能,尤其是XGBoost模型在总体分类精度、召回率、精确度、F值和AUC值方面的表现均优于其他模型,显示出其在冠心病风险预测上的强大潜力。
3.1 冠心病发病的影响因素
本研究结果确认了已知的冠心病风险因素,如年龄、性别、高血压、高脂血症、糖尿病和吸烟等。但更重要的是发现自我健康评价水平、收入水平和教育水平是冠心病的潜在影响因素。其中,自我健康评价和收入水平对冠心病发病的影响与ORIMOLOYE等[18]和HEMINGWAY等[19]的研究结果相同。尽管自我健康评价是主观的评价指标,但在流行病学和健康经济学研究中,此指标已被证实与死亡率、住院率及慢性病发病率等客观健康指标密切相关。例如,DESALVO等[20]的研究发现,自我健康评价与死亡风险之间存在显著关系,即使在控制了其他健康指标后,这种关系仍然存在。MAVADDAT等[21]的系统综述中也发现,在既往有和没有心血管疾病的人群中,自评健康状况不佳都与心血管死亡率有关。因此,自我健康评价在个体冠心病风险的预测中具有不容忽视的价值。然而,考虑到自我健康评价可能受到个人主观感受的影响,存在一定程度的主观偏差,在应用这一指标时应保持谨慎。教育水平与TILLMAN等[22]的研究结果相反,这可能是因为教育水平高的人虽然健康意识更高,但其职业压力和不健康的饮食习惯更多,这一定程度上也会增加冠心病的风险。此外,本研究发现患有妊娠高血压或糖尿病前期并不能增加患冠心病的风险。这与当前许多研究结果不一致,如妊娠高血压[23]以及糖尿病前期[24]与冠心病有关的研究结果。但是,本研究结果与HOZAWA等[25]关于高血压前期与心脑血管疾病的关系研究结果一致。同时,当前服用高血压药物能够降低冠心病的发病风险,这与CORRAO等[26]的研究结果一致。无论是已经戒烟、现在偶尔吸烟还是现在每天吸烟都能够显著增加患冠心病的风险,并且已经戒烟的人群中患冠心病的风险更高,与相关研究一致[27]。关于喝酒对冠心病的影响,本研究发现过去30 d内至少喝过1次、重度饮酒以及酗酒都能显著降低冠心病的发病风险,目前比较的成熟的研究表明平均饮酒量对冠心病的影响呈J型,轻度至中度饮酒者的冠心病发病风险比戒酒者低,但重度饮酒者中的冠心病风险最高[28],此外,ZHAO等[29]的研究也证实与不饮酒者相比,轻度至中度饮酒能够显著降低心血管疾病的死亡率。
3.2 冠心病风险预测模型
本研究结果表明在经过不平衡数据的处理后,5种算法在准确率和稳定性方面都有了显著提高,其中XGBoost模型对冠心病的预测效能最佳,这与ZHANG等[30]在冠状动脉疾病风险预测模型构建中得到的结论一致,而支持向量机模型与决策树模型在预测冠心病风险方面表现较差。因为相比其他4种机器学习方法,XGBoost采用了更为优秀的树结构优化方法,例如叶子节点权重缩减等[31]。此外,在每次训练模型时,XGBoost还会对模型进行正则化,以避免过拟合,并且使用了一种经过优化的目标函数,这能够更有效地控制决策树的生成,从而提高模型的精度[32]。此外,XGBoost在训练过程中还能够对特征进行子采样并且还支持并行计算,能够利用多核中央处理机和分布式环境加速模型训练[33]。
在模型的总体分类精度表现方面k最邻近算法得分较低,这与PAPANIKOLAOU等[34]的研究结果一致,但其简单性和易于实现可能在某些情况下具有优势[35],虽然决策树算法的准确率略低,但其是一种成熟的算法,在TEAM[36]的研究发现决策树算法在冠心病风险预测表现较好,本研究结果与其不一致的原因可能是决策树算法对输入数据的微小变化很灵敏,这可能导致树结构和预测结果发生很大变化并且进一步降低冠心病风险预测模型的稳定性,从而导致准确性降低[37]。支持向量机算法在精准度、召回率和F1评分方面表现良好,JAISWAL等[38]在使用多种机器学习方法构建冠心病的诊断模型中也得到相同的结论,可见使用支持向量机算法构建的预测模型可以有效降低疾病诊断的假阳性率。逻辑回归在精度和稳定性方面表现出良好的性能,所以这可成为大规模人群预测模型研究的最佳选择。虽然XGBoost是5种算法中冠心病风险预测的最佳算法,但算法的选择将取决于预测任务的具体要求,其较低的召回率表示在实际使用的过程中可能无法筛查出阳性。一般来说,算法的性能受到数据集的大小和质量以及使用的预测变量的数量的影响[38]。本研究强调了不同算法在冠心病风险预测中的优势和劣势,未来计划扩展研究,包括更多的算法和更大的数据集,以更好地评估这些算法的性能。
3.3 本研究的优点和局限性
