基于GNN 的显著目标检测综述
2024-12-01芮成豪文达张凯旋伍虹缘朱子刚




摘要:显著目标检测作为一个具有广泛应用的研究焦点,其性能经历了从传统模型到深度学习模型的飞跃。近期,图神经网络(GNN) 由于能够高效处理图数据而被应用于显著目标检测领域,引领了该领域的前沿探索。本综述总结了该领域的发展历程,聚焦于GNN的应用进展,通过分类展示其多样化架构及取得的成效,并介绍了主流数据集和评价标准,为研究与实践奠定基础。此外,本文展望了GNN在此领域的潜在发展空间,旨在激发新的研究思路与创新技术,指导学界进一步进步。
关键词:图神经网络;显著目标检测;深度学习;计算机视觉
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2024)32-0016-04 开放科学(资源服务)标识码(OSID) :
0 引言
受初期灵长目视觉系统行为与神经结构的启发,Litti等人[1]提出了一种视觉注意力机制,开启了计算机视觉中显著对象检测研究的篇章。自1998年起,显著对象检测方法可以明确地划分为两个阶段:传统策略阶段和深度学习主导阶段。
在传统方法中,具体细分为以下几类[2]:
1) 基于块的检测模型。通过分析图像的局部块或区域来识别显著对象,利用对比度、颜色差异和纹理特性等。他们通过引入不受网络同质性限制的块级图卷积网络(BM-GCN) ,实现了“分类聚合”的功能,自适应学习不同类型的邻居聚合规则,取得了显著成果[3]。
2) 基于区域的检测模型。关注较大图像区域,利用区域特征进行显著性分析,通常借助超像素分割等技术来加强目标与背景的关联理解。比如,Ren 等人[4]的研究,通过区域检测模型与深度学习检测网络共享卷积特征,实现了近乎实时的检测速度。
3) 融合外部引导的检测模型。整合图像外的信息,例如眼动追踪、深度线索、物体边界等,增强内部与外部信息的结合,提高检测的准确性与鲁棒性。Liu等人[5]提出的像素级上下文注意力模型有效融合了局部与全局信息,优化了检测效果。
然而,这些基于块、区域及外部引导的传统模型也暴露了一些共性局限:
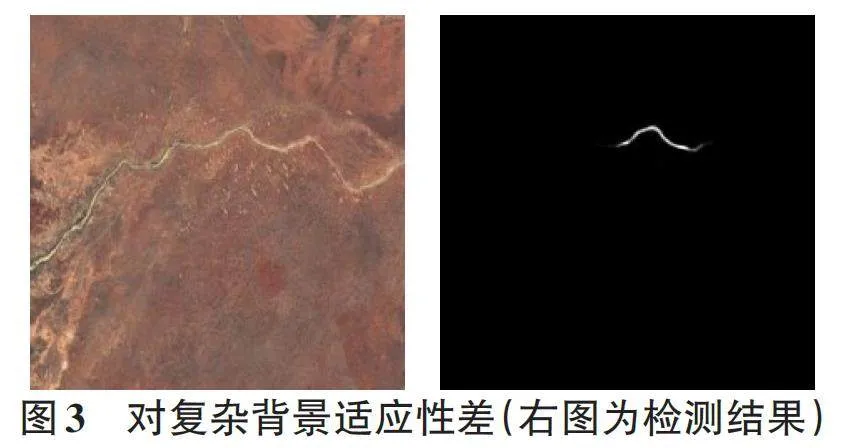
1) 全局上下文理解不足。过于集中在局部特征,忽视全局上下文。在复杂场景或目标周围干扰过多的情况下,检测效果容易下降。
2) 复杂背景适应力弱。在面对多样化背景或复杂场景时,难以有效区分目标与背景。
3) 尺寸与形态敏感性。对目标的尺寸和形状变化较为敏感,在处理多样性目标时稳定性较差。
4) 手工特征依赖。部分依赖于预设特征,导致在复杂环境中的泛化能力受限。
5) 多模态处理局限。通常侧重单一感官模式分析,对于图像、文本等多模态数据的处理能力有限。
深度学习的兴起为显著目标检测带来了革新,尽管初期面临图像复杂性等挑战,但全卷积网络(FCN) 的引入标志着像素级预测的新纪元,极大增强了对复杂场景的理解能力[6]。此后,进阶模型如CenterNet通过创新的中心点检测策略,优化了对小且被遮挡物体的检测精度与效率[7];而DETR(Detection Transformer) 通过摒弃传统锚框设计,利用Transformer直接预测目标位置与类别,简化了检测框架,同时强化了对重叠目标的处理能力,为显著目标检测提供了更加直观且简化的方案[8]。
