国家中心城市碳排放达峰预测及影响因素研究
2024-12-07胡剑波叶树张宽元







[摘要] 本文运用STIRPAT扩展形式,通过GRU模型预测4个非控制性变量,并结合“十四五”规划中3个控制性变量,构建包含7个变量的GRU模型,对国家中心城市碳排放进行预测,并分析其影响因素。为了预测结果的稳健性,本文采用Informer模型进行检验。研究表明:(1)使用GRU模型预测非控制性变量,国家各个中心城市的总人口、进出口总额、研发支出及能源消费总体均呈上升态势。(2)GRU预测结果和Informer校验结果均表明,北京市、上海市为碳达峰先锋城市,将于2025年前达峰;重庆市为碳达峰平稳城市,将于2030年前达峰;天津市和广州市为碳达峰迟缓城市,但总体碳排放量可控。国家中心城市的碳排放强度均呈下降趋势,差距在逐渐缩小。(3)GRU模型的影响因素分析显示,总人口、能源消费量会对碳排放产生正向效应,而森林覆盖率、研发支出及能源结构会对碳排放量产生抑制作用。
[关键词] 碳达峰 预测 机器学习 影响因素
[基金项目] 本文为国家社会科学基金项目“中国隐含碳全要素生产率动态演进与提升策略研究”(编号:23XJY022)的阶段性成果。
[作者简介] 胡剑波,贵州财经大学经济学院教授、博士生导师,研究方向为低碳经济与绿色发展、气候变化经济学;叶树(通讯作者),上海财经大学公共经济与管理学院博士研究生,研究方向为低碳经济与城市发展,邮箱:shuye000503@163.com;张宽元,西安交通大学经济与金融学院博士研究生,研究方向为低碳经济。
[中图分类号] F29;X51
[文献标识码] A
[文章编号] 1008-7672(2024)05-0130-19
一、 引言
近年来,由碳排放增加引起的全球变暖问题在世界各国引起了广泛关注。2020年9月,国家主席习近平在第七十五届联合国大会一般性辩论上向世界做出重要承诺:“二氧化碳排放力争于2030年前达到峰值,努力争取2060年前实现碳中和。”城市消耗大量的经济能源,对气候变暖产生重大的影响。联合国政府间气候变化专门委员会(Intergovernmental Panel on Climate Change,IPCC)第五次评估报告指出,城市消耗占全球能耗总量的67%~76%。城市由于具有产业结构优化的巨大潜力与能源清洁技术提高的巨大动力,可以通过制定规范的减排策略、合理的政策引导①,提升综合达峰水平,推进绿色低碳转型。
2010年,住房和城乡建设部发布的《全国城镇体系规划(2010—2020年)》首次提出,将北京市、天津市、上海市、广州市、重庆市等设立为首批国家中心城市,并在2016年后设立成都、武汉、郑州、西安等市为新一批国家中心城市。据此,国家九大中心城市在经济、社会、交通、文化、信息技术以及全国城镇化等建设发展方面处于主导地位。②如何冲破传统思维定式,发挥区位优势,提升城市综合功能,推进属地区域产业城镇集群发展,尽快实现“双碳”目标,发挥国家中心城市引领功能,是亟待解决的重大难题。
本文测算国家中心城市碳排放现状,模拟国家中心城市碳排放趋势,预测国家中心城市碳排放强度,分析碳排放影响因素,重点聚焦国家中心城市是否能于2030年前碳达峰,为科学制定政策指标及碳减排行动提供支撑。
二、 文献综述
梳理国内外相关文献,笔者发现已有研究对不同区域和预测模型进行了有益的探讨。在宏观层级方面,预测国家层面的碳排放达峰是重要的研究方向。一些学者分析中国碳减排政策,通过结构模型预测中国将在2030年前实现碳达峰。③一些学者基于混频数据ADL-MIDAS模型对“十四五”规划期间中国碳排放结构及总量进行预测,预计2025年全国碳排放总量接近115亿吨。④构建包含中国终端部门的新型综合评估RICE-LEAP模型,一些学者模拟2020—2050年全球气候变化趋势及中国碳达峰路径,认为在供给侧改革背景下中国最早于2029年碳达峰,且峰值水平最低。①省域层面的碳达峰预测也是重要的研究方向。有学者测算中国省市2005—2019年脱钩系数,得出在混合式增长模式下大部分省份于2026年左右完成碳达峰目标。②一些学者基于混合型能源投入产出模型,预测2020—2040年全国30个省(自治区、直辖市)在经济发展和碳排放强度改善的9种情景下的碳排放总量,得出各个省的碳达峰时间点。③
