如何监管生成式人工智能在科学研究中的应用:风险与策略
2024-12-03赵悦
摘要:生成式人工智能因其快速、强大的内容生成能力,在科学研究领域引发广泛关注。如何有效监管其在科学研究中的应用成为讨论焦点。在此方面,欧盟和美国率先采取行动,制定了系列人工智能政策,以全面规范人工智能的研发、部署与使用。基于政策工具和政策内容的二维分析框架对近年来欧盟和美国的人工智能风险管理相关政策进行分析发现:生成式人工智能辅助科学研究可能涉及隐私安全、歧视传播、诚信挑战、监管滞后等风险。欧盟和美国在坚持构建可信赖的人工智能系统的目标定位以及以人为本的价值导向下,通过建立全面的风险管理框架,制定了风险界定与风险应对的具体流程和方法,并通过促进不同利益相关主体的共同参与和合作,明确了各自的权责。同时,为确保监管的顺利实施,欧盟和美国还通过建立数据保护条例、版权保护法律和道德伦理框架等,完善了人工智能科研应用的监管机制。未来,我国应联合各方力量,共同构建细致且适应性强的人工智能应用风险监管框架和相应的政策法律,以确保生成式人工智能在科学研究中的使用合乎道德伦理和法律规范。
关键词:生成式人工智能;科学研究;风险管理框架;监管策略;学术伦理
中图分类号:G434 文献标识码:A 文章编号:1009-5195(2024)06-0020-10 doi10.3969/j.issn.1009-5195.2024.06.003
一、引言
生成式人工智能技术是指具有文本、图片、音频、视频等内容生成能力的模型及相关技术(中华人民共和国中央人民政府,2023)。自2022年ChatGPT发布以来,生成式人工智能快速发展,其所具备的巨大社会价值和商业潜力,已在各个领域引发变革,或将成为未来个体在生产生活中不可或缺的重要工具(高奇琦,2023)。在科学研究领域,生成式人工智能亦在有效辅助科研过程、提升科研效率方面(Kocoń et al.,2023;Lund et al.,2023)体现出潜在的应用价值。如在研究初期,ChatGPT可以辅助研究者进行“头脑风暴”,提供创新想法和相关信息;在研究过程中,它可以辅助撰写研究背景和文献综述,帮助研究者优化实验设计、进行初步的数据分析和结果阐释;在研究后期,它还可以翻译、润色语言文字,按照不同格式生成参考文献等(刘宝存等,2023;Rahman et al.,2023)。总而言之,生成式人工智能可以辅助研究者处理耗时的常规性和程序性工作,在一定程度上能解放科研人员的时间和精力,使其投入更具创新性的工作之中。
然而,应用生成式人工智能进行科学研究仍面临监管方面的困境(UNESCO,2023a)。一方面,生成式人工智能所使用的预训练数据集大多来自网络爬虫(Brown et al.,2020),存在信息不准确、带有偏见或有害信息,以及侵犯个人隐私和版权的风险等(中国科学技术信息研究所,2023)。作者如果不加分辨地采用这类信息,或将加剧制度性种族主义或性别歧视(兰国帅等,2023;UNESCO,2023a)。另一方面,生成式人工智能可以生成高度接近自然语言的文本,审稿人很难辨别人类文章与机器生成文章的差异,或将加剧学术不端行为(Chowdhury et al.,2018),对整个科研生态产生危害。
在此背景下,一些研究者、科研机构发布了如何运用ChatGPT进行科学研究的具体操作指南(Atlas,2023;中国科学技术信息研究所,2023),为生成式人工智能在科研领域的规范应用奠定了基础。然而,如何有效监督和管理这一新兴技术在科研过程中的使用,特别是针对其可能引发的数据隐私泄露、伦理道德及安全风险等问题,现有研究尚缺乏系统探讨。在这方面,欧盟与美国已率先采取行动,发布了如《欧盟人工智能法案》(European Union Artificial Intelligence Act,简称EU AI Act)、《人工智能风险管理框架》(Artificial Intelligence Risk Management Framework,简称AI RMF)等政策文件,以全面规范人工智能的研发、部署与使用。基于此,本研究采用政策文本分析法,聚焦分析欧盟和美国在生成式人工智能应用于科研领域的监管策略及其差异,旨在为我国学术界、科研机构及政策制定者提供参考与建议。
二、研究设计
1.研究对象
欧盟委员会(European Commission)于2022年提出EU AI Act草案,并在2024年正式发布实施。该法案作为全球范围内首个具有系统性、高约束力的法律框架,全面且细致地规定了人工智能领域政策制定、监管职责、风险分级监管策略、信息披露机制、数据保护原则及法律规范等内容,为人工智能的研发与应用提供了政策支撑。与此同时,美国国家标准与技术研究院(National Institute of Standards and Technology,简称NIST)于2021年提出AI RMF草案,并在2023年正式发布1.0版并实施。AI RMF侧重于构建灵活且细致的风险管理体系,为人工智能技术的实际应用提供了详细的风险评估与管理策略,旨在辅助组织识别、评估、缓解和监控人工智能系统中的潜在风险。这两份政策文件都经过了长时间的深入研究与讨论,适用范围广泛,且充分吸纳了多维利益相关者的建议,在国际上具有较高的认可度和影响力,因此本研究将其作为核心分析对象。
