有状态协议模糊测试的种子调度算法
2024-10-14谢宇豪徐向华



摘 要:为了探索有状态协议的程序漏洞,AFL-NET提出了有状态协议模糊测试。在有状态协议模糊测试中,种子的选择对路径的探索有着重大的贡献。然而,目前的有状态协议模糊测试往往重复执行几个相同的种子,导致不能很好地探索更多的路径。为了缓解该问题,从种子的收益入手,提出了一种有效的基于有状态协议的种子动态调度算法。利用种子的潜在收益和实际收益以及成本作为收益,利用收益来进行动态的种子调度,并分配种子的执行次数。实验表明,该方法在漏洞发现数量上有显著提升,在提高覆盖率方面也有一定的提升,说明此收益定义以及种子调度算法能有效选择种子,探索更多的路径以及漏洞。
关键词:模糊测试; 灰盒; 协议测试; 漏洞挖掘
中图分类号:TP311 文献标志码:A
文章编号:1001-3695(2024)10-033-3119-05
doi:10.19734/j.issn.1001-3695.2024.01.0053
Seed scheduling algorithm for fuzzing stateful protocols
Xie Yuhao, Xu Xianghua
(School of Computer Science, Hangzhou Dianzi University, Hangzhou 310018, China)
Abstract:In order to investigate vulnerabilities in stateful protocols, AFL-NET has put forward stateful protocol fuzz testing. In such fuzz testing, the selection of seeds makes a major contribution to the exploration of paths. However, current stateful protocol fuzz testers often repeatedly execute the same several seeds, resulting in an inability to effectively explore more paths. To alleviate this problem, starting from the gain of seeds, this paper proposed an effective seed dynamic scheduling algorithm based on stateful protocols. The algorithm utilized the potential gain, actual gain, and cost of seeds as the gain, using this gain to dynamically schedule seeds and allocate the number of times seeds. Experiments show that this method significantly improves the number of vulnerabilities found and also has a certain degree of improvement in increasing coverage, indicating that the definition of this gain and the seed scheduling algorithm can effectively select seeds and explore more paths and vulnerabilities.
Key words:fuzz testing; grey box; protocol testing; vulnerability mining