现阶段主流的预测方法主要有灰色预测法、多情景模拟法和机器学习法。(1)灰色预测法主要是针对数据序列的预处理,通过灰方程背景值构造、响应式生成和还原过程,以累加形式进行数据生成预测。④一些学者基于自适应调节的灰色滚动预测模型ARGM(1,1)对中国宏观范围能源碳排放趋势进行预测,其研究结果较好地拟合了中国能源领域的发展趋势。⑤一些学者结合GM(1,1)模型对青藏高原东缘生态过渡带碳汇量进行预测,并对不同情景下碳汇量演变趋势进行模拟研究,他们认为在没有宏观调控的情况下,碳汇量始终无法抵消碳排放量。⑥(2)多情景模拟法。一些学者利用拓展STIRPAT模型测算2005—2019年长三角城市群碳排放量,认为大部分城市能在2030年前率先达峰。⑦一些学者运用STIRPAT模型分析交通运输、仓储和邮政业增加值、人口总量、旅客周转量、货物周转量和节能技术水平对交通二氧化碳排放量的影响,并预测了中国2021—2030年的交通碳排放量。⑧(3)机器学习法。目前神经网络模型被广泛运用于二氧化碳排放量预测。一些学者将ARIMA-BP神经网络和LSTM模型得到的碳排放强度预测值进行对比分析,预估中国2030年碳排放强度能够下降到0.9840吨/万元。⑨将门限STIRPAT模型与LSTM神经网络结合对中国工业碳排放预测,学者们发现持续调整的工业能源和行业结构可能会对自主技术创新的减排效果产生影响,进而影响工业碳排放。⑩然而,这类循环神经网络结构以顺序计算,上一时间点的输出完全决定下一时间点的权重。随着时间的增加其难度系数递增,预测精准度逐渐降低。对于长时间序列预测(Long sequence time-series forecasting,LSTF)而言,其计算过程可能存在信息丢失从而使算法误差较大。为进一步解决上述问题,谷歌团队于2017年应用自注意力(Self-Attention)运算机制,构建Transformer模型,解决对循环和卷积网络模型的依赖,避免信息的递归传递,并检测长序列中遥远的数据元素相互依赖的微妙关系。在Transformer模型基础上使用ProbSparse Self-Attention蒸馏机制优化原有的自注意力机制,提高了LSTF预测的准确性,很好地解决了长输入堆叠层的内存瓶颈,降低了常规自注意力计算的时间和空间的复杂度,是时间序列模型的新起点。
已有研究在区域层级多集中在中国整体或省级层面,在预测方法上的选择也比较多元,但却存在一定问题。传统灰色预测在处理快速变换的数据会与定性分析产生较大的偏差,只适合中短期和近似指数增长的预测,且预测研究精度与时间序列长短呈反向关系。①虽然LSTM可以解决循环网络神经不能长期依赖的问题,但是只能部分解决梯度问题。本文采用具有参数量更小、过拟合较少的门控循环网络(GRU)模型,通过多变量年度数据进行碳排放预测。Informer模型可以有效进行长时间序列输入和输出,通过月度碳排放的预测校验可以有效解决上述问题,因此,通过两种方法的结合可有效加强国家中心城市碳排放预测的科学性与合理性。本文的边际贡献是:(1)运用GRU模型与扩展STIRPAT方法,从“量”的角度探究国家中心城市碳排放达峰的峰值与峰时,并从“质”的角度检验其碳排放强度。(2)从森林覆盖率、能源结构、总人口、研发投入、能源消费量分解碳排放的影响因素,提高预测模型的经济学解释力。(3)采用Informer模型对国家中心城市月度碳排放数据进行预测,换算年度碳排放数据,提高预测准确度的同时进一步校验GRU模型预测结果。
