非遗数字资源从元数据到语义知识图谱一体化构建
2024-12-04王伟许鑫






摘 要 文章探讨了非遗数字资源从元数据到语义知识图谱的转化,旨在提高构建效率的同时实现非遗数字资源的知识融通和有序化管理。通过两阶段映射的方法,将非遗数字资源元数据映射为本体,然后进一步将本体映射为知识图谱,完成从非遗数字资源元数据到本体与语义知识图谱一体化构建。研究表明,在已有非遗数字资源元数据的基础上,该方法可以有效提高本体与知识图谱构建效率,实现非遗数字资源元数据、本体和知识图谱一体化构建。
关键词 非遗数字资源;元数据;本体;知识图谱;知识融通
分类号 G250.73
DOI 10.16810/j.cnki.1672-514X.2024.10.009
Consilience Construction of Intangible Cultural Heritage Digital Resources from Metadata to Semantic Knowledge Graphs
Wang Wei, Xu Xin
Abstract This paper explores the transformation of intangible cultural heritage digital resources from metadata to semantic knowledge graphs, aiming to enhance construction efficiency while also achieving knowledge consilience and systematic management of these digital resources. Through a two-stage mapping method, metadata of intangible cultural heritage digital resources is mapped to ontologies, which are then further mapped to knowledge graphs, completing the consilience construction from metadata to ontologies and semantic knowledge graphs. The research indicates that, based on existing metadata of intangible cultural heritage digital resources, this method can effectively improve the construction efficiency of both ontologies and knowledge graphs, achieving an consilience construction of metadata, ontologies, and knowledge graphs for intangible cultural heritage digital resources.
Keywords Intangible cultural heritage digital resources. metadata. ontologies. knowledge graphs. Knowledge Consilience.
