基于字段感知的文本协议灰盒模糊测试方法
2024-10-14孙语韬徐向华




摘 要:基于变异的灰盒协议模糊测试方法使用便捷、可扩展性好,但缺乏协议报文格式信息,只能对报文整体进行变异以产生测试用例,导致生成的大部分测试报文会被被测协议实现直接拒绝,严重影响测试效率。针对这一问题,提出了基于字段感知的文本协议模糊测试方法。该方法在基于变异的协议模糊测试中加入了模板学习的概念,使用分隔符划分报文字段,使用字段字典获取每个字段的合法取值;然后,针对划分后的报文,设计了多种字段级的变异策略,并根据每个字段可能的取值数量和覆盖率反馈计算相应的字段变异能量;此外,还利用对报文进行字段划分的结果,对被测协议实现的状态进行更细粒度的刻画。实验结果表明,该方法可以提高经典的基于变异的协议模糊测试框架AFLNET产生的可被被测协议实现接受的测试用例的比例,进而将测试效率提高到5倍以上。这表明基于变异的协议模糊测试方法普遍存在的可被接受的测试用例比例过低的问题确实会影响最终的测试效率,改善测试用例的被接受率可以大幅提高测试效率。
关键词:网络安全; 协议测试; 模糊测试; 字段感知; 字段变异能量度量; 细粒度状态刻画
中图分类号:TP311 文献标志码:A
文章编号:1001-3695(2024)10-032-3110-09
doi:10.19734/j.issn.1001-3695.2024.01.0035
Greybox fuzzing method for text protocol based on field perception
Sun Yutao, Xu Xianghua
(School of Computer Science, Hangzhou Dianzi University, Hangzhou 310018, China)
Abstract:The mutation-based grey-box protocol fuzzing methods are convenient and highly scalable. However, they lack the message format information of the protocol under test, resulting in most of the messages in test cases being rejected by the target protocol implementation, severely affecting the testing efficiency. To address this issue, this paper proposed a greybox fuzzing method for text protocol based on field perception. This method incorporated the concept of template learning into mutation-based protocol fuzzing. It used delimiters to segment message fields and utilized a field dictionary to obtain valid values for each field. Subsequently, this paper designed multiple field-level mutation strategies for the segmented messages and calculated the corresponding field mutation energy based on the number of valid values and coverage feedback. Moreover, this approach leveraged the results of message field segmentation to provide a more fine-grained characterization of the protocol implementation state. Experimental results demonstrate that this method can improve the proportion of test cases accepted by the target protocol implementation generated by the classic mutation-based protocol fuzzing framework AFLNET, thereby increasing testing efficiency over five times. It proves that the low acceptance rate of test cases in the commonly used mutation-based protocol fuzzing methods decrease the overall testing efficiency, and increasing the test case acceptance rate can improve the testing efficiency significantly.
Key words:network security; protocol testing; fuzzing; field perception; field’s mutation energy measurement; fine-grained state characterization
0 引言
协议模糊测试继承了软件模糊测试高效、易用的特点,并针对有状态协议添加了状态选择机制[1,2],是目前流行的网络协议测试技术之一[3],在网络安全问题日益突出的今天[4~7]显得尤为重要。根据生成测试用例的方式这一关键问题,可以将协议模糊测试大体分为基于生成的协议模糊测试和基于变异的协议模糊测试两类。其中,基于生成的协议模糊测试[8,9]需要人工编写协议报文模板和状态机,以生成符合协议规范的测试用例。然而,编写协议报文模板和状态机的工作量巨大,且很难保证人工编写的结果完全准确[10],导致此类模糊测试方法实际使用并不方便。而基于变异的协议模糊测试[11~17]使用被测协议实现的真实流量或人工构造的部分报文作为初始种子,通过对其进行变异生成测试用例,不需要人工编写协议报文模板和状态机,是协议模糊测试最新的研究热点。
AFLNET[11]是首个基于变异的协议模糊测试框架[18],也是当前各个基于变异的协议模糊器的基础。它使用被测协议实现的真实流量作为初始种子,并通过对种子的变异产生测试用例。同时,它将服务器每次返回的响应码作为此时的协议实现状态,在测试过程中动态构建被测协议实现的状态机。在此基础上,文献[13,16]使用快照保存被测协议实现的各个状态,避免重复发送前缀报文序列的开销,以提高协议测试的吞吐量。针对使用响应码表示协议实现状态可能导致状态机构建不准确的问题,文献[14,15]提出了使用协议实现中的特定长期变量的哈希值来更为准确地刻画协议状态的方法,以此改进基于变异的协议模糊的测试性能。