这一系列深度学习模型的演进,不仅丰富了显著目标检测的理论与实践,还不断拓宽了技术边界。特别是近年来,图神经网络(GNN) [9]作为研究的亮点,凭借其在处理图结构数据中捕获复杂关系和上下文信息的卓越能力,为显著目标检测开创了新途径。GNN 通过构建像素间的连接,精确定位目标的上下文与空间结构,尤其在复杂场景下显著提升了检测的准确性和鲁棒性,为该领域的发展注入了新的活力与可能性。
1 图神经网络
图神经网络(GNN) 是计算机视觉中专为图数据设计的强大工具,能够有效分析由节点和边构成的网络,捕获图像内部的复杂关系。其核心优势在于通过迭代聚合邻居节点的信息来提炼高级特征表示,从而深入洞察全局及局部关联。
主要GNN类型包括:
1) 图卷积网络 (GCN)。在图上应用卷积以提取特征,理解局部与全局信息[10]。
2) 图注意力网络。融合注意力机制,动态聚焦于图结构中重要的部分,从而增强关系建模能力[11]。
3) 图自编码器。通过无监督学习方式,通过压缩和重构来学习图数据的低维表示,实现降维和特征提取[12]。
4) 图生成网络。用于生成特定结构的图数据,适用于图数据创造任务[13]。
接下来,笔者将介绍图神经网络在显著目标检测中的应用,并根据主要应用的网络进行分类。
2 基于GNN 的显著目标检测方法
2.1 基于图卷积进行显著目标检测
该部分着重于利用图卷积的推理能力来建模区域关系,以提取显著目标特征[10]。在计算机视觉任务中,如分类[14]、分割[15]及动作识别[16],对长距离、任意形状的区域间关系进行推理极为关键。尽管传统的卷积神经网络(CNN) 能够有效处理局部关系,但在捕获全局和远距离关联时效率较低,通常需要叠加多层来实现。为应对这一挑战,DenseASPP[17]整合了多尺度特征以扩大感受野,提高分割效果;同时,CoT引入了创新的Transformer模块,利用上下文指导动态注意力学习,增强了视觉表征能力。此外,由于图神经网络(GNN) 能够有效地把握全局图像结构与关系,其通过图表示学习来连接区域间联系,优化全局上下文的利用,成为一个有效的解决方案。
2.1.1 图推理
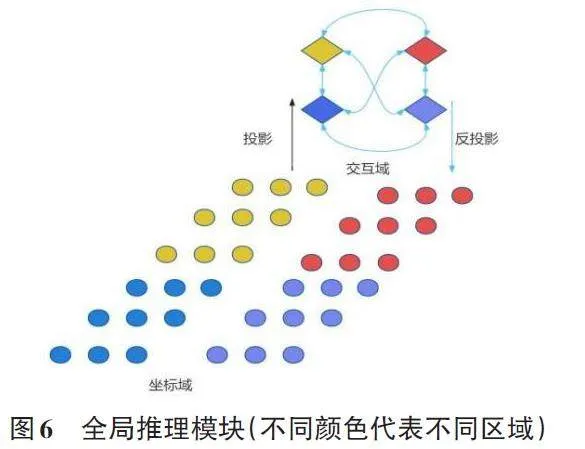
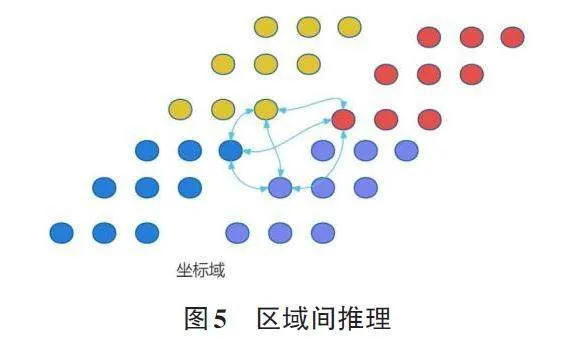
作为一种有效的解决方案,图推理近年来在关系推断方面受到越来越多的关注。图模型如条件随机场(CRFs) [18]在图像分割中得到了成功应用,而图卷积网络(GCNs) 在半监督分类[19]及通过捕捉对象间关系进行的视频识别中也展现出强大能力[20]。这些方法依赖于预训练的检测器来识别对象。而与之相比,部分研究直接采用GCN进行端到端训练,实现任意形状的非相邻远端区域间推理,无需独立的对象检测或额外的标注[21]。这种方法涉及特征的全局聚合与交互空间的映射。通过GCN推理后,将关系感知特征映射回原空间,从而促进如显著目标检测等后续任务的执行[22]。其大致框架如下:
1) 坐标到交互空间转换。首先,确立投影函数,将原始特征映射至有利于全局推理的交互空间,特别是针对远隔和非重叠区域。
2) 图卷积推理。在映射后,形成描述节点特征的图,捕捉节点关系并转化为节点特征互动。利用图卷积进行高效分析,优于高成本的特征连接或简单关系网络,通过全连通图结构学习节点间的权重,保持特征维度的一致性。
