基于YOLOv5s 的PCB 板缺陷检测与实践教学评分系统的应用设计与实现
2024-12-01王竟羽郭斌








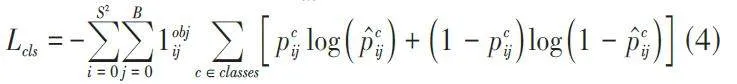



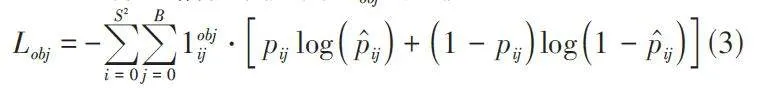


摘要:PCB板缺陷检测是实践教学评分系统中的重要环节。为了减轻教师在PCB检测与评分过程中的工作负担,提高教学质量和效率,文章对现有检测模型进行了改进。针对YOLOv5s模型在PCB板缺陷检测中存在的通道和空间信息提取不足问题,文章增加了CBAM注意力机制,并使用SlideLoss损失函数。改进后的模型相较原始模型,准确率提升了7.17%,平均召回率提升了4.38%。文章利用全栈Web开发的技术组合进行用户交互、数据存储和管理,使用改进后的YOLOv5s模型进行缺陷自动检测,实现了自动化评分。该系统减少了教师的重复性工作,提高了检测的准确性和效率,学生能够获得及时的反馈,使教师能够更专注于教学和研究。
关键词:YOLOv5s算法;CBAM注意力机制;教学应用;SlideLoss损失函数
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2024)32-0129-07 开放科学(资源服务)标识码(OSID) :
0 引言
随着电子信息技术的飞速发展,印刷电路板(Printed Circuit Board,PCB) 作为电子产品的关键组成部分,其质量直接影响产品的可靠性与稳定性。PCB 上的缺陷不仅会导致电子产品性能下降,甚至可能引发安全隐患。PCB缺陷检测对于保障电子产品质量至关重要。然而,传统的人工检测方法效率低下、容易出错,无法满足大规模生产的需求[1]。近年来,随着集成电路和半导体技术的快速发展,PCB结构愈加复杂、小巧和精致,对其缺陷检测的要求也相应提高[2]。
传统的PCB缺陷检测方法主要依赖于图像处理技术和人工目视检查。Ismail I等[3]提出了基于图像加减法的集成图像处理技术,Melnyk等[4]提出了基于Kmeans聚类的图像比较方法,这些方法在一定程度上提高了检测的精度和速度,但仍然存在着灵敏度和特异性平衡难、实际应用受限等问题。此外,支持向量机(SVM) [5]和神经网络(NN) [6]等机器学习算法也被应用于PCB缺陷检测领域,进一步提升了检测效果。然而,随着深度学习的发展,卷积神经网络(CNN) 等方法在图像处理中的表现尤为突出,Ding等[7]提出的TDDnet和Hu等[8]提出的改进Faster R-CNN和FPN模型,展示了深度学习在提高检测精度方面的显著潜力。尽管如此,这些方法在实现高精度的同时,往往以牺牲检测速度为代价。
在此背景下,开发高效的PCB板缺陷检测系统具有重要的意义,尤其是在电子信息等专业教育中,PCB板焊接是学生必须掌握的一项核心技能。然而,在传统的实训教学中,教师手动检查学生的PCB板,不仅耗时且容易出错。随着学生数量的增加,教师的工作量随之增加,影响了教学质量。因此,开发一个高效、准确的PCB板缺陷检测系统对于减轻教师负担、提高教学质量具有重要意义。本文设计并实现了一种基于YOLOv5s的PCB板缺陷检测系统,该系统通过集成CBAM注意力机制和SlideLoss损失函数,显著提高了检测的精确度和召回率。此外,系统具备自动化评分、实时反馈、数据驱动教学改进等功能,有效提高了教学效率和质量。该系统不仅有助于提升实训教学质量,还为我国电子信息产业的人才培养提供了支持,推动了行业的良性发展。
1 YOLOv5s 模型
YOLO(You Only Look Once) 是一种革命性的目标检测算法,以其卓越的检测速度和准确性在实时目标检测领域占据重要地位。YOLO的核心优势在于其全卷积网络设计和端到端的处理流程,这使得它能够一次性处理整个图像,而无须依赖复杂的候选区域提取过程。YOLO的设计目标是在单张图像中快速、准确地检测并定位多个目标物体。与传统的基于候选区域(如R-CNN) 方法不同,YOLO通过将输入图像划分为固定数量的网格,每个网格负责预测其内部是否包含目标物体。当物体的中心位于某个网格时,该网格负责输出该物体的类别和边界框位置,从而实现高效的端到端检测。这种方法将候选区域生成和目标分类两个任务合并在一个网络中,大幅度提高了检测速度。通过非极大值抑制(NMS) 处理,YOLO能够同时预测多个边界框及其类别概率,从而实现速度与精度的平衡。
