多模态健身运动知识图谱构建
2024-10-31余卓成刘心怡李素建赵冰婵罗文杨彤晨丁立祥宋继鹏





摘 要 构建健身运动知识图谱可以为人们科学运动提供直观便捷的指导,对推动健身研究领域的发展和促进人们身体健康具有重要意义。而如何全面获取科学健身运动的多模态知识,并进行系统的关联和集成以及形成多模态知识图谱,目前相关研究较少,且面临着诸多挑战。针对上述问题,利用自然语言处理、深度学习技术、视觉识别技术等,以人机结合的方式探索构建多模态科学健身运动知识图谱。具体步骤包括:1)数据选择和处理,确保知识图谱的基础数据可靠且全面;2)设计多模态知识体系,以整合文字、图像等多种信息形式;3)运用关键技术获取知识,特别是将运动视频转换为细粒度运动文本进行描述;4)构建可视化平台,使知识图谱更加直观和易于使用。通过系统地关联和集成多模态的健身知识,构建了一个包含丰富信息的健身运动知识图谱。该图谱系统不仅能够有效地将运动视频转换为详细的文本描述,还能可视化地直观展示图片、视频等信息,为用户提供易于理解和使用的科学运动指导。多模态科学健身运动知识图谱的构建,为其在健身方面的应用提供了重要参考。这表明,多模态知识的获取和集成是实现科学健身指导的重要途径,能够有效推动健身研究领域的发展以及促进人们的身体健康。
关键词 多模态知识图谱;知识获取;科学运动
中图分类号:G80-05 学科代码:040302 文献标志码:A
DOI:10.14036/j.cnki.cn11-4513.2024.05.002
Abstract Constructing an exercise knowledge graph can provide intuitive and convenient guidance for scienti-fic exercise, significantly contributing to the development of the fitness course and the promotion of public health. However, there are currently few studies on how to comprehensively acquire multi-modal knowledge of scientific exercises and systematically integrate this knowledge to form a multi-modal knowledge graph. This task faces numerous challenges. To address these issues, we explore the construction of a multi-modal scientific fitness exercise knowledge graph using natural language processing, deep learning, and visual recognition techn-ologies in a human-machine collaborative manner. The specific steps include: 1) data selection and processing to ensure the reliability and comprehensiveness of the foundational data for the knowledge graph; 2) designing a multimodal knowledge system to integrate various forms of information, such as text, images, and videos; 3) empl-oying key technologies to acquire knowledge, particularly converting exercise videos into fine-grained textual descriptions; 4) building a visualization platform to make the knowledge graph more intuitive and user-friendly. By systematically relating and integrating multi-modal fitness