本研究的一个显著特点是采用了先进的数据平衡技术,并探索了多种机器学习算法在处理冠心病数据时的效能。优化后的XGBoost模型不仅性能出色,且考虑到其与逐步Logistic回归分析的综合应用,为临床实践提供了更高的可行性和准确性。此外本次研究有模型输入变量都来自自我报告,所以具有可及性高、数据信噪比较低以及贴近实际应用场景等优势。然而,本研究的方法也存在一定的局限性。首先,由于机器学习模型的构建基于逻辑回归筛选后的变量,可能忽略了一些未被初步选中但实际上对疾病预测有潜在价值的变量。其次,本文的研究数据来源于美国人群自我报告的横断面BRFSS数据库,数据的可获取性和实际应用场景的贴近性是其优势所在。然而,此类数据可能受到回忆偏差的影响,且横断面研究的设计限制了对因果关系的探讨,并存在结局变量影响输入变量的可能。此外,研究中仅考察了有限的预测模型,并未包括已验证有效的其他模型,如人工神经网络(Artificial Neural Network,ANN)、随机森林和朴素贝叶斯。尽管有研究显示CatBoost和LightGBM等梯度提升模型在风险预测上有优秀表现,但本研究未能涉及[39-40]。
4 小结
在处理不平衡数据后,KNN、SVM、决策树、逻辑回归和XGBoost这5种机器学习算法在预测冠心病风险方面的性能可以显著提高,XGBoost是这五种算法中表现最佳的。但是,算法的选择将取决于预测任务的具体要求,以及考虑预测准确性、计算能力、可解释性和运行效率等方面[41]。此外,虽然本研究所采用的方法论和策略在其他人群中具有普适性,但特定的风险预测结果并不适宜直接应用于非美国地区。未来的研究可以通过纳入更广泛的预测模型和多元化的数据来源,来提高模型的普适性和预测的精确度。
作者贡献:岳海涛、何婵婵负责数据分析及解读、文章撰写、文章修改;成羽攸、张森诚协助数据分析及文章撰写;吴悠、马晶负责研究设计、文章的质量控制与审查,监督管理,对文章整体负责。
本文无利益冲突。
参考文献
马丽媛,王增武,樊静,等. 《中国心血管健康与疾病报告2021》要点解读[J]. 中国全科医学,2022,25(27):3331-3346. DOI:10.12114/j.issn.1007-9572.2022.0506.
SAFIRI S,KARAMZAD N,SINGH K,et al. Burden of ischemicheart disease and its attributable risk factors in 204 countries and territories,1990-2019[J]. Eur J Prev Cardiol,2022,29(2):420-431. DOI:10.1093/eurjpc/zwab213.
DAI H J,MUCH A A,MAOR E,et al. Global,regional,and national burden of ischaemic heart disease and its attributable risk factors,1990-2017:results from the Global Burden of Disease Study 2017[J]. Eur Heart J Qual Care Clin Outcomes,2022,8(1):50-60. DOI:10.1093/ehjqcco/qcaa076.
D'AGOSTINO R B Sr,VASAN R S,PENCINA M J,et al. General cardiovascular risk profile for use in primary care:the Framingham Heart Study[J]. Circulation,2008,117(6):743-753. DOI:10.1161/CIRCULATIONAHA.107.699579.
ANDRUS B,LACAILLE D. 2013 ACC/AHA guideline on the assessment of cardiovascular risk[J]. J Am Coll Cardiol,2014,63(25 Pt A):2886. DOI:10.1016/j.jacc.2014.02.606.
CUENDE J I,CUENDE N,CALAVERAS-LAGARTOS J. How to calculate vascular age with the SCORE project scales:a new method of cardiovascular risk evaluation[J]. Eur Heart J,2010,31(19):2351-2358. DOI:10.1093/eurheartj/ehq205.