0 引言
非物质文化遗产(以下简称“非遗”)是维护文化多样性的重要因素[1]。随着科技的迅速发展,非遗领域大量使用数字化技术来保存非遗资源[2]。非遗资源数字化不仅能有效地保护非遗资源免受物理损害,还能通过互联网使其更易于被广泛访问和理解。非遗数字资源具有无破坏性、传播面广的优势,已成为其重要的发展趋势。然而,数字化的异构性、多源性和活态性对传统的资源共享方式提出了新的挑战[3]。因此,对非遗数字资源的有序化管理和深度开发利用成为当前亟待解决的问题。
知识图谱是一种结构化的语义知识库,最早由谷歌2012年正式提出, 其初衷是实现更智能的搜索引擎[4]。知识图谱能够将知识进行更加有序、有机的组织,使用户可以更加快速、准确地访问自己需要的知识信息, 并进行知识挖掘和智能决策[5]。其目标在于描述客观世界的概念、实体、事件以及它们之间的关系[6]。在知识图谱中,每个节点表示一个实体,而边表示实体之间的关系。通过知识图谱,非遗数字资源相关要素可以被有效地表示和链接,使得不同的知识点之间产生联系,从而提高知识的耦合度和关联性。知识图谱为实现知识的有机整合和深层次的理解提供了有力的工具和框架。
1 非遗知识图谱相关研究
知识图谱可分为基于RDF存储的语义知识图谱(关联数据)和基于图数据库的广义知识图谱,语义知识图谱(关联数据)是谷歌知识图谱的延续和发展[7]。语义知识图谱作为知识管理中数据挖掘和知识发现的有效手段[8],针对非遗的文化传承研究已有一定探索和实践。研究大致分为两类,一类侧重于非遗知识图谱语义组织方法研究,张卫等通过非遗非结构化文本到结构化知识至开放共享知识库的一整套知识组织模式,提出基于语义知识图谱的非遗人文知识服务[9]。王艺茹等运用TextRank算法处理文本语料,以知识图谱的形式实现中国传统木结构建筑营造技艺这一非遗领域可视化展示[10]。另一类侧重于非遗知识图谱的实践,王常珏等以元曲四大家现存杂剧为例进行抽取、融合、存储,最终构建元曲知识图谱[11]。张强等以黄河流域非遗资源为研究对象,构建了黄河流域非遗资源相关的知识图谱[12]。赵雪芹等将Protégé工具与Neo4j相结合,提出万里茶道数字资源知识图谱的构建思路[13]。
综上,当前非遗知识图谱的研究已取得显著进展,尤其在语义知识图谱方面已取得了丰富的研究成果,这为本研究提供了坚实基础,然而仍有一些值得思考的问题。首先,尽管非遗数字化得到广泛应用,但对于非遗数字资源的研究相对较少。随着非遗数字资源的快速增长,对其深入挖掘与知识组织的研究变得愈发重要。其次,在知识图谱的构建过程中,面对多源异构的非遗数据机器处理难度较大,依赖人工抽取效率较低,因此提高知识图谱的构建效率成为值得讨论的问题。针对上述问题,本文提出两阶段映射的方法来构建非遗数字资源语义知识图谱,旨在探索一种基于元数据映射的半自动知识图谱构建方式,在提高非遗数字资源知识图谱构建效率的同时,为非遗数字资源的知识融通和有序化管理提供可能性。
2 非遗数字资源知识图谱构建思路
2.1 元数据、本体、知识图谱的关系