YOLOv5s的模型架构通过精心设计,实现了高效的目标检测能力。其结构主要由三大部分构成:骨干网络(Backbone) 、颈部网络(Neck) 和头部网络(Head) 。
首先,骨干网络(Backbone) 是图像特征提取的核心。图1左侧的蓝色模块代表Focus模块,该模块通过对输入图像的切片和拼接操作,将图像的通道数从3个(RGB) 扩展为更多通道,从而有效压缩数据量并提高计算效率。接下来,绿色的卷积层(Conv) 和黄色的C3模块通过多次卷积操作进一步提取图像的深层特征。其中,C3模块采用了残差连接(类似ResNet的结构),使得网络能够捕捉更复杂和多样化的特征。红色的SPP模块(空间金字塔池化)通过多尺度的池化操作,增加了对不同尺度目标物体的检测能力,使模型对物体的大小、位置和形状具有更高的鲁棒性。
接着,颈部网络(Neck) 负责特征融合,图1中紫色和黄色模块分别表示上采样层(Upsample) 和拼接层(Concat) 。上采样层将低分辨率特征图放大,并与来自骨干网络的高分辨率特征图拼接在一起,从而融合不同尺度的信息。这样,模型在处理大目标和小目标时都能利用这些不同层次的特征进行更有效的检测。通过这种自底向上和自顶向下的特征融合路径,增强了模型对多尺度目标的适应性,进而提高了整体检测性能。颈部网络还采用了CSP2_X结构(图中未标明)来进一步增强特征融合的能力。
最后,头部网络(Head) 负责最终的目标检测。图1底部的三个Detect 模块对应三个不同的尺度输出(小、中、大),分别对不同尺寸的目标进行检测。这种多尺度检测机制确保了YOLOv5s在处理复杂场景时,能够同时检测到大物体和小物体。每个尺度的检测模块都通过卷积层提取特征,并根据特定大小的目标调整输出权重,以便在总损失函数中提供适当的贡献。
在YOLOv5s中,损失函数的设计对于算法的准确性和鲁棒性至关重要。损失函数主要由三部分组成,每部分都针对不同的预测任务进行优化。
首先,边界框回归损失(Bounding Box RegressionLoss) 是评估预测边界框与真实边界框差异的关键指标。YOLOv5s采用了CIOU损失(Complete Intersectionover Union Loss) ,这是一种先进的边界框回归损失计算方法。CIOU损失不仅考虑了预测框与真实框的交集面积,还综合了框的中心点距离、宽高比以及重叠区域的形状,从而更全面地评估边界框的准确性。其次,置信度损失(Confidence Loss) 用于评估模型对目标存在的置信度预测。该部分损失通过二元交叉熵损失(Binary CrossEntropy Loss) 来实现,目的是确保模型能够正确识别预测框中实际包含的物体。通过引入该损失,提高了模型在目标存在性预测上的准确性。最后,类别分类损失(Classification Loss) 负责评估预测类别与真实类别之间的差异,采用了多分类交叉熵损失(Multiclass CrossEntropy Loss) ,对每个目标的类别预测进行评估,确保类别预测的准确性和多样性。在YOLOv5s中,这三种损失加权求和,构成最终的总损失函数。具体公式如下所示:
Itotal = λbox ⋅ Lbox + λobj ⋅ Lobj + λcls ⋅ Lcls (1)
总损失是三个主要部分的加权和:边界框损失 Lbox、目标置信度损失 Lobj 和类别分类损失Lcls。每个部分都有一个相应的权重系数 λ,用于平衡各个损失项的贡献。
边界框损失为 Lbox 公式如下:
Lbox = 1 - CIoU (b ) pred,btrue (2)
这部分使用CIOU(Complete Intersection over Union) 损失。公式中,bpred 是预测的边界框,btrue 是真实的边界框。CIOU不仅考虑了IoU(交并比),还考虑了中心点距离、宽高比和重叠区域的形状。1减去CIOU值作为损失,使得CIOU值越高,损失越小。
目标置信度损失为 Lobj公式如下:
S2 是特征图的大小(假设是正方形);B 是每个网格单元预测的边界框数量1objij 是一个指示函数,当第i个网格的第j 个边界框负责预测目标时为1,否则为0;pc ij是真实的置信度得分;p̂cij是预测的置信度得分。
类别分类损失为Lcls公式如下:
