NDP-FD6:一种IPv6网络NDP洪泛行为多分类检测框架
2024-10-14夏文豪张连成郭毅张宏涛林斌



摘 要:当前NDP洪泛行为检测研究主要集中于RA和NS洪泛行为的检测,对于NDP协议中其他报文洪泛行为的检测能力不足。此外,传统阈值规则检测方法存在动态性差、准确率低的问题,而基于人工智能的检测方法大多只能进行二分类检测,缺乏多分类检测能力。为此,提出一种针对NDP协议洪泛行为的多分类检测框架,并提出基于时间间隔特征的NDP协议洪泛行为检测方法。通过流量收集、数据处理等过程构建了首个用于NDP洪泛检测的多分类数据集,并对比使用了5种机器学习和5种深度学习算法来训练检测模型。实验结果表明,利用机器学习中XGBoost算法的检测准确率可达99.18%,深度学习中的Transformer算法的检测准确率可达98.45%。与现有检测方法相比准确率更高,同时该检测框架可以检测出NDP协议5种报文的9类洪泛行为,并可对洪泛行为进行多分类划分。
关键词:IPv6; NDP; 洪泛检测; DDoS; 机器学习; 深度学习
中图分类号:TP393.08 文献标志码:A
文章编号:1001-3695(2024)10-037-3141-08
doi:10.19734/j.issn.1001-3695.2023.12.0633
NDP-FD6: multi-classification detection framework forNDP flooding behaviors in IPv6 network
Xia Wenhao1a, Zhang Liancheng2, Guo Yi2, Zhang Hongtao1b, Lin Bin1a
(1.a.School of Cyber Science & Engineering, b.Network Management Center, Zhengzhou University, Zhengzhou 450001, China; 2.College of Cyberspace Security, Information Engineering University, Zhengzhou 450002, China)
Abstract:Current researches on NDP flooding behavior detection mainly focus on detecting RA flooding and NS flooding behaviors, and there is insufficient flooding detection for other messages of the NDP protocol. Moreover, traditional threshold rule detection methods suffer from poor dynamics and low accuracy, while most of the AI-based detection methods can only perform binary classification detection, and there are still challenges in performing multi-classification detection. In short, there is a lack of corresponding research in multi-classification flooding detection of all messages of NDP protocol. Therefore, this paper proposed a multi-classification detection framework for NDP protocol flooding behaviors, and proposed a flooding behavior detection method for NDP protocol based on time interval characteristics. The framework constructed the first multi-classification dataset for NDP flooding detection through the processes of traffic collection and data processing, it compared and used 5 machine learning and 5 deep learning algorithms to train the detection model. The experimental results show that the detection accuracy of the XGBOOST algorithm in machine learning can reach 99.18%, and the detection accuracy of the Transformer algorithm in deep learning can reach 98.45%. Compared with the existing detection methods, the accuracy is higher. Meanwhile, the detection framework can detect 9 types of flooding behaviors for all 5 types of messages of NDP protocol and classify the flooding behaviors into multiple types.
Key words:IPv6; NDP; flooding detection; DDoS; machine learning; deep learning
0 引言
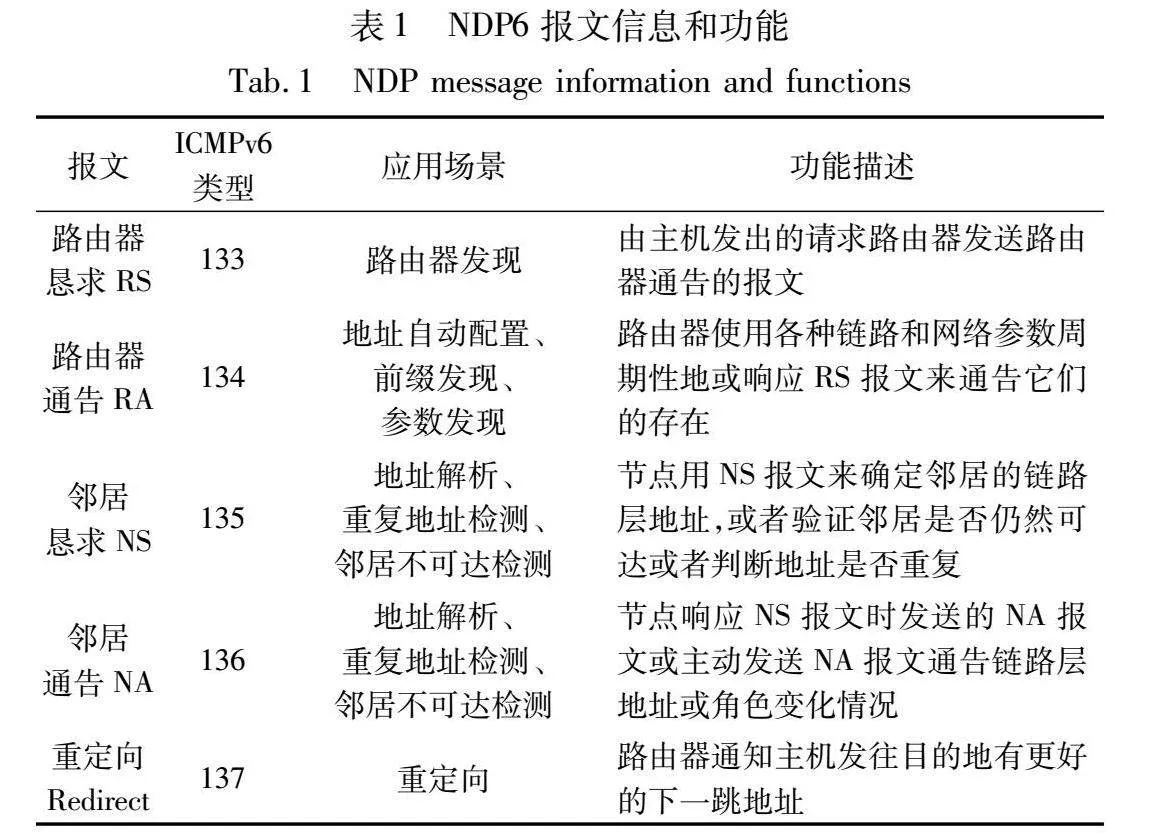
邻居发现协议(neighbor discovery protocol,NDP)是IPv6协议体系的关键组成部分,描述了IPv6网络的基本通信机制,结合了IPv4中的地址解析和重定向功能,并进一步增加了邻居不可达检测(neighbor unreachability detection,NUD)和重复地址检测(duplicate address detection,DAD)等新功能,从而显著提高了IPv6网络环境的通信效率。表1显示了NDP协议的5种报文信息和功能[1]。
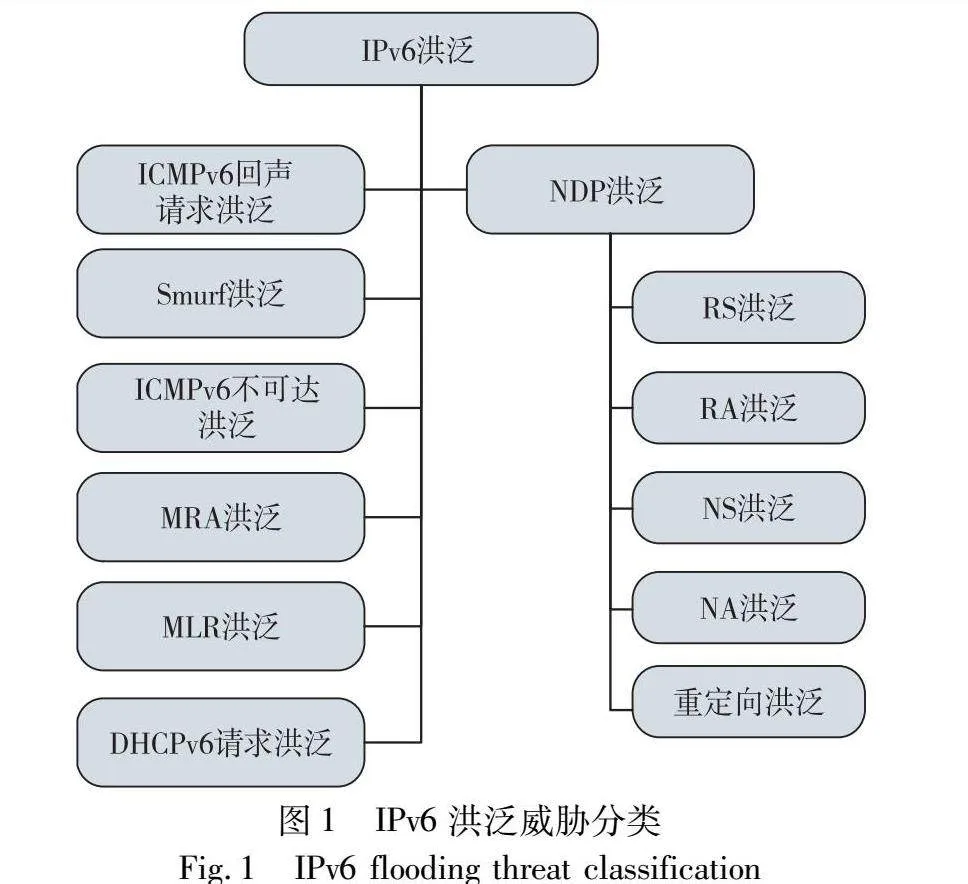
尽管NDP协议为IPv6网络带来了诸多优势,但它也存在一些安全漏洞。在默认情况下,NDP协议缺乏对报文的身份验证机制,这意味着报文发送者无须提供身份验证信息,为威胁者提供了进行伪造和欺骗的机会,中间人(man-in-the-middle,MITM)和拒绝服务(denial-of-service,DoS)等安全威胁在NDP中较为常见[2,3]。洪泛威胁具有极大的破坏性且难以防范,会在短时间内向目标设备(如路由器、主机)发送大量虚假或无用报文,使目标节点无法为正常用户提供服务。IPv4网络洪泛威胁主要有传输控制协议(transmission control protocol,TCP)、同步(synchronize,SYN)泛洪、用户数据报协议(user datagram protocol,UDP)泛洪和因特网控制报文协议(Internet control message protocol,ICMP)泛洪等,而在IPv6网络环境中也同样存在洪泛威胁,如图1所示。
本文关注于NDP洪泛威胁,它们通常发送大量NDP恳求或通告报文,伪造源地址或使用随机源地址,使目标网络中的设备无法准确地识别和处理这些报文。这种威胁方式使目标网络中的设备不断地进行NDP报文处理,消耗大量的中央处理器(central processing unit,CPU)、内存和带宽资源,导致网络性能下降甚至瘫痪[4,5]。
现有针对NDP洪泛威胁的检测方法主要有阈值规则方法和人工智能方法。其中,阈值规则方法主要涉及基于流的表示、动态阈值、基于熵的计算等方法,而人工智能方法则主要是先利用信息增益比(information gain ratio,IGR)、主成分分析(principal component analysis,PCA)等方法进行特征选择,然后选择机器学习或者深度学习模型进行训练,最后根据模型检测异常流量。然而,阈值规则方法缺少动态性,由于洪泛威胁方法的多样性以及正常流量与恶意流量间阈值设定的难度,要想为洪泛检测设定一套绝对可靠的规则是极其困难的。而机器学习或深度学习方法则大多关注于RA报文、NS报文洪泛行为的检测,缺少对NDP中其他报文洪泛行为的检测能力,此外只能进行二分类检测,无法进行多分类检测[6,7]。
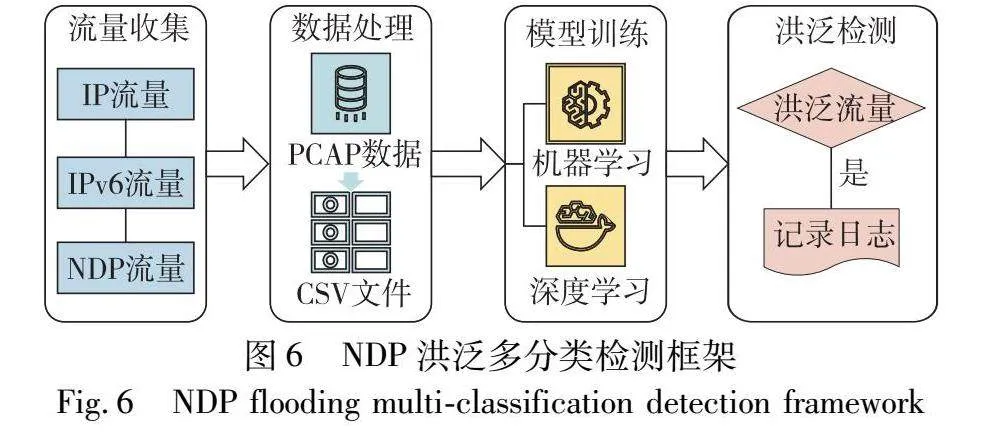
针对上述问题,本文提出一种NDP协议洪泛行为的多分类检测框架,集成了机器学习和深度学习算法,可以对NDP五种报文的9类洪泛行为进行检测。该框架包含四个阶段:首先是流量收集阶段,从复杂的网络环境中收集所需的NDP流量;然后是数据处理阶段,该阶段是重要和关键的一步,需要对NDP原始流量处理,分析提取可用字段,并且需要对数据集进行多分类标签标记。此外,在本文中通过对数据集分析,创新性提出关键特征——数据包时间间隔特征;接着是模型训练阶段,将上一阶段得到的数据集,选择合适的机器学习和深度学习算法,进行训练得到检测模型;最后是洪泛检测阶段,将检测模型部署在网络中,来检测NDP洪泛行为。
1 背景知识
1.1 NDP洪泛威胁
根据洪泛报文的不同,NDP洪泛威胁可分为RS洪泛、RA洪泛、NS洪泛、NA洪泛和重定向洪泛五种。
1.1.1 RS洪泛
RS报文用于主机在IPv6网络中主动发现路由器,以获取路由器的相关信息[8]。在RS报文洪泛中,会发送大量的伪造RS报文,通常使用随机化源IPv6地址,以使目标网络中的路由器无法准确识别和处理这些报文。这种洪泛威胁使得目标网络中的路由器不断进行RS报文的处理和响应,消耗大量的CPU、内存和带宽资源,导致网络性能下降甚至瘫痪。
1.1.2 RA洪泛
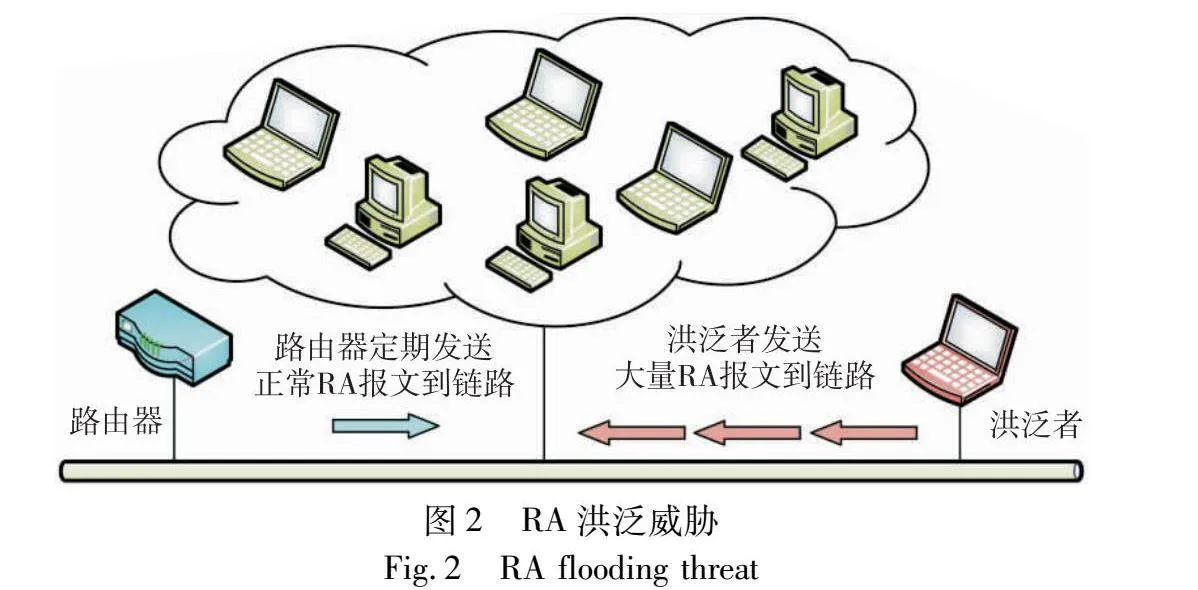
RA报文用于IPv6网络中的路由器发现和地址配置,路由器通过发送RA报文来通告网络中的设备有关网络配置和路由信息[9]。然而,接收者并不会验证所收到的RA报文,收到伪造RA报文的节点会盲目地根据RA报文更新自己的配置与参数。恶意节点可以传播虚假的地址前缀信息,以重新路由合法流量,阻止受害者访问所需的网络。RA洪泛威胁如图2所示,该洪泛威胁可以用不同的网络前缀洪泛本地网络,并让主机基于宣布的前缀更新网络参数,从而导致系统不可用和无响应。
1.1.3 NS洪泛
NS报文用于IPv6网络中的地址解析、重复地址检测等功能,设备通过发送NS报文来查询目标设备的媒体访问控制(media access control,MAC)地址等信息[10]。在NS报文洪泛中,会发送大量的伪造NS报文,这些报文通常使用随机化源IPv6地址。这种洪泛威胁旨在淹没目标网络中的主机,使其不断处理和响应这些伪造的NS报文,受害者节点被迫在邻居缓存表中创建虚假的IPv6地址和对应的MAC地址表项。
1.1.4 NA洪泛
NA报文同样用于IPv6网络中的地址解析、重复地址检测等功能,设备通过发送NA报文来回应邻居的查询请求[11]。这种泛洪行为将大量具有伪造源地址的NA报文发送给受害者主机。受害者主机将接收这些数据包并不断更新其邻居缓存表,消耗大量的CPU资源。此外,重复地址检测过程中可以不断发送大量伪造的NA报文,回复正在进行重复地址检测(duplicate address detection,DAD)验证的NS报文,使受害者节点错误地认为该地址已被占用,从而无法使用该地址。
1.1.5 重定向洪泛
重定向报文用于通知目标设备更优的路由信息,以便进行数据包转发[12]。这种洪泛行为通过发送大量的虚假重定向报文来干扰网络中的节点,造成网络拥塞和服务中断。节点接收到重定向报文时,它会更新其本地路由表,将原本的下一跳地址替换为重定向报文中指定的新下一跳地址。通过发送大量的虚假重定向报文,目的是让受害节点频繁地更新其路由表,从而导致网络中的受害节点造成无法与目的节点进行正常通信。
1.2 分类算法
本节介绍本文测试对比所用10种分类算法中典型的4种。其中,随机森林是一种经典分类算法,XGBoost则是在随机森林算法思想上更进一步地改进。人工神经网络(artificial neural network,ANN)和Transformer都属于深度学习算法的范畴。其中,ANN是起源较早的一种算法,而Transformer则是最近备受瞩目的算法[13]。
1.2.1 随机森林算法
随机森林是一种基于集成学习的机器学习算法,通过构建多个决策树对数据进行全面分析。随机森林的名称源于其构建过程中的随机性。在构建每个决策树时,算法随机选择部分特征分割数据,增加模型多样性,降低过拟合风险。随机森林能处理高维度数据,保持良好性能。此外,随机森林能处理缺失值和异常值,不影响模型构建。随机森林的预测结果相对稳定,因为由多个决策树组成,每个决策树的预测结果都会影响最终结果。
1.2.2 XGBoost算法
XGBoost是一种高效且具备诸多优点的梯度增强算法,基于梯度提升决策树,通过梯度信息优化目标函数,构建出高效、可扩展且并行化的机器学习模型。它具备出色的优化效果、可扩展性、灵活的目标函数、正则化等功能[14]。在构建增强模型时,XGBoost采用梯度提升决策树方法,每步拟合一个决策树模型,并将前一步的残差作为新的输入特征。训练过程中,XGBoost计算样本权重,以关注被错误分类或未充分考虑的样本。同时,它提供灵活的目标函数和损失函数接口,适应各种监督学习任务。