随着非遗的数字化进程,大量非遗数字资源得以创建和积累。结构化元数据可以实现对非遗数字资源的定位、管理及下一步开发利用。元数据使非遗数字资源有了基本的微观结构,但其在解决语义异构问题方面存在局限。在此背景下,知识本体的应用显得尤为重要,知识本体通过对复杂关联关系的实体对象进行描述,从而为信息的组织、管理以及检索、查询提供了高效的模型和方法[14]。值得注意的是,虽然元数据和本体在信息管理和知识表示的目标上存在差异,但二者之间有着密切的联系。元数据主要关注描述数据的属性、来源、格式等,而本体则更深入地探讨领域内的概念和关系。元数据元素可以作为本体中概念的属性,而本体则可以看作是关于元数据的元数据,是元数据的进一步抽象和规范,为不同的元数据方案提供高层的互操作方案[15]。因此,基于合理设计本体模型基础上,可通过映射的方式将元数据中的元素转化为非遗数字资源本体中类的对象属性、数据属性和实体等。利用非遗数字资源的元数据规范,实现其本体知识组织,提升对非遗数字资源的语义理解和利用。
本体和知识图谱的联系体现在以下三点。在知识表示方面,本体作为知识图谱的基础,提供了一套标准化词汇和概念框架。本体定义了知识图谱中所用到的类、属性和关系的语义,确保了知识的一致性和准确性,标准化框架对于维持知识图谱的结构化和系统化至关重要。在知识共享与重用方面,知识图谱中本体的作用相当于知识库的模具,通过本体的约束,可以极大的减少知识的冗余程度[16]。通过本体,不同来源的数据和信息可以被统一解释和整合。在查询推理方面,本体不仅用于知识的组织和分类,还支持复杂的查询和逻辑推理。本体中定义的规则和逻辑可以用来推导出新的知识或发现知识图谱中的隐含关系。知识图谱依赖于本体来提供一个清晰的结构和语义框架,而本体通过应用于具体的知识图谱,其效用和实践价值得到体现。因此,本体可以帮助丰富知识图谱,提供更深层次的语义关联和逻辑推理能力,构建非遗数字资源语义知识图谱的前提是构建非遗数字资源知识本体。
2.2 基于映射的本体与知识图谱构建思路
考虑到多源异构的非遗数字资源获取知识信息效率较低,难度较大,同时由于元数据、本体、知识图谱的密切联系。本文的思路为从结构化非遗数字资源元数据获取数据来源,通过元数据映射的方式构建的知识本体,最终通过知识本体映射为非遗数字资源知识图谱。
如图1所示,本文提出基于两阶段映射的方式构建非遗数字资源知识图谱。
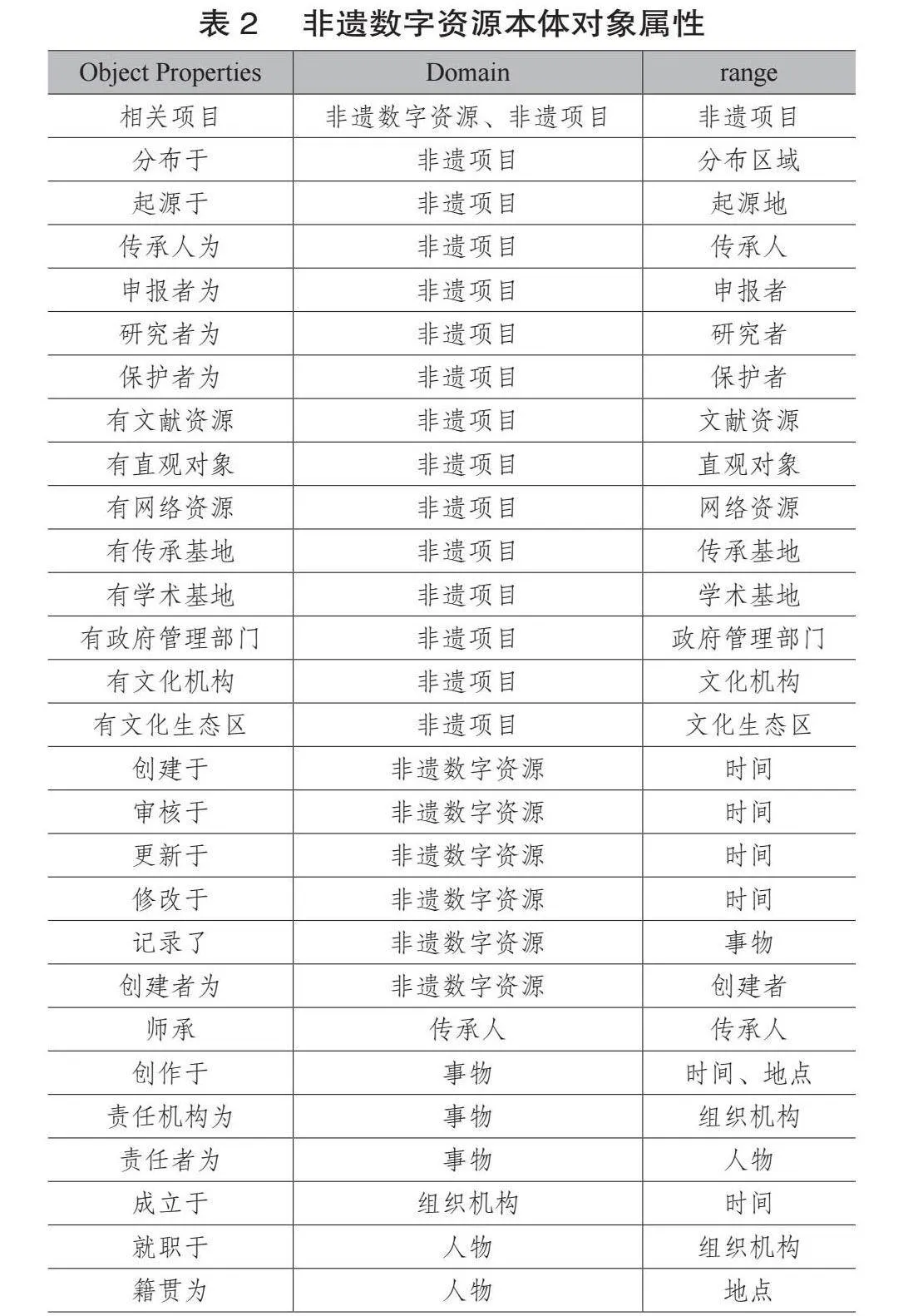
(1)元数据到本体的映射。元数据中的每个元素可以对应到本体中的相应概念,为非遗数字资源提供更丰富和结构化的语义描述。在非遗数字资源本体的构建中,本文在复用CIDOC-CRM文化遗产信息概念参考模型基础上,主要通过非遗数字资源元数据核心元素、限定词与本体中的类、实体与属性的映射关系,同时参考VRA、CHWA、MARC、古籍描述元数据规范、电子图片文件元数据、音频资料描述元数据规范等元数据规范扩展部分子类的数据属性,将非遗数字资源元数据映射到本体中来。通过非遗数字资源本体对其元数据核心元素与限定词数据的调用,实现非遗数字资源本体构建。
(2)本体到知识图谱映射。本体到知识图谱的映射主要在于实现二者之间元素的对应关系,即将本体的元素(包括类、实体、数据属性和对象属性)有效映射到构成知识图谱的关键组成部分,包括标签、节点、节点属性和关系。其中,标签要通过本体中定义的类表示,确保概念一致性和准确性。节点则对应于本体中的实体。对于本体中定义的数据属性和对象属性,可分别应用于知识图谱的节点属性和节点间的连接,进一步增强图谱的表达能力和语义丰富性。通过上述映射关系的建立实现基于本体驱动的知识图谱构建方法。