三、 方法选取、模型构建和数据来源
(一) STIRPAT模型构建
扩展的STIRPAT模型在IPAT模型的基础上,容纳人口(P)、财富(A)、技术(T)的同时,拒绝单位弹性假设,并赋予模型更多的随机性,是最常用的碳排放达峰预测模型之一。②IPAT模型公式如式(1)所示:
I = aPbAcTdu(1)
式(1)中,a为模型系数,b、c、d皆为模型指数,u为随机误差项。
本文研究国家中心城市的碳排放达峰预测,因此使用扩展STIRPAT模型对影响因素做出适当优化,具体模型公式如式(2)所示:
C = aPbIcRdEfGgShFiu(2)
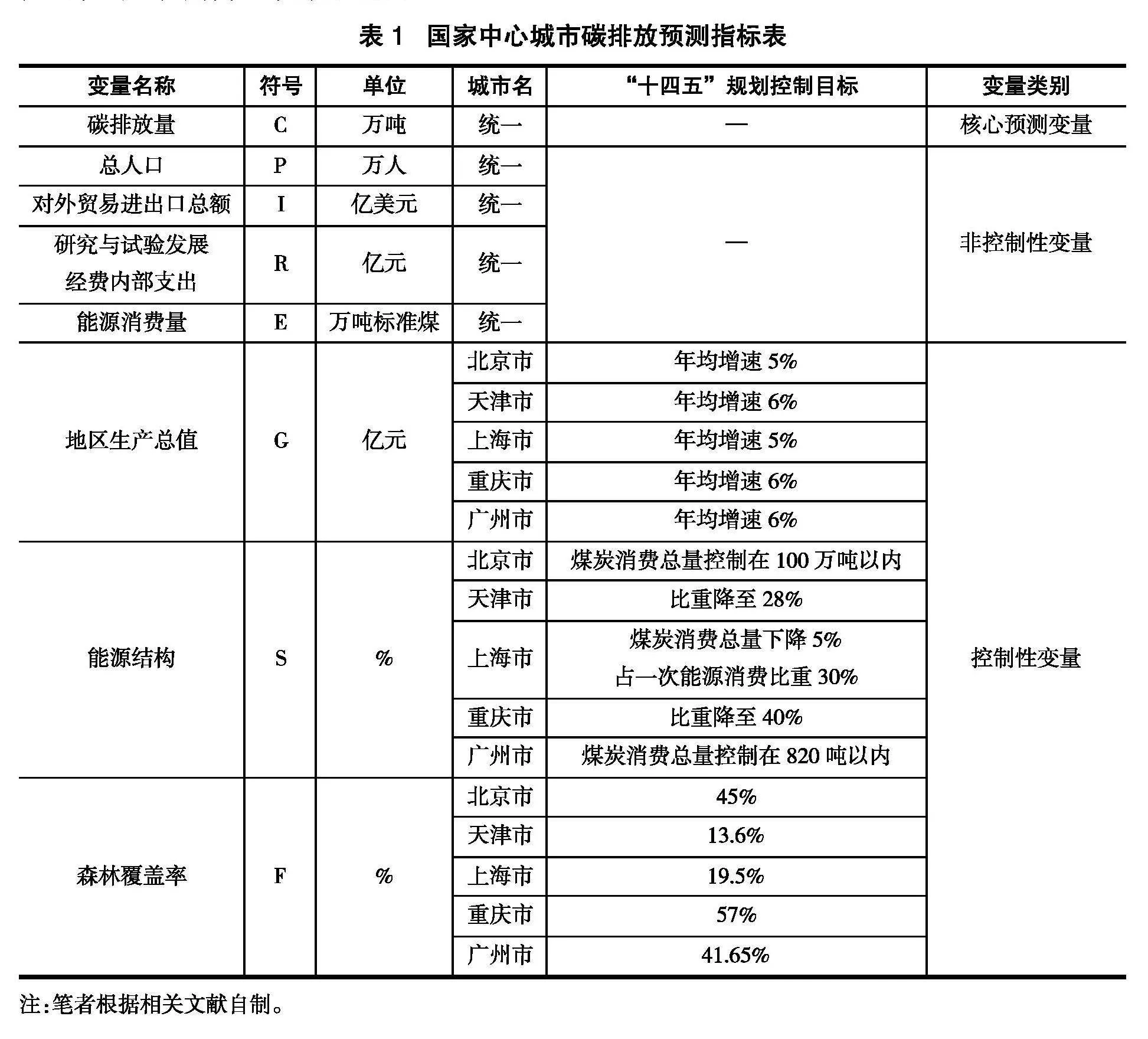
其中,C表示因变量城市的碳排放量①,P代表各个城市的总人口,I为各个城市的对外贸易进出口总额,R为城市研究与试验发展经费内部支出(下文简称“研发支出”),E为各城市能源消费量,G为各个城市地区生产总值,S为城市能源结构(计算方法为煤炭消费量占总能源消耗之比),F为森林覆盖率。具体指标说明如表1所示。
(二) GRU模型构建
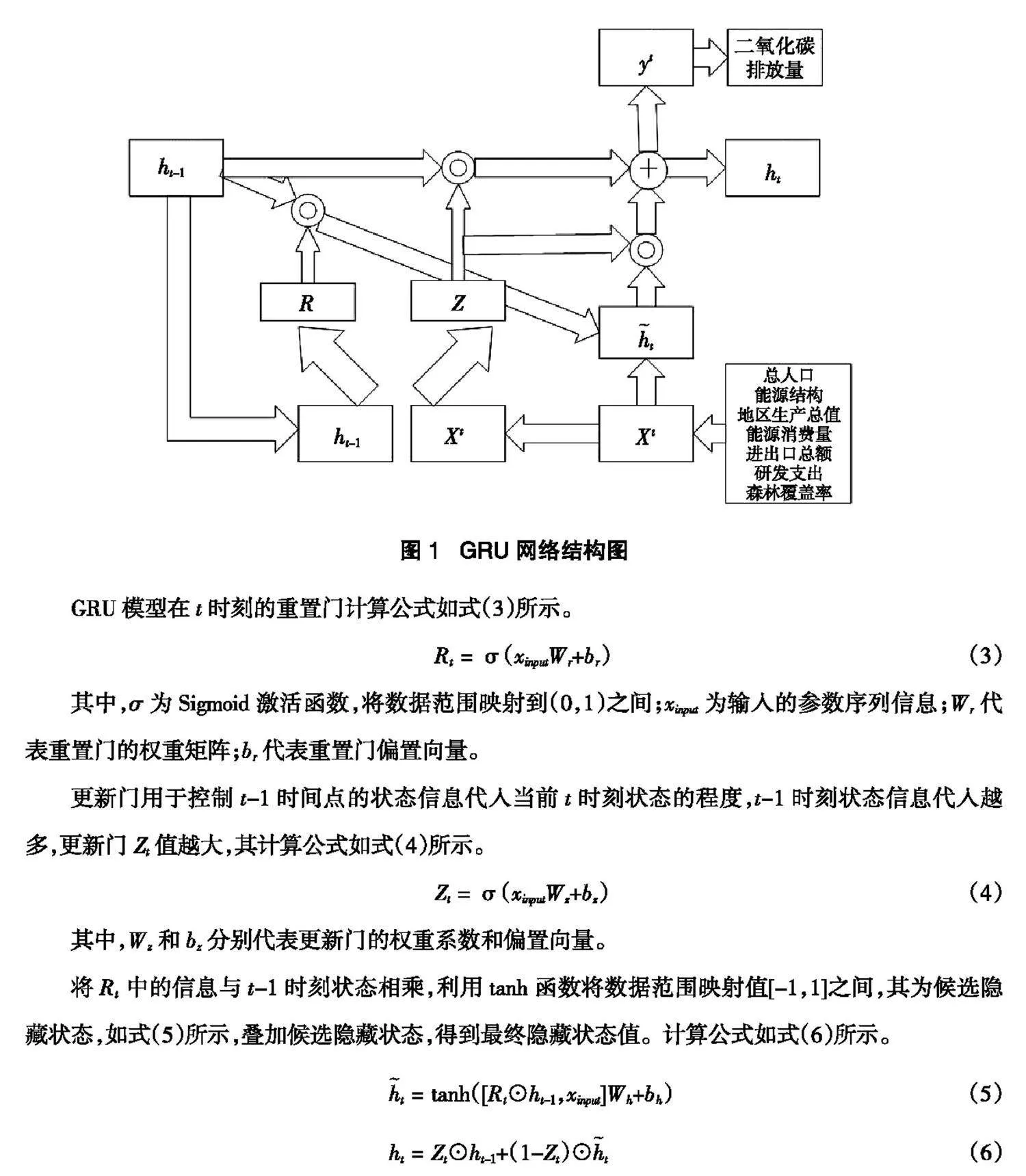
本文利用门控循环网络构建多变量模型进行国家中心城市的碳排放预测。GRU是基于循环神经网络结构的机器学习模型,将LSTM(Long Short Term Memory)的遗忘门、输入门结构进行合并优化,并形成更新门的结构网络,保留了LSTM模型优点,提高了序列数据训练的效率。①GRU模型的网络结构如图1所示。
GRU模型在t时刻的重置门计算公式如式(3)所示。
Rt = σ(xinputWr+br)(3)
其中,σ为Sigmoid激活函数,将数据范围映射到(0,1)之间;xinput为输入的参数序列信息;Wr代表重置门的权重矩阵;br代表重置门偏置向量。
更新门用于控制t-1时间点的状态信息代入当前t时刻状态的程度,t-1时刻状态信息代入越多,更新门Zt值越大,其计算公式如式(4)所示。
Zt = σ(xinputWz+bz)(4)
其中,Wz和bz分别代表更新门的权重系数和偏置向量。
将Rt 中的信息与t-1时刻状态相乘,利用tanh函数将数据范围映射值[-1,1]之间,其为候选隐藏状态,如式(5)所示,叠加候选隐藏状态,得到最终隐藏状态值。计算公式如式(6)所示。
t = tanh([Rt☉ht-1,xinput]Wh+bh)(5)
ht = Zt☉ht-1+(1-Zt)☉t(6)
经过上述公式的递归,不断迭代,最终得到本文所用的碳排放预测结构模型。
(三) Informer模型构建
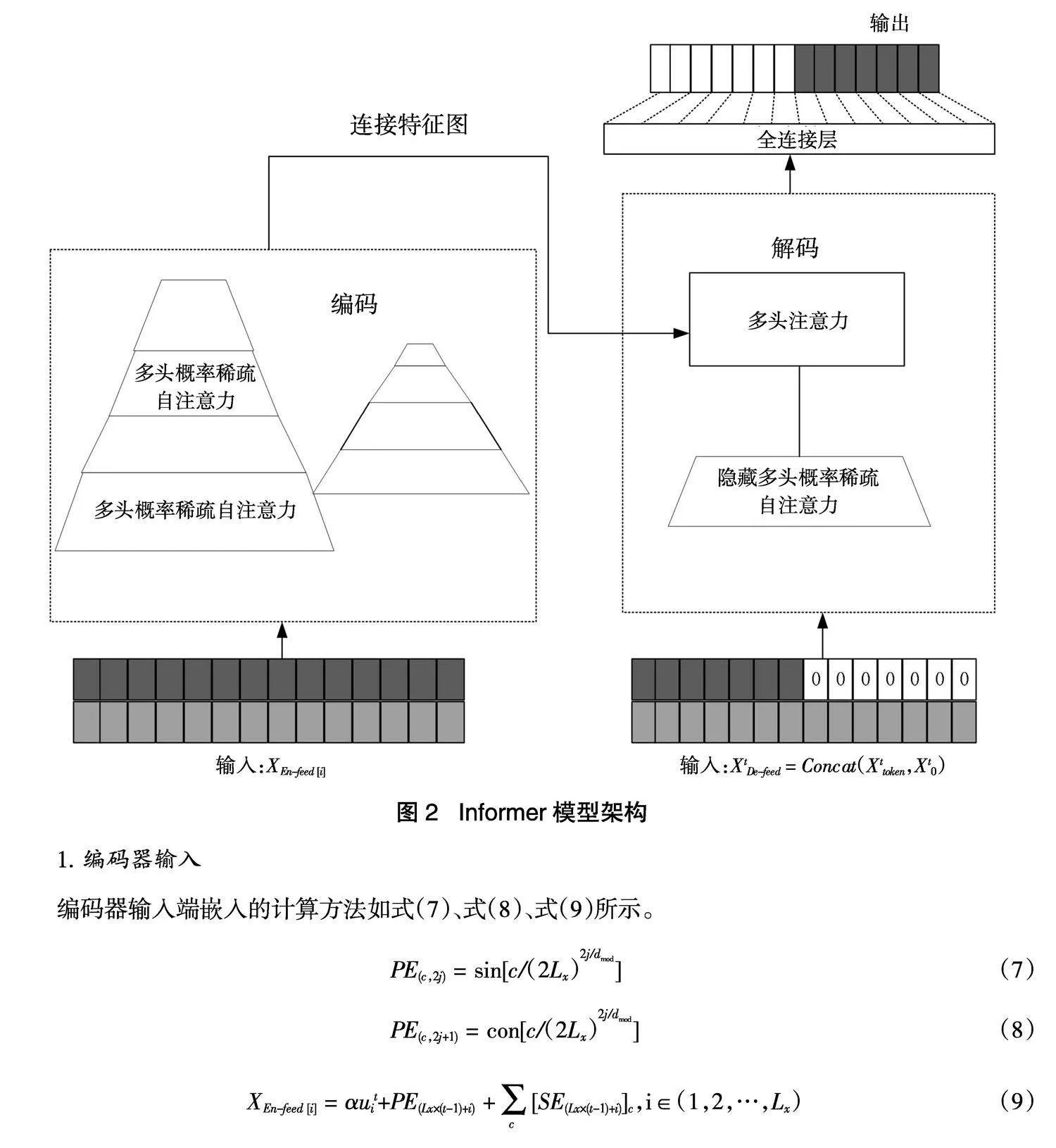
国家中心城市的月度碳排放采用Informer模型进行预测。Informer模型结构如图2所示。Informer模型是一种可训练神经网络的深度学习模型,主要分为编码器(Encoder)和解码器(Decoder)两个部分,编码器部分主要接收超长的输入数据,将传统Transformer模型中的Self-Attention层替换为Informer特有的ProbSpare Self-Attention层,并且通过Self-Attention distilling操作对特征压缩,堆叠上述两个操作提高算法的鲁棒性。解码器部分接收LSTF的长序列预测,将预测位置填充0,经过掩码(Mask)的ProbSpare Self-Attention层,得到最后的预测值。
1. 编码器输入
编码器输入端嵌入的计算方法如式(7)、式(8)、式(9)所示。
PE(c,2j) = sin[c/(2Lx)](7)
PE(c,2j+1) = con[c/(2Lx)](8)