1.2.3 ANN算法
ANN,即人工神经网络,是一种深度学习分类算法。它由多个神经元组成,这些神经元相互连接,形成类似于人脑神经元网络的系统。每个神经元接收来自其他神经元的信号,通过一个非线性输入函数处理这些信号,并将处理过的信号传递给其他神经元。这些连接称为边,它们具有可调整的权重,这些权重在学习过程中会进行微调。权值的作用是调整信号强度,影响传输信号的强弱。
1.2.4 Transformer算法
Transformer是2017年由Vaswani等人首次提出的深度学习算法,其核心是自注意力机制[15]。这种机制让模型在处理序列数据时能同时考虑所有位置,更好地捕捉上下文信息。这改变了传统深度学习模型处理序列数据的思维方式,使Transformer在处理自然语言数据时有强大能力,更好地理解语言的内在关系和语义信息。此外,Transformer还广泛应用于计算机视觉、推荐系统和其他序列数据建模任务,展示其多领域适用性。
2 相关工作
在设计之初,IPv6就充分考虑了安全问题,将IPSec(Internet protocol security)集成为其核心协议的一部分。IPSec作为一项安全服务,提供了加密、认证和完整性保护等功能,旨在确保IPv6数据包在传输过程中的安全性。此外,为了提高NDP协议的安全性,引入了安全邻居发现(secure neighbor discovery,SEND)机制,该机制保护邻居节点的发现、地址解析和重定向等过程[7]。
针对NDP洪泛威胁检测,现有研究可分为阈值规则方法和人工智能方法两大类。前者通过定义检测阈值或规则来将正常流量和异常流量分开,而后者则利用机器学习或者深度学习等,通过对数据集进行学习训练,生成异常流量检测模型。
2.1 IPSec和SEND
IPv6扩展报头的出现为其提供了对认证及机密性的扩展能力。IPSec最初作为IPv6的基本协议套件,旨在保护IP通信的安全性和隐私。在保护NDP协议方面,IPSec使用加密算法对NDP报文进行加密,确保其机密性,防止敏感信息被窃听。同时,IPSec通过完整性校验算法计算和验证NDP报文,确保其传输过程中未被窜改。最后,IPSec利用数字签名机制(如RSA)对NDP报文进行签名和验证,确保真实性和发送者身份。
SEND是IPv6中的一种安全增强的邻居发现协议,旨在保护NDP协议的安全[8]。SEND解决了原始IPv6规范中存在的安全漏洞和威胁风险。SEND引入了邻居验证机制,节点通过发送验证请求和应答报文来验证邻居节点的真实性。同时,使用时间戳和序列号来防范重放威胁,节点验证报文的时间戳和序列号,以确保报文的顺序和合理的时间间隔。最后,SEND支持对NDP报文进行完整性校验和加密,使用数字签名和公钥验证来保护报文的完整性和真实性,并使用对称密钥加密算法来确保报文的机密性。
2.2 阈值规则方法
除了IPSec和SEND机制,对于洪泛威胁检测,阈值规则是一种广泛应用的检测方法,该方法通常定义一组识别正常和异常流量的检测规则。
文献[9]介绍了一种用于检测IPv6网络中RA洪泛的混合熵和自适应阈值方法。通过将熵机制和自适应阈值相结合,提供一种有效的RA洪泛检测方法,其自适应阈值可以根据网络流量规模动态地调整检测阈值大小和选择正确的熵特征,能够检测各种RA洪泛的情况,包括使用了规避技术,根据实验结果,该技术的检测准确率达到了98%。然而,该检测方法只能检测RA洪泛,对于其他类型的NDP洪泛威胁无法有效检测。此外,该方法只能适用于小规模的网络流量。
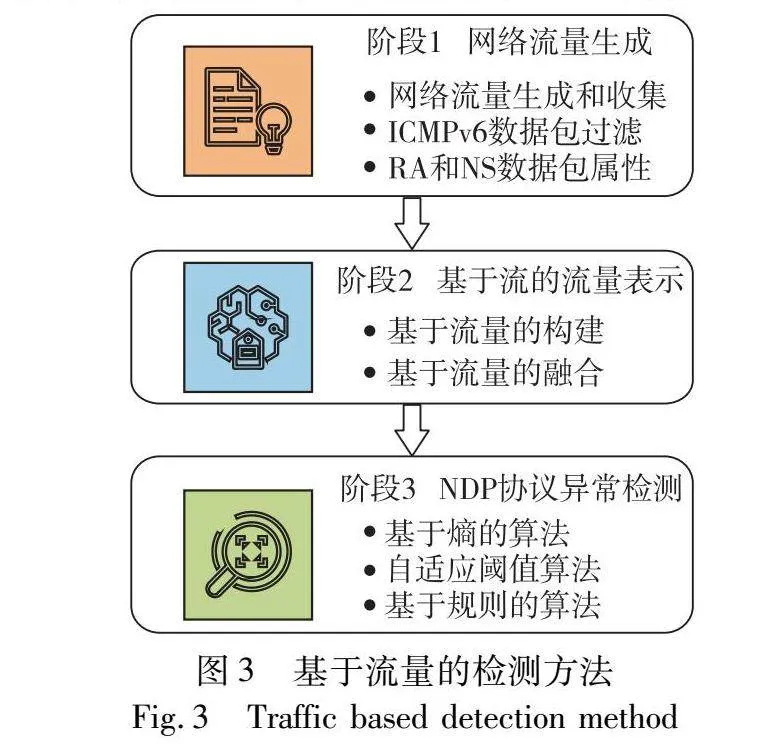
在面对大规模网络流量时,文献[10]提出了一种基于流量的方法来检测NDP中的异常行为,通过收集网络流量数据,并利用熵和流量属性来检测NDP流量中RA和NS洪泛。该方法使用流量表示而不是基于数据包的表示来提高检测的效率,并利用熵和流量属性来计算NDP流量的异常程度,从而能够准确地检测出RA和NS洪泛行为。同样,该方法只能检测RA和NS洪泛行为,对于其他类型的NDP洪泛行为可能不适用。此外,由于该方法仍然需要处理大量的网络流量数据,对于高速网络可能存在效率问题。
文献[11]提出了一种基于流量的方法来检测NDP中的异常行为,同样是针对NDP协议中的RA和NS洪泛行为进行检测,如图3所示。与文献[10]不同的是,文献[11]提出了基于熵的算法、自适应阈值算法和基于规则的技术来检测NDP中的异常行为。其创新在于采用了流量表示和基于熵的算法来检测异常行为,以适应高速网络。同时,自适应阈值算法可以根据实际情况动态调整阈值,提高检测准确性。此外,基于规则的技术可以根据特定规则对网络流量进行分类,进一步提高检测效果。
2.3 人工智能方法
相比传统的阈值规则方法[12],人工智能方法在检测准确率上有着明显提高,检测速度也表现出色。此外,人工智能方法还具有更高的灵活性和适应性,并且,随着人工智能的发展,其应用前景广阔,具有巨大的潜力和发展空间。
文献[13]最早提出用人工智能方法解决IPv6邻居发现协议洪泛威胁,旨在研究使用机器学习机制来检测NDP洪泛威胁。使用机器学习的优势在于可以不依赖威胁签名,而是学习威胁属性的更广泛定义。通过使用机器学习中经典的K最近邻(K-nearest neighbor,KNN)、C4.5、支持向量机(support vector machine,SVM)等算法训练检测模型。然而,该研究的检测对象只有RA、NS报文,并且检测效果并不理想。
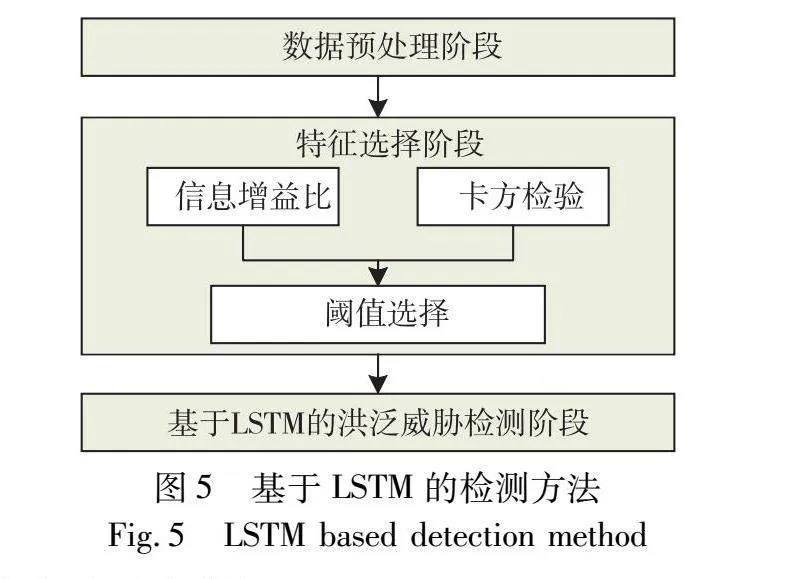
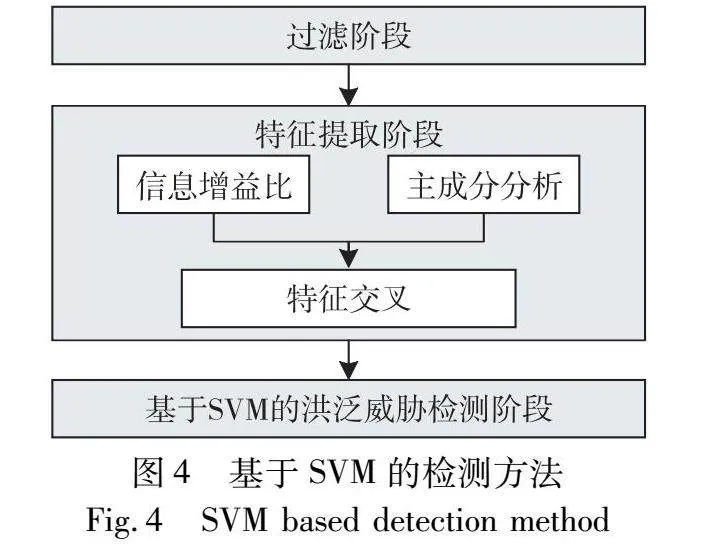
文献[14]提出一种基于机器学习方法来检测IPv6网络中RA洪泛行为,如图4所示。相比于上一方法,该方法首先利用信息增益比和主成分分析进行特征选择,然后利用支持向量机构建预测模型,以检测输入流量的异常情况。然而,该文献没有对所提出方法与其他方法进行比较,缺乏与现有方法的性能对比。此外,该方法只能检测RA报文洪泛行为,缺乏对NDP协议中其他报文洪泛行为的检测能力。
相比与机器学习方法,文献[15]使用了深度学习进行IPv6协议异常入侵检测的研究,提出了一种基于反向传播神经网络的ICMPv6洪泛威胁检测框架,并通过监督学习算法进行训练。同样,该方法只能检测NDP协议中的RA报文。此外,该方法缺乏对实际应用场景的讨论和验证,需要更多的实验和实际案例来验证该方法的有效性。
