基于GBS-YOLO的轻量级烟焰检测方法
2024-12-05黄旭罗子健


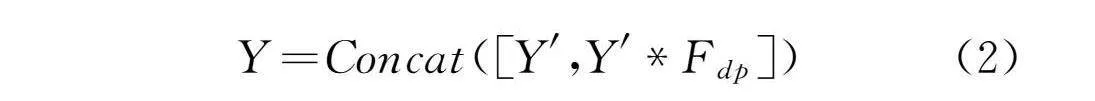







摘要:文章针对车载智能消防炮上基于图像的烟焰检测算法检测平均精度低、烟焰漏检和误检率高的问题,提出一种烟焰检测算法GBS-YOLO(以Ghost-BiFusion-SIoU首字母命名)。GBS-YOLO以YOLOV5s为基准模型,引入轻量级网络GhostNet、使用较复杂的多尺度特征融合网络BiFusion Neck、采用SIoU损失函数对基准模型进行改进。实验结果表明,GBS-YOLO在自定义数据集上的平均精度相较于原始模型提升了2.2%,是YOLOV7-tiny提升精度的2倍;检测速度达到77fps,相较于基准模型提升了6.9%。将模型部署到NVIDIAJetsonOrin平台上,有效实现了烟焰的检测能力,满足火灾救援场景的实际需求。
关键词:烟焰检测;轻量化;YOLOV5
中图分类号:TP311文献标识码:A文章编号:1673-1794(2024)05-0001-04
作者简介:黄旭,安徽理工大学计算机科学与工程学院硕士生,研究方向:目标检测(安徽淮南232001);罗子健,安徽大学计算机科学与技术学院硕士生(合肥230601)。
基金项目:安徽省重点研究与开发计划“智能化复合射流及凝胶细水雾关键技术与装备研究”(2023g07020007);安徽省高等学校科研计划项目“留守儿童溺水突发事件敏捷预警建模与响应技术研究”(2022AH051101)
收稿日期:2024-04-16
在火灾救援场景下,为了有效提高救援装备的工作效力,需要对消防车辆进行智能化提升,实现自主寻火功能,对火灾发生时的烟雾与火焰进行快速准确地检测,以提高救援装备对火灾的扑救效率,减少损失。
传统烟焰检测依赖于图像处理技术,该方法主要是通过分析视频图像中火焰烟雾的特征,如颜色、运动、纹理等实现。Chen等[1]提出了一种结合RGB和HIS的方法,用于提取火焰烟雾的颜色和动态特征,并判断火灾是否发生。Celik和Demirel[2]提出了一种基于YCbCr颜色空间的火灾图像识别模型,相比于RGB颜色空间的模型,在适应光照变化方面表现更好。Kong等[3]提出了一种利用逻辑回归算法判断火焰静态和动态特征的融合算法。然而,传统烟焰检测方法受制于手动特征提取,限制显著,在复杂场景下,其适应性差,容易受颜色空间选择、特征融合和光照条件的干扰。