ZHANG L Y,NIU M M,ZHANG H Y,et al. Nonlaboratory-based risk assessment model for coronary heart disease screening:model development and validation[J]. Int J Med Inform,2022,162:104746. DOI:10.1016/j.ijmedinf.2022.104746.
AMBRISH G,GANESH B,GANESH A,et al. Logistic regression technique for prediction of cardiovascular disease[J]. Glob Transitions Proc,2022,3(1):127-130. DOI:10.1016/j.gltp.2022.04.008.
马婧怡,刘相佟,吕世云,等. 北京市成年人冠心病七年发病风险评估与预测模型[J]. 心肺血管病杂志,2022,41(1):25-30,50. DOI:10.3969/j.issn.1007-5062.2022.01.006.
李婕,向菲. 冠心病风险因素识别及其预测模型构建[J]. 中华医学图书情报杂志,2020,29(6):7-13. DOI:10.3969/j.issn.1671-3982.2020.06.002.
王晓丽,施天行,彭德荣,等. 两种机器学习算法构建老年冠心病患病风险评估模型的效能比较研究[J]. 中华全科医学,2021,19(4):523-527. DOI:10.16766/j.cnki.issn.1674-4152.001852.
谭志军,梁英,石福艳,等. 基于企业健康管理的劳动力人群冠心病风险评估模型研究[J]. 现代预防医学,2017,44(12):2192-2195,2210.
ALI H,MOHD SALLEH M N,SAEDUDIN R,et al. Imbalance class problems in data mining:a review[J]. Indones J Electr Eng Comput Sci,2019,14(3):1552. DOI:10.11591/ijeecs.v14.i3.pp1552-1563.
齐俊锋,韩胜红,李俊琳,等. 心血管病危险因素的风险特征分析及疾病预测模型研究[J]. 现代预防医学,2022,49(18):3283-3287. DOI:10.20043/j.cnki.MPM.202111359.
Delaware Department of Health and Social Services,Division of Public Health,Delaware Behavioral Risk Factor Survey (BRFS) [EB/OL]. [2023‑04‑30]. https://dhss.delaware.gov/dhss/dph/index.html.
The behavioral risk factor surveillance system[EB/OL].(2022‑12‑02)[2023‑04‑30]. https://www.cdc.gov/brfss/index.html.
CHAWLA N V,BOWYER K W,HALL L O,et al. SMOTE:synthetic minority over-sampling technique[J]. Jair,2002,16:321-357. DOI:10.1613/jair.953.
ORIMOLOYE O A,MIRBOLOUK M,IFTEKHAR UDDIN S M I,et al. Association between self-rated health,coronary artery calcium scores,and atherosclerotic cardiovascular disease risk:the multi-ethnic study of atherosclerosis(MESA)[J]. JAMA Netw Open,2019,2(2):e188023. DOI:10.1001/jamanetworkopen.2018.8023.
HEMINGWAY A. Determinants of coronary heart disease risk for women on a low income:literature review[J]. J Adv Nurs,2007,60(4):359-367. DOI:10.1111/j.1365-2648.2007.04418.x.
DESALVO K B,BLOSER N,REYNOLDS K,et al. Mortality prediction with a single general self-rated health question. A meta-analysis[J]. J Gen Intern Med,2006,21(3):267-275. DOI:10.1111/j.1525-1497.2005.00291.x.
MAVADDAT N,PARKER R A,SANDERSON S,et al. Relationship of self-rated health with fatal and non-fatal outcomes in cardiovascular disease:a systematic review and meta-analysis[J]. PLoS One,2014,9(7):e103509. DOI:10.1371/journal.pone.0103509.
TILLMANN T,VAUCHER J,OKBAY A,et al. Education and coronary heart disease:Mendelian randomisation study[J]. BMJ,2017,358:j3542. DOI:10.1136/bmj.j3542.
CANOY D,CAIRNS B J,BALKWILL A,et al. Hypertension in pregnancy and risk of coronary heart disease and stroke:a prospective study in a large UK cohort[J]. Int J Cardiol,2016,222:1012-1018. DOI:10.1016/j.ijcard.2016.07.170.
HUANG Y L,CAI X Y,MAI W Y,et al. Association between prediabetes and risk of cardiovascular disease and all cause mortality:systematic review and meta-analysis[J]. BMJ,2016,355:i5953. DOI:10.1136/bmj.i5953.
