高职院校Hive 数据仓库技术课程教学案例分析
2024-12-01宋志伟刘天宇





摘要:Hive数据仓库技术是高职院校中大数据技术相关专业的核心课程之一。为了更好地帮助学生学习、理解课程内容,在教学实践过程中汇总积累了学生在各个阶段的实操过程中存在的典型问题案例,从学生角度出发,追溯问题案例根源,为课程设计的更新优化提供参考。
关键词:Hive;数据仓库技术;高职学生;案例分析;大数据技术
中图分类号:G642 文献标识码:A
文章编号:1009-3044(2024)32-0156-03 开放科学(资源服务)标识码(OSID) :
0 引言
随着大数据时代的到来,数据仓库技术已成为企业数据存储、分析、预测的重要工具之一[1]。Hive作为一种基于Hadoop分布式系统的数据仓库工具,因其强大的海量数据处理和数据分析能力,在大数据分析领域中的热度一直居高不下,也备受企业青睐[2]。为了适应大数据技术的发展趋势,高职院校纷纷开设Hive数据仓库技术这门课程,旨在让学生理解并掌握Hive的基本原理、核心操作及其应用方法,为学生未来从事大数据相关工作打下坚实基础。相比于MySQL、SQL Server等常用数据库工具在高职院校中多年的使用基础,Hive在高职院校的引入和教学面临一些特殊的挑战和差异,尤其是Hive的教学需要包含Hadoop分布式生态的基础原理、Hive的架构、海量数据清洗、数据分析等多个方面的内容,相对于传统关系型数据库更加复杂和深入。本文基于高职学生的学习特点,针对Hive数据仓库技术在实际教学实践过程中出现的典型问题案例,进行分析讨论,帮助学生更好地理解和掌握Hive 数据仓库技术,提升专业水平。
1 问题案例分析
在高等职业教育中,Hive数据仓库技术课程应基于高职学生的实际需求、未来职业发展的导向以及教学过程中的有效性。在教学过程中,需紧密贴合实际应用,强调Hive在实际项目开发中的应用和操作[3],避免过于理论化或脱离实际的教学内容,确保学生能够学以致用。以下分别从Hive的环境配置、Hive的部署、数据库与数据表的定义、查询、自定义函数、优化等6个教学内容进行典型问题案例展示,通过分析学生在实践中所出现的共性问题,动态优化课程设计、更新教学方法。
1.1 Hive 环境配置问题案例
Hive是建立在Hadoop之上的数据仓库工具,利用Hadoop 的分布式存储和计算能力来处理海量数据。因此,Hive的环境配置需要严格遵守Hadoop生态模型[4]。对于初学者来说,Hadoop的安装和配置具有一定挑战性,需要提前学习实践,夯实基础。下面列举Hive在安装配置中的常见问题。
(1) 虚拟机的网络配置。Hadoop 的部署需要在Linux系统运行,因此需要提前准备虚拟机,课程中采用VMware软件作为虚拟机的载体。部分学生在配置虚拟机的过程中,无法在虚拟机中联网,这是虚拟机的网络配置错误导致。正确的做法应该是网络适配器设置中选择NAT模式,依次填写子网IP、子网掩码和网关IP,保存设置后即可联网,在虚拟机中输入“ping www.baidu.com”,若显示如图1中的结果,则表示联网成功。
(2) 虚拟机的克隆与时间同步。Hadoop完全分布式集群至少需要三台虚拟机,因此,需要对虚拟机进行底层克隆操作,构建三台虚拟机。很多学生在克隆虚拟机的过程中,没有同步时间,导致集群存在数据不一致、任务调度等问题。可分别在三台虚拟机中执行“ntpdate ntp4.aliyun.com”命令,同步集群时间,保持集群中节点的一致性。
(3) JDK的安装。Hadoop集群需要Java环境来运行,若没有在Liunx中安装Java环境,则无法部署Ha⁃doop集群。少部分学生因忘记安装JDK,导致Hadoop 集群启动失败。正确做法是从Java官网中下载JDK 安装包,在Linux环境中完成安装,并配置环境变量。
在三台虚拟机中输入代码“java -version”,若出现如图2中的Java版本,则JDK配置成功。