XEn-feed [i] = αuit+PE(Lx×(t-1)+i) +[SE(Lx×(t-1)+i)]c,i∈(1,2,…,Lx)(9)
其中,PE代表LSTF中位置编码,c为绝对坐标,dmod代表输入特征维度,输入长度用Lx表示。式(7)、式(8)分别代表PE在奇数和偶数位置的计算公式。式(9)中的XEn-feed [i]是Encoder部分中每个i包含位置及时序状态的输入,αuit将输入时间序列通过一维卷积滤波器映射到高维的特征向量,PE(Lx×(t-1)+i)为局部时间戳,[SE(Lx×(t-1)+i)]c为全局时间戳。
2. 编码器编码
Informer模型中ProbSpare Self-Attention层和Self-Attention Distilling的计算公式分别如式(10)、式(11)所示。
A(Q,K,V) = Softmax
V(10)
Xtj+1 = MaxPool(ELU(Convld([Xtj]AB)))(11)
式(10)中,A(Q,K,V)为ProbSpare Self-Attention层注意力机制的权值,K、K、V分别为活跃查询向量、键向量、值向量。式(11)中,[Xtj]AB表示注意力模块,它包含多头概率稀疏自注意力,Convld表示一维卷积,ELU为激活函数,通过MaxPool层得到下一时刻的[Xtj+1],并传入解码器中。①
3. 解码器解码
解码器解码的公式如式(12)所示。
XtDe-feed = Concat(Xttoken,Xt0)∈R(12)
其中,XtDe-feed为解码器中的输入部分,Xttoken和Xt0分别为编码器中的已知部分和掩盖部分,Ltoken和Ly分别为其对应的长度。解码和编码的进行过程相同, ProbSpare Self-Attention学习输入的时间序列的相关信息,通过全连接层输出。
(四) 数据处理及来源
本文选取2000—2019年国家中心城市的面板数据,由于成都、武汉、郑州、西安等市在“十四五”规划中没有能源结构方面的具体数值,研究仅限于北京市、上海市、天津市、重庆市、广州市等国家中心城市。数据来自《中国统计年鉴》《中国科技统计年鉴》《北京市统计年鉴》《上海市统计年鉴》《天津市统计年鉴》《重庆市统计年鉴》《广州市统计年鉴》。其中碳排放量原始数据来自Center for Global Environmental Research网站(www.cger.nies.go.jp/en/)提供的2000年1月至2019年12月的全球1km*1km分辨率的GeoTIFF月度碳排放量数据。通过栅格化和分区域汇总,本文得到中国各城市碳排放量月度面板数据。以2000年为基期不变价格对各个城市生产总值进行平减,个别年份的少量缺失值用插值法进行补齐。本文对地区生产总值、能源结构、森林覆盖率3个控制性变量的预测值按照“十四五”规划目标值进行设定,并借鉴前人的方法①,对2025—2030年的变量预测值进行平均递增,对其余4个非控制性变量按过去数据的内部信息,使用GRU模型进行合理估算。
四、 GRU模型对国家中心城市碳排放的预测及分解
(一) 国家中心城市非控制性变量预测
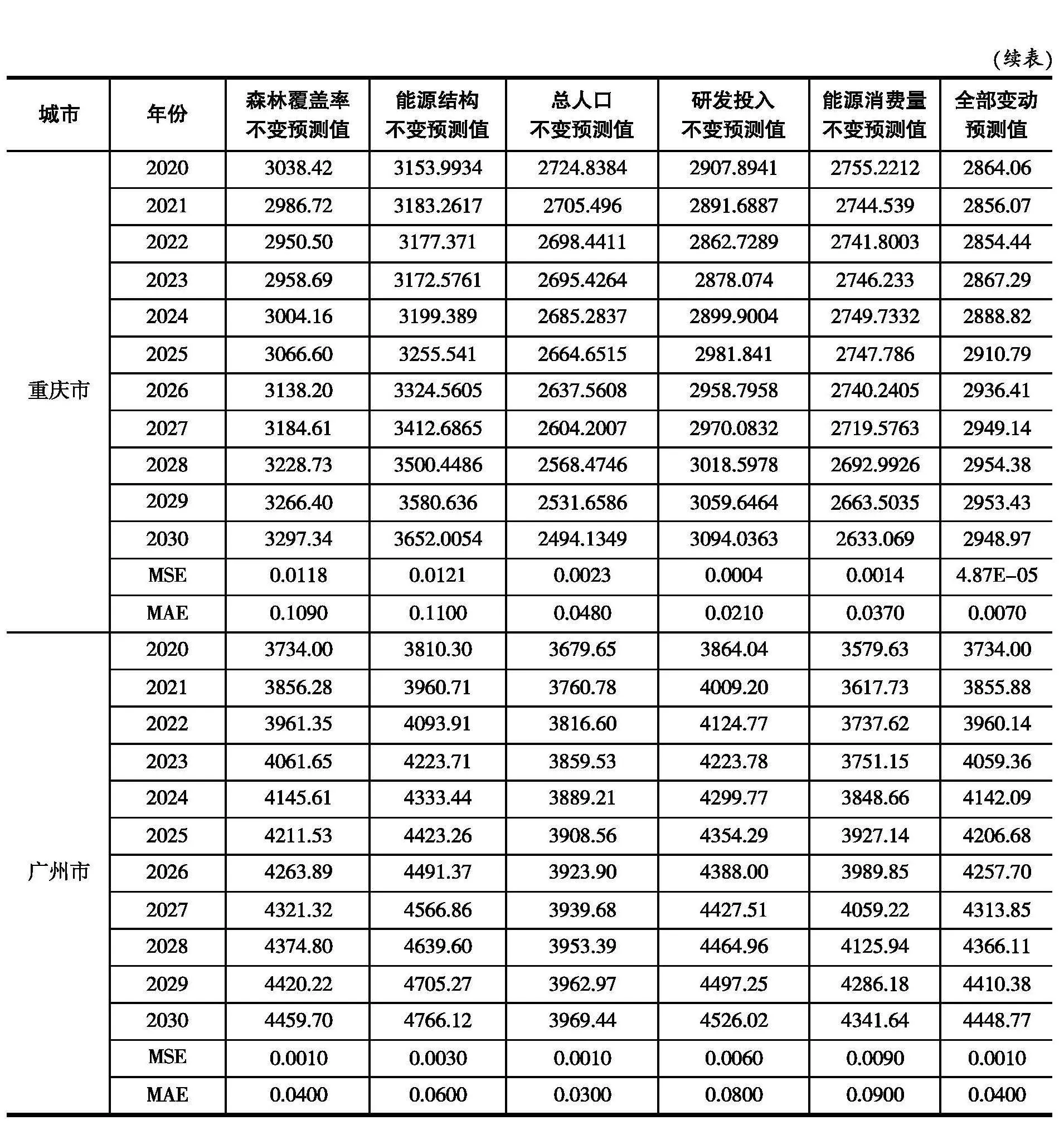
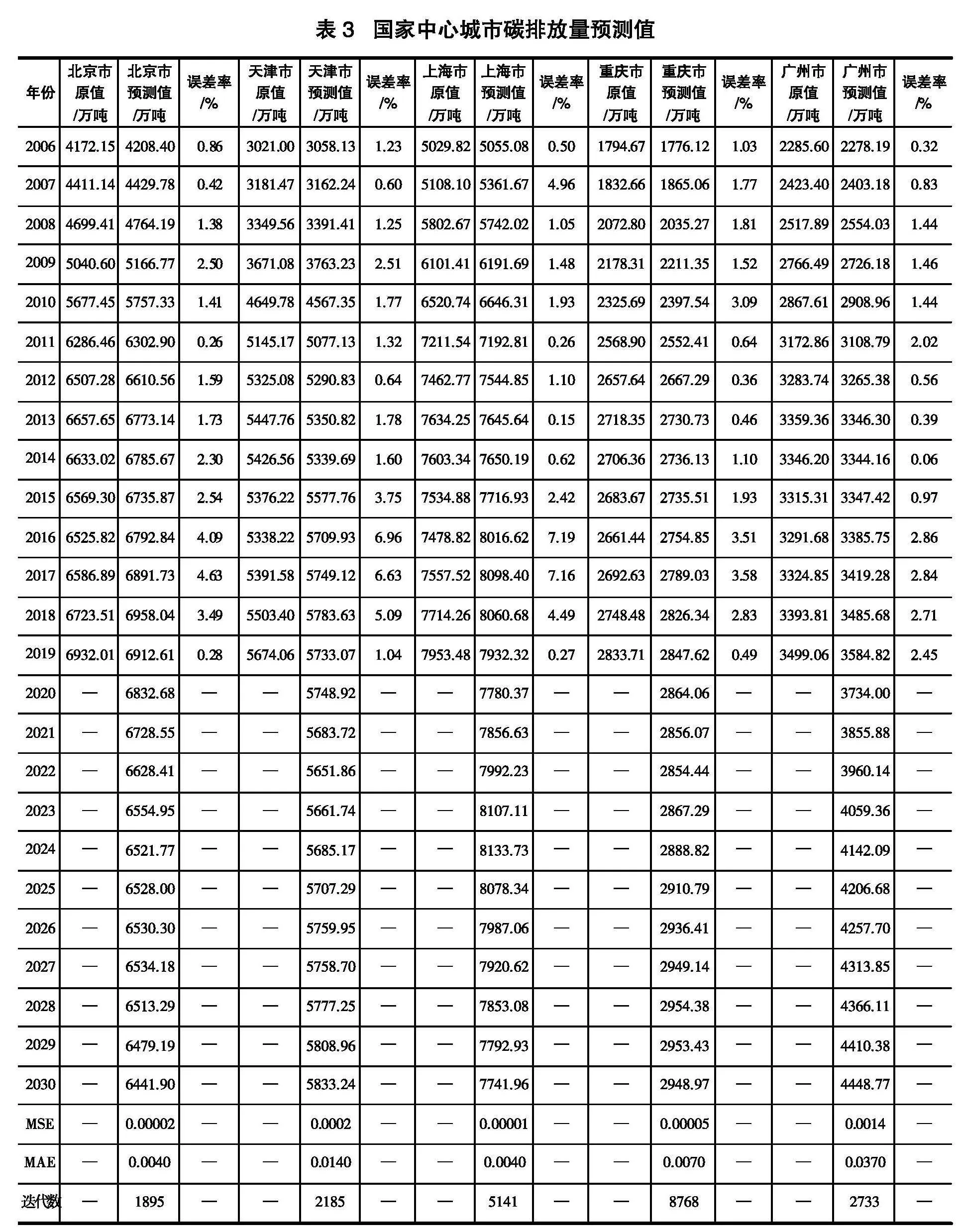
表1的控制性变量,特指政策强制调控的目标值,以期在合理的时间节点达峰的硬性指标值。非控制性变量,会按照时间惯性向前发展。本文利用GRU模型对非控制性变量2020—2030年的数据进行估计,将预测步长设置为6,送入GRU模型进行归一化处理,将批处理组设置为12,两层神经元数量分别设置为32和64,在模型训练回调时设置均方误差(MSE)为0.0001,在训练数据小于该MSE值时结束训练,并在验证集上进行MSE及MAE数值的校验预测值准确性,并进行数据反归一化,最终得到2020—2030年的预测值,如表2所示。