然而,基于变异的协议模糊测试方法缺少被测协议的报文格式信息,只能识别报文的结束位置。对于每个报文,此类模糊测试方法则只会将其视为一个完整的字节流。在产生测试用例时,此类模糊测试工具采用类似于软件模糊测试中的变异方法,将变异算子直接作用于整个报文。这样得到的测试用例有很大概率与种子中的原始报文差异巨大,不符合被测协议实现的基本要求,导致该测试用例无法通过被测协议实现的报文解析,被直接丢弃。此类测试用例的比例过高,显然会影响协议模糊测试的整体效率。
针对基于变异的协议模糊测试产生的测试用例中能被被测协议实现接受的比例过低的问题,本文将基于生成的协议模糊测试中的部分思想引入到基于变异的协议模糊测试中,提出了一种基于字段感知的文本协议灰盒模糊测试方法。为了提高产生的测试用例符合被测协议实现的基本要求的概率,该方法使用分隔符对种子中的每个报文进行字段划分,并为划分得到的每个字段分别建立一个字段字典,用于记录该字段出现过的合法取值及每个取值在种子中出现的次数。然后,为每个字段分别计算字段变异能量,减少对不适合进行随机变异的字段进行随机变异的次数。在上述改进的基础上,为了缓解基于变异的协议模糊测试的典型工作AFLNET所存在的状态划分粒度过粗的问题,利用字段划分的结果对协议状态进行细粒度的刻画,为模糊测试提供更准确的引导。
本文的主要贡献如下:
a)提出了基于字段感知的文本协议模糊测试方法。使用字段感知方法,学习协议模板,提高测试用例接受率。在此基础上,使用字段级变异策略、字段能量度量方法和基于请求消息类型的状态刻画方法,提高测试效率。
b)实现了一个基于字段感知的文本协议模糊测试方法的原型模糊器FPFuzzer(field perception fuzzer),并评估其效果。实验表明,FPFuzzer产生的测试用例的接受率可以达到AFLNET的3~9倍,实现5~10倍的测试加速,提升3%的分支覆盖。
1 研究动机
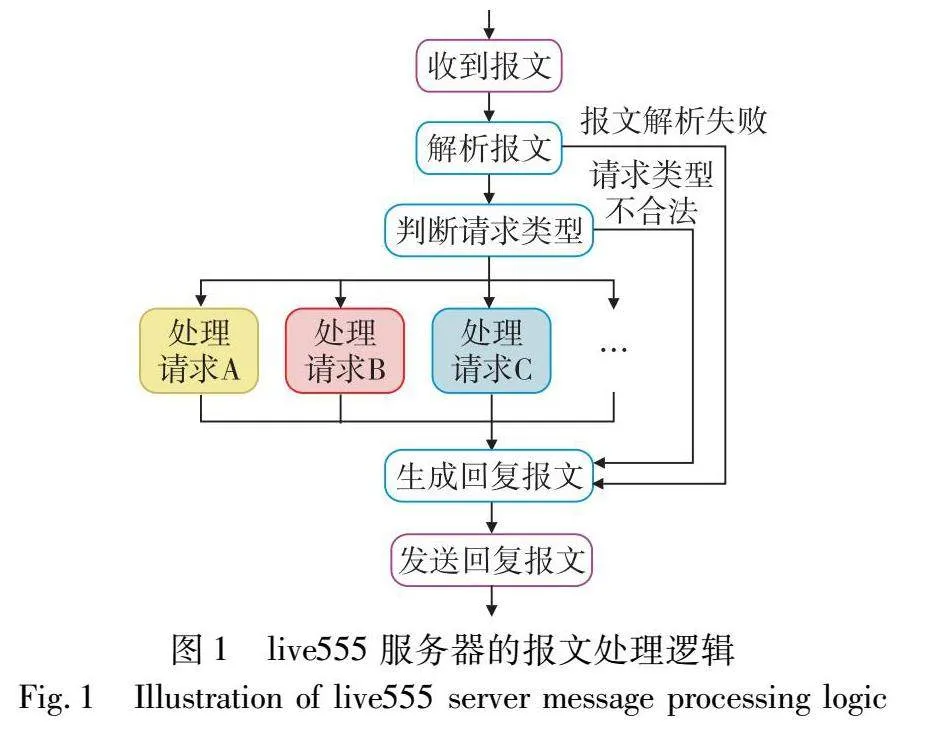
与一般的软件不同,网络协议实现通常对收到的报文具有较高的格式要求,对于不能满足基本格式要求的报文,通常不会进行实际的处理,而是返回错误信息。例如,RTSP(real time streaming protocol)协议的一个著名开源实现live555,其处理客户端发送来的请求报文的逻辑如图1所示。
收到报文后,live555服务器首先会对收到的报文进行解析,提取其中包含的各个字段。在解析报文的过程中,如果发现该报文的格式错误,例如缺少必要的字段,则会跳过之后的处理步骤,直接返回包含错误类型代码的回复报文。否则,根据请求类型字段(FTP协议中为第一个字段)的值,进入对应的处理逻辑,对报文进行实际处理。如果请求类型字段的值不是live555服务器支持的类型,则同样会跳过处理阶段,直接返回包含错误类型代码的回复报文。只有当报文格式符合RTSP协议的基本要求且请求类型字段的值合法时,才能进入live555服务器的实际处理逻辑,完成请求报文所要求的操作。
大部分协议的实现都会在收到客户端发来的请求报文后进行类似的检查。不符合协议要求的报文通常是无法进入协议实现中各类请求报文的处理逻辑的,它们在报文解析阶段或请求类型判别阶段就会被拒绝。由此可知,协议模糊器产生的不符合协议基本要求的报文主要用于测试协议实现通过报文解析的边界条件,挖掘其中可能存在的解析错误问题。而对协议实现的请求处理逻辑进行测试,则需要能够通过协议实现基本检查的大体上正确的报文。
这两类测试用例都有助于对协议实现进行全面的测试,保持这两类测试用例的比例处于合理区间才能得到最好的测试效果。然而,基于变异的模糊测试方法完全没有考虑报文格式的问题,而是将整个报文作为字节流进行变异,无疑会导致产生的测试用例大部分都不符合被测协议的基本要求。且随着测试时间的推移,越来越多完全不符合协议规范的测试用例被保存为新种子,以这些本身就不符合被测协议基本要求的种子为基础产生的测试用例能够进入被测协议实现实际报文处理逻辑的可能性愈发渺茫。这就导致了基于变异的协议模糊测试对被测协议实现实际处理逻辑的测试效率低下。
为了验证上述问题在实际测试中的严重程度,本文使用基于变异的协议模糊测试的一个典型模糊器AFLNET对live555服务器进行测试,收集其中可以通过live555自身的检测进入实际处理逻辑的测试用例的占比。具体地,本文在使用Ubuntu 18.04系统、配备24个Intel Xeon E5-2620 v3内核和256 GB 内存的服务器上对live555进行为期1 h的模糊测试。在测试中,每隔1 min采样一次,记录截止到目前为止产生的所有测试用例中被服务器接受的比例。为了提高测试结果的可信程度,本文重复进行该实验3次。测试结果如图2所示。
可以看到,AFLNET对报文进行整体变异产生的测试用例确实大部分完全不符合协议的基本要求,且随着测试时间的推移,产生可以被被测协议实现接受的测试用例的概率持续下降。实际上,对于RTSP协议这种具有较多字段的报文而言,测试用例接受率的下降速度是非常惊人的。开始测试10 min后,测试用例的平均接受率就已经低于10%;此后,测试用例接受率进一步下降,在开始测试1 h后,平均测试用例接受率跌破5%。
换言之,AFLNET产生的测试用例只有不到5%的比例可以进入live555实际的报文处理逻辑中,这样的比例明显过低,显然会降低基于变异的协议模糊测试的效率。在某种意义上来说,适当提高基于变异的协议模糊测试产生的测试用例符合协议基本要求的比例,在功效上相当于加快了协议模糊测试处理测试用例的速度。
综上所述,现有基于变异的协议模糊测试生成的测试用例中能被被测协议实现接受的比例过低,严重影响了测试效率。因此,为基于变异的协议模糊测试提出一种能够提高测试用例被接受率的方法,是提高测试效率的必然需求。
2 解决方案
基于变异的协议模糊测试都存在测试用例被被测协议实现直接拒绝的比例过高的问题,这是由于此类协议模糊测试方法变异粒度(整个报文)过粗导致的固有问题。而基于生成的协议模糊测试使用人工输入的报文模板指导测试用例的生成,可以知道每个报文包含哪些字段、每个字段的类型及每个字段的默认取值等关键信息,生成的测试用例被拒绝的概率远低于基于变异的协议模糊测试。但基于生成的协议模糊测试对测试人员提出了很高的要求,需要测试人员给出被测协议的所有报文模板和完整的状态机,实际使用困难较大。
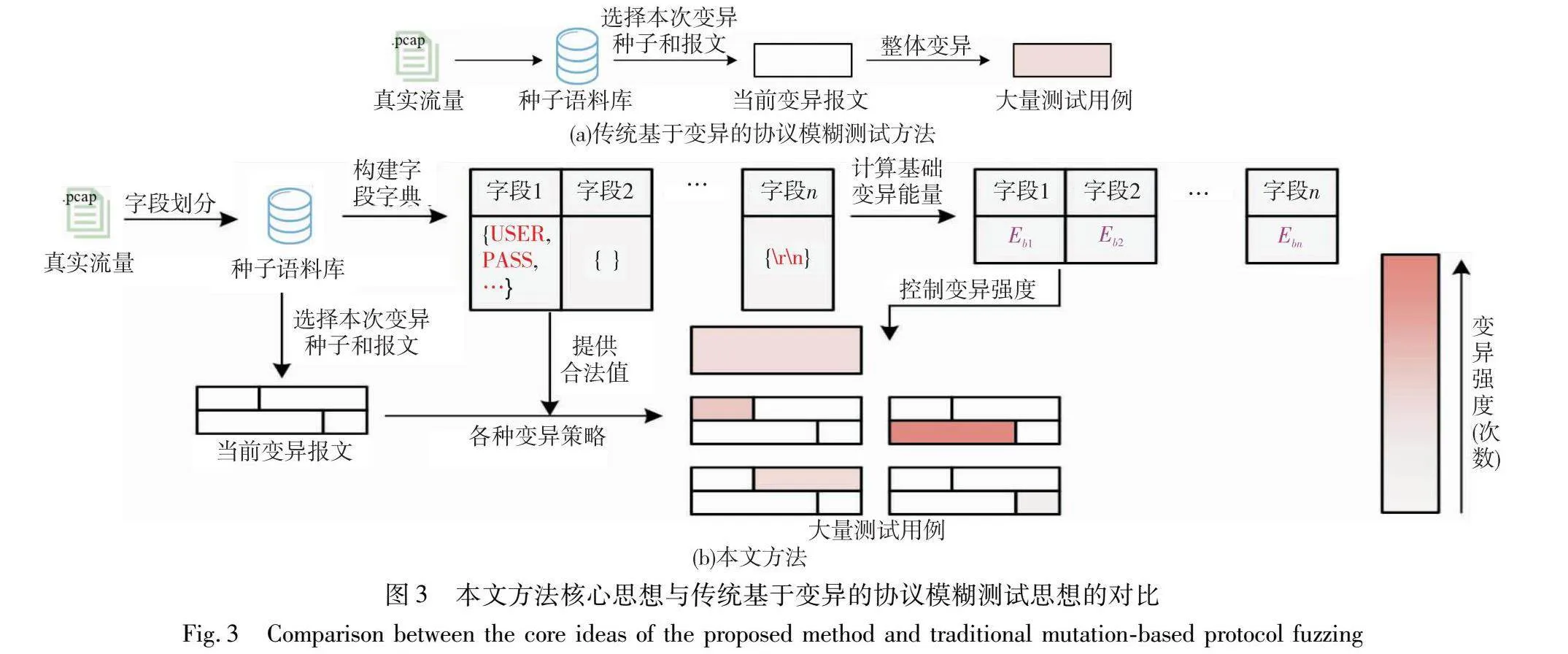
为此,本文在基于变异的模糊测试中引入模板学习的概念,提出一种基于变异加生成的全新协议模糊测试方法。在保留基于变异的协议模糊测试易于使用的优点的同时,自动学习协议报文模板,并使用模板指导测试用例的生成和状态机的构建,提高测试用例被被测协议实现接受的比例,从而提高测试效率。该方法的核心在于对报文进行有针对性的变异,其与传统基于变异的协议模糊测试方法的核心区别如图3所示。
从整体上看,本文通过模板学习获取报文的字段信息和每个字段的合法取值,以此减小生成测试用例时的变异粒度;通过字段变异能量度量每个字段是否适合进行字段级的变异,将更多测试时间用于更适合变异的字段。此外,本文还通过基于请求消息类型的状态刻画方法,利用已经学习到的模板信息对被测协议状态进行更细粒度的刻画,提高状态机的准确性。
2.1 报文模板学习方法
如前所述,为了提高生成的测试用例符合被测协议基本要求的概率,本文在传统的基于变异的协议模糊测试中引入了模板学习的概念。协议通常会对报文包含的字段数量及关键字段的取值进行检查,一旦发现当前报文不符合协议的要求,就会将其拒绝。为了提高测试用例被被测协议实现接受的概率,就必须同时考虑这两个方面。因此,模板学习方法同样需要包含报文字段划分和字段合法取值学习两个方面。