knowledge, we have successfully constructed a fitness exercise knowledge graph rich in information. This graph not only effectively converts exercise videos into detailed textual descriptions but also intuitively displays the information through a visualization platform, providing users with easy-to-understand and user-friendly scientific exercise guidance. The construction of the multi-modal scientific exercise knowledge graph provides an important reference for the construction and appli-cation of knowledge graphs in the fitness field. This indicates that acquiring and integrating multi-modal knowledge is an essential approach to achieving scientific fitness guidance, which can effectively promote the development of the fitness course and enhance people's health.
Keywords multimodal knowledge graph; knowledge acquisition; scientific exercise
随着社会的进步和生活水平的提高,体育健身成为人们追求健康生活的主要方式。《全民健身计划(2021—2025年)》和《关于构建更高水平的全民健身公共服务体系的意见》等政府文件的发布和落实,使得体育健身的社会氛围愈加浓厚。近年来,国内外学者也从不同的角度和层次对科学健身运动的理论、技术等方面进行了深入的研究和探讨,涉及体育学、运动医学、计算机等多个学科领域,形成了一些有价值的研究成果[1-3]。然而,如何全面获取这些科学健身运动的相关知识,并进行系统的关联和集成,形成知识图谱,目前相关研究还比较少,面临着诸多挑战。
知识图谱及其相关技术是人工智能知识工程领域的发展方向之一。知识图谱最初由Google提出,目的是优化搜索引擎反馈的结果和提高用户搜索质量。知识图谱构建技术则是利用自然语言处理、数据挖掘、机器学习等技术对海量数据进行加工和分析,从中获取常识知识和领域知识,并用图状概念模型来描述这些知识,从而建构真实世界中的概念及其相互关系的技术。知识图谱通常分为通用知识图谱和领域知识图谱。其中:通用知识图谱不指向特定领域,会包含大量常识知识;而领域知识图谱则指向某个具体的专业领域,强调知识的深度,包括该领域的特色知识。领域知识图谱因具有更实际的应用场景而受到了广泛的关注,目前多数应用于电商平台、金融、科技情报、生物医药等相关领域[4-6],健身运动方面的知识图谱构建工作还较为少见。
传统的知识图谱大部分以纯文本形式表示,而健身运动方面有大量图片、视频等数据,其中丰富的多模态知识能够更高效地帮助并指导科学健身,例如,在视觉模态中,运动实体的位置关系可以被轻易地识别。然而,这些多模态知识无法被传统知识图谱所包含。因此,将知识符号与文本之外的其他模态数据(如图像、声音等)关联,即多模态化,对科学健身运动知识图谱的构建具有重要意义。近年来,一些多模态知识图谱陆续出现[7],大部分是在传统知识图谱的基础上将一部分知识多模态化得到的多模态知识图谱,并应用于推荐系统[8]、电子商务[9]、问答系统[10]等垂直领域,然而目前在健身运动领域还没有知识多模态化的有效实践。
构建科学健身运动多模态知识图谱的工作面临着诸多挑战,其中,如何有效地获取高质量的多模态健身运动数据、如何将这些异构数据进行融合并解决模态之间的不一致性和冲突、如何进行有效的跨模态推理、如何动态地更新知识图谱,以及如何处理新出现的模态数据等问题都需要解决。针对上述挑战,本研究利用自然语言处理与多模态处理技术探索构建科学健身运动多模态知识图谱,文中将介绍该知识图谱构建的总体方案、描述体系设计、知识获取技术等。