基于覆盖的灰盒模糊测试使用的方法主要是遗传算法,通过遗传算法来探索路径。主要思想是:将一个输入作为一个种子,通过大量变异算子变异后进行迭代,将其输入到程序中,再通过对程序的覆盖统计等方法判断该种子是否探索了新的执行路径。探索了新执行路径的种子会被添加到种子池中进行下一轮的选择,如此反复,不断繁衍。有状态协议模糊测试还需要考虑到程序的不同状态,需要到达程序的不同状态,再进行种子的输入[1]。由于有状态的灰盒协议模糊测每次执行需要重启服务器,并且种子的输入是通过socket套接字,所以效率低于基于覆盖的灰盒模糊测试。对于基于覆盖的灰盒模糊测试已经有很多相关工作,例如定向模糊测试[2]、嵌入式模糊测试[3]、工控协议模糊测[4]等。
对于有状态协议模糊测试如何优化,目前主要的研究方向有四点:a)对变异算法的改进;b)对状态选择的改进;c)对种子的选择;d)提高效率。
当前的有状态协议模糊测试对于种子的选择主要考虑种子收益,即种子探索新路径的能力。一般从路径的转移概率、种子中新路径数量、种子中独特的状态个数、种子执行时间来进行考虑,并且通过这些数据来计算给种子分配的能量(即该种子执行多少次变异)。然后,将增加了新覆盖的种子加入到种子池中。然而,这种方式无法进行种子的动态选择,比如,一个种子在执行过程中产生了新的覆盖,那么理所当然该种子的收益更大,选择该种子的概率越大。然而,这种方式在第一次执行时就确定了该种子的收益,无法根据程序的执行动态增加或者减少该种子的收益。因此,动态计算种子收益、动态选择种子、动态能量分配十分重要。
针对上述问题,本文提出了一种轻量级的动态种子调度算法和能量分配算法SCFuzzer。SCFuzzer利用种子潜在收益、实际收益、成本进行动态概率分配和能量分配,通过在模糊执行过程中动态计算种子的收益来调度种子,实现种子调度的优化。
本文主要贡献如下:
a)提出了一种基于种子潜在收益、实际收益和成本来动态计算收益并调度种子的算法。从多方面考虑种子探索新路径的能力,并给出了一种有效性度量,实现动态的种子调度。
b)基于该度量实现了种子的动态能量分配策略,对重点种子执行更多次数的变异,使其能够有更多时间进行对程序空间的探索。
c)基于AFLNET[5]实现了SCFuzzer,并在广泛使用的RTSP和DTLS协议中进行了实验测试。在24 h的实验中,对覆盖率的提升约2%,对漏洞发现数量提升约50%。
1 背景和动机
1.1 研究动机
在本节中,通过一个例子来说明种子的选择对模糊器在路径探索中的影响。在算法中,使用静态的种子选择策略,假设有两个种子S1和S2,种子S1的执行路径为7->11->12,种子S2的执行路径为7->8->2->4。假设在先前的执行中,S2更有可能被选中,那么S2会持续执行,但是最终S2会一直执行到代码行4的判断语句,因为该判断语句很难被突破,它是字符串的比较,那么在很长的一段时间内S2都不会探索新的路径。而种子S1在先前的执行中被选中的概率较小,但它更有可能探索新的路径。
算法1 不同种子执行路径的探索
1 bool isCompare(string str){
2 if (str.size()>5)
3 retum false;
4 if (str[0]=='a' && str[1]=='b' && str[2]=='c'&& str[3]=='d'&& str[4]=='e'
5 return true;
6 }
7 if (flag==1){
8 if (isCompare(str))
9 …
10 }
11 else {
12 …
13 }
因此,如果使用静态的种子调度算法,那么就不能很好地反映种子在执行过程中不断变化发现新执行路径的能力。
1.2 研究背景
如上所述,AFL-NET在种子调度上并没有很好地利用程序执行过程中的信息,导致可能会长时间选择同一个很难探索新路径的种子,而且选择的种子大多执行的都是相同的路径。事实上,已经有许多研究表明,种子的选择对于模糊测试来说非常重要。
有状态协议模糊测试中,对于种子调度尚未有充分的研究。而在基于覆盖的灰盒模糊测试中,已经有许多对于种子调度的研究,它们考虑了影响种子收益的不同影响因子,大致可以分为两类:
a)基于历史信息。在基于历史信息的相关研究中,确定一个种子的收益主要基于该种子的历史执行信息。EcoFuzz[6]通过多臂老虎机确定一个奖励概率,该奖励概率基于该种子的自转移概率和加入种子池的时间来确定。EcoFuzz将自转移概率定义为该种子进行变异以后,探索路径和未变异时的探索路径相同的次数和总次数的比值,并将模糊测试阶段分为三个阶段,只有在每个种子都选择过一遍以后,才会通过奖励概率来选择种子,并且提出了一种基于探索新路径需要的平均执行次数来确定种子执行次数的能量分配方案。AFL-FAST[7]提出了利用马尔可夫链说明更深层次的路径需要更多执行过程,因此AFL-FAST给低频路径分配了更多的收益和能量。DiPri[8]提出了基于种子距离的种子调度算法,其依据是应该模糊整个程序代码不同位置,探索不同代码位置的新路径。DiPri通过位图计算种子与其他种子的距离之和,该种子距离越远,则种子的收益越高,因为该种子的执行路径位于代码块的不同位置。Truzz[9]认为具有更多新发现路径的种子收益更大。然而这些方法并不能完全表明种子探索新路径的能力,如果该种子遇到的分支很难被突破,那么这些方法将会浪费大量的时间执行很难突破的分支。
b)基于程序控制流图。在基于控制流图的相关研究中,确定一个种子选取的概率和能量主要基于该种子的执行路径上有多少未探索的路径。K-Scheduler[10]利用图的中心性对一个种子计算得分,分数越高的种子收益越高。K-Scheduler提出了一种方法,将程序控制流图转换为边缘视界图,通过该图计算一个种子的得分。BELIEFFUZZE[11]提出了一种平衡收益和成本的种子调度算法。一个种子的收益是基于程序控制流图中该种子变异之后可能覆盖的潜在路径的数量来计算的,而成本定义为该种子的执行次数。BELIEFFUZZE综合考虑了一个种子的收益和成本,收益高的种子优先执行,但是如果对该种子付出了难以接受的成本,而该种子并未探索新的路径,那么就应该放弃该种子。基于程序控制流图的方法需要得到程序的控制流图,然而,在有状态的协议模糊测试中,在不同状态下,程序的走向不同,那么程序的控制流图也会不同。因此,在有状态的协议模糊测试中使用该方法会导致更多额外的开销。
为了解决有状态的协议模糊测试中,种子调度和能量分配的问题,使得选取的种子能更加有效地探索新路径,并给其分配适应的能量。本文提出了一种在有状态的协议模糊测试下,能够动态调度种子并分配能量的轻量级算法。
2 方法概述
2.1 种子收益的影响因子
本文目标是对更能探索新路径的种子进行更多变异测试,因此应该选择更能探索新路径的种子。本文将能够探索新路径的能力映射为种子的收益。
种子收益的影响因子主要有探索新的路径的数量、执行路径旁的未探索路径的数量、执行路径中低频路径的数量、种子的执行次数等因子。
种子执行路径旁的未探索路径表明了该种子还可以探索的路径数量,因此其可以表示为种子的潜在收益。而种子探索新路径的数量表明了该种子探索新路径的能力,本文认为其可以表示为种子的实际收益。种子的执行次数表明了该种子探索新路径所花费的时间,其可以表示为所需要的成本。因此可以定义一个种子的收益,包含其未探索路径的能力,将探索路径转换为已探索路径的能力以及探索的成本。
2.2 种子距离算法
DiPri提出了一种种子距离的算法,可以很好地计算种子执行路径在程序空间中的分布。DiPri通过记录覆盖率的位图来计算种子和其他种子的距离。其中,记录覆盖率的位图是将程序的每一个基本块通过哈希映射到位图中的一位,如果该位为1,那么就表明该基本块已经被探索过。因此,种子之间的距离就很好地反映了该种子执行经过的基本块与其他种子执行经过的基本块的距离,也即程序中的不同位置。通过计算种子的距离,可以避免探索密集的区域,并为很少探索的区域节省资源。
2.3 使用种子距离的动机
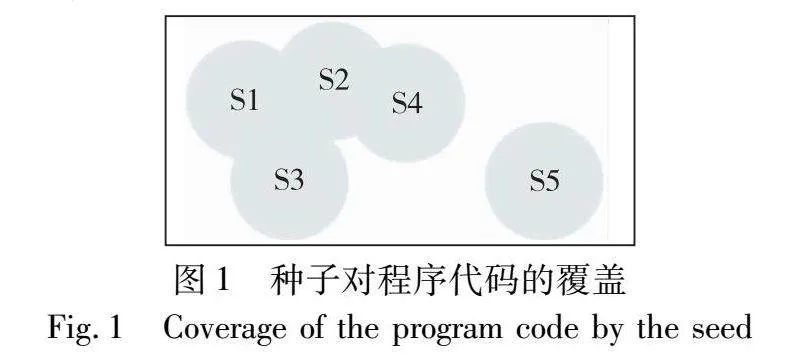
使用程序控制流图计算种子收益的缺点已在1.2节详细阐述。因此,本文更倾向于使用历史信息来计算一个种子的收益。其中,种子的距离能更好地体现出一个种子的潜在收益,即一个种子能探索新路径的潜在能力。以图1为例,假设有5个种子,其中S1、S2、S3、S4的执行路径都集中在程序代码空间的一部分,而S5在程序代码空间的其他部分。那么直观地发现S5周围可以探索的空间比其他四个种子都要大,因此种子S5的潜在收益更大。然而,由于只是将种子距离近似为程序控制流图中一个种子可能探索的新路径,有的路径可能很难被突破,所以将其认为是该种子潜在的收益。