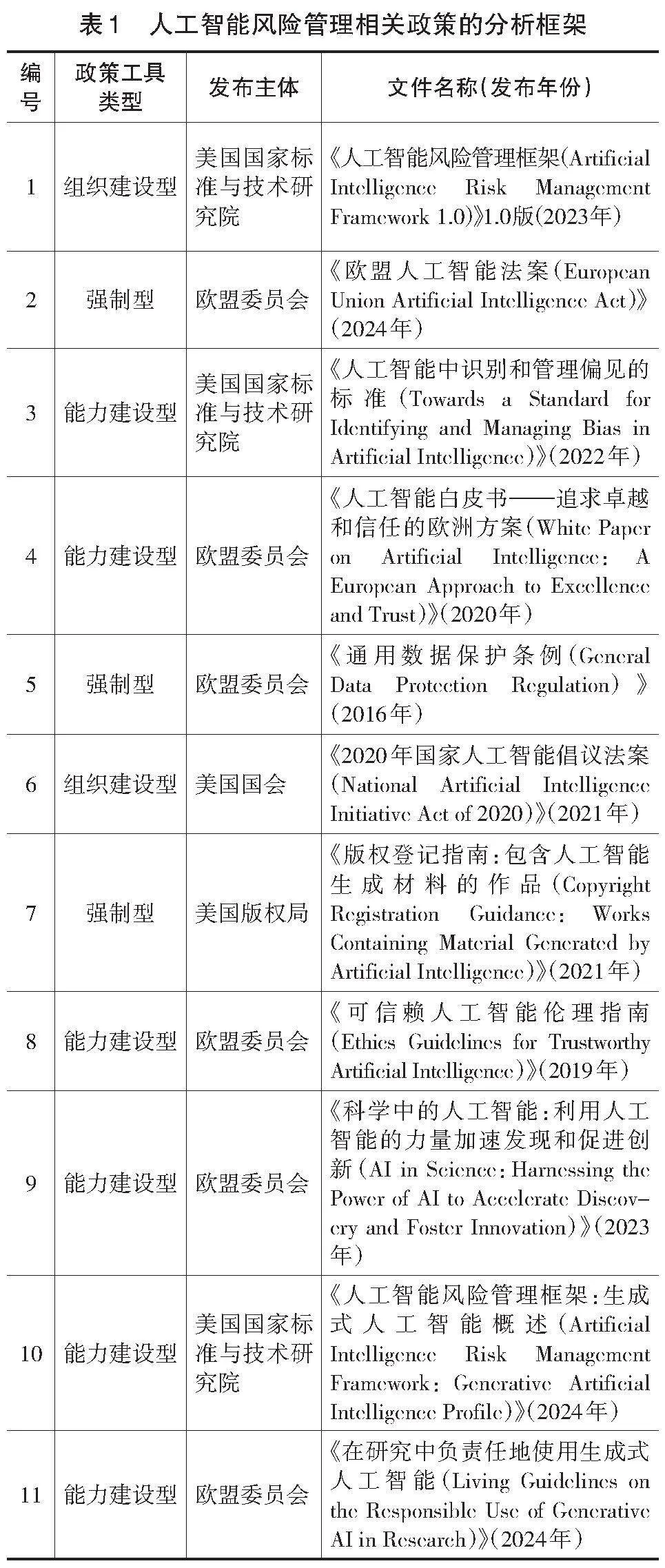
同时,为了更全面且深入地探讨欧盟和美国在生成式人工智能监管方面的实践框架,本研究将上述政策文本所涉及的关联政策也一并纳入分析。关联政策筛选遵循以下原则:(1)相关性,政策文本与生成式人工智能在科学研究中的应用相关;(2)典型性,政策文本应包含人工智能应用于科学研究的具体监管措施和实践案例,以支持对监管策略的深入解读。经过筛选,本研究最终确定了11份具有代表性的政策文本作为分析对象(见表1)。从政策发布主体上看,美国人工智能政策的发布机构呈现出多机构分散负责的特点,尚未形成全国性、统一的人工智能监管法律框架(US Congress,2020)。相比之下,欧盟人工智能政策的发布机构呈现高度一致性和统一性,政策制定与发布主体较为集中。从政策工具的数量分布上看,能力建设型政策工具使用频率较高,共计6份;强制型政策工具为3份,组织建设型工具为2份。
2.分析框架
本研究采用X—Y二维政策分析框架。X维度为政策工具类型,是政府部门为实现政策目标而使用的辅助手段。政策工具有多种分类方式,本研究借鉴McDonnell等对政策工具的分类(McDonnell et al.,1987)。选择该分类方式的原因有:第一,这种分类方式标准清晰、界定明确,易于区分。第二,这种分类方式所涉及的政策工具与人工智能监管具有高度的相关性。在结合欧盟和美国政策文件特点的基础上,本研究最终确定的政策工具类型包括能力建设型、强制型、组织建设型三类。其中,强制型政策工具主要是制约和规范个体、组织等的行为,确保生成式人工智能应用的合法性和规范性,包括强制命令、实施处罚等;能力建设型政策工具主要是提供资源、培训和信息等,包括资源配置、技术支持等;组织建设型政策工具主要是重构与优化权力关系,通过调整不同组织机构在生成式人工智能应用中的职责与权限,以促进组织内部的适应性变革,包括机构变革、功能调整等。
政策工具可以显示政策为实现目标所采取的基本手段,但无法体现政策保护的具体方向,因此需进一步通过Y维度展现政策内容要素。政策内容的编码方式有两种:一是归纳式编码,即直接根据实证数据编码,形成自由节点,并根据节点之间的内在联系形成子节点、父节点;二是推论式编码,即根据已经确定的维度,形成研究框架,进而在研究框架下编码(伍多·库卡茨,2017)。本研究采用归纳式编码,具体操作如下:首先,将11份政策文本导入NVivo14 Plus分析软件,以政策文本条款为分析单元进行手动编码。通过一级编码,共形成了148项风险类型的自由节点和533项监管策略的自由节点。其次,对自由节点进行合并、聚类,将相互联系的自由节点纳入子节点,完成二级编码。再次,从子节点中归纳概括出父节点,完成三级编码。总体而言,针对生成式人工智能应用于科学研究所涉及的风险类型,归纳形成了隐私安全、歧视传播、诚信挑战、监管滞后四类风险(父节点)及其下7项风险内容(子节点)。针对Y维度政策内容要素,归纳形成了目标定位、价值导向、行动策略和监管机制四类监管策略(父节点)及其下14项风险应对措施(子节点)。
三、生成式人工智能辅助科学研究的风险
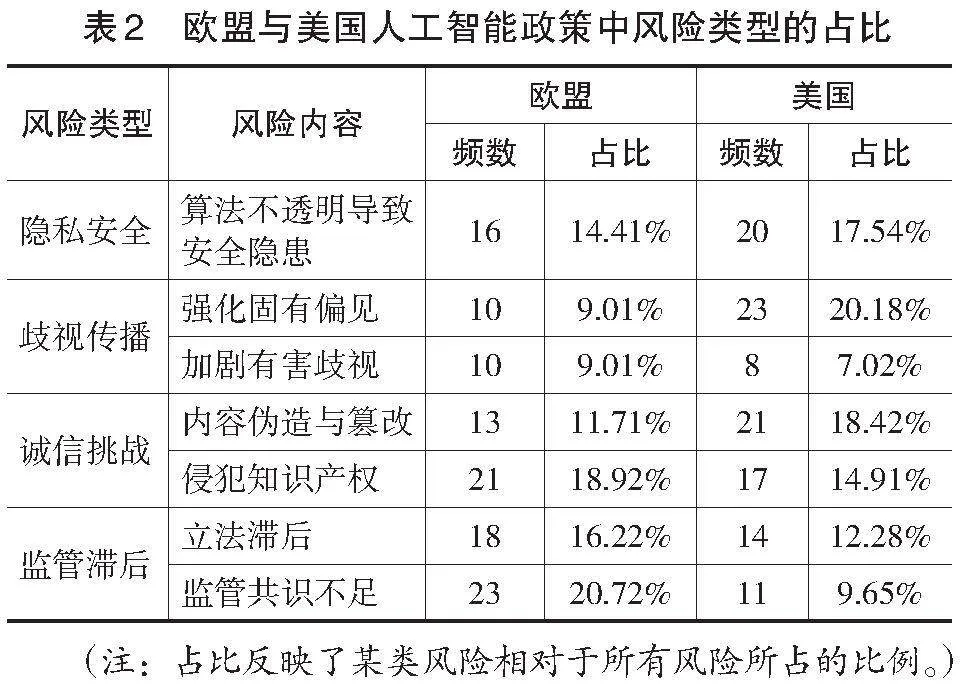
如前所述,在欧盟和美国的人工智能政策文件中,有关生成式人工智能辅助科学研究的风险可归纳为隐私安全、歧视传播、诚信挑战以及监管滞后四类,但二者对不同风险类型的关注度存在差异。表2显示了欧盟和美国人工智能政策文件中提及的风险类型以及各类风险在政策文件中出现的频数与占比。
1.隐私安全:算法不透明导致安全隐患
如表2所示,在隐私安全风险方面,欧盟在相关政策中16次提及算法不透明导致的安全隐患问题,占所有风险的14.41%;美国在这方面的关注度更高,共提及20次,占所有风险的17.54%。这侧面反映了社会大众对人工智能算法不透明的担忧。《自然》杂志一项针对1600名研究人员的调查显示,超过69%的研究者担忧人工智能系统的不透明性(Van Noorden et al.,2023)。生成式人工智能的算法“黑箱”,令人无法知晓或追溯其输出是如何确定的(兰国帅等,2023)。生成式人工智能依赖海量的数据支持,数据主要来源于互联网,存在质量参差不齐的问题;同时,模型中存在数十亿个参数,而每个参数及其权重都不透明,验证其输出内容是否遵循基本权利及现有规则成为一项艰巨任务(European Union,2024)。如果缺乏对数据质量、数据使用步骤和环节的审查,就难以保障数据的安全(Miller et al.,2013)。尤其是在使用人工智能进行科学研究的过程中,若用于研究或训练人工智能模型的个人信息,被用于科研分析之外的其他用途(Department of Education of Australian Government,2023),将为个体隐私安全带来风险。