1 研究现状
1.1 多模态技术在运动领域的研究现状
对人体运动的多模态研究开展已久,并产生了一些成果。这些成果主要研究视觉-文本多模态学习和运动-文本多模态学习。在视觉-文本多模态学习研究中,分析对象为包含着人体运动的图片或视频;而在运动-文本多模态学习研究中,运动是一种独立的模态,可以实现与文本的对齐。
构建视觉信息与标注文本一一对应的数据集是视觉-文本多模态学习的基础。根据涵盖范围不同,现有的视觉数据集可以分为通用数据集和专业数据集。通用数据集规模较大,广泛涵盖各个主题,如图像数据集COCO、视频数据集MSR-VTT等。这些数据集可以为表征学习提供丰富的知识,但在人体运动这一特定领域的任务上表现不佳。专业数据集只涵盖某一细分领域的数据,适合在特定任务上改善模型表现,如只包含烹饪视频的Youcook2数据集。近年来,有一些研究聚焦于运动领域专业数据集的构建和理解,如篮球赛、足球赛等集体性体育赛事的视频数据集。一项细粒度运动视频描述研究收集了2 000个篮球比赛视频,人工标注构建数据集,并建立了自动生成比赛场实况的描述模型[11]。除了人工标注之外,还有一些研究使用现存的与视频匹配的文本构建数据集,诸如比赛中的解说词或直播平台的实时评论[12]。这些研究更侧重于运动场实况的整体描述,缺少对运动技术的深入研究。
运动-文本多模态学习研究包括人体运动图像或视频与文本描述的相互转化等任务。例如:运动到文本的转化,即运动描述任务,指的是给定运动图片或视频数据,通过模型生成对该运动图片或视频数据的文本描述;文本到运动的转化,即运动生成任务,指的是给定文本,通过模型生成符合文本描述的运动表现,并将其可视化为图片或视频,有时会将运动的初始状态、结束状态或中间状态作为约束条件。
人体运动作为一种单独的模态,通常使用姿态提取获得模型,并将其转换为相对于父关节旋转角的表现形式[13]。父关节是指在骨骼层次结构中位于某个关节(称为子关节)上一级的关节,决定了子关节的参考系。近期的运动-文本多模态学习模型主要采用编码器-解码器结构,这些模型通常使用矢量量化变分自编码器(VQ-VAE),可以将连续的运动表现转化为离散的词元。将运动表现转化为词元后,运动可以被视为一种特殊的语言,运动和语言之间的跨模态转换则是一个机器翻译问题[14]。随着预训练模型的变化,越来越多的研究将预训练模型与运动-文本模型进行结合。例如:MotionCLIP在训练运动自编码器时将运动的特征空间与CLIP的特征空间对齐,使运动特征和对应的文本、图片特征相接近[15];MotionGPT将运动自编码器获取的运动词元和文本词元混合,在T5模型的基础上继续预训练,随后在现有数据集的基础上建立了一个运动-文本的指令数据集进行指令微调[16]。以上多模态技术都可以用于健身运动知识图谱构建。
1.2 知识图谱相关工作
知识图谱的概念于2012年出现,最初用于优化搜索引擎反馈的结果。随着相关技术的不断发展,知识图谱作为一种高效的知识表示形式,逐渐在各领域得到了广泛的应用[17-18]。知识图谱可以看作是结构化的语义知识库,以符号形式描述物理世界中的概念及其相互关系,其基本组成单位是实体及其相关属性构成的键值对,实体间通过关系相互联结,构成网状的知识结构。作为一种结构化的知识,知识图谱在学术界和工业界都引起了广泛的研究关注[17-18]。
知识图谱一般分为通用知识图谱和领域知识图谱。相较于通用知识图谱,领域知识图谱指向某一特定领域,专业性强,较有权威性,知识表示相对困难,在构建过程中需要专家的深度参与。目前,领域知识图谱大多应用于互联网行业,研究内容主要是知识的获取和表达等,而其余研究分布在矿产、汽车制造等行业。例如:叶帅结合矿产学科知识的组织结构,构建出煤矿知识图谱的本体,形成了煤矿领域知识图谱系统[19];魏卉子提出一种煤矿安全概念知识库半自动化构建方法,为煤矿安全融合知识图谱构建做了初步探索[20];袁芳怡将定量知识与定性知识相结合,建立了指向制造业的知识图谱[21];许力基于网络公开数据构建了汽车制造领域的知识图谱[22]。
随着多模态技术的发展,多模态知识图谱成为新兴研究热点。根据不同的构建方法,一般将多模态知识图谱分为2类:一类是将其他模态的数据如图片、视频视为文本实体或关系的属性;另一类则是将各模态数据均作为独立的实体节点。在将图像作为实体的关系图谱中,通常使用视觉模型提取知识。Neil使用预训练的分类器为每个图像标注单一标签,并通过提取实体位置存在的启发式规则分析视觉关系[23]。Gaia可以通过目标识别和细粒度分类提取新闻中的细粒度概念[24]。基于Gaia的框架,Resin可以提取视觉新闻事件的概念,并在小规模数据基础上将识别的相关视觉实体和概念作为基本元素[25]。
检索也是多模态知识的重要获取途径之一。Image-Graph可以将知识图谱中的实体作为查询条件,在搜索引擎中搜索图像[26]。在此基础上,通过MMKG在多个知识图谱中对准实体。为了使检索获取的图像尽可能全面地反映实体[27],图像的多样性十分重要。因此,Richpedia训练了一个额外的多样性检索模型来选择多样化的图像,但其中的实体类别仅限于城市、景点和人物[28]。此外,有研究者认为,许多抽象实体无法可视化,所以应从最典型的可视化实体开始,迭代地挖掘其他相关的可视实体[29],然而Visual Sem的规模也远远不能满足下游应用的知识需求。由此可见,为了满足下游应用的需求,需要从不断增长的海量互联网数据中自动获取知识。而如何自动而有效地获取多模态数据,并从数据中识别多模态的实体、实体间关系以及实体的属性值,是一个极具挑战性的问题。
2 健身运动知识图谱构建总体方案
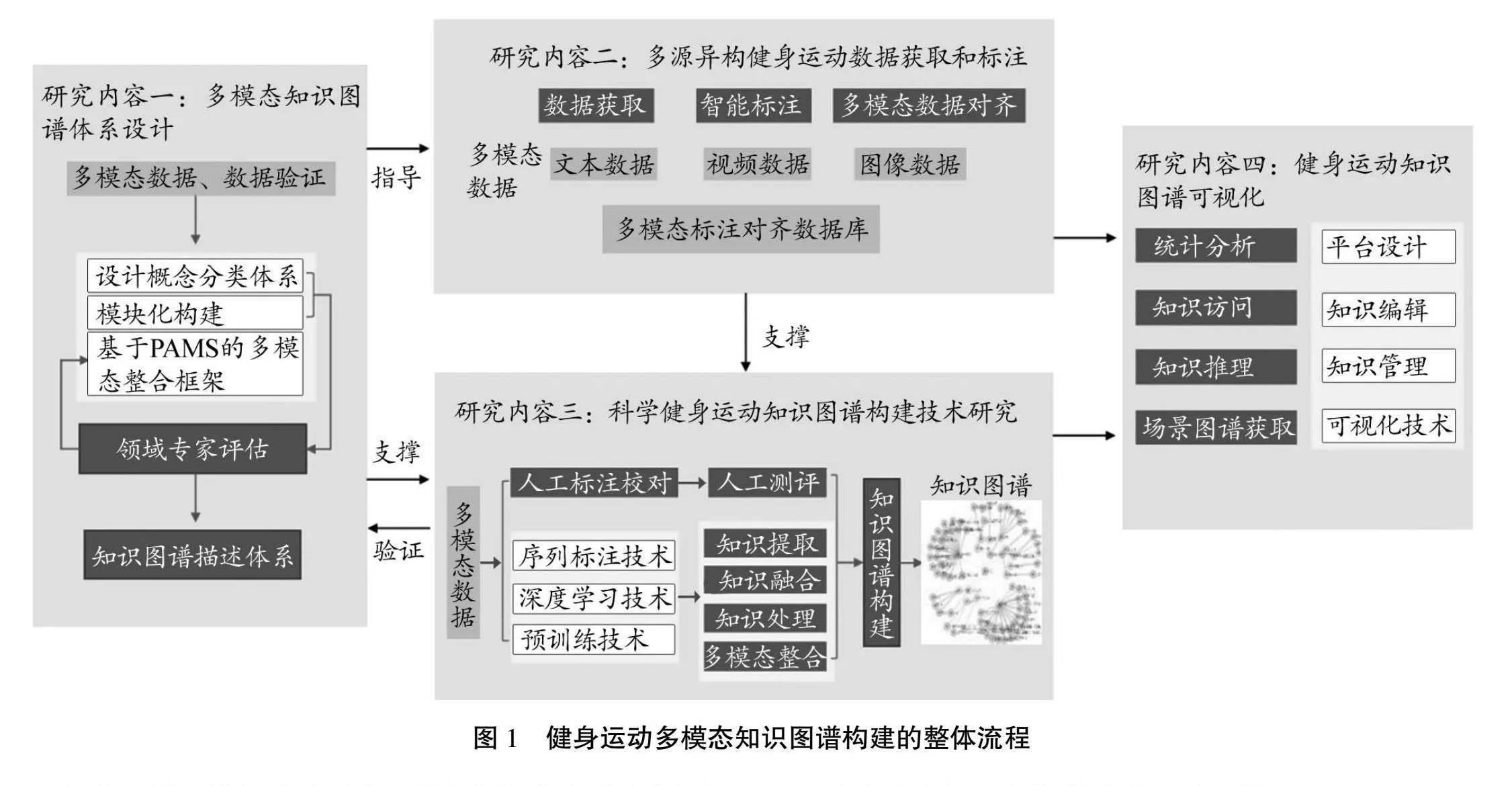
本研究中构建的多模态健身运动知识图谱,不仅可以作为知识库服务于运动姿态纠正等任务,还能够直接面向大众,为大众运动健身提供有效指导。因此,知识图谱应当包含便于人类理解的细粒度描述文本,同时结合多模态信息,如图片、视频等,将运动技术直观可视化。基于以上考虑,本研究设计了健身运动多模态知识图谱构建的整体流程,如图1所示。首先,针对科学健身运动技术指导和主动健康知识的检索和推介需求,研究多模态知识图谱知识0SdmY07ZUQh4P5k4DU7Y7u15+gawikITTUkzQQ6XwNk=体系的分类规范。在知识体系规范的基础上,获取相关的多模态健身运动技术数据,并研发健身运动知识、健身实体属性和健身实体之间关系的知识抽取技术,将这些知识进行融合建立知识图谱库,最后将科学健身运动技术知识图谱可视化呈现,从而可以满足健身运动知识检索和推介的需求。
具体而言,首先在理论层面结合体育专家和运动医学专家的指导及专业知识,梳理和设计多模态健身运动知识体系。为了高效获取大量的、高质量的多模态标注数据,可以使用机器学习方法和大语言模型辅以专家校对进行标注,从而加深知识图谱构建的自动化程度。在多模态知识图谱的构建过程中,通过实体抽取、关系抽取和属性抽取可以逐步递进地提取与健身运动技术相关的知识。其次是基于科学健身运动技术的知识检索和智能推荐等需求,搭建知识图谱可视化平台,对科学运动健身多模态知识图谱进行可视化展示。
3 健身运动知识描述体系设计
当前,体育运动领域的知识体系并没有一个统一的规范,所以在设计健身运动知识图谱的描述体系时,从实用角度出发,参考现在主流的运动知识分类标准,综合考虑健身人群、健身方式、身体机能、运动损伤等因素,以运动技术为核心,以促进全民健身为目标,选择了力量训练、瑜伽、球类运动等运动类型,构建科学健身运动知识图谱。
知识图谱可以视为结构化的语义知识库,主要用符号描述物理世界中的概念及其相互关系,知识表示形式通常为(实体-关系-实体)和(实体-属性-属性值)2类。本研究依据前人的工作也把知识图谱定义为一个有向图,可以形式化为六元组:G=<E,R,A,V,TR,TA>。其中:E表示实体集合;R表示关系;A表示属性集合;V表示属性值集合;TR=E×R×E表示实体关系三元组集合;TA=E×A×V表示实体属性值三元组集合。在对实体进行多模态化时,可以在知识图谱中融入图片、视频等多模态知识。
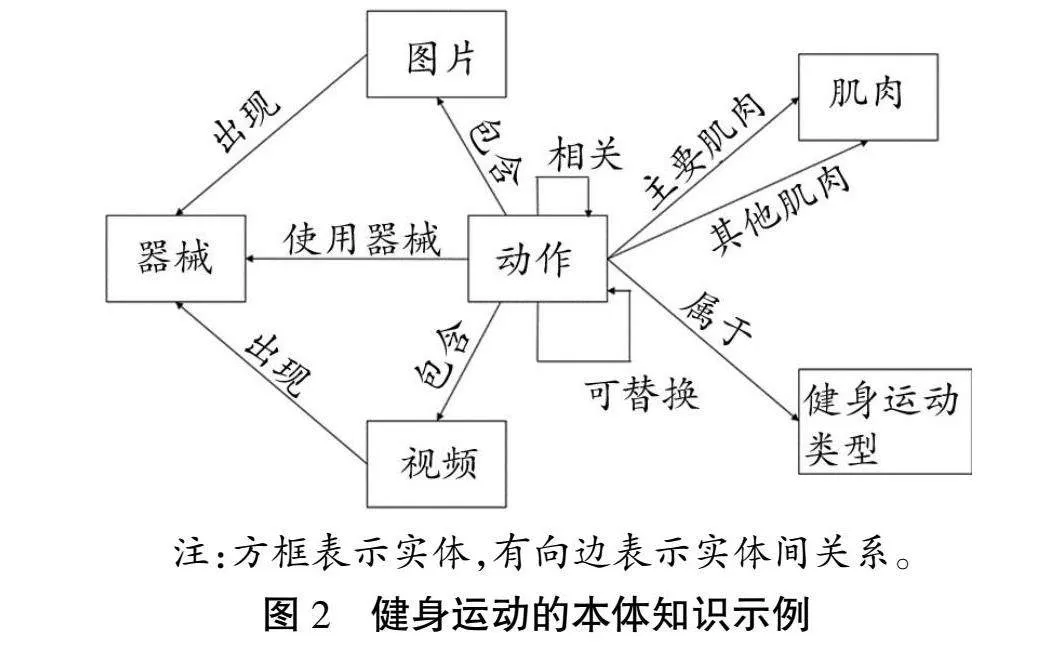
为了更好地定义和描述科学运动健身知识,本研究根据不同的健身运动的特点设计了知识图谱的本体,定义了实体的种类、每个种类的实体具有的属性、实体之间的关系集合等。以健身运动为例,构建多模态知识图谱的体系,如图2所示,针对健身运动的特点,以及根据需要在知识图谱中融入多模态知识的要求,定义如表1所示的实体类型。
采用将图片、视频等其他模态单独作为实体节点的方式构建知识图谱,一方面可以确保不同模态具有同等作用,使知识图谱能够表示不同模态知识之间的关系,另一方面可以避免不同模态直接融合的错误。对于不同类型的运动,主要运动实体也会有所变化,如瑜伽和球类运动,其身体部位是重要的运动实体,而肌肉不是主要的运动实体。
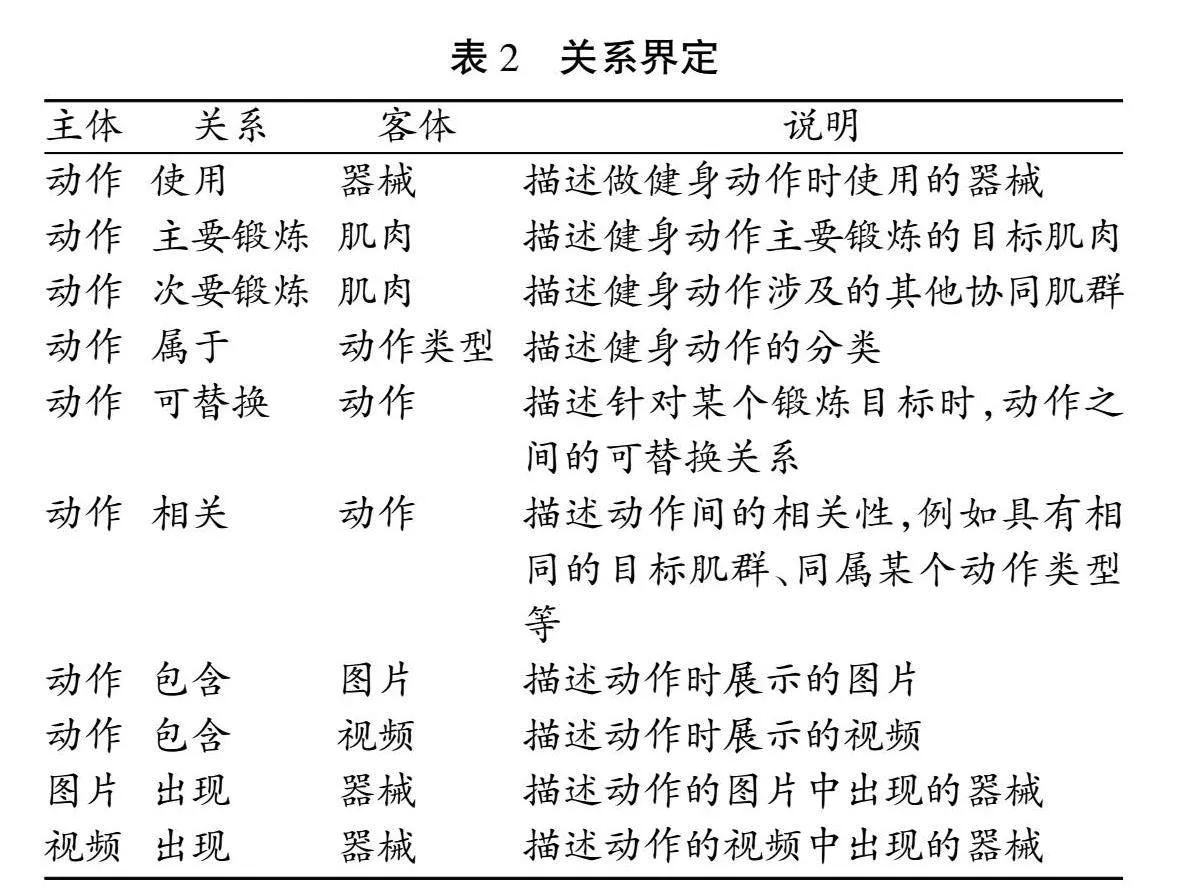
基于上述运动实体的定义,针对健身运动界定运动实体之间的关系,见表2。