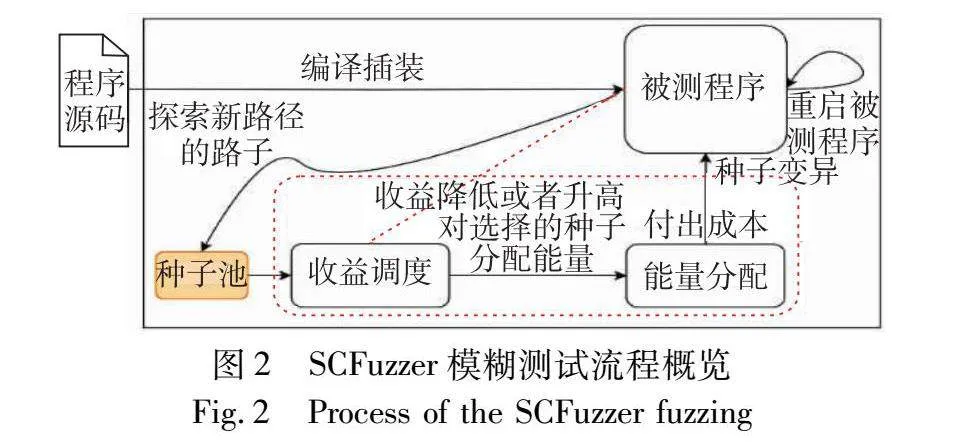
2.4 框架
本文的设计方案工作流程如图2所示,其中红色框中的内容即为本文的主要内容,其主要分为收益调度和能量分配两个模块。由这两个模块共同组成本文的动态种子调度算法和能量分配算法,通过这两个模块,可以动态地选择种子和切换种子,动态地改变一个种子的能量分配。
2.5 收益调度模块
如2.1节,本文目标是对更能探索新路径的种子进行更多变异测试,因此,种子收益即为种子探索新路径的能力。种子执行路径旁的未探索路径的数量表明了该种子还可以探索多少条新路径。种子实际探索路径的数量表明该种子将未探索路径转换为已探索路径的能力。种子执行花费的时间表明该种子探索新路径花费的时间成本。这三元组规定了种子探索新路径的潜在能力,探索新路径的实际能力和探索新路径的成本,因此该三元组即可很好地表明一个种子探索新路径的能力。综上所述,将一个种子的收益定义成潜在收益、实际收益和成本三个方面。
a)潜在收益。将潜在收益定义为种子能够探索到多少新路径的能力,并将其解释为种子距离。种子距离可以很好地表示种子在程序代码空间中与其他种子的位置,该位置与其他种子位置越远,那么该种子可以探索的潜在路径就更多,也就是潜在收益越高。
潜在收益的计算:将潜在收益定义为种子的距离,其计算方法和DiPri类似,使用海明距离通过位图来计算种子与其他种子的距离,将其距离之和作为种子的潜在收益。与DiPri不同的是,首先DiPri没有状态的概念,在AFL-NET中一个种子对应于多个报文,首先需要发送前序报文到达指定状态,然后才能发送需要变异的报文,其中的一个报文对应于DiPri中的一个种子。因此,在AFL-NET中所关注的种子距离会受到前序报文的影响。如果两个种子到达该状态时执行的路径距离很远,然而执行变异报文而探索的路径距离几乎一致,则认为这两个种子距离相近。因为需要考虑的是到达同一个状态之后种子的距离,而DiPri就没有考虑到状态,导致所发送的前序报文会污染种子的距离。因此,本文提出的种子距离的计算需要剔除掉前序报文的影响,单独计算变异报文探索路径的距离。此外,如果每次单独计算种子的距离,如果有n个种子,那么每次添加一个种子都需要计算n次再次求和。因此提出了一种优化的种子距离算法,通过海明距离计算,其公式如下:
distance(s,S)=∑k1(si^(s0i,S1i))
其中:s表示为需要计算种子的位图;S0和S1记录其他所有种子位图中每一位的0出现的次数和1出现的次数。因此每次计算一个种子的距离时,只需要判断位图中的每一位,如果该位是1,那么distance(s,S)就加上位图中该位0出现的次数,反之亦然,然后更新S1和S2。这样每次添加一个种子需要n次求和降低到了1次求和。种子距离算法如算法2所示。
算法2 距离计算模块
输入: 当前的种子s;位图S0,S1;位图的长度size。
输出: 种子s的距离。
pre=get_pre_message(s) //获取种子的前序报文路径
trace_bit_pre=exec_pre_message(pre) //计算前序报文的路径
trace_bit=exec_message(s) //计算整个种子的路径
for j=0 to size do
trace_bit_bef[j]=trace_bit[j] ^ trace_bit_pre[j]
//计算后续报文路径
end for
for i=0 to size do //计算路径距离
if (race_bit_bef[i]==0)
distance=distance + S1[i]
else
distance = distance + S0[i]
end if
end for
b)实际收益。将实际收益定义为该种子探索新路径的数量。实际收益能够表明种子将潜在收益转换为收益的能力,即探索潜在路径的能力。通过实际收益可以解决先前工作可能会将大量时间浪费在很难产生新覆盖的种子上,并进行种子的动态调度。