2.歧视传播:加剧固有偏见与有害歧视
生成式人工智能可能加剧固有偏见和有害歧视,引发歧视传播风险。对此,美国相关政策中提及了31次,占比27.20%;欧盟提及20次,占比18.02%。与欧盟相比,歧视传播是美国人工智能应用政策文本中更为关注的风险类型,尤其是对其中的“强化固有偏见”风险关注最多(见表2)。偏见以多种形式存在于生活之中,放大原有的偏见或将对特定社会群体造成不利影响(European Commission,2023a)。生成式人工智能中的偏见主要涉及三个方面:第一,系统偏见,源自特定机构的程序和设定,导致某些社会群体在系统中获得不公正的优势或弱势地位;第二,统计性与计算性偏见,源自人工智能系统所采用数据集和算法的局限性;第三,人为偏见,源自人类思维中的系统性错误或数据处理方法的局限性,典型如McNamara谬误,指过度依赖可量化的数据而忽视其他不可量化但重要的因素(NIST,2022)。从偏见类型上看,性别偏见、种族偏见和地域偏见的问题尤为突出。《自然》杂志上的一项研究结果显示,当要求GPT-4为一系列临床案例提供治疗与诊疗建议时,其回答因患者的性别和种族而异(Van Noorden,2023)。欧盟在《科学中的人工智能:利用人工智能的力量加速发现和促进创新》报告中指出,人工智能的设计和研发过程中,男性主导的现象可能导致算法和模型忽略女性视角及其需求,从而不能充分反映社会的多样性(European Commission,2023a)。算法模型可能复制并放大性别歧视(Van Doorn,2017)。此外,欧洲的人工智能研发机构、人工智能研究专家主要集中在法国、德国和瑞士,因而可能在人工智能的部署与使用过程中加剧地域偏见(European Commission,2023b)。类似地,联合国教科文组织也指出,互联网上南半球、北半球边缘化地区等人群的数据不足,算法将加剧数据匮乏地区边缘化问题(UNESCO,2023a)。
3.诚信挑战:内容伪造与侵犯知识产权
欧盟和美国均高度重视生成式人工智能可能带来的诚信挑战。具体而言,欧盟在政策中对此类风险提及了34次,占比30.63%;而美国则提及了38次,占比33.33%(见表2)。一方面,生成式人工智能存在内容伪造与篡改的问题。以ChatGPT为例,其可以生成看似合理的答案(UNESCO,2023b),但在信息准确性和逻辑推理上却存在明显问题。通过生成式人工智能检索到的参考文献可能包含相关性低、过时的,甚至是编造的资料,研究人员在使用时需要谨慎甄别(European Commission,2023a)。尤其对于学术界的新手而言,因缺乏丰富的先验知识,更易被这些看似合理实则错误的信息所误导(UNESCO,2023a)。
另一方面,生成式人工智能可能助长学术剽窃与知识产权侵犯等问题。生成式人工智能具备的快速生成高度逼真文本的功能,可能加剧论文抄袭、考试作弊等行为(Susnjak,2022)。已有研究表明,人工智能能够创作出与领域专家水平相当甚至更出色的文本内容(Schwitzgebel et al.,2023),进而加大了学术不端检测的难度(中国科学技术信息研究所,2023)。审稿人难以辨别这些由生成式人工智能辅助学者生成或完全由生成式人工智能生成的论文。研究人员也可能利用这一漏洞,将生成式人工智能生成的内容冒充为自己的研究成果,以不诚实的手段产出低质量的科研成果(王佑镁等,2023)。此外,个体在未经授权的情况下,利用生成式人工智能窃取他人研究思想、研究创意或研究成果,还可能构成内容剽窃或版权侵犯的严重问题(UNESCO,2023a)。
4.监管滞后:立法滞后与监管共识不足
欧盟与美国均表现出对人工智能立法与监管措施滞后问题的关注,并体现在其相应的政策中。具体而言,欧盟对此类风险提及了41次,占比36.94%;而美国则提及了25次,占比21.93%。欧盟相对于美国而言,对监管滞后问题的关注度更高(见表2)。生成式人工智能正在以惊人的速度迭代,其发展速度远超国家监管制度的改革步伐。联合国教科文组织近期的一项覆盖450所大中小学的全球性调研结果显示,仅有不到10%的机构制定了关于生成式人工智能应用的组织规范或操作指南(UNESCO,2023a)。尽管已有部分高等院校、研究机构及出版商发布了相关建议或指南,但这些建议或指南尚不全面,且在实际应用中,如何根据具体情况选择合适的指南还缺乏有效的指导(European Commission,2023a)。由此可见,在利用生成式人工智能进行科学研究时,科研机构普遍面临规范性政策与指南缺失的困境,这凸显出国家层面加快政策制定的紧迫性。从更广泛层面来看,国际社会在立法方向上尚未形成广泛共识,增加了监管框架构建与实施的难度。特别是在数据保护、公平与伦理框架构建,以及人工智能生成内容的版权保护等核心领域,现有法律体系显得尤为不足,亟须立法层面的跟进与完善(European Union,2024)。