近年来,随着深度学习的发展,基于深度学习的目标检测算法逐渐被应用于火焰检测中,取得了不错的效果,其中YOLO系列算法由于其高效和准确性而备受关注。文献[4-6]对模型进行了一定的改进,但是仍然有以下问题未得到解决。
(1)烟焰检测在实际应用中需要对目标进行精准检测。在原始YOLOV5s模型及改进模型中,检测的平均精度一般不高,模型无法有效处理目标的精确定位和分类,导致性能下降。
(2)火焰烟雾可能受到建筑结构、风向影响,导致火焰的尺寸和形状变化较大。在原始YOLOV5s模型及改进模型中,未考虑复杂背景下模型对背景结构或纹理问题的误判问题。
(3)部署模型到边缘设备时,需要综合考虑计算资源、模型大小和实时性。边缘设备资源有限,需要对模型进行优化以适配,模型大小会影响存储和传输效果。同时,模型需具备快速推理以满足实时性需求。
针对现有的烟焰检测算法检测的不足,本研究选用YOLOv5s作为基准网络,并提出一种名为GBS-YOLO的烟焰检测算法。引入Ghost-NetV2主干特征提取网络,以减少原始网络模型的参数量并提高检测精度;引入较复杂的多尺度特征融合网络BiFusion Neck,融合烟焰的多尺度特征,提升网络对烟焰的检测精度;引入SIoU优化损失函数,提高检测框回归精度。提高模型对火焰烟雾多尺度特征的关注度,加快推理速度,使模型兼顾烟焰检测的实时性和准确性。
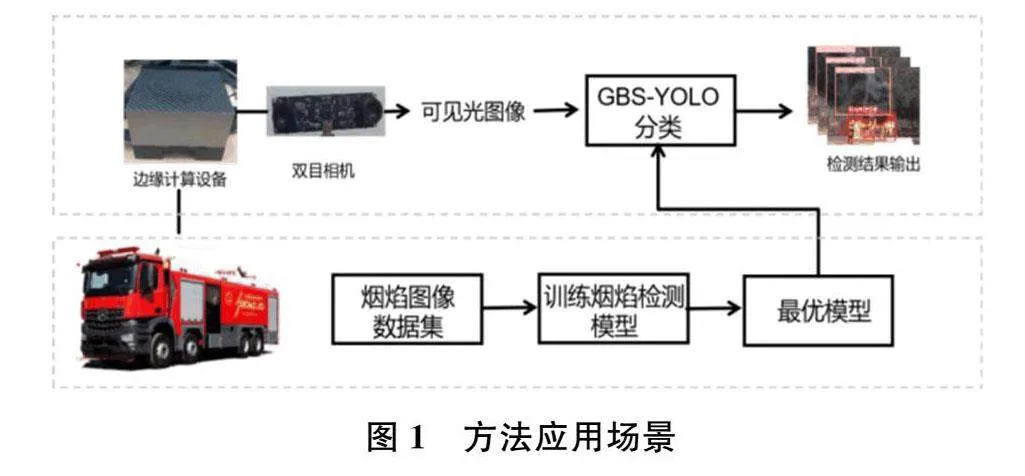
图1为本研究方法的应用场景。智能消防炮搭载的双目相机用于捕捉火场图像,经过部署在边缘计算设备上的GBS-YOLO方法处理,最终生成烟焰检测结果。
1 GBS-YOLO目标检测方法
1.1算法概述
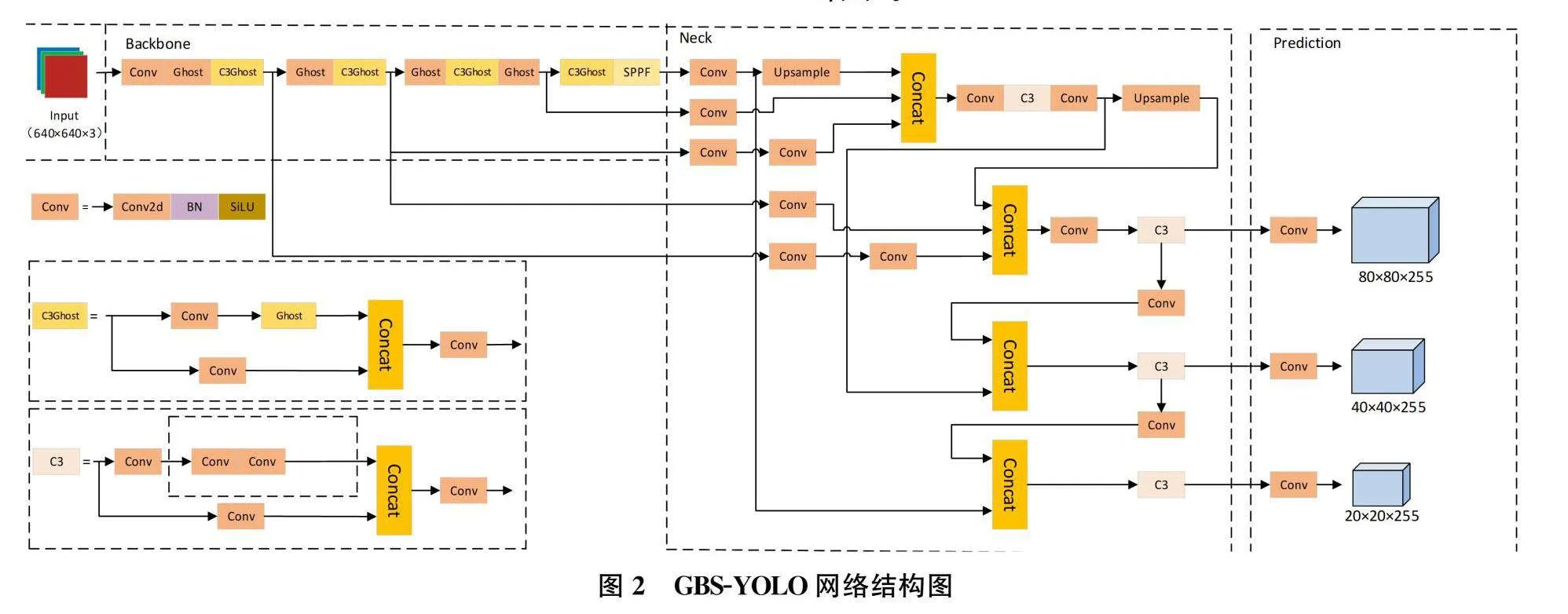
当前主流的目标检测算法包括R-CNN[7-8]系列和YOLO系列[9-10],R-CNN系列在目标检测需要较高的精确度上较为优越,但其检测速度相比YOLO系列而言比较缓慢,在实际应用场景中,无法满足目标检测的实时性。本研究提出的GBS-YOLO烟焰检测方法在YOLOv5算法基础上进行研究。GBS-YOLO网络由四个部分组成,包括输入端(Input)、主干网络(Backbone)、颈部网络(Neck)和输出端(Prediction)。
输入端包括Mosaic数据增强、自适应图片尺寸缩放和自适应锚框计算。Mosaic数据增强将四张图片组合起来,以增加背景丰富性;自适应图片尺寸缩放能够统一图片尺寸;自适应锚框计算能够输出预测框,在与真实框比对后进行更新,以不断调整锚点框大小。