这是一个多类别交叉熵损失,用于评估类别预测的准确性。符号含义与置信度损失相同 ;c 遍历所有可能的类别;pc ij 是类别c的真实概率;p̂cij 是类别c的预测概率。
2 YOLOv5s 算法改进
2.1 CBAM 模块
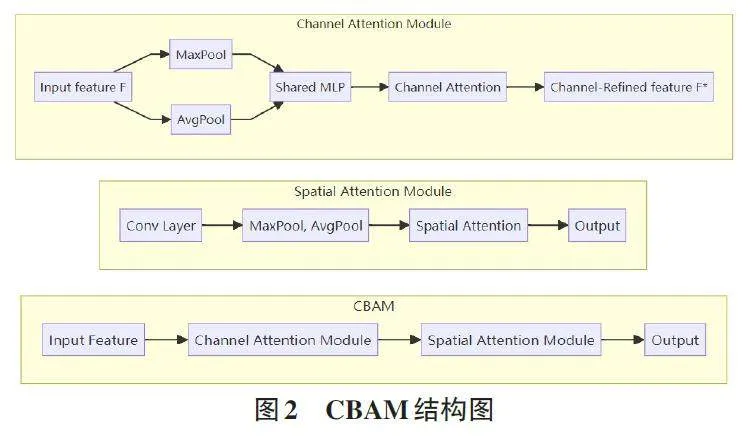
CBAM模块是一种轻量级的混合域注意力模块,该模块的作用是通过学习通道和空间特征之间的相互关系来提高网络模型的性能[9]。在该模块中同时集成了通道注意力模块(Channel Attention Module,CAM) 和空间注意力模块(Spatial Attention Module,SAM) 。
CBAM模块的结构如图2所示,分为通道注意力模块(CAM) 和空间注意力模块(SAM) 两部分。通道注意力模块(Channel Attention Module,CAM) 通过全局最大池化(MaxPool) 和全局平均池化(AvgPool) ,分别从输入特征中提取不同的全局特征。随后,这两个池化操作生成的特征通过一个共享的多层感知器(Shared MLP) 进行处理,输出的特征相加并经过Sig⁃moid激活函数生成通道注意力权重。最后,这些注意力权重与输入特征逐元素相乘,生成加权后的通道特征(Channel-Refined feature F) 。这种方式有助于网络关注图像中特定通道的重要性,提升网络性能。空间注意力模块(Spatial Attention Module,SAM) 首先通过一个卷积层提取初步的空间特征。接下来,对这些特征进行通道维度的最大池化和平均池化,生成两个不同的特征图。然后,将这两个特征图沿通道维度拼接,再通过一个卷积层生成空间注意力图。最终,这个空间注意力图与输入特征相乘,生成加权后的输出特征图。这一模块帮助网络更好地关注图像中特定空间位置上的重要信息,从而进一步提升网络的表现。CBAM模块整体流程:首先,对输入特征图进行通道注意力操作,生成加权后的通道特征图;然后,再对该特征图进行空间注意力处理,以增强对重要空间位置的关注。通过这种方式,CBAM能够在通道和空间两个维度上优化网络的特征表达能力,从而提升检测的精度。CBAM模块的核心作用是通过分别在通道和空间维度进行注意力加权,提升网络对关键信息的感知能力。这种双重注意力机制能够有效提高模型在目标检测任务中的表现,尤其在处理复杂场景时,CBAM能够帮助网络更准确地识别和定位重要特征。
原始YOLOv5s模型虽然速度快,但在处理小目标和复杂场景时,模型对细节的捕捉能力有限。引入CBAM模块后,可以增强模型对关键信息的注意力,帮助其更好地区分目标和背景,从而提升检测精度。CBAM还能提高模型在有噪声或光照变化等复杂条件下的表现,使网络更具鲁棒性。改进算法网络结构如图3所示,在保持原始结构的基础上,引入了CBAM 模块。在骨干网络中将SPP后的C3替换为CBAM,在颈部网络中的每个卷积层(Conv) 之后增加了CBAM模块,使得特征图在进行上采样和拼接之前先经过CBAM模块的处理。通过在颈部网络部分的卷积层后添加CBAM 模块,提升了模型对重要特征的关注度。这种改进可以在不显著增加计算量和检测时间的情况下,增强模型对重要特征的关注度,提高检测精度,尤其是在处理图像模糊和小目标检测方面表现明显。
2.2 SlideLoss 损失函数
SlideLoss损失函数是一种创新的损失函数,通过替换传统损失函数可以提高目标检测模型的性能[10]。SlideLoss损失函数相比传统损失函数,在多个方面展现了显著优势。其自适应权重机制能够动态调整难以检测目标的权重,提升对模糊和边界不清晰目标的处理能力,尤其在复杂场景中表现出色。通过引入平滑机制,SlideLoss在处理接近边界的目标时减少了过拟合风险,增强了模型的稳定性。该损失函数能够根据样本难度自适应调整损失值,使模型更加关注难样本,从而提升整体检测性能,尤其是在小目标检测中显著提升了精度并减少了漏检。此外,SlideLoss在光线变化和图像模糊等不利条件下表现出较强的鲁棒性,有效提高了模型的稳定性和可靠性。
SlideLoss是将基础损失和平滑损失结合,并通过自适应权重机制调整样本的贡献,其公式为:
α 和β 分别是基础损失和平滑损失的权重参数,用于平衡两者的影响。wi = 1/1 + e-γ(gi - τ) 是样本i 的自适应权重,使得难检测样本在总损失中的贡献更大。1/1 + e-γ(gi - τ) 是一个Sigmoid函数,用于将样本的难度估计值gi 映射到权重wi。gi 是样本的难度估计值,可以基于IoU或损失值来确定。γ 控制权重的变化速率,调整γ 可以改变权重分布的陡峭程度。τ 是难度阈值,样本难度超过阈值时,权重迅速增加。SlideLoss 通过综合考虑分类、定位和稳定性,并对难样本给予更多关注,有效提升了模型在各种检测任务中的整体性能。将实现提高检测精度,特别是在检测小目标缺陷时,SlideLoss能够显著提升模型的精度;减少漏检测,通过自适应机制,提高对难以检测目标的关注度,减少漏检测的情况,增强鲁棒性,在光线不稳定和图像模糊的情况下,SlideLoss能够提升模型的稳定性和鲁棒性。
3 实验准备
3.1 数据集构建
本文使用的数据集基于北京大学智能机器人开放实验室公开发布的印刷电路板缺陷数据集,包含693张图像,涵盖6种不同类型的缺陷,分别是漏孔(Missing_hole) 、鼠咬(mouse_bite) 、开路(open_circuit) 、短路(short) 、余铜(spurious_copper) 和毛刺(spur) 。
为了增强模型的泛化能力和鲁棒性,本文引入了运动模糊等图像增强技术,对每张图像进行处理,使数据集的规模从原始的693张扩展到1386张。通过对图像进行增强处理,不仅增加了数据的多样性,还能够使模型更好地适应实际应用中可能遇到的多种变化情况,如光照条件的变化、拍摄角度的不同以及目标位置的偏移。这种图像增强技术通过扩展训练数据的规模,有效提高了模型在不同环境下的检测鲁棒性和准确性,从而确保系统在实际应用中的稳定性和可靠性。
3.2 实验环境
本文实验均在Windows平台下运行,使用Python 语言,调用PyTorch库进行网络搭建、调试、训练与测试。实验在一台配备Intel Core i7-11800H处理器和NVIDIA GeForce RTX 3060(130W,6GB) 显卡的电脑上进行。
3.3 模型评估
为了评估模型的性能,本文使用目标检测领域常用的评价指标:准确率(Precision) 、召回率(Recall) 、F1 值(F1 Score) 和平均精度(mAP) 。具体公式如下所示:
准确率(Precision) :定义为正确检测到的目标数量与实际检测到的目标数量之比,公式为:
Precision = TP/TP + FP (6)
式中:TP(True Positive) 是正确检测的正样本数,FP(False Positive) 是误检测的样本数。
召回率(Recall) :定义为正确检测到的目标数量与真实目标数量之比,公式为:
Recall = TP/TP + FN (7)
式中:FN(False Negative) 是漏检测的样本数。
F1值(F1 Score) :F1值是准确率和召回率的调和平均数,综合了两者的优缺点,公式为:
F1 = 2 ⋅ Precision Recall/Precision + Recall (8)
平均召回率(mAP) 是目标检测评估中最常用的指标,用于计算所有类别的平均精度。对每个类别计算平均精度AP(Average Precision) ,AP是召回率从0到1 的情况下,精度的平均值。计算AP采用11点插值法,通过在固定的11个召回率点上计算精度的最大值,然后取这些值的平均值来估算Precision-Recall曲线下的面积,从而得到AP。计算AP的公式为:
这种方法简化了计算,同时提供了对模型性能的合理估计。mAP是所有类别的AP的平均值。故此推导出mAP 的公式为:
4 实验结果分析
4.1 模型对比
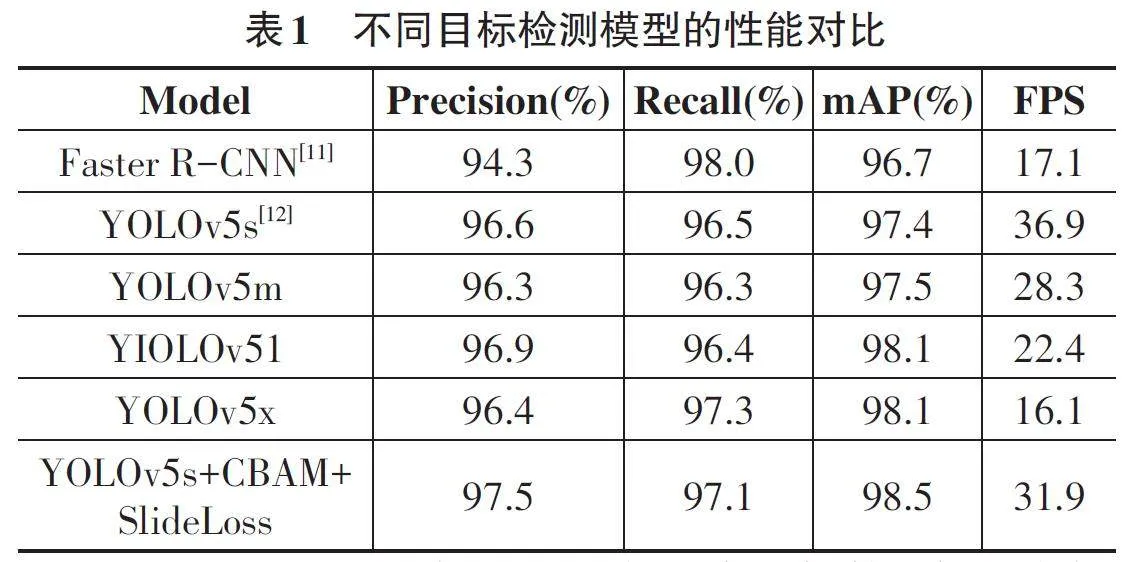
表1展示了六种不同目标检测方法的对比数据,包括Faster RCNN、YOLOv5s、YOLOv5m、YOLOv51、YOLOv5x 以及改进后的YOLOv5s+CBAM+SlideLoss。每种方法在精度(Precision) 、召回率(Recall) 、平均精度(mAP) 和每秒帧数(FPS) 四个指标上的表现如下:
Faster R-CNN采用了两阶段检测架构,先生成候选区域再分类定位,因此召回率高(98.0%) ,但由于计算复杂度大,推理速度慢(FPS为17.1) ,不适合对实时性要求较高的应用。其精度(94.3%) 和mAP(96.7%) 略低,这表明尽管在召回率方面表现出色,但在精度上有所欠缺。YOLO系列模型采用单阶段检测架构,在一次前向传播中完成检测和分类,极大提升了速度。YOLOv5s 由于模型较小,推理速度最快(FPS 为36.9) ,适合对实时性要求高的应用场景,但其特征提取能力较弱,因此精度(96.6%) 和mAP(97.4%) 略低于更复杂的YOLOv5l 和YOLOv5x。YOLOv5m 在精度(96.3%) 、召回率(96.3%) 和mAP(97.5%) 上表现均衡,速度适中(FPS为28.3) ,适合对精度和速度均有要求的场景。YOLOv5l通过增加模型深度和宽度提升了特征提取能力,精度(96.9%) 和mAP(98.1%) 较高,但推理速度(FPS为22.4) 较慢,适合对检测精度要求高的场景。YOLOv5x 的精度(96.4%) 和召回率(97.3%) 表现出色,mAP达到98.1%,但推理速度最慢(FPS为16.1) ,虽然适合处理复杂背景和小目标,但不适合实时检测任务。改进后的YOLOv5s+CBAM+SlideLoss引入了CBAM注意力机制和SlideLoss损失函数,提升了模型对关键区域的关注,显著提高了精度(97.5%) 、召回率(97.1%) 和mAP(98.5%) ,尤其在处理图像模糊和小目标检测时表现突出。虽然FPS为31.9,不及YO⁃LOv5s,但在需要高精度检测的场景中表现最佳。总体来看,YOLOv5s+CBAM+SlideLoss在精度、召回率和mAP方面均优于其他模型,特别适用于需要高检测精度和处理复杂图像场景的应用。YOLOv5s由于其最高的FPS,适合对实时性要求较高的应用场景,而Faster R-CNN和YOLOv5x虽然在某些指标上表现较好,但综合性能和实时性不如YOLOv5系列。综上所述,YOLOv5s+CBAM+SlideLoss 提供了最佳的检测性能,是高精度和复杂环境下目标检测的理想选择。
4.2 消融实验
为了评估改进后的YOLOv5s模型在教学端PCB 检测中的效果,本文进行了四次消融实验。这些实验使用经过运动图像模糊处理的数据集,以突出不同模型在处理模糊图像和小目标检测中的性能差异。具体实验数据如表2所示。
根据实验结果,YOLOv5s原始模型在目标检测任务中的准确率为0.895 5,显示其在目标检测分类任务中具备较高的精确性。然而,尽管F1值达到0.914 3,表明模型在正负样本不均衡的情况下综合性能较好,但在召回率和准确率之间的平衡仍有改进空间。与原始模型相比,加入CBAM 模块的YOLOv5s(YO⁃LOv5s+CBAM) 模型的准确率提升至0.934 9,F1值显著提升至0.940 9,表明CBAM增强了模型在正负样本不均衡问题上的综合表现,尤其是在对重要特征的关注上提高了模型的整体检测效果。当将损失函数替换为SlideLoss 后,YOLOv5s 模型的准确率提升至0.906 6,F1 值上升至0.928 0,mAP 显著提升至0.964 9。这表明SlideLoss通过平滑和自适应机制改善了模型在处理小目标和模糊图像方面的性能,减少了漏检的情况。SlideLoss在处理更复杂的样本分布和难度不同的目标检测时表现出更高的鲁棒性和精度。结合CBAM 模块和SlideLoss 损失函数的YO⁃LOv5s改进模型表现最佳,准确率达到0.964 7,召回率为0.972,F1值为0.968 3,mAP提升至0.981 7。这说明该改进模型在所有评估指标上表现出色,尤其在处理模糊图像和小目标检测任务时展现了卓越的能力。这些结果进一步证明CBAM和SlideLoss的结合在提高模型检测性能方面具有显著的效果和鲁棒性。
5 系统设计
5.1 系统架构
系统采用Django 框架的MVC(Model-View-Controller) 模式,前端负责页面展示和用户交互,后端负责业务逻辑和数据处理,模型层负责数据存储和管理。同时,利用改进后的YOLOv5s深度学习模型,实现PCB板缺陷的自动检测。数据库设计方面,结合Django的ORM特性,定义了多个模型来存储用户、图片和检测结果等信息。整个系统采用模块化设计,具有良好的可扩展性和可维护性。
基于YOLOv5s的自动化PCB检测系统的设计包括前端、后端和算法模型三个主要部分。前端主要负责用户界面的设计与实现,后端负责数据的存储和处理,算法模型负责PCB板的缺陷检测。
1) 前端设计:系统使用了HTML、CSS和JavaScript 来构建用户界面,采用了Bootstrap等CSS框架,确保页面在不同设备和浏览器上的兼容性。使用Django 的模板引擎,将后端数据渲染到HTML页面中,模板中使用变量、循环和条件语句,动态生成内容。JavaS⁃cript用于实现动态交互效果,如表单验证、异步请求等,增强用户体验。