3) 反向映射。为了与标准CNN框架兼容,最后一步是将推理后的特征反投回原坐标空间,以便后续卷积层利用增强的特征进行决策。反向映射过程与正向映射相似。
2.1.2 关系推理
该模型的核心包括关系推理编码器和多尺度注意力解码器,旨在克服光学遥感图像(RSIs) [23-25]中显著物体检测的难题,如复杂背景和尺度变化,并已取得显著成果。具体如下:
1) 关系推理编码器。面对检测目标的多样性和尺度变化,模型利用目标间的关系辅助检测,通过图结构将对象关系转化为特征节点交互,实施关系推理。借鉴图模型在视觉任务中的有效性,编码器综合空间与通道维度,分步进行关系推理,先构建空间推理特征,再据此进行通道关系推理,深化内部关系理解。
2) 多尺度注意力解码器。解码阶段融合多级特征图,旨在恢复不同尺度的显著目标。利用底层特征的高分辨率和细节优势,结合多尺度与注意力机制,一方面应对物体尺寸变化,另一方面筛选编码阶段的冗余信息。解码器设计了两种注意力策略:一是直接计算不同视野下的多尺度注意力图并融合;二是先提取多尺度特征,再逐尺度计算注意力。
尽管成效显著,该模型仍面临挑战:完全识别突出物体、有效抑制非显著高对比度物体,以及妥善处理复杂阴影,这些问题需要在后续研究中持续优化。
2.2 基于图注意网络进行显著目标检测
图注意力网络通过注意力机制聚焦关键节点,增强特征捕捉能力。例如,DANet利用空间和通道注意力整合局部与全局特征[26],而金字塔注意力网络[10]通过多级上下文聚合处理尺度变化,两者均能促进显著目标检测。也有研究将几种图网络融合以提升检测性能,例如在[27]中创新性地引入了图交互网络,结合图结构信息和图卷积特征,提高了在场景中检测显著目标的性能。另如ST-GCN[28]虽然主要用于动作识别,但其时空建模能力对理解目标运动模式和分布同样宝贵。ST-GCN运用GCN处理时空数据,不仅捕获空间关系和时序动态,还通过节点表示学习区分图像或视频中不同区域的特征,适应不同尺度的特征分析,增强了在显著目标检测中的位置和形状识别,以及鲁棒性和准确性。
2.3 基于图自编码器进行显著目标检测
图自编码器通过学习图数据的低维表示,有效压缩和重构特征,在显著目标检测中捕捉深层结构信息。研究结合图卷积网络与图自编码器,前者用于理解360°视XSoMlHpkC+fd29bFEVlRRA==频中目标的空间上下文,后者则学习低维特征以提取关键信息,优化检测效果。而文献[29]中加入的图注意力机制,使网络能动态聚焦3D场景中关键区域,精准捕捉目标特征,同时借助自编码器提炼高级特征表示,增强了从3D数据中提取显著特征的能力,整体提升了复杂场景下显著目标的检测性能。这表明图自编码器与其他图模型的融合,可极大促进多场景下显著目标检测的性能。
2.4 基于图生成网络进行显著目标检测
图生成网络凭借学习图内节点与边的互动,革新了显著目标检测领域,通过图像生成强调目标,以节点代表像素或区域,边定义彼此关联。网络设计围绕节点和边的定义及架构搭建,利用生成过程区分并突出目标,借助图结构特征学习实现高效数据压缩与高质量重构,深化对目标结构特征的理解[13]。
为精确把握目标空间分布及上下文,常结合图卷积网络(GCN) 来强化节点间联系理解。另外,结合图注意力机制,可使系统动态聚焦图的关键部分,精准定位与描述显著目标。扩展到3D场景,该方法通过自编码器学习高阶特征表示,从3D数据中提炼显著特征,增强检测效果与泛化能力。
