基于子网融合的多智能体系统自组网连通性恢复方法
2024-10-14何杏宇余萍萍杨桂松






摘 要:在受损的多智能体自组网中,在维持现有连通结构的前提下快速恢复全连通极具挑战性。为此,提出一种基于子网融合的多智能体系统自组网连通性恢复方法。首先,该方法设计基于网络故障探测的子网划分算法来确定系统中的故障节点以及子网割裂情况。其次,该方法在子网内部署领航-追随者的主从移动模型,从而维持子网内部的稳定性。最后,该方法设计基于强化学习的子网融合算法,根据建立强化学习模型来进行领航者选举,依据智能体移动距离和智能体能量消耗设计奖励函数,引导子网完成周期性领航者选举的动作,领航者带领追随者移动实现子网之间的融合,从而实现全网连通性恢复。实验结果表明,相比于现有方法,该方法在实现连通恢复时所需的时间平均减少了11.3%,系统所产生的能量消耗平均降低了10.58%,证明该方法在效率和能耗方面更具优势。
关键词:多智能体系统; 连通性恢复; 领航-追随者; 强化学习
中图分类号:TP393.03 文献标志码:A
文章编号:1001-3695(2024)10-036-3135-06
doi:10.19734/j.issn.1001-3695.2024.03.0040
Self-organized network connectivity recovery method for multi-agentsystem based on subnet fusion
He Xingyua,b, Yu Pingpinga, Yang Guisonga
(a.School of Optical-Electrical & Computer Engineering, b.College of Communication & Art Design, University of Shanghai for Science & Technology, Shanghai 200093, China)
Abstract:It is challenging to quickly restore full connectivity in a damaged multi-agent self-organizing network while maintaining the residual connectivity structure. Therefore, this paper proposed a connectivity restoring method based on subnet fusion for self-organized networks in multi-agent systems. Firstly, the method designed a subnet partition algorithm based on network fault detection, to identify faulty nodes and subnet fragmentation in the system. Secondly, the method deployed a leader-follower mobility model within each subnet to maintain the residual network connectivity. Finally, the method designed a reinforcement learning-based subnet fusion algorithm for leader election, where elected leaders periodically according to a reward function related to mobility distance and energy consumption, being responsible for guiding their followers to move for fusion between subnets. The experimental results show that this method reduces average restoration time by 11.3% and decreases energy consumption by 10.58%, demonstrating its advantages in efficiency and energy usage.