3 非遗数字资源知识图谱构建过程分析
本文以非遗数字资源为研究主题,目标是在非遗数字资源元数据核心元素和限定词的基础上,通过非遗数字资源元数据到本体、本体到知识图谱两阶段映射,构建非遗数字资源领域语义知识图谱,实现非遗数字资源开发利用,挖掘潜在的知识关联。
3.1 从元数据到本体的映射分析
本体建模是一个复杂的过程,在参考斯坦福大学提出的七步法[17]的基础上,利用protégé工具构建非遗数字资源本体,从元数据到本体的映射主要需要解决以下两个方面问题。
3.1.1 非遗数字资源本体核心类的确定
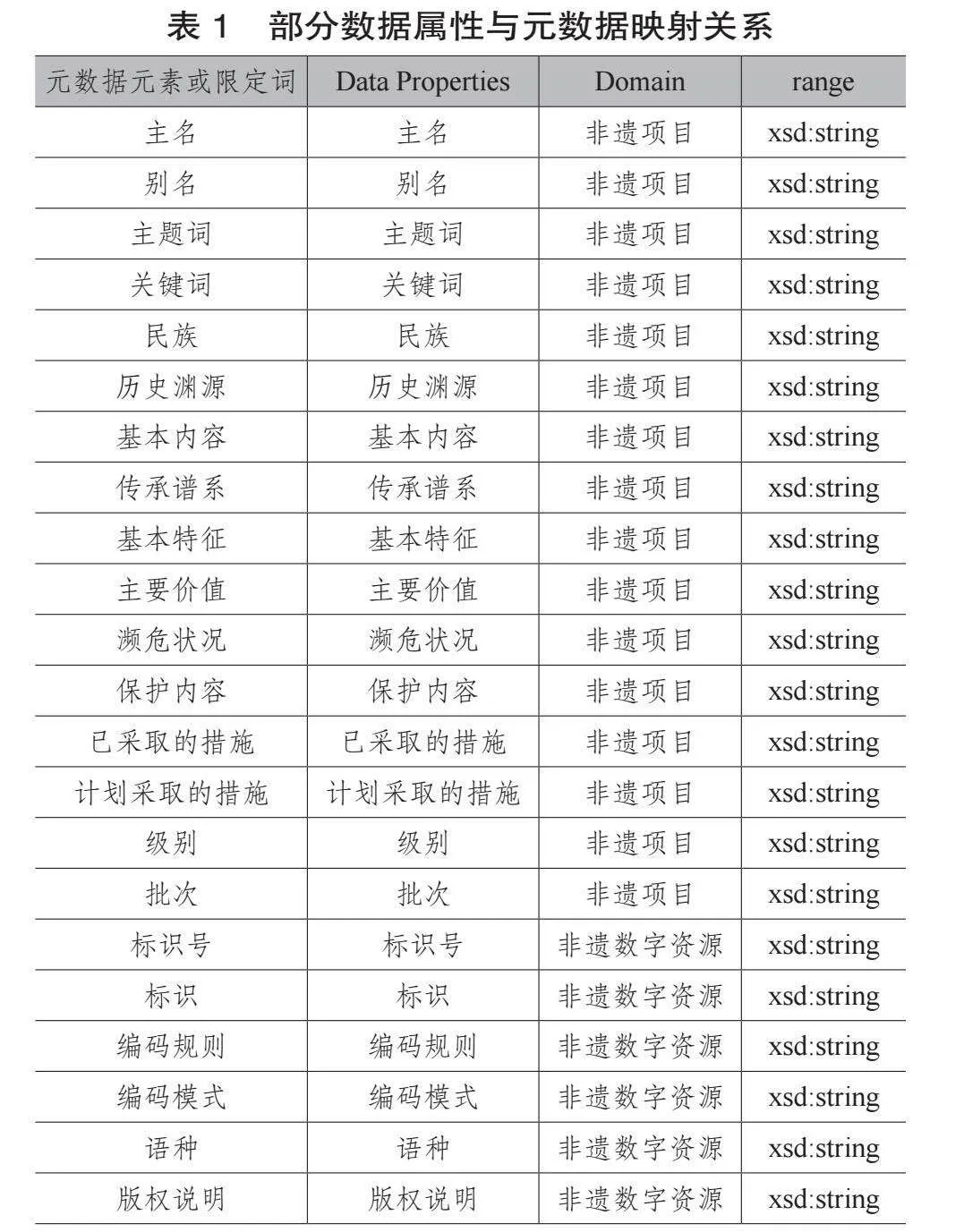
非遗数字资源核心类首先可参考CIDOC-CRM等文化遗产领域通用模型。CIDOC-CRM是为了促进文化遗产信息的整合、管理和交换而设计的共享语义框架。当前稳定版本 7.1.1包含了81个实体类和160个属性定义。在元数据方面,本文借鉴许鑫等构建的非遗数字资源元数据规范[18],该规范以国际通用的DC元数据标准为基础,从资源内容及属性、管理规范两个角度提炼出非遗资源的核心元数据集, 再根据非遗特点进行元素扩展,是一套具有兼容性、互操作性和非遗特色的元数据规范体系。
总体上看,该元数据规范可分为三个部分,分别为内容及属性描述、管理数据描述、关联信息描述。如图2所示:内容及属性描述部分可以归为非遗项目的类与属性,关于非遗项目的子类,有联合国教科文组织的五分法和我国的十分法等,考虑到现有整理的非遗数字资源主要为国内非遗资源,因此将非遗项目子类分为10类;管理数据描述部分可以主要归为非遗数字资源的类与属性;关联信息描述部分复用CIDOC-CRM中3个类,事物(E24 Physical Man-Made Thing)、人物(E21 Person)、组织机构(E40 Legal Body)。同时添加时间(E61 Time Primitive)类和地点(E53 Place),用于对非遗数字资源时间信息描述和非遗项目地点信息描述。综上,共构建“非遗项目”“非遗数字资源”“人物”“组织机构”“事物”“时间”“地点”7个类,完成本体核心类的构建。
为描述7个非遗数字资源本体核心类之间的关系,构造非遗数字资源核心类模型。如图3所示,图中方框表示非遗数字资源本体一级类目,箭头表示类目间的语义关系。各个类目间关系交叉渗透,如“非遗数字资源”记录了“事物”,“非遗数字资源”的相关项目是“非遗项目”,同时“非遗项目”之间也具有相关关系。“非遗项目”的关联人物关系是“人物”,关联机构关系是“组织机构”,起源于关系是“地点”,同时“人物”中具有师承关系。具体关系分析在下节本体对象属性中体现。从整体来看,非遗数字资源本体模型以非遗项目为核心构成网状关联结构。
3.1.2 非遗数字资源本体属性的映射设计
在对非遗数字资源的本体核心类进行确定后,需要对核心类的属性和关系进行确定,即对本体的数据属性和对象属性进行定义。本体的数据属性可以丰富对实体的描述,对象属性可以加强实体间的联系。
非遗数字资源数据属性可以根据元数据元素或限定词的映射来实现,上文将非遗数字资源元数据中“内容及属性描述、管理数据描述”两部分归为“非遗项目”和“非遗数字资源”两类,因此,如表1所示,这两部分的元素或限定词可以直接映射为两类的数据属性。