四、生成式人工智能辅助科学研究的监管策略
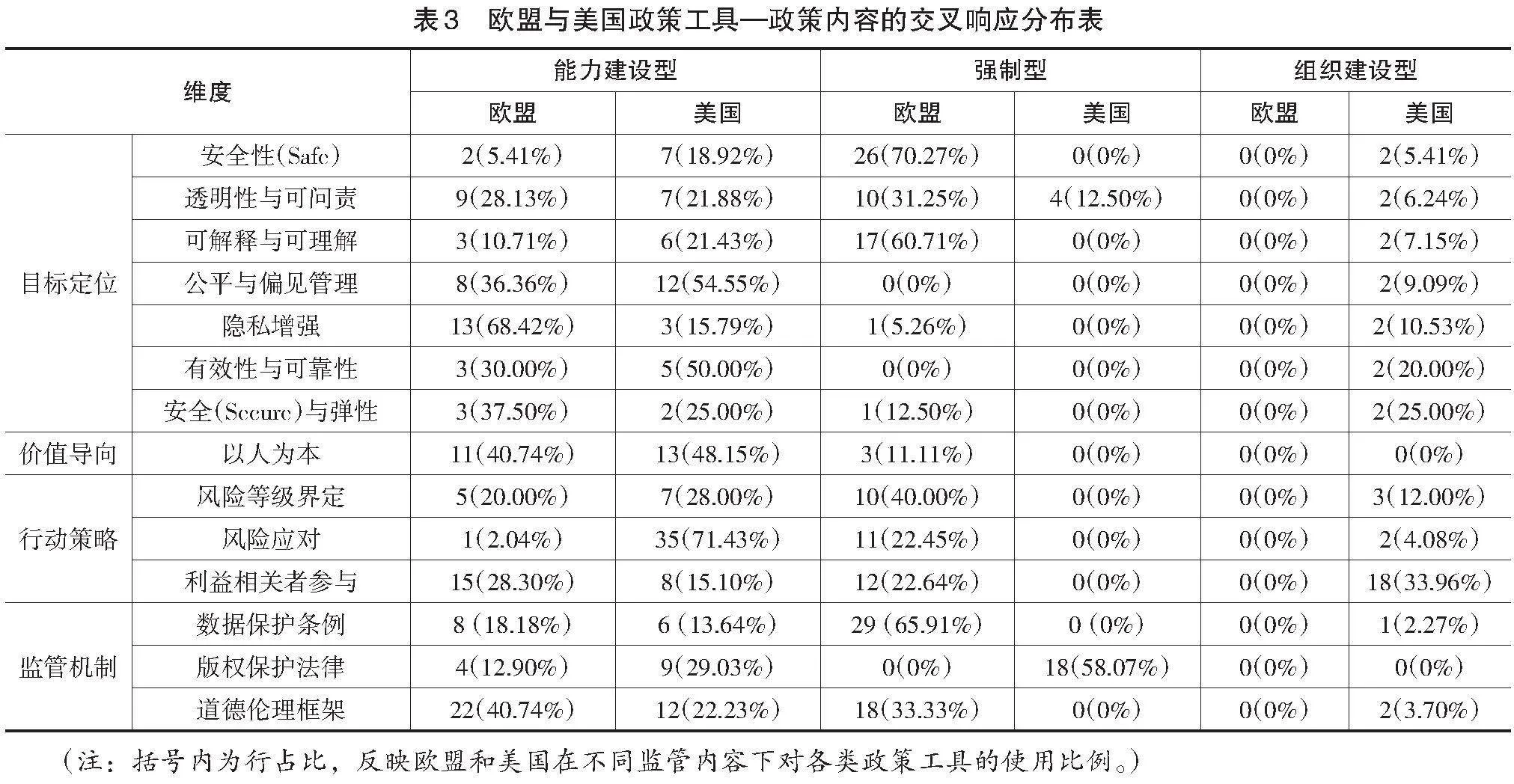
如前所述,研究根据政策内容,将欧盟与美国有关生成式人工智能应用的监管策略归纳为四个关键维度:目标定位、价值导向、行动策略和监管机制。其中,目标定位和价值导向是监管策略制定的基础,提供监管的方向和行动指引;行动策略是监管策略的核心,明确监管具体的实施方式;监管机制是监管有效运行的保障,确保监管措施得以落实。为了更好地展现欧盟和美国生成式人工智能监管政策中所采取的政策工具对政策内容的支持情况,研究以政策工具为X维度,政策内容为Y维度,形成了不同发文主体的交叉响应结果,详见表3。
如表3所示,欧盟与美国的人工智能政策在目标定位上,响应次数由高到低依次是安全性(37次)、透明性与可问责(32次)、可解释与可理解(28次)、公平与偏见管理(22次)、隐私增强(19次)、有效性与可靠性(10次),以及安全与弹性(8次)。安全性(Safe)强调生成式人工智能系统不能对人、财产或环境造成威胁。透明性指生成式人工智能系统及其输出结果应能够被使用者识别,使用者也应明确披露对生成式人工智能的使用情况;可问责指关键利益相关者应建立问责标准和相关信息。可解释指生成式人工智能系统的运作机制是可解释的,可理解指生成式人工智能的输出结果是可理解的。公平与偏见管理指消除生成式人工智能输出中存在的有害偏见、歧视的内容。隐私增强指保护使用者的自主权、身份和尊严,避免泄露或滥用个人信息。有效性指生成式人工智能满足特定预期要求,可靠性指生成式人工智能系统能够按要求无故障运行。安全(Secure)指通过保护机制防止未经授权的访问,而弹性指发生意外的不利事件后能够恢复正常功能。
总体来看,欧盟和美国人工智能政策中,对安全性、透明性与可问责、可解释与可理解的响应次数较多,说明二者均倡导建立可信赖的人工智能系统,且在标准制定上较为一致。而对比二者在政策工具上的使用情况发现,欧盟使用强制型政策工具在安全性(26次,占比70.27%)、透明性与可问责(10次,占比31.25%)、可解释与可理解(17次,占比60.71%)等方面的响应次数更多;而美国使用能力建设型工具在公平与偏见管理(12次,占比54.55%)上的响应次数更多。
2.价值导向:以人为本的价值导向
欧盟与美国的人工智能监管政策在“以人为本”的价值导向方面分别响应了14次与13次,二者均主要使用能力建设型工具倡导并贯彻实施这一理念。欧盟强调监管的核心在于维护欧盟的基本价值观,尊重人类尊严、自由、平等、民主及法治(European Union,2024),并保障个体基本权利,如免受歧视、数据隐私保护,以及儿童权益维护等。美国NIST在AI RMF中提出“以人为本”人工智能系统设计的六大核心要素。第一,深入理解用户、任务及使用环境,以此作为设计决策的基石。第二,确保用户在设计与开发的全周期中持续参与,以即时整合用户需求与反馈。第三,建立用户导向的评价体系,驱动设计的持续优化与完善。第四,实施原型设计、测试与迭代修改,形成持续改进的循环过程。第五,全面考量所有用户的体验,促进设计成果的和谐与高效。第六,组建跨学科设计团队,融合多样知识与技能,以多元化视角激发创新潜力(NIST,2023)。相较于欧盟统一的价值规范,美国NIST所倡导的以人为本的人工智能系统设计原则在人机交互的语境下展现出更为具体的技术与伦理考量,包括确定特定的用户群体和目的、设计差异化应用场景、促进科学研究者与专家采用实证研究以反馈评估人工智能系统的适用性等。
3.行动策略:风险管理框架与多方参与
(1)风险管理框架:风险界定与应对措施
风险管理框架(Risk Management Framework,简称RMF)已成为欧盟和美国在监管人工智能应用过程所采取的共识性策略。如表3所示,欧盟主要使用强制型政策工具以建立风险管理框架,针对风险等级界定响应10次(占比40.00%)、风险应对响应11次(占比22.45%)。EU AI Act中明确界定了四个风险等级:不可接受风险、高风险、有限风险和极低风险。不可接受风险是指威胁人类生命、安全和权利的人工智能系统,这类人工智能系统禁止投放市场、投入服务或使用。高风险是指对个人健康、安全与基本权利产生高风险的人工智能系统,在投入市场前必须按照法案进行评估。EU AI Act界定了8项高风险等级的人工智能系统。有限风险是指对用户权利或安全构成一定风险的人工智能系统,使用者在应用系统时能够意识到是在与人工智能互动,且能够根据个体判断进行决策。根据这一标准,应用生成式人工智能进行科学研究的行为隶属于有限风险等级。