Key words:multi-agent system; connectivity restoration; leader-follower; reinforcement learning
0 引言
多智能体系统因具备较高的自适应性,在众多实际场景中得到应用,如交通管理[1]、灾害救援[2]、物流配送[3]。多智能体群智协同是其系统效率和智能化水平提升的关键,且是建立在多智能体系统网络的稳定连通性基础之上,连通的重要性体现在信息传递与共享[4]、协作[5]以及系统的稳定可靠性上[6]。但在实际应用中,由于智能体自身的能耗有限或者来自外部环境的破坏,多智能体系统中会出现部分节点故障或死亡的情况,从而导致系统网络的连通性被破坏,割裂成多个无法连通的子网。针对上述情况,现有研究主要从两个方面对多智能体系统的网络连通性进行恢复:部署额外的中继节点以及重新部署健康节点两种方法。
部署额外的中继节点方法是通过向损坏网络系统中的关键位置派遣新的中继节点。文献[7]通过基于虚拟力量的接力动作和利用分区领导者之间的博弈论来部署额外的中继节点。文献[8]通过使用无人机群向孤立的地面网络补充空中无线链路来修复网络,从空中执行网络探测,并找出部署后可显著恢复本地和全局路由性能的关键点,文献[9]提出了一种新的多无人机网络寿命增强恢复方法,该方法不仅提供了一种路由解决方案,而且还提供了一种故障安全方法。
重新部署健康节点是重新对现有健康节点进行路径规划、排序等方式实现网络连通性恢复。文献[10]采用分区检测方法,快速使传感器意识到网络中的分区,传感器利用存储在每个传感器处的到汇聚节点的先前路由信息并利用传感器移动性来联合分区恢复数据通信。文献[11]通过模糊逻辑在健康节点中选择最佳恢复团队达到恢复连通的目的,文献[12]通过开发健康节点中的最佳p循环恢复模型来实现网络恢复。文献[13]研究了无人机群网络在不可预测外部破坏下快速重建通信连通性所需要的自愈问题。针对一次性外部破坏和一般化外部破坏,提出了可在线查找无人机群网络恢复拓扑的图卷积神经网络和基于GCN的轨迹规划算法,使无人机群在自愈过程中重建连通性。
上述第一类方法不需要调整已有的连通结构,相对简单,但需要相对长的额外节点部署时间,不能对网络进行实时修复,在实时性要求高的任务场景无法适用。相反地,第二类方法则可以在网络故障后立即作出网络连通性恢复响应,但其复杂性更大,具体来说,主要面临两大挑战:a)在调整健康节点位置的同时维持其原有的连通性;b)要兼顾网络连通性恢复的开销和速度。
本文主要对第二类方法展开研究。针对该类方法的第一个挑战,本文将在健康节点组成的子网内引入领航-追随者[14]模式来保持子网已有的连通性。领航-追随者模式是编队控制中的一种常用方法,其将团队中的一个智能体指定为领航者统一调度其余作为追随者的智能体的行动,以维持团队的内部稳定,例如文献[15]提出了一种领航-追随者无人机编队控制规律,将控制和通信约束以平衡的方式结合在一起,实现无人机编队,又例如文献[16]通过优化网络中领航者和跟随者之间协调控制的代价函数来获得智能体的控制输入,保证领航者和跟随者之间的共识。
针对第二类方法的第二个挑战,本文将利用强化学习[17]方法来优化多智能体系统网络连通性恢复过程中的效率和开销。强化学习是智能体以“试错”的方式进行学习,通过与环境进行交互获得的奖赏从而指导行为,该方法已被应用于多智能体系统的协同以完成通信来执行任务,例如文献[18]采用Actor-Critic强化学习方法解决智能体之间没有通信的情况下达到共识的目的。又例如文献[19]提出了灾害应急场景下基于多智能体深度强化学习的任务卸载策略,避免动作空间大量无用的搜索。
目前,并没有相关研究将领航-跟随者模式以及强化学习方法共同引入网络连通性恢复过程中。基于上述构思,本文提出了一种基于子网融合的多智能体系统自组网连通性恢复方法。该方法首先设计基于网络故障探测的子网划分算法来确定系统中的故障节点以及子网划分情况,进而在子网内部部署领航-追随者的移动模型。最后,该方法设计基于强化学习的子网融合算法,根据建立强化学习模型来进行领航者选举,依据智能体移动距离和智能体能量消耗设计奖励函数,引导子网完成周期性领航者选举的动作,领航者带领追随者移动实现子网之间的融合,从而实现全网连通性恢复。本文的主要贡献如下:
a)为了在调整健康节点位置的同时维持其原有的连通性,首先,本文设计基于网络故障探测的子网划分方法来确定系统中的故障以及子网割裂情况;然后,在子网中采用领航-追随者移动控制模型。每个智能体从引发子网割裂的故障消息中找出故障节点的邻居节点,将它们中位于其他子网的节点其放入候选子目标列表。在实现网络连通恢复的过程中,领航者会收集到子网追随者反馈的环境信息(其他子网的智能体,即陌生智能体的位置信息),并将其放入候选子目标列表。领航者选择候选子目标列表中距离自身最近的智能体作为移动子目标,同时,领航者负责收集追随者信息和广播子网状态信息,追随者向领航者反馈自身所探测的环境状态,并且根据邻居的移动方向均值来更新更新自身的移动方向,从而兼顾了连通性恢复的运行控制和子网内部连通性的维持。
b)为了兼顾网络连通性恢复的开销和速度,本文设计了用于领航者选举的强化学习模型,依据领航者的能量消耗设置个体奖励以及子网中智能体与子目标的距离平均值设置全局奖励,使得子网周期性完成一次领航者选举的动作,选举结果由当前领航者广播给追随者,新的领航者将带领追随者朝着新的子目标移动。此外,本文设计了基于子网融合的连通性恢复算法,即在子网移动的过程中,通过周期性更新子网状态和候选子目标列表,领航者即时广播状态信息和子目标信息来促进子网进行融合,从而实现网络连通性恢复。
1 系统模型
本文构建了一个多智能体系统,包括I个智能体,表示为A={A1,A2,…,Ai,…,AI},其中第i个智能体表示为Ai(1<i<I),智能体Ai是具有感知、计算、存储、通信能力的无人车、无人机或机器人,其初始能量为Ei。智能体对应的位置集合为L={L1,L2,…,Li,…,LI},Li表示智能体Ai的位置。每个智能体有固定的探测半径R1和通信半径R2(R1>R2)。
每个智能体周期性与邻居智能体交换邻居列表(时间周期为Δt)。智能体Ai的邻居列表定义为Aneighbori={A1i,A2i,…,Aδi},其中Ai的第n个邻居智能体用Ani表示。每个智能体可以通过收集其他智能体的邻居列表来计算和更新全网的连通性矩阵C,如式(1)所示。
C=CA1,A1…CA1,Ai2…CA1,AICAi1,A1…CAi1,Ai2…CAi1,AICAI,A1…CAI,Ai2…CAI,AI(1)
在矩阵C中,智能体Ai1和Ai2之间的连通性度量用CAi1,Ai2表示,通过式(2)计算获得。
CAi1,Ai2=∑I-1w=1cwij(2)
cwij为任意两个智能体Ai和Aj之间的w跳连通性度量,由式(3)迭代计算获得。
cwij=∑Iy=1cw-1iyc1yj(3)
当w=1时,cwij为任意智能体Ai和Aj之间的直接连通度量,可通过分析邻居关系直接获得,若cwij=1,则智能体Ai和Aj之间存在w跳连通,否则不连通。
2 基于网络故障探测的子网划分
为了判断故障智能体是否导致网络割裂,本文设计基于网络故障探测的子网划分算法,如算法1所示。在算法1中,智能体Ai向邻居智能体发送邻居列表交互请求后,如果在时间间隔Δt内未收到邻居智能体Aj的请求确认,则认为智能体Aj发生故障。在探测到智能体Aj发生故障后,智能体Ai会更新邻居列表,并通过式(2)(3)更新全网的连通性矩阵C,根据该矩阵C判断网络是否发生割裂,以及根据该矩阵C从智能体Aj的邻居表中与自身仍然连通的智能体,将自身和这些智能体放入网络故障处理候选者列表Aci。
当智能体Ai根据矩阵C发现智能体Aj的故障没有引发网络割裂,如果自身的中介度为Aci中最小的(智能体Ai的中心度为其到所在子网其他节点的最小跳数和),则需要自身作为故障处理者负责将子网号不变的故障消息Mimsg沿着最短路径广播给其所在子网的其他智能体,否则不做任何处理。
当智能体Ai发现智能体Aj的故障引发了网络割裂,如果自身比Aci其他故障处理候选者距离Aj更近,则需要作为故障处理者生成包含自身位置和故障探测时间的新子网号,并将包含该新子网号的故障信息Mimsg沿着最短路径广播给所在子网的其他智能体,否则不做任何处理。
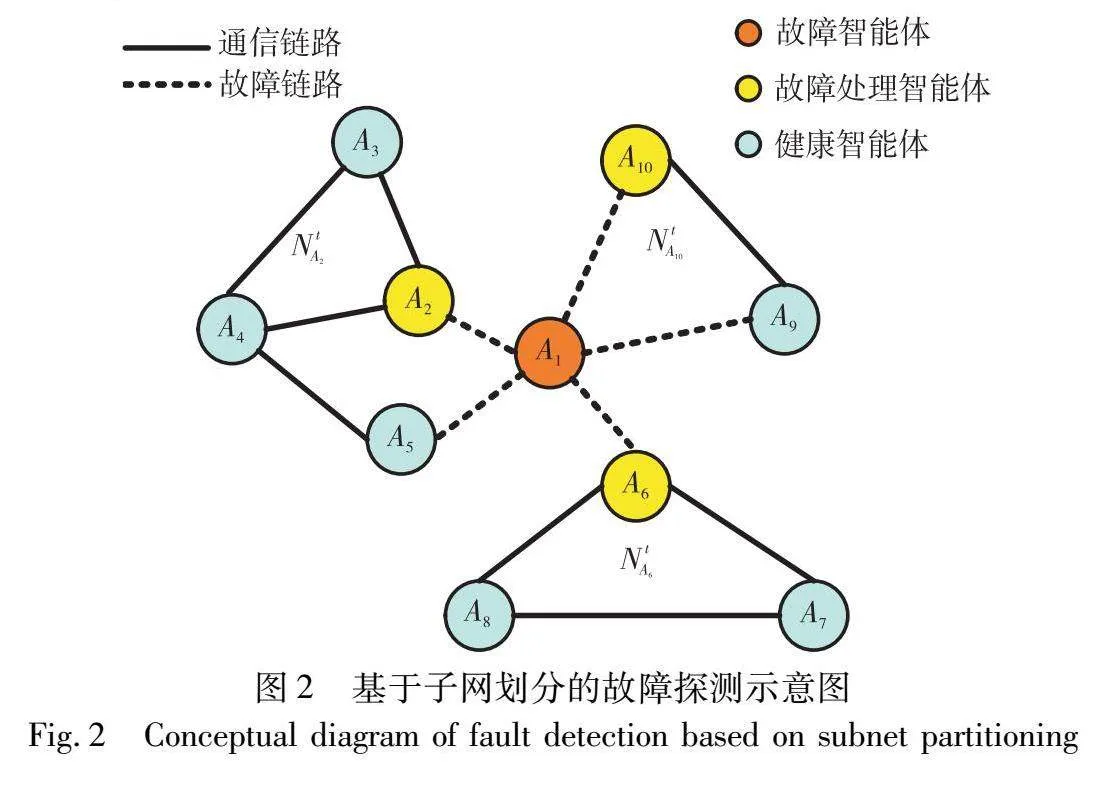
为了对因节点故障导致网络割裂而形成的各个子网进行唯一标识,本文将处理网络割裂的智能体位置和其探测到网络割裂的时间定义为新产生的子网号。如图1所示,故障消息Mimsg由以下几部分组成:消息发送者Ai,消息接收者Aρ(Aρ为Ai所在子网的其他智能体),子网号NtAi(t表示子网划分时间,Ai表示子网割裂的故障处理者),故障智能体Aj的ID、位置Lj以及邻居列表Anj。
算法1 基于故障探测的子网划分算法
输入:连通矩阵C,故障智能体Aj。
输出:子网号NtAi。
a)智能体Ai根据故障智能体Aj更新邻居列表,同时通过式(2)(3)更新连通矩阵C;
b)获取Aj的邻居表中与Ai存在链路的智能体集合Aci;
c)if网络未发生割裂then
d) if智能体Ai为Aci中中心度最小的节点 then:
e) 广播子网号未变化的故障消息Mimsg;
f) end if ;
g)else 网络发生割裂then
h)智能体Ai为Aci中距离故障智能体Aj最近的智能体, 将自身位置和探测到故障智能体Aj的时间定义为新子网号NtAi,广播包含新子网号NtAi的故障消息Mimsg;
i)end if;
本文将以图2的场景为例对上述算法1进行详细说明。在图2中,智能体A1~A10之间周期性交互邻居信息,某时刻,A2、A5、A6和A10无法在规定时间间隔内接收到A1的邻居消息确认,即检测到智能体A1故障。A2、A5、A6和A10分别通过式(2)(3)来计算更新全网连通矩阵,判断网络已经发生割裂。由于智能体A2和A5相连通且A2比A5离故障节点A1更近,则A2会生成新的子网号NtA2,并把包含NtA2的故障消息MA2msg发送给A3、A4以及A5。A6和A10与A1的其他邻居节点都不相连通,则各自生成子网号NtA6和NtA10,并将子网号NtA6和NtA10分别发送给A7、A8和A9。
3 基于强化学习的子网融合
3.1 子网中领航者和追随者定义
1)功能角色 在广播故障消息结束后,每个子网会启动领航-追随者模式来实现网络连通性恢复。每个子网中会周期性选举出一个智能体担任领航者,其余智能体则为追随者,领航者引导追随者移动寻找与其他子网的融合机会,在移动过程中,领航者通过强化学习模型得出下一次的领航者选举决策,将决策结果在子网内广播。本文设置领航者选举时间间隔为Δt,即时间间隔Δt内更新一次子网状态。在子网NtAi中第k次选举后的领航者标记为leadertAi(k),追随者定义为follower(g)tAi(k),即子网NtAi第k次选举后的第g个追随者智能体。
2)子目标 每个智能体从引发子网割裂的故障消息中找出故障节点的邻居节点,将它们中位于其他子网的节点其放入候选子目标列表。在实现网络连通恢复的过程中,领航者会收集到子网追随者反馈的环境信息(其他子网的智能体,即陌生智能体的位置信息),将其放入候选子目标列表,并将更新后的候选子目标列表广播给其他追随者。子网中的领航者将从候选子目标列表中选择距离自己最近的候选子目标作为实际子目标,并带领追随者朝着实际子目标的位置移动。将子网NtAi中第k次选举后的实际子目标定义为TARtAi(k)。
3)移动模型 在移动过程中,领航者会根据当前子目标的位置进行移动,追随者则结合领航者共享的子网状态和邻居智能体的运动方向来更新自身的运动方向。本文以子网为例说明领航者和追随者之间的移动模型。在子网NtAi的移动过程中,其领航者智能体NtAi会通过移动子目标的位置获得移动方向θleadertAi(k),其计算如下:
θleadertAi(k)=atan2(dy,dx)TARtAi(k)(4)
(dy,dx)TARtAi(k)表示当前子网的移动子目标所在的位置,系统中所有智能体速度都为vei。追随者follower(g)tAi(k+1)的移动方向更新计算如下:
θfollower(g)(k+1)=〈θfollower(g)(k)〉Γ(5)
其中:〈θfollower(g)(k)〉Γ表示子网NtAi中追随者follower(g)tAi(k+1)的所有邻居智能体上一轮移动方向的平均值,可由下式计算:
〈θfollower(g)(k)〉Γ=arctan∑j∈Γi(k)sin〈θfollower(j)(k)〉∑j∈Γi(k)cos〈θfollower(j)(k)〉(6)
3.2 基于强化学习的子网领航者选举
为了提升网络连通性恢复效率,本文提出用于子网领航者选举的强化学习模型(图3),该模型在子网内部的每个智能体上部署,当前轮被选为领航者的智能体通过观察环境中位于其他子网的陌生智能体作为候选移动子目标,然后在与移动开销相关的奖励函数引导下作出下一轮的领航者选择决策,并且领航者带领追随者向着移动子目标移动,直至与其他子网发生融合。强化学习模型的具体定义如下:
a)状态。子网NtAi中智能体的状态信息包含子网号、当前子目标、子网中的所有智能体的位置和能量信息,以及候选子目标集合,例如第k轮领航者选举中的状态信息定义如下:
s(k)=[NtAi(k),PtAi(k),EtAi(k),TARtAi(k),tartAi(k)](7)
其中:NtAi(k)表示在第k次领航者选举时的子网号;PtAi(k)表示子网NtAi所有智能体在第k次领航者选举时的位置信息集合;EtAi(k)表示子网NtAi中所有智能体在第k次领航者选举时的剩余能量集合;TARtAi(k)表示第k次领航者选举时的子目标;tartAi(k)表示第k次领航者选举时的候选子目标集合。
b)动作。从子网智能体集合中选择下一轮的领航者,定义为
a(k)=AuNtAi,AuNtAi∈AUNtAi(8)
其中:AUNtAi表示子网NtAi中智能体的集合;AuNtAi表示集合中第u个智能体。领航者的动作是自主选择,追随者的动作是由领航者广播告知。
c)奖励。本文通过设置奖励函数引导子网选举合适的领航者,奖励函数定义为r(k),表示第k轮选举所获得的奖励,计算如下:
r(k)=λr1(k)+μr2(k)(9)
其中:λ和μ分别代表奖励值r1(k)和奖励值r2(k)在总奖励值的占比权重,两者和为1。r1(k)为第k轮选举的领航者能量相关的奖励,通过第k轮领航者的剩余能量与子网中所有智能体的平均能量差值计算得出,具体如式(10)所示。在第k轮结束时,子网中智能体平均剩余能量定义为Eκt,Ai,领航者智能体Ai的当前剩余能量为Eki。
r1(k)=Eki-Eκt,AiEi(10)
r2(k)是与第k轮选举后移动子目标位置相关的奖励,根据第k轮选举后所有智能体距离移动子目标的总距离与第k-1轮子网中所有智能体距离移动子目标的总距离的差值计算得出,具体如式(11)所示。其中dktar是第k轮选举后所有智能体距离移动子目标的总距离,dk-1tar是第k-1轮子网中所有智能体距离移动子目标的总距离。
r2(k)=-(dktar-dk-1tar)R2(11)
其中:奖励r1(k)的设计考虑到了领航者智能体因信息的收集与广播将消耗比其他智能体更多的能耗;奖励r2(k)的设计是为了降低连通性恢复的开销。
3.3 子网融合
为了促进子网融合来实现整个多智能体系统的网络全连通,本文提出基于强化学习的子网融合算法,如算法2所示。在算法2中,在基于故障探测的子网划分过程结束之后,各子网探测到故障智能体并启动领航-追随者模式进行移动,在子网移动过程中,间隔时间Δt内更新当前子网的状态和子网连通矩阵,若子网内有智能体探测到陌生智能体,则将探测到的信息反馈给当前领航者,并将探测到的智能体信息存入候选子目标列表中,领航者根据追随者所反馈的信息更新子网状态信息,并进行下一轮领航者选举决策以及将决策结果广播给子网中其他智能体。当选的领航者在带领追随者移动的过程中不断更新全网连通性矩阵C,通过分析该矩阵探测新故障以及子网融合事件的发生。若探测到子网中出现新故障,则直接重启该算法;如果探测到发生子网融合,则更新子网号(新的子网号由融合时间以及融合处能量最高的节点决定),并更新移动候选子目标列表(将移动子目候选列表中融合进新子网的智能体删除,在新子网内交互移动子目候选列表信息,然后再重启该算法)。
算法2 基于强化学习的子网融合算法
输入:子网割裂的故障消息以及新子网号。
输出:全网连通矩阵C。
a)初始化子网状态;
b)for间隔时间Δt do
c) 更新子网状态信息;
d) 基于强化学习的领航者选举;
e) 若被选举为领航者则带领子网中追随者朝着子目标移动,否则作为追随者;
f)将子网中智能体探测到的陌生智能体存入候选子目标列表;
g)if子网内部发生新的割裂故障then
h) 返回步骤a);
i)else if子网发生融合then
j) 更新全网连通性矩阵C;
k)更新子网号和候选子目标列表;
l)在新的子网中交换候选子目标列表;
m)连通矩阵C显示全网未全连通,间隔时间Δt结束返回至步骤c);
n) end if;
o)end for;
4 强化学习模型的求解
本文采用多智能体深度确定性策略梯度算法(multi-agent deep deterministic policy gradient,MADDPG)[20]对本文强化学习模型求解。MADDPG算法使用Actor-Critic基本框架,采用深度神经网络作为策略网络和动作价值函数的近似,使用随机梯度法训练策略网络和价值网络模型中的参数。在训练本文定义的模型时需要将动作连续化,输入的是子网中所有智能体的位置信息、所有智能体的剩余能量、候选子目标列表以及当前子目标,输出的是选举出的领导者智能体及子目标位置。
算法3 基于MADDPG的强化学习模型求解算法
a)for episode=1 to M do:
b) 初始化一个用于动作探索的随机过程Φ;
c) 获得初始观察状态s(k);
d) for t=1 to T do:
e) ai=μθi(oi)+Φt;
f)执行动作a=(a1,…,aΦ),得到奖励r(k)和下一个状态s(k+1);
g)数据[s(k),a(k),r(k),s(k+1)]存入经验池D;
h)s(k)←s(k+1)
i)for agent i=1 to I do:
j) 从D中随机抽取一个数目值为S的样本集合[s(k)j,a(k)j,r(k)j,s(k+1)j];
k) yi=rji+γQμ′i[s(k+1)j,a(k+1)1,…,a(k+1)1|a(k+1)w=μ(k+1)w(σjw)
l)最小化损失函数L来更新Critic网络;
m)L(θi)=1S∑j(yj-Qμi(sj,aj1,…,ajI))2;
n)采用策略梯度更新Actor策略网络;
o)θiJ≈1S∑jθiμi(oji)aiQμi(sj,aj1,…,ai,…,ajI)|ai=μi(oji);
p)若智能体Ai为本轮子网中的领航者, 更新智能体Ai的目标网络;
r)θ(k+1)i←τθ(k)i+(1-τ)θ(k+1)i;
s) end for;
t)end for;
5 实验及分析
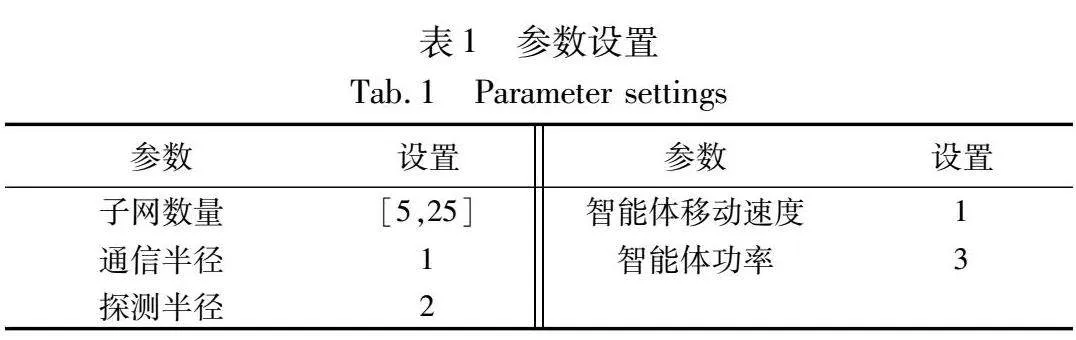
为了评估本文算法的性能优劣,在Python实验环境中,本文首先对奖励值收敛性进行了对比和验证,之后再通过与现有的方法在时间和能耗两个方面进行对比分析。实验的主要参数设置如表1所示。
5.1 本文算法性能分析
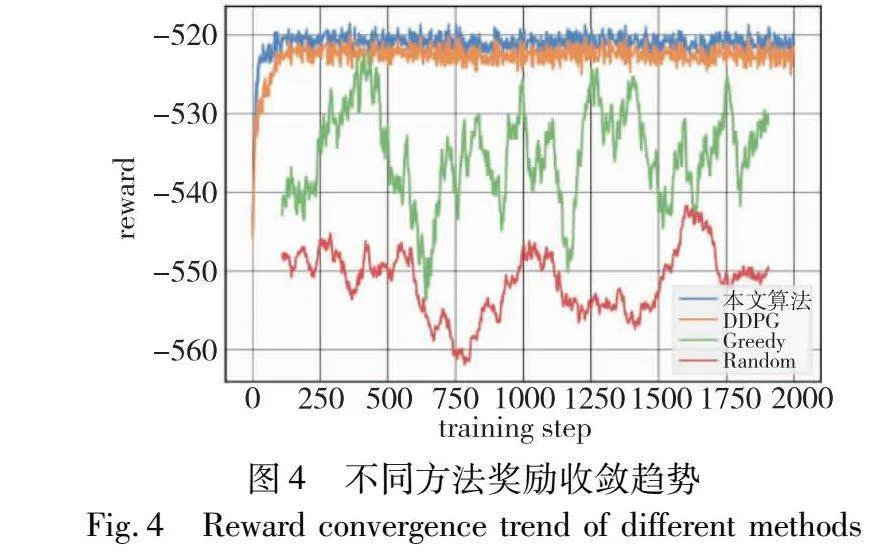
本文算法考虑到智能体之间的相互作用和协作,智能体共享一个全局的Actor网络和Critic网络来学习,在选择动作时兼顾其他智能体的动作和状态,使用一个集中的动作-价值函数来评估联合动作的价值。此外,本文算法的经验池允许智能体共享和重复使用经验,智能体可以从其他智能体的经验中学习,并且可以通过经验回放缓冲区中的样本来减少训练过程中的样本相关性,这种经验共享有助于提高智能体学习效率。为了评估本文算法的特性,在实验过程中以深度确定性策略梯度(DDPG)算法、贪婪算法(Greedy)以及随机算法(Random)作为奖励收敛对比,三种方法分别部署在单个智能体上,通过观察本文算法与三种算法的奖励值以及奖励收敛情况来评估本文算法在训练智能体学习方面的性能。DDPG中的Actor-Critic网络是单个智能体的,它使用一个单独的动作-价值函数来评估当前智能体的动作价值,并根据评估出的价值更新策略。贪婪算法通过每次选择当前最优的解决方案来逐步构建问题的解决过程,它不会进行回溯或全局优化,只关注当前步骤的最优选择。随机算法则通过在每一步使用随机选择的方法作出决策,通过概率分析,对算法的平均性能进行评估。
从图4可以得出,通过设置2 000轮训练迭代过程,本文算法和DDPG的算法性能对于本文研究都展现出较好的效果,但相比于本文算法,DDPG奖励收敛的值略小于本文算法,并且趋于收敛的迭代次数也要略多于本文算法,而贪婪算法和随机算法则达不到收敛效果。
5.2 对比算法及实验指标
为了体现实验结果的客观性和准确性,本文以文献[11,12]中的两种方法作为对比,对比算法具体如下:
a)分布式节点重定位算法(CoRFL)。CoRFL算法通过模糊逻辑在分区的健康节点中选择节点来组成恢复团队实现与部署中心(CoD)的通信,从而实现全网连通性恢复。
b)p循环恢复算法(p-cycle)。p-cycle网络恢复模型考虑到网络资源利用率和保护网络免受故障影响,通过提供环形恢复速度为网络提供足够的保护。
为了验证本文算法对本文场景应用的有效性,从系统总消耗对本文算法和两种对比算法进行评估。其中系统平均总消耗可以细分为平均时延和平均能量消耗两项指标,系统平均时延是由在完成连通性恢复过程系统需求的总时间除以子网分区数量得出;系统平均能量消耗是由在完成连通性恢复过程中系统产生的总消耗除以子网分区数量得出。
5.3 对比实验结果与分析
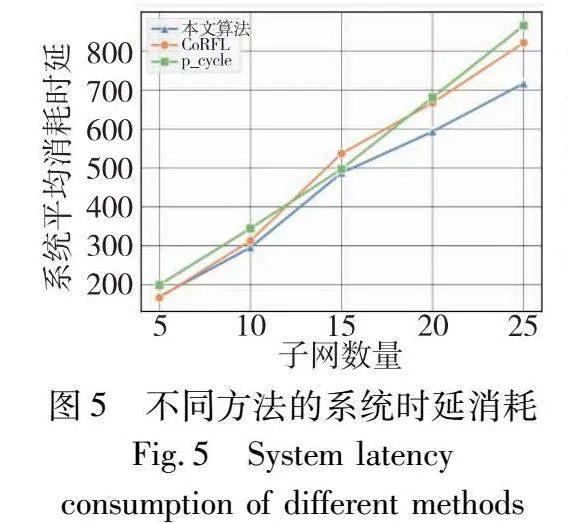