2.1.1 字段划分
为了获取报文包含的字段信息,本文提出了基于分隔符的字段划分方法。
文本协议与二进制协议不同,单个报文包含的字段数量和每个字段的长度通常都是不固定的,各个字段之间直接使用分隔符进行区分。因此,本文直接利用文本协议的这一特点,在将种子加入队列前,根据分隔符,将其中的每个报文划分为字段列表。其中,分隔符单独作为一个字段。这种方式可以获取被测协议报文的大致报文结构,虽然可能出现将部分字段内部的符号误认为分隔符,导致该字段被截断的问题,但实际对生成有效测试用例的影响较小。
对于种子中的每个报文进行划分的方法可以用算法1描述。依次读入当前种子的每个报文(第2行),每当读入一个报文,即对该报文进行划分。完成读入过程,则完成了整个种子所有报文的划分,最终信息存放在一个结构体中(第28行)。对于当前要划分的报文,则:首先记录当前报文的长度(第4和5行)。然后初始化当前检查的字节位置(第7行)和截止到目前为止划分出的最后一个字段的结束字节位置(第8行)。然后,依次读入当前报文的每个字节(第10行),如果当前读入的字节不是分隔符,则继续读入下一个字节(第24行);否则,如果当前字节前不存在没有被分配到字段的字节,则将当前字节作为一个字段添加到种子结构体中(第14~16行),否则,将当前字节之前所有未被分配的字节作为一个字段、当前字节作为另一个字段,依次添加到种子结构体中(第18~20行)。
算法1 基于分隔符的字段划分算法
输入:AFLNET为当前种子构建的结构体q;当前被测协议使用的分隔符的集合D。
输出:添加了字段信息的当前种子的结构体q。
1 //依次读入当前种子的每个报文
2 for r in q->regions do
3 //将实际报文读入为字符串,并记录报文长度
4 r_text=readFile(q->fname,r->start_byte,r->end_byte)
5 r_length =r->end_byte -r->start_byte
6 //初始化报文划分的位置
7 last_byte=-1
8 now_byte=0
9 //依次读取当前报文的每个字节
10 while last_byte <r_length do
11 //找到属于分隔符的字节
12 if r_text[now_byte] in D then
13 /*判断当前需要添加的是一个字段还是两个字段,并将字段添加到当前种子对应报文的结构体中*/
14 if last_byte =now_byte-1 then
15 r->fields.add(r_text,now_byte, 1, is_delimiter)
16 r->field_count += 1
17 else
18 r->fields.add(r_text,last_byte+1,now_byte–last_byte-1)
19 r->fields.add(r_text,now_byte, 1, is_delimiter)
20 r->field_count +=2
21 end if
22 last_byte =now_byte
23 end if
24 now_byte++
25 end while
26end for
27//返回更新了字段信息的结构体
28return q
2.1.2 字段字典学习
为了学习报文每个字段的合法取值,本文提出了字段字典值学习方法。如前文所述,文本协议单个报文包含的字段数量通常不是固定的。因此,需要首先确定设置字段字典的数量。通常情况下,文本协议的一个报文可以包含固定字段、选项和数据这三类字段,其中固定字段的位置和个数一般都是确定的,且通常位于报文的开头,而选项和数据部分通常位于固定字段之后,且可以包含也可以不包含,可以包含一个也可以包含多个,是不能确定的。同时,报文的固定字段更有可能取值受限,而后续的选项和数据部分则没有太大的限制。因此,关键是为每个固定字段分别建立字段字典,而对于其余的选项或数据字段,可以使用一个统一的字典。
基于这一思想,本文将初始种子中单一报文包含的最少字段数定义为必要字段数,将所有报文的前必要字段数个字段定义为必要字段,而将其余字段定义为非必要字段。前述的固定字段大概率被分为了必要字段。因此,本文为每个必要字段单独构建一个字段字典,而对于所有非必要字段,则使用一个统一的字段字典。
在测试准备阶段读入所有初始种子后,开始构建初始的字段字典,具体的构建方法如算法2所示。首先,创建必要字段数量加1个字段字典,共同组成字段字典列表,其中每个字段字典初始均为空(第2行)。然后,遍历初始种子队列中每个种子中的每个报文(第4~6行),每遍历一个报文,则遍历其中的每个字段(第8行)。如果当前字段的值已经存在于对应的字段字典中,则将该取值的计数加1(第10、11行);否则,将该取值添加到对应的字段字典中并设置计数为1(第12~14行)。遍历完所有种子后,即完成全部字段字典的构建。
算法2 字段字典构建算法
输入:初始种子队列queue;必要字段数min_fields。
输出:每个字段对应的字段字典组成的列表d_list。
1 //创建空的字段字典列表
2 d_list=createDicts(min_fields+1)
3 //遍历种子队列中的每个种子
4 for q in queue do
5 //遍历当前种子包含的每个报文
6 for r in q->regions do
7 //遍历当前报文的所有字段
8 for index in len(r->field_count) do
9 /*添加到对应的字段字典中,如果已经存在当前取值,则计数加1,否则,设置计数为1*/
10 if r->fields[index] in d_list[index] then
11 d_list[index][r->fields[index]] +=1
12 else
13 d_list[index].add (r->fields[index])
14 d_list[index][r->fields[index]]=1
15 end if
16 end for
17 end for
18end for
19return d_list
在模糊测试阶段会对字段字典进行动态更新。当发现新的种子时,使用产生当前种子所变异报文的每个字段值更新字段字典。更新过程如算法2的第7~16行。
2.2 变异策略及变异能量度量
如前所述,本文方法的核心在于学习报文模板,并根据学习到的报文模板进行细粒度的变异,以提高产生有效测试用例的概率。因此,本文在保留基于变异的协议模糊测试原始的变异策略外,还引入了字段级的变异策略。
同时,不同的字段进行随机变异的价值不同。例如,对于取值受限的关键字段进行随机变异,产生的绝大部分测试用例都将完全不符合被测协议的基本要求,价值较低。因此,在对报文进行变异时,需要计算其中每个字段的变异能量,确定对每个字段进行随机变异的次数,将更多测试时间用于变异潜在价值更大的字段。
2.2.1 变异策略
本文引入的字段级变异策略可以分为确定性字段变异和非确定性字段变异两大类。其中,确定性变异策略作用的结果是可以预测的,对任意一个种子使用此类策略能够产生的测试用例的数量都是确定的。因此,每个种子仅在第一次变异时使用确定性变异策略。而非确定性变异策略产生的测试用例难以预测,每次应用都能产生不同的测试用例,因此每次对种子进行变异时都会使用。但正因为如此,非确定性变异没有明确的变异次数限制,对一个种子进行多少非确定性变异需要模糊器指定。此外,由于使用非确定性变异策略的结果难以预料,为了减少对报文格式的破坏,本文仅对非分隔符字段使用非确定性变异。
具体地,本文使用的字段变异策略如下:
1)确定性变异策略
对于分隔符字段依次使用两种策略。a)字段字典替换:依次将当前字段替换为对应的字段字典中的各个值;b)特殊字符替换:依次将当前字段替换为预先定义好的一系列特殊字符值。对于非分隔符字段则依次使用以下两种策略。a)一位翻转:依次翻转当前字段值的每一位;b)字典值替换/插入。依次将当前字段替换为各个字典值(包括人工提供的字典和自动构建的字段字典),再依次在当前字段前/后插入这些字典值。
2)非确定性变异策略
对于非分隔符字段依次使用以下三种策略,每种策略生成的测试用例数由字段变异能量决定。a)超长特殊字符:随机使用预先定义好的容易导致崩溃的特殊字符的大量重复(长c0e2b2fafd85271a622777a41318a692aac38a5f164833ce839d730cb468d665度随机)来替换当前字段;b)字段重复:从当前报文中随机复制一个字段,并随机拼接到当前字段的前面或后面;c)字段级大破坏:类似于Havoc策略[19],根据字段长度随机一个变异次数,对当前字段进行这一次数的累积变异。其中,每次变异的方法包括:(a)一位翻转;(b)随机设置其中一个字节的值;(c)随机删除一些连续字节(长度随机);(d)随机插入一些连续字节(长度随机);(e)随机替换一些连续字节。
2.2.2 变异能量度量
如前所述,对不同字段进行非确定性变异的价值是不同的。为了提高测试效率,将更多测试时间用于潜在价值更大的字段,需要为每个实际进行非确定性变异的字段计算一个字段变异能量,以确定每个字段进行非确定性变异的次数(其中,超长特殊字符策略和字段重复策略分别分到1/5的字段变异能量,字段级大破坏策略分到3/5的字段变异能量)。
在实际测试中,本文观察到,特定种子的特定字段的潜在变异价值主要受两个方面的因素影响:a)该字段本身是否适合随机变异;b)当前种子及种子中该字段的取值是否有趣。首先,如前所述,协议实现对不同字段的约束强度是不同的,这就导致了对不同字段随机变异的价值不同。例如,有的字段可能只有少数几个合法的取值,对这样的字段进行随机变异的价值显然比较低。而有些字段能够影响协议实现的处理逻辑,但本身的取值可以在一个范围内变化。对这样的字段进行随机变异,显然更有可能触发被测协议多种处理逻辑,对全面测试被测协议有很大帮助。其次,实际每个种子本身的价值也有所不同,这会影响到对其中每个字段进行变异的价值。更关键的是,当前种子中各个字段的实际取值会影响保留该字段不进行变异的价值。例如,某个字段有两种合法的取值,其中该字段取值为a的种子有99个,而取值为b的种子仅1个。此时,对该字段取值为b的种子进行测试时,就不应该对该字段进行过多的变异。
根据上述思想,本文将字段变异能量分为字段基础变异能量和字段实际变异能量。其中,字段基础变异能量是全局的,用于刻画字段本身的随机变异价值。而字段实际变异能量是每个报文单独的,使用所属种子的变异价值和该报文中每个字段取值的稀有度对字段基础变异能量进行了修正。
1)字段基础变异能量
在测试准备阶段中,当构建完字段字典后开始计算每个字段的基础变异能量。和构建字段字典时一致,所有非必要字段共用一个基础变异能量,且由于非必要字段的特殊性,计算其基础变异能量的方式与必要字段略有不同。通常情况下,一个字段在所有种子中出现过的合法取值越少,这个字段是取值受限字段的可能性就越大,应该分配更少的字段变异能量。因此,本文根据每个字段的取值多样性计算其基础变异能量,并在模糊测试过程中逐渐更新。
首先,根据每个字段对应的字段字典中包含的合法取值数量及构建该字段字典使用的报文数量计算每个字段在初始种子中的多样性。特别地,对于非必要字段而言,由于所有非必要字段共用一个字段字典,所以在计算其取值多样性时需要考虑该字段字典实际包含的字段数量的最大值。具体计算方法如式(1)所示。
D(x)=values(x)Rtotal x∈[1,fmin]
values(x)Rtotal×(fmax-fmin)x=fmin+1(1)
其中:D(x)表示当前计算的是第x个字段的多样性;values(x)表示第x个字段在初始种子中出现过的取值数量;Rtotal构建当前字段字典时使用的报文总数;fmin表示必要字段数;fmax表示构建字段字典的种子中单个报文包含的最大字段数。
根据笔者以往的测试经验,每个字段的变异次数在几十次时,整体测试效率较好。因此,需要将取值为[0,1]的字段多样性映射到一条取值为[1,100]的光滑曲线上,以此作为字段基础变异能量。考虑到字段多样性的取值接近0或1的概率很低,为了凸显中间取值的字段的差异,本文使用sigmoid函数的变形来实现此映射。具体如式(2)所示。
Eb(x)=φ(D(x)) x∈[1,fmin]
φ(D(x))×(fmax-fmin)x=fmin+1(2)
其中:Eb(x)为计算得到的第x个字段的基础变异能量;fmin表示必要字段数;fmax表示用于构建字段字典的种子中单个报文包含的最大字段数;φ(d)为未经修正的映射函数,具体为
φ(d)=1+99d×(f(d)-f(0))f(1)-f(0)(3)
其中:f(d)是sigmoid函数的变形,如式(4)所示。
f(d)=1001+e-10(d-0.5)(4)
通过上述方式可以在测试准备阶段得到每个字段的基础变异能量,但是在模糊测试过程中,还需要根据实际测试情况,对每个字段的基础变异能量进行更新。具体地,如果对某个字段进行非确定性变异产生了新种子,则可以认为,对该字段进行非确定性变异确实具有潜在价值,应该增大该字段的基础变异能量。此外,一般认为,发现新种子所用的变异次数越少,则该字段的潜在价值越大;同样地,历史上对该字段进行非确定性变异产生的种子越多,则该字段的潜在价值也越大。基于这一思想,在每次发现新种子时,使用式(5)对当前进行非确定性变异的字段进行的基础变异能量更新:
Eb(x)′=Eb(x)+Seedn(x)M(x)(5)
其中:Eb(x)′代表第x个字段更新后的字段基础变异能量;Eb(x)代表第x个字段更新前的字段基础变异能量;Seedn(x)代表对当前字段进行非确定性变异产生的种子的数量;M(x)代表本次测试对当前字段进行非确定性变异的次数。
2)字段实际变异能量
如前所述,在模糊测试阶段中,每次对当前选择的报文进行变异前,都需要根据当前变异的报文所属的种子本身的价值(种子整体的变异能量)和当前报文中每个字段实际取值的稀有程度来修正字段基础变异能量,得到每个字段的实际变异能量。根据之前的分析,对于整体价值大的种子中的所有字段,都应该分配更多的实际变异能量;对于取值稀有的字段,则应该分配更少的实际变异能量。
基于这一思想,首先根据每个字段的当前取值在字段字典中是否出现或记录的出现次数,计算字段取值的稀有度。如果出现过,则稀有度为其出现的次数占所有取值总出现次数的比例,否则,规定为所有取值总出现次数的倒数的十分之一。具体计算方法如式(6)所示。
R(x)=valuetimes(x)Rtotal 字段字典中存在当前取值
0.1Rtotal字段字典中不存在当前取值(6)
其中:R(x)表示第x个字段当前取值的稀有度;valuetimes(x)表示第x个字段的取值在对应的字段字典中的计数(出现次数);Rtotal表示所有构建字段字典时使用的报文总数。
之后,根据当前种子本身的变异能量、每个字段当前的基础变异能量和每个字段当前取值的稀有度,计算每个字段的实际变异能量。同计算字段基础变异能量时相同,对于非必要字段,仍需要使用单个报文最多包含多少非必要字段进行修正。特别的,如前所述,本文不会对分隔符字段使用非确定性变异策略,因此规定分隔符字段的实际变异能量为-1。计算方法为
E(x)=Es×Eb(x)×R(x)100 x∈[1,fmin]
Es×Eb(x)×R(x)100×(fmax-fmin)x=fmin+1
-1第x个字段是分隔符字段(71p2tIxkB8MtR+2vPeYH/dA==)
其中:E(x)表示第x个字段的实际变异能量;Es代表当前种子的整体能量;Eb(x)代表第x个字段的基础变异能量;R(x)表示第x个字段当前取值的稀有度;fmin表示必要字段数;fmax表示构建字段字典的种子中单个报文包含的最大字段数。
2.3 基于请求消息类型的状态刻画方法
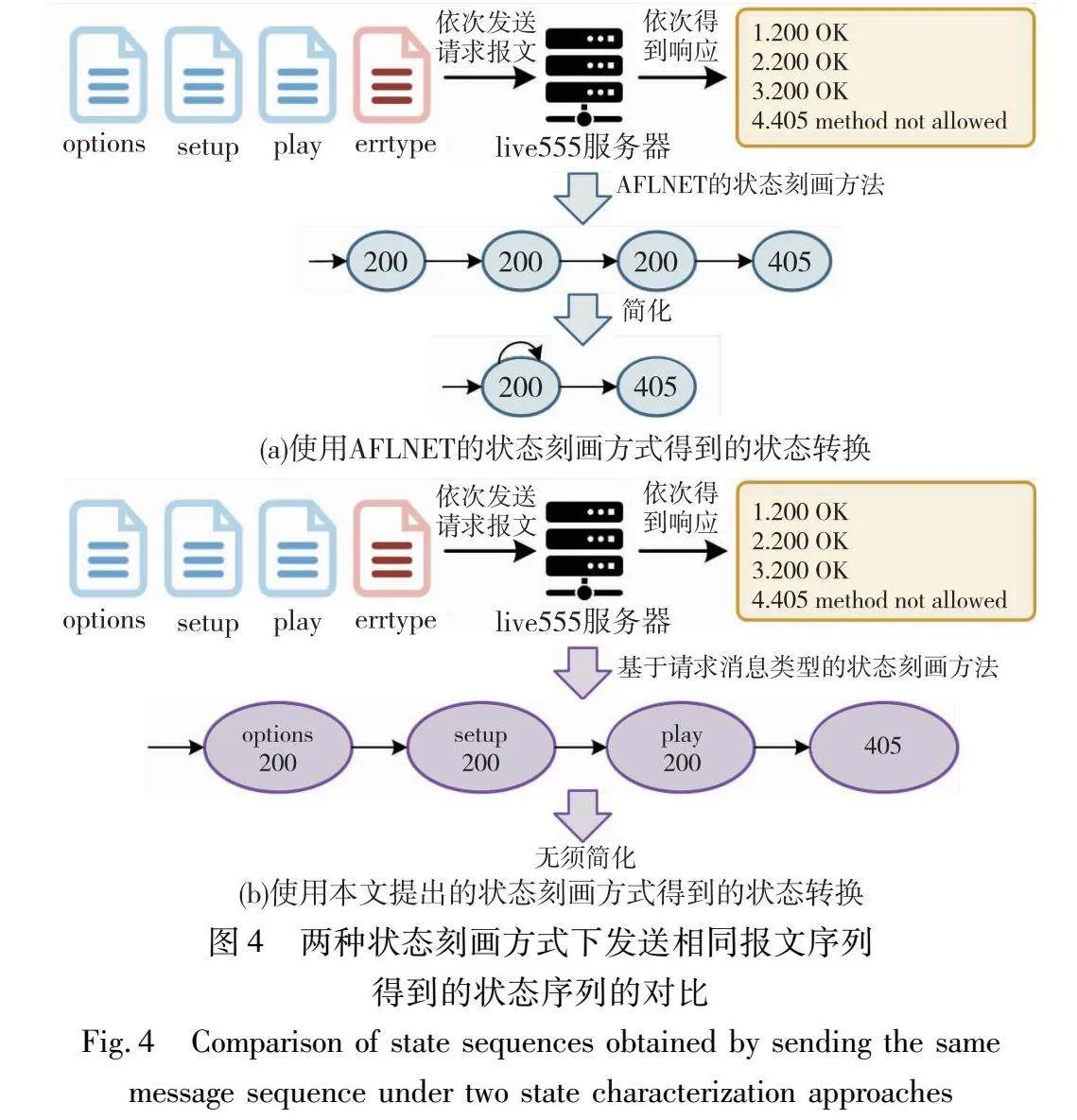
通常情况下,协议实现对不同类型的请求报文具有不同的处理逻辑。因此,在成功处理不同类型的请求报文后,协议实现的实际状态通常也是不同的。然而,一些文本协议只要正确处理收到的请求报文都会返回相同的响应报文,导致以协议实现的响应码刻画协议状态的方法无法区分协议实现正确处理不同类型的请求后的状态,显然会影响测试效果。如图4(a)的例子所示,在以options→setup→play→errtype的顺序向RTSP协议实现live555发送报文后(其中,errtype不是一种真实存在的报文类型,而是代表请求类型字段取值不合法的任意报文),AFLNET无法区分live555服务器在接受options报文、setup报文和play报文后的状态。然而,live555服务器在接受这些报文后,允许接受的报文类型的集合都是不同的,表明这些状态实际并不相同。
因此,本文提出了基于请求消息类型的状态刻画方法,对上述被混淆的状态进行细分,从而更准确地指导测试状态和对应种子的选择。对于表示正确处理了请求报文的响应码对应的状态,该方法使用被测协议实现当前接受并处理的请求报文的类型字段的值进行细分。具体地,将前一个请求报文的类型字段(可以人工指定,默认是报文的第一个字段)的值和响应码拼接成一个字符串,然后对该字符串进行哈希运算,将得到的值作为细分后的状态。对于其他响应码(主要是各种类型的错误代码)代表的状态,则仅对该响应码进行哈希,以此作为被测协议实现的状态。如图4(b)所示,同样以options→setup→play→errtype的顺序向RTSP协议实现live555发送报文后,该方法可以区分live555服务器在接受每个报文后的状态。这表明这种状态刻画方法比AFLNET刻画的状态更为精准,有利于在模糊测试中指导测试状态和本次变异种子的选择。
上述细粒度状态刻画方法可以使用算法3描述。在发送当前测试用例并获得AFLNET给出的响应码序列(状态序列)后,首先创建与原始状态序列等长的空的细粒度状态序列(第2行)。然后,遍历当前测试用例中的每个报文(第4行),如果协议实现处理当前报文后返回表示正确的响应码,则将当前报文的请求类型和响应码拼接,然后将其哈希值作为细粒度状态添加到细粒度状态序列中(第6~8行);否则,直接将响应码的哈希值作为细粒度状态添加到细粒度状态序列中(第9、10行)。遍历完当前测试用例中的所有报文,则细粒度状态序列构建完成。
算法3 基于请求消息类型的状态刻画算法
输入:当前测试用例的报文序列kl_message;原始的状态序列S_sequence;当前协议表示成功接受报文的响应码的集合S_code;当前协议的关键字段编号key。
输出:细分后的状态序列FS_sequence。
1 创建细分后的状态序列(此时所有值为空)
2 FS_sequence=createSequence(len(S_sequence))
3 /*遍历报文序列和对应的原始状态序列(省略两者不对齐(即有的报文没有收到响应)时的处理逻辑)*/
4 for i in len(S_sequence) do
5 /*如果当前状态表示成功接受报文,则进行细分,否则直接使用响应码(为了统一格式,两者都需要散列)*/
6 if S_sequence[i] in S_code then
7 F_state=str(S_sequence[i])+kl_message[i]->fields[key]
8 FS_sequence[i]=hash32(F_state)
9 else
10 FS_sequence[i] = hash32(str(S_sequence[i]))
11 end if
12end for
13return FS_sequence
2.4 整体流程
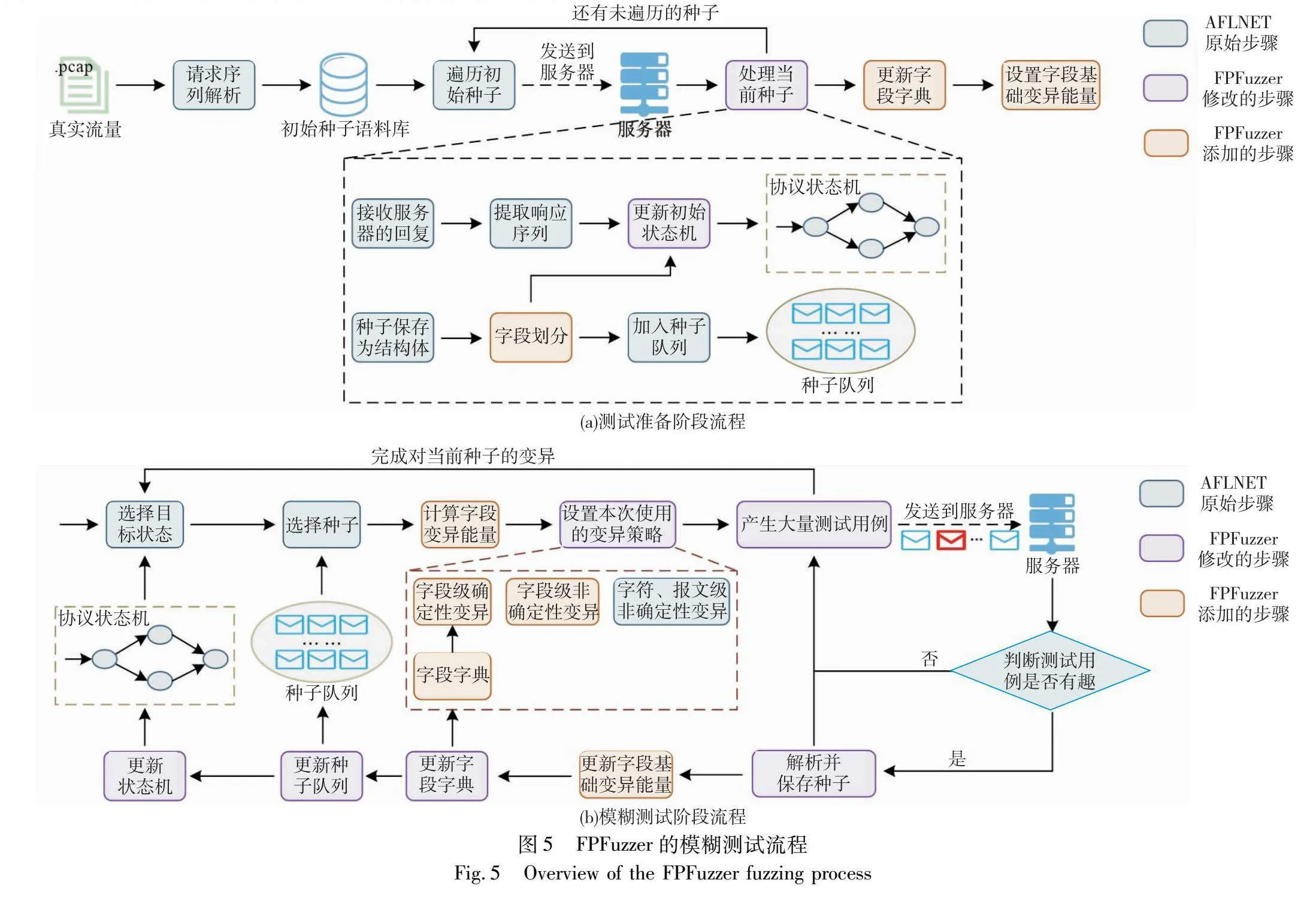
本文对典型的基于变异的协议模糊框架AFLNET的测试流程进行修改,得到基于字段感知的文本协议灰盒模糊测试方法,其测试流程如图5所示。
可以看到,FPFuzzer的整个测试流程可以分为测试准备阶段和模糊测试阶段。其中,测试准备阶段逐一读入初始种子并进行相应的处理以构建种子队列。在读入所有种子后,初始化字段字典并设置字段基础变异能量。而模糊测试阶段则是一个无限循环。每次选择一个状态和其对应的一个种子进行变异,产生大量测试用例。在测试过程中,不断保存新种子、更新字段字典和状态机,以供后续测试使用。
具体地,实际进行模糊测试时,FPFuzzer首先进入测试准备阶段。在该阶段中,FPFuzzer首先依次读入初始种子语料库中的每个种子,每读入一个种子,就将其对应的报文序列发送给被测协议实现,获取被测协议实现的回复报文序列。之后,一方面将当前种子转换为结构体,然后解析其中每个报文的字段,将字段信息保存在结构体中,将更新后的结构体加入种子队列中;另一方面,解析得到的回复报文序列,提取每个回复报文的响应码,组成响应码序列,然后使用当前种子每个报文的字段划分结果对响应码序列进行增强,得到细粒度的状态转换并以此更新状态机。在读入所有初始种子后,FPFuzzer根据初始种子中单个报文包含的最少字段数确定必要字段数。然后,FPFuzzer使用种子队列中所有种子已经划分好的字段信息,构建每个字段对应的字段字典。最后,根据字段字典,计算每个字段的初始基础变异能量。
完成上述准备工作后,FPFuzzer正式进入模糊测试阶段。在该阶段中,FPFuzzer每次根据协议状态机选择一个测试状态,然后在该状态对应的种子中选择一个进行变异。之后,FPFuzzer根据当前待变异的报文每个字段的取值及该种子本身的变异能量,为每个字段计算一个实际变异能量。然后,依次使用各种变异策略,生成大量测试用例。每当生成一个测试用例,就将其发送给被测协议实现,获取覆盖率反馈和状态转换序列。如果该测试用例覆盖了新分支,则将其保存为新种子,然后根据本次变异的字段更新字段基础变异能量并使用本次变异的报文尝试更新字段字典,如果出现新的状态转换,则更新状态机。当完成对当前种子所有测试用例的测试后,重新选择下一个测试状态。整个模糊测试过程始终保持上述循环,直到耗尽测试人员给定的所有测试时间。
3 实验评估
为了评估本文方法的有效性,通过在AFLNET中添加5 500多行C代码实现了模糊器原型FPFuzzer。该模糊器原型除第2章提到的策略外,其余部分与AFLNET完全相同。因此,之后的实验以AFLNET为基准,避免其他策略对结果的干扰。
根据FPFuzzer的设计思想,需要验证以下两个问题:
问题1:FPFuzzer是否可以提高测试用例的接受率?