“人物”类的数据属性根据元数据中“人”的基本限定词定义为姓名、职业、职务、性别、民族、个人简介、传承人等级。“组织机构”的数据属性根据元数据中“机构”的基本限定词定义为名称、地址、邮编、电话、网址、邮箱、机构简介。“事物”类分为文献资料、直观对象、网络资源3个二级类目,其细分子类的数据属性可根据需要分别参考VRA、CHWA、MARC、DC、《拓片描述元数据规范》《古建筑描述元数据规范》《古籍描述元数据规范》《电子图片文件元数据》《音频资料描述元数据规范》等。通过元数据的映射关系,完成非遗数字资源类的数据属性定义。
非遗数字资源的对象属性即为7个类之间关系,在上文本体核心类已初步确定了7个类之间的主要关系,可进一步进行细分和优化。如“非遗项目”与“人物”的关系为关联人物,人物的二级子类为“传承人”“申报者”“研究者”“保护者”“创建者”5类,因此关联人物的关系可分解为“传承人为”、“申报者为”、“研究者为”“保护者为”“创建者为”5项。以此类推,“非遗项目”与“组织机构”的关系为关联机构,可分解为“有传承基地”“有学术基地”“有政府管理部门”“有文化机构”“有文化生态区”5项,“非遗数字资源”与“时间”的关系分解为“创建于”“审核于”“更新于”“修改于”4项。如表2所示,非遗数字资源本体对象属性共定义28项。
在完成非遗数字资源知识本体的类别、数据属性和对象属性定义之后,最后需要对知识本体创建实体,即将具体的实体数据导入到本体中。实体的导入使得本体从一个抽象的结构转变为一个充满实际内容的知识网络。完成以上步骤,具有结构化且富有信息内容的非遗数字资源知识本体便得以创建。
3.2 从本体到知识图谱的映射分析
本体提供了一种丰富语义的方式来表示知识。它不仅是数据的集合,而且反映了数据之间的语义关系和逻辑结构,这使得知识图谱能够支持复杂的查询和推理。通过protégé完成非遗数字资源的本体构建后,下一步需要实现非遗数字资源本体到知识图谱的映射。当前知识图谱工具有neo4j、Apache Jena、Ontotext GraphDB等,本文通过Neo4j进行知识图谱构建,Neo4j是一种开源图数据库管理系统,能够高效存储、管理和查询图数据,同时采用Cypher查询语言,使得表达图模式和关系操作更为简洁和可读。
由于protégé和neo4j工具的差异,同时本体和知识图谱构建规则的不同,二者在知识表达上存在着一定的差异。因此,本体模型中的类、属性、实例需要映射到知识图谱中,实现知识图谱的知识存储。Neo4j知识图谱中共有标签(Label)、 节点(Node)、 关系(Relationship)、 属性(Property)4 种元素。因此,neo4j知识图谱的映射过程主要包括四种。(1)标签映射。标签与本体中的类或子类项对应,如本体中的传承人、传承基地等类在neo4j形成标签,同时neo4j也自动生成Class、DatatypeProperty、ObjectProperty、NamedIndividual等标签。(2)节点映射。节点可与本体中的类、实体相对应,如本体中的非遗项目、事物、人物、地点在neo4j中可形成独立节点,同时非遗数字资源中的实体如宣纸制作技艺、皮纸制作技艺、藏族造纸制作技艺等也可作为neo4j中节点。(3)关系映射。关系与本体中的对象属性相对应,本体中对象属性表达的是类间的关系,与neo4j中的关系形成映射关系。(4)属性映射。节点的属性与本体中类的属性相对应,即将本体中描述类特征的数据属性映射为neo4j节点的属性。