主干网络用于输入图像的特征提取,在GBS-YOLO网络中主干网络主要由Ghost模块、C3Ghost模块和SPPF模块组成。Ghost模块为深度可分离卷积、批标准化(BatchNormalization,BN)和ReLU激活函数,C3Ghost模块由2个标准卷积层以及多个Ghost模块组成,可以减少网络参数量并提高训练速度,SPPF模块是空间池化金字塔(SpatialPyramidPooling,SPP)[11]模块的改良版,SPPF采用多个小尺寸池化核级联,从而在融合不同感受野的特征图、丰富特征图的表达能力的情况下,进一步提高了运行速度。
颈部网络中采用了BiFusion Neck结构,将高层特征通过上采样向下对特征图进行传递融合并从不同的主干层对不同的特征层进行特征聚合,使模型获取更加丰富的特征信息,实现多层次信息的交互。输出端先采用SIOU损失函数,使预测框更接近真实框,在预测过程中通过NMS对预测的烟焰坐标信息进行校正和筛选,生成检测结果。
1.2 ECA注意力模块
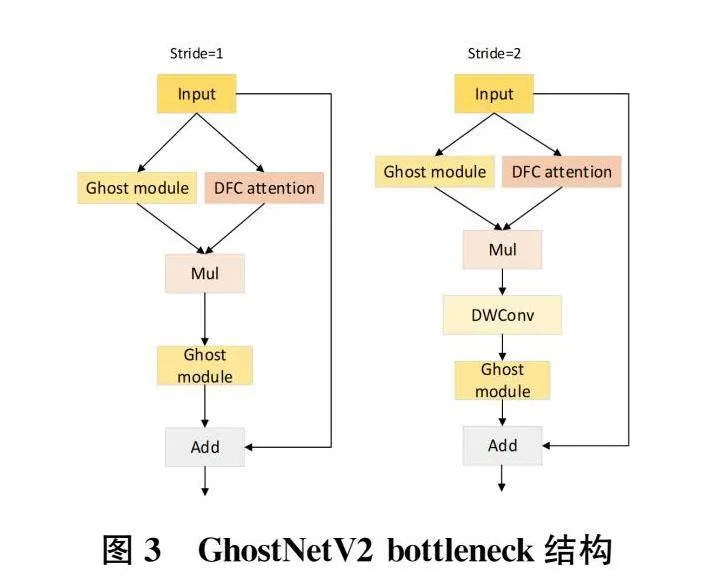
本研究使用GhostNet V2[12]作为GBS-YOLO模型的主干网络。GhostNetV2模块由多个Ghost模块组成,输入特征图分为两部分,一部分通过卷积生成特征图,对输入特征X∈RH×W×Cout使用F1×1卷积核生成n个特征Y':
Y'=X*F1×1(1)
另一部分则根据特征Y'生成m=ns个输出特征Y∈RH×W×Cout ,之后在通道维度上拼接这两部分特征,如式(2)所示:
图2为步长为1和2的Ghost模块。通过Ghost模块生成的特征与使用DFC机制生成的特征逐元素相乘得到语义更加丰富的特征,且不改变输出特征维度。GhostNetV2结构图如图3所示:
由于火焰和烟雾特征可能散布在图像的不同区域,因此需要模型能够综合全局信息,以更好地理解它们在整个图像中的分布情况,从而提高检测的准确性。GhostNetV2提出了解耦全连接注意力机制(DFC attention)捕捉全局信息和长距离依赖关系,对于输入特征X∈RH×W×C,利用简单实现的固定权重全连接层(FC)生成全局感受野的层(注)C(力))将其(图A)水平({a11),··,和垂直方(a12)a,分(),并(})对(将)特(全)征(连)图(接)的像素进行聚合操作。具体步骤为:
式中FH,FW为垂直和水平的转换权值,α'hw为经过垂直变换的输出特征,αhw是对α'hw经过水平变换的输出特征,通过在水平和垂直方向上使用下采样操作减少特征图的大小,减少计算量,随后通过Sigmoid函数将注意力值限制在(0,1)范围内,实现加速推理,其结构图如下:
DFC注意力机制中使用平均池化来减小特征图的维度,以减少计算和参数量,从而提高训练和推理速度。然而,这一过程也伴随着对空间结构信息的丢失以及对局部特征敏感性的减小,一定程度上限制了火焰烟雾检测的精度。因此本研究对原DFC注意力机制进行了改进,引入了一条最大池化分支。这一改进有助于突出火焰的显著特征,同时捕捉了火焰烟雾图像的边缘和轮廓信息,从而提高了模型对关键特征的识别和对火焰烟雾的检测精度。
1.3颈部网络改进
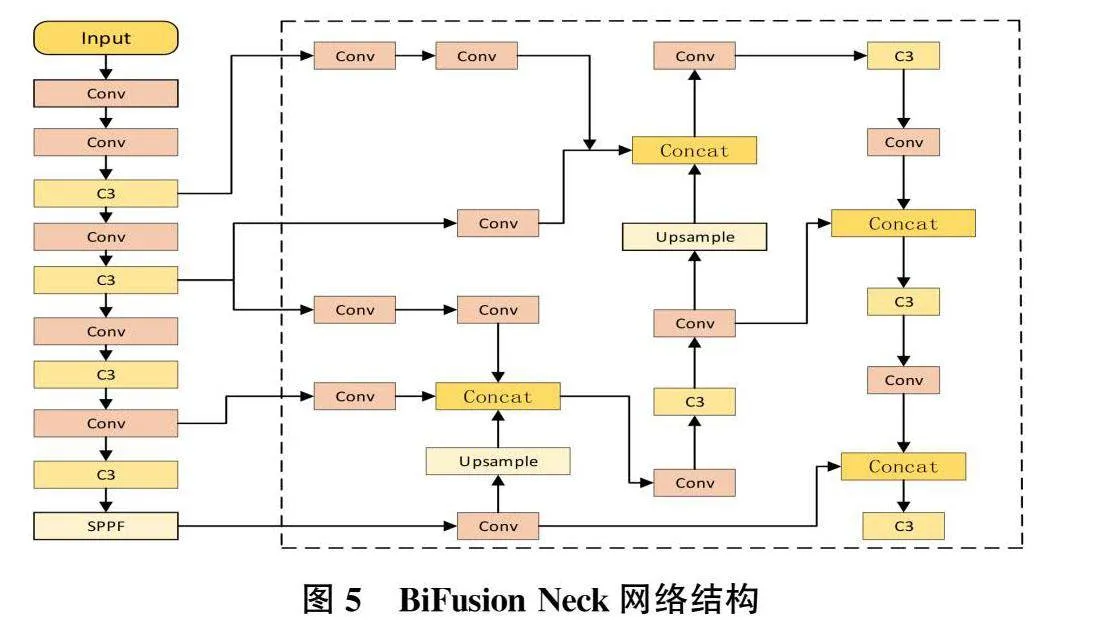
在YOLOv5中,颈部网络采用PAN结构,然而这一方法在提取多尺度的火焰烟雾特征方面并未表现出很好的效用,在融合多尺度特征的过程中,部分特征信息可能遭到损失。因此,本研究使用一种新的特征融合模块BiFusion Neck[13]结构,对PAN结构进行改进,通过引入更为复杂的融合机制,BiFusion Neck结构能够有效地融合不同层次的特征图,使模型能够充分适应火焰烟雾特征的多样性,提高模型的检测准确性和鲁棒性。该结构的详细示意图参见图5。
由于火焰烟雾具有高度可变的特点,包括形状轮廓和尺度的不断变化,当前的方法未能有效地捕获多尺度烟雾特征,导致特征图在传播过程中逐渐损失关键信息。为了缓解这一问题,本模块采用不同尺度的特征融合策略。首先,对同尺度特征图应用1×1卷积进行降维处理,随后对大尺度特征图进行1×1卷积降维,并使用3×3步长为2的卷积进行下采样,再对小尺度特征图进行上采样操作,最后将这三个部分产生的特征图拼接在一起,再次利用1×1卷积进行降维处理。这一简洁高效的操作流程有助于有效融合不同尺度的特征,显著提升模型性能。鉴于转置卷积操作常导致生成的特征图呈现显著的棋盘状伪像,这不仅损害了图像质量,还可能对最终检测结果的准确性产生不利影响。相较之下,采用最近邻插值法能够有效减轻伪像问题,提升生成特征图的质量。此外,最近邻插值法不仅计算高效,而且具备简洁性,有助于降低模型的复杂性,适用于轻量级模型的设计。因此,本研究使用最近邻插值法替代原BiFusion Neck结构中的转置卷积操作,经过改进后融合的特征图包含了更具体的火焰烟雾图片的语义信息和细节。
1.4损失函数优化
针对损失函数理论的不足,GIoU Loss[14]、DIoU Loss[15]、CIoU Loss[16]相继被提出来解决候选框的回归问题,在GBS-YOLO模型网络中,采用的损失函数包括边界框损失、分类损失和置信度损失。边界框回归损失函数使用的是CIoULoss,CIoU损失函数公式如下式表达:
式中:ρ2(b,bgt)代表预测框中心点b与真实框中心点bgt的欧式距离,c为可以同时包含预测框与真实框的最小闭合区域的对角线长度,β为权衡参数,ν为衡量长宽比的一致性参数,和分别代表目标框和预测框各自的宽高比。从上式可以看出,CIoU增加了检测框尺度的loss,增加了长和宽的loss,这样预测框就会更加符合真实框,但是其反映的纵横的差异为相对值,其结果相对固定,没有考虑真实框与预测框之间方向不匹配的问题。
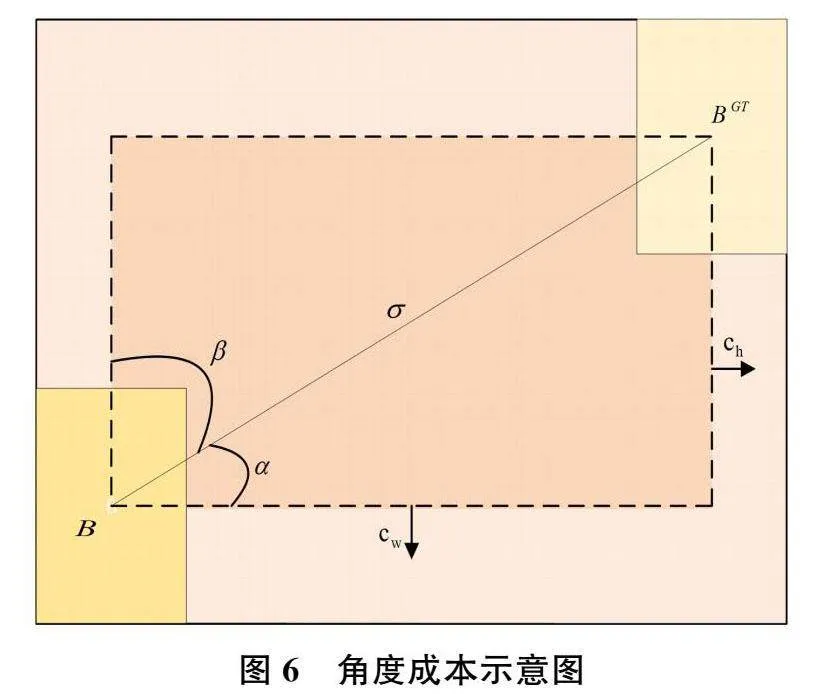
因此本研究引入SIoU loss[17]来替换CIoU,提高模型的定位能力。SIoU包括四个成本函数,分别是角度成本、距离成本、形状成本以及IOU成本。角度成本定义如式(9):
其中,x=和(bCx,bCy)分别表示预测框与真实框的中心点坐标。ch是真实框与预测框中心点的高度差,σ是真实框与预测框中心点的距离。
式中,ρx=2;ρy=2;ch和cw为预测框和真实框最小外接矩形的高和宽;γ=2-Λ。Ww,Wh,其中,(w,h)和wgt,hgt表示预测框和真实框的宽度和高度,θ表示对形状的关注度。
最后一项是IOU损失,因此SIoU Loss的最终损失如式(12):
为了提高因替换轻量化主干特征提取网络丢失的检测精度,本研究引入SIoU损失代替CIoU损失函数,考虑预测框和真实框之间的角度位置信息,有效解决了烟焰检测时边界框不匹配的问题。
2实验结果与分析
2.1实验环境和数据集
本实验使用NVIDIA GeForce RTX3080显卡,编译语言是python3.8.8,GPU加速软件为CUDA11.1和CUDNN8.0.5,最后在NVIDIA Jetson Orin上进行模型推理实验。通过Pytorch深度学习框架实现的模型的搭建、训练和验证。所用的火焰烟雾数据集主要来源为部分公开数据集和网络爬取采集,对其中不符合本实验的图片进行剔除,数据集共6070张图片,图片目标标注使用LabelImg,标注后的文件以xml作为后缀,文件名和图片名称一致,按8∶2的比例划分训练集和验证集,并将格式从xml转换为txt格式。图片分辨率大小为640×640,并启动Mosaic数据增强,随机对图片进行缩放、平移、左右翻转、色彩变换等处理后再进行拼接,Mosaic数据增强可以极大丰富训练样本数量,减少过拟合的可能性。训练批次设置为16,初始学习率为0.01,学习率动量为0.937,权重衰减为0.0005,所有参照模型均按照此参数训练500个epoch。