2) 后端设计:后端主要负责用户信息、图片信息和检测结果的存储与管理。后端接收到前端上传的图片后,会调用算法模型进行检测,并将检测结果存储在数据库中。后端采用Django框架进行开发,使用Django的ORM(对象关系映射)进行数据库操作。后端主要负责接收前端上传的图片,调用算法模型进行检测,并将检测结果存储在数据库中。数据库使用MySQL进行存储,确保数据的可靠性和稳定性。
5.2 功能模块
在用户管理模块中,系统使用了Django的内置用户认证系统来管理用户注册和登录。为了确保密码的安全性,采用了Django 默认的密码加密机制(bcrypt) 对用户密码进行加密存储,并在用户登录时验证密码。数据库方面,使用了Django自带的User模型,包含用户名、密码、电子邮件等基本信息。同时,定义了一个自定义的Person模型,与User模型通过外键关联,用于存储用户的角色信息(教师或学生)。用户注册时,前端表单收集用户名、密码、确认密码和角色信息,后端接收数据后,验证密码是否一致,并检查用户名是否已存在。如果验证通过,使用Django的User模型创建新用户,并在Person模型中保存角色信息。登录时,系统验证用户名和角色是否匹配,使用Django的认证系统验证密码,成功登录后,根据用户角色重定向到相应的页面。为实现权限控制,系统使用自定义的装饰器role_required,根据用户角色限制访问特定视图函数,未授权的用户访问受限页面时,会被重定向或提示无权限访问。
在图片上传模块中,系统使用Django处理文件的上传和存储,利用os库进行文件路径和目录的管理。学生和教师用户都可以上传图片,教师可以创建和管理文件夹,以组织上传的PCB板图片和检测结果。上传的图片信息存储在自定义的ImageUpload模型中,包括图片路径、文件名、上传用户等信息。为确保时间记录的准确性,使用pytz库来处理时区信息。教师用户可以通过前端创建新的文件夹或使用已有的文件夹组织图片,支持本地上传和服务器上传两种方式。上传的图片保存在MEDIA_ROOT/images/教师用户名/文件夹名称的目录结构中,并在ImageUpload表中记录图片信息,便于后续的管理和查询。学生用户需输入教师的用户名,并从下拉菜单中选择要上传的文件夹,上传的图片将被保存到对应教师的文件夹下,同样在ImageUpload 表中记录上传的图片信息。文件夹管理功能允许教师用户在前端创建、删除文件夹,以便组织和管理图片,后端使用OS库进行目录的创建和删除操作,并提供接口获取教师已有的文件夹列表,供学生在上传图片时选择。
缺陷检测模块是系统的核心功能,利用PyTorch 深度学习框架和改进后的YOLOv5s目标检测模型。模型文件存放在服务器指定路径中。系统获取待检测图片的文件路径列表,遍历每张图片,使用模型进行检测,提取检测结果并统计每种缺陷的数量。缺陷类别包括缺孔、鼠咬、开路、短路、毛刺和杂铜。根据用户在评分设置页面输入的总分和焊点总数,计算每个缺陷的扣分权重,计算每张图片的总评分,并将检测结果和评分保存到自定义的数据库中。
在历史记录模块中,系统利用Django处理数据查询、分页和模板渲染。系统查询当前用户的所有图片上传记录,按照上传时间降序排序。对每个上传记录,汇总对应的检测结果,包括总检测图片数、每种缺陷的总数和平均评分。使用Django的Paginator对历史记录进行分页,每页显示固定数量的记录。在前端页面中提供分页导航,方便用户浏览不同页的数据。用户可以点击某个历史记录,查看对应的详细检测结果,详细页面显示每张图片的缺陷统计和评分。
在结果查看和导出功能中,系统使用pandas库处理数据并生成Excel文件。检测完成后,系统查询最新的检测结果,并在前端页面中以表格形式展示每张图片的检测结果,包括缺陷数量和评分。用户可以点击导出Excel按钮,后端使用pandas将检测结果转换为DataFrame,导出为Excel文件并供用户下载。评分设置模块中,用户可以输入焊点总数和总分,提交表单后,后端接收数据,计算每个缺陷的扣分权重,并存储在会话中。在后续的检测过程中,系统会读取会话中的参数进行评分计算。会话管理使用Django的request.session,确保用户的评分设置在整个检测流程中保持一致。文件夹管理模块中,教师用户可以在前端创建和删除文件夹,以组织和管理图片。系统使用os库在指定路径创建或删除目录,并提供接口获取教师已有的文件夹列表,供学生在上传图片时选择。在创建文件夹时,系统会检查文件夹是否已存在,避免重复创建。删除文件夹时,系统会验证文件夹是否存在,删除操作须谨慎,避免误删重要数据。