相较于高风险人工智能系统,有限风险人工智能系统具有一定自由度,在投放市场或使用前无需特殊的牌照、认证、报告、监督、记录留存,但人工智能供应商和使用者应承担人工智能透明度方面的义务。根据美国NIST的界定,若人工智能系统是在包含敏感或受保护数据(例如个人身份信息)的大型数据集上进行训练,或其输出对人类有直接或间接的重大影响,则该系统应被明确界定为高风险等级;若仅与计算系统交互,并且使用非敏感数据集进行训练的人工智能系统,在初始风险评估时不需要被赋予过高的风险等级(NIST,2023)。综合上述标准,应用生成式人工智能进行科学研究的风险等级主要因具体应用场景、数据集而异。如果生成式人工智能处理的是非敏感数据集且研究结果的影响可控,则属于有限风险等级;如果处理的是敏感数据,或可能对人类健康、社会政策等产生重大影响,则需要重新评估其风险等级,并可能升级为高风险。
美国在风险应对中较多地使用能力建设型政策工具,响应次数达35次,占比71.43%;相比之下,欧盟主要使用强制型政策工具。风险应对包括映射(Map)、测量(Measure)、管理(Manage)和治理(Govern)四个核心步骤,它们并非线性排列而是相互交织、彼此关联的(NIST,2023)。映射旨在定义和记录人工智能使用流程;测量旨在采用科学的方法分析、评估或监测人工智能的风险及影响;管理旨在确定风险等级并采取相应行动;治理旨在建立组织的风险管理文化,澄清、定义监督人工智能系统的角色和责任。在具体操作层面,AI RMF在其官方网站提供了一系列工具包,包括手册、路线图和操作示例等(NIST,2024)。以美国圣何塞市(San José)为例,首先,该市的政策执行者进行背景调查,确立监管机构(人工智能治理负责人、工作组、数据隐私咨询工作组等)及其权责,并采取相应监管措施。其次,参照AI RMF的四个核心步骤及其下的72个子项对现有的人工智能治理情况进行评分,并针对低分项采取针对性措施,制定行动计划。例如,针对圣何塞市在测量方面得分较低的问题,该市采取重新确认人工智能治理关键内容、提供相应教育培训、增设反馈渠道、探索第三方合作机会等措施,以改进当前的人工智能系统。尽管NIST尚未直接提供具体案例说明AI RMF如何应用于科学研究,但可以参照上述步骤指导生成式人工智能在科学研究中应用的风险管理。特别是在测量过程中,应重点关注科学研究是否可能危害个体的基本权利、心理健康或公共安全,是否存在信息的滥用情况,以及输出内容是否带有冒犯性或歧视性等。
(2)利益相关者共同参与
人工智能的风险防范和治理需要利益相关者共同承担责任。对此,欧盟和美国的人工智能政策均有较多响应,其中欧盟采用各类政策工具响应27次,美国采用各类政策工具响应26次。在欧盟和美国的相关政策中,提及的利益相关者包括政府和地方当局、人工智能供应商、科研机构与科研工作者,以及其他行业合作伙伴。从比例上看,政策工具对科研机构与科研工作者、政府与地方当局的响应比例较高,达34.00%;其次为人工智能供应商,占比25.00%。从风险管理视角来看,不同利益相关者的职责不同。
第一,政府和地方当局主要提供政策支持和科研资助。如表3所示,美国主要使用组织建设型政策工具来提供政策支持(18次,占比33.96%),规定并调整如科学与技术政策办公室(Office of Science and Technology Policy,简称OSTP)、能源部(Department of Energy,简称DOE)、国家科学基金会(National Science Foundation,简称NSF)等机构在人工智能监管方面的具体职责,并成立国家人工智能倡议办公室来专门执行相关任务(US Congress,2020)。DOE负责成立国家人工智能咨询委员会,旨在为总统和倡议办公室提供政策指导,并致力于提升与DOE使命紧密相关的人工智能系统的可靠性。在科学研究领域,NSF负责制定人工智能系统的风险管理框架,从财政角度支持人工智能研发机构,推动人工智能技术的研发和应用,资助相关领域的研究和教育活动,以促进知识创新和人才培养。欧盟则倡导通过科研资助来调动多方利益相关者共同开展人工智能研究,组织人工智能行业专家、科研工作者开展科研伦理、风险评估等方面的研究。例如,欧盟委员会在“地平线欧洲战略计划”(Horizon Europe Strategic Plan)项目中纳入科研伦理的指南制定、审查机制及培训等内容(European Commission,2023a),旨在确保人工智能辅助科学研究在合法、合规和道德的框架内开展。
第二,人工智能供应商应提升人工智能系统的透明度,确保人工智能输出的内容以机器可读的格式标记,以便于回溯和查验。透明度主要指数据透明度,如底层数据集、数据来源和数据处理等,都需说明采纳和应用的方法,同时需要披露知识产权和版权使用情况。为提升人工智能系统的透明度,供应商应在充分考虑各种类型内容的局限性和特殊性、实施成本和公认的技术水平的基础上,在相关技术标准中提供解决方案(European Union,2024)。