2.2模型评估指标
本研究实验将使用召回率(Recall)、精度(Precision)、平均精度均值(mean average preci-sion,mAP)以及画面每秒传输帧数(Frames Per Second,FPS)四个指标来对目标检测算法实验结果进行评测,通过以下公式计算:
式中,P表示精准率,针对最后的预测结果,描述预测出来的正例占所有正例的比率,R表示召回率,针对样本,用于描述在所有正例的样本中,有多少在预测中被检测出来,TP表示算法将样本正类预测为正类的个数,FP表示将样本中负例预测为正例的个体数量,指的是被错误分类的正样本,FN表示将样本正类预测为负类的个数,指的是被错误分类的负样本。
式中,平均精度(AveragePrecision,AP)是指以召回率Recall为横轴,以精确度Precision为纵轴组成的曲线围成的面积。均值平均精度(mAP)为AP值在所有类别下取平均。其中AP50为IoU阈值取0.5时对应的AP值。FPS指的是模型每秒处理的图片数量,用来衡量检测速度。
2.3实验结果
2.3.1消融实验
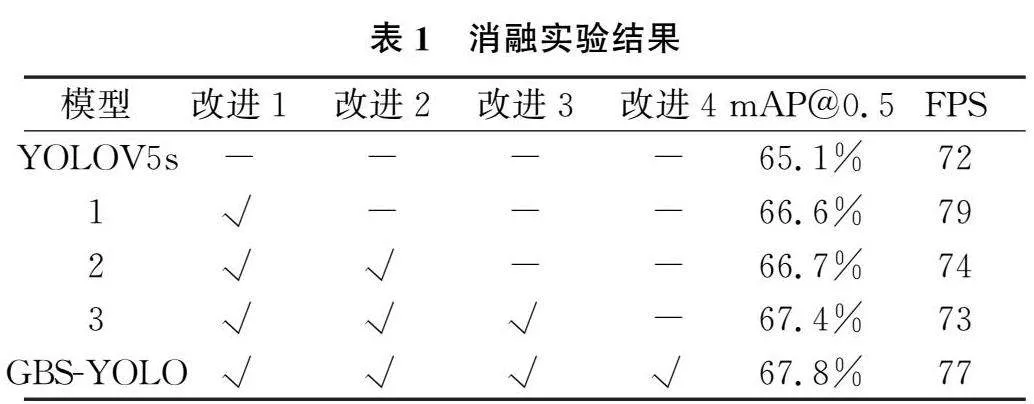
为进一步验证本研究提出的GBS-YOLO烟焰检测算法的有效性,本实验在自定义数据集进行五组消融实验。从表1中可知,方法1使用GhostNetV2替换原始主干网络,得到语义更加丰富的特征,且不改变输出特征维度,提升了mAP,可以使算法更加精准地定位和识别烟焰;方法2在GhostNetV2主干网络中的DFC注意力机制增加一条最大池化的分支增加对烟焰边缘特征的捕获能力;方法3使用一种更复杂的多尺度特征融合模块Bifusion Neck捕获烟焰的关键特征信息,使烟焰检测的准确率升高;GBS-YOLO结合SIOU边框回归损失函数,提升了mAP和mAP@0.5∶0.95,可以整体提高模型的检测性能。实验结果表明主干网络、多尺度特征融合模块和边框回归损失函数的共同优化可以有效地提升火焰烟雾检测的效果。
2.3.2对比实验
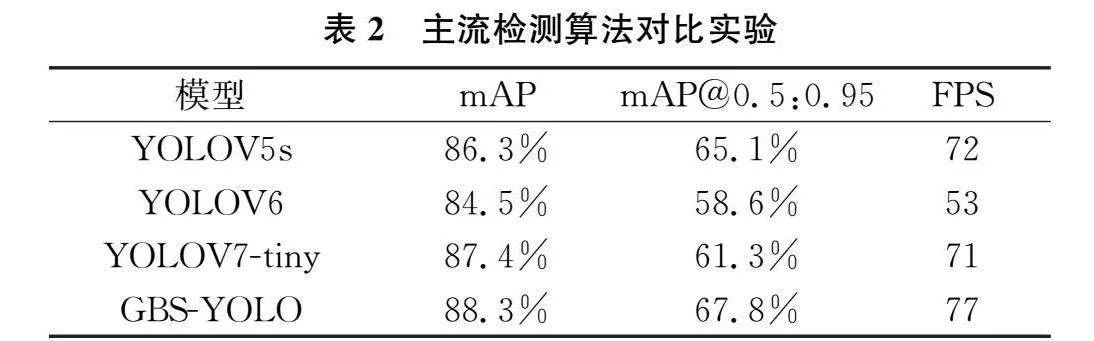
为了进一步验证改进算法的有效性,将本研究提出的算法GBS-YOLO与YOLOV5s、YOLOV6、YOL7-tiny、Faster-RCNN等网络在相同境配置下做对比验。如表2示,GBS-YOLO网络模型对比其他网络模型更具有优势,mAP@0.5:0.95值对比原始的YOLOV5模型高了2.5个百分点,比YOLOV7-tiny效果分别高约6个百分点。从对比的实验结果可以证明,GBS-YOLO的烟焰检测效果更佳。