表中的预测数据大体与各城市“十四五”规划中既有的数据相符合,如《北京市市国土空间近期规划(2021年—2025年)》明确规定,北京市常住人口在2025年控制在2300万以内,北京市2025年的预测值为2241.58万人;《天津市市人口发展“十四五”规划》规定,到2025年,常住人口达到1500万人左右,本文预测值为1475.24万人,预测值具有一定的合理性。(1)在人口方面,北京市和上海市的人口呈现出一种饱和状态,基本维持不变;天津市总人口在10年间上涨幅度最高;重庆市上涨 了1.37%;广州市上涨了5.64%。(2)在对外贸易进出口总额方面,北京市维持在4000亿美元附近;上海市则维持在4840亿美元附近;天津市上涨20.34%;重庆市则下降9.8%;广州市的进出口总额具有先升后降的特点,但总趋势仍上升。(3)在研发支出方面,天津市基本维持不变;其余4个城市在研发支出上均有较大幅度的提升,北京市上涨58.05%,上海市上涨到4103.45亿元,重庆市上涨到1980.39亿元,广州市上涨到1547.31亿元。(4)在能源消费量方面,仅广州市有大幅度的上升,其余4个城市均无较大变化,国家中心城市在能源消费量方面的上升较为有限,得到较为有效的控制。
(二) 国家中心城市的碳排放及碳强度预测
本文在上述GRU模型预测4个非控制性变量基础上,加入“十四五”规划中的3个控制性变量,构建多变量GRU预测模型。本文先对数据进行归一化处理,将多变量模型的输入维度增加至7,同样将MSE控制在0.0001,跳出循环并代入验证集进行验证,将神经元在第一层和第二层的数量设为64,在输出预测变量时将数据反转,最终得到各个国家中心城市预测的碳排放,结果不尽相同,如表3所示。国家各中心城市的碳排放量原值与预测值,拟合效果较好。①如图3所示,北京市的碳排放量在2019年已经达到最高,然后呈现下降的趋势;天津市的碳排放量在2019年之后上升速度较之前有所放缓,呈缓慢的上升趋势,总体碳排放量得到控制,但仍然无法在2030年达到峰值;上海市的碳排放量预测在2024年前仍在上升,并于2024年达到峰值,随之开始逐年下降;重庆市在2027年之前保持着上升的趋势,在2028年达到峰值,在随后的2年内出现缓慢下降的趋势;广州市的碳排放量在之后的10年内仍在快速上升,在2030年前尚未达到峰值。
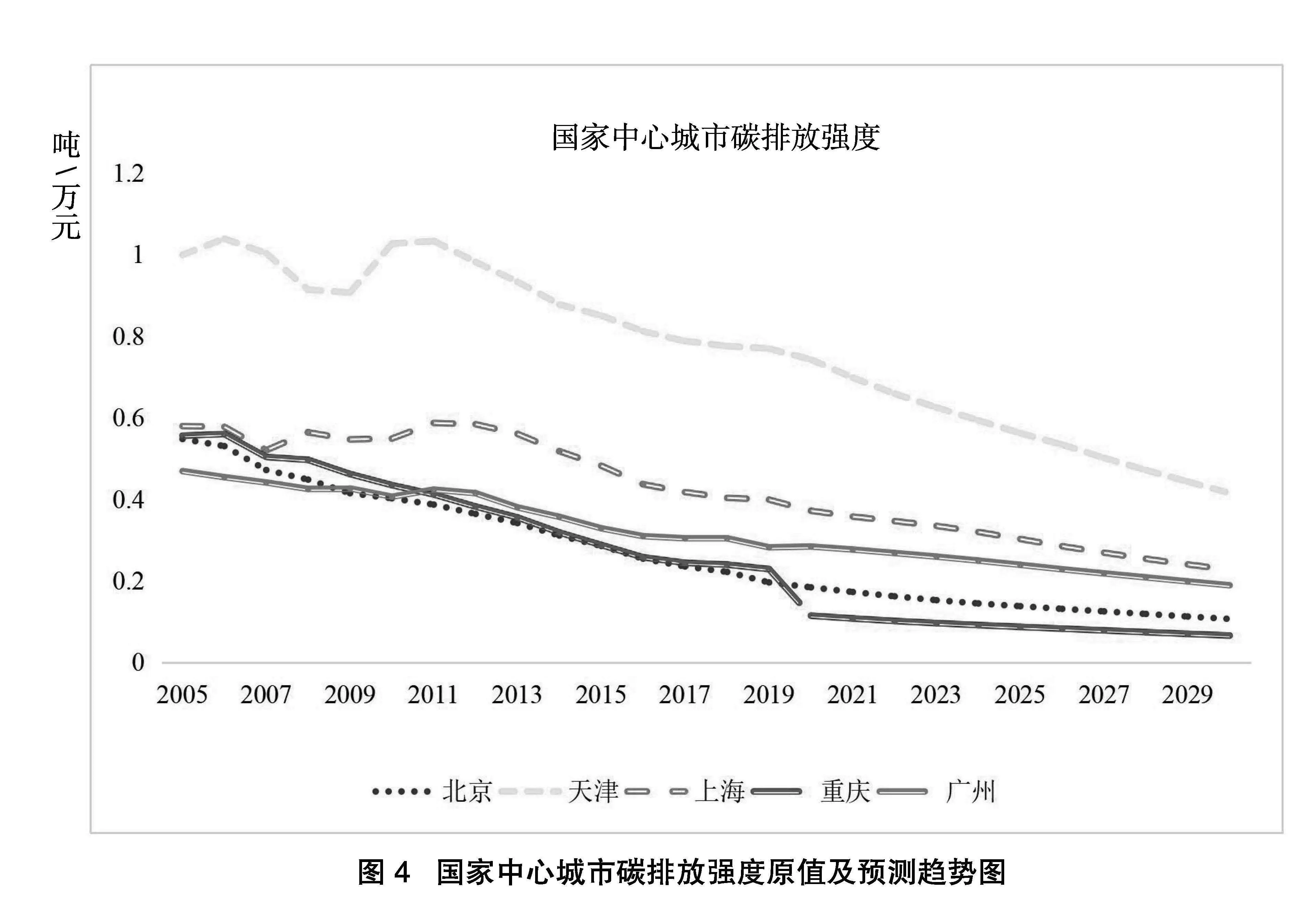
本文在预测出国家中心城市碳排放总量的基础上,结合地区生产总值,计算各城市的碳排放强度指标,如表4和图4所示。结果表明,国家中心城市的碳排放强度都呈现下降的趋势,但下降的速度有所差异,北京市碳排放强度从2005年的0.548吨/万元,下降至2030年的0.106吨/万元。重庆市从起始的0.556吨/万元下降至2030年的0.066吨/万元,降幅最高。北京市和重庆市在实现单位国内生产总值二氧化碳排放比下降65%以上这一指标时表现出优良的结果。天津市碳排放强度的起始值较高,处于初始弱势地位,下降幅度为58.47%。上海市和广州市的下降幅度分别为60.8%和59.7%。初始值较高的城市并没有因禀赋的弱势而造成差距的进一步扩大,国家中心城市的碳排放强度间的差距在日益缩小,并且于2020年后碳排放强度的波动性进一步降低,处于稳定下降的趋势。值得注意的是,重庆市与上海市的碳排放强度在2005年初始位置处于同一水平,并分别于2011年与2020年赶超广州市和北京市。
五、 Informer模型对国家中心城市碳排放的校验
为了校验预测的稳健性以及预防出现极端误差,本文采用Informer模型对国家中心城市的月度碳排放量进行预测分析,交叉验证及确定碳达峰预测的有效区间。
本文将编码器和解码器的输入数值都设置为6,编码器层数设置为2,解码器层数设置为1,使用gelu激活函数,使用MSE定义损失函数,耐心值设置为3,编码器的输入序列长度设为24,解码器token长度设为12,同样利用滑动窗口预测长度为12的数据值,最后见表5所示的预测值。
GRU模型和Informer模型的预测值整体浮动范围不大,但由于Informer模型采用的是单变量的月度数据的预测,其在国家个别中心城市的达峰峰值时间点和趋势有所不同,预测的波动性更大。北京市的碳排放量在2019年后仍保持上升趋势,在2023年达到峰值,与GRU模型相比推迟了4年,在2027年到2029年之间有小幅度上升,并于2030年下降到7458.14万吨。天津市的碳排放量则出现很强的波动性,峰值为2023年的6295.463万吨,在2025年出现V字底,2027年至2029年间在6250万吨上下浮动,最终于2030年降为6221.083万吨。上海市的碳排放量则于2023年达到峰值,在2024年至2027年间出现小范围的波动,但在2028年后出现了稳定下降的趋势,比GRU模型中的预测结果提前1年。重庆市碳排放的变化幅度较小,处于一个较饱和的区域,峰值出现在2026年,与GRU模型相比提前2年达到峰值,并在2026年后出现稳定的下降态势。广州市碳排放量峰值出现在2025年,并在之后2年内出现下降。城市二氧化碳达峰并不仅仅指某一年二氧化碳排放达到峰值,只有城市二氧化碳排放出现持续稳定下降,才意味着城市实现二氧化碳达峰,天津市和广州市在严格意义上说并没有达到二氧化碳达峰,只是在一段时期内达到了某个碳排放量的最高值。
六、 国家中心城市碳排放的影响因素分析
由于国家中心城市禀赋的差异,变量对碳排放的作用程度不同,现将森林覆盖率、能源结构、总人口、研发投入、能源消费量作为控制性变量进行因素分解①,即维持单个变量不变,其余变量维持原有趋势,输入前文中的多变量GRU模型中进行再预测,研究不同控制因素作用的方向及大小,通过观察,得出国家中心城市的森林覆盖率、能源结构、研发投入增长会导致碳排放量降低,而总人口和能源消费量增加,与碳排放量呈同向增长。
如表6所示,北京市森林覆盖率增长将带来0.22%~1.14%的碳排放量降低;天津市森林覆盖率变化会带来0.09%~1.83%的变动;上海市森林覆盖率变化介于0.47%~4.3%;重庆市森林覆盖率的影响最显著,为3.19%-11.81%;广州市森林覆盖率的增长会带来0.001%~0.25%的波动。北京市、天津市、上海市、广州市煤炭能源结构占比的降低会对碳排放量分别产生1.05%~2.16%、1.66%~2.07%、1.48%~4.68%、2.04%~7.13%的抑制作用,重庆市能源结构调整对碳排放的影响比例最高,为10.12%~23.84%。煤炭作为一次能源的主体,带来的环境问题也是很大的,减少煤炭的消费与减碳目标一致,煤炭消费的降低和提升非化石能源的比重是各个城市在“十四五”规划中明确要求的,会对城市碳达峰造成比较显著的影响,与已有研究一致。①北京市、天津市、上海市由于在预测中人口总量接近饱和,其带来的影响变化也相对较小,3个城市的人口变量对碳排放量的影响分别为0.89%~3.33%、 2.38%~5.2%、-0.02%~4.14%的碳排放量的增长。上海市呈现了人口聚集对节能减排效应的阶段性特征,聚集效应大于增排效应,使人口聚集对碳排放表现为抑制作用。在2025—2030年快速发展阶段,上海市的增排效应大于减排效应,从而产生正向的作用效果。①重庆市和广州市由总人口产生的碳排放压力则相对较高,分别为4.86%~15.42%和1.6%~10.77%。研发投入对碳排放的影响在国家中心城市中呈现一定的相似性,北京市、天津市、上海市、重庆市、广州市研发投入的增长降低了碳排放量,与已有的研究结果相一致。②由于国家大部分中心城市的能源消费在原预测值中没有较大幅度的增长,对碳排放的影响幅度也较小,北京市、天津市、上海市的能源消费的增长分别带来0.14%~2.12%、0.19%~0.91%、0.09%~1.13%的碳排放量上升,而重庆市、广州市则分别有3.8%~10.71%、2.41%~7.59%的大幅度促进。大规模的人口和产业的聚集会带来更大的能源消耗,并带来较高的碳排放水平。③