第三,研究者承担对科研产出的最终责任,应严格遵守科研规范,不伪造、篡改数据,以维护科研的严肃性和科学性(European Commission,2023a)。在应用生成式人工智能提升语言可读性、解释基础数据时,研究者应保持批判性思维,避免过度依赖生成式人工智能,并在论文的方法、声明处清晰标明生成式人工智能的使用过程与方法(European Commission,2023b;Rahman et al.,2023)。科研机构在充分考虑使用者的技术知识、经验、教育背景和使用环境的基础上,给予人工智能使用者相应的技术培训,提升其人工智能素养,以推动科学创新(European Commission,2023a;NIST,2023;European Union,2024)。
第四,其他行业合作伙伴共同参与人工智能治理,例如国家科技管理机构、出版集团等,共同制定并协商关于人工智能在科学研究领域应用的使用准则和指南等(中国科学技术信息研究所,2023)。
4.监管机制:法律规范与伦理框架
(1)数据保护条例
欧盟使用政策工具对数据保护响应37次,占比84.09%;其中使用强制型政策工具响应29次,占比65.91%。相对而言,美国使用政策工具响应较少,各类政策工具共响应7次,占比15.91%(见表3)。欧盟认为,建立数据保护、数据隐私,以及数据的再利用、共享和汇集的可信机制和服务,对开发高质量、数据驱动的人工智能模型至关重要(Meszaros et al.,2021;European Union,2024)。2016年,欧盟率先发布了《通用数据保护条例》,成为全球数据保护的典范。该条例在第三章中规定了数据主体的权责,包括要求对自动决策算法给出解释,在对算法决策不满意时可以选择匿名或退出等。为鼓励科学研究,《通用数据保护条件》设立了三项豁免条款:一是数据处理原则的豁免,即在采取适当的保护措施后,某项研究中的数据也可以用于与原始研究目的不同的研究项目。二是数据主体权利的有限豁免,例如,医疗领域科研人员可以长期保留患者的健康数据,即便数据主体决定撤回对研究的同意,研究人员也可以选择不删除其个人数据。三是欧盟成员国可依据实际情况制定额外的豁免规则。尽管科学研究享有一定豁免权,但在数据处理中也应遵循“合法、公平、透明”的基本原则。尤其在医学、生物医学等领域,高校或科研机构当处理涉及个体民族、健康、基因等高度敏感数据时,数据控制者与处理者必须以“公共利益或法定职权”为合法处理基础,通过目的性、必要性和利益平衡测试,采取一定技术与管理措施以保护个体隐私,确保数据处理的合法性。
(2)版权保护法律
针对人工智能生成内容的版权问题,美国使用强制型政策工具响应18次,占比58.07%;欧盟使用政策工具响应4次,占比12.90%(见表3)。根据美国版权局(US Copyright Office)发布的《版权登记指南:包含人工智能生成材料的作品》的规定,生成式人工智能输出的内容不受美国版权法保护,只有由人类的创造力所产生的作品才受版权保护(US Copyright Office,2023)。因此,如果科研成果是由生成式人工智能生成的,则不受美国版权法的保护。欧盟2020年发布的《人工智能的趋势与发展:对知识产权框架的挑战》(Trends and Developments in Artificial Intelligence:Challenges to the Intellectual Property Rights Framework)认为,现有的版权法足以灵活应对人工智能所带来的挑战,因此无需大规模调整。尽管未有明确的新法规,但EU AI Act中对人工智能供应商提出了透明性要求,规定其需在构建系统时披露所使用的受版权保护的材料。为实现这一目标,供应商可以采用高科技手段,如水印技术,来标识这些受版权保护的内容(European Union,2024)。不过,目前法律界仍在就一些具体情况进行辩论。例如,当人工智能生成的科研结果与受版权保护的作品存在相似之处,但并未构成完全复制时,这些结果是否应受到版权法的保护(NIST,2023)。
(3)道德伦理框架
欧盟相较于美国更加重视建构道德伦理框架,采用政策工具对此响应40次,占比74.07%;而美国则响应14次,占比25.93%(见表3)。欧盟发布了一系列规范道德伦理的框架指南,如《可信赖人工智能伦理指南》(2019年)、《算法的可问责和透明的治理框架》(A Governance Framework for Algorithmic Accountability and Transparency)(2019年)等,为全球范围内的人工智能伦理治理树立了典范。上述指南和框架共同构成了欧盟在人工智能技术和数据处理方面公平性法案的核心内容,旨在通过推动人工智能技术的公平、透明与可持续发展,消除信息获取的不平等现象,确保个体能够平等、普遍地获得数据和技术资源,从而有效缩小信息鸿沟,促进科学研究的公平性和多样性。2020年,欧盟推出“可信赖人工智能系统评估清单”(Assessment List for Trustworthy AI,简称ALTAI),将道德伦理框架转化为易于访问、动态更新的自评工具,用以辅助科研人员自主核查在使用生成式人工智能过程中是否充分考虑了多样性因素,如性别、残疾状况、社会与经济地位、种族及文化背景等。