总体来说,图生成网络利用图论优势,在多样环境中展现了卓越的显著目标检测能力,开创了捕捉目标特征的新途径。
3 显著目标检测数据集
3.1 数据集合
当前的深度学习显著目标检测技术高度依赖大规模数据集,如DUT-OMRON、DUTS、HKU-IS、ECSSD/ CSSD、SOD 及PASCAL-S 等,用以训练和评估模型。这些数据集的特点如下:
1) DUT-OMRON。包含5 168幅图像,最大边为400像素,背景复杂,含有多个显著对象,标注详尽。
2) DUTS。包含10 553幅训练图和5 019幅测试图,源自ImageNet DET与SUN,场景丰富,适用于显著性检测。
3) HKU-IS。包含4 447幅图像,全部带有像素级显著对象标注,划分为测试集和训练集。
4) ECSSD/CSSD。分别包含1 000幅和200幅复杂场景图,含有像素级标注,有助于学习显著性特征。
5) SOD。基于BSD,包含300幅图像,涵盖7类对象,专注于显著边界。
6) PASCAL-S。源于PASCAL VOC,包含850 幅图像,具有二进制标注,用于评估显著目标检测性能。
这些数据集共同推动了显著目标检测技术的发展,提供了多样化和复杂的测试基准。
3.2 评价指标
为了评估性能,本节重点介绍以下广泛使用的评价指标:精确率(PR) 、F分数(F-Measure) 、平均绝对误差(Mean Absolute Error,MAE) 、S分数(S-Measure) 、PR 曲线(PR curves) 、E分数(E-Measure) 。
1) 精确率(PR) 。精确率是输出位置在给定的真值阈值距离内的帧的百分比。在某些场景下,也可以使用最大精确率(MPR) 作为评价指标。
2) F-分数(F-Measure) 。融合准确率与召回率,通过调和平均取得,反映综合性能。
3) 平均绝对误差(MAE) 。表示预测值和观测值之间绝对误差的平均值,通常越小越好。
4) S分数(S-Measure) 。该指标的计算涉及显著性图的结构相似性和显著性图的区域相似性。具体形式可能因研究和实现而异。该指标的取值范围通常在0到1之间,其中1表示完美匹配。
5) PR曲线(PR curves) 。即以召回率(Recall) 为横坐标,精确率为纵坐标绘制而成的曲线,通过调节分类阈值,可以得到不同的召回率和精确率,从而得到PR曲线。
6) E分数(E-Measure) 。综合考虑了算法生成的显著性图与真实显著性图之间的结构相似性、亮度一致性和显著目标的区域相似性。E-measure的计算公式和具体实现可能有一些变化,取决于研究和评估的具体设置。该指标的取值范围通常在0到1之间,其中1表示完美匹配。
4 总结
本文回顾了显著目标检测的演进,包括从早期技术到近期深度学习技术,并着重介绍了图神经网络(GNN) 在此领域的应用。文章首先概述了GNN的基本构成,随后分类探讨了其在显著目标检测上的研究进展,同时涵盖了关键数据集与评价标准。
展望未来,GNN在该领域的潜在研究方向包括:
1) 动态图处理。针对视频数据,研发适应性强的GNN,实现实时图分析预测,提升视频显著目标检测的精度。
2) 不完整图学习。研究处理图数据缺失问题的方法,恢复丢失信息,增强实际场景下的应用能力。
3) 不确定性建模。探究GNN在捕捉显著目标不确定性上的潜力,以增强系统的鲁棒性和可靠性。
这些方向有望推动显著目标检测技术的进一步发展。
【通联编辑:唐一东】