使用protégé将本体以RDF或其他支持的格式导出,Neo4j自身不直接支持RDF格式的导入,可以通过安装插件neosemantics (n10s) 来实现。Neosemantics (n10s) 插件支持多种RDF序列化格式,并提供了一系列工具来映射、管理和查询RDF数据。通过安装n10s插件,同时配置Neo4j数据库以便能够解析和存储RDF格式的数据。使用n10s提供的工具和命令,CALL n10s.rdf.import.fetch(“path:\\非遗数字资源本体.rdf”, “RDF/XML”);
命令中,path为rdf文件本地路径,非遗数字资源本体.rdf为rdf文件名。将RDF文件导入到Neo4j中,通过建立映射,n10s 会自动将 RDF 本体映射为 Neo4j 的图结构。在这个过程中,RDF 类型和关系会被转换为 Neo4j 的节点和关系,从而实现rdf数据向neo4j知识图谱数据的导入。导入后可对标签下各个节点的标题内容、颜色、大小进行调整,完成非遗数字资源知识图谱构建。
4 非遗数字资源本体与知识图谱一体化构建
4.1 研究工具与数据来源
通过上述映射分析,设计了由元数据、本体、知识图谱两阶段映射的非遗数字资源知识图谱构建流程。本文采用的本体构建工具为Protege-5.6.1,知识图谱构建工具为neo4j社区版neo4j-community-5.15.0,JDK开发环境为jdk-21.0.1。使用的数据来源为为联合国教科文组织、中国非物质文化遗产网、安徽非物质文化遗产网中宣纸制作技艺的相关数字资源。这三个网站分别为世界级、国家级和省级非物质文化遗产收录网站,含有较为丰富的文本、图片、视频等非遗数字资源。采集数据为宣纸制作技艺相关非遗数字资源,造纸术为中国古代四大发明之一,宣纸是传统手工纸品最杰出的代表,居文房四宝之首,迄今已有一千五百多年的历史[19]。2006年,宣纸制作技艺经国务院批准、公布,列入第一批国家级非物质文化遗产名录。2009年,宣纸传统制作技艺被联合国教科文组织列入人类非物质文化遗产代表作名录。
4.2 非遗数字资源本体构建
通过非遗数字资源本体类与子类、数据属性、对象属性的定义,构建完成非遗数字资源本体模型。根据非遗数字资源元数据规范和实际具体情况,该模型共包含7个核心类、25个子类、28个对象属性、59个数据属性,同时由于涉及的元数据种类较多,其数据属性保留根据特定需求进行扩展的灵活性。为直观展示本体模型,如图4所示,利用protégé的OntoGraf插件进行本体模型可视化处理,类别和子类以方框形式呈现,实线用于表示类别间的继承关系,对象属性则通过虚线连接相关类别。最后,本体模型的完成需要实体数据的导入,这一步骤确保了模型的实际应用价值和数据的完整性。
4.3 非遗数字资源知识图谱构建
使用Neosemantics (n10s)插件通过映射向neo4j导入rdf数据后,进行适当颜色、大小调整,即可使用Cypher语言对知识图谱进行可视化。可视化是知识图谱的基础应用之一,即利用有向图直观地理解和分析图谱中的关系、实体和属性。通过知识图谱中的三元组数据可视化,用户可以清晰的了解各个节点之间相关内容,使各非遗数字资源的单独个体链接成为系统性知识,使用户能够整体了解非遗数字资源的整体概貌。