五、结论与讨论
针对生成式人工智能应用于科学研究中存在的潜在风险,欧盟与美国在构建风险管理框架上形成了基本共识,但也存在一定差异。欧盟在人工智能政策中明确提出了统一且规范的指导原则,《欧盟人工智能法案》与欧盟过往的法律与政策文件保持高度一致性,包括强调构建可信赖人工智能系统、秉承以人为本的价值导向等。同时,其也注重与现有二级立法体系的协同,在数据保护、不歧视原则及性别平等等关键领域保持了高度一致,包括重视数据保护、构建公平性法案和道德伦理框架等。相比之下,美国NIST提供了更具操作性的生成式人工智能监管框架。政策制定者可以在充分考量地区政治、经济和文化的基础上,通过映射、测量、管理和治理等措施灵活应对具体情境,识别监管缺失并改进。
当前生成式人工智能的发展与应用已经超越国界,不同国家、地区间对人工智能的协同监管将成为一种趋势。2023年,国家网信办、国家发展改革委、教育部等共同制定并发布了《生成式人工智能服务管理暂行办法》(简称《办法》)。《办法》提出对生成式人工智能服务的风险进行评判,并根据其服务适用的领域进行行业部门监管。同年,国务院办公厅印发的《国务院2023年度立法工作计划》(国办发〔2023〕18号),将起草《人工智能法草案》列入国务院立法工作计划等。随后,中国签署了《布莱切利宣言》(Bletchley Declaration),强调通过国际合作,建立人工智能应用监管方法。美国和欧盟的人工智能监管政策,为我国生成式人工智能的发展带来两点重要启示:第一,我国人工智能系统供应商、科研机构以及科研人员应协同合作,共同构建一套细致且适应性强的监管框架。该框架应全面考量人工智能模型的应用目的、科研应用场景以及训练数据的敏感性等因素,据此制定详尽的风险等级划分标准与监管措施;同时可参考美国NIST的AI RMF配套工具包以及欧盟的ALTAI自查工具等,为科研人员提供易于理解且操作性强的监管工具,以确保其在科学研究过程中严格遵循道德伦理和法律规范。第二,我国在制定人工智能应用于科学研究的法律法规与政策文本时,应充分考虑政策工具与现行政策体系的协调性,注重政策工具运行的连贯与稳定性。在此过程中,还应着重关注人工智能应用中所涉及的科研数据保护、版权归属等核心议题,完善相关法律规范。
参考文献:
[1][德]伍多·库卡茨(2017).质性文本分析:方法、实践与软件使用指南[M].朱志勇,范晓慧.重庆:重庆大学出版社:34-35.
[2]高奇琦(2023).GPT技术与人文社会科学知识生产:智能时代的学者与学术研究[J].上海交通大学学报(哲学社会科学版),31(6):111-122.
[3]兰国帅,杜水莲,宋帆等(2023). 生成式人工智能教育:关键争议、促进方法与未来议题——UNESCO《生成式人工智能教育和研究应用指南》报告要点与思考[J].开放教育研究,29(6):15-26.
[4]刘宝存,苟鸣瀚(2023). ChatGPT等新一代人工智能工具对教育科研的影响及对策[J].苏州大学学报(教育科学版),11(3):54-62.
[5]王佑镁,王旦,梁炜怡等(2023).“阿拉丁神灯”还是“潘多拉魔盒”:ChatGPT教育应用的潜能与风险[J].现代远程教育研究,35(2):48-56.
[6]中国科学技术信息研究所(2023).学术出版中AIGC使用边界指南[EB/OL].[2024-01-19].https://www.istic.ac.cn/ueditor/jsp/upload/file/20230922/1695373131354098301.pdf.
[7]中华人民共和国中央人民政府(2023).生成式人工智能服务管理暂行办法[EB/OL].[2024-01-19].https://www.gov.cn/zhengce/zhengceku/202307/content_6891752.htm.
[8]Atlas, S. (2023). ChatGPT for Higher Education and Professional Development: A Guide to Conversational AI[EB/OL]. [2024-01-19]. https://digitalcommons.uri.edu/cgi/viewcontent.cgi?article=1547&context=cba_facpubs.