文献[16]同样提出了一种基于深度学习的方法,用于检测ICMPv6分布式拒绝服务(distributed denial of service,DDoS)洪泛威胁,如图5所示。该论文首先使用集成特征选择技术来选择对检测洪泛威胁有重要贡献的流量特征,接着对基于深度学习的分类器进行了性能比较分析,以确定最佳的深度学习模型,最后将最佳的深度学习分类器与基于选定特征的集成特征选择相结合。然而,该检测方法只能检测出RA、NS、NA报文,不能检测出NDP协议其他报文洪泛行为。此外,该框架采用的是二分类检测,只能将报文分为正常报文和洪泛报文两类。
作为IPv6洪泛威胁检测领域中的最新研究,文献[17]提出了一种基于ICMPv6协议的DDoS洪泛威胁检测框架,该框架使用机器学习和深度学习算法对数据进行分类,并通过实验评估了不同分类算法的性能。通过与其他机器学习方法相比,该框架具有更高的分类精度和更低的误报率。然而,该检测框架也存在一些局限性,如它只能检测出RA报文洪泛行为以及一些其他ICMPv6报文洪泛行为,而不能检测NDP协议其他报文洪泛行为。同样,该框架采用的是二分类检测方法,只能将报文分为正常报文和洪泛报文两类。
2.4 现有方法对比分析
尽管IPSec提高了IPv6及NDP安全性,但IPSec的配置需要考虑加密算法、密钥管理、身份验证和安全策略等多个方面,因而复杂性高。同时,IPSec对数据包进行加密和解密的过程会引入一定的性能开销。此外,SEND在保护NDP报文方面也存在一定的局限性:首先,加密生成地址(cryptographically gene-rated address,CGA)无法识别合法节点的特征,因此,威胁者可以通过修改CGA参数来影响目标节点性能;此外,使用SEND会增加进程开销,导致较长的处理时间,因此,SEND不适合在IPv6链路本地网络中大规模部署。现有方法对比分析如表2所示。
对比阈值规则和人工智能两类方法,基于阈值规则的检测方法是将传入的网络流量与一组预定义的规则进行比较,这些规则可以将正常流量与洪泛流量分开。但是由于洪泛威胁方案的多样性以及定义正常流量和恶意流量之间阈值的难度,所以为洪泛检测设置万无一失的规则极其困难。
在数据规模较小的情况下,人工智能模型在面对泛洪威胁检测时的准确率,相对于传统检测方法略有优势,但在其他方面并没有表现出其检测优势,检测性能并不突出。但是随着系统扩展到更大的数据集,研究人员发现深度学习模型最终变得比其他已建立的洪泛检测工具更准确、错误更少,包括基于其他机器学习算法的工具,包括支持向量机和决策树。因此,基于人工智能的检测研究是未来的趋势[16]。
然而,当前的人工智能方法在进行NDP协议洪泛威胁检测时存在一些局限。首先,这些方法大多只能对NDP协议中的RA报文进行检测,而无法对NDP协议的全部报文类型进行检测。其次,目前的研究主要集中在二分类检测,无论是只研究RA报文洪泛威胁或者是包含多种报文的ICMPv6协议洪泛威胁,均无法对洪泛行为进行更为精细的分类[17]。
3 IPv6网络NDP洪泛行为多分类检测框架
为解决当前NDP洪泛检测研究中存在的问题,本文提出一种IPv6网络NDP洪泛行为多分类检测框架。该框架的主要目标是能够对NDP协议中全部的五种报文进行准确的多分类检测,并克服现有研究中检测不全面、分类不详细等问题。
该检测框架结构包括流量收集、数据处理、模型训练和洪泛检测四个阶段,如图6所示。
3.1 流量捕获及NDP流量收集
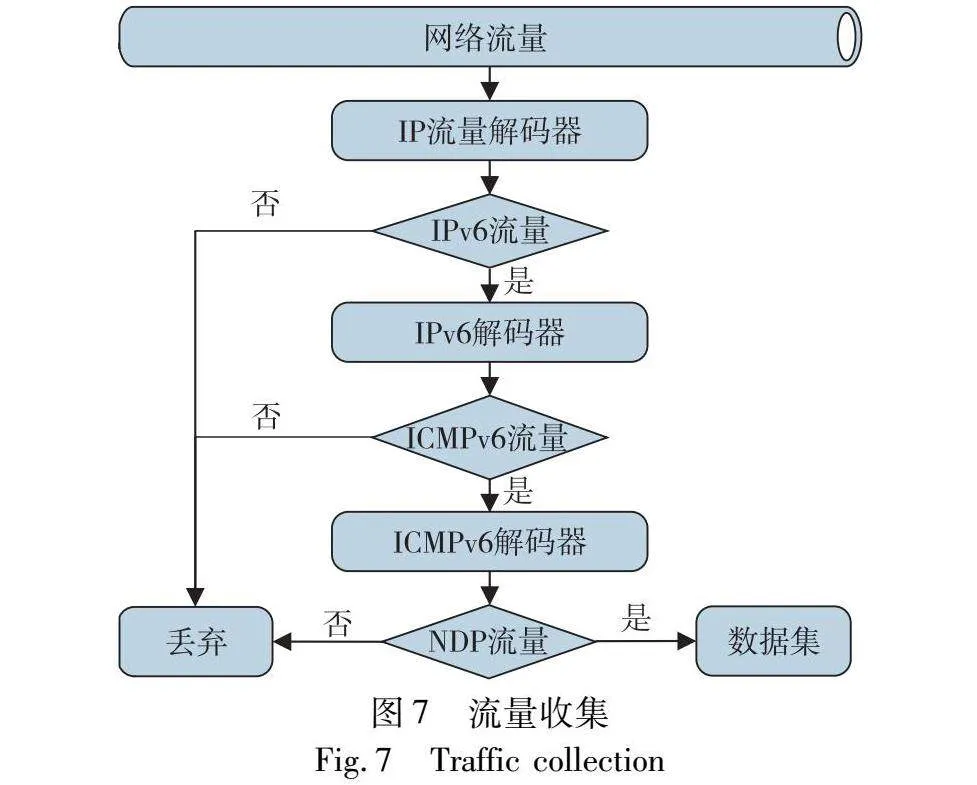
本文的研究对象是NDP协议洪泛威胁,因此需要收集NDP流量,NDP协议包含了5种类型的报文,即ICMPv6报文类型133~137的报文。流量收集阶段的目的就是从复杂的网络环境中捕获和过滤的实验所需的NDP流量,如图7所示。
这一阶段包含捕获模块和过滤模块。首先,捕获模块会先捕获目标网络的流量。通过使用网络抓包工具,如tcpdump或Wireshark等来捕获网络流量,这些工具可以监听、收集网络接口上的流量。其次,过滤模块负责过滤掉IPv4流量,并收集IPv6流量中的NDP流量。可以使用过滤器或正则表达式等工具,从捕获的流量中过滤出IPv6流量,并从中提取NDP报文,并将其保存到一个数据集中,用于后续的数据处理、模型训练以及洪泛检测。通过以上两个模块可以有效地捕获和过滤出网络流量中的NDP流量,为后续检测提供数据基础。
3.2 数据处理及时间间隔特征数据集构建
该阶段的主要目的是将前一阶段所收集的NDP流量数据进行处理,涉及到数据的清洗、预处理等步骤。在清洗阶段,需要处理缺失值、删除重复值、检查异常值等,以便确保数据的质量和可靠性。预处理阶段则包括数据规范化、标准化、特征选择等,并将数据转换为适合机器学习算法的格式,以便进行训练和预测。
首先,解析原始NDP流量的数据包捕获(packet capture,PCAP)文件,将数据包的内容提取出来,包括目的MAC地址、目的IPv6地址、协议类型、报文类型、数据包长度等信息,并将提取出的特征信息存入到逗号分隔值(comma separated values,CSV)文件中。接着,进行数据清洗,需要根据具体情况选择不同的方法来处理缺失值。例如,对于缺失的数值型数据,可以通过均值插补或中位数插补等方法来填充缺失值;对于缺失的分类数据,则可以使用众数插补或平均值插补等方法。同时,还需要删除重复值和检查异常值,以确保数据的质量和可靠性。
在预处理阶段,需要对数据进行规范化或标准化,以便将数据转换为适合机器学习算法的格式。例如,可以通过最小最大规范化将数据转换为一个较小的范围,或者通过标准化将数据的均值为0,标准差为1。此外,还需要进行特征选择,以便选择与预测目标相关的特征,并去除无关的特征。然而,除了可以直接从报文中提取的特性信息外,本文还有两个特征:与上一个报文的时间间隔和与上一个报文的时间间隔,则需要经过对数据进行再次计算而获得。
算法1 数据包时间间隔特征算法
输入:data.csv。
输出:data_interval.csv。
//计算Former Interval(与上一个数据包的时间间隔)
a)for i in range(len(data)) //遍历数据集文件
b) if i>0
c) former_interval=(data[i]['Time']-data[i-1]['Time']).total_seconds()
//计算与上一个数据包的时间间隔特征值
d) data[i]['Former Interval'] = former_interval
e) else
f) data[i]['Former Interval'] = None
// 计算Latter Interval(与下一个数据包的时间间隔)
g) for i in range(len(data) - 1)
h) latter_interval=(data[i + 1]['Time'] - data[i]['Time']). total_seconds()
//计算与下一个数据包的时间间隔特征值
i) data[i]['Latter Interval'] = latter_interval
j) data[-1]['Latter Interval'] = None
算法1描述了数据包时间间隔特征的计算方法,输入为已经完成数据处理的含有时间戳的CSV数据集文件,该算法将通过计算相邻两个数据包时间戳差值为数据集新增两个特征,分别是上一个报文发送时间和当前报文发送时间的时间差以及当前报文发送时间和下一个报文发送时间的时间差。
这两个时间间隔特征是本文在NDP洪泛威胁检测研究领域首次提出的。在传统的NDP洪泛威胁检测方法中,往往只考虑了报文发送时间,而忽略了不同报文之间的时间间隔信息。然而,在实际网络环境中,威胁者往往会采用特定策略来避免被传统方法检测到。例如,威胁者可能会采用时间延迟方式,将威胁报文分批次发送,以避免被传统方法检测到。因此,考虑时间间隔特征对于提高NDP洪泛威胁检测的准确率具有重要的意义。本文提出的两个时间间隔特征分别是上一个报文发送时间和当前报文发送时间的时间差以及当前报文发送时间和下一个报文发送时间的时间差。通过计算这两个时间间隔特征,可以更加准确地描述网络流量行为,并提高NDP洪泛威胁检测的准确率。
3.3 NDP洪泛检测多分类模型训练
这一阶段的目的是将上一阶段得到的数据集选择合适的机器学习和深度学习算法进行模型训练。模型训练是NDP洪泛检测中的关键步骤,它旨在从数据中学习模式和关联,以便模型能够在未来的数据上进行准确的识别并分类NDP洪泛流量。
在模型训练阶段,该框架选取了10种常用的分类算法对NDP洪泛多分类检测数据集进行训练。这10种分类算法包括5种机器学习算法,如随机森林、XGBoost、Lightgbm、支持向量机(SVM)和朴素贝叶斯;以及5种深度学习算法,如人工神经网络(ANN)、卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆网络(LSTM)和Transformer。
在前面步骤中收集并处理得到的数据集,会经过这些不同的分类算法进行训练,以得到检测模型。这些模型在训练过程中,不同的分类算法有着不同的特点和适用范围,因此会根据各自分类算法的特性生成不同的检测模型。其中,机器学习方法适用于许多传感器数据的分析和特征提取,解决较小规模的问题。机器学习算法通常具有较好的可解释性,可以帮助分析人员理解模型的决策过程。对于一些较简单的问题,机器学习模型通常需要较少的计算资源和数据量,因此更容易部署和维护。深度学习算法可以自动学习和提取数据中的特征,无须手工设计特征,这对于处理大规模和高维度数据非常有帮助。深度学习模型在大规模数据上训练后,通常具有更好的泛化能力,可以应对不同类型和不同来源的洪泛数据。
3.4 NDP洪泛行为检测
该框架的核心部分之一是NDP泛洪行为检测阶段,该阶段旨在准确且高效地检测NDP的洪泛行为。通过将上一阶段训练出的检测模型部署在网络中,该阶段能够实时监控网络流量,并迅速识别出异常的NDP洪泛行为。一旦检测到可疑活动,该阶段会立即触发相应的响应措施,阻止恶意流量、隔离受影响的节点,从而保护网络资源和服务的正常运行。
此外,NDP泛洪检测阶段还具备强大的记录功能,能够详细记录所有与NDP泛洪检测相关的事件和警报。这些记录为后续详细的分析提供了重要的依据,帮助管理员更好地理解洪泛威胁的行为模式,从而制定更加有效的防御策略。
4 实验对比与结果分析
4.1TjvOzWt3fC9lxPds5XL/g1M3mCGHFypgpdCYzFIt44U= 实验数据
本文实验所用的数据集,参考了文献[13,15]中的NDP洪泛流量收集方法。其中,真实流量来自郑州大学网络管理中心网络安全实验室,洪泛流量则在实验室网络环境中使用THC-IPv6工具生成。
此外,对THC-IPv6工具[18,19]进行了改进升级,使其可以设置更多参数来自定义NDP报文的字段值,并且可以设置数据包的发包速度。
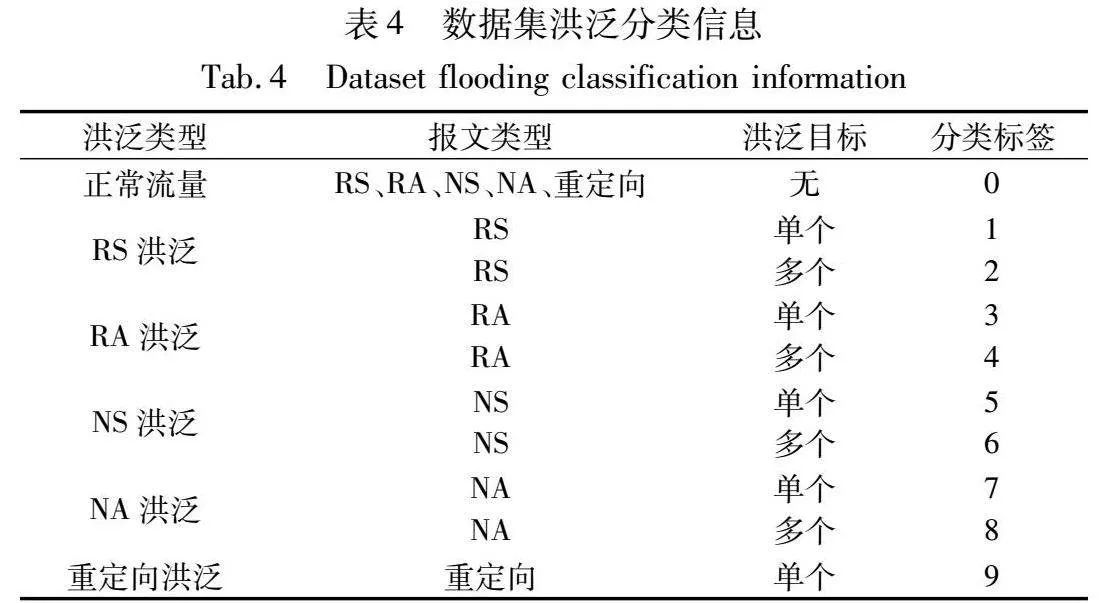
数据集包括14个特征信息,共有349 371条流量,其中正常流量42 941条,每类异常流量均为34 000条左右。针对每一类洪泛,设置了四个不同的发包速度,分别是每秒1个数据包、每秒10个数据包、每秒100个数据包和每秒1 000个数据包。数据集信息如表3所示,数据集洪泛分类信息如表4所示。
数据集由正常和洪泛流量组成,包括正常流量和9类异常流量,涉及NDP协议的五种报文,其中RS洪泛、RA洪泛、NS洪泛、NA洪泛各两类。
RS洪泛可以根据目的地址字段,分为针对链路内某一具体路由器进行洪泛,或是将目的地址设为ff02::2,针对链路内所有路由器进行洪泛。RA洪泛同理,可以将目标设置为链路内某一具体主机,或是将目的地址设为ff02::1,向链路内所有主机进行洪泛。NA洪泛同样根据目的地址字段,分为针对单一目标洪泛和多个目标洪泛。而NS洪泛则是根据报文中的目标地址字段,来选择洪泛目标是某一具体主机还是所有主机。上述四种报文洪泛分类都是根据洪泛的目标数量,而重定向洪泛只有一类,它只能针对单个目标进行洪泛。
4.2 评价指标
本节描述用于评估NDP洪泛检测框架性能的评估指标。在二分类条件下,可以很轻易地在混淆矩阵的基础上定义出各种指标(如准确率、精度、召回率、F1分数)[20]。在已有NDP洪泛检测的研究中,基本上只做二分类检测,本文则是多分类检测。
因此,下面将介绍针对多分类检测的评估标准。宏平均(macro-averaging)是一种在多类别分类问题中计算性能指标的方法,它将每个类别视为等权重,然后计算每个类别的性能指标,最后对这些指标取平均值。
4.2.1 Macro准确率
准确度是多分类中最常用的度量指标之一,它直接由混淆矩阵计算而来。Macro准确率是一种评估分类模型性能的指标,对所有类别的预测结果给予了相等的权重,无论每个类别中的样本数量多少,它计算所有类别预测结果的平均准确率。
MacroAccuracy=∑Ni=11N×accuracyi=
∑Ni=11N×TPi+TNiTPi+TNi+FPi+FNi(1)
4.2.2 Macro精度
Macro精度计算所有类别的平均精度。Macro精度的计算方法为:对于每个类别,计算该类别的真阳性(TP)、假阳性(FP)和假阴性(FN)。然后,将所有类别的真阳性、假阳性和假阴性加总,得到总的真阳性(Total_TP)、假阳性(Total_FP)和假阴性(Total_FN)。Macro精度计算公式为
Precisionk=TPkTPk+FPk(2)
MacroPrecision=∑Kk=1PrecisionkK(3)
4.2.3 Macro召回率
Macro召回率计算所有类别预测正例的平均召回率。Macro召回率的计算方法为:对于每个类别,计算该类别的真阳性(TP)、假阴性(FN)和假阳性(FP)。然后,将所有类别的真阳性、假阴性和假阳性加总,得到总的真阳性(Total_TP)、假阴性(Total_FN)和假阳性(Total_FP)。Macro召回率计算公式如下:
Recallk=TPkTPk+FNk(4)
MacroRecall=∑Kk=1RecallkK(5)
4.2.4 Macro F1分数
Macro F1分数为Macro精度和Macro召回率的调和均值,需要先计算Macro精度和Macro召回率。它们分别通过取每个预测类的平均精度和每个实际类的平均召回率来计算。因此,Macro方法将所有类视为计算的基本元素:每个类在平均值中具有相同的权重,因此在填充程度高的类和填充程度低的类之间没有区别。
Macro F1-score=2×MacroPrecision×MacroRecallMacroPrecision-1+MacroRecall-1(6)
4.3 结果分析
分类算法的好坏将直接影响检测框架的效果。因此,本节将使用前面小节中的评价指标对机器学习中的随机森林、XGBoost、Lightgbm、SVM和贝叶斯算法和深度学习中的ANN、CNN、RNN、LSTM和Transformer等算法进行比较。
根据上述提到的四个指标对结果进行评估[21]。由于基于NDP的洪泛威胁数据集包含了两个子数据集,一个用于训练阶段,另一个用于测试阶段。本文选择在一个数据集上训练分类器和神经网络模型,然后在另一个数据集上测试它们,而不是使用交叉验证在同一数据集上构建和测试模型。最后对NDP洪泛威胁检测结果进行了总结,计算了Macro准确率、Macro精度、Macro召回率和Macro F1分数。
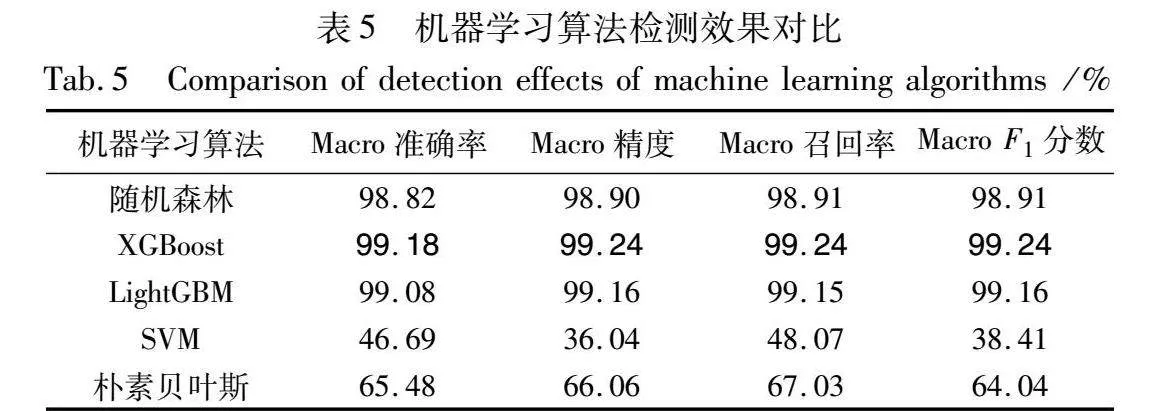
4.3.1 机器学习算法对比
表5对NDP洪泛威胁检测结果进行了总结,实验共使用5种机器学习算法,分别是随机森林、XGBoost、LightGBM、SVM和朴素贝叶斯,其中XGBoost、LightGBM和RF的检测准确率均在98%以上,XGBoost的准确率最高,接着是LightGBM和随机森林算法[22]。这三种算法都属于集成学习方法,即通过组合多个模型的预测来获得更准确的结果。它们都通过组合多个基本模型的预测来降低过拟合风险,提高模型的性能。其中,随机森林算法是基于决策树的集成方法;LightGBM是基于梯度提升框架的决策树算法,它使用基于直方图的分桶方式,加速了训练过程;XGBoost也是一种基于梯度提升框架的算法,但它采用了一种更复杂的正则化技术,以减小过拟合风险。
SVM和贝叶斯算法的检测效果表现欠佳,其中SVM算法检测准确率仅为46.69%,贝叶斯算法的检测准确率为65.48%。SVM是可用于分类问题的监督学习算法,旨在找到一个超平面,它可以在不同类别的数据点之间实现最大的间隔,这个超平面被用来分隔不同类别的数据。贝叶斯算法是基于贝叶斯定理的概率统计算法,它用来估计给定数据的概率分布,并通过计算后验概率来进行分类或预测。
综上所述,它们在工作原理、适用性和处理的数据类型等方面有显著的不同。选择哪个算法取决于具体问题的性质和数据的特点。从本实验结果来看,基于树型集成学习的机器学习算法表现更好,尤其是XGBoost算法各方面指标均为最优。
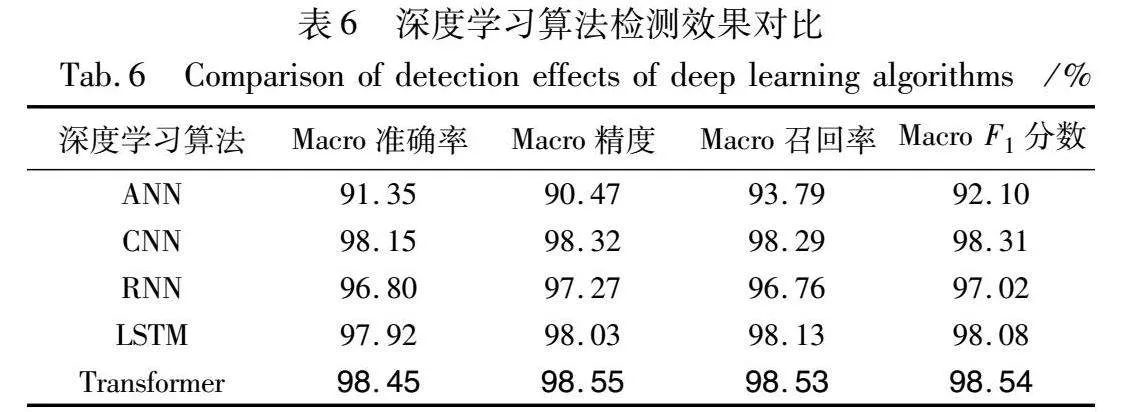
4.3.2 深度学习算法对比
接着又使用5种深度学习算法对NDP洪泛威胁进行检测[23],结果如表6所示。ANN是由两层全连接层组成,两层之间使用激活函数ReLU。CNN模型主要由一维卷积和残差网络构建,确保训练的稳定收敛。RNN采用标准的PyTorch框架中实现的双向RNN,LSTM同样采用标准的PyTorch框架中实现的双向LSTM。Transformer基于FT-Transformer[24]实现对于表格数据的训练学习。可以看到采用深度学习的方法普遍可以达到不错的准确率,同时也需要更多的训练技巧和训练时间。
4.3.3 与现有人工智能方法对比
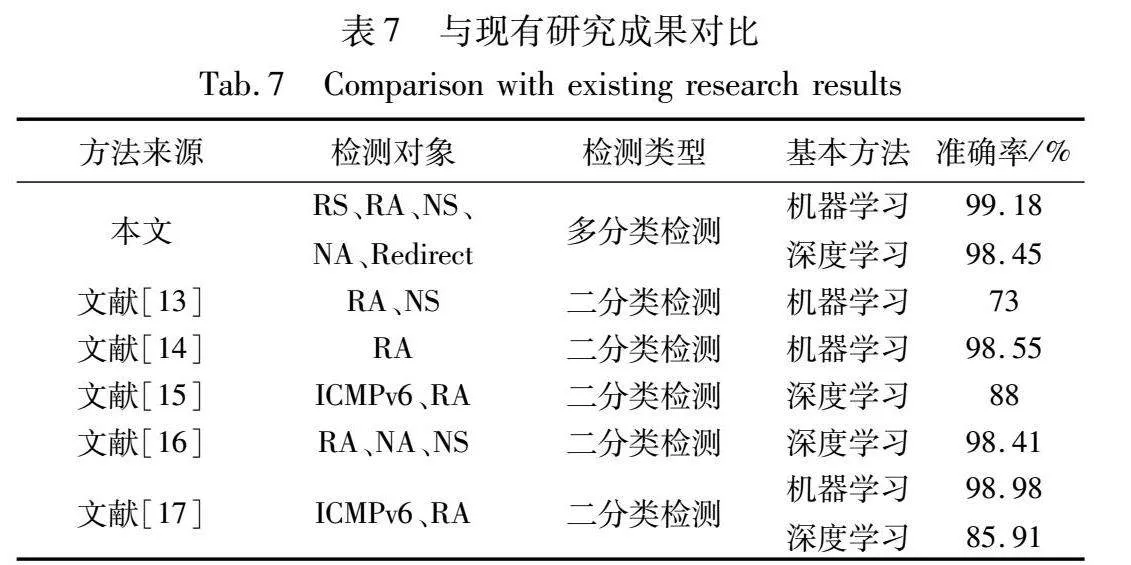
表7是本文提出的检测框架与现有基于人工智能检测方法的对比,详细比较了各项指标,包括检测对象、检测类型、基本方法和检测效果。
通过对比发现,本文研究在检测对象方面更加广泛,涵盖了更多的类型,并实现了多分类检测,同时检测效果也更加准确和稳定。如表7所示,现有研究的检测都是二分类检测,并且检测对象也没有包含NDP协议中的所有报文类型。文献[13,14]为机器学习方法,前者只是简单地使用机器学习算法,后者则增加了特征选择阶段。文献[15,16]为深度学习方法,同样后者比前者多了特征选择阶段。因此文献[14,16]的准确率都高于文献[13,15]。而本文不但进行了特征选择,并且新增了时间间隔特征。此外,集成了机器学习和深度学习的检测框架能够更好地选择检测效果最佳的算法,因此本文检测准确率均优于上述方法。文献[17]为2023年的最新研究,同样结合了机器学习和深度学习算法,但本文在检测对象、检测类型、准确率等方面则更具优势。因此,本文的检测框架具有更高的实用价值和应用前景。
首先,本文研究针对的是NDP协议中全部五种报文,检测更加全面。现有研究大多针对RA洪泛进行检测,这是由于RA报文在NDP协议中的作用明显,并且RA洪泛的危害较大。然而,NDP协议中的其他报文也同样在IPv6网络中发挥着重要作用,其洪泛威胁带来的危害也是不可忽略的。
其次,本文实现的是洪泛多分类检测,通过对NDP洪泛分析来细分洪泛类型,构建多分类数据集,检测更加细致。现有检测基本只进行二分类检测,本文则将NDP洪泛进行了更加细致化的划分,并进行了多分类检测。二分类检测只能将流量分为异常和正常,而本文的多分类检测可以更加准确地识别和分类洪泛威胁,将威胁信息整理和分析从而更好地保护网络安全。
最后,本文提出一种IPv6网络NDP洪泛行为多分类检测框架,并提出基于时间间隔特征的NDP协议洪泛威胁检测方法。其中基于XGBoost的机器学习检测准确率最高分别可达99.18%。
4.3.4 实验总结
从洪泛威胁检测研究的发展来看,基于人工智能的方法更优于经典阈值规则方法。由于洪泛威胁方案的多样性以及定义正常流量和恶意流量之间的阈值难度,要为洪泛检测设置万无一失的规则是极其困难的。因此,阈值规则方法在洪泛威胁检测中存在一定的局限性。相比之下,基于人工智能的洪泛威胁检测方法能够更好地处理这一问题。人工智能技术可以通过对大量数据的训练和学习,自动发现正常流量和恶意流量之间的模式和特征,并生成更加精准的分类模型。这些模型可以更好地适应各种不同的洪泛威胁方案,并且可以随着时间的推移不断优化和更新。
从本文的实验结果来看,机器学习中的随机森林算法、XGBoost、LightGBM都有不错的检测效果,其中XGBoost算法检测准确率更是达到了99.18%,是所有算法中效果最好的。深度学习的5种算法的检测准确率虽然没有高于XGBoost,但大多也接近XGBoost算法准确率。这样的结果并不意味着机器学习在洪泛检测效果优于深度学习,因为本实验所采集的数据集并不复杂,并且经过专业预处理,增加了一些有利于分类的特征字段,这恰好有助于机器学习算法。相反,随机物联网设备的增加,网络流量规模的扩大,今后的网络环境将是更加复杂、多变的。而这样的环境将更适合深度学习算法,因为它们具有更强的自适应能力,可以更好地处理复杂多变、非线性的数据模式[25]。