问题2:FPFuzzer是否可以提高模糊测试效率?
1)测试数据集
为了尽可能地保证对比的公平性,本文选用与AFLNET的论文中相同的协议和具体实现作为被测对象,包括RTSP协议和FTP(file transfer protocol)协议两个文本协议。选择的RTSP协议实现为live555,具体测试目标为其中的live555MediaServer。而选择的FTP协议实现为LightFTP,具体测试目标为其中的fftp。
2)实验环境和实验参数
本文在配备24个Intel Xeon E5-2620 v3内核和256 GB内存且系统为Ubuntu 18.04的服务器上进行全部的实验。在测试时,每个模糊器都仅在一个内核上运行,但不限制内存占用量。
为了提高评估结果的可信度,在以下所有实验中,启动模糊测试的参数设置(包括单个测试用例的超时时长、清理脚本、状态选择算法、种子选择算法、是否使用假阴性减少模式等)全部与AFLNET项目文档中给出的建议相同。
3.1 测试用例接受率
本文的出发点在于:基于变异的协议模糊测试产生的测试用例中能被被测协议实现接受的比例过低,严重影响测试效率。因此,为了评估本文方法的有效性,需要首先评估FPFuzzer是否可以提高生成的测试用例能被被测协议实现接受的比例。
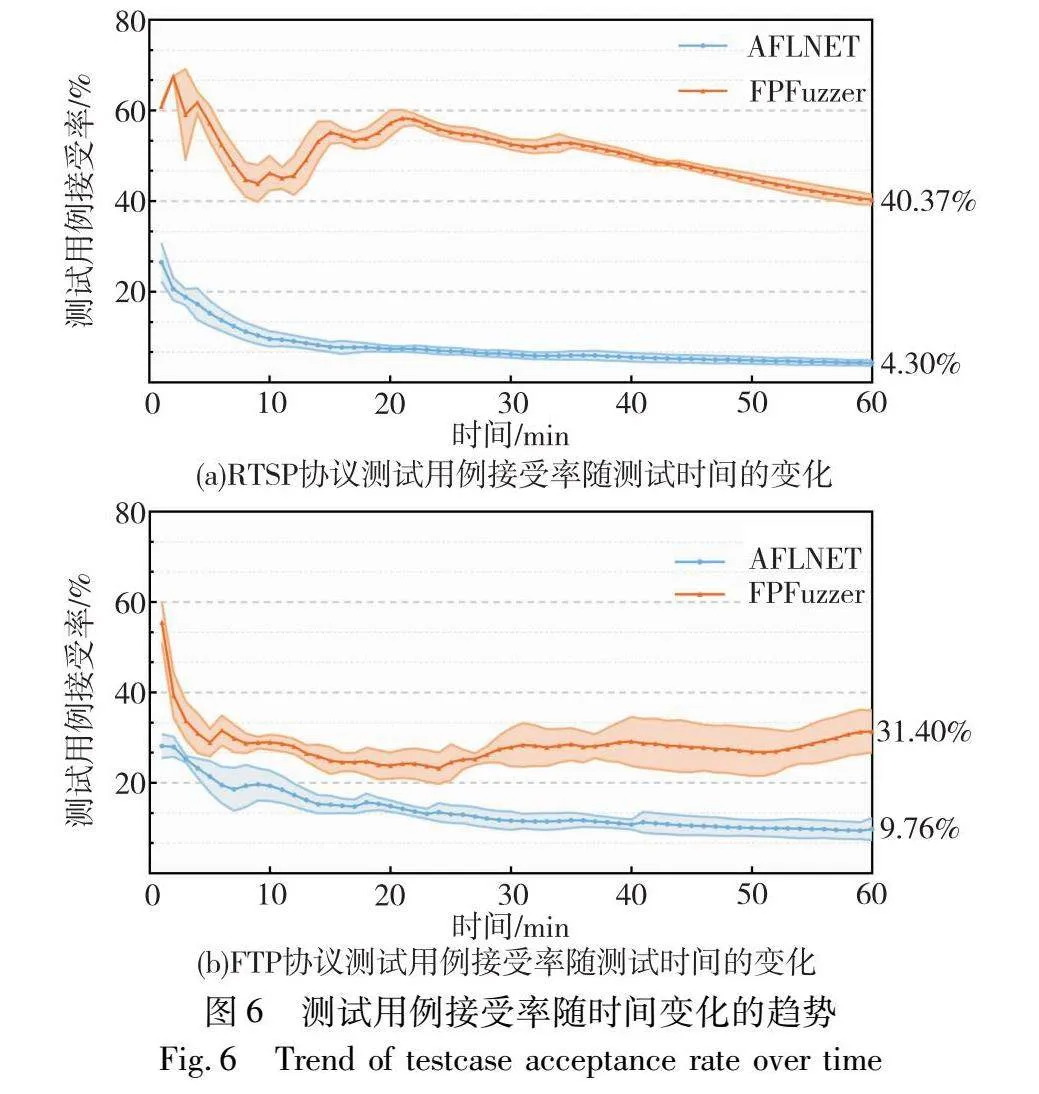
具体地,在每个被测协议实现上进行了3次实验,每次实验测试1 h。在实验中,每隔1 min采样一次,统计截止到当前时刻为止产生的所有测试用例中被被测协议实现接受的比例。最终得到的在模糊测试过程中测试用例被被测协议实现接受的比例随时间的变化趋势,如图6所示。
可以看到,原始的AFLNET产生的测试用例能被接受的比例很低。即使是在报文结构非常简单的FTP协议中,截止到测试1 h为止,产生的测试用例的平均接受率也不足10%。而使用FPFuzzer,在RTSP协议上,可以实现40.37%的测试用例接受率,是AFLNET的9倍以上。在FTP协议中使用FPFuzzer,则可以实现31.40%的测试用例接受率,是AFLNET的3倍以上。这表明,FPFuzzer确实可以显著提高测试用例被被测协议实现接受的比例。
3.2 模糊测试效率
如前所述,基于变异的协议模糊测试生成的测试用例被被测协议实现接受的比例过低,能够对被测协议实现的实际处理逻辑进行测试的测试用例占比太低,最终严重影响整体测试效率。因此,从理论上看,应该可以通过提高测试用例被接受的比例的方式,实现大幅提高测试效率的最终目标。然而,虽然实验已经证明FPFuzzer可以大幅提高测试用例被接受的比例,但实际是否可以实现大幅提高测试效率的预期目标仍有待实验证明。
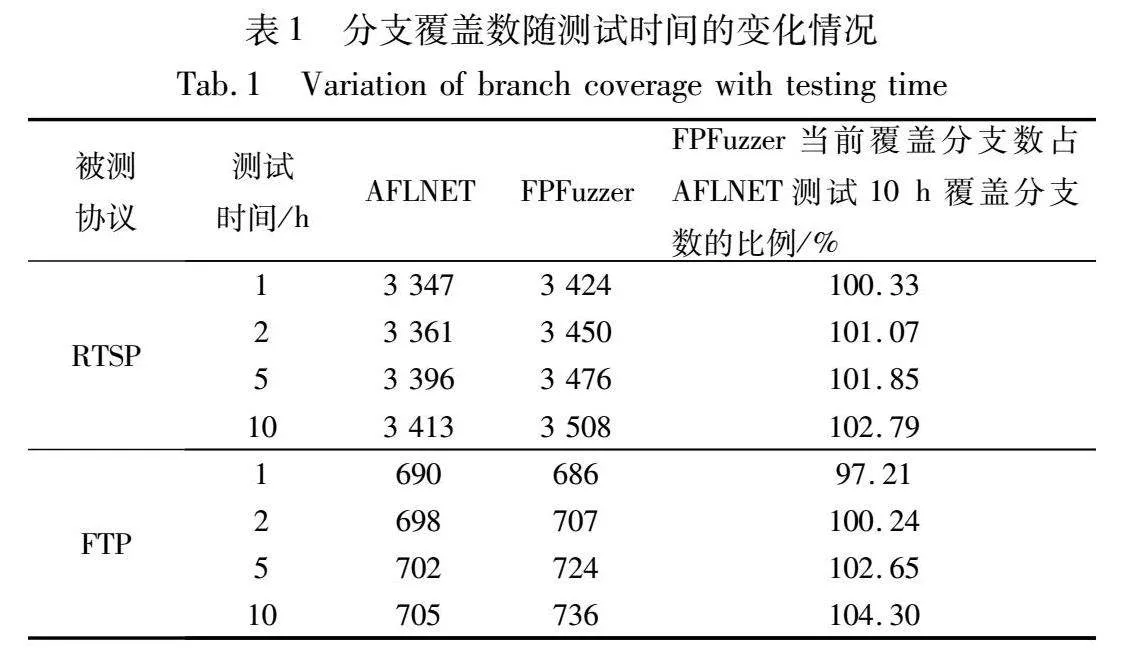
因此,本文通过实验比较了AFLNET和FPFuzzer覆盖分支的效率。具体地,在每个被测协议实现上进行3次实验,每次实验测试10 h,然后比较了AFLNET和FPFuzzer测试1 h、2 h、5 h和10 h时平均覆盖的分支数,并计算了FPFuzzer当前覆盖的分支数占AFLNET测试10 h所达到的最终覆盖分支数的比例。结果如表1所示。
可以看到,对于RTSP协议而言,FPFuzzer只需要测试1 h就可以达到AFLNET测试10 h的分支覆盖水平,实现了10倍加速。对于FTP协议而言,FPFuzzer也只需要测试2 h就可以达到AFLNET测试10 h的分支覆盖水平,实现5倍加速。FPFuzzer在这两个被测协议上表现出的加速倍率与测试用例接受率的提高比例高度相关,完全符合预期。这表明本文方法确实和第1章中分析的一致,可以通过提高生成的测试用例被被测协议实现接受的比例来大幅提高整体测试效率。
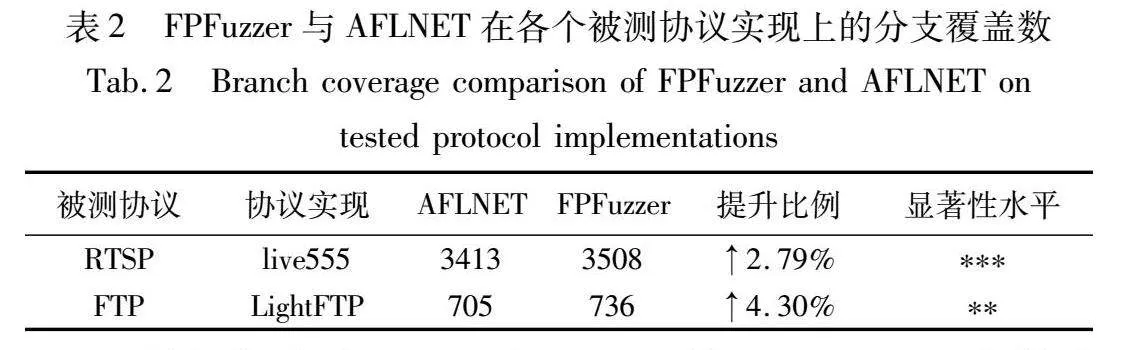
此外,由于FPFuzzer大幅提高了测试效率,同样测试10 h所能覆盖的分支数也会受益。因此,本文还额外比较了AFLNET和FPFuzzer测试10 h最终能够覆盖的分支数,并计算了其显著性。本文使用未配对的t-test来计算显著性,并假设每个模糊器在每个被测协议上的测试结果都符合高斯分布,每次测试的结果是从具有相同标准差的总体中进行抽样的。显著性水平以“*”表示,其中“ns”表示P值≥0.05,“*”表示P值<0.05,“**”表示P值<0.01,“***”表示P值<0.001。测试结果如表2所示。
可以看到,在RTSP和FTP协议上,FPFuzzer分别比AFLNET多覆盖2.79%和4.30%的分支。虽然提升比例不高,但均具有显著性,表明该提升非常稳定并非偶然。这表明FPFuzzer在大幅提高测试效率后,确实可以提高模糊测试的最终效果。
3.3 案例研究
为了明确本文方法在实际测试中的作用,本文以对FTP协议的“USER”报文的测试为例予以说明。
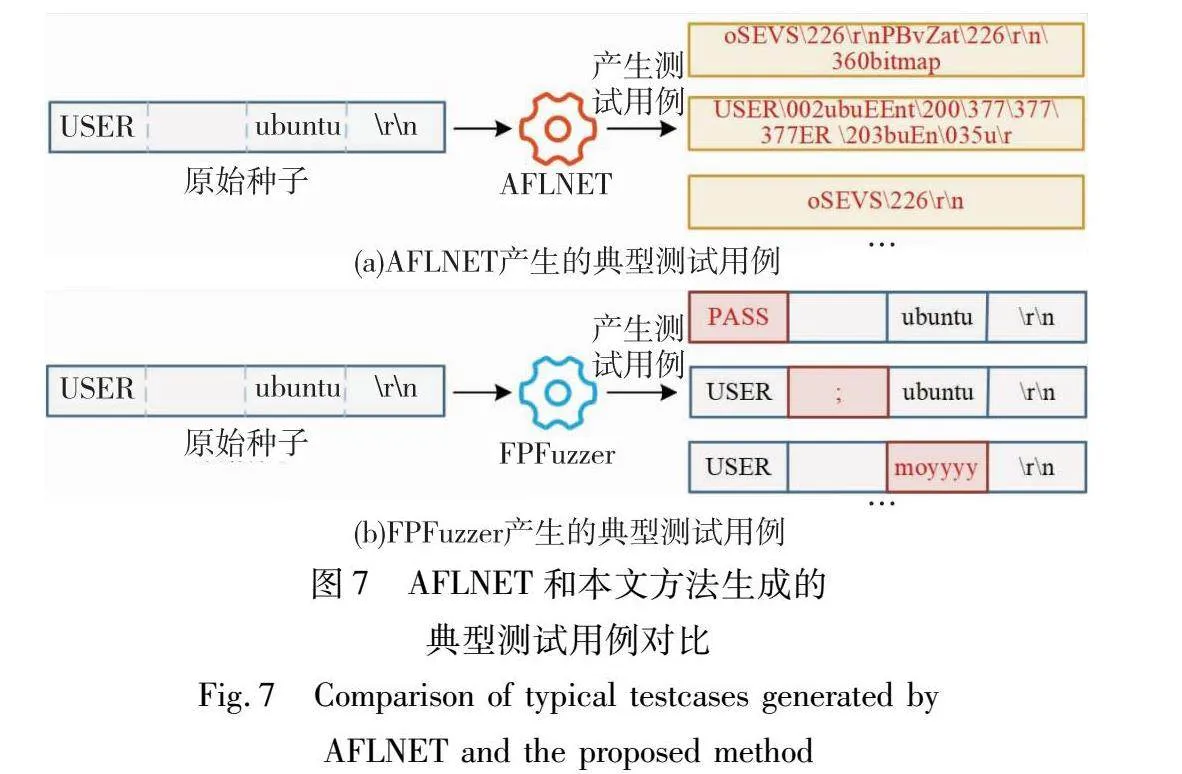
根据FTP协议的规定,与服务器连接后,客户端首先需要发送“USER”报文来进行登录。其中,可以使用真实的用户名进行登录,例如用户名为“User1”,则登录报文为“USER User1\r\n”。也可以使用匿名方式登录,登录报文统一为“USER anonymous\r\n”。无论使用何种登录方式,发送的登录报文均包含4个字段,其中第一个字段是请求类型,此时的值为“USER”;第二个字段为分隔符,此时的值为“ ”;第三个字段是用户名,可以取各种值,最后一个字段为报文结束标识,此时的值为“\r\n”。
对该类报文的一个实例“USER ubuntu\r\n”分别使用AFLNET的方法和本文方法进行变异,产生的测试用例的典型实例如图7所示。
可以看到,AFLNET对整个报文不加区分地进行变异,产生的测试用例基本完全失去了报文原有的结构,甚至连报文结束标志“\r\n”都可能被变异掉。因此,正如第1章中分析的那样,传统的基于变异的协议模糊测试产生的测试用例中能够被被测协议实现接受并进行实际处理的报文的比例是很低的。与此同时,FPFuzzer产生的典型测试用例有较大概率保留报文的基本格式,更有可能产生能够被被测协议实现接受的报文。
从上述实例中可以看到,本文方法确实可以提高生成的测试用例被被测协议实现接受的概率。因此,使用本文方法进行测试有更多机会探索被测协议实现的实际报文处理逻辑,从而大幅提高测试效率。
4 相关工作
4.1 基于变异的协议模糊测试
基于变异的协议模糊测试不需要人工提供的协议模板与状态机,而是将真实流量作为初始种子,通过对种子的变异来探索被测协议实现并动态构建被测协议实现的状态机。