2.4检测结果
为了进一步测试GBS-YOLO烟焰检测模型的检测性能,本研究使用测试集火焰图像进行测试,YOLOV5s、YOLOV7-tiny和GBS-YOLO的测试结果如图7所示。由检测结果可知,GBS-YOLO烟焰检测模型相比原始模型,误检和漏检情况有所改善,能够准确识别出图像中的烟焰目标;相比YOLOV7-tiny,GBS-YOLO检测模型在预测烟雾和火焰预测框的置信度方面有显著提升。同时,对于复杂背景、多尺度烟焰情境下的检测,基于此模型的检测方法仍具有良好的准确度。
2.5边缘计算设备部署
NVIDIA Jetson Orin是NVIDIA推出的边缘计算设备,具备高性能和低功耗的特性。该设备旨在为智能边缘设备提供强大的计算能力和人工智能加速,为应用场景提供可靠的嵌入式计算解决方案。NVIDIA Jetson Orin设备连接图和模型部署测试效果如图8所示。
经将GBS-YOLO模型移植至NVIDIA Jetson Orin后的结果显示,该模型在边缘计算设备上可实现稳定的烟焰检测,推理速度达到37fps,可满足实时检测要求。在复杂背景和多尺度目标的情况下,该模型也能准确识别烟焰目标,为火灾救援提供支持。
3结论
本研究针对目前车载智能消防炮上基于图像的烟焰检测算法检测平均精度低、烟焰漏检率高等问题,在原始烟焰检测模型的基础上进行了改进,提出了一种名为GBS-YOLO的烟焰检测方法。GBS-YOLO以YOLOV5网络结构为基础,通过使用轻量级GhostNetV2模块替代原网络的主干特征提取部分,引入了较为复杂的多尺度特征融合网络BiFusion Neck,并采用SIoU作为边界框回归的损失函数,提高边界框回归的精度。实验结果显示,该检测方法的mAP达到了88.5%,比原始模型提高了2.2%,检测速度达到77fps,相较于基准模型提升了6.9%。将GBS-YOLO烟焰检测方法部署在NVIDIA Jetson Orin设备上,能够满足实时检测要求,实现对烟焰的自动实时检测,满足火灾救援的实际需求。
[参考文献]
[1]CHEN T H,WU PH,CHOU YC.Anearlyfire-detectionmethodbased on imageprocessing[C]//InternationalCon-ferenceon ImageProcessing.IEEE,2004,3:1707-1710.