[9]Brown, T., Mann, B., & Ryder, N. et al. (2020). Language Models Are Few-Shot Learners[J]. Advances in Neural Information Processing Systems, 33:1877-1901.
[10]Chowdhury, H. A., & Bhattacharyya, D. K. (2018). Plagiarism: Taxonomy, Tools and Detection Techniques[EB/OL]. [2024-01-19]. https://arxiv.org/abs/1801.06323.
[11]Department of Education of Australian Government(2023). The Australian Framework for Generative Artificial Intelligence (AI) in Schools[EB/OL]. [2024-01-19]. https://www.education.gov.au/schooling/announcements/australian-framework-generative-artificial-intelligence-ai-schools.
[12]European Commission (2023a). AI in Science Harnessing the Power of AI to Accelerate Discovery and Foster Innovation[EB/OL]. [2024-01-19]. https://apre.it/wp-content/uploads/2023/12/ec_rtd_ai-in-science-pb.pdf.
[13]European Commission (2023b). Living Guidelines on the Responsible Use of Generative AI in Research[EB/OL]. [2024-01-19]. https://european-research-area.ec.europa.eu/news/living-guidelines-responsible-use-generative-ai-research-published.
[14]European Union (2024). EU AI Act[EB/OL]. [2024-07-19]. https://artificialintelligenceact.eu/the-act/.
[15]Kocoń, J., Cichecki, I., & Kaszyca, O. et al. (2023). ChatGPT: Jack of All Trades, Master of None[EB/OL]. [2024-01-19]. https://arxiv.org/abs/2302.10724.
[16]Lund, B. D., & Wang, T. (2023). Chatting About ChatGPT: How May AI and GPT Impact Academia and Libraries?[J]. Library Hi Tech News, 40(3):26-29.
[17]McDonnell, L. M., & Elmore, R. F. (1987). Getting the Job Done: Alternative Policy Instruments[J]. Educational Evaluation and Policy Analysis, 9(2):133-152.
[18]Meszaros, J., & Ho, C. H. (2021). AI Research and Data Protection: Can the Same Rules Apply for Commercial and Academic Research under the GDPR?[J]. Computer Law & Security Review, 41:105532.
[19]Miller, H. G., & Mork, P. (2013). From Data to Decisions: A Value Chain for Big Data[J]. IT Professional, 15(1):57-59.
[20]NIST (2022). Towards a Standard for Identifying and Managing Bias in Artificial Intelligence[EB/OL]. [2024-01-19].https://www.nist.gov/publications/towards-standard-identifying-and-managing-bias-artificial-intelligence.
[21]NIST (2023). Artificial Intelligence Risk Management Framework (AI RMF 1.0)[EB/OL]. [2024-01-19]. https://nvlpubs.nist.gov/nistpubs/ai/nist.ai.100-1.pdf.
[22]NIST (2024). Use Cases[EB/OL]. [2024-07-19]. https://airc.nist.gov/Usecases.
[23]Rahman, M. M., Terano, H. J., & Rahman, M. N. et al. (2023). ChatGPT and Academic Research: A Review and Recommendations Based on Practical Examples[J]. Journal of Education, Management and Development Studies, 3(1):1-12.
[24]Schwitzgebel, E., Schwitzgebel, D., & Strasser, A. (2023). Creating a Large Language Model of a Philosopher[EB/OL]. [2024-01-19]. https://arxiv.org/abs/2302.01339.
[25]Susnjak, T. (2022). ChatGPT: The End of Online Exam Integrity? [EB/OL]. [2024-01-19]. https://arxiv.org/abs/2212.09292.
[26]UNESCO (2023a). Guidance for Generative AI in Education and Research[EB/OL]. [2024-01-19]. https://www.unesco.org/en/articles/guidance-generative-ai-education-and-research.
[27]UNESCO (2023b). Generative AI and the Future of Education[EB/OL]. [2024-01-19]. https://unesdoc.unesco.org/ark:/48223/pf0000385877.
[28]US Congress (2020). National Artificial Intelligence Initiative Act of 2020[EB/OL]. [2024-01-19]. https://www.congress.gov/bill/116th-congress/house-bill/6216.
[29]US Copyright Office (2023). Copyright Registration Guidance: Works Containing Material Generated by Artificial Intelligence[EB/OL]. [2024-01-19]. https://www.copyright.gov/ai/ai_policy_guidance.pdf.
[30]Van Doorn, N. (2017). Platform Labor: On the Gendered and Racialized Exploitation of Low-Income Service Work in the“On-Demand”Economy[J].Information, Communication Society, 20(6):898-914.
[31]Van Noorden, R., & Perkel, J. M. (2023). AI and Science: What 1,600 Researchers Think[J]. Nature, 621(7980):672-675.
How to Regulate the Application of Generative Artificial Intelligence in Scientific Research:
Risks and Strategies
——Based on an Analysis of EU and U.S. AI Policies
Abstract: Generative artificial intelligence has garnered extensive attention in scientific research due to its rapid and powerful content generation capabilities, sparking discussions on how to effectively regulate its application in scientific research. In this regard, the European Union and the United States have taken the lead in initiating actions, formulating a series of AIGC policies to comprehensively regulate its research, deployment and use. Based on a two-dimensional analytical framework of policy tools and policy content, an analysis of recent EU and U.S. policies related to risk management reveals that the use of AIGC to assist scientific research may pose risks such as privacy and security concerns, dissemination of discrimination, integrity challenges and regulatory lags, etc. The EU and the U.S., while adhering to the goal oTiGCLl6/qxCReKZ/M/ta3g==f building trustworthy AI and a human-centered value orientation, have established comprehensive risk management frameworks that outline specific processes and methods for risk identification and response. They have clarified the respective rights and responsibilities of different stakeholders by promoting their participation and collaboration. Meanwhile, to ensure the implementation of regulation, the EU and the U.S. have improved the regulatory mechanism by establishing data protection regulations, copyright protection laws and ethical frameworks. In the future, China should unite different parties to construct a detailed and adaptable regulatory framework for AIGC application risks and corresponding policies and laws, ensuring that the use of AIGC in scientific research complies with ethical and legal norms.
Keywords: Generative Artificial Intelligence; Scientific Research; Risk Management Framework; Regulatory Strategies;Academic Ethics