七、 结论和政策建议
(一) 主要结论
针对国家中心城市碳排放达峰问题,本文运用STIRPAT扩展形式,通过GRU模型预测4个非控制性变量,结合“十四五”规划中的3个控制性变量,构建包含7个变量的GRU模型,预测国家中心城市碳排放,并分解其影响因素,采用Informer模型进行校验,得到以下结论:第一,GRU模型对非控制性变量的预测结果显示,北京市和上海市的人口接近饱和,上涨趋势缓慢,但天津市、重庆市、广州市皆有不同幅度的上涨;在对外贸易进出口总额方面,北京市、上海市维持原有趋势没有大幅度变化,天津市在10年间上涨20.34%,重庆市则下降9.79%,广州市的进出口总额具有先升后降的特点,但总趋势仍上升;在研究支出方面,天津市基本维持不变,其余4个城市在科研支出上均有较大幅度的提升;在能源消费量方面,广州市有大幅度的上升变化,重庆市也上升了,其余3个城市均无较大变化,基本维持在11050万吨标准煤左右。第二,在GRU模型的预测分析中,北京市、上海市、重庆市的碳排放量皆能达到峰值,达峰时间点分别为2019年、2024年和2028年。天津市的总体碳排放量得到控制,但仍然无法在2030年前实现达峰。广州市呈现快速上涨的趋势。各城市的碳排放强度的差距逐渐缩小,个别城市出现赶超现象。第三,使用Informer模型发现,北京市、上海市、重庆市皆能实现城市碳达峰,北京市和上海市都于2023年达峰,和GRU模型相比,分别推迟4年和提前1年。重庆市于2026年达峰,提前2年。综合来看,北京市和上海市属于碳达峰先锋城市,预计于2025年前碳达峰,重庆市属于碳达峰平稳城市,预计2025年至2030年前达峰,而天津市和广州市则属于碳达峰迟缓城市,但总体碳排放量得到缓和。(4)总人口、能源消费量会对碳排放产生正向效应,而森林覆盖率、研发投入及能源结构会对碳排放产生抑制作用。
(二) 政策建议
第一,对原有基础上能实现碳达峰的北京市、上海市、重庆市,应确保其在国家碳达峰指导方针下的优先达峰,发挥尽早达峰的引领优势,通过技术溢出效应支持其他地区尽早实现碳达峰,这对带动全国其他城市实现创新发展、协调发展、绿色发展、开放发展、共享发展具有重要意义。对于碳达峰迟缓城市而言,要实现建筑、生活、交通等全方位减排,加强城市低碳绿色技术攻关,突破现有技术瓶颈,加快产业转型,优化产业能源结构。第二,城市作为资金、技术、人才、信息等要素的集聚载体,是具有转型探索精神和技术创新活力的地区。碳达峰迟缓的城市,应控制其人口总量和能源消费量,扩大绿地面积,进一步通过科技创新,发展绿色低碳相关领域高新技术①,优化能源结构和淘汰落后产能,推进城市“双碳”发展模式融合创新。第三,城市碳达峰方案要根据本地区人口集聚趋势、经济发展前景、产业结构状况、技术水平条件、资源环境禀赋等进行差异化定制,充分发挥减排降碳作用,制定具有城市特色和竞争优势的低碳转型路径,形成差别化竞争新优势。第四,完善推进城市碳达峰监督考评机制,健全城市碳排放统计标准,细化碳排放评分准则,在国家同一指标下突出率先碳达峰城市的引领性,积极推动国家中心城市能源、工业、建筑、交通等重点行业部门制定碳达峰方案,实施重点领域城市碳排放强度分类管理,健全城市碳排放动态监测体系。
(责任编辑:余风)
① J. Parikh and V. Shukla,“Urbanization, Energy Use and Greenhouse Effects in Economic Development,” Global Environmental Change, Vol. 5, No. 2, 1995, pp.87-103.