本文算法与对比算法的系统平均时延消耗如图5所示。由图5可知,随着系统中子网数量的不断增加,本文算法与两种对比算法的时延消耗都逐渐增大,p-cycle算法在子网数量规模增大的过程中,系统消耗时长增幅也逐渐增大。CoRFL算法的消耗时长在小规模系统应用中表现效果尚佳,但对于大规模系统所耗费时间逐渐增多。在子网数量从5增加到25时,本文算法的时延消耗增加值大约为500,并且其耗费时长的涨幅也随着子网数量增加表现出缩小的趋势,因此本文算法在实现连通性恢复时所耗费的时间方面均优于两种对比算法,并且随着系统规模的增大,本文算法与两种对比算法所耗费时间的差值也有所增大。
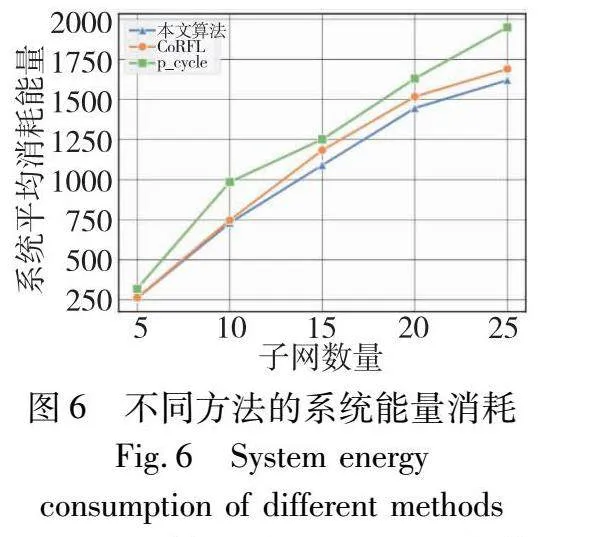
本文算法与两种对比算法的系统平均能量消耗如图6所示。由图可知,在实现连通恢复过程中四种方法的系统平均能量消耗值都随着系统中智能体数量的增加变化幅度较大,p-cycle在实现网络连通恢复过程中的智能体能量消耗值明显高于其他三种方法。在子网数量规模较小时,本文算法以及CoRFL所产生的系统消耗相差不大,但随着子网数量的增多,CoRFL和本文算法消耗的能量增幅较小,并且本文算法在大规模子网系统中所产生的能量消耗小于CoRFL,因此在能量消耗方面,本文算法优于两种对比算法。
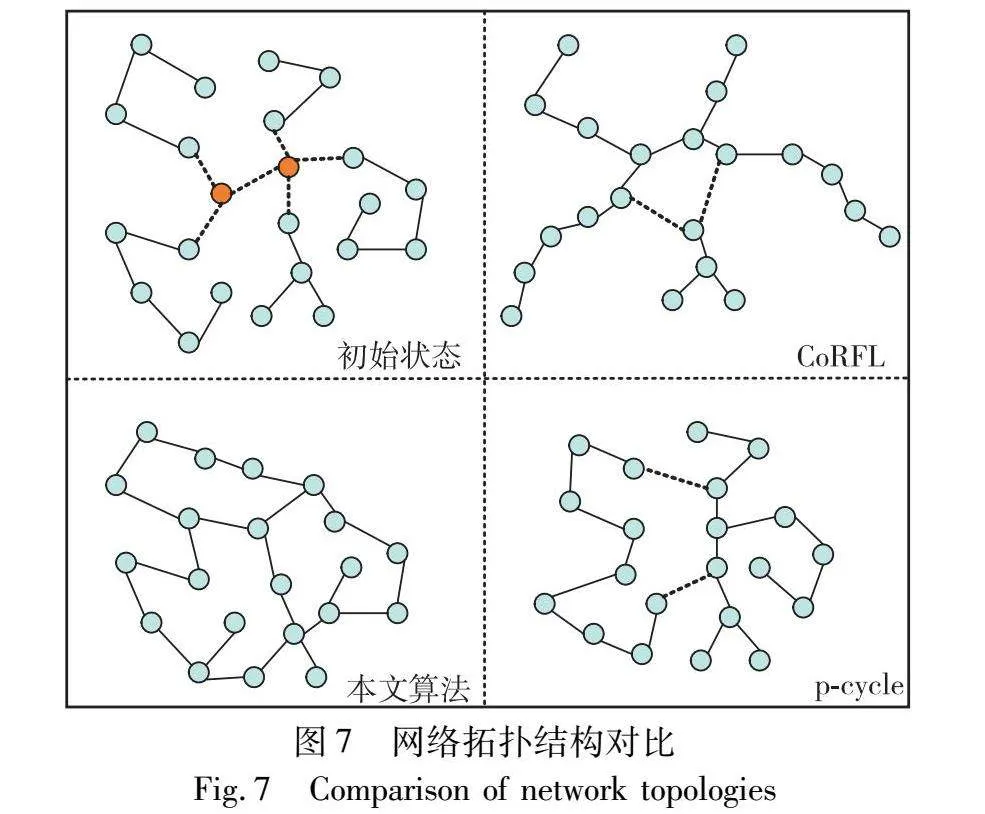
为了展现本文算法相较于两种对比算法在实现连通恢复过程中的效率优势,图7展示了本文算法连通性恢复过程结束时与其他两种算法的网络拓扑结构对比(图中节点则代表智能体)。由图7可以得出,本文算法相比于两种对比算法,更早完成网络全连通恢复,在相同的恢复时间内,本文算法已实现全部连通,不存在割裂子网,而两种对比算法均存在不同程度的割裂情况,未达到全连通恢复的效果。在恢复的过程中,CoRFL算法更多考虑对节点进行路径规划和编队,其所实现的连通性恢复更趋向于形成一条通信链路。p-cycle算法在实现连通恢复的过程中更多考虑避障,节点间会保持最大的安全距离。
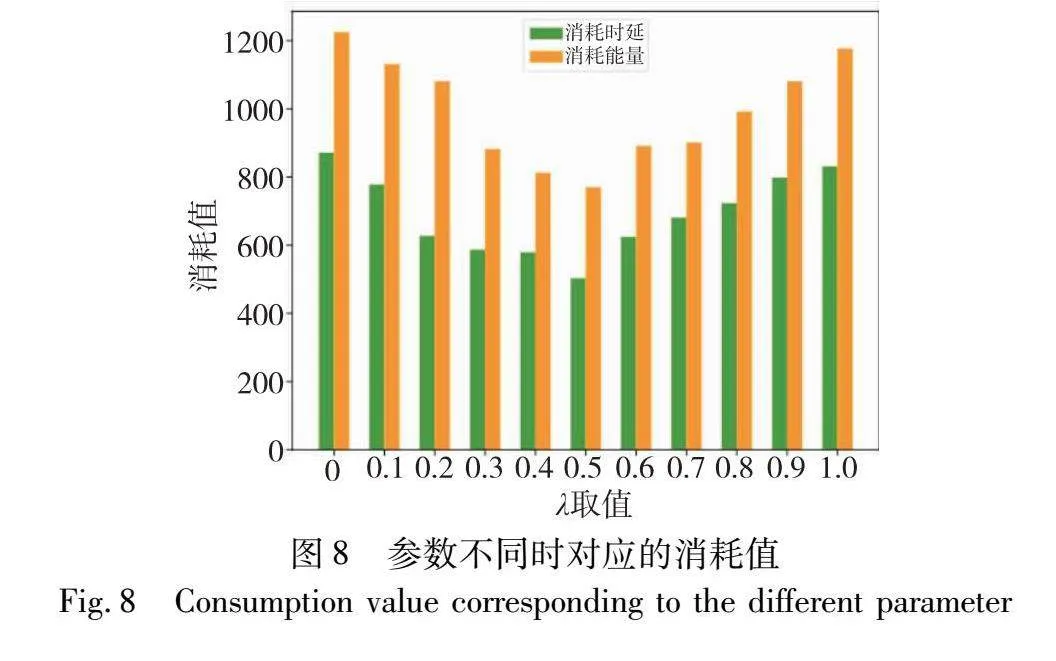
此外,由于本文设置的奖励函数由领航者的剩余能量和与子目标距离两部分组成,通过设置奖励函数不同部分的参数来得到最终智能体在时延和能量两部分的消耗值,如图8所示。λ是针对能量消耗所设置的奖励参数,按[0,1]进行取值,可以观察到,随着λ参数的增大,系统完成连通性恢复所消耗的能量和时间都出现了先减小后增大的趋势。在过度追求能耗奖励的时候,子网会更贪心地选择剩余能量较多的智能体作为领航者,忽视了对移动子目标的探索,从而增加了系统恢复所消耗的时间,造成系统产生的总能量增加。同样,在过度追求恢复时间时,在进行领航者切换时忽略了智能体本身所剩余的能量,会导致网络恢复过程中产生较多的故障智能体,这也为系统的连通性恢复带来了阻碍,从而增加了系统恢复所需的时间。因此,本文所设计的两个部分奖励:能耗奖励和距离奖励函数,是息息相关的,两者呈现出同样的变化趋势,只有在两者权重相同的时候,才能使系统实现网络连通性恢复所产生的能量消耗和时间消耗达到最优的效果。
6 结束语
为了实现多智能体网络中的连通性恢复,本文通过在分区中选择健康节点的方式,提出了一种领航-追随者模式的网络连通性恢复方法。首先,通过智能体周期性信息交互确定网络中的故障区域以及子网划分情况;然后,结合子网在融合过程中会产生的网络开销等提出了基于强化学习的领航-追随者恢复机制,各子网之间呈现分布式,子网内部采用领航-追随者模式,通过强化学习不断去探索更优的恢复策略,选举出每一轮的最佳领航者。最后,提出子网融合来实现全网连通恢复,在子网连通矩阵发生改变时判断是否达成全网连通,从而实现全网连通的结果。实验结果表明,本文方法不仅能有效恢复网络连通,更适用于较大的网络系统的连通性恢复。在未来的工作中,将考虑任务环境下的多智能体网络连通性恢复,节点移动不仅要考虑到实现连通,更要兼顾环境中的任务完成情况。同时,将考虑网络拥塞、网络异常流量等因素对网络连通恢复的影响。
参考文献:
[1]Xu Jianyou, Zhang Zhichao, Zhang Shuo, et al. An improved traffic signal control method based on multi-agent reinforcement learning[C]//Proc of the 40th Chinese Control Conference. Piscataway, NJ: IEEE Press, 2021: 6612-6616.