需要注意的是,这些实体和关系类型用于指导自动获取知识,在知识获取过程中,也会进一步调整知识类型。
4 健身运动知识获取技术
4.1 数据来源
为了确保所获取知识的专业性和广泛性,需要采集多种来源的数据,由于结构化数据很难得到,一般只能获得半结构化数据或非结构化数据。其中:半结构化数据来源于百科、专业运动健身网站等信息发布网站,这些网站已经对知识进行了归纳和整理,实现了一定的结构化,相对容易从中获取需要的运动知识;非结构化数据则来源于书籍、论文、公开的健身运动网页等,如《力量训练与运动机能强化指导》《美国国家体能协会力量训练指南》《老年人运动健身指南》。与此同时,还拍摄和录制了一些专业化的运动动作,以确保获得高质量的图片、视频等多模态数据。对于半结构化数据,根据数据源的结构解析数据,利用前文定义的运动本体框架即可提取所需知识。对于非结构化数据,则需要应用自然语言处理技术、大语言模型技术等自动获取知识。
4.2 基于文本的知识获取技术
非结构化文本是多模态知识图谱构建的重要数据来源之一,而构建的核心在于从其中进行知识获取。命名实体识别和关系分类是知识获取的基础任务。命名实体识别(NER)是指识别文本中的实体,并判断其类型。通常最简单的方式是利用规则得到文本中的实体,需要针对不同领域总结不同的规则,从而导致实体识别的召回率偏低。同时,实体在文中的表现形式也非常灵活,可以为扁平实体、嵌套实体和不连续实体[30-31]。例如,在“引体向上主要是练习背阔肌外侧和上侧”的文本中,“引体向上”为扁平实体,但是“背阔肌”和“背阔肌外侧”同为身体部位,是2个嵌套的实体,“背阔肌上侧”则为不连续实体。近年来,研究者通常用序列到序列生成式方法统一识别各种实体类型[32],即输入要分析的语句,直接输出若干个实体名称及其类型。使用生成式方法识别命名实体一般存在训练和预测目标不一致的问题,训练使用交叉熵损失函数,而预测指标却是准确率、召回率和F1,两者之间存在差异。为了解决这个问题,本研究采用了一种基于重排序的序列似然校正方法[33],基于对比学习根据模型生成的候选项质量来校准模型的输出,可以改善模型生成效果,增强实体识别的性能。在对文本完成实体识别、得到实体之后,关系分类能够判断一对实体之间的关系类型。如上例所示,“引体向上”和“背阔肌上侧”已经被识别为实体,需要判断两者为“锻炼”关系。运动领域的标注资源有限,难以使用监督学习方法。一种可能的方式是直接使用句法分析,通过分析句子结构并根据预定义规则判断实体关系,但句法分析规则的局限性影响了关系分类的正确性。考虑到大语言模型在文本处理上的突出作用,尝试使用大语言模型上下文学习方法对关系类型进行标注。由于不同运动类型的关系类型具有较大差异,大模型需要持续学习不同运动类型中的关系知识,这容易导致灾难性遗忘问题。对此,本研究使用了基于解释增强的增量式关系识别方法,运用大语言模型对数据集中的关系分类样本标注解释,通过知识蒸馏将大语言模型的推理能力迁移到持续学习的小模型中,该方法在公开数据集上的准确率可达到80%以上[34]。
4.3 基于多模态的知识获取技术
为了给用户提供更为直观的运动指导,本研究中的知识图谱融入了大量的多模态信息,这需要针对多个模态的数据来源进行知识获取技术的研究,如图片、视频等。考虑到部分的数据来源于网络,其形式为带有图片的文本,所以以下重点介绍结合图片的多模态命名实体识别和关系抽取技术。同时,由于获取的很多运动视频缺少对运动技术的详细文字描述,以下将介绍运动视频到细粒度运动文本描述的生成技术。
4.3.1 多模态信息抽取
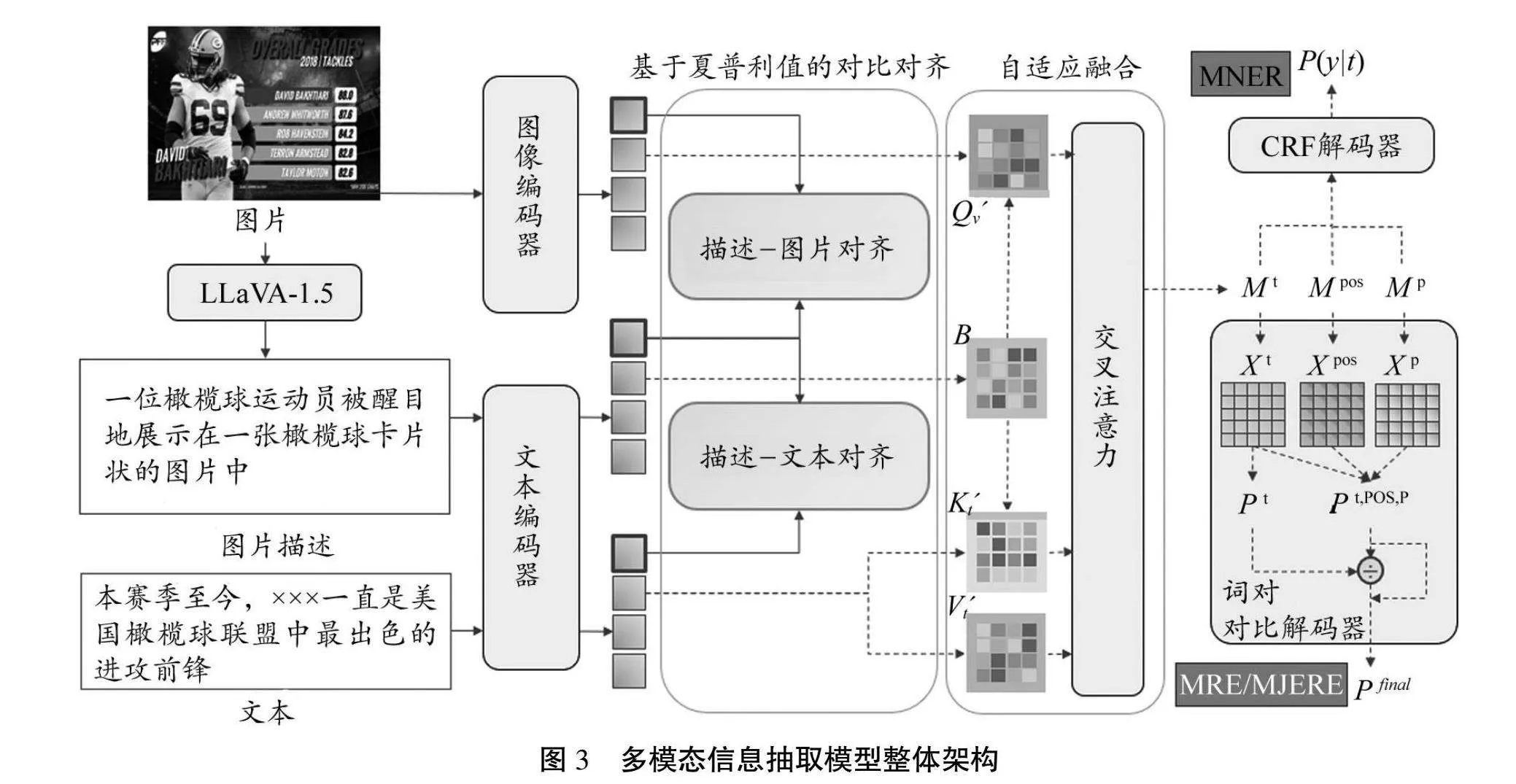
给定一段与运动相关的非结构化文本,相比直接对文本进行知识抽取以及引入与该文本直接相关的图像信息作为辅助信息,有助于模型更好地从中识别运动相关的实体,或进行实体间的关系分类。现有的方法主要侧重于图像和文本之间的直接交互,这种方法会同时受到语义间隔和模态间隔的影响。为了解决这个问题,本研究采用了一种基于夏普利值的对比对齐方法,捕捉图像与文本对之间的语义和模态关系,从中获得连贯有效的多模态表征,从而增强抽取多模态信息的功能。模型的整体架构如图3所示。
将任务的输入设定为一段文本t={t1,…,tnt}以及对应的图片I,使用预训练的大规模多模态模型对图片生成描述c={c1,…,cnc}。该描述将作为方法中的重要中间桥梁,通过描述-文本和描述-图片的对齐弥补文本与图片之间的语义间隔和模态间隔。之后,使用预训练的语言模型和视觉模型对文本、描述及图片进行编码,表示为下式:
xt,Ht,xc,Hc=Transformer([t;c] ) 1);
xv,Hv=ImageEncoder(I) 2)。
下一步,使用夏普利值进行描述-文本和描述-图片的对齐。夏普利值源于合作博弈论[35],其是根据参与者各自在合作中的边际贡献,为参与者之间的总收益公平分配提供一种解决方案。在合作游戏中,假设有k个玩家,玩家集合表示为K={1,…,k},使用效用函数u:2k→R表示每个子集的玩家分配奖励。玩家i的夏普利值计算公式如下:
?准i(u)=sK\{i})[u(S∪{i} )-u(S) ] 3)。
以描述-文本对齐为例解释对齐的过程。具体为:输入k个描述-文本对{(xac,xat ) }ka=1,首先将k个描述视为玩家K={1,…,k},将某个描述集合S(由若干描述组成,为K的一个子集)对文本xjt的语义贡献定义为下式:
uj (S)=∑i∈Spisim(x jt,xic) 4);
pi= 5)。
有了如上定义后,可使用蒙特卡洛方法得到所有描述的夏普利值的近似{(uj),…,k(uj) }。使用对比学习的方法,最大化描述对齐对应的文本的边缘语义贡献,进而同时最小化描述对其他非匹配文本的语义贡献。定义损失函数如下式:
Lc2t=-∑k j=1[j (uj)-∑i≠jj (uj)] 6)。
同理,可将所有的k个文本视为玩家,得到损失函数Lt2c,并定义语义对齐的损失函数如下式:
Lsemantic=(Lc2t+Lt2c) 7)。
类似地,进行描述-图片对齐,损失函数如下式:
Lmodality=(Lc2v+Lv2c) 8)。
为了进行更为精细的跨模态融合,本研究设计了一种自适应注意力融合模块,该模块可根据2种模态的不同特征以及连接它们的上下文的相关性动态权衡不同特征在2种模态中产生的影响,从而增强实体识别和关系抽取的功能。
4.3.2 运动视频到细粒度文本生成技术
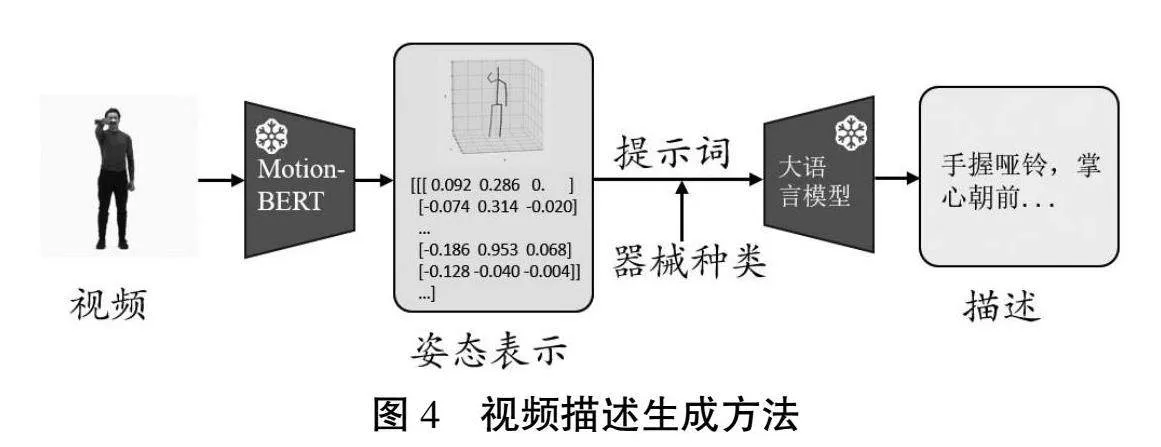
在图谱构建的过程中,本研究将运动视频作为独立的实体,并从网络中收集了大量的运动视频,但其中很多运动视频没有相应的文字描述,这会对用户精确地掌握运动动作造成困扰。为此,本研究构建了细粒度人体运动视频描述任务的对应数据集,并提出了一种使用大语言模型的解决方案。具体是:通过三维人体姿态识别技术捕捉视频中人体的姿态,并将姿态转换为视频与文本之间的中间表示;随后使用少样本学习方法,命令大语言模型根据示例样本和给定的中间表示生成人体动作的细粒度描述。方法的整体结构如图4所示。
首先,使用MotionBERT[36]从给定视频中提取三维人体运动信息。MotionBERT既可以确定每帧中人体骨骼关键点的三维坐标,也可以计算关节围绕运动树上父关节的局部旋转。获得人体关节三维坐标和局部旋转后,得到如下2种表示方式作为视频和描述文本的中间表示。
1)夹角表示。该方法假设人体的肢体为刚体,并直接计算人体不同肢体对之间的夹角。首先,定义一种人体坐标系统。将右髋至左髋的方向定义为Y轴,骨盆中心至腰椎的方向定义为Z轴,垂直于Y轴和Z轴方向定义为X轴。随后根据关节的自由度将人体的关节分为2类,如果关节只有一个自由度,则计算关节连接的两部分肢体之间的夹角;在其他情况下,计算肢体相对于人体坐标系各坐标轴的夹角。此外,使用人体相对于全局坐标系的跳跃、旋转和平移建模运动。
2)泰特布莱恩角表示。泰特布莱恩角也称为ZYX欧拉角,将3D坐标中的旋转表示为围绕z轴,y轴,x轴的3个连续旋转。首先从MotionBERT中得到关节旋转的四元数表示[36]q=[q ]T,根据相关研究[37],将其转换为泰特布莱恩角表示为下式:
?准=arctan2(q-(q21+q22)) 9);
θ=arcsin(-)) 10);
ψ=arctan2(q(q22+q23))11)。
对第i个视频的第t帧,使用上式计算所有关节的泰特布莱恩角Li,t∈R16×3。同时,取根节点(骨盆)在全局坐标系中的旋转作为全局信息gi,t=[xr,yr,zr],将它们拼接后得到当前时刻的中间表示为:Ri,t=[gi,t,Li,t]。
凭借预训练大语言模型的上下文学习能力3eC9Un0krmKkHR+gkaJWhQ==,分别根据以上2种中间表示设计提示词,生成视频描述。对于零样本场景,提示词由中间表示含义的描述(c)、任务提示(q)、注意事项说明(n)和各时刻中间表示序列(Ri)组成,可以表示为: Pi=[c,q,n,Ri] 。
对于单样本学习,在零样本提示词的基础上另外添加样例R0和I0,表示为: Pi=[c,q,n,R0,I0,Ri]。