c)成本。将成本定义为种子的执行时间。先前的工作将成本定义为种子的执行次数,在基于覆盖的灰盒测试中,例如BELIEFFUZZE,提出了以执行次数作为成本,这是可行的,因为每个种子执行的时间都很快,而且都大致相同。而在有状态的协议模糊测试中,每个种子的执行时间可能相差很大。这是因为在有状态的协议模糊测试中,每个种子中的报文数量也不尽相同,有的种子的前序报文很短,可能很快就能执行完成,有的种子的前序报文可能很长,所有需要更多的执行时间,因此使用执行时间来衡量种子的成本。本文基于以下的事实,即潜在收益是固定的,根据种子距离表明该种子能探索新路径的潜在能力,而实际收益根据该种子是否真正探索了新路径,表明该种子的真正能力,而成本根据种子的执行时间,表明付出的成本是否得到了预期的收益,因此定义种子的收益为
Benefit=Benefitp×l1+Benefitr×l2-cost×l3
d)动态的种子调度算法。基于上述收益公式,定义如算法3所示的动态种子选择算法。首先,将初始种子进行执行,并将其(即种子s)添加到相应状态下的种子池中,并计算每个种子的距离,更新每个状态下的位图S0和S1,其中S0和S1分别记录该状态下的所有种子每个基本块被执行次数。然后,每次在一个状态下有一个变异的种子探索了新的路径时,将其加入到该状态下的种子池中,并且计算其种子距离和相应的执行时间,同时更新S0和S1。当一个种子执行完毕时,需要从种子池中选择下一个种子,通过收益选取种子,如算法4所示。具体地,计算所有种子的收益,以及种子集合S的收益总和,然后计算出每个种子收益的占比,将此占比作为种子选择的概率,通过此概率依概率选择下一个种子。
算法3 种子选择模块
输入:当前的种子s;初始种子集合S。
输出: 选中的种子s。
benefit_sum=calculate_benefit_sum(S);
//计算总收益
for s in S
benefit_rate_s = benefit_s / benefit_sum;
//计算每个种子的收益占比,将其作为概率
end for
s=choose_seed_by_benefit_rate(S);//依概率选择选中
算法4 收益调度模块
输入:当前的种子s;初始种子集合S。
输出:null。
s=choose_seed(S) //根据收益选取一个种子
power=calculate_power(s, benefit(s)) //计算能量
while power do
mutate_exec_seed(s)
if find_new_path()
add_power(update_benefit(s)) //增加能量
update_bitmap(s, S0, S1)
add_to_seed_pool(s)
end if
decrease_power(power)
update_benefit(s)
if is_choose_next_seed(benefit(s), S) /*如果付出过多成本而没有预期的收益,那么本文选择下一个种子*/
choose_next_seed(S)
end if
end while
能量分配模块给选出的种子分配相应的能量。在该种子的执行过程中,每次执行都会付出相应的成本(即执行时间),如果该种子经过多次执行并未探索新的路径,那么其收益由于付出的成本就会降低,能量分配模块就会降低给其分配的能量。而如果该种子执行过程中探索了新的路径,那么该种子的实际收益就会变高,导致整体的收益增加,能量分配模块就会增加其分配的能量。当为该种子付出的成本而没有得到预期收益的时候,那么就会切换种子,转而执行下一个种子。
2.6 能量分配模块
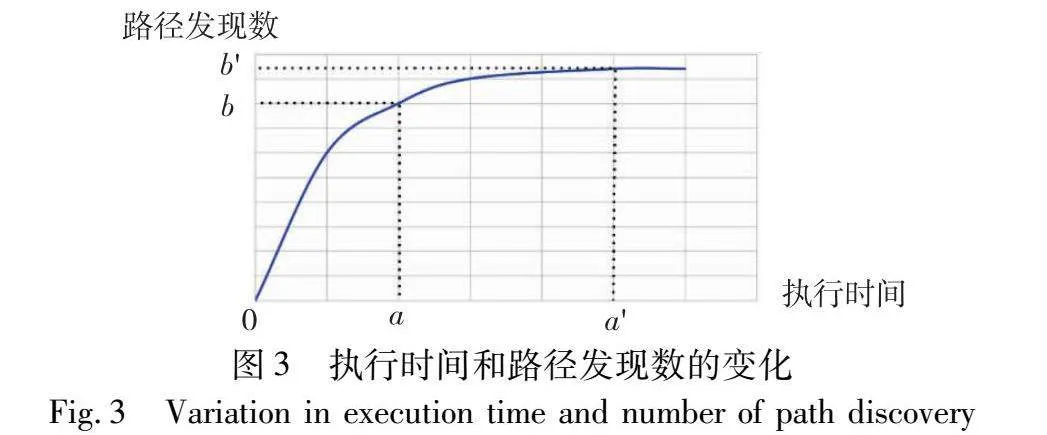
基于种子的收益进行能量的分配,将能量定义为分配给种子的执行时间。在有状态协议模糊测试中,每个种子的执行时间不尽相同,因此,基于执行次数的能量分配偏差较大,而执行时间更能公平地分配能量。本文基于一个动态平均值分配能量,即每次发现新路径需要的种子执行时间,如图3所示。
随着测试时间增加,需要更多的执行时间才能够探索新的路径,因此,平均的能量应该基于模糊的进行而改变,当前探索一条新路径所需要的时间作为基准。收益较高的种子初始分配的能量略高于平均值,因为希望它们能有更多的时间探索新的路径。在种子每次执行之后,将减少其能量,而如果该种子探索了新路径,那么就会增加该种子的能量。当一个种子始终没有探索新的路径,就认为付出了过多的成本,而没有获得相应的收益,则会切换到下一个种子。
因此,根据这个当前时间的平均值来分配能量。每次选取种子时根据种子收拾增加或者减少分配的能量。在种子执行时能量会不断减少,在种子获得新的收益时,那么种子的能量就会增加。如果在执行过程中,该种子付出了太多的成本而没有探索新的路径,那么就会转而选择下一个种子进行执行。
3 实验评估
3.1 实验设置
为了对本文方法进行效果验证,对几款使用不同收益影响因子进行种子选择的工具进行比较,即AFL-FAST[7]、DiPri[8]、BELIEFFUZZER[11]。AFL-FAST将执行次数作为种子收益,执行次数越少的种子收益越高;DiPri仅仅利用种子的距离作为收益;而BELIEFFUZZER使用程序控制流图计算种子可以到达的边,以到达的边数作为收益,执行时间作为成本。由于这三款工具都没有公开源码,而且它们实现时基于覆盖的灰盒模糊测试,所以在AFL-NET上面简单地实现了这三种方法,使用其收益定义的方法依收益选择种子,并进行了对覆盖率和漏洞数量检测的实验。
实验时长:24 h×5×2×3=576 h,设备参数:Intel CoreTM i7-8750H CPU @ 2.20 GHz 2.21 GHz,内存设置4 GB,操作系统版本:Ubuntu 18.04.6 LTS。
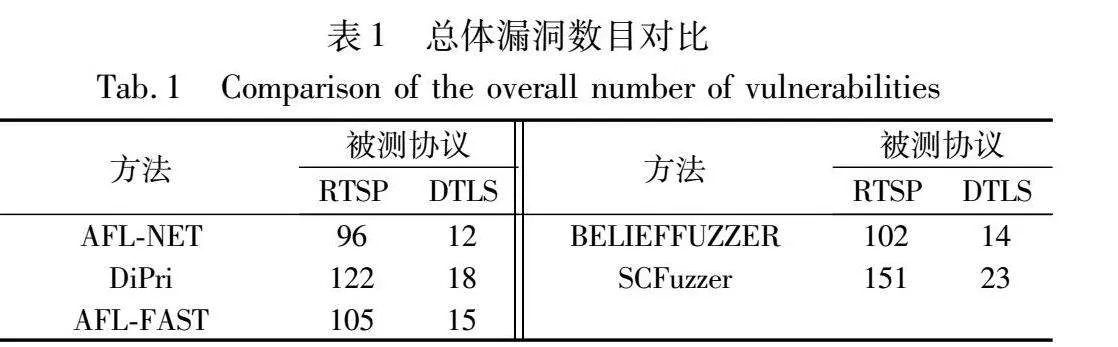
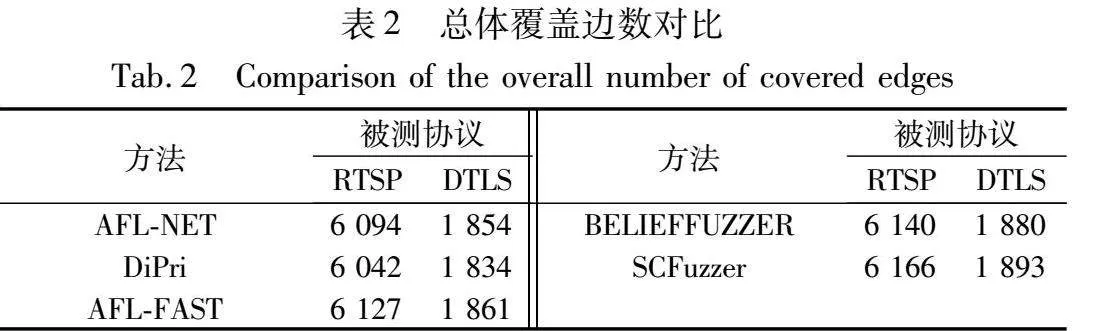
本文的单个测试实验都设定为24 h,测试在24 h内能够发现的漏洞数与覆盖率情况。实验方式:单组实验做三次,取这三次平均的情况作为单组实验结果进行记录。表1记录发现的漏洞数量,表2记录覆盖的边数。
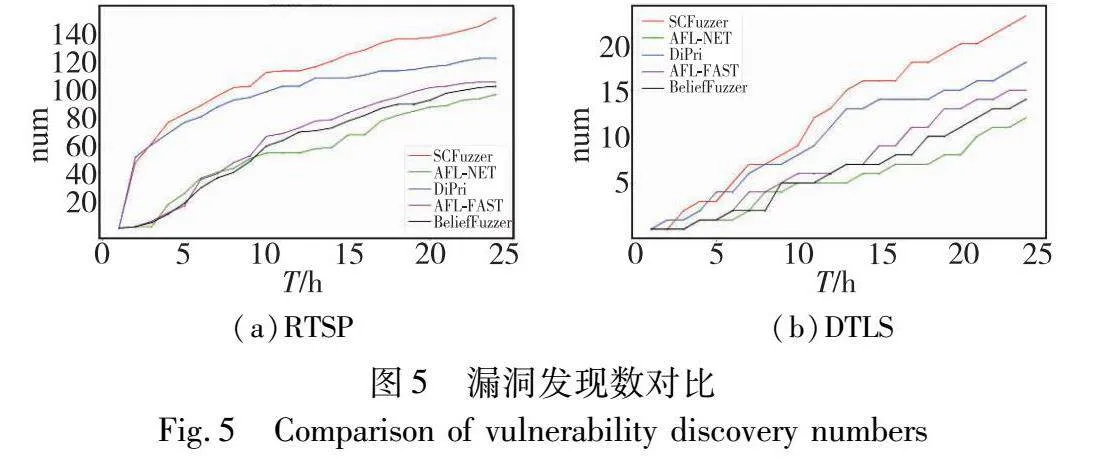
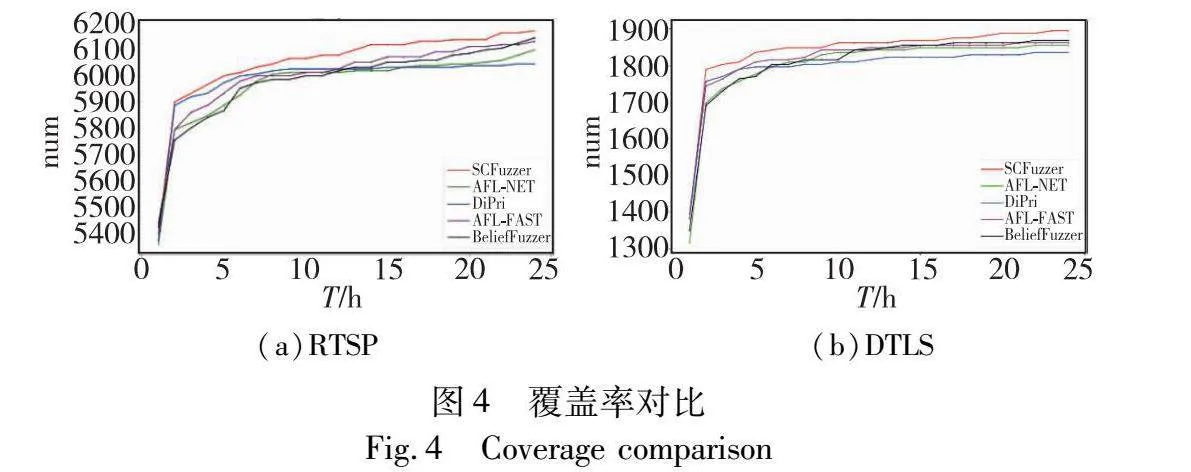
图4记录RTSP和DTLS的覆盖率变化,图5记录RTSP和DTLS协议的漏洞发现数量的变化。
3.2 实验结果
通过实验结果可以发现,SCFuzzer在漏洞发现数量和覆盖率上都优于其他的模糊测试工具。对于RTSP协议,SCFuzzer能够覆盖6 166条边,相较于AFL-NET提高了大约1%,SCFuzzer能够发现151个漏洞,相较于AFL-NET提高了大约57%。而其他使用不同收益影响因子的算法,DiPri能够覆盖6 032条边,发现122个漏洞,AFL-FAST能覆盖6 127条边,发现105个漏洞,BELIEFFUZZER能够覆盖6 140条边,发现102个漏洞。
对于DTLS协议,SCFuzzer能够覆盖1 893条边,相较于AFL-NET提高了大约2%,SCFuzzer能够发现23个漏洞,相较于AFL-NET提升了大约91%。而其他使用不同收益影响因子的算法,DiPri能够覆盖1 834条边,发现18个漏洞,AFL-FAST能覆盖1 861条边,发现15个漏洞,BELIEFFUZZER能够覆盖1 880条边,发现14个漏洞。在方案开销方面,SCFuzzer的开销要大于AFL-NET和AFL-FAST,但是小于DiPri和BELIEFFUZZER。
因此,SCFuzzer在覆盖率方面有一些提升,在发现漏洞方面提升较为明显。
3.3 结果分析
通过结果可以发现,SCFuzzer在漏洞发现数量上面有明显的提升,是因为收益影响因子的方案会优先选择与其他种子距离更远的种子,这些种子由于其路径的独特性,更有可能潜藏着漏洞。其次,由于AFL-NET等模糊测试工具主要模糊的都是比较相似的路径,所以就更难发现在其他代码位置上的其他种子。还可以发现,DiPri的方案虽然发现的漏洞数量有较大的提升,然而其覆盖率却没有提升反而有所下降。由于DiPri的种子距离计算方法开销较大,所以导致该模糊测试效率降低。此外,由于DiPri的种子调度方案是静态的,只考虑了种子的距离,所以经常会执行一些很难探索新路径的种子,导致在这些种子上面浪费了大量的能量。而且由于DiPri没有考虑到状态的因素,导致该方案的种子距离计算不够准确,也就导致了其覆盖率的降低。AFL-FAST由于收益由低频路径的数量来决定,那么可能导致会经常执行很难突破的路径分支,产生大量浪费。BELIEFFUZZER在漏洞和覆盖率这两方面相较于AFL-NET都有一定的提升。主要是因为其综合考虑了成本和收益,不会在一个很难探索新路径的种子上浪费大量的能量。但是经过分析发现,BELIEFFUZZER的主要问题在于该方案生成的程序控制流图中没有考虑状态的因素,即有些边可能只有在某个状态才能被突破,因此对该种子收益的计算不够准确,会将在该状态下不能被突破的边也计算进入收益。此外,收益高一些的种子一般都执行一些相似的路径,所以导致BELIEFFUZZER经常执行这些高频路径。