(4) HDFS的初始化。在第一次使用Hadoop集群之前,需要对Hadoop中的HDFS组件进行初始化,以创建Hadoop集群中必要的目录结构和配置信息。有学生没有进行初始化就开启Hadoop,终端中提示系统错误,无法开启集群。还有学生在HDFS集群开启的情况下进行初始化操作,导致数据丢失或损坏。正确做法应该如下所示:
① 找到Hadoop 安装路径中的bin 目录,并进行定位。
② 确保当前Hadoop集群处于关闭的基础上,在bin目录下,执行命令“HDFS namenode -format”,此命令会格式化HDFS的名称节点(NameNode) ,清空已存在的HDFS数据。
③ 在HDFS 名称节点格式化完成后,执行命令“start-all.sh”,启动Hadoop进程。
需要注意的是,少部分学生对Hadoop分布式技术使用不熟练,导致Hive环境配置任务进程缓慢,对于此类学生,需要积极关注,引导其“笨鸟先飞”,打好良好的学习基础。Hive的执行过程需要在Hadoop生态的基础上进行,若学生没有吃透Hadoop的基本原理,后续的实践学习将举步维艰。
1.2 Hive 部署问题案例
(1) Hive启动失败。有许多学生在严格执行Hive 环境配置流程后仍无法启动Hive,检查其虚拟机后,发现Hadoop集群尚未启动。因Hive的运行必须基于Hadoop生态,因此需要在执行Hive之前部署Hadoop 集群。在虚拟机中输入“start-all.sh”命令开启Hadoop 集群中的HDFS组件与yarn组件。以主节点为例,若出现如图3中的组件信息,则此时可顺利启动Hive。
(2) 防火墙影响Hive正常启动。少数学生在启动Hive时,明明之前能够成功使用,突然启动失败。究其原因,发现是虚拟机防火墙的拦截所致。在启动Hive之前,要确保Hive所在的服务器或Hadoop集群的防火墙允许设置Hive运行所需通信,可以通过打开特定的端口(如HiveServer2的端口)以允许远程连接。同时,也需要保证Hive能够与其他系统进行通信,如Hadoop集群、MySQL数据库等,防止因连接受阻导致Hive无法正常启动。
(3) 元数据问题。Hive使用元数据服务(metastore) 来存储数据库、数据表等元数据信息。若metastore服务未正确配置或启动,可能导致Hive无法正常工作。目前hive中自带的metastore为derby,但derby并不稳定,因此许多学生在使用过程中,常常出现hive崩溃的情况。通常的解决方法是,将Hive自带的derby数据库,更换为更加稳定的MySQL,利用MySQL的高可用性与高拓展性,可以确保数据的完整性和一致性。
1.3 Hive 数据库与数据表的定义问题案例
Hive 中定义了简单的类SQL 查询语言,称为HQL,它允许熟悉SQL的用户查询Hive中的数据。因HQL语句与SQL语句在语法上较为类似,因此学生在MySQL的学习基础上,能够较快上手。但Hive的执行需要在Hadoop集群上将任务转化为mapreduce作业,和传统关系型数据库存在较大差异,因此在Hive中构建数据库、数据表也存在着一些新的问题,下面进行列举。
(1) 语法差异问题。HQL和SQL在语法上存在一些区别,许多学生习惯使用SQL语句查询数据库,将其硬套入HQL中,运行代码提示报错。在课程实践过程中,整理学生所出现的此类问题,主要有以下几个方面:
① 查询对象不同。在SQL语句中,查询的是数据库中的表和表中的列;而在HQL语句中,所查询的是对象与对象中的属性。
② 关键词大小写敏感性。SQL语句对大小写不敏感,因此在书写过程中表名、字段名、关键词可以自由组合;而HQL语句虽然对关键词不敏感,但类名、属性名需要区分大小写。
③ 语法结构差异。在SQL语句中,FROM后面跟着的是表名,WHERE后面接的是表中的条件查询;而在HQL语句中,FROM 后跟的是类名+类的对象,而WHERE后面用对象的属性作为条件。
根据上述典型问题,需要反复做针对性的实践练习,让学生在编码中理解SQL和HQL的语法差异内容,减少类似错误的发生。