将提示词输入大语言模型,即可运用大语言模型生成细粒度的视频描述文本,表示为=LLM(Pi) 。
最后,把生成的视频描述作为图谱中视频的属性,丰富图谱内容。
5 健身运动知识图谱平台
为了便于用户检索知识图谱的内容、了解健身运动知识,本研究设计并研发了知识图谱可视化平台。
首先,该展示平台采用了前后端分离框架,后端使用了MySQL数据库和Neo4j图数据库,完成了数据和知识的增删查改等工作,并向前端提供API接口,前端接受后端Json数据对图谱进行展示。该平台在部署阶段使用了Docker容器,显著减少了运维调试的成本。
其次,该平台界面分为“功能区”“检索区”“展示区”3个部分。在“功能区”,用户将看到本软件具有的功能的入口。在“检索区”,实体和关系按照不同的分类标准形成层级的树形结构。用户可在期望的分类下查询或搜索所需要的实体和关联知识。在“展示区”,该平台将对用户所选实体和相关关系进行展示。基于以上,用户可以用鼠标拖动实体节点,查看图谱的任意部分,还可以点击实体节点,查看实体的属性信息。对于视频和图片节点,用户点击该实体节点后,可以对视频或图片进行展示,还可以双击某个实体节点,对该实体的图的结构进行扩展,可以围绕该实体展示与该实体相关的知识。此外,该平台支持将查询结果以Json格式进行导出和对知识图谱的增、删、改等操作。
6 结束语
科学健身运动多模态知识图谱的构建工作刚刚起步,本研究介绍了该知识图谱构建的总体方案、知识获取技术、多模态技术等。未来工作将继续针对不同的健身运动类型,采用数据驱动的方法,利用自然语言处理、大语言模型、数据挖掘等技术进一步改进多模态实体和关联知识的抽取,逐步完善科学运动健身知识图谱平台。同时需要考虑百科知识等外部知识数据,研究实体链接和对齐等技术与已有领域图谱知识的关联。
参考文献:
[1] CHENG K, GUO Q, HE Y, et al. Artificial intelligence in sports medicine: Could GPT-4 make human doctors obsolete?[J]. Annals of Biomedical Engineering, 2023, 51(8): 1658-1662.
[2] SONG H, MONTENEGRO-MARIN C E, KRISHNAMOORTHY S. Secure prediction and assessment of sports injuries using deep learning based convolutional neural network[J]. Journal of Ambient Intelligence and Humanized Computing, 2021, 12: 3399-3410.
[3] NAIK B T, HASHMI M F, BOKDE N D. A comprehensive revi-ew of computer vision in sports: Open issues, future VjgHDkMHhwSJ/8unFqWSyA==trends and research directions[J]. Applied Sciences, 2022, 12(9): 4429.
[4] BAKAL G, TALARI P, KAKANI E V, et al. Exploiting semanti-c patterns over biomedical knowledge graphs for predicting treatment and causative relations[J]. Journal of Biomedical Info-rmatics, 2018, 82: 189-199.
[5] TENNAKOON C, ZAKI N, ARNAOUT H, et al. Leveraging biomedical and healthcare data[M]. New York: Academic Press, 2019: 107-120.
[6] VLIETSTRA W J, ZIELMAN R, VAN DONGEN R M, et al. Automated extraction of potential migraine biomarkers using a semantic graph[J]. Journal of Biomedical Informatics, 2017, 71: 178-189.