学生图片上传模块需要学生输入教师的用户名,并从下拉菜单中选择要上传的文件夹。后端验证教师用户是否存在,获取对应教师的文件夹列表,供学生选择上传。上传的图片将保存到对应教师的文件夹下,并在数据库中记录图片的上传信息,方便教师查看和管理。
为实现权限控制和装饰器,系统使用了Django提供的认证和权限控制基础设施,并使用functools.wraps 自定义了装饰器role_required。该装饰器用于限制视图函数的访问权限,确保只有特定角色的用户才能访问。不符合条件的用户将被重定向或提示无权限访问。在需要限制访问的视图函数上,添加@role_re⁃quired(teacher)或@role_required(student)即可实现角色权限控制。
5.3 功能演示
1) 评分设置:评分设置页面允许用户为每个焊点分配分数,该分数基于焊点总数与设定总分的比例,即每个焊点分数为总分除以焊点总数。此页面同时作为历史记录查看和文件管理的中心枢纽,用户登录后默认进入此页面。
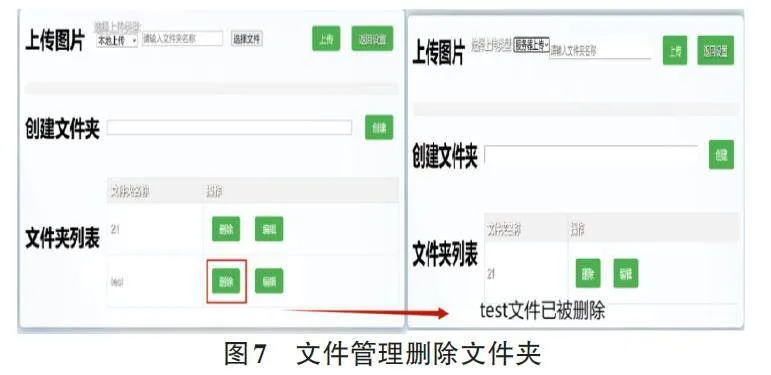
2) 文件夹管理和图片上传:用户可以通过文件管理功能对文件进行创建、删除、修改和查询操作。例如,在创建文件夹时,用户需在输入框中输入文件夹名称(如“test”) ,点击创建按钮后,新文件夹将显示在文件列表中,如图6所示。若需删除文件夹,可在文件列表中选择“test”文件夹旁的删除按钮进行操作,如图7所示。
通过下拉框选择图片上传方式(本地上传或服务器上传)即单击上传按钮即可完成图片上传。
3) 检测结果处理和展示:请依次完成评分设置和图片上传,当上传完成后,等待几秒,即可跳转到结果界面如图9所示,单击图9所标注出的导出Excel按钮,即可导出表格。
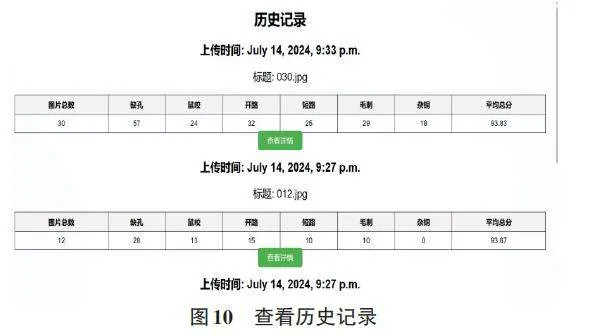
4) 历史记录查看:请通过分数设置页面的查看历史记录按钮进入界面,此界面可以查看以往检测数据,如图10查看历史记录所示,若想查看详情界面可以通过“查看详情”按钮查看对应的详细界面。
5) 学生图片上传:学生界面可通过输入教师的用户名,并通过下拉菜单完成文件夹选择,再通过选择文件夹完成图片上传,上传成功后会有3秒钟的图片上传成功提示。
6 结论
本文设计并实现了一种基于改进YOLOv5s模型的PCB板缺陷检测系统。针对原始YOLOv5s模型在PCB缺陷检测中通道和空间信息提取不足的问题,本文引入了CBAM注意力机制,增强了模型对重要特征的关注度,提高了特征提取的有效性。同时,采用SlideLoss损失函数,增强了模型对难以检测样本的识别能力,减少了漏检现象。实验结果表明,改进后的模型在准确率上提升了7.17%,平均召回率提升了4.38%,在处理图像模糊和小目标检测方面表现尤为突出。本文研究的创新点在于将改进的YOLOv5s模型成功应用于教学实践,提供了高效、准确的PCB缺陷检测解决方案,具有实际应用价值和推广潜力。未来的研究工作将致力于进一步提升模型的检测精度和速度,如优化模型结构、探索更深层次的特征提取方法、引入更先进的损失函数和注意力机制,进一步提高模型的性能。此外,计划将该系统扩展应用到其他类型的缺陷检测任务中,如焊点检测、电子元器件检测等,为更多领域的教学和工业检测提供支持,推动智能检测技术的发展与应用。
参考文献:
[1] 于心怡.基于深度学习的印刷电路板表面图像增强与缺陷识别研究[D].长沙:中南大学,2023.
[2] 徐一奇,肖金球,汪俞成,等.基于机器视觉的PCB表面缺陷检测研究综述[J/OL].微电子学与计算机,1-15[2024-08-03].https://kns. cnki. net/kcms2/article/abstract? v=3uoqIhG8C44YLTlOAiTRKibYlV5Vjs7ioT0BO4yQ4m_mOgeS2ml3UHH4bN4tKXwL-YoSKs8wQHHEXlUk-D-Dq9bTB6kj6bJi&uni ⁃platform=NZKPT