AFLNET[11]是首个基于变异的协议模糊测试框架(AFLNWE是无状态的,不是真正意义上的协议模糊器),给出了基于变异的协议模糊器的基本工作流程和整体思想。它使用真实流量作为初始种子,使用被测协议实现返回的消息的响应码作为被测协议实现的当前状态,可以自动构建状态机,提高了协议模糊测试的便捷程度。
协议模糊测试中发送测试用例需要通过网络(一般通过TCP套接字),这一过程是比较耗时的。为了加快发送测试用例的过程,增加协议模糊测试的吞吐量,SnapFuzz[16]提出了将TCP套接字替换为UNIX套接字的方法。
协议模糊测试每次发送变异产生的测试报文前,需要先发送一系列的前缀报文,使服务器到达被测状态,而这个过程是很耗时的。为了解决这一问题,提出了使用虚拟机来保存已经到达目标状态的服务器的工作SNPSFuzzer(fuzzer for stateful network protocols using snapshots)[12]和Nyx-Net[11]。
由于很多协议的响应码种类很有限,AFLNET提出的基于服务器响应码的状态机是比较粗略的。为了提高状态机的精度,StateAFL[14]和NSFuzz[15]提出了使用被测协议实现的部分长期变量的值来刻画状态的方法。它们各自提出了一系列状态变量应该满足的条件,以此查找协议实现中可能用于表示状态的长期变量,然后通过将这些变量值进行散列来表示状态,使得状态机更加细粒度。
上述工作都是对基于变异的协议模糊测试的有益改进。然而,它们都将待变异的报文视为字节流,没有考虑协议对报文格式的要求,导致测试用例的有效率低。本文着力于此提出了字段感知方法,通过基于分隔符的字段划分方法和字段字典值学习方法,显著提高了测试用例的被接受率。
4.2 输入有格式的基于变异的模糊测试
在软件模糊测试中,也存在输入是有格式的文件(例如jpg、elf、MP3等)的情况,使用传统的基于变异的模糊测试方法同样存在测试用例大概率通不过被测软件的检测,无法进入实际处理的问题。为此,有研究提出了针对输入是有格式的文件的软件进行模糊测试的基于变异的模糊方法。
针对这一问题,AFLsmart[20]首先给出了一种解决方案,使用Peach Pit描述被测程序所需输入的格式、取值范围等,在模糊测试时,使用这些信息解析要变异的种子,然后根据结构信息对种子进行针对性变异,大概率保持生成的测试用例的结构完整性和语义完整性。
这种方式需要提供格式模板,使基于变异的模糊测试的一大优点——易用性,受到巨大的挑战。而且,与有格式文件相比,协议格式是更加复杂的,人工书写协议的格式文件实际上很难保证完全正确。本文着力于解决在没有人工提供报文模板的前提下,猜测被测协议可能的格式要求。
而ProFuzzer[21]提出了一种基于字节猜测的解决方案。在开始测试前,它先对种子的每一个字节的256种可能的取值分别进行测试,得到每个字节取值对整体分支覆盖数影响的分布,并合并相邻且分布相似的字节组成字段。之后,再根据分布的具体模式,将每个字段分为6大类(断言、原始数据、枚举、循环计数、偏移量、大小),并记录每个字段允许的取值范围。在测试时,根据字段的种类分配不同的变异能量,且对于关键类型的字段,在变异时大概率使其符合其取值范围。
这种方式适用的前提是每个字段的长度相对固定,否则,将无法得到较为通用的协议模板。而如果对于每个种子都要重新猜测字段,则其消耗是不可接受的。因此,这种方法可能适用于二进制协议,但对字段长度、字段数量都不固定的文本协议来说,是不适用的。本文着力于根据文本协议的特点,提出专门针对文本协议的字段感知方法。
5 结束语
基于变异的协议模糊测试,没有考虑被测协议对报文格式的要求,导致产生的测试用例被接受率过低,影响测试效率。为了解决这一问题,本文提出了基于字段感知的文本协议灰盒模糊测试方法,通过字段感知方法学习报文模板,提高生成的测试用例的被接受率。在此基础上,本文还提出了字段级变异策略、字段变异能量度量方法和基于请求消息类型的状态刻画方法,进一步提高测试效率。实验表明,基于本文方法所实现的模糊器原型FPFuzzer确实可以有效提高生成的测试用例被被测协议实现接受的比例,并大幅提高整体测试效率。
参考文献:
[1]Zhu Xiaogang, Wen Sheng, Seyit C,et al. Fuzzing: a survey for roadmap[J]. ACM Computing Surveys, 2022, 54(11s): 1-36.
[2]Liang Hongliang, Pei Xiaoxiao, Jia Xiaodong,et al. Fuzzing: state of the art[J]. IEEE Trans on Reliability, 2018, 67(3): 1199-1218.
[3]喻波, 苏金树, 杨强, 等. 网络协议软件漏洞挖掘技术综述[J]. 软件学报, 2023, 35(2): 1-27. (Yu Bo, Su Jinsu, Yang Qiang,et al. Survey on vulnerability mining techniques of network protocol software[J]. Journal of Software, 2023, 35(2): 1-27.)
[4]李东, 郝艳妮, 彭升辉, 等. 国家自然科学基金委员会网络安全现状与展望[J]. 网络与信息安全学报, 2022, 8(6): 90-101. (Li Dong, Hao Yanni, Peng Shenghui,et al. Network security of the national natural science foundation of China: today and prospects[J]. Chinese Journal of Network and Information Security, 2022, 8(6): 92-101.)
[5]李艳, 王纯子, 黄光球, 等. 网络安全态势感知分析框架与实现方法比较[J]. 电子学报, 2019, 47(4): 927-945. (Li Yan, Wang Chunzi, Huang Guangqiu,et al. A survey of architecture and implementation method on cyber security situation awareness analysis[J]. Acta Electonica Sinica, 2019, 47(4): 927-945.)
[6]Mamdouh A, Sadiq A. Security risks in the software development lifecycle[J]. International Journal of Recent Technology and Engineering, 2019, 8(3): 7048-7055.