② 住房和城乡建设部城乡规划司、中国城市规划设计研究院编:《全国城镇体系规划(2006—2020年)》,商务印书馆,2010年,第47-95页。
③ Haikun Wang, Xi Lu, Yu Deng, Yaoguang Sun, Chris P. Nielsen, Yifan Liu, Ge Zhu, Maoliang Bu, Jun Bi and Michael B. McElroy,“China’s CO2 Peak before 2030 Implied from Characteristics and Growth of Cities,” Nature Sustainability, Vol. 2, No. 8, 2019, pp.748-754.
④ 赫永达、文红、孙传旺:《“十四五”期间我国碳排放总量及其结构预测——基于混频数据ADL-MIDAS模型》,《经济问题》2021年第4期。
131
① 洪竞科、李沅潮、蔡伟光:《多情景视角下的中国碳达峰路径模拟——基于RICE-LEAP模型》,《资源科学》2021年第4期。
② 王怡:《中国省域二氧化碳排放达峰情景预测及实现路径研究》,《科学决策》2022年第1期。
③ 蒋昀辰、钟苏娟、王逸、黄贤金:《全国各省域碳达峰时空特征及影响因素》,《自然资源学报》2022年第5期。
④ 丁松、李若瑾、党耀国:《基于初始条件优化的GM(1,1)幂模型及其应用》,《中国管理科学》2020年第1期。
⑤ 徐宁、秦邱皓、王天宇、丁松:《基于自适应调节的灰色滚动预测模型及对碳排放趋势预测》,《控制与决策》2023年第12期。
⑥ 高峰、律可心、乔智、马丰魁、姜群鸥:《青藏高原东缘生态过渡带碳中和评估与预测》,《生态学报》2022年第23期。
⑦ 蒋惠琴、陈苗苗、余昭航、李奕萱、鲍健强:《异质性视角下长三角城市群碳达峰影响因素研究》,《城市问题》2022第8期。
⑧ 戢晓峰、白淑敏、陈方、普永明:《效率视角下省域交通碳排放配额分配研究》,《干旱区资源与环境》2022年第4期。
⑨ 胡剑波、罗志鹏、李峰:《“碳达峰”目标下中国碳排放强度预测——基于LSTM和ARIMA-BP模型的分析》,《财经科学》2022第2期。
⑩ 刘朝、王梓林、原慈佳:《结构视域下自主技术创新对工业碳排放的影响及趋势预测》,《中国人口·资源与环境》2022年第7期。
经济管理
132
① 胡剑波、赵魁、杨苑翰:《中国工业碳排放达峰预测及控制因素研究——基于BP-LSTM神经网络模型的实证分析》,《贵州社会科学》2021年第9期。
② 吴青龙、王建明、郭丕斌:《开放STIRPAT模型的区域碳排放峰值研究——以能源生产区域山西省为例》,《资源科学》2018年第5期。
133
① 《京都议定书》规定的6种温室气体为:二氧化碳(CO2)、甲烷(CH4)、氧化亚氮(N2O) 、氢氟碳化合物(HFCs) 、全氟碳化合物(PFCs) 、六氟化硫(SF6)。但囿于数据的可得性,本文研究的温室气体仅为CO2。
经济管理
134
① 易靖韬、严欢:《基于小波分解和ARIMA-GRU混合模型的外贸风险预测预警研究》,《中国管理科学》2021年第6期。
① 文思齐、龙天渝:《基于长时间序列预测的计量区给水管网爆管识别》,《重庆市大学学报》2023年第5期。
137
① 袁晓玲、郗继宏、李朝鹏、张武林:《中国工业部门碳排放峰值预测及减排潜力研究》,《统计与信息论坛》2020年第9期。
① 值得说明的是,GRU模型可以很好地捕获动态趋势,但由于信息中噪声的存在以及本文研究重点并不是具体数值,后文在使用Informer模型进行对照时,是对达峰平台期的一个预估计。比如模型对2030年北京市碳排放总量的预测值为6441.90万吨,那么只是说明2030年的碳排放总量在6441.90万吨附近的概率很大,并不意味着本文预测北京市2030年就是6441.90万吨的排放量。因为从连续变量的概率分布上看,每一个具体数值出现的概率都为0。
① 由于经济产出与碳排放的高度相关性以及通过控制产出缩减碳排放的不可行性,本文剔除相关经济变量,考察其他控制性变量对碳排放的影响。
① 林伯强、李江龙:《环境治理约束下的中国能源结构转变——基于煤炭和二氧化碳峰值的分析》,《中国社会科学》2015年第9期。
① 邵帅、张可、豆建民:《经济集聚的节能减排效应:理论与中国经验》,《管理世界》2019年第1期。
② 蔺雪芹、边宇、王岱:《京津冀地区工业碳排放效率时空演化特征及影响因素》,《经济地理》2021年第6期。
③ 王正、樊杰:《能源消费碳排放的影响因素特征及研究展望》,《地理研究》2022年第10期。
147
① 胡剑波、张宽元、蔡雯欣:《碳交易政策提高中国省域低碳贸易竞争力了吗?——基于碳排放权交易试点的准自然试验》,《杭州师范大学学报》(社会科学版)2023年第1期。