[7] ZHU X, LI Z, WANG X, et al. Multi-modal knowledge graph construction and application: a survey[J]. IEEE Transactions on Knowledge and Data Engineering, 2022, 36(2): 715-735.
[8] SUN R, CAO X, ZHAO Y, et al. Multi-modal knowledge graphs for recommender systems[C]//Proceedings of the 29th ACM international conference on information & knowledge managem-ent. New York: Association for Computing Machinery, 2020: 1405-1414.
[9] XU G, CHEN H, LI F L, et al. Alime mkg: A multi-modal knowledge graph for live-streaming e-commerce[C]//Proceedi-ngs of the 30th ACM International Conference on Information & Knowledge Management. New York: Association for Computing Machinery, 2021: 4808-4812.
[10] LI M, ZAREIAN A, LIN Y, et al. Gaia: A fine-grained multim-edia knowledge extraction system[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations. Stroudsburg: ACL, 2020: 77-86.
[11] YU H, CHENG S, NI B, et al. Fine-grained video captioning for sports narrative[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6006-6015.
[12] SUGLIA A, LOPES J, BASTIANELLI E, et al. Going for GOAL: A resource for grounded football commentaries[Z/OL]. (2022-11-08)[2024-02-15]. https://arxiv.org/abs/2211.04534.
[13] KANG H, LI Y, LIU D, et al. Human kinematics modeling and simulation based on OpenSim[C]//2021 International Confere-nce on Control, Automation and Information Sciences (ICCAIS). Piscataway: IEEE, 2021: 644-649.
[14] GUO C, ZUO X, WANG S, et al. Tm2t: Stochastic and tokeniz-ed modeling for the reciprocal generation of 3d human motions and texts[C]//European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022: 580-597.
[15] TEVET G, GORDON B, HERTZ A, et al. Motionclip: Exposing human motion generation to clip space[C]//European Confere-nce on Computer Vision. Cham: Springer Nature Switzerland, 2022: 358-374.
[16] JIANG B, CHEN X, LIU W, et al. MotionGPT: Human motion as a foreign language[Z/OL]. (2023-07-20)[2024-02-15] https://arxiv.org/abs/2306.14795.
[17] DONG X, GABRILOVICH E, HEITZ G, et al. Knowledge vault: A web-scale approach to probabilistic knowledge fusion[C]//Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: Association for Computing Machinery, 2014: 601-610.
[18] NICKEL M, MURPHY K, TRESP V, et al. A review of relationa-l machine learning for knowledge graphs[C]//Proceedings of the IEEE. Piscataway: IEEE, 2015, 104(1): 11-33.
[19] 叶帅. 基于Neo4j的煤矿领域知识图谱构建及查询方法研究[D]. 徐州:中国矿业大学,2019:1-81.
[20] 魏卉子. 煤矿安全融合知识图谱构建研究[D]. 徐州:中国矿业大学,2020:1-88.
[21] 袁芳怡. 面向制造业的知识图谱表示模型与构建技术研究[D]. 哈尔滨:哈尔滨工业大学,2019:1-63.
[22] 许力. 汽车智能客户服务系统的设计与实现[D]. 绵阳:西南科技大学,2020:1-66.
[23] CHEN X, SHRIVASTAVA A, GUPTA A. Neil: Extracting vis-ual knowledge from web data[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE, 2013: 1409-1416.
[24] LI M, ZAREIAN A, LIN Y, et al. Gaia: A fine-grained multim-edia knowledge extraction system[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations. Stroudsburg: ACL, 2020: 77-86.
[25] WEN H, LIN Y, LAI T, et al. Resin: A dockerized schema-guided cross-document cross-lingual cross-media information extrac-tion and event tracking system[C]//Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies( Demonstrations). Stroudsburg: ACL, 2021: 133-143.
[26] ORO-RUBIO D, NIEPERT M, GARCA-DURN A, et al. Answering visual-relational queries in web-extracted knowledge graphs[Z/OL]. (2019-05-03)[2024-02-15]. https://arxiv.org/abs/1709.02314.
[27] LIU Y, LI H, GARCIA-DURAN A, et al. MMKG: multi-modal knowledge graphs[C]//The Semantic Web: 16th International Conference, ESWC 2019. Cham: Springer International Publis-hing, 2019: 459-474.
[28] WANG M, WANG H, QI G, et al. Richpedia: A large-scale, comprehensive multi-modal knowledge graph[J]. Big Data Research, 2020, 22: 1-11.
[29] ALBERTS H, HUANG T, DESHPANDE Y, et al. Visual Sem: A high-quality knowledge graph for vision and language[Z/OL]. (2021-10-20)[2024-02-15] . https://arxiv.org/abs/2008.09150.
[30] LI J, FEI H, LIU J, et al. Unified named entity recognition as word-word relation classification[Z/OL]. (2021-12-19)[2024-02-16]. https://arxiv.org/abs/2112.10070.
[31] YAN H, GUI T, DAI J, et al. A unified generative framework for various NER subtasks[Z/OL]. (2021-06-02)[2024-02-16]. https://arxiv.org/abs/2106.01223.
[32] LU Y, LIU Q, DAI D, et al. Unified structure generation for un-iversal information extraction[Z/OL]. (2022-03-23)[2024-02-17]. https://arxiv.org/abs/2203.12277.
[33] XIA Y, ZHAO Y, WU W, et al. Debiasing generative named entity recognition by calibrating sequence likelihood[C]//Proc-eedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Stroudsb-urg: ACL, 2023: 1137-1148.
[34] XIONG W, SONG Y, WANG P, et al. Rationale-enhanced language models are better continual relation learners[Z/OL].(2023-10-10)[2024-02-17]. https://arxiv.org/abs/2310.06547.
[35] DUBEY P. On the uniqueness of the shapley value[J]. Intern-ational Journal of Game Theory, 1975, 4(3): 131-139.
[36] ZHU W, MA X, LIU Z, et al. Motionbert: A unified perspective on learning human motion representations[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 15085-15099.
[37] BERNER P, TOMS R, TROTT K, et al. Technical concepts: Orientation, rotation, velocity and acceleration, and the SRM[S/OL].[S.I.]:[s.n], 2008: 39[2023-12-15]. https//sedris.org/wg8home/document.htm.