HOZAWA A,KURIYAMA S,KAKIZAKI M,et al. Attributable risk fraction of prehypertension on cardiovascular disease mortality in the Japanese population:the Ohsaki Study[J]. Am J Hypertens,2009,22(3):267-272. DOI:10.1038/ajh.2008.335.
CORRAO G,NICOTRA F,PARODI A,et al. Cardiovascular protection by initial and subsequent combination of antihypertensive drugs in daily life practice[J]. Hypertension,2011,58(4):566-572. DOI:10.1161/HYPERTENSIONAHA.111.177592.
BOUABDALLAOUI N,MESSAS N,GREENLAW N,et al. Impact of smoking on cardiovascular outcomes in patients with stable coronary artery disease[J]. Eur J Prev Cardiol,2021,28(13):1460-1466. DOI:10.1177/2047487320918728.
MATSUMOTO-YAMAUCHI H,KONDO K,MIURA K,et al. Relationships of alcohol consumption with coronary risk factors and macro- and micro-nutrient intake in Japanese people:the INTERLIPID study[J]. J Nutr Sci Vitaminol,2021,67(1):28-38. DOI:10.3177/jnsv.67.28.
ZHAO J H,STOCKWELL T,ROEMER A,et al. Alcohol consumption and mortality from coronary heart disease:an updated meta-analysis of cohort studies[J]. J Stud Alcohol Drugs,2017,78(3):375-386. DOI:10.15288/jsad.2017.78.375.
ZHANG S S,YUAN Y Y,YAO Z H,et al. Improvement of the performance of models for predicting coronary artery disease based on XGBoost algorithm and feature processing technology[J]. Electronics,2022,11(3):315. DOI:10.3390/electronics11030315.
LIU J L,WU J F,LIU S R,et al. Predicting mortality of patients with acute kidney injury in the ICU using XGBoost model[J]. PLoS One,2021,16(2):e0246306. DOI:10.1371/journal.pone.0246306.
ZHENG H T,YUAN J B,CHEN L. Short-term load forecasting using EMD-LSTM neural networks with a xgboost algorithm for feature importance evaluation[J]. Energies,2017,10(8):1168. DOI:10.3390/en10081168.
DHALIWAL S,NAHID A A,ABBAS R. Effective intrusion detection system using XGBoost[J]. Information,2018,9(7):149. DOI:10.3390/info9070149.
HASSAN C A U,IQBAL J,IRFAN R,et al. Effectively predicting the presence of coronary heart disease using machine learning classifiers[J]. Sensors,2022,22(19):7227. DOI:10.3390/s22197227.
PAPANIKOLAOU M,EVANGELIDIS G,OUGIAROGLOU S. Dynamic k determination in k-NN classifier:a literature review[C]//2021 12th International Conference on Information,Intelligence,Systems amp; Applications(IISA). Chania Crete,Greece. IEEE,2021:1-8. DOI:10.1109/IISA52424.2021.9555525.
KIM J,LEE J,LEE Y. Data-mining-based coronary heart disease risk prediction model using fuzzy logic and decision tree[J]. Healthc Inform Res,2015,21(3):167-174. DOI:10.4258/hir.2015.21.3.167.
TEAM C. Decision Tree[EB/OL].(2022-11-29)[2023-02-12].
https://corporatefinanceinstitute.com/resources/data-science/decision-tree/.
GARAVAND A,SALEHNASAB C,BEHMANESH A,et al. Efficient model for coronary artery disease diagnosis:a comparative study of several machine learning algorithms[J]. J Healthc Eng,2022,2022:5359540. DOI:10.1155/2022/5359540.
JAISWAL S,GUPTA P. Ensemble approach:XGBoost,CATBoost,and LightGBM for diabetes mellitus risk prediction[C]//2022 Second International Conference on Computer Science,Engineering and Applications(ICCSEA). Gunupur,India. IEEE,2022:1-6. DOI:10.1109/ICCSEA54677.2022.9936130.
白皙,罗云云,周智博,等. 基于机器学习算法的大于胎龄儿风险预测模型[J]. 中华流行病学杂志,2021,42(12):2143-2148. DOI:10.3760/cma.j.cn112338-20210824-00677.
马倩倩,孙东旭,石金铭,等. 基于支持向量机与XGboost的成年人群肿瘤患病风险预测研究[J]. 中国全科医学,2020,23(12):1486-1491. DOI:10.12114/j.issn.1007-9572.2020.00.066.
(收稿日期:2024-03-16;修回日期:2024-09-11)
(本文编辑:崔莎)