本文方案相较于DiPri,根据有状态的协议模糊测试的特点,将种子距离的计算改为了对到达该状态后的后续报文的距离计算,并且优化了种子距离算法。但是由于考虑到了状态,在每次添加一个种子时,需要在不同状态的种子池中添加该种子,并计算距离,导致了额外的开销,所以本文方案的执行速度低于AFL-NET。此外,本文使用种子距离作为潜在收益,然而种子距离并不代表可能探索的新路径。由于根据不同状态得到不同的程序控制流图可能导致更多的额外开销,所以只能选择将可能探索的新路径近似为种子间的距离,导致了覆盖率的提升不够明显。此外,本文使用了平均探索一条新的路径所需要的执行时间来作为能量分配的基线,通过执行时间作为成本,考虑到了有状态的协议模糊测试中种子执行时间不尽相同的问题。总的来说,SCFuzzer在有状态的协议模糊测试中对比先前两种算法,考虑到了更多的影响因子,通过动态的种子调度算法和合理的收益计算以及可以接受的额外开销,发现更多的漏洞,对于覆盖率的提升有限。
4 相关工作
有状态的协议模糊测试由AFL-NET首次提出,其在AFL的基础上考虑了状态的因素,并将其被测程序改为网络应用程序。AFL-NET可以支持多种协议,继承了AFL等基于覆盖的灰盒模糊测试的特点。AFL-NET对状态的定义是基于报文的响应码,根据不同协议的不同响应码人为定义状态,然而这种方式并不能真正地表示服务器的状态。因此,文献[12]提出了StateFuzz,StateFuzz利用一般服务器会利用一些枚举变量表示服务器状态的特性,通过追踪这些枚举变量的改变来确定当前服务器的状态。NSFuzz[13]与其类似,通过服务器中的状态变量定义服务的状态,并且检测服务器是否完成一个收发循环,完成一个收发循环之后则立马进行下一次测试,提高了效率。Natella[14]更进一步提出了StateAFL,StateAFL会自动推断服务器的状态,StateAFL通过追踪被测服务程序内存中的长生存周期的变量来自动推断服务器的状态。SNPSFuzzer[15]通过快照机制,保存服务器的各种状态,下次需要模糊该状态时只需要通过快照恢复该服务器的状态,减少了需要发送前序报文的操作,加快了模糊测试的执行速度。Snapfuzz[16]考虑了将缓慢的Socket异步网络通信转换为基于UNIX域套接字的快速同步通信。PAVFuzz[17]提出在不同状态下应该进行针对性突变,此想法来源于传统的模糊器对每个数据元素或字节/比特都一视同仁,在每次模糊迭代中具有相同的变异概率。但是,考虑到不同协议状态之间的复杂关系,协议状态会受到之前发送数据包的影响,因此状态中受影响的数据元素应给予较高的变异机会。
5 结束语
针对当前有状态的协议模糊测试调度和能量分配的问题,本文提出了一种基于种子距离的种子调度算法。本文优化了种子距离的计算算法,并且将种子距离近似为种子的潜在收益,将种子探索的新路径近似为实际收益,将种子执行时间近似为成本,通过这些输入进行种子的调度,并使用平均探索一条新路径的执行时间作为基线来动态分配能量。本文方案在同等的实验环境下,对比其他的方案覆盖率和漏洞发现数量都有提升,说明了其效果。
参考文献:
[1]徐威, 李鹏, 张文镔, 等. 网络协议模糊测试综述[J]. 计算机应用研究, 2023, 40(8): 2241-2249. (Xu Wei, Li Peng, Zhang Wenbin, et al. Survey of network protocol fuzzing[J]. Application Research of Computers, 2023, 40(8): 2241-2249.)