(2) 注释乱码问题。注释属于Hive元数据的一部分,存放在Hive的metastore库(一般是MySQL) 中,如果metastore库中的字符集不支持中文,就会导致Hive 的中文显示乱码。解决此问题,需要确保修改metas⁃tore库的字符集为UTF-8,同时确保URL所连接的编码也指定为UTF-8。
1.4 Hive 查询操作问题案例
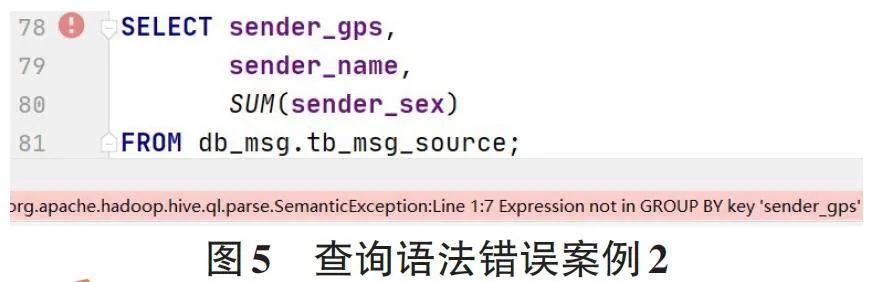
(1) 查询语法错误。语法错误是学生在Hive学习过程中最常见的问题。如图4所示,一位学生在使用select语句查询多个字段时,在最后一个字段后多写了一个逗号,造成代码运行提示报错。如图5所示,一位学生在使用SUM()聚合函数时,没有在GROUP BY 子句中指定此列,造成代码运行提示报错,正确做法是在字段后加上GROUP BY字句,并选择需要聚合指定的列。
(2) 查询速度缓慢。有多位学生在查询过程中产生疑问,Hive作为海量数据的处理分析工具,其查询速度并不快,甚至部分语句查询效率低于MySQL。要搞清楚这个问题的解决方案,首先需要熟悉Hive查询的基本原理。Hive查询的基本原理是将HQL查询转换为mapreduce任务,并在Hadoop集群上并行执行。mapreduce在执行过程中存在map切片和reduce合并两个阶段,需要花费一定时间,因此Hive主要用于海量数据的离线分析,在线查询分析速度偏慢。如果要改善Hive查询的速度,可以采用DISTRIBUTE BY和CLUSTER BY分组查询语句,通过将数据均匀分布到不同的Reducer中,以减少因数据倾斜带来的影响。
1.5 Hive 自定义函数问题案例
Hive 自定义函数(UDF, User-Defined Functions) 允许用户独立扩展 Hive 的 SQL 功能,通过编写具有指向性作用的函数来处理数据。UDF 可以用于数据格式转换、字符串操作、数理计算等场景。由于MySQL中并没有直接内置UDF的概念,对于学生来说UDF是一个全新的知识点,因此许多学生在UDF的实际操作过程中出现较多问题,下面进行典型问题案例的分析:
(1) 函数定义错误。许多学生在进行UDF的定义时,所起函数名称与已有的函数冲突,或者函数参数的类型定义发生错误,如有学生定义一个具有计算功能的UDF,起名为SUM(),因SUM()函数已经是Hive当中的内置函数,因此在定义时发生错误,如图6所示。正确做法是在定义UDF时,选择一个与已有函数不冲突的名称。需要注意的是,在Hive中,函数的名称是不区分大小写的,所以禁止通过更改大小写的方式规避已有的内置函数名。
(2) JAR包管理问题。UDF的定义在Java中进行,完成定义后,需要将 Java 代码编译成一个 JAR 文件,可以通过使用Maven、Gradle 等其他构建工具来完成打包任务,以确保 在JAR 文件中包含必要的依赖项。许多学生在操作过程中省略了此步骤,导致函数无法被定义及调用。因此,在Hive中使用UDF之前,必须确保所有依赖的库或JAR包都已成功添加至Hive的类路径中。
(3) 版本兼容性问题。如果UDF与当前Hive版本的API或行为不兼容,也无法使用UDF。如果是UDF 依赖的库版本与当前系统安装的库版本发生冲突,导致UDF无法正常运行,解决方法是使用pip、conda或相应的包管理工具更新或降级依赖库到与UDF所兼容的版本,或在UDF的代码中去指定一个依赖库的版本,确保在不同环境中都能使用正确版本的库。如果是Hive 运行环境不兼容,特别是在定义UDF时指定了某一个Hive的版本,需要升级或降级运行环境到与UDF兼容的版本。若无法更改当前的运行环境版本,则尝试修改UDF代码以适应当前Hive版本的运行环境。
1.6 Hive 优化问题案例
相比于传统MySQL对于CPU、内存和磁盘I/O的利用特点的优化,Hive的优化既包含Hive在建表的设计过程,对HQL语句自身的优化,同时也包含Hive的配置参数和Hadoop生态中底层引擎mapReduce方面的调整[5]。这通常涉及mapReduce作业的初始化、数据倾斜问题的解决以及合理的分区与分桶策略等。这一块内容是Hive学习的难点,也是大部分学生在学习过程中的共性问题,下面对学生在实操过程中的普遍问题进行讲解。