[7]Shipra P, Rajesh K S, Angappa G,et al. Cyber security risks in globalized supply chains: conceptual framework[J]. Journal of Global Operations and Strategic Sourcing, 2020, 13(1): 103-128.
[8]Eddington M. peach-fuzzer-community[EB/OL]. (2021-03-30)[2024-04-02]. https://gitlab.com/peachtech/peach-fuzzer-community.
[9]Joshua P, Maximilian L, Ryan,et al. BooFuzz: network protocol fuz-zing for humans[EB/OL]. (2023-10-09) [2024-04-02]. https://github.com/ jtpereyda/boofuzz.
[10]Luo Zhengxiong, Yu Junze, Zuo Feilong,et al. BLEEM: packet sequence oriented fuzzing for protocol implementations[C]//Proc of USENIX Security Symposium. Berkeley, CA: USENIX Association Press, 2023: 4481-4498.
[11]Van Thuan P, Marcel B, Abhik R. AFLNET: a greybox fuzzer for network protocols[C]//Proc of the 13th International Conference on Software Testing, Validation and Verification. Piscataway, NJ: IEEE Press, 2020: 460-465.
[12]Li Junqiang, Li Senyi, Sun Gang,et al. SNPSFuzzer: a dast greybox fuzzer for stateful network protocols using snapshots[J]. IEEE Trans on Information Forensics and Security, 2022, 17: 2673-2687.
[13]Sergej S, Cornelius A, Andrea J,et al. NYX-Net: network fuzzing with incremental snapshots[C]//Proc of the 7th European Conference on Computer Systems. New York: ACM Press, 2022: 166-180.
[14]Roberto N. StateAFL: greybox fuzzing for stateful network servers[J]. Empirical Software Engineering, 2022, 27(7): 191.
[15]Qin Shisong, Hu Fan, Ma Zheyu,et al. NSFuzz: towards efficient and state-aware network service fuzzing[J]. ACM Trans on Software Engineering and Methodology, 2023, 32(6): 1-26.
[16]Anastasios A, Cristian C. SnapFuzz: high-throughput fuzzing of network applications[C]//Proc of the 31st ACM SIGSOFT International Symposium on Software Testing and Analysis. New York: ACM Press, 2022: 340-351.
[17]张冠宇, 尚文利, 张博文, 等. 一种结合遗传算法的工控协议模糊测试方法[J]. 计算机应用研究, 2021, 38(3): 680-684. (Zhang Guanyu, Shang Wenli, Zhang Bowen,et al. Fuzzy test me-thod for industrial control protocol combining genetic algorithm[J]. Application Research of Computers, 2021, 38(3): 680-684.)
[18]徐威, 李鹏, 张文镔, 等. 网络协议模糊测试综述[J]. 计算机应用研究, 2023, 40(8): 2241-2249. (Xu Wei, Li Peng, Zhang Wenbin,et al. Survey of network protocol fuzzing[J]. Application Research of Computers, 2023, 40(8): 2241-2249.)
[19]Wu Mingyuan, Jiang Ling, Xiang Jiahong,et al. One fuzzing strategy to rule them all[C]//Proc of the 44th International Conference on Software Engineering. New York: ACM Press, 2022: 1634-1645.
[20]Van Thuan P, Marcel B, Andrew E S,et al. Smart greybox fuzzing[J]. IEEE Trans on Software Engineering, 2019, 47(9): 1980-1997.
[21]You Wei, Wang Xueqiang, Ma Shiqing,et al. ProFuzzer: on-the-fly input type probing for better zero-day vulnerability discovery[C]//Proc of IEEE Symposium on Security and Privacy. Piscataway, NJ: IEEE Press, 2019: 769-786.