[2]杨克, 贺也平, 马恒太, 等. 有效覆盖引导的定向灰盒模糊测试[J]. 软件学报, 2021, 33(11): 3967-3982. (Yang Ke, He Yeping, Ma Hengtai, et al. Effective cover-guided directional gray-box fuzzing[J]. Journal of Software, 2021, 33(11): 3967-3982.)
[3]卢昊良, 邹燕燕, 彭跃, 等. 基于物联网设备局部仿真的反馈式模糊测试技术[J]. 信息安全学报, 2023, 8(1): 78-92. (Lu Hao-liang, Zou Yanyan, Peng Yue, et al. Feedback-driven fuzzing tech-nology based on partial simulation of IoT devices[J]. Journal of Cyber Security, 2023, 8(1): 78-92.)
[4]张冠宇, 尚文利, 张博文, 等. 一种结合遗传算法的工控协议模糊测试方法[J]. 计算机应用研究, 2021,38(3): 680-684. (Zhang Guanyu, Shang Wenli, Zhang Bowen, et al. Fuzzy test method for industrial control protocol combining genetic algorithm[J]. Application Research of Computers, 2021, 38(3): 680-684.)
[5]Pham V T, Bhme M, Roychoudhury A. AFLNET: a greybox fuzzer for network protocols[C]//Proc of the 13th IEEE International Conference on Software Testing, Validation and Verification. Piscataway, NJ: IEEE Press, 2020: 460-465.
[6]Yue Tai, Wang Pengfei, Tang Yong, et al. EcoFuzz: adaptive energy-saving greybox fuzzing as a variant of the adversarial multi-armed bandit[C]//Proc of the 29th USENIX Conference on Security Symposium.[S.l.]: USENIX Association,2020: 2307-2324.
[7]Bhme M, Pham V T, Roychoudhury A. Coverage-based greybox fuzzing as Markov chain[C]//Proc of ACM SIGSAC Conference on Computer and Communications Security. New York :ACM Press, 2016: 1032-1043.
[8]Qian Ruixiang, Zhang Quanjun, Fang Chunrong, et al. DiPri: distance-based seed prioritization for greybox fuzzing(registered report)[C]//Proc of the 2nd International Fuzzing Workshop. New York: ACM Press, 2023: 21-30.
[9]Zhang Kunpeng, Xiao Xi, Zhu Xiaogang, et al. Path transitions tell more: optimizing fuzzing schedules via runtime program states[C]//Proc of the 44th International Conference on Software Engineering. Piscataway, NJ: IEEE Press, 2022: 1658-1668.
[10]She Dongdong, Shah A, Jana S. Effective seed scheduling for fuzzing with graph centrality analysis[C]//Proc of IEEE Symposium on Security and Privacy. Piscataway, NJ: IEEE Press, 2022: 2194-2211.
[11]Huang Heqing, Chiu H C, Shi Qingkai, et al. Balance seed scheduling via Monte Carlo planning[J]. IEEE Trans on Dependable and Secure Computing, 2024, 21(3): 1469-1483.
[12]Zhao Bodong, Li Zheming, Qin Shisong, et al. StateFuzz: system call-based state-aware Linux driver fuzzing[C]//Proc of the 31st USENIX Security Symposium. 2022: 3273-3289.
[13]Qin Shisong, Hu Fan, Ma Zheyu, et al. NSFuzz: towards efficient and state-aware network service fuzzing[J]. ACM Trans on Software Engineering and Methodology, 2023,32(6):1-26.
[14]Natella R. StateAFL: greybox fuzzing for stateful network servers[J]. Empirical Software Engineering, 2022, 27(7): 191.
[15]Li Junqiang, Li Senyi, Sun Gang, et al. SNPSFuzzer: a fast greybox fuzzer for stateful network protocols using snapshots[J]. IEEE Trans on Information Forensics and Security, 2022, 17: 2673-2687.
[16]Andronidis A, Cadar C. SnapFuzz: high-throughput fuzzing of network applications[C]//Proc of the 31st ACM SIGSOFT International Symposium on Software Testing and Analysis. New York: ACM Press, 2022: 340-351.
[17]Zuo Feilong, Luo Zhengxiong, Yu Junze, et al. PAVFuzz: state-sensitive fuzz testing of protocols in autonomous vehicles[C]//Proc of the 58th ACM/IEEE Design Automation Conference. Piscataway, NJ: IEEE Press, 2021: 823-828.