[2]CELIKT,DEMIREL H.Firedetection in video sequencesusingagenericcolormodel[J].FireSafetyJournal,2009,44(2):147-158.
[3]KONGGS,JIND,LIS,etal.Fastfire flame detectioninsurveillancevideo using logistic regression and temporal smoothing[J].FireSafetyJournal,2016,7937-43.
[4]任嘉锋,熊卫华,吴之昊,等.基于改进YOLOv3的火灾检测与识别[J].计算机系统应用,2019,28(12):171-176.
[5]RENJIEX,HAIFENGL,KANGJIEL,etal.Aforestfiredetection system based on ensemble learning[J].Forests,2021,12(2):217-217.
[6]WU Z,XUE R,LI H.Real-time video fire detection viamodified YOLOv5network model[J].Fire Technology,2022,58,2377-2403.
[7]GIRSHICKR.FastR-CNN[C]//InProceedingsofthe2015IEEE InternationalConference on Computer Vision.IEEE Computer Society.NW Washington DC,UnitedStates:2015:1440-1448.
[8]REN S,HE K,GIRSHICK R,etal.FasterR-CNN:Towards real-time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis and MachineIntelligence,2017,39(6):1137-1149.
[9]REDMON J,FARHADIA.YOLOv3:An IncrementalIm-provement[EB/OL].(2018-04-08).https://arxiv.org/pdf/1804.02767.pdf.
[10]BOCHKOVSKIYA,WANG CY,LIAO H.YOLOv4:Op-timalSpeed and Accuracy ofObject Detection[EB/OL].(2020-04-23).https://arxiv.or/abs/2004.10934.
[11]HEK M,ZHANG X Y,REN SQ,etal.SpatialPyramidPoolinginDeepConvolutionalNetworksforVisualRecog-nition[J].IEEE Transactionson Pattern Analysis andMa-chineIntelligence,2015,37(9):1904-1916.
[12]TANG Y,HAN K,GUO J,et al.GhostNetv2:Enhancecheap operation with long-range attention[J].Advances in Neural Information Processing Systems,2022,35:9969-9982.
[13]LICY,LILL,GENG Y F,et al.YOLOV6 V3.0:AFull-Scale Reloading[EB/OL].(2023-01-13).http://arxiv.org/abs/2209.02976.
[14]REZATOFIGHIH,TSOIN,GWAK JY,etal.Generaliz-edintersectionoverunion:ametricandalossforbounding-box regression[C]//2019IEEE/CVFConfere-nceonCom-puterVisionandPattern Recognition,2019:658-666.
[15]ZHENG Z,WANG P,LIU W,etal.Distance-IoUloss:faster and better learning for bounding box r-egression[C]//34th AAAI Conference on Artificial Intelligence,2020:12993-13000.
[16]YIFZ,WEIQR,ZHANG Z,etal.FocalandefficientIOUlossfor accurate bounding box regression[J].Neurocom-puting,2022:506146-157.
[17]GEVORGYANZ.SiouLoss:morepowerfullearningforboundingbox regression[EB/OL].(2022-05-25).http://arxiv.org/abs/2205.12740.
责任编辑:陈星宇