5 结束语
本文详细阐述了一种针对IPv6 NDP协议洪泛多分类检测框架,并提出了基于XGBoost算法的检测方法。这一框架为保障IPv6网络的安全性提供了坚实的基础,突显了其重要的应用价值。该框架巧妙地融合了机器学习和深度学习技术,能够更高效地识别和区分不同类型洪泛威胁。
值得一提的是,该检测框架是首个针对NDP洪泛威胁进行全面检测并进行多分类的,体现了其前瞻性、创新性和实用性。不仅能够准确地检测出NDP洪泛,而且能够对不同类型的NDP洪泛进行分类,从而为提升网络安全性提供了更加全面的保障。同时,该检测框架具有良好的效果,其检测准确率处于领先水平。即使在网络环境繁忙的情况下,也能够有效地检测并区分各种类型的洪泛威胁。最后,机器学习和深度学习技术的结合使用,使得该框架具有强大的适应能力、可扩展性和易用性。
为适应新的威胁和挑战,后续将对NDP洪泛威胁多分类检测框架进行优化和扩展,以提高其性能和可靠性。框架的优化和扩展将包括以下几个方面:
a)洪泛分类的精细化。
当前仅根据报文类型和洪泛目标简单分类NDP洪泛报文。实际上,不同的报文类型和洪泛目标可能会产生不同特点的洪泛威胁。例如,RA报文洪泛中还涉及路由器生存时间、MTU值等参数,这些参数可以作为区分不同类型RA洪泛的标志。因此,还需要对NDP洪泛威胁多分类检测框架进行改进,使其能够根据这些参数对报文进行更精细的分类,从而更好地识别和应对各种类型的洪泛威胁。
b)框架算法的提升。
本文所提框架的核心是机器学习和深度学习算法,因此,需要不断提升其算法的性能和准确性,包括但不限于改进机器学习模型的准确率、提高深度学习模型的泛化能力、优化神经网络的训练过程等。通过不断提升算法的性能和准确性,可以更准确地识别和应对各种网络威胁,从而提高IPv6网络的安全性和可靠性[26]。
总之,对NDP洪泛威胁多分类检测框架进行优化和扩展是一个持续的过程,需要不断地改进和完善其各个方面,以适应不断变化的网络威胁,从而有效地保护IPv6网络。
参考文献:
[1]Li Xiang, Liu Baojun, Zheng Xiaofeng, et al. Fast IPv6 network periphery discovery and security implications[C]//Proc of the 51st Annual IEEE/IFIP International Conference on Dependable Systems and Networks. Piscataway,NJ: IEEE Press, 2021: 88-100.
[2]Ahmed A S, Hassan R, Othman N E. IPv6 neighbor discovery protocol specifications, threats and countermeasures: a survey[J]. IEEE Access, 2017, 5: 18187-18210.
[3]Hamid Z, Daud S, Razak I S A, et al. A comparative study between IPv4 and IPv6[J]. ANP Journal of Social Science and Humanities, 2021, 2(2): 43-47.
[4]Hossain T, Rahman N. A review paper on IPv4 and IPv6: a comprehensive survey[C]//Proc of IICT. 2022.
[5]刘向举, 尚林松, 方贤进, 等. 基于可编程协议无关报文处理的分布式拒绝服务攻击检测[J]. 计算机应用研究, 2022, 39(7): 2149-2155. (Liu Xiangju, Shang Linsong, Fang Xianjin, et al. Distributed denial of service attack detection based on programming protocol-independent packet processors[J]. Application Research of Computers, 2022, 39(7): 2149-2155.)
[6]Liu Yanru. Research on network security based on IPSec[C]//Proc of the 7th International Conference on Education, Management, Computer and Medicine.[S.l.]:Atlantis Press, 2017: 150-154.
[7]Arkko J, Ericsson, Kempf J, et al. RFC 3971, Secure neighbor discovery(SEND)[S]. 2005.
[8]Ahmed A S, Hassan R, Othman N E. Secure neighbor discovery (SEND): attacks and challenges[C]//Proc of the 6th International Conference on Electrical Engineering and Informatics. Piscataway,NJ: IEEE Press, 2017: 1-6.
[9]Shah S B I, Anbar M, Al-Ani A. Hybridizing entropy based mechanism with adaptive threshold algorithm to detect RA flooding attack in IPv6 networks[C]//Proc of the 5th ICCST Computational Science and Technology. Berlin: Springer, 2019: 315-323.
[10]Bahashwan A A, Anbar M, Manickam S. Propose a flow-based approach for detecting abnormal behavior in neighbor discovery protocol(NDP)[C]//Proc of International Conference on Advances in Cyber Security. Berlin: Springer, 2021: 401-416.