[2]Majima T, Takadama K, Watanabe D, et al. Application of multi agent system and transition matrix analysis to logistics system for equal distribution under disaster situation[C]//Proc of the 58th Annual Conference of the Society of Instrument and Control Engineers of Japan. Piscataway, NJ: IEEE Press, 2019: 108-114.
[3]Zhang Jiawei, Chang Cheng, Zeng Xianlin, et al. Multi-agent DRL-based lane change with right-of-way collaboration awareness[J]. IEEE Trans on Intelligent Transportation Systems, 2022, 24(1): 854-869.
[4]Wang Jie, Li Shaoyuan, Zou Yuanyuan. Connectivity-maintaining consensus of multi-agent systems with communication management based on predictive control strategy[J]. IEEE/CAA Journal of Automatica Sinica, 2023, 10(3): 700-710.
[5]ElHamamsy A, Aghili F, Aghdam A. Connectivity preservation and collision avoidance in multi-agent systems using model predictive control[J]. IEEE Trans on Network Science and Engineering, 2023, 10(3): 1779-1791.
[6]Zhou Ruimin, Ji Wenqian, Xu Qingzheng, et al. Collision avoidance and connectivity preservation for time-varying formation of second-order multi-agent systems with a dynamic leader[J]. IEEE Access, 2022, 10: 31714-31722.
[7]Akkaya K, Senturk I F, Vemulapalli S. Handling large-scale node failures in mobile sensor/robot networks[J]. Journal of Network and Computer Applications, 2013, 36(1): 195-210.
[8]Park S Y, Shin C S, Jeong D, et al. DroneNetX: network reconstruction through connectivity probing and relay deployment by multiple UAVs in Ad hoc networks[J]. IEEE Trans on Vehicular Techno-logy, 2018, 67(11): 11192-11207.
[9]Bashir N, Boudjit S, Saidi M Y. A distributed anticipatory life-enhancing recovery approach for unmanned aerial vehicular networks[C]//Proc of the 18th IEEE Annual Consumer Communications & Networking Conference. Piscataway, NJ: IEEE Press, 2021: 1-7.
[10]Senturk I F, Akkaya K, Yilmaz S. Relay placement for restoring connectivity in partitioned wireless sensor networks under limited information[J]. Ad hoc Networks, 2014, 13: 487-503.
[11]Baroudi U, Aldarwbi M, Younis M. Energy-aware connectivity restoration mechanism for cyber-physical systems of networked sensors and robots[J]. IEEE Systems Journal, 2020, 14(3): 3093-3104.
[12]Awoyemi B S, Alfa A S, Maharaj B T. Network restoration in wireless sensor networks for next-generation applications[J]. IEEE Sensors Journal, 2019, 19(18): 8352-8363.
[13]Mou Zhiyu, Gao Feifei, Liu Jun, et al. Resilient UAV swarm communications with graph convolutional neural network[J]. IEEE Journal on Selected Areas in Communications, 2021, 40(1): 393-411.
[14]Sader M, Wang Fuyong, Liu Zhongxin, et al. Distributed fuzzy fault-tolerant consensus of leader-follower multi-agent systems with mismatched uncertainties[J]. Journal of Systems Engineering and Electronics, 2021, 32(5): 1031-1040.
[15]Mukherjee S, Namuduri K. Formation control of UAVs for connectivity maintenance and collision avoidance[C]//Proc of IEEE National Aerospace and Electronics Conference. Piscataway, NJ: IEEE Press, 2019: 126-130.
[16]Cao Lei, Liu Guoping, Zhang Dawei. A leader-follower formation strategy for networked multi-agent systems based on the PI predictive control method[C]//Proc of the 40th Chinese Control Conference. Piscataway, NJ: IEEE Press,2021: 4763-4768.
[17]Liu Chunming, Xu Xin, Hu Dewen. Multiobjective reinforcement learning: a comprehensive overview[J]. IEEE Trans on Systems, Man, and Cybernetics: Systems, 2014, 45(3): 385-398.
[18]Kandath H, Senthilnath J, Sundaram S. Mutli-agent consensus under communication failure using actor-critic reinforcement learning[C]//Proc of IEEE Symposium Series on Computational Intelligence. Piscataway, NJ: IEEE Press, 2018: 1461-1465.
[19]米德昌, 王霄, 李梦丽, 等. 灾害应急场景下基于多智能体深度强化学习的任务卸载策略[J]. 计算机应用研究, 2023, 40(12): 3766-3771,3777. (Mi Dechang, Wang Xiao, Li Mengli, et al. Task offloading strategy based on multi-agent deep reinforcement learning in disaster emergency scenarios[J]. Application Research of Computers, 2023, 40(12): 3766-3771,3777.)
[20]Zhao Maomao, Zhang Shaojie, Jiang Bin. Multi-agent cooperative attacker-defender-target task decision based on PF-MADDPG[C]//Proc of the 6th International Symposium on Autonomous Systems. Piscataway, NJ: IEEE Press, 2023: 1-6.