如图5所示,该图谱展示了宣纸制作技艺数字资源的相关信息,用不同颜色表示了非遗项目、非遗数字资源、组织机构、事物、人物、地点、时间7类实体节点,用户点击相应的实体节点,可以看到相应的节点属性,并可进行按需扩展。该图谱还展示了宣纸制作技艺项目、宣纸制作数字资源、传承人刑春荣、组织机构中国宣纸文化园、文献资料《中国造纸技术史稿》、宣纸专题片等相应节点属性。另外,点击相应的标签,用户可以对非遗数字资源的某一专题进行浏览研究,如紫色代表非遗项目标签,红色代表传承人标签,蓝色代表非遗数字资源标签,通过某一类标签的单独展示,可以更清晰地了解该专题的内在联系。知识图谱使得复杂的知识结构和关系以图形的方式呈现,使人们更容易理解实体之间的联系和关联,用户可以更容易地发现隐藏在数据中的模式、趋势和规律。
4.4 知识图谱查询与知识发现
在构建完成的非遗数字资源知识图谱中,可以通过Cypher进行查询,虽然Cypher本身不直接支持推理,但可以使用Neo4j中的APOC(Awesome Procedures on Cypher)库提供的过程和函数来执行推理操作,如发现中心节点、群体发现或路径查找等。例如通过Cypher命令:MATCH(n:研究者{uri:’潘吉星’}) RETURN n;来获取研究者为潘吉星的相关信息,包括其研究的相关非遗项目、文献资料、工作机构、籍贯地点等。进一步看,通过推导实体间的路径关系,可探讨实体间的联系,双击任意节点进行扩展,可得到与该节点距离为1的全部节点,可以发现与潘吉星研究的宣纸制作技艺相关的其他图书、照片、视频、网页等。由此,关于研究者潘吉星的相关信息一目了然。
知识图谱可以显著提升对非遗数字资源的理解和洞察力。通过Cypher查询,用户不仅可以获得单一实体的信息,而且还能探究不同实体之间的复杂联系,如某个非遗项目或非遗数字资源与相关人物、地点、事件、事物的关联。此外,知识图谱的可视化功能使得这些关系一目了然,为用户提供了直观的工具来探索和发现非遗资源之间的隐藏模式和趋势。特别是当前需要处理大量非遗数字资源时,这种方法尤其有效,它不仅提高了信息检索的效率,而且丰富了数据的语义解释,使用户能够从宏观上洞察非遗文化的多样性和丰富性。
5 结语
本文在非遗数字资源元数据的基础上,通过映射元数据元素和限定词构建本体类和属性,进而创建非遗数字资源知识本体。随后,通过本体类、实体、对象属性、数据属性映射到知识图谱的标签、节点、关系、属性,成功构建非遗数字资源语义知识图谱。这一过程实现了非遗数字资源的可视化展示和细粒度关联,并支持知识检索、发现和推理功能。非遗数字资源从元数据到本体与语义知识图谱的转化,能够在提高一体化构建效率的同时实现非遗数字资源的知识融通和有序化管理。
本文的思路是在元数据的基础上初步实现非遗数字资源的半自动化构建,即将语义知识图谱的自动构建简化为元数据的自动抽取,从而降低语义知识图谱构建难度。但是存在的不足是没有探讨非遗数字资源元数据的自动抽取问题,人工抽取仍需大量时间,这是该研究需要进一步完善的地方。同时,本文提出的元数据映射方法不仅适用于非遗数字资源,还具有向其他领域扩展的潜力,特别是在已经完成元数据建设的领域,可以将传统数据转换为更丰富和互动性更强的语义知识图谱,有效地提高数据的可访问性,同时促进知识的发现和共享。
参考文献:
UNESCO.What is Intangible Cultural Heritage?[EB/OL].[2024-05-01].https://ich.unesco.org/en/what-is-intangible-heritage-00003.
PROMPAYUK S,CHAIRATTANANON P.Preservation of cultural heritage community: cases of Thailand and developed countries[J].Procedia-Social and Behavioral Sciences,2016,234:239-243.
翟姗姗,许鑫,夏立新,石义金.语义出版技术在非遗数字资源共享中的应用研究[J].图书情报工作,2017,61(2):23-31.
漆桂林,高桓,吴天星.知识图谱研究进展[J].情报工程,2017,3(1):4-25.
李涛,王次臣,李华康.知识图谱的发展与构建[J].南京理工大学学报,2017,41(1): 22-34.
李涓子,侯磊.知识图谱研究综述[J].山西大学学报(自然科学版),2017,40(3):454-459.
陈涛,刘炜,单蓉蓉,等.知识图谱在数字人文中的应用研究[J].中国图书馆学报,2019, 45(6):34-49.
秦长江,侯汉清.知识图谱:信息管理与知识管理的新领域[J].大学图书馆学报,2009, 27(1):30-37, 96.
张卫,王昊,李跃艳,等.面向非遗文本的知识组织模式及人文图谱构建研究[J].情报资料工作,2021,42(6):91-101.
王艺茹,史东辉.使用CIDOC CRM构建建筑领域非遗知识本体[J].计算机工程与应用, 2023,59(3):317-326.
王常珏,张强,王盟燏,等.基于本体的剧曲类非遗知识图谱构建研究:以元曲为例[J]. 图书馆杂志,2023,42(11):91-98.
张强,吴艳飞,高颖,等.基于知识图谱的黄河流域非遗资源智能问答研究[J].文献与数据学报,2023,5(3):100-115.
赵雪芹,李天娥,曾刚.基于Neo4j的万里茶道数字资源知识图谱构建研究[J].情报资料工作,2022,43(5):89-97.
刘炜,李大玲,夏翠娟.元数据与知识本体[J].图书馆杂志,2004,(6): 50-54, 49.
夏翠娟.文化记忆资源的知识融通:从异构资源元数据应用纲要到一体化本体设计[J]. 图书情报知识,2021(1):53-65.
林炀平.文物知识图谱构建与检索关键技术研究与实现[D].杭州:浙江大学, 2017.
NOY N F, MCcGUINNESS D L.A guide to creating your first ontology[J]. Biomedical Informatics Reseach, 2001,2:14.
许鑫,张悦悦.非遗数字资源的元数据规范与应用研究[J].图书情报工作,2014,58 (21):13-20, 34.
中国非物质文化遗产网.宣纸制作技艺[EB/OL]. (2022-12-12)[2024-05-01]. https://www.ihchina.cn/project_details/14376.
王 伟 安徽师范大学图书馆副研究馆员。 安徽芜湖,241002。
(收稿日期:2024-05-11 编校:左静远,曹晓文)