[11]Bahashwan A A, Anbar M, Hasbullah I H, et al. Flow-based approach to detect abnormal behavior in neighbor discovery protocol(NDP)[J]. IEEE Access, 2021, 9: 45512-45526.
[12]Satrya G B, Chandra R L, Yulianto F A. The detection of DDoS flooding attack using hybrid analysis in IPv6 networks[C]//Proc of the 3rd International Conference on Information and Communication Technology. Piscataway,NJ:IEEE Press, 2015: 240-244.
[13]Najjar F, Kadhum M M, El-Taj H. Detecting neighbor discovery protocol-based flooding attack using machine learning techniques[C]//Advances in Machine Learning and Signal Processing. Berlin:Springer, 2016: 129-139.
[14]Anbar M, Abdullah R, Al-Tamimi B N, et al. A machine learning approach to detect router advertisement flooding attacks in next-generation IPv6 networks[J]. Cognitive Computation, 2018, 10: 201-214.
[15]Saad R M A, Anbar M, Manickam S, et al. An intelligent ICMPv6 DDoS flooding-attack detection framework(v6IIDS) using back-propagation neural network[J]. IETE Technical Review, 2016, 33(3): 244-255.
[16]Elejla O E, Anbar M, Hamouda S, et al. Deep-learning-based approach to detect ICMPv6 flooding DDoS attacks on IPv6 networks[J]. Applied Sciences, 2022, 12(12): 6150.
[17]Ksimi A E, Leghris C, Lafraxo S, et al. ICMPv6-based DDoS flooding-attack detection using machine and deep learning techniques[J]. IETE Journal of Research, 2023(5): 1-10.
[18]THC-IPv6[EB/OL]. (2021)[2023-12-26]. https://github. com/vanhauser-thc/thc-ipv6.
[19]Scapy[EB/OL].[2023-12-26]. https://scapy.net/.
[20]Prasath M, Perumal B. Network attack prediction by random forest: classification method[C]//Proc of the 3rd International Conference on Electronics, Communication and Aerospace Technology. Piscataway,NJ: IEEE Press, 2019: 647-654.
[21]Lafraxo S, Ansari M E, Charfi S. MelaNet: an effective deep learning framework for melanoma detection using dermoscopic images[J]. Multimedia Tools and Applications, 2022, 81(11): 16021-16045.
[22]Sahoo K S, Puthal D. SDN-assisted DDoS defense framework for the Internet of multimedia things[J]. ACM Trans on Multimedia Computing, Communications, and Applications, 2020, 16(3S): 1-18.
[23]Aleesa A M, Zaidan B B, Zaidan A A, et al. Review of intrusion detection systems based on deep learning techniques: coherent taxonomy, challenges, motivations, recommendations, substantial analysis and future directions[J]. Neural Computing and Applications, 2020, 32: 9827-9858.
[24]Gorishniy Y, Rubachev I, Khrulkov V, et al. Revisiting deep lear-ning models for tabular data[C]//Advances in Neural Information Processing Systems. 2021.
[25]Elejla O E, Belaton B, Anbar M. Intrusion detection systems of ICMPv6-based DDoS attacks[J]. Neural Computing and Applications, 2018, 30: 45-56.
[26]Mishra P, Varadharajan V, Tupakula U, et al. A detailed investigation and analysis of using machine learning techniques for intrusion detection[J]. IEEE Communications Surveys & Tutorials, 2018, 21(1): 686-728.