[3] IBRAHIM I,IBRAHIM Z,ABIDIN M,et al.An algorithm for clas⁃sification of five types of defects on bare printed circuit board[J].Interm ational Journal of Computational I,2008,13(1):57-64.
[4] MELNYK R A,TUSHNYTSKYY R B.Detection of defects in printed circuit boards by clustering the etalon and defected samples[C]//2020 IEEE 15th International Conference on Ad⁃vanced Trends in Radioelectronics, Telecommunications and Computer Engineering (TCSET). February 25-29, 2020, Lviv-Slavske,Ukraine.IEEE,2020:961-964.
[5] YUN T S,SIM K J,KIM H J.Support vector machine-based in⁃spection of solder joints using circular illumination[J].Electron⁃ics Letters,2000,36(11):949.
[6] WU H,ZHANG X M,XIE H W,et al.Classification of solder joint using feature selection based on Bayes and support vector machine[J].IEEE Transactions on Components,Packaging and Manufacturing Technology,2013,3(3):516-522.
[7] DING R W,DAI L H,LI G P,et al.TDD-net:a tiny defect detec⁃tion network for printed circuit boards[J].CAAI Transactions on Intelligence Technology,2019,4(2):110-116.
[8] HU B,WANG J H.Detection of PCB surface defects with im⁃proved faster-RCNN and feature pyramid network[J].IEEE Ac⁃cess,2020,8:108335-108345.
[9] WOO S,PARK J,LEE J Y,et al.CBAM:convolutional block at⁃tention module[M]//Lecture Notes in Computer Science.Cham:Springer International Publishing,2018:3-19.
[10] YU Z P,HUANG H B,CHEN W J,et al.YOLO-FaceV2:a scale and occlusion aware face detector[J]. Pattern Recognition,2024,155:110714.
[11] REN S,HE K,GIRSHICK R,et al.Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks [J].IEEE Transactions on Pattern Analysis and Machine Intel⁃ligence,2015,39(6):1137-1149.
[12] SHEN M H,LIU Y J,CHEN J,et al.Defect detection of printed circuit board assembly based on YOLOv5[J]. Scientific Re⁃ports,2024,14(1):19287-19287.
【通联编辑:谢媛媛】
基金项目:新疆农业大学大学生创新项目:电子技术基本技能实训评分系统(项目编号:dxscx2024355)