(1) 数据倾斜问题。数据倾斜是Hive执行中最常见的性能问题,它指的是某个Reduce任务处理的数据量远远超过其他任务,导致在作业执行过程中其他任务必须等待最大数据量任务结束后,才能顺利完成作业。学生在执行真实项目时,因数据样本过多,加上对数据内容不敏感,常常会导致数据倾斜问题,浪费大量运行时间。数据倾斜可能由key分布不均匀、null 值过多等原因导致。针对Hive中产生的数据倾斜问题,可以采取如下优化策略:
① 数据预分区。根据key的分布情况对整个数据进行预分区,使得相同key的数据尽可能分布在同一节点上,从而减少跨节点数据的开销。
② 空值处理。对于null值过多引起的数据倾斜问题,可以通过在查询数据之前,对数据进行预处理工作。通过将null值替换为某个特定值(如统一定义一个不存在的值),或者在查询过程中就将包含空值的记录过滤掉。
③ Salting技术。对于倾斜比较严重的key,可以在数据中添加上随机数前缀(也称为salting) ,让原本倾斜的key分散到不同的reduce任务当中。在reduce 阶段中再删除这些随机数前缀,保持各任务中数据的分散性。
(2) 处理小文件问题。Hive在处理大量小文件数据时,由于每个小文件都需要一个Map任务,因此会消耗大量mapreduce的资源。许多学生在操作过程中忽略了小文件数据,直接调用mapreduce任务,造成任务效率低下。此问题的优化策略是当目标数据写入Hive 之前,通过Hadoop 集群中的CombineFileInput⁃Format或者Hive中的merge()函数将小文件合并成大文件。
(3) Map和Reduce的任务数量问题。因Hive的任务执行是依靠maprecude引擎,map和Reduce任务数的设置会直接影响Hive作业的执行效率。如果任务数设置不合理,会导致系统资源浪费或性能下降。大部分学生在运行任务时,忽略此问题,常常导致在Map阶段花费大量的时间进行任务划分,影响整体效率。正确的优化策略是根据待处理数据的量合理设定任务数,确保每个Map任务处理的数据量适中(每一个Map中的数据尽量不超过128M) 。
以上只是授课过程中常见的一些问题案例及其优化策略,实际上Hive的优化是一个复杂的过程,需要具体问题具体分析,根据具体的业务场景和目标数据的特点进行优化和调整。
2 结论
Hive数据仓库技术是实践性、创新性很强的一门课程,课程内容较为新颖,融合liunx系统、Hadoop集群等多门课程,需要教师合理地安排教学内容、聚焦重难知识点。高职学生的基础较为薄弱,但学习热情较高,能够以饱满的热情投入项目的开发过程中。然而,一旦遇到如上述问题,部分学生会产生挫败感,知难而退,降低学习的热情。还有少部分学生会钻牛角尖,卡在某一个子任务中停滞不前,效率低下。因此对于Hive数据仓库技术的教学,需要及时跟进学生在实践过程中出现的各类问题,及时分析总结学生的共性问题案例,优化课程设计与教学方法。本文分别从Hive的环境配置、Hive的部署、数据库与数据表的定义、查询、自定义函数、优化等6个教学部分中出现的典型问题进行了总结,为Hive数据仓库技术这门课的教学内容、教学方法的有效改进提供思路。
参考文献:
[1] 刘强. 试论数据仓库与大数据融合[J]. 电脑知识与技术,2020,16(10):7-9.
[2] 王科《. 实战HADOOP》课程教学改革与探索[J].电脑知识与技术,2020,16(16):147-148.
[3] 云桂桂,杜彬,刘淑梅.三全育人背景下师生数据仓库建设研究与实践[J].中国管理信息化,2023,26(1):180-184.
[4] 张黎平,段淑萍,俞占仓.基于Hadoop的大数据处理平台设计与实现[J].电子测试,2022(20):74-75,83.
[5] 荆忠航,张伟,王佳慧,等.面向Hive查询的存储优化技术[J]. 北京信息科技大学学报(自然科学版),2021,36(6):93-100.
【通联编辑:王力】
基金项目:2023 年度江苏省教育科学规划课题(重点课题)“高职院校SPOC 教学评价体系构建研究”(课题编号:B/2023/02